基于預訓練模型的雙通道情感分類方法
2023-08-26 08:37:58石杰
電腦知識與技術 2023年20期
石杰

關鍵詞: 預訓練模型; 雙通道模型; TCN網絡; BiGRU網絡; 情感分類
中圖分類號:TP18 文獻標識碼:A
文章編號:1009-3044(2023)20-0031-05
0 引言
隨著人工智能技術的不斷發展,情感分類技術在現實生活中變得越來越重要,目前已在多個領域得到了廣泛應用,例如輿情分析、產品推薦、情感監測等。深度學習興起以來,基于深度學習的神經網絡方法已成了自然語言處理任務的研究熱點。Mikolov等人[1]最先提出了Word2vec 模型,包括 CBOW 詞袋模型和Skip-gram 模型用于當前詞與上下文內容的預測。Pennington 等人[2]提出了具有將全局統計信息與局部上下文相結合特點的 GloVe 模型。Devlin 等人[3] 結合ELMo 和 GPT 模型提出了 BERT 模型,通過字向量和多頭自注意力機制,解決了現有詞向量模型無法捕獲完整文本語義信息的問題。隨后百度團隊以 BERT 模型為基礎,針對中文文本任務進行優化提出了ERNIE [4]模型,并取得了良好的效果。Bai等人[5]提出了TCN網絡,并將因果卷積、膨脹卷積和殘差連接應用其中,使其得到了廣泛應用。GRU網絡是Tang 等人[6]在繼 LSTM 網絡之后對RNN做出的又一次優化,將LSTM 中的三個門結構進行了簡化,提升了訓練效率。Adabelief算法[7]是一種新興的優化算法,它結合了Adam和AMSGrad的優點,能夠為模型訓練提供高效穩定的支持,特別是在處理文本任務時表現出色。綜上,本文基于詞向量表示、情感特征提取、模型訓練優化三方面考慮,提出了一種基于預訓練模型的雙通道情感分類方法。
1 相關理論技術
1.1 ERNIE模型
ERNIE 模型是為了使模型訓練時能夠更好地匹配中文語義語法所做出的改進,在結構上,仍然是采用雙向Transformer進行特征學習。和BERT模型的不同之處在于該模型訓練所使用的數據全部來自中文語料庫,通過大量中文語料的訓練使其能夠更好地適用于中文文本處理任務。另外,ERNIE 模型在掩碼機制方面也做出了改進,它不同于BERT 模型隨機地遮蓋單個漢字,而是利用詞語掩碼和實體掩碼來遮蓋詞語或命名實體,因為漢語的語法結構不同于其他語言,如果只遮蓋某個單獨漢字,極大可能會拆散字詞間的關系,導致特征提取不準確,而ERNIE 模型的掩碼機制能很好地預測完整語義信息。
1.2 TCN網絡
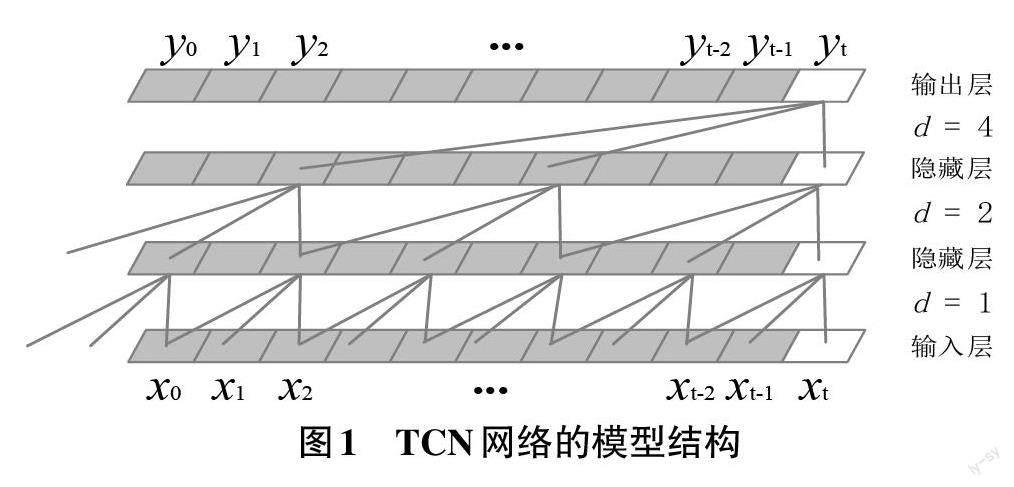
TCN(Temporal Convolutional Network) 網絡基于卷積神經網絡的時間序列進行建模,一般用于時序數據的建模任務,其主要思想是利用卷積神經網絡提取數據中的特征,通過殘差網絡進一步優化模型的性能。相較于傳統的循環神經網絡,TCN網絡在處理長序列數據時更為高效,而且可以避免梯度消失的問題。TCN網絡所具有的因果卷積和膨脹卷積,不僅可以用于時間序列預測,而且在語音識別、自然語言處理、圖像處理等多個領域也得到了廣泛應用。TCN網絡的模型結構如圖1所示。
