基于YOLOv5s改進的口罩佩戴檢測算法
2023-07-21 01:15:22葛延良李德鑫王冬梅董太極
黑龍江大學自然科學學報 2023年3期
葛延良, 李德鑫, 王冬梅, 董太極, 賀 敏
(1.東北石油大學 電氣信息工程學院, 大慶 163000; 2.中國移動通信集團黑龍江有限公司 大慶分公司, 大慶 163000)
0 引 言
根據世界衛生組織的通告,戴口罩是預防新型冠狀病毒等空氣傳播傳染病最有效的措施之一。疫情期間,為了有效減少新型冠狀病毒的傳播,在公共場所或室內工作時,應當佩戴口罩。采用人工監督和檢測方法不僅耗費人力,還會存在與被檢查人員接觸從而感染病毒的風險。因此,對于企業和商場等公共場所來說,能夠實時的進行口罩佩戴檢測是非常有必要的。
隨著深度學習技術的飛速發展,使得計算機視覺領域取得巨大進展。目標檢測屬于計算機視覺中非常重要的研究方向,目前主要有基于雙階段的目標檢測算法和基于單階段的目標檢測算法兩類。其中,基于雙階段的目標檢測算法的典型代表主要有區域卷積神經網絡(Region-convolutional neural network, R-CNN)[1]、快速的區域卷積神經網絡(Fast Region-convolutional neural network, Fast R-CNN)[2]、更快的區域卷積神經網絡(Faster Region-convolutional neural network, Faster R-CNN)[3]、基于掩碼分割的區域卷積神經網絡(Mask Region-convolutional neural network, Mask R-CNN)[4]、特征金字塔網絡(Feature pyramid network, FPN)[5]等,此類算法對目標進行檢測時分為兩個步驟:首先生成一系列候選框,再用卷積神經網絡進行分類和邊框回歸。基于單階段的目標檢測算法把生成候選框和分類回歸這兩個步驟合并在一個網絡中進行,常見的基于單階段目標檢測算法有OverFeat[6]、單階段多錨框目標檢測器(Single shot multibox detector, SSMD)[7]、你只需看一次(You only look once, YOLO)[8-11]系列等。考慮到在實際監控任務中需要達到實時檢測的目的,而單階段的目標檢測算法在檢測速度上可以達到實時的效果。
近年來,為了解決口罩佩戴檢測的精度與速度問題,許多學者都已經將YOLO系列目標檢測算法應用到了口罩佩戴檢測應用中。張烈平等使用MobileNetV2作為特征提取網絡與YOLOv2相結合構成口罩佩戴檢測網絡模型,使其均值平均精度(mean average precision,mAP)達到91.3%[12]。