人工智能的自動語言處理系統在社交網絡分析中的應用研究
2023-08-31 18:40:24陸苗
互聯網周刊 2023年15期
關鍵詞:人工智能


摘要:在信息技術不斷創新的今天,互聯網已成為人們日常生活與工作生產的必備要素,尤其是在社交網絡快速發展的背景下,社交網絡越來越廣,為人們言語交流提供了良好的網絡平臺,為言語交際提供了更多的便利。就社交網絡分析來看,為準確提取社交網絡中的語言,解決中文字詞不準確及數據非結構化等問題,本文研究以人工智能技術應用為背景,分析自動語言處理系統在社交網絡分析中的應用,為社交網絡中字詞校對、語法查錯、語義校對及文本校對提供依據,以此來豐富有關社交網絡語言處理的研究理論。
關鍵詞:人工智能;自動語言處理系統;社交網絡分析
引言
社交網絡中匯聚了各種各樣的語言信息,代表了不同人群的思想觀點,這些語言具備一定的傳播性與影響性,尤其是不利社會和諧發展的負面語言,或有傷害性的網絡暴力語言,會對網絡輿論環境造成影響。對此,為維護和諧、穩定的網絡環境,構建健康的社交網絡語言秩序,為社交網絡健康發展提供保障,在社交網絡語言處理中,提倡運用人工智能的自動語言處理系統,依靠科學技術處理的方式來對不符合社交網絡發展的負面語言進行校對。本研究結合國內外文獻資料,基于前人提出的研究成果,借鑒過往研究提出的思路來分析自動語言處理系統在社交網絡分析中的應用,探究自動語言處理系統應用的價值與意義,從而為社交網絡長效發展提供依據。
1. 自動語言處理系統在社交網絡分析中的字詞校對
1.1 構建語料庫
為實現對社交網絡語言字詞的準確校對,自動語言處理系統可通過對社交網絡中已發布的文章、文案等進行字詞核查,對相鄰字、相鄰詞及字詞進行校對,自動檢測當中錯誤的字詞。研究以微博平臺2022年某營銷號發布的文章為例,字數共有326萬字,運用自動語言處理系統構建容量為20.5MB的語料庫。依托人工智能、大數據、云計算等先進技術分類整合相關數據,利用人工智能的特性,根據人們文章寫作的用詞習慣對語料庫內容進行更新,為社交網絡中字詞校對提供保障。
1.2 查錯接續關系
在語言處理中,字詞存在二元接續關系,要想有效過濾社交網絡中不合規的語言,在字詞校對上還需結合字詞間的接續關系進行查錯處理,重點對字串相鄰的字詞關系進行校對。比如字串為S1S2…Si-1SiSi+1…Sn,自動語言處理系統在判斷S和鄰近字詞關系時,可結合語言學二元模型理論,對Si-1與Si的關系、Si和Si+1的關系進行查錯處理。基于前文構建的語料庫,提出Si-1至Si轉移率為P(Si/Si-1)的假設,若P達到一定閾值,可確定Si與Si-1為二元接續關系。自動語言處理系統的應用可準確認定Si是否出錯,首先要確定Si-1和Si的接續關系,若為接續,則確定Si無錯誤,查錯結果符合相關標準;若為不接續,就要還確定Si和Si+1的接續關系,若結果仍為不接續,就可確定為Si錯誤。
2. 自動語言處理系統在社交網絡分析中的查錯算法
基于社交網絡語言快速傳播的特點,媒體營銷號在微博平臺上發表的文章會快速發酵,且傳播范圍極廣,若存在語法錯誤,就會產生負面輿論,從而影響營銷號的運營。對此,應用自動語言處理系統的查錯算法能夠對社交網絡中的語言語法進行分析與處理。以社交網絡語言的規則庫為基準,對語言的結構進行識別,明確劃分語言的主謂賓結構,并以由下到上的處理方式來分別對語句結構進行校對,檢測是否存在語法錯誤的問題[1]。從自動語言處理系統語法查錯的過程來看,要先對句子進行預處理,使短句串聯與捆綁,為語句的精準處理提供依據,確保查錯算法在識別語法錯誤問題上,結果更加準確。比如對謂語語法的校對,查錯算法的運用如下:
input語句:P=Q1…Qi…Qn
For i=1 to n do
if(詞Qi不在語片中)
{結合規則庫確定Qi能否充當謂語;}
if(Qi可充當謂語)
{添加謂語鏈Prdelink;
for (w=Predlink->firstword to Predlink->lasword)
if(Predlink->num=1)代表P謂語成分正確;
if(Predlink->num=0)代表P謂語缺失;}
3. 自動語言處理系統在社交網絡分析中的語義校對
3.1 構建依存關系
