威脅情報(bào)提取與知識圖譜構(gòu)建技術(shù)研究
2023-09-07 08:47:48史慧洋魏靖烜蔡興業(yè)高隨祥張玉清
西安電子科技大學(xué)學(xué)報(bào) 2023年4期
史慧洋,魏靖烜,蔡興業(yè),王 鶴,高隨祥,張玉清,,6
(1.中國科學(xué)院大學(xué) 計(jì)算機(jī)科學(xué)與技術(shù)學(xué)院,北京 101408;2.中國科學(xué)院大學(xué) 國家計(jì)算機(jī)網(wǎng)絡(luò)入侵防范中心,北京 101408;3.中國科學(xué)院大學(xué) 沈陽計(jì)算技術(shù)研究所,遼寧 沈陽 110168;4.西安電子科技大學(xué) 網(wǎng)絡(luò)與信息安全學(xué)院,陜西 西安 710071;5.中國科學(xué)院大學(xué) 數(shù)學(xué)科學(xué)學(xué)院,北京 101408;6.中關(guān)村實(shí)驗(yàn)室,北京 100094)
1 引 言
當(dāng)今網(wǎng)絡(luò)攻擊手段日趨成熟,兩方博弈中,如何快速利用威脅情報(bào)分析對手的攻擊行為,從而彌補(bǔ)自身的不足,由被動防御轉(zhuǎn)為主動進(jìn)攻。如何從海量的數(shù)據(jù)中快速提取有效的威脅情報(bào),如何對離散分布的各類威脅情報(bào)進(jìn)行有效收集并有效利用,如何將威脅情報(bào)融合分析發(fā)揮整體威力,已成為學(xué)術(shù)界關(guān)注的熱點(diǎn)。威脅情報(bào)經(jīng)過聚合和標(biāo)準(zhǔn)化、去重去偽,使用混合策略納什均衡來評估時間威脅等級,從而預(yù)測攻擊行為[1]。
威脅情報(bào)主要包括以下幾種標(biāo)準(zhǔn)格式:結(jié)構(gòu)化威脅信息表達(dá)(Structured Threat Information eXpression,STIX)、可信任的指標(biāo)信息自動變換(Trusted Automated eXchange of Indicator Information,TAXII)、網(wǎng)絡(luò)可觀察表達(dá)(Cyber Observable eXpression,CybOX)和惡意軟件屬性舉和描述(Malware Attribute Enumeration and Characterization,MAEC)。文中采用STIX標(biāo)準(zhǔn)格式,STIX 可以使用對象和描述性關(guān)系來表達(dá)可疑、攻陷和溯源的所有方面的內(nèi)容;通過關(guān)系連接多個對象可以簡化或復(fù)雜地表示網(wǎng)絡(luò)空間威脅情報(bào)。其優(yōu)勢在于類型豐富,適用于各類場景,能夠獲取更為廣泛的網(wǎng)絡(luò)威脅信息,且更加標(biāo)準(zhǔn)化和結(jié)構(gòu)化。
隨著人工智能以及自然語言處理(Natural Language Processing,NLP)技術(shù)的發(fā)展,出現(xiàn)大量信息抽取工具,如自然語言處理的Stanford NLP工具和NLTK(Natural Language ToolKit)工具包,還有THUTag清華關(guān)鍵詞抽取工具包等,在這些工具的基礎(chǔ)上,結(jié)合第三方詞庫進(jìn)行數(shù)據(jù)標(biāo)記,采用數(shù)據(jù)庫匹配、啟發(fā)式規(guī)則和安全詞集3種方式對文本數(shù)據(jù)進(jìn)行標(biāo)記,記錄BIO(Begin,Inside,Outside)標(biāo)簽[2]。因此,文中使用BIO標(biāo)簽作為特征提取方法,使用神經(jīng)網(wǎng)絡(luò)進(jìn)行非結(jié)構(gòu)化文本中安全信息的提取。
本體是同一領(lǐng)域中不同主體之間的交流和聯(lián)系的語義基礎(chǔ)[3]。文中參考威脅情報(bào)數(shù)據(jù)標(biāo)準(zhǔn)STIX格式提出本體構(gòu)建,并作為圖數(shù)據(jù)庫模式。本體構(gòu)建的過程是首先將實(shí)體和提取的關(guān)系構(gòu)建成知識網(wǎng)絡(luò),然后將數(shù)據(jù)轉(zhuǎn)換為知識,并將知識與應(yīng)用相結(jié)合。通過本體構(gòu)建可以促進(jìn)知識的融合,從而發(fā)揮數(shù)據(jù)的實(shí)用價(jià)值。
知識圖譜由谷歌提出,作為搜索引擎的輔助存儲知識庫。知識圖譜主要是以多種不同形式分發(fā)的信息通過關(guān)聯(lián)融合,形成了統(tǒng)一的高質(zhì)量知識。文獻(xiàn)[4]根據(jù)現(xiàn)有知識推理,挖掘潛在知識,同時,產(chǎn)生新知識。目前,在威脅情報(bào)領(lǐng)域中知識圖譜的研究和應(yīng)用還處于起步階段。
