面向色情音頻檢測的內容分類研究*
2023-08-02 07:06:54司朋舉
計算機與數字工程 2023年4期
司朋舉
(中國石油大學(華東)計算機科學與技術學院 青島 266580)
1 引言
色情音頻檢測及有效屏蔽色情信息一直是網站、直播平臺信息安全檢測的重要組成部分。目前存在許多用來防止未成年人瀏覽不良網站網頁信息的網絡防火墻軟件,例如格雷盒子(PIRPDA)、凈網大師(KNN)等,但該類軟件只針對含有不良文字和圖片內容的信息進行攔截,且在音頻不良信息過濾方面普遍需要依靠人工對初步未過濾的音視頻做進一步的審核,因此在管理方面工作繁忙且浪費人力,容易造成誤判漏判等情況。
目前,國內外部分研究者將目光聚焦在了視頻、彈幕文字檢測上,為不良信息檢測提供了很好的技術、思想以及理論支撐。但在不良信息傳播過程中,音頻形式占據了很重要的地位,如談話聊天、脫口秀、在線廣播等一些以語音為主的直播節目,視頻檢測所用到圖像處理技術,如裸露檢測[1]、動作識別[2],并不適用于音頻檢測場景下。
在色情音頻分類與檢測問題中[3~4],工業界及傳統的色情音頻檢測一般通過檢索關鍵詞過濾不良信息,需要龐大的色情關鍵詞庫以及需要對關鍵詞庫不斷更新支撐[5~9]。與傳統的機器學習相比,深度學習在圖像識別、語音識別、文本分析等方面有著更加出色的表現。同時能夠有效地解決梯度擴散、過擬合等問題[10~15]。因此在色情音頻信息檢測問題中應用深度學習技術是解決傳統方法所面臨問題的一種有效途徑[16~17]。然而目前國內外缺乏公開的色情音頻數據庫去應用測試實驗效果是應用深度學習技術檢測音頻中色情內容中的關鍵問題之一。因此本文針對色情音頻信息檢測展開研究,實現對網絡色情音頻的精準而快速檢測,過濾網絡傳播中的色情音頻信息,具有一定的實際應用價值。
2 基于內容的色情音頻檢測算法