在社交網絡分析中的語義校對中,自動語言處理系統的應用能夠以實例語義查錯為基礎,研判語句語義是否正確,分析語句結構,并通過采集網絡系統中相關語句案例,通過建立集合n,對集合n中所有的語句實例和未校對語句相似度進行計算,從中選取相似度較高的實例i。比較i和未校對的語句,從中獲取語義校對的查錯結果。從校對操作來看,自動語言處理系統整個運作的過程雖簡便,但考慮到集合n中存有較多實例,在計算語義相似度方面,需要處理的語句較多,會使工作量增加,延長了語義相似度計算的時間。對此,為充分發揮自動語言處理系統在社交網絡語義校對中準確判斷的效能,通過構建依存關系,能夠以語義依存語法的形式來對字詞句進行準確判斷,依托字詞句之間良好的依存關系來確定語句的語義特征,為語句相似度計算的準確性提供保障[2]。
3.2 語句相似度計算
為實現精準高效的語義查錯,自動語言處理系統在語義校對中,要通過對語句相似度的計算來確保語義準確無誤[3]。在語句相似度的計算中,要從字詞句有效搭配相似度的角度進行考慮,須抓住每一個語句的核心詞和語句中依存的有效字詞。從語句結構來看,有效詞可看作形容詞、名詞及動詞等類型,此類詞組能夠準確表達出一段語句的語義,對這些詞組的相似度進行計算是社交網絡語言中語義查誤的重點[4]。例句:事發后,傷員被及時送往就近醫院救治。這句話中的關鍵詞為“送往”,其搭配的字詞可表現為送往-傷員、送往-醫院及送往-救治等,通過對關鍵詞和有效詞相似程度的計算,不僅簡化了傳統語句相似度計算繁雜的工作量,在省略多個計算過程后,還能保障語句相似度計算結果的準確性,這便是語義校對中應用自動語言處理系統的價值與意義。文中公式(1)為語句相似度計算公式:
(1)
基于上述式子來看,SIM(Sen1, Sen2)是語句相似度,代表了語句字詞有效搭配對匹配的總權重,PairCount1與PairCount2則為語句有效搭配數,不同情況下的權重設計見表1。
Word1為語句1,Word1為語句1的相似語句;Word2為語句2,Word2為語句2的相似語句。在多種例句相似度計算情況下,對比未校對語句和相似度最高語句,由此來對語句語義正誤進行判斷,完成語義校對。
4. 自動語言處理系統在社交網絡分析中的文本校對
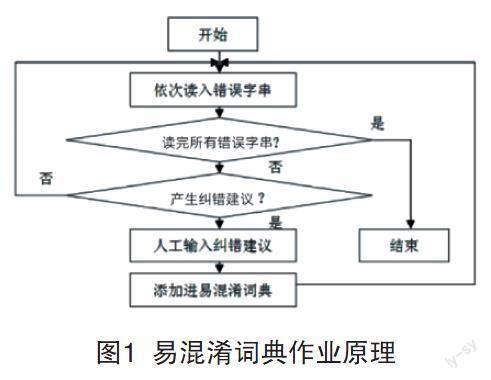
4.1 構建易混淆詞典
文本的校對和字詞、語法、語義的校對有較大差異。應用自動語言處理系統對社交網絡文本校對,分別有糾錯與查錯兩種校對方式,前者是通過檢測出文本的錯誤,根據錯誤的內容提出對應措施進行糾正,基于中文文本的常見錯誤,自動提取錯誤特征,收集相關詞典內容,從而為系統自動識別錯誤用詞提供參考;后者則為文本錯誤內容的提取,通過指明文本的錯誤點和特征,以供文本錯誤內容的修改進行參考[5]。易混淆詞典的構建要依托糾錯的校對方式,混淆詞典的內容包含了文本錯誤字詞與糾錯建議,圖1為混淆詞典作業原理。
4.2 糾錯算法編程
為凸顯自動語言處理系統智能化、自動化高效運作與處理的效能,在校對社交網絡語言文本上,一般都以糾錯的校對方式為主[6]。通過對文本字詞錯誤的判斷,能夠根據不同的錯誤特征提出針對性糾錯建議,但針對文本校對中,未發現文本錯誤的情況,就無法給出客觀合理的糾錯建議。所以,在自動語言處理系統的應用中,還需進行糾錯算法編程處理,比如力矩我們認為可以延長時間[7]。將“可疑延長”作為系統文本校對中判斷出的字詞錯誤,設計糾錯算法的編程如下:
string[ ]zc correct;//定義數組用作糾錯建議緩沖區
inti=0;//糾錯計數器為0
//x系統檢測的錯誤字串
//易混淆詞典中提出糾錯建議
for(intm=0;m<=errmatchco rrect.leng th;m++)
//易混淆詞典中未找到糾錯建議
if(i==0){
for(m=0;m<=zctx.length;m++)
if(e.gerErrword()==zctxcorrect[m].getErrword())
//字詞同現概率表
Zccorrect[i]=zctxcorrect[m].getCorrect();}
5. 自動語言處理系統的搭建與實驗
5.1 文本自動校對的流程
為實現對社交網絡語言文本的準確校對,選用的自動語言處理系統,要具備查錯、預處理及校對糾錯等模塊功能,系統功能實現流程如下:(1)輸入與打開文本,以正向的順序讀入單句,預處理文本結構和內容,并通過雙向模式匹配處理,根據事先構建的詞庫,對文本結構進行識別,明確字詞句的詞性;(2)構造字頻向量與二元詞性同現頻率表,創建完善的文本查錯知識庫。基于系統查錯、糾錯的模塊,對文本字詞進行識別與查誤,判斷文本字詞是否存在連接方式與連接順序的錯誤,并判斷語句結構是否完整,語法和語義的表達是否正確;(3)利用易混淆詞典,準確定位自動語言處理系統查詢中得出的錯誤內容,提出相應的糾錯建議,進行糾錯處理;(4)在完成糾錯處理后,要執行判斷程序文本處理是否結束。當完成處理后,則流程解鎖;若未完成處理,系統將自動跳轉至步驟(1),反復處理指導文本處理無誤,完成整個文本自動校對的程序。