文中技術(shù)研究的貢獻(xiàn)如下:
(1) 提出了一種基于Bert+BiSLTM+CRF(Conditional Random Fields)的失陷指標(biāo)(Indicator Of Compromise,IOC) 識別抽取方法。通過對非結(jié)構(gòu)化文本信息的分析處理,并將其與正則匹配方法相結(jié)合,從中抽取出需要的IOC信息并進(jìn)行標(biāo)準(zhǔn)化輸出,得到STIX標(biāo)準(zhǔn)格式的數(shù)據(jù)。
(2) 構(gòu)建威脅情報(bào)的知識圖譜框架,包括情報(bào)搜集、信息抽取、本體構(gòu)建和知識推理4個過程。
(3) 基于STIX構(gòu)建威脅情報(bào)本體模型,以知識圖譜的形式表示重要指標(biāo)和威脅情報(bào)實(shí)體間的關(guān)系,設(shè)計(jì)出威脅情報(bào)檢索系統(tǒng)。結(jié)合ATT&CK描述攻擊行為,挖掘出威脅情報(bào)潛在關(guān)聯(lián)信息和攻擊主體。
2 相關(guān)工作
失陷指標(biāo)指在網(wǎng)絡(luò)或操作系統(tǒng)中觀察到的偽像,指示計(jì)算機(jī)入侵行為并在早期檢測到網(wǎng)絡(luò)攻擊,因此,它們在網(wǎng)絡(luò)安全領(lǐng)域中發(fā)揮著重要作用。但是IOC檢測系統(tǒng)嚴(yán)重依賴具有網(wǎng)絡(luò)安全知識的專家的判斷結(jié)果,因此研究需要大規(guī)模的手動注釋語料庫來訓(xùn)練IOC分類器。
何志鵬等[5]總結(jié)概述了國際上部分國家(組織)在網(wǎng)絡(luò)威脅情報(bào)領(lǐng)域開展的標(biāo)準(zhǔn)化工作。孫銘鴻等[6]介紹了情報(bào)、威脅溯源對國家層面的影響。在威脅情報(bào)識別抽取技術(shù)中,基于web爬蟲和郵件解析的技術(shù)具有構(gòu)造方便、模型簡單的優(yōu)點(diǎn),缺點(diǎn)在于精度很低,對于復(fù)雜的場景不能做出很好的處理。隨著人工智能和NLP 技術(shù)的發(fā)展,徐留杰等[7]提出了一種多源網(wǎng)絡(luò)安全威脅情報(bào)采集與封裝技術(shù),首先針對不同來源的威脅情報(bào)進(jìn)行搜集處理,最后生成JSON 格式的標(biāo)準(zhǔn)化情報(bào)庫。HUANG 等[8]提出了一種基于雙向長短期記憶的序列標(biāo)記模型用于命名實(shí)體識別(Named Entity Recognition,NER)任務(wù)。LONG等[9]提出了利用基于神經(jīng)的序列標(biāo)簽從網(wǎng)絡(luò)安全文章的非結(jié)構(gòu)化文本抽取IOC 模型。該模型引入了多頭注意力機(jī)制和上下文特征,顯著提高了IOC 識別的性能。LAMPLE等[10]提出了將LSTM 編碼器與word embedding和神經(jīng)序列標(biāo)記模型相結(jié)合的方法,在命名實(shí)體識別任務(wù)和詞性標(biāo)記任務(wù)上取得了顯著的效果。
LANDAUER等[11]從原始日志中提取網(wǎng)絡(luò)威脅情報(bào),所提方法還利用數(shù)據(jù)異常檢測來揭示可疑日志事件,這些事件用于迭代聚類、模式識別和優(yōu)化。KUROGOME等[12]提出了枚舉和優(yōu)化勒索軟件的枚舉和推斷家族典型示例(Enumerating and Inferring Genealogical Exemplars of Ransomware,EIGER) 的方法,通過惡意軟件的跟蹤自動提取生成可靠的IOC。該方法首先利用TextRank 生成文章的摘要,然后按文章的時間戳對摘要和實(shí)體進(jìn)行排序,生成安全事件鏈的網(wǎng)絡(luò)威脅情報(bào)(Cyber Threat Intelligence,CTI)。胡代旺等[13]使用輕量級預(yù)訓(xùn)框架ALBERT、圖卷積網(wǎng)絡(luò)和負(fù)樣本學(xué)習(xí)三元組損失,提出了一種新的實(shí)體關(guān)系抽取算法。郭淵博等[14]使用BiLSTM融合Focal loss和字符特征就行實(shí)體抽取,驗(yàn)證了其有效性。程順航等[15]融合自舉法與語義角色標(biāo)注,利用少量樣本構(gòu)建語義實(shí)體之間的關(guān)系。
