基于關聯規則的數字圖書館書目查詢系統設計
2023-08-27 09:02:38周香
電子設計工程 2023年17期
周香
(陜西電子信息職業技術學院,陜西西安 710500)
數字圖書館是一種新型的圖書管理模式,滿足了網絡化的需求。數字化、多媒體信息資源是數字圖書館服務的基礎與先決條件,也是數字圖書館建設的核心。作為信息資源的持有者和提供者,如何充分利用互聯網,構建大規模的數字資源庫,并通過互聯網進行網上查詢,是當前各大圖書館面臨的一個重要難題。圖書館是使用者能夠獲取最豐富的文獻資料的主要來源,過去的文獻資料則把圖書館與網絡之間的聯系分割開來。另外,不同的數字圖書館系統開發語言、開發平臺和通信協議也各不相同,在不同的數字圖書館體系中,信息資源的共享存在著很大的困難。文獻[1]提出的基于Solr 的標準查詢技術,通過Solr 查詢引擎對標準書目進行拆分,并對查詢結果排序,使其應用到數字圖書館書目查詢工程實踐中;文獻[2]提出的基于人工智能技術的查詢方案,通過對數據標準化處理,實現對數字圖書館書目的挖掘,結合人工智能技術實現數字圖書館書目查詢。然而,這兩種方法受到大量數字圖書館書目信息影響,導致查詢效果不佳,為此,設計了基于關聯規則的數字圖書館書目查詢系統。
1 系統硬件結構設計
設計的基于關聯規則的數字圖書館書目查詢系統,硬件結構如圖1 所示。
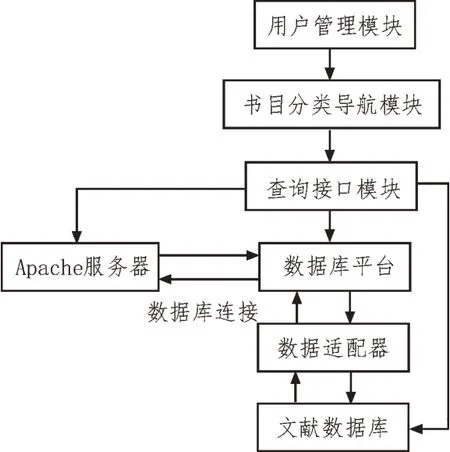
圖1 系統硬件結構
1.1 書目分類導航模塊
為了確保該書目分類導航模塊基本功能,用戶可以通過查詢式目錄的查詢界面選取目錄號,并按照目錄進行查詢。讀者在進入分類導航界面后,開始查詢書目,并向目錄數據庫發送查詢請求[4]。
1.2 查詢接口模塊
使用的數字圖書館數目查詢接口,如圖2 所示。
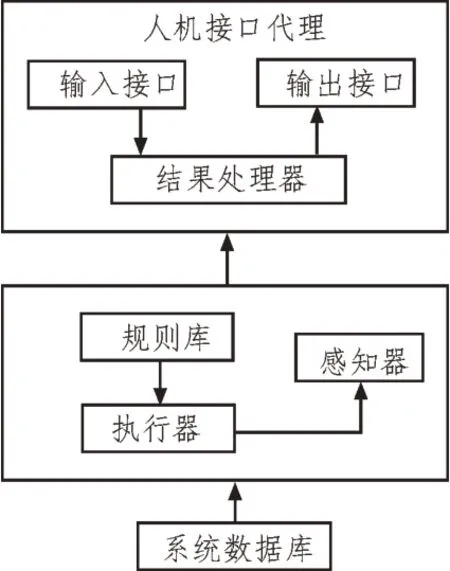
圖2 查詢接口
數字圖書館數目查詢接口具有模糊查詢功能,能夠校驗前后查詢語句一致性和完整性。通過定位檢索方式,構建索引標識,能夠提高檢索響應速度[5]。通常查詢接口主要有兩種,分別是人機代理接口和監控代理接口。
1.2.1 人機代理接口
人機代理接口包括輸入接口、輸出接口和輸出處理模塊,其工作方式如下:輸入接口接收讀者的輸入信息,并對其進行檢驗,如果不滿足接收條件,則提示讀者修改輸入信息;如果滿足,則向結果處理器發送查詢詞[6-7]。結果處理器接收到查詢詞后,根據索引地址集獲取查詢詞的相關屬性信息,之后在MIS 系統中提取相關屬性信息,并將提取結果發送給輸出接口,輸出接口負責顯示和打印[8]。
