基于大數(shù)據(jù)挖掘的移動通信網(wǎng)絡(luò)故障診斷方法研究
2023-09-02 07:07:26李小聰
通信電源技術(shù) 2023年14期
李小聰
(中國電信股份有限公司北京分公司,北京 100032)
0 引 言
目前,隨著用戶的需求越來越多樣化,如何保證網(wǎng)絡(luò)正常運轉(zhuǎn)成為了一個重大的難題。網(wǎng)絡(luò)故障診斷技術(shù)是一種能夠?qū)崟r監(jiān)控網(wǎng)絡(luò)和其相關(guān)節(jié)點的改變情況,觀測鏈路之間是否正常運行,若發(fā)現(xiàn)問題則第一時間反饋給管理系統(tǒng)的技術(shù)[1-4]。該技術(shù)主要是保障網(wǎng)絡(luò)服務(wù)的質(zhì)量,及時提供故障預(yù)警信息。隨著人工智能技術(shù)的興起,研究者逐漸在網(wǎng)絡(luò)故障診斷領(lǐng)域引入人工智能技術(shù)[5-9]。與傳統(tǒng)的人工診斷方法相比,基于人工智能的網(wǎng)絡(luò)故障診斷可以進一步提升故障診斷效率。
1 基于生成對抗網(wǎng)絡(luò)的網(wǎng)絡(luò)故障診斷方法
1.1 系統(tǒng)模型
以毫微微小區(qū)、微小區(qū)與宏小區(qū)覆蓋的4G 網(wǎng)絡(luò)場景為研究目標,其異構(gòu)無線網(wǎng)絡(luò)場景如圖1 所示。該研究目標具有復雜的系統(tǒng)結(jié)構(gòu),因此難以有效管理網(wǎng)絡(luò)。針對該研究目標探討如何診斷網(wǎng)絡(luò)故障,首先分析和關(guān)聯(lián)衡量網(wǎng)絡(luò)性能的關(guān)鍵性能指標(Key Performance Indicator,KPI)與常見的網(wǎng)絡(luò)故障,這也是構(gòu)建模型的必要前提工作。
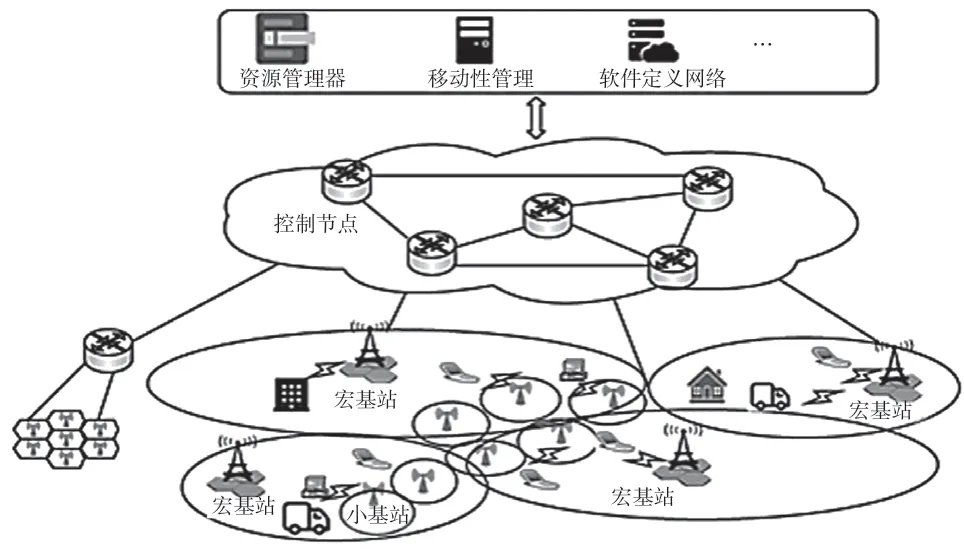
圖1 異構(gòu)無線網(wǎng)絡(luò)場景
1.2 生成對抗網(wǎng)絡(luò)概述
生成對抗網(wǎng)絡(luò)(Generative Adversarial Network,GAN)從提出至今受到了領(lǐng)域內(nèi)許多研究者的歡迎。GAN 分別包括生成模型和判別模型2 種模型,即模型G和模型D。模型G和模型D之間會不停對弈,在對弈中模型各自的性能也會隨之提高。基于模型D,模型G可以在無大量先驗知識的情況下產(chǎn)生相近的數(shù)據(jù)。多層感知器定義的優(yōu)化目標函數(shù)公式為
式中:E為數(shù)學期望;D(x)為真實輸入x經(jīng)過模型D的輸出值;G(Z)為噪聲輸入Z經(jīng)過模型G的輸出值;pdata為輸入x的分布;pz為輸入Z的分布。
更新模型D參數(shù)時,希望D(x)的輸出結(jié)果最優(yōu)可以在1 附近或者等于1,即最大化logD(x)。對于基于噪聲產(chǎn)生的數(shù)據(jù)G(Z)而言,希望D[G(Z)]的輸出可以是0,即當模型D產(chǎn)生的數(shù)據(jù)足夠逼真時,仍可以篩選出D[G(Z)]輸出數(shù)據(jù)中的假數(shù)據(jù),因此需要最大化log{1-D[G(Z)]},從而要求判別器輸出結(jié)果最大化。
更新模型G的參數(shù)時,盡量保持pz=pdata,因此log{1-D[G(Z)]}的值越小越好,即最小化生成器的輸出。