通過相關(guān)研究分析,文中采用從安全文章中提取IOC的方式來獲得標(biāo)準(zhǔn)化威脅情報(bào)。雖然其獲取過程需要更多的工作,但其優(yōu)勢在于可自定義抓取所需時間段內(nèi)的文本數(shù)據(jù),因此時效性較高。此外,安全文章通常是經(jīng)過專業(yè)安全人員審核發(fā)表,IOC信息可對應(yīng)到文章所提到的具體事件,其可信度更高,具有更高的數(shù)據(jù)價(jià)值。在抽取技術(shù)方面,現(xiàn)有的研究工作表明,使用深度學(xué)習(xí)相關(guān)的技術(shù)會有更好的效果。因此,文中在模型的構(gòu)建上采用了NER命名實(shí)體識別技術(shù)。
關(guān)于威脅情報(bào)的實(shí)體有如下信息:pattern_type(模式類型)、valid_from(有效期)、pattern_version(模式版本)、name(威脅情報(bào)名稱)、indicator_types(指標(biāo)類型)、created(創(chuàng)建時間)、pattern(攻擊模式)、labels(情報(bào)標(biāo)簽)、spec_version(情報(bào)規(guī)格版本)、modified(情報(bào)修改時間)、type(情報(bào)類型)、id(情報(bào)編號)、is_family(威脅情報(bào)是否相關(guān))、description(情報(bào)描述)、ip(攻擊網(wǎng)絡(luò)地址)、domain(域名)等。文中設(shè)計(jì)的實(shí)體之間具有松耦合性,為本體的擴(kuò)充留下了充足的空間。與此同時,在本體關(guān)系及約束規(guī)則下,本體之間關(guān)聯(lián)融合,從而豐富和完善了威脅情報(bào)領(lǐng)域知識圖譜。
知識圖譜首先通過不同形式分發(fā)的信息,關(guān)聯(lián)融合后形成統(tǒng)一的高質(zhì)量知識。然后根據(jù)現(xiàn)有知識推理,挖掘潛在知識,同時產(chǎn)生新知識。因此,設(shè)計(jì)威脅情報(bào)的知識圖譜,目的是將知識映射技術(shù)引入威脅情報(bào)領(lǐng)域。最后,針對開源威脅情報(bào)的輸入,采用Kill-Chain 模型、鉆石模型或異構(gòu)信息網(wǎng)絡(luò)模型,結(jié)合現(xiàn)有的開源威脅情報(bào)和實(shí)時數(shù)據(jù),對威脅情報(bào)進(jìn)行深入關(guān)聯(lián)、碰撞和分析,找到潛在的攻擊行為,并通過推理挖掘揭示隱藏的攻擊鏈和其他威脅信息。石波等[16]驗(yàn)證了基于知識圖譜的安全威脅感知方法更適用于對高強(qiáng)度安全威脅的感知。
在知識圖譜構(gòu)建的相關(guān)研究中,董聰?shù)萚17]提出情報(bào)知識圖譜構(gòu)建的框架和關(guān)鍵技術(shù)。包括信息抽取、本體構(gòu)建和知識推理等。WU等[18]提出了一種創(chuàng)新的基于本體和基于圖的方法來進(jìn)行安全評估,該方法利用本體模型的推理能力生成攻擊圖和評估網(wǎng)絡(luò)安全性。劉強(qiáng)等[19]采用了聯(lián)合學(xué)習(xí)的方法,說明了該端到端威脅情報(bào)知識圖譜構(gòu)建方法的有效性。對于在線社交網(wǎng)絡(luò)用戶,GONG等[20]提出了新的隱私攻擊來推斷屬性,文中的攻擊是利用在線社交網(wǎng)絡(luò)上公開提供的看似無害的用戶信息來推斷目標(biāo)用戶的缺失屬性。GASCON等[21]介紹了一種威脅情報(bào)平臺,可通過基于屬性圖的新型類型不可知相似性算法,對不同標(biāo)準(zhǔn)進(jìn)行統(tǒng)一分析,并對威脅數(shù)據(jù)進(jìn)行關(guān)聯(lián),提高組織的防御能力。XU等[22]提出了一個新的模型,用于解決二進(jìn)制代碼分析的問題。
3 知識圖譜構(gòu)建框架作
威脅情報(bào)知識圖譜構(gòu)建的目的是借助知識圖譜技術(shù)將分散的威脅情報(bào)集成在一起,建立和完善威脅情報(bào)評估機(jī)制[23]。通用知識圖譜的構(gòu)建基于知識的廣度,目的是建立一個覆蓋所有領(lǐng)域的通用搜索輔助知識庫,而威脅情報(bào)知識圖則需要實(shí)現(xiàn)深度知識系統(tǒng)的構(gòu)建,從而達(dá)到使知識系統(tǒng)適應(yīng)實(shí)際應(yīng)用的目的。因此,威脅情報(bào)知識圖譜的構(gòu)建不同于一般知識圖譜的構(gòu)建。文中在前人對知識圖譜研究的基礎(chǔ)上,提出了知識圖譜構(gòu)建流程圖,如圖1所示。

圖1 知識圖譜構(gòu)建流程圖