1.2.2 監控代理接口
監控代理接口主要負責對查詢界面中的索引文件進行維護,該部分主要由感知器、知識庫、控制器和執行器組成。由于人機代理接口無法更改系統原始索引,所以只能通過監控索引結構進行更改[9]。如果出現變化,需要在書目中及時反映出來。監控代理工作方式如下:感應器是感應環境,并在第一時間作出指標[10]。在原始指標數據發生變化時,需要立即向控制器發送信號,依據控制器預先設置的關聯規則來更改原始指標數據[11]。將更改后的指標數據加入系統,該記錄就會被傳送到該索引中。此時,系統會自動創建一個新的索引,控制器也會立刻執行索引更新任務,待控制器獲取來自感知器的全部數據后,即可完成知識庫全部索引更新任務[12]。通過監控代理接口,能夠及時判斷索引結構,一旦發現結構變化,只需更新關聯規則,不用更改代理程序,就能快速完成索引的更新,該過程靈活、簡便,方便移植。
HPV感染與肺癌預后相關性的機制暫不明確。既往研究提示,HPV陽性肺癌組織中HPV E6、E7癌蛋白的過度表達會下調p53蛋白,導致HPV陽性肺癌患者預后更好[23]。也有研究提出,HPV感染相關惡性腫瘤的主要特征為p53退化和p16上調,導致野生型TP53[24]和p16[25]基因攜帶幾率增大,無病生存率提高。同時,遺傳學研究提示,相比未感染HPV的腫瘤細胞,HPV感染腫瘤細胞的染色體畸變率和染色體增倍體出現幾率明顯降低,對放療和化療的敏感性明顯升高,預后更好[26]。未來仍需進一步深入的基礎研究來闡述HPV感染與肺癌預后相關性的可能機制。
1.3 Apache服務器模塊
Apache 可以在任意一臺計算機操作系統上運行,其結構如圖3 所示。
圖3 Apache服務器模塊結構
由圖3 可知,該服務器主要用于監視系統運行情況。Apache 能夠在很大程度上靈活地記錄和監控服務器的運行狀態,并且能夠滿足用戶的需要[13]。同時,它還配備了一個虛擬主機,主要功能是通過一個服務器實現多個主機之間的互聯,為整個系統提供HTTP 服務[14]。Apache 模塊可以在運行時進行動態加載,從而減少了內存負載。
2 系統軟件部分設計
2.1 基于關聯規則的查詢索引構建
書目推薦算法一般都是以項集合來表達,這些項集合彼此獨立,沒有重復屬性。對于關聯規則,需要計算書目特征集的支持度,對于項集D的支持度,其計算公式為:
式中,Q表示全部數據集。如果項集D是一種頻繁項集,那么該項集支持度大于等于頻繁項集中的任意最小頻繁項集。集合間的個性化規則必須符合以下條件:各項集合是有效的,且各項集合之間的個性化應具有某種普遍性[15]。以此為依據,構建的基于關聯規則的查詢索引模型,如圖4 所示。
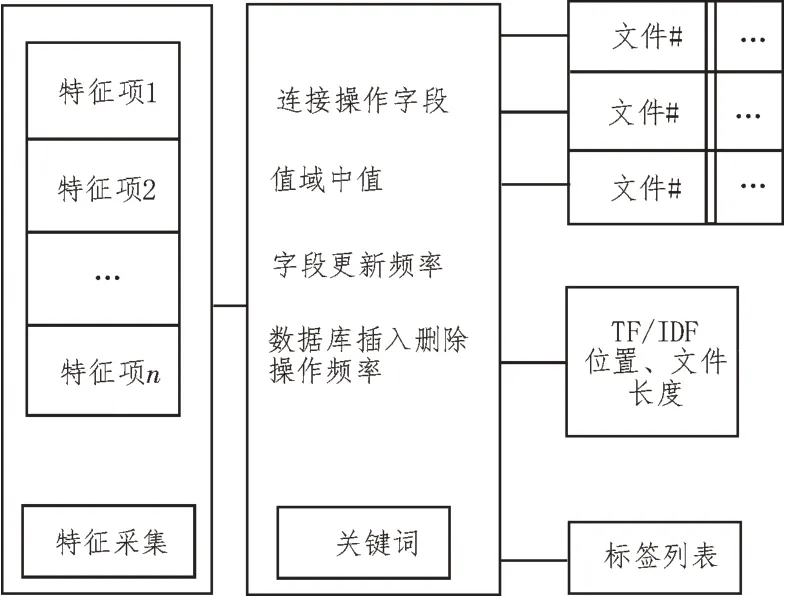
圖4 基于關聯規則的查詢索引模型
由圖4 可知,在確定特征采集結果和關鍵詞后,在字段上建立索引,由此完成索引的構建。在查詢系統中,構建查詢索引模型詳細步驟如下:首先,讀者提出查詢需求的條件,然后,系統按照查詢需求來檢索與查詢相關的文件,同時系統根據查詢條件與書目數據之間的關聯性按照相似度大小依次排序,最后,將排序后的結果反饋給讀者[16]。
2.2 數字圖書館書目查詢步驟設計
根據構建的查詢索引模型搜索頻繁項集,待搜索完成后會產生強大的關聯規則。在該規則中,設1為非空子集,0 為空子集,如果項集合的每一個頻繁項集為1,說明該項集為非空子集,可以將此集合作為書目查詢集合,反之,則不能。
針對數字圖書館查詢書目存在特征集合xm,對這些特征進行矢量化處理,得到的特征均與書目單詞相呼應。
設需要查詢的書目庫為W,可表示為:
式中,gn表示第n個書目;N表示書目總量。在需要查詢的書目庫中,將全部特征映射成一組節點數據,使其成為一條量化路徑。
在該條量化路徑上,使用一種能控制字段存儲的估計參數,可表示為:
式中,l(μ)表示估計參數相對于特征集合xm的似然函數。通過對似然函數進行數據轉化處理,能夠得到書目查詢模型,如下所示:
式中,Uμ表示數字圖書館書目全部查詢結果。該公式計算結果越高,書目查詢結果就越精準,由此完成數字圖書館書目查詢。
3 系統測試
3.1 數據源選取
系統測試選取的圖書館歷史記錄數據作為圖書館查詢系統的研究對象,登錄某校圖書館自動化管理系統模塊,統計2018 年1 月—2022 年1 月的讀者查詢歷史記錄。
3.2 系統生成的關聯規則
從基于關聯規則的數字圖書館書目查詢系統生成的頻繁數據庫中產生具有強關聯的規則,如果這些規則的支持度和置信度大于設定的閾值0.4 和0.7,則說明該系統查詢結構與讀者查詢結果關聯性較大。
使用該平臺生成的15 條歷史記錄關聯規則,如表1 所示。
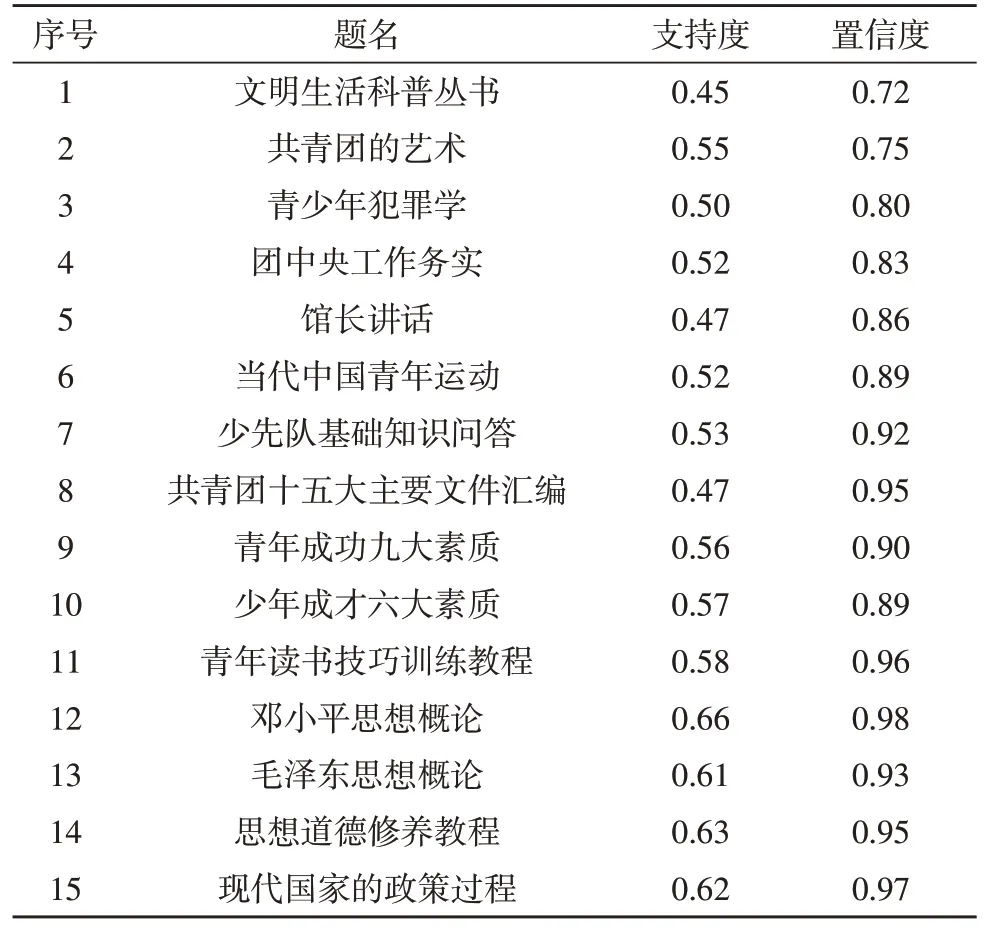