張鑫等將在特征提取網絡中引入空間金字塔池化,并結合GIoU損失函數,在其使用的數據集上對比原始YOLOv3將mAP提高到90.1%[13]。王藝皓等提出在YOLOv3算法中引入改進的空間金字塔池化結構,從而實現特征增強,在其使用的數據集上mAP達到90.2%[14]。談世磊等基于YOLOv5網絡模型,在原數據集基礎上進行擴充,采用翻轉和旋轉兩種方式得到30 000張圖片來用于訓練,使mAP達到92.4%[15]。Yang等采用將GIoU與Center Loss相結合的方式來提升口罩識別精度,在其數據集上mAP達到97.9%[16]。Popescu等通過將YOLOv5與ResNet相結合,使得在其數據集上mAP達到87%[17-18]。因此,本文選擇YOLOv5s算法為基礎進行口罩佩戴檢測。
為了解決錯檢和漏檢等問題,Hou等提出協調注意力機制(Coordinate attention, CA)模塊來提高檢測性能[19]。本文通過在YOLOv5s網絡模型中融入改進的CA注意力機制模塊CA-A來增強網絡的特征提取能力,并引入改進的CIoU損失函數AD-CIoU來提高邊界框的定位準確度。實驗表明所提出的口罩佩戴檢測算法精度相較于YOLOv5s有所提升。
1 口罩佩戴檢測模型設計
1.1 改進的YOLOv5s模型設計
YOLOv5s的網絡結構由四部分組成,分別為輸入端、主干網絡Backbone、Neck和輸出端,其網絡結構如圖1所示。YOLOv5s所使用的主干特征提取網絡為跨階段局部網絡(Cross stage partial dark network, CSPDarknet),其中包含了CBS模塊、C3模塊[20]和空間金字塔池化模塊(Spatial pyramid pooling, SPP)[21]。CBS模塊可以在圖像進行下采樣,其中第一個CBS模塊的卷積核尺寸為6×6用于替換Focus結構,以達到提高運算速度、減少內存開銷的目的。C3模塊主要功能為圖像特征的提取,SPP模塊主要解決了卷積神經網絡對圖像進行重復特征提取的問題,既提高了產生候選框的速度又節約了計算成本。但是小目標特征信息在C3模塊多次作用下,容易造成丟失現象,從而引起錯檢與漏檢問題。為了提高檢測的精確度,在C3模塊后引入改進的CA-A注意力機制模塊來增強網絡特征提取能力,達到提升檢測精度的目的。改進后的Backbone 如圖2所示。

圖1 YOLOv5s網絡

圖2 改進的主干網絡
1.2 注意力機制的創新