圖1中數(shù)據(jù)采集的任務(wù)是通過分布式爬蟲等方式從網(wǎng)絡(luò)中威脅情報(bào)開放網(wǎng)站獲取情報(bào)信息。知識抽取包括通過第三方開源包如jieba分詞工具對實(shí)體進(jìn)行抽取,然后利用深度學(xué)習(xí)方式抽取出威脅情報(bào)實(shí)體及其關(guān)系,從而獲得有用信息。實(shí)體指安全活動中的主體信息,例如漏洞病毒、事件等;關(guān)系是指安全實(shí)體間存在的關(guān)聯(lián)關(guān)系,如攻擊者與漏洞的關(guān)系,病毒和惡意行為的關(guān)系等;本體構(gòu)建過程是在標(biāo)準(zhǔn)威脅情報(bào)表達(dá)式STIX格式的基礎(chǔ)上,結(jié)合獲取信息的實(shí)際情況,進(jìn)行圖的本體構(gòu)建。對抽取出的知識進(jìn)行存儲,主要是將獲取的知識存入圖數(shù)據(jù)庫[24]。文中采用neo4j數(shù)據(jù)庫形成情報(bào)知識圖譜后,便于知識的增刪查詢及數(shù)據(jù)的可視化展示。
3.1 情報(bào)搜集
數(shù)據(jù)采集的任務(wù)是通過分布式爬蟲等方式從網(wǎng)絡(luò)中威脅情報(bào)開放網(wǎng)站獲取情報(bào)信息,威脅情報(bào)信息分為無結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)和結(jié)構(gòu)化數(shù)據(jù)。從6個安全平臺爬取了總計(jì)1 172 條安全博客高級持續(xù)性威脅(Advanced Persistent Threat,APT)攻擊報(bào)告,情報(bào)來源既有國內(nèi)知名情報(bào)廠商,也有訪問度較高的情報(bào)共享開源平臺,包括Feebuf、GreenSnow、blocklist、奇安信、VirusTotal和360等。爬取過程如下:首先設(shè)置反爬蟲機(jī)制,添加Cookie用來偽裝身份ID;在各個安全網(wǎng)站中自定義搜索中輸入APT 攻擊報(bào)告,采用廣度優(yōu)先搜索的方式,遍歷查詢列表,通過檢查定位資源,使用爬蟲的方式獲取文章的統(tǒng)一資源定位符(Uniform Resource Location,URL),再通過URL獲取文章內(nèi)容信息。
通過對文章內(nèi)容進(jìn)行人工審查發(fā)現(xiàn),部分報(bào)告對于攻擊行動的描述過于簡單,關(guān)于攻擊模式、攻擊過程等信息的記錄不充分。為避免模型訓(xùn)練受到數(shù)據(jù)的影響并且獲取更多的有價(jià)值信息,可從文章篇幅、規(guī)范程度、描述細(xì)節(jié)等幾個標(biāo)準(zhǔn)進(jìn)行篩選,盡量選擇篇幅較長且具體的介紹了整個攻擊流程的文章。最終挑選了爬取的745 篇,提取出其正文文本信息,作為本實(shí)驗(yàn)的原始數(shù)據(jù)集,如表1所示。

表1 原始安全報(bào)告信息
3.2 識別抽取
通過攻擊報(bào)告發(fā)現(xiàn),報(bào)告在正文內(nèi)容中描述了攻擊策略技術(shù)、惡意軟件和惡意IP等,這些IOC信息在報(bào)告中通常以固定的格式標(biāo)準(zhǔn)出現(xiàn)。例如,在沙箱環(huán)境中監(jiān)控惡意軟件等動態(tài)分析方法,使用Snort等網(wǎng)絡(luò)安全工具來監(jiān)控網(wǎng)絡(luò)流量。由此可見,IOC信息提取是一項(xiàng)非常重要的任務(wù),可以幫助安全專家更好了解網(wǎng)絡(luò)攻擊的策略、目標(biāo)和工具,以及加強(qiáng)系統(tǒng)防御。但是采用正則匹配會存在非惡意IP等信息被誤提取和IOC信息被漏報(bào)。因此,文中首先考慮利用神經(jīng)網(wǎng)絡(luò)建模的方法,引入上下文特征,然后采用正則匹配和命名實(shí)體識別相結(jié)合的辦法識別抽取。
3.2.1 識 別
首先對文本信息進(jìn)行向量化操作,將其映射為數(shù)字向量。文中采用Google公司推出的基于Transformer的 Bert 模型將文本信息處理為詞向量。在輸入時,Bert的編碼方式與Transformer的相同。以固定長度的字符串作為輸入,數(shù)據(jù)從下到上傳輸,每層都采用自我注意的方式,可表示為
(1)
多頭自注意機(jī)可表示為
(2)

輸出是每個位置返回的隱藏層大小向量,定義為Bert(x)。與傳統(tǒng)的詞向量詞word2vec相比,Bert模型的優(yōu)點(diǎn)是引入上下文特征,可以有效地捕捉上下文的依賴關(guān)系,使向量空間中上下文相似的語料庫距離非常近,因此可以產(chǎn)生更準(zhǔn)確的特征表示,對IOC的識別、提取和判斷是否為惡意信息非常有效。