表1 生成的關聯規則
由表1 可知,讀者在查詢圖書時表現出較強的個性化,因此,系統生成的關聯規則支持度和置信度較高。根據系統測試結果可以看出,《鄧小平思想概論》、《思想道德修養教程》、《現代國家的政策過程》關聯規則較高,說明被查詢的次數也較多。
3.3 測試結果與分析
為了進一步驗證基于關聯規則的數字圖書館書目查詢系統設計合理性,需將其與基于Solr 的標準查詢技術、基于人工智能技術的查詢方案的查詢結果進行對比分析。以查全率和查準率為指標,三種方法的查詢效果對比結果如圖5 所示。
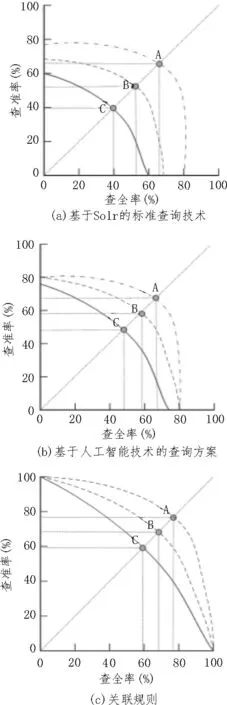
圖5 三種方法查詢效果對比分析
由圖5 可知,A、B、C 三個點分別代表《鄧小平思想概論》、《思想道德修養教程》、《現代國家的政策過程》書目,這三個點也為三種方法的平衡點,曲線A 完全包住曲線B,曲線B 完全包住曲線C,其中A 點為查詢效果最佳點,C 點查詢效果最差點。通過對比結果可知,使用基于Solr 的標準查詢技術,C點查全率和查準率均為40%,A 點查全率和查準率均為67%;使用基于人工智能技術的查詢方案,C 點查全率和查準率均為49%,A 點查全率和查準率均為68%;使用基于關聯規則的數字圖書館書目查詢系統,C 點查全率和查準率均為60%,A 點查全率和查準率均為78%。
通過上述分析結果可知,使用基于關聯規則的數字圖書館書目查詢系統查全率和查準率均最高,說明使用該系統具有高效查詢效率。
4 結束語
文中設計了基于關聯規則的數字圖書館書目查詢系統,對查詢數據進行了關聯分析,確定圖書館書目之間存在的關聯信息,并形成了強大的關聯規則,為讀者提供了一種主動的、個性化的查詢服務,通過對查詢方式分析向讀者提供有關書籍的建議。
目前,數據查詢技術在圖書館的應用尚處于起步階段,對個性化查詢服務的發展起到積極的推動作用。針對關聯規則數字圖書館書目查詢問題,提出了如下期望:下一步需要設置一個頻率門限,來決定頻繁書目集合,從而迅速找到讀者所關心的書目。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
Coco薇(2017年11期)2018-01-03 20:59:57
讀者(2017年5期)2017-02-15 18:04:18
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