本章將通過借鑒語音識別和文本分類領域中的經典成果[17~18]以及作者的工作經驗,設計如圖1所示的基于內容的色情音頻檢測算法,基于GPL-Licensed 制作開源音頻剪輯軟件對收集的原始音頻以色情、非色情為標簽剪切以及預處理分為訓練集和測試集,同時對收集的原始文本以及訓練集中音頻文本化后的數據預處理分為訓練集和測試集,隨后訓練文本分類模型,實現檢測文本化后的音頻數據信息色情檢測。
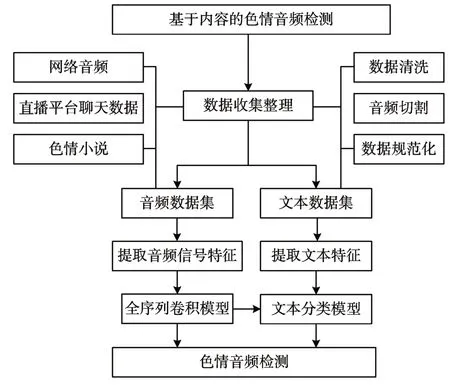
圖1 基于內容的色情音頻檢測框架
2.1 基于全序列卷積神經網絡的語音識別算法
在實現色情音頻檢測過程中或者在應用色情音頻檢測模型之前,需要將音頻文本化提取出內容信息,因此本文采用科大訊飛提出的較為經典的全序列卷積神經網絡框架實現語音識別。首先對音頻的時域信號通過Python 中的librosa 等開發包進行分幀、加窗以及傅里葉變化得到每個音頻所對應的時頻圖,如圖2 所示,每個時頻圖包含了時間、頻率以及幅度,其中時間通過x 軸表示,y 軸表示頻率,幅度高則用亮色表示,低用深色表示。

圖2 全序列卷積神經網絡輸入時頻圖
圖中x 軸表示音頻時間,y 軸表示音頻頻率,可看作圖像的兩個維度,直接作為全序列卷積神經網絡的輸入,隨后對時頻圖做多次卷積、池化操作組合,輸入到全連接層中,訓練輸出單元與識別結果相對應。網絡架構如圖3所示,每個卷積層使用3×3 的小卷積核,并在多個卷積層之后再加上池化層,在增強了網絡表達能力的同時表達了語音的長時相關性。
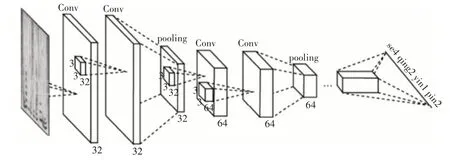
圖3 全序列卷積神經網絡架構示意圖
2.2 文本分類
在音頻及文本數據預處理后,經過word2vec轉化為向量輸入,使用基于深度學習的文本分類技術訓練模型,以檢測原始音頻是否為色情,其中訓練步驟如下:
Step 1:首先將切割后的文本使用Python 版的JieBa 分詞工具包分詞,隨后轉化為One-Hot 向量作為word2vec 的輸入,經隱藏層以及softmax 回歸訓練后,將參數作為詞的向量化表示;
Step 2:假設Xi∈Rk表示句子中的第i 個單詞對應的k 維向量,那么將長度為n 的句子可表示為X1:n=X1⊕X2⊕…Xn,其中⊕為連接運算符;