該神經(jīng)網(wǎng)絡(luò)模型是基于循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)的變體 BiLSTM 模型。BiLSTM作為RNN的變體,在處理此類數(shù)據(jù)上具有更為優(yōu)秀的表現(xiàn)。BiLSTM由前向LSTM和后向LSTM組成。當(dāng)輸入詞向量為 [w1,w2,w3,…,wn] 時,前向LSTM將得到n個詞向量[hr1,hr2,hr3,…,hRn];當(dāng)輸入詞向量為 [wn,wn-1,wn-2,…,w1] 時,后向LSTM將得到n個詞向量[hln,wl3,wl2,…,wl1]。將前向和后向量拼接在一起后,可以得到[H0,H1,… ,Hn]。該向量包含向后信息,即也包含上下文特征,對順序文本信息的處理有很好的影響。由于該模型采用了Bert預(yù)訓(xùn)練模型來獲得單詞向量,因此,BiLSTM層的輸入是上一層的Bert層的輸出,可表示為
BiLSTM(w)=S[LstmL(w),LstmR(w)] ,
(3)
其中,S[L,R] 表示l和r拼接的輸出,w表示上面Bert層的輸出Bert(x)。
在命名實(shí)體識別任務(wù)中,詞向量通過神經(jīng)網(wǎng)絡(luò)模型即可輸出標(biāo)簽分值,即每個標(biāo)注詞的概率,可以選擇一個分值最大的標(biāo)簽作為該字符的標(biāo)簽,但是無法保證概率最大的就是正確的預(yù)測結(jié)果。因此,在命名實(shí)體模型中,在神經(jīng)網(wǎng)絡(luò)模型輸出后增加一個條件隨機(jī)場(Conditional Radom Field,CRF)層,CRF 在假定隨機(jī)變量構(gòu)成馬爾科夫隨機(jī)場的前提下,預(yù)測一組隨機(jī)變量的條件分布。
一代青年有一代青年的成長,一代青年有一代青年的使命,成長各異,使命相同。黨的十九大報(bào)告描繪了“兩個一百年”的宏偉藍(lán)圖。中國石化提出了“兩個三年、兩個十年”的發(fā)展戰(zhàn)略。在這一跨越近30年的歷史進(jìn)程中,石化青年生逢其時,成長期、奮斗期與民族復(fù)興、企業(yè)奮進(jìn)的目標(biāo)同向同行,將完整經(jīng)歷實(shí)現(xiàn)新時代目標(biāo)的偉大進(jìn)程,成為強(qiáng)國夢、強(qiáng)企夢的親歷者和見證者、追夢者和圓夢人。
在該模型中,在 CRF 層充分的引入了文本與標(biāo)簽的對應(yīng)關(guān)系和文本的上下文標(biāo)注關(guān)系,通過對輸出標(biāo)簽二元組進(jìn)行建模,使用動態(tài)規(guī)劃算法找出得分最高的路徑作為最優(yōu)路徑進(jìn)行序列標(biāo)注。避免出現(xiàn)得到的文本標(biāo)簽出現(xiàn)前后沖突的情況,在最后輸出時為最后的預(yù)測結(jié)果添加一個限制標(biāo)簽,以此來控制提高輸出結(jié)果的正確性,并預(yù)測最有可能的標(biāo)簽序列,即
(4)
其中,score(y)為BiLSTM層的輸出,對應(yīng)于條件下標(biāo)簽y的概率;T矩陣包含兩個相鄰實(shí)體標(biāo)簽的轉(zhuǎn)移概率,表示標(biāo)簽為后標(biāo)簽項(xiàng)的概率。該功能是為了避免文本標(biāo)簽之間的沖突,并在預(yù)測結(jié)果中添加一個限制標(biāo)簽,以控制和提高輸出結(jié)果的精度。
3.2.2 模型融合
通過以上的描述,可得到最終的模型結(jié)構(gòu)的文本表達(dá)為
Result=Re(BiLSTM(Bert(x))+score(y)) 。
(5)
首先,引入了正則性來提取可能的識別結(jié)果集。在詞向量層中,使用Bert預(yù)訓(xùn)練模型進(jìn)行編碼;然后將其輸入到BiLSTM層得到特征和預(yù)測結(jié)果,并將該層的結(jié)果輸入到CRF得到最優(yōu)解,Re(x)表示一個常規(guī)的輸出限制。
3.2.3 提 取
采用Bert+BiLSTM+CRF的方法進(jìn)行實(shí)體和關(guān)系抽取。首先對原始數(shù)據(jù)進(jìn)行數(shù)據(jù)清洗預(yù)處理,然后按照以下兩個流程進(jìn)行抽取:一種是定義正則表達(dá)式,抽取出文章中的IOC 匹配數(shù)據(jù);另一種是對標(biāo)注好的數(shù)據(jù)進(jìn)行詞向量生成,構(gòu)建神經(jīng)網(wǎng)絡(luò)模型。之后獲取模型的抽取結(jié)果,將兩種結(jié)果進(jìn)行匹配。將正則匹配結(jié)果中出現(xiàn)在模型輸出結(jié)果中的信息直接輸出;對于未出現(xiàn)在模型輸出結(jié)果中的信息將其上下文標(biāo)注為疑似IOC,重新輸入到模型中,用于二次識別抽取,再輸出抽取結(jié)果,以此來更加準(zhǔn)確地抽取出文章中的IOC 信息。算法流程如圖2所示。

圖2 IOC抽取算法流程圖