博弈過程中,基于真實數(shù)據(jù),可以取樣出x并將其作為模型D的輸入數(shù)值。輸入該數(shù)值后,模型D可以基于自身的邏輯框架生成一個在[0,1]內(nèi)的數(shù)值,該數(shù)值越接近1 越好,從而可以判斷模型D的輸入數(shù)據(jù)是真實數(shù)據(jù)。之后,模型D和模型G會進行不停的訓練。模型G的輸入信號為服從特定分布規(guī)律的噪聲,其可以基于真實數(shù)據(jù)進行學習直到可以產(chǎn)生相似的數(shù)據(jù),然后將該數(shù)據(jù)輸入模型D,模型D可以基于自身的邏輯判斷框架生成一個[0,1]范圍內(nèi)的數(shù)值,且輸出值越接近0 越好,表示模型可以判斷數(shù)據(jù)為假數(shù)據(jù)。
1.3 基于生成對抗網(wǎng)絡(luò)的網(wǎng)絡(luò)故障診斷流程
基于GAN 的網(wǎng)絡(luò)故障診斷模型如圖2 所示。首先,基于異構(gòu)無線網(wǎng)絡(luò)收集和關(guān)聯(lián)不同網(wǎng)絡(luò)情況下的KPI 數(shù)據(jù),收集來的數(shù)據(jù)需要先通過歸一化處理,然后基于GAN 進行數(shù)據(jù)擬合,得到附有標記的模擬數(shù)據(jù)(不同網(wǎng)絡(luò)狀態(tài)下)。其次,分別處理由原始網(wǎng)絡(luò)和GAN 模擬制造的2 種數(shù)據(jù)集,同時利用極限梯度提升算法(Extreme Gradient Boosting,XGBoost)降維數(shù)據(jù),篩除冗余的數(shù)據(jù),在診斷故障時選擇輸入?yún)?shù)的最優(yōu)特征組合。最后,基于XGBoost 算法的訓練可以得到最優(yōu)模型。
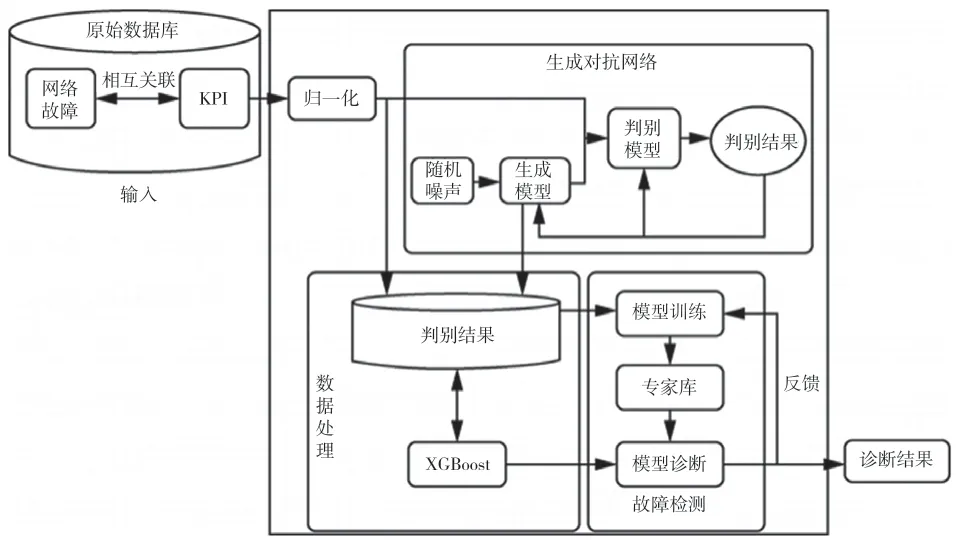
圖2 基于GAN 的網(wǎng)絡(luò)故障診斷模型
1.4 數(shù)據(jù)處理
網(wǎng)絡(luò)故障診斷模型必須具備可以識別多個故障的能力,因此需要確定不同網(wǎng)絡(luò)狀態(tài)對應(yīng)的癥狀。將具有m個KPI 的輸入向量(不同網(wǎng)絡(luò)狀態(tài)下)定義為S,S=[KPI1,KPI2,KPI3,…,KPIm];網(wǎng)絡(luò)的狀態(tài)定義為C=[FC1,FC2,FC3,…,FCn]。
被研究小區(qū)的KPI 可以組成小樣本數(shù)據(jù),作為異構(gòu)無線網(wǎng)絡(luò)的輸入數(shù)據(jù)。如果在某一區(qū)間時段內(nèi),有網(wǎng)絡(luò)故障FCi出現(xiàn),那么相應(yīng)的網(wǎng)絡(luò)狀態(tài)公式為
式中:KPImt表示第m個KPI處于t時刻的數(shù)值。
輸入數(shù)據(jù)時,歸一化特定的KPIi'以保證其具有相似的動態(tài)范圍。基于每個最大KPI 進行歸一化操作,其計算公式為
式中:KPIi'表示對第i個KPI進行歸一化處理后得到的數(shù)據(jù);max(KPIi')表示在已收集的數(shù)據(jù)中出現(xiàn)的最大的第i個KPI。式(3)表示排除[0,1]范圍內(nèi)的KPIi,對特定的KPIi范圍進行轉(zhuǎn)換。
網(wǎng)絡(luò)狀態(tài)經(jīng)過歸一化后變成
1.5 網(wǎng)絡(luò)故障診斷模型
GAN 框架如圖3 所示,需要具備2 個處于競爭狀態(tài)的網(wǎng)絡(luò)并同時優(yōu)化目標。