Step 3:隨后卷積提取連接而成的句子Xi:i+j特征ci,其中Xi:i+j由Xi,Xi+1,Xi+j連接而成;
Step 4:使用多個不同窗口大小的卷積核應用于句子Xi:i+j提取多個特征ci組成c;
Step 5:將特征輸入全連接softmax 層,輸出標簽的概率分布,預測類別標簽的置信度;
Step 6:隨后輸入測試集,依次將預測類別標簽與實際標簽對比,計算模型分類準確度。
2.2.1 基于TextCNN的色情文本分類
TextCNN 在網絡結構上包含了一個卷積層、一個最大池化層,以及softmax 分類預測層,支持Word2Vec或者GLOV 等向量化方式。如圖4所示,基于TextCNN 的色情文本分類模型將一個句子分割成單詞,隨后通過經典的word2vec將單詞映射成詞向量,在對輸入向量進行卷積操作后,通過采用最大池化層減少參數以增加優化速度,同時為了避免模型過擬合,最終計算softmax 預測得到的標簽置信度以實現色情文本檢測。

圖4 TextCNN模型訓練示意圖
2.2.2 基于TextRNN的色情文本定義
RNN 模型具有短期記憶功能,在引入門控機制解決長期依賴問題后,比較適合處理自然語言處理等序列問題。2016 年PengfeiLiu 等提出TextRNN 應用于文本分類任務中。基于TextRNN的色情文本分類模型,經過word2vec 文本向量化后,將雙向長短期記憶網絡在最后一個時間步上隱藏狀態,且連接其他時間步長后,其結果作為softmax 函數的輸入,得到色情類別的概率分布。結構如圖5所示。
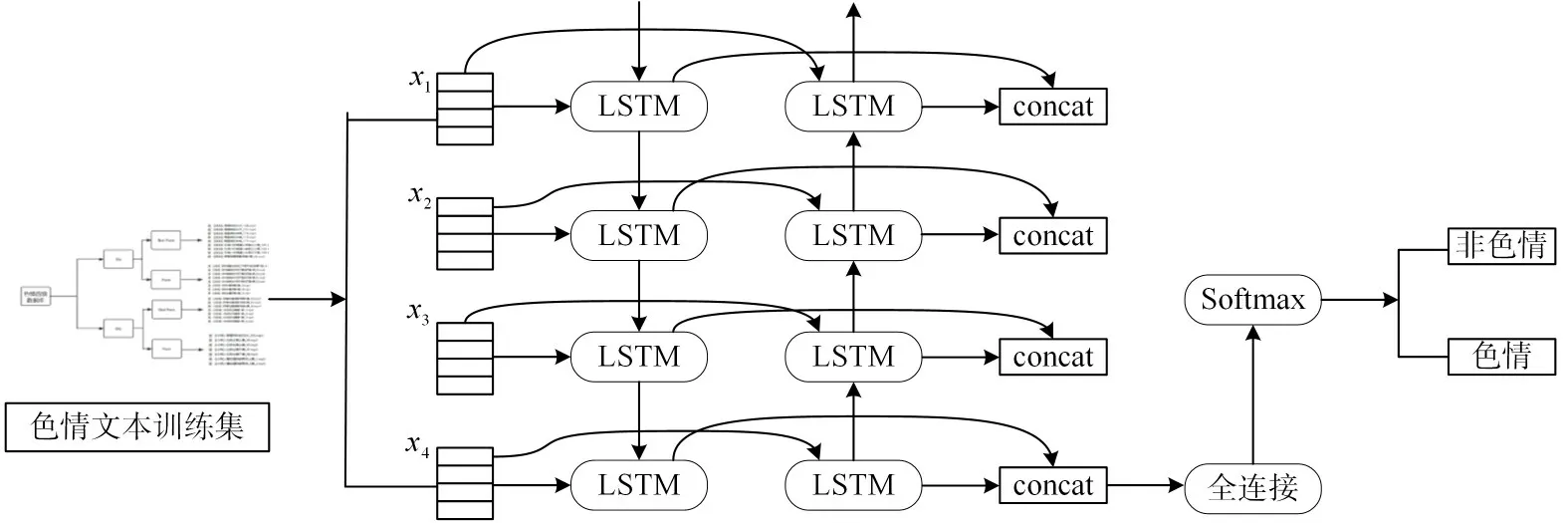
圖5 TextRNN模型訓練示意圖
3 實驗結果與分析