1.3 GRU網絡
GRU(Gated Recurrent Unit) 網絡,即門控循環單元,是傳統循環神經網絡的變體模型。相比傳統的循環神經網絡,GRU具有更好的長期記憶能力和更少的參數量,可以有效避免傳統RNN中遇到的梯度消失和梯度爆炸問題。GRU的結構也比較簡單,由更新門、重置門和候選隱藏狀態組成。其中,更新門控制了前一時刻的隱藏狀態有多少信息需要傳遞給當前時刻,重置門控制了前一時刻的隱藏狀態需要被多大程度地忘記,而候選隱藏狀態則是當前時刻的輸入和前一時刻的隱藏狀態的線性組合。GRU網絡結構如圖2 所示:
2 基于預訓練模型的雙通道情感分類方法
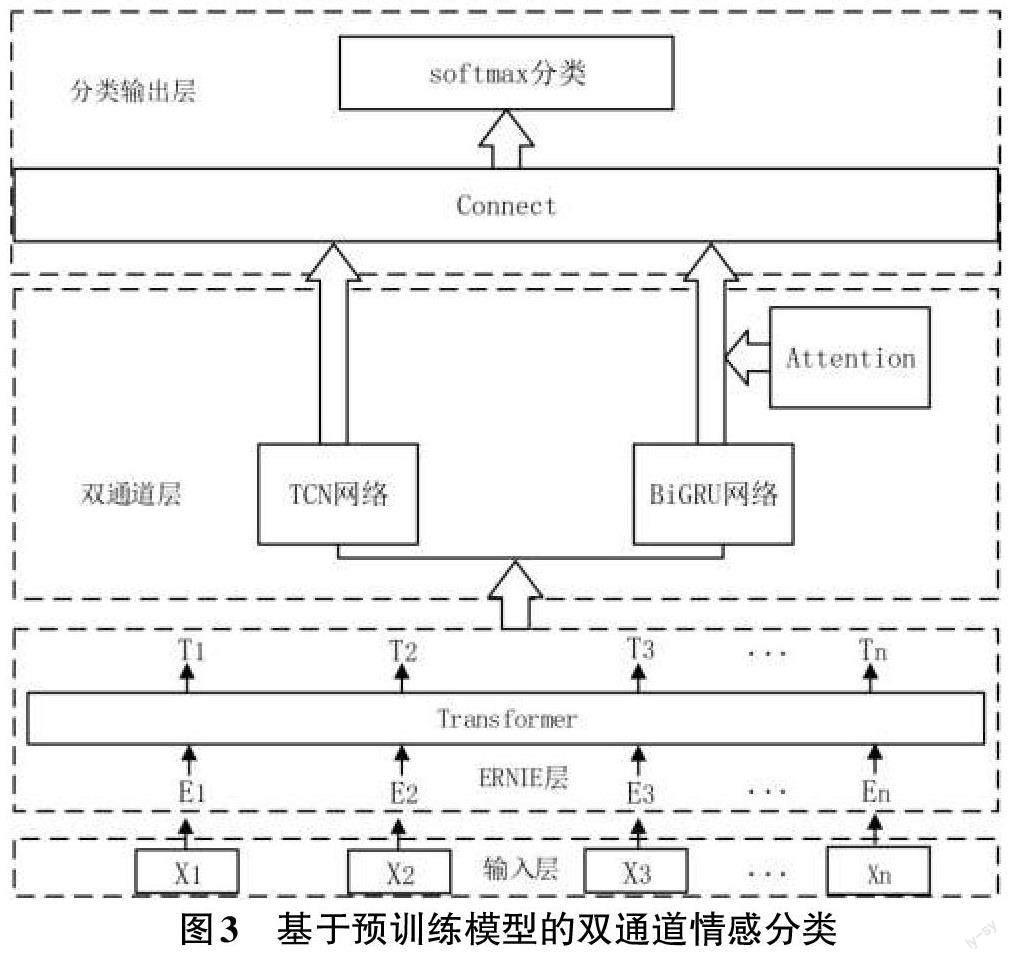
由于情感特征的提取具有一定的復雜性,因此基于深度學習的神經網絡方法目前仍是情感分類任務中研究最為廣泛的方法之一。黃澤民等人[8]提出在BERT模型的預訓練下,利用BiSRU網絡和注意力機制進行情感特征提取。胡玉琦等人[9]針對文本評論數據利用BiGRU-CNN模型和注意力機制進行情感分類任務。蘇天等人[10]提出利用BERT模型結合BiGRU網絡對水利新聞數據進行情感分析研究。本文基于Adabelief 算法,并結合ERNIE 預訓練語言模型和TCN、Att-BiGRU雙通道網絡提出了一種基于預訓練模型的雙通道情感分類方法。其結構如圖3所示:
2.1 預訓練層
原始文本數據經過預處理后以詞向量的形式輸入預訓練層中,經過多層的雙向Transformer 進行訓練后形成最終的文本特征。該模型中預訓練層使用ERNIE模型,由于ERNIE模型基于雙向結構的Trans?former進行訓練,且本身具有多頭注意力機制,因此能夠很好地增強文本的情感語義特征表示,其計算方式如下所示:
2.2 雙通道層
在模型的特征提取部分,分別使用TCN網絡和Att-BiGRU網絡進行數據特征的訓練提取。由于兩種網絡模型在文本特征的處理上有著各自不同的優勢,利用雙通道模型進行文本信息提取,再對兩者進行特征融合,從而獲取到更豐富的情感特征信息。
1) TCN網絡
TCN網絡所具有的因果卷積和膨脹卷積,能夠很好地對時序數據進行處理。因果卷積具有嚴謹的因果性,它只能利用當前時刻之前的時間步信息來進行預測,而不能利用之后的時間步信息進行預測,因此,可以有效避免未來因素所造成的影響。將預訓練后得到的特征輸入TCN網絡中,從右至左進行計算來提取特征,其公式如式(13)所示:
3 實驗與分析
3.1 實驗環境及參數設置
實驗所使用的操作系統為Windows10,內存為32GB,CPU 為英特爾的E5-2678v3,GPU 為NVIDIARTX3080。模型所用的深度學習框架為PyTorch,在Pycharm上使用Python3.8完成編程和訓練。
實驗參數:ERNIE預訓練模型保持原有的默認參數不變;TCN網絡的卷積層數為4,卷積核大小為3,膨脹因子為2,詞向量維度為768。另外,學習率為1e-5,損失率為0.25,BiGRU的隱藏層為256,使用ReLU 作為激活函數,Adabelief 算法作為模型訓練時的優化器。