CA注意力機制模塊使用的是Sigmoid歸一化,但是Sigmoid函數會存在梯度飽和現象,即在當X>>0或X<<0時,梯度接近于0,導致訓練緩慢和梯度消失。因此,提出了一個改進注意力機制模塊CA-A,將ACON激活函數與CA注意力機制模塊相融合的方法。與通過二維全局池化將特征張量轉換為單個特征向量的通道注意力不同,CA-A注意力模塊可以看作一個計算單元,其目的是增強網絡模型的特征表達能力。CA-A注意力機制通過坐標信息嵌入和坐標注意力生成兩個步驟來進行編碼,這種編碼過程可以提升坐標注意力的準確度,從而幫助模型更好識別特征信息。ACON激活函數可以學習并決定是否要激活神經元,從而提高檢測精度。CA-A注意力機制模塊的水平與垂直的特征信息由XAvg Pool和YAvg Pool沿著x與y軸做平均池化提取,隨后進行特征信息的聚合并使用 ACON 激活函數進行歸一化,具體如圖3所示。
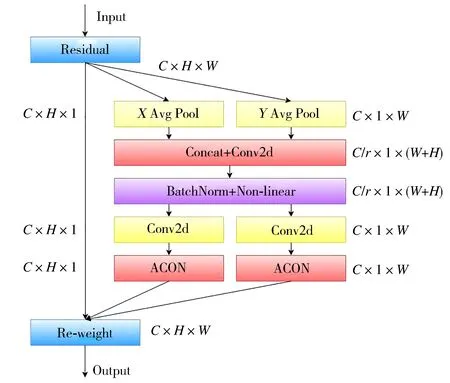
圖3 CA-A注意力機制模塊
1.3 損失函數的改進
原YOLOv5s網絡模型中采用了CIoU作為Bounding Box的損失函數,其公式定義為:
(1)
由于CIoU采用的是預測框與真實框的寬和高的比值,所以會存在一定的模糊性,即一旦收斂到預測框與真實框的寬和高的比值呈線性比例狀態時,會導致預測框回歸時寬和高不可以同時增加或減少。為解決上述問題,提出了AD-CIoU,將CIoU結合角度損失與距離損失來提升邊界框定位的精確度。角度損失公式定義為:
(2)
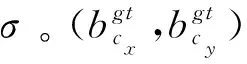
(3)
(4)
(5)
距離損失的定義和具體參數公式為:
(6)
(7)
(8)
γ=2-Λ
(9)
改進后的YOLOv5s網絡模型的回歸損失函數AD-CIoU公式為:
(10)
2 實驗過程及結果分析
2.1 模型訓練
采用Kaggle的Face mask detection數據集進行訓練,此數據集一共5 049張圖片,其中訓練集含有3 390張圖片,驗證集與測試集分別為699張和960張圖片。
具體的測試環境:CPU采用12核 Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz,GPU為Nvidia GeForce RTX 2080ti。深度學習框架為PyTorch1.8.1,編譯語言Python3.8,Cuda版本為11.1。
在目標檢測領域,性能評價指標常用精準率P(Precision)、召回率R(Recall)和均值平均精度mAP(mean average precision)來進行衡量檢測效果。其具體計算公式為:
(11)
(12)
(13)
采用官方預訓練權重,輸入圖像的尺寸大小為640×640,訓練的批量大小Batchsize為16,迭代次數Epoch為300次。
2.2 實驗結果
原YOLOv5s與改進的YOLOv5s的mAP數據對比如圖4所示。圖中YOLOv5s的map@0.5達到了0.944,改進后的YOLOv5s的map@0.5達到了0.961,提升了1.7%。
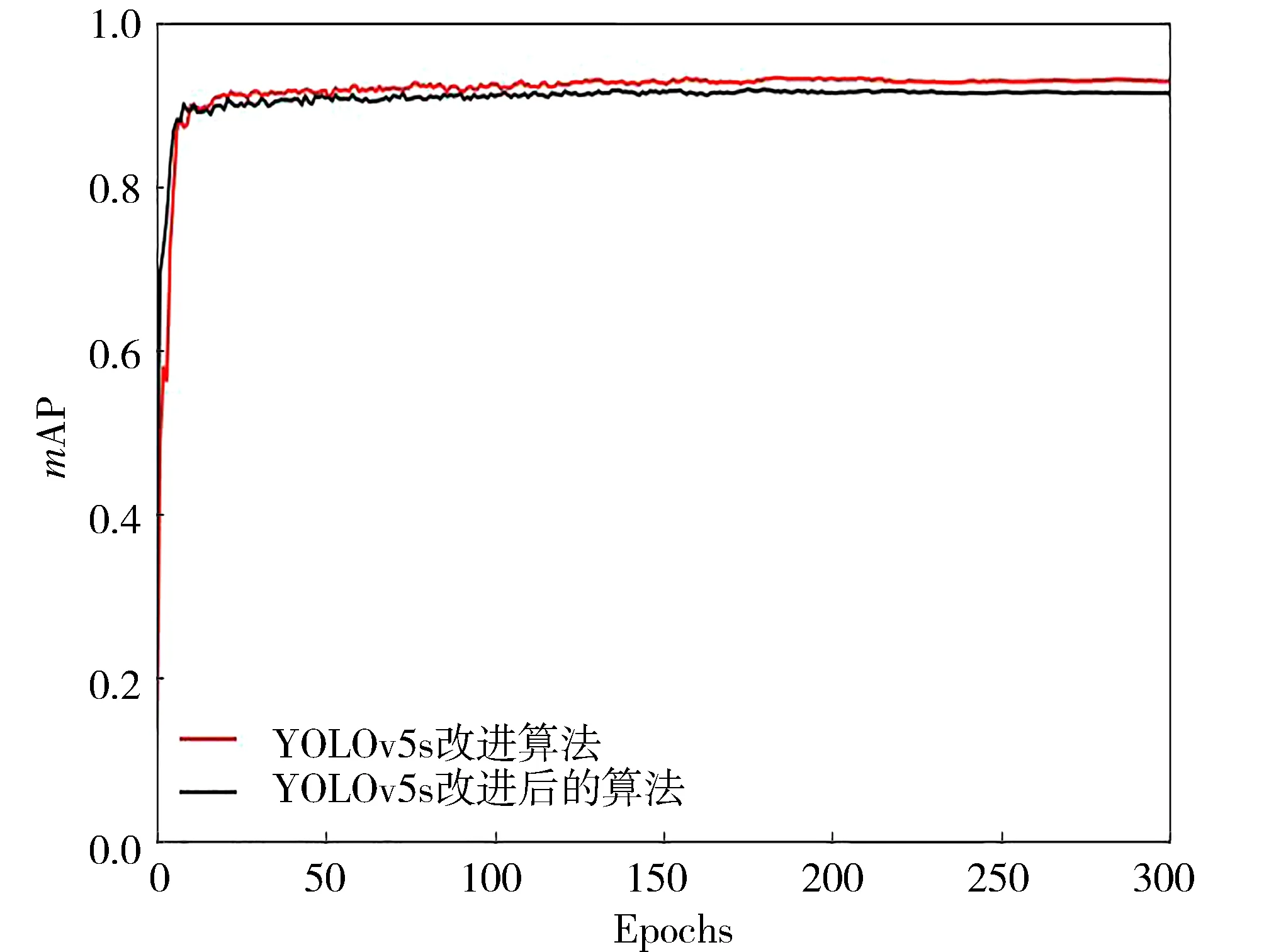