本文依據色情音頻以及文本特點特征,收集整理形成色情文本訓練集以及色情音頻測試訓練集,其中共1387 個音頻,包含了897 個色情音頻片段,490個非色情音頻片段,每段音頻持續1min或30s,同時本文提出了一種基于內容的色情音頻檢測方法,采用基于深度學習的文本分類技術作為文本分類模塊,并將其與語音識別技術相結合,用于色情音頻檢測以及評估本文所公開數據集。并提出了基于內容的色情音頻檢測算法,驗證了色情音頻數據集的合理性。實驗綜合比較了本文所提算法以及經典音頻分類算法在色情音頻數據集上的各項指標如表1 所示,其中TP表示綜合真正率、TN表示綜合真負率,FP表示假正率,FN表示假負率,accuracy表示正確率。
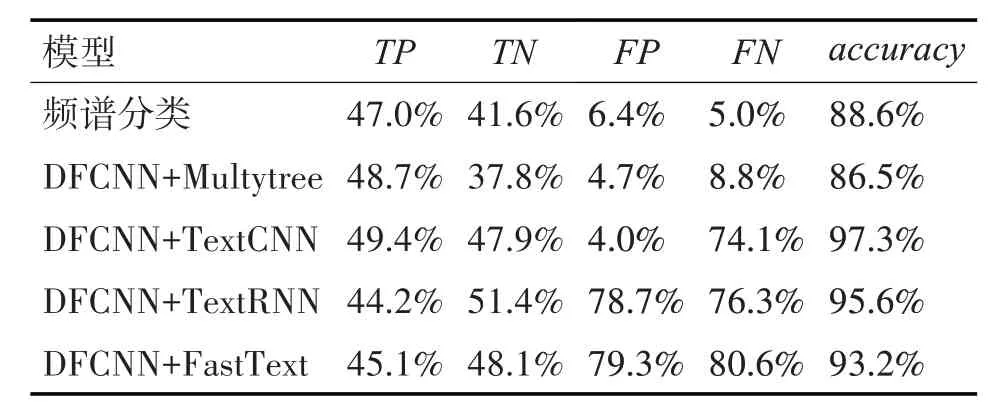
表1 各方法在色情音頻數據集中的各項指標
可以看出在識別色情音頻問題中,本文將全序列卷積神經網絡結合文本分類技術經典模型后,所提出的基于內容的色情音頻檢測算法,同等條件下相較于基于頻譜特征的分類模型準確率可提高將近9%左右,相較于多叉樹關鍵詞匹配算法可提高將近11%左右,且真正率和真負率均有提高。其中全序列卷積神經網絡結合TextCNN 后在數據集上的平均分類正確率為97.3%。為便于工作人員后續使用,形成了cs 形式的客戶端,其流程界面如圖6所示。
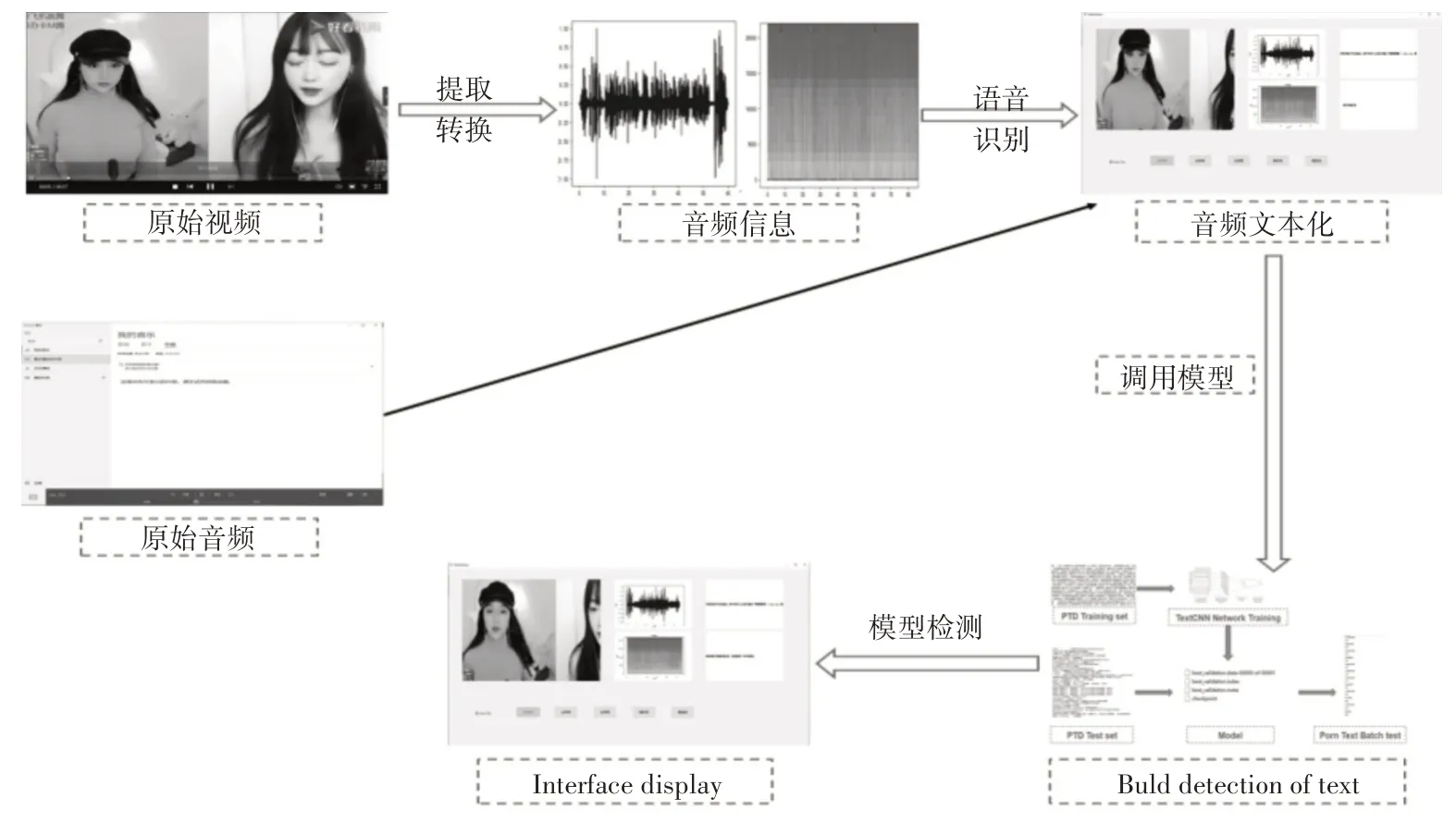
圖6 cs客戶端系統流程圖
4 結語
本文通過收集分析色情音頻以及文字小說,整理形成了色情音頻、文本數據集,結合語音識別與文本分類等技術提出了CA-PAD算法,驗證了數據集的合理性,實現了基于內容的面向網絡色情音視頻智能監管的系統設計實現。在多種文本分類經典模型算法的基礎上進行有效融合,使之更加適用于網絡環境中的音視頻監管,保證青少年的瀏覽信息安全健康以及平臺工作的順利開展,以及充分考慮音頻其他特征。將成為下一步的主要研究工作,且在實驗訓練過程中,隨著訓練集的擴充,模型各項指標均有提高的趨勢,因此如何利用數據增強等算法擴充數據集也是下一步的主要研究工作。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
海峽科技與產業(2016年3期)2016-05-17 04:32:12