3.2 數據集及評價指標
1) 實驗數據集
本模型訓練所用的數據集為中文情感分析語料庫提供的新浪微博評論數據集和平板商品評論數據集,所有數據均按積極和消極兩類情感進行了標注,并按照8:2劃分訓練集和測試集。數據集條目統計及示例如表1、表2所示。
其中,TP 表示將正樣本預測為正樣本的數量;FP表示將負樣本預測為正樣本的數量;FN 表示將正樣本預測為負樣本的數量。
3.3 結果分析與對比
1) 評價指標對比
為證明該雙通道模型在情感分類任務中的有效性,該實驗從精確率、召回率和F1值方面,對該模型進行消融實驗對比分析。實驗結果如圖4、圖5所示:
通過圖4、圖5可知,在新浪微博評論數據集上,TCN+Att-BiGRU 模型相比單一的TCN 和Att-BiGRU 模型,F1值分別提升了2.05%和1.98%,在平板商品評論數據集上,則提升了2.4%和2.3%,這是由于雙通道模型對各自提取的特征進行融合后,所提取的情感特征更加豐富;在新浪微博評論數據集上,RENIETCN+Att-BiGRU 模型相比于TCN+Att-BiGRU 模型,F1值提升了3.24%,在平板商品評論數據集上,則提升了3.51%,這說明使用ERNIE模型進行預訓練后,使得詞向量的情感特征表示更加充分,模型性能有了很大提升;本文模型相比于RENIE-TCN+Att-BiGRU 模型,在兩個數據集上,其F1值則分別提升了0.32% 和0.26%,這主要是由于該模型在訓練過程中引入了Adabelief算法,在加速收斂的同時,也使模型的訓練更加穩定,因此其性能指標也有所上升。
2) 優化算法收斂性對比
為證明基于Adabelief算法的雙通道模型在情感分類任務中的有效性,分別將Adam算法和Adabelief 算法的損失率情況進行了對比。對比結果如圖6、圖7 所示:
由圖6和圖7可以看出,在新浪微博評論數據集上,基于Adabelief算法的雙通道模型在訓練之初,其收斂速度就要明顯優于Adam算法,雖然在訓練到2000步時發生了波動,但在3 000步左右時又很快恢復了正常收斂,并保持穩定狀態,損失率最終收斂到0.22。在平板商品評論數據集上,基于Adabelief算法的雙通道模型仍然在訓練開始時,其收斂速度仍然優于Adam算法,雖然在訓練到1 000步左右時發生了波動,但在3 000步之后又開始正常收斂,并逐漸超越Adam算法,最終損失率保持到0.18。整體可知,基于Adabelief算法的雙通道模型在情感分類任務上,其收斂速度更快,具有較強的泛化性,整體表現性能要優于Adam算法。
4 結束語
針對中文文本情感分類任務,本文提出了一種基于預訓練模型的雙通道情感分類方法。通過將處理后的文本數據輸入ERNIE 模型中進行預訓練,然后將預訓練后的特征向量分別輸入TCN 網絡和Att-BiGRU網絡中進行特征提取,最后將雙通道模型獲取的特征進行融合拼接后經由Softmax計算輸出。同時在訓練過程中,使用Adabelief算法進行模型優化。經實驗證明,該模型在新浪微博評論數據集和平板商品評論數據集上各方面表現性能均優于對比模型。下一步,將對更加復雜的多模態情感分類任務展開研究,進一步提升情感分類應用范圍。