以“蔓靈花攻擊行動(簡報(bào))”為測試樣本舉例說明抽取流程。首先將測試樣本進(jìn)行數(shù)據(jù)清洗后,通過定義正則表達(dá)式,抽取候選集合:{RequirementList.doc,…,C:ProgramDataMicrosoftDeviceSynctemp.txt }作為正則匹配候選集;將樣本輸入到訓(xùn)練好的Bert-BiLSTM-CRF模型中,與正則匹配候選集進(jìn)行匹配驗(yàn)證,最終輸出得到“蔓靈花攻擊行動(簡報(bào))”抽取結(jié)果(為表達(dá)直觀,采用< >框選實(shí)體部分)。
蔓靈花攻擊行動(簡報(bào))標(biāo)注結(jié)果:研究人員發(fā)現(xiàn),該組織經(jīng)常使用<魚叉郵件>攻擊的手法,<魚叉郵件>中包含
…
程序首先嘗試在
…
3.3 本體構(gòu)建
本體構(gòu)建過程是在標(biāo)準(zhǔn)威脅情報(bào)表達(dá)式STIX 格式的基礎(chǔ)上[25],結(jié)合獲取信息的實(shí)際情況,進(jìn)行圖的本體構(gòu)建。對抽取出的知識進(jìn)行存儲主要是將獲取的知識存入圖數(shù)據(jù)庫。文中采用neo4j數(shù)據(jù)庫形成情報(bào)知識圖譜,便于知識的增刪改查操作以及數(shù)據(jù)的可視化展示。
入侵集合是攻擊活動的組合,由單個威脅源發(fā)起;特征指標(biāo)即威脅情報(bào)指標(biāo),在攻擊過程中產(chǎn)生,常見的IOC 指標(biāo)通常包括:HASH、URL、域名和IP值;身份歸屬于威脅源,與其一一對應(yīng);防御策略是針對攻擊模式所制定的策略,保護(hù)組織應(yīng)對攻擊[26]。
通過對威脅情報(bào)的原子構(gòu)建最終實(shí)現(xiàn)圖譜的架構(gòu)。以攻擊模式和漏洞為例,攻擊模式是組織快速理解攻擊強(qiáng)弱的途徑,從攻擊方法來說,分為DDOS攻擊、web入侵、數(shù)據(jù)庫入侵、系統(tǒng)入侵和病毒植入。其中,web 入侵有遠(yuǎn)程入侵和隱秘通道入侵兩種方式,系統(tǒng)入侵包括系統(tǒng)提權(quán)和Webshell;攻擊過程分為遠(yuǎn)程漏洞利用、Web暴力破解登錄、本地漏洞利用、XSS攻擊、數(shù)據(jù)庫注入、欺騙和flood攻擊;漏洞從技術(shù)類型來說,劃分為內(nèi)存破壞類、邏輯錯誤類、輸入驗(yàn)證類、設(shè)計(jì)錯誤類和配置錯誤。
3.4 情報(bào)推理
Adversarial Tactics,Techniques,and Common Knowledge (ATT&CK)以攻擊者的視角來描述攻擊中各階段用到的技術(shù)。通過將已知攻擊者行為轉(zhuǎn)換為結(jié)構(gòu)化列表,以矩陣和結(jié)構(gòu)化威脅信息表達(dá)式(STIX)、指標(biāo)信息的可信自動化交換(TAXII)來表示攻擊戰(zhàn)術(shù)和技術(shù)。ATT&CK 在kill chain 模型的基礎(chǔ)上提出,關(guān)注攻擊過程的上下文,構(gòu)建共享的知識模型和框架,解決了分析檢測以IOC 為主的行為標(biāo)記和攻擊描述缺乏規(guī)范化兩大問題。文中提出的抽取模型從多個來源獲取威脅情報(bào)數(shù)據(jù)后,首先根據(jù)ATT&CK模型將攻擊者行為轉(zhuǎn)化為標(biāo)準(zhǔn)化結(jié)構(gòu),使用知識圖譜清晰描繪出攻擊行為,并且進(jìn)行威脅情報(bào)融合分析,然后進(jìn)行關(guān)聯(lián)分析[27],幫助還原攻擊事件的量化指標(biāo),通過理解上下文進(jìn)行態(tài)勢感知,為威脅響應(yīng)團(tuán)隊(duì)提供及時、相關(guān)、完整和準(zhǔn)確的情報(bào)。關(guān)聯(lián)分析可以應(yīng)對不斷增加的數(shù)據(jù)及數(shù)據(jù)復(fù)雜性,常用的關(guān)聯(lián)分析方法有內(nèi)部溯源和外部溯源。外部溯源通過給攻擊者描繪畫像信息,如個人信息、攻擊用網(wǎng)絡(luò)資產(chǎn)、工具、目標(biāo)和事件發(fā)生位置等進(jìn)行分析。在APT攻擊中,惡意軟件通常以家族形式演化。
因此,對于追蹤攻擊的來源和了解新的惡意軟件可以使用建立惡意軟件家族圖的方式。當(dāng)攻擊對象知道某類攻擊名稱,其所屬的類型后,以及類型中所包含的攻擊病毒家族后[28],可以判斷出某一類關(guān)系是否合法,從而對于威脅情報(bào)進(jìn)行有效評估。同理,知道第1、2、4、5、6類的關(guān)系,能夠推理出第3類關(guān)系,從而更能廣泛挖掘出數(shù)據(jù)之間存在的深度關(guān)聯(lián),發(fā)掘出潛在的攻擊行為,從而更好地發(fā)現(xiàn)威脅情報(bào)信息。