圖4 數據對比圖
2.3 YOLOv5s消融實驗
為驗證本研究提出的改進方案,在相同的實驗環境與數據集下,進行消融實驗。實驗結果如表1所示。可以看出,在引入CA注意力機制時,檢測均值平均精度mAP達到了0.957。CA注意力融合AD-CIoU損失函數時,召回率Recall提升到0.929。僅使用CA-A注意力機制時,mAP提升到了0.959。CA-A結合AD-CIoU損失函數在精度Precision和均值平均精度mAP上均有提升,可見改進的方案相比原YOLOv5s有明顯優勢。

表1 YOLOv5s消融實驗
2.4 對比實驗
為了驗證本研究提出的改進算法具有更好的檢測效果,選擇YOLOv3-tiny、YOLOv4-tiny、YOLOv5s以及YOLOv5s結合SENet和CBAM注意力機制在相同配置下進行對比實驗,結果如表2所示。
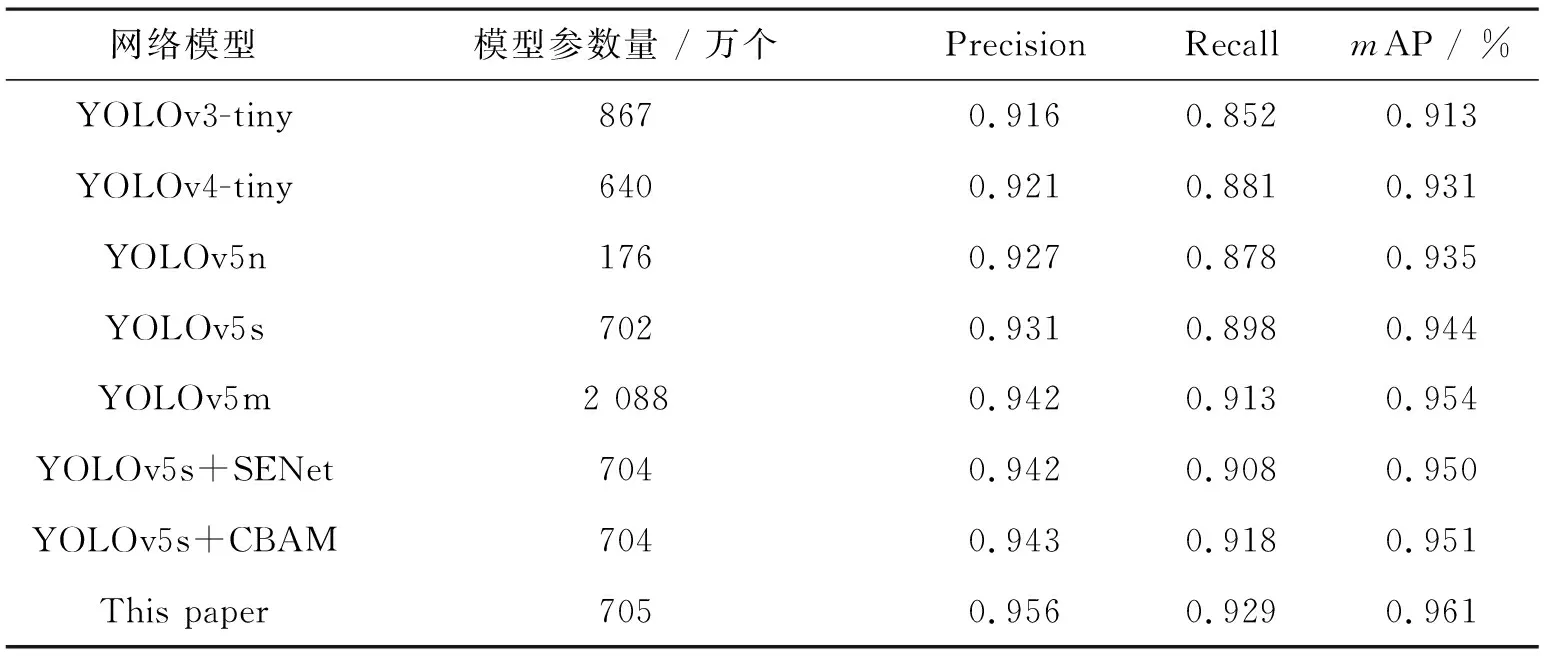
表2 不同網絡對比數據
為了展示改進的YOLOv5s網絡模型的檢測效果,從測試集中隨機選取圖片進行測試,原YOLOv5s網絡模型與改進后的YOLOv5s網絡模型的對比數據如圖5和圖6所示。原始YOLOv5s在圖中的平均檢測精度達到了0.85和0.83,改進的YOLOv5s在圖中的平均檢測精度可以達到0.95和0.91,可見在多人密集的情況下,改進后的YOLOv5s網絡模型具有更高的檢測精度。

圖5 YOLOv5s檢測效果

圖6 改進的YOLOv5s檢測效果
3 結 論
為了提升口罩佩戴檢測的精度,提出了一種基于YOLOv5s改進的口罩佩戴檢測算法。原CA注意力機制模塊使用Sigmoid歸一化會存在梯度消失和訓練緩慢等問題,所以將ACON激活函數融合CA注意力機制模塊構成新的CA-A注意力機制模塊,并結合在原始YOLOv5s的主干網絡部分,通過坐標信息嵌入和坐標注意力生成兩個步驟來提升坐標注意力的準確度,從而達到增強網絡的特征提取能力;CIoU損失函數一旦收斂到預測框與真實框的寬和高的比值呈線性比例狀態時,會導致預測框回歸時寬和高不可以同時增加或減少,為了改善其定位的模糊性,將CIoU通過結合角度損失和距離損失來構建新的AD-CIoU損失函數,以達到提升回歸精度的目的。經過實驗結果證明,改進后的算法相比原始YOLOv5s網絡模型mAP提升了1.7%,達到了96.1%,同時與其他算法對比明顯具有更高的精確度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年21期)2018-11-09 01:23:06
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國衛生(2015年9期)2015-11-10 03:11:12