5.2 實驗內容
選取微博平臺某營銷號發布的136篇文章進行實驗分析,從中挑選出230個正確句子與200個錯誤句子,其中60個有字詞級錯誤,100個有語法級錯誤,40個有語義級錯誤。病句舉例如下:
(1)他是本地一家知名企業的總載。(“載”應為“裁”,屬于字詞級錯誤);(2)本縣蘋果的品種非常多,這里無法一一例舉。(“例舉”應為“列舉”,屬于語義級錯誤);(3)巴西總理授予法院獲得簽發“禁止未成年人進入酒吧證”的權力。(應刪除“獲得”,屬于語法級錯誤)。
實驗引入以下參數:(1)召回率=正確發現句子數/實際錯誤句子數×100%;(2)誤報率=(發現錯誤句子數-正確發現句子數)/發現錯誤句子數×100%;(3)準確率=1-誤報率。
實驗結果見表2。
利用自動語言處理系統校對社交網絡語言的文本,發現召回率與準確率較高,基本在60%以上,在語法錯誤句子的判斷中,召回率與準確率較理想,分別為81%和84.4%。
結語
基于上述研究分析可以看出,社交網絡在蓬勃發展的背景下,網絡體系中傳播的語音信息還需從語言結構、字詞準確性、語法正誤、語義正誤及文本正誤等方面進行充分考慮。為利用社交網絡來傳播符合社會主義核心價值觀的語言信息,應用人工智能的自動語言處理系統,能夠以科學化處理的方式準確判斷社交網絡中各類賬戶在文章發表中語言的準確性,有效過濾一些不符合社交網絡語言規則庫的違規語言,及時糾正在字詞、語法、語義等方面的錯誤,以完善的語料庫來優化語言規律,為語言自動處理系統在社交網絡中的應用與推廣提供依據。同時,社交網絡還能依托自動語言處理系統,減少網絡暴力語言的產生,維護和諧、穩定的網絡語言秩序,構建良好的網絡語言環境,從而為社交網絡的健康發展提供保障。
參考文獻:
[1]張洪忠,王競一.社交機器人參與社交網絡輿論建構的策略分析——基于機器行為學的研究視角[J].新聞與寫作,2023, (2):35-42.
[2]薛飛.人工智能在計算機網絡技術中的應用研究[J].現代雷達,2022,44 (12):125-127.
[3]古天龍,郝峰銳,李龍,等.社交網絡中負責隱私協商的智能體行為追責[J].軟件學報,2022,33(9):3453-3469.
[4]李小偉,舒輝,光焱,等.自然語言處理在簡歷分析中的應用研究綜述[J].計算機科學,2022,49(S1):66-73.
[5]Girish K,Pushpavathi M,Abraham A,et al.Automatic speech processing softwareNew sensitive tool for the assessment of nasality:A preliminary study[J].Journal of Cleft Lip Palate and Craniofacial Anomalies,2022,9(1):62-88.
[6]郭九霞.基于自然語言處理的空管系統危險源文本分類方法研究[J].安全與環境學報,2022,22(2):819-825.
[7]張志勇,荊軍昌,李斐,等.人工智能視角下的在線社交網絡虛假信息檢測、傳播與控制研究綜述[J].計算機學報,2021,44(11):2261-2282.
作者簡介:陸苗,博士研究生,講師,研究方向:人工智能。
猜你喜歡
西安航空學院學報(2022年2期)2022-07-04 07:45:42
汽車零部件(2020年3期)2020-03-27 05:30:20
表面工程與再制造(2019年1期)2019-05-11 08:52:04
商界(2019年12期)2019-01-03 06:59:05
家庭影院技術(2018年9期)2018-11-02 05:31:34
IT經理世界(2018年20期)2018-10-24 02:38:24
通信電源技術(2018年3期)2018-06-26 06:33:30
軍營文化天地(2018年1期)2018-02-10 05:19:25
小康(2017年16期)2017-06-07 09:00:59
學與玩(2017年12期)2017-02-16 06:51:12