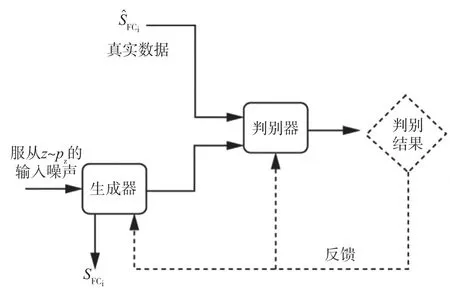
圖3 GAN 框架
第一個網(wǎng)絡(luò)是基于均勻噪聲或者給定高斯噪聲來輸出模擬輸入數(shù)據(jù)的生成器模型G;第二個網(wǎng)絡(luò)是判別模型D,其用0 或1 來標記判斷樣本,進而判斷輸入數(shù)據(jù)是生成的還是來自真實采集。經(jīng)過迭代,該競爭網(wǎng)絡(luò)模型可以更好地完成任務(wù)。生成模型G甚至可以產(chǎn)生出以假亂真的輸入數(shù)據(jù)。優(yōu)化的目標函數(shù)公式為
基于GAN 生成模型,僅僅需要一個噪聲(有一定規(guī)律)、2 個網(wǎng)絡(luò)(可逼近函數(shù))和一些數(shù)據(jù)(實際數(shù)據(jù)),不會存在特別困難的計算問題。2個模型(判別器和生成器)彼此間互相博弈,判別器穩(wěn)定時,可以由生成器獲取不同的網(wǎng)絡(luò)狀態(tài),輸入數(shù)據(jù)的分布也趨向于實際數(shù)據(jù)分布'FCi,其計算公式為
此外,本研究利用了帶梯度懲罰的Wasserstein GAN 算法(Wasserstein GAN with Gradient Penalty,WGANGP)[10]。
2 仿真結(jié)果
首先,進行仿真時,在數(shù)據(jù)處理階段采用WGAN-GP 算法學習小樣本數(shù)據(jù),該數(shù)據(jù)具有特定規(guī)律性;其次,得到附有標記的大量虛擬數(shù)據(jù),并基于得到的虛擬數(shù)據(jù)集與小樣本數(shù)據(jù),采用XGBoost 算法診斷網(wǎng)絡(luò)故障,網(wǎng)絡(luò)故障診斷正確率如圖4 所示。由圖4 可知,本研究提出的方法隨著迭代次數(shù)增加最終可以達到0.9848 的正確率,一定限度上提高了網(wǎng)絡(luò)故障診斷的正確率。
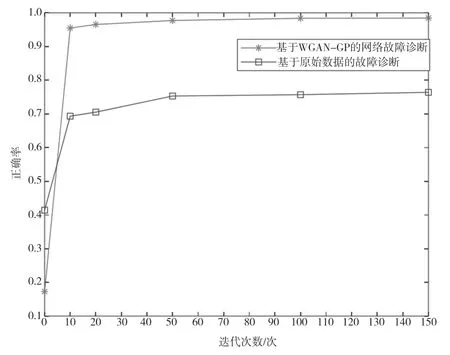
圖4 網(wǎng)絡(luò)故障診斷準確率
3 結(jié) 論
由于傳統(tǒng)方法難以解決基于異構(gòu)無線網(wǎng)絡(luò)狀態(tài)下大量獲得附帶標簽的歷史數(shù)據(jù)問題,受GAN 啟發(fā),提出一種新的異構(gòu)無線網(wǎng)絡(luò)故障診斷方法。首先基于WGAN-GP 算法,對從網(wǎng)絡(luò)環(huán)境中收集得到的小樣本進行學習,隨后得到大量帶標記的模擬數(shù)據(jù),利用XGBoost 算法對數(shù)據(jù)進行網(wǎng)絡(luò)故障診斷,最后進行仿真實驗,證明該方法可以顯著提高網(wǎng)絡(luò)故障診斷的準確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
裝備制造技術(shù)(2020年3期)2020-12-25 05:22:30
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
北京航空航天大學學報(2016年6期)2016-11-16 01:50:43
光學精密工程(2016年6期)2016-11-07 09:07:19
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
核科學與工程(2015年4期)2015-09-26 11:59:03
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