4 實(shí)驗(yàn)評估
4.1 數(shù)據(jù)源
數(shù)據(jù)來源是結(jié)構(gòu)化信息標(biāo)準(zhǔn)促進(jìn)組織(oasis)公布的威脅情報(bào)數(shù)據(jù),將爬取得到的非結(jié)構(gòu)化數(shù)據(jù)進(jìn)行簡單的預(yù)處理,包括數(shù)據(jù)清洗、停用詞過濾后,選擇文章的正文內(nèi)容作為數(shù)據(jù)集。將報(bào)告按照8∶1∶1的比例,從中隨機(jī)抽取出74篇進(jìn)行人工IOC標(biāo)注,標(biāo)記出文章中涉及到的惡意IP,URL等,作為測試集。再隨機(jī)選出74篇作為驗(yàn)證集,剩下的部分為訓(xùn)練集。采用的標(biāo)注工具為Colabeler,標(biāo)注過程如圖3所示。
圖3 標(biāo)注過程
4.2 識別抽取實(shí)驗(yàn)結(jié)果
在生成詞向量階段,直接調(diào)用Bert模型生成。在訓(xùn)練神經(jīng)網(wǎng)絡(luò)模型時,采用隨機(jī)梯度下降的方法。為了防止出現(xiàn)過擬合的現(xiàn)象,模型引入Dropout正則化處理,設(shè)置最大epoch個數(shù)為100,經(jīng)過調(diào)參發(fā)現(xiàn)當(dāng)Embedding_dim值為100、Hidden_dim值為129、Dropout_rate為0.5、Batch_size為32、學(xué)習(xí)率為0.001的情況下最優(yōu)。訓(xùn)練過程如圖4所示。

圖4 訓(xùn)練過程
文中采用常用的NER評價(jià)指標(biāo)值:精確率P(Precision)、召回率R(Recall)和F1(F-measure) 來衡量實(shí)驗(yàn)結(jié)果。根據(jù)評估標(biāo)準(zhǔn),模型對比如表2所示。

表2 神經(jīng)網(wǎng)絡(luò)抽取模型改進(jìn)
當(dāng)單獨(dú)使用正則匹配時,模型的識別率非常低,原因在于非惡意IOC的錯誤識別和非標(biāo)注格式IOC的漏報(bào),當(dāng)使用神經(jīng)網(wǎng)絡(luò)BiLSTM時,相比于正則匹配性能有了非常顯著的提升;當(dāng)對BiLSTM的輸出加以CRF限制時,識別性能也相對提高。可見CRF 對標(biāo)簽限制輸出在命名實(shí)體識別任務(wù)中的必要性。采用Bert模型進(jìn)行詞向量的生成也提高了模型的識別準(zhǔn)確率,Bert和CRF的引入可以看出引入上下文特征在文本信息處理任務(wù)上具有非常好的效果; 最后,文中添加了正則匹配,將正則匹配結(jié)果進(jìn)行二次識別。實(shí)驗(yàn)
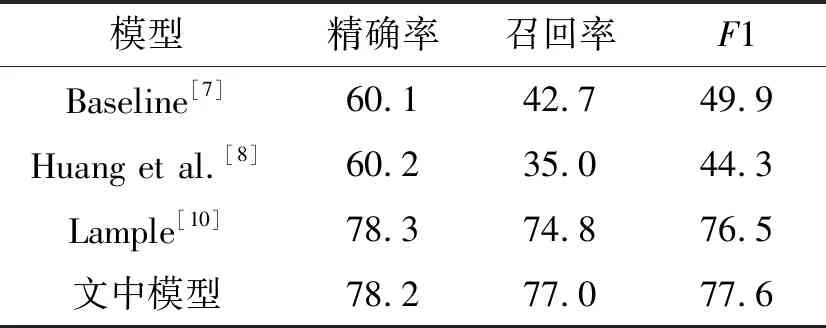
表3 各抽取模型對比
結(jié)果表明,這一方法對模型優(yōu)化也存在一定幫助。
同時將該法與其他抽取模型對比,文中所使用的模型評分明顯高于基準(zhǔn)線。對比結(jié)果如表3所示。
4.3 實(shí) 現(xiàn)
ATT&CK的應(yīng)用之一是威脅情報(bào),通過將報(bào)告轉(zhuǎn)化為結(jié)構(gòu)化格式,把依賴IOC轉(zhuǎn)變?yōu)榛赥TPs和行為的攻擊檢測。文中首先使用ATT&CK Navigator工具進(jìn)行分析,Dicovery戰(zhàn)術(shù)中使用5種技術(shù),Collection階段使用兩種技術(shù):Automated Collection和Data from Local System,然后通過構(gòu)建知識圖譜描述攻擊行為和過程。
對APT1 建立知識圖譜進(jìn)行分析,攻擊手段通常為魚叉攻擊,通過尋找易受攻擊的web 服務(wù)器,然后上傳webshell,達(dá)到訪問目標(biāo)內(nèi)部網(wǎng)絡(luò)的目的。攻擊周期包括初步偵察、建立立足點(diǎn)、特權(quán)提升、內(nèi)部偵察和橫向移動5個階段。數(shù)據(jù)格式為JSON格式,圖譜中包含實(shí)體200個,關(guān)系133個,關(guān)系類別包括uses、mitigates、indicates、targets和attributed_to。將威脅情報(bào)對象和對應(yīng)的值輸入查詢系統(tǒng)時,可以根據(jù)cypher語句從圖數(shù)據(jù)中查詢到相應(yīng)的點(diǎn)及關(guān)系,從而返回頁面中。本次分析采用標(biāo)準(zhǔn)的STIX格式數(shù)據(jù),需要創(chuàng)建本體及原子本體。其中,圖譜中共有7類本體,分別為入侵集合、威脅源、特征指標(biāo)、惡意代碼、身份、攻擊工具和攻擊模式,圖譜中本體關(guān)系如圖5所示。

圖5 本體關(guān)系
各個本體下的原子本體是實(shí)例化的實(shí)體,是本體中最小的不可分割的概念。具體的數(shù)據(jù)即為圖譜中的一個實(shí)體。依據(jù)本體關(guān)系建立實(shí)體關(guān)聯(lián),從圖譜中任一實(shí)體出發(fā),可根據(jù)關(guān)系查詢出與之相關(guān)的所有信息。如圖6所示,通過特征指標(biāo)indicator--8da68996-f175-4ae0-bd74-aad4913873b8指示惡意軟件malware--4de25c38-5826-4ee7-b84d-878064de87ad具有攻擊性,其威脅源來自于campaign--752c225d-d6f6-4456-9130-d9580fd4007b,通過分析協(xié)助用戶快速找到威脅源,從而有效處置。

圖6 APT1實(shí)體關(guān)系圖譜
從圖6中也可以看出,根據(jù)邊顏色的不同進(jìn)行實(shí)體間關(guān)系的劃分[29],更加直觀地了解攻擊事件中本體及原子本體以及其之間的關(guān)系。通過知識圖譜的情報(bào)搜索,可以更加充分挖掘數(shù)據(jù)之間潛在關(guān)系,對于威脅情報(bào)的精準(zhǔn)可視化具有重要意義。
4.4 工程應(yīng)用
4.4.1 數(shù)據(jù)可視化
可視化是知識圖的一個典型應(yīng)用。對于各種類型的威脅情報(bào),可以使用模式匹配的原則來查詢特定的節(jié)點(diǎn)和關(guān)系并可視化顯示。例如,與攻擊事件相關(guān)的所有節(jié)點(diǎn)的信息、相同攻擊模式的所有節(jié)點(diǎn)等,可以幫助專業(yè)人員進(jìn)行推理分析。
4.4.2 知識推理
這部分使用了知識圖的推理函數(shù)。雖然neo4j的存儲方法不如RDF穩(wěn)健,具有較強(qiáng)的語義能力,但基于弱語義的推理仍被廣泛應(yīng)用。知識推理可以被理解為基于一般的規(guī)則和結(jié)論來獲取新的知識。它應(yīng)用于威脅情報(bào)領(lǐng)域,可以推斷出各種潛在的威脅。例如,當(dāng)多個攻擊者在同一攻擊模式下攻擊某一特定公司時,可以假設(shè)該公司對這種攻擊模式的防御能力較差。還可以推斷出在這種攻擊模式下的其他攻擊者也受到了威脅。此外,它還包含了一些基于知識推理的錯誤檢查和分類等功能。
5 結(jié)束語
文中介紹了知識圖譜的相關(guān)構(gòu)建技術(shù),包括數(shù)據(jù)獲取、識別抽取、本體構(gòu)建及情報(bào)推理。使用了一種基于Bert+BiLSTM+CRF的命名實(shí)體識別模型,加以正則匹配機(jī)制進(jìn)行輸出限制,用于從文本信息中識別抽取IOC信息,并輸出為STIX標(biāo)準(zhǔn)化格式數(shù)據(jù)的方法。Bert模型和條件隨機(jī)場的引入充分利用了上下文特征,從而獲得了比前人更好的性能,提高了IOC抽取的準(zhǔn)確度。實(shí)驗(yàn)結(jié)果對比表明,文中模型相比于其他模型在識別準(zhǔn)確度上有提升,在中文數(shù)據(jù)集上有較為良好的表現(xiàn)。最后提出一個KGCP系統(tǒng),該系統(tǒng)使用ATT&CK技術(shù)對威脅情報(bào)進(jìn)行格式轉(zhuǎn)換完成情報(bào)推理。基于本體建立了本體與原子本體知識圖譜,通過知識圖譜關(guān)聯(lián)分析數(shù)據(jù)之間潛在關(guān)聯(lián),發(fā)現(xiàn)具有相似性和相關(guān)性的威脅,完成攻擊行為的查詢與分析預(yù)測。
未來,將首先構(gòu)建一個平臺,該平臺能夠收集不同數(shù)據(jù)格式的威脅情報(bào)并對其進(jìn)行關(guān)聯(lián);然后引入相似度算法進(jìn)行相似性分析,來表示不同粒度級別威脅之間的關(guān)系,將相似性分析整合到平臺中,設(shè)計(jì)出高效的情報(bào)檢索,提高組織的防御能力。云托管的應(yīng)用程序容易受到 APT 攻擊、Sybil 攻擊和 DDOS 攻擊,針對這一攻擊特點(diǎn),需要提出新的有針對性的威脅情報(bào)共享平臺,可以快速檢測出混淆的數(shù)據(jù)以防御上述攻擊,提高 CTI 共享平臺的有效性和可靠性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學(xué)數(shù)學(xué)雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創(chuàng)作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
