基于聚類算法的電網告警數據分析與處理模型*
2023-09-12 09:01:10萬維威鄒大均
通信技術 2023年7期
劉 波,萬維威,鄒大均,李 立
(中國電子科技集團公司第三十研究所,四川 成都 610041)
0 引言
目前,全球網絡安全形勢日益嚴峻,針對關鍵信息基礎設施的惡意網絡攻擊頻發。隨著負荷側資源不斷擴充,電力監控系統的安全防護范圍不斷擴大,接入安全顯得尤為重要。隨著安全防護范圍的不斷拓展,產生的安全數據日益倍增,告警數量不斷增大,如何確保告警及時有效,提升告警的精準度和實效性,成為安全防護監管的一大難題[1]。
大量學者對智能告警技術開展了深入研究。其中,有研究利用K-近鄰算法(K-Nearest Neighbors algorithm,KNN)、卷積神經網絡(Convolutional Neural Network,CNN)等機器學習或人工智能算法對電網大數據進行清洗,并采用典型建模方法分析安全事件,實現對電網數據的智能處理[2-5],但是這些算法需要占用一定的計算空間。此外,還有研究基于規則、模型等基本數據,采用層次分析法等方法得到當前告警信息特征并進行分層分類,為更具價值的數據分配更高權重[6],但此類方法需要多名專家對數據的重要性進行評價,使用起來較為 煩瑣。
針對上述問題,本文使用K-Means[7]和DBSCAN[8]算法,以電力監控系統網絡安全管理平臺的歷史告警數據為處理數據,提取告警數據特征信息,進行多維度的特征聚類,最終建立電力監控系統網絡安全事件告警數據綜合分析模型,提高已有分析系統的效率。
1 算法描述
1.1 K-Means 聚類算法
作為經典且應用廣泛的聚類算法之一,K-Means 聚類算法具有的優點有理論可靠、算法簡單、收斂速度快、能有效處理大數據集等。K-Means算法中的K 代表類簇個數,Means 代表類簇內數據對象的均值。K-Means 算法是一種基于劃分的聚類算法,以距離作為數據對象間相似性度量的標準,即數據對象間的距離越小,它們的相似性越高,則它們越有可能在同一個類簇。
具體的聚類過程如下:
算法1:K-Means 算法


1.2 DBSCAN 聚類算法
DBSCAN 基于一組鄰域來描述樣本集的緊密程度,參數(ε,MinPts)用來描述鄰域的樣本分布緊密程度。其中,ε描述了某一樣本的鄰域距離閾值,MinPts描述了某一樣本的距離為ε的鄰域中樣本個數的閾值。
DBSCAN 算法的具體聚類過程如下:
算法2:DBSCAN 算法

2 電網告警數據分析與處理模型
本文提出的電網告警數據分析與處理模型,分為基于時間的K-Means 聚類和基于特征關鍵詞的DBSCAN 聚類。第1 步主要使用K-Means 對輸入的原始告警日志數據進行壓縮,依據的條件為日志數據中的時間信息,包括告警數據最新發生時間和告警開始時間。第2 步則提取前一步壓縮后數據的特征,根據特征關鍵字使用DBSCAN 算法進行進一步壓縮。最終實現對電網原始告警日志數據的壓縮與聚類,建立電力監控系統網絡安全事件告警數據綜合分析模型,并根據聚類的結果對告警數據進行分析和研判,給出每一類告警信息的具體描述,提高現有電網告警數據分析系統的效率。模型的具體流程如圖1 所示。
2.1 基于時間的K-Means 聚類
分析原始告警日志數據可以發現,現有的電網告警系統根據告警數據的各項屬性對原始數據進行了具象化描述。對于任意一條告警數據s,根據屬性可以將其劃分為告警級別、告警內容、告警設備、上報設備、告警開始時間、最新發生時間、告警次數、上報狀態、日志類型、日志子類型和告警狀態,具體可以描述為s(level,content,dev_ale,dev_up,time_beg,time_new,count,status_up,type_main,type_sub,status_ale)。使用K-Means 算法可以根據任一屬性對原始數據集進行聚類,但實際聚類效果有所不同,最終進行描述時所依據的屬性也會存在差異。本模型主要從告警數據的時間維度出發,考慮原始告警數據集中的告警最新發生時間S.time_new 和告警開始時間S.time_beg,最終聚類完成后將時間維度作為信息描述的一個重點。基于告警數據中時間屬性的K-Means 聚類如圖2 所示。
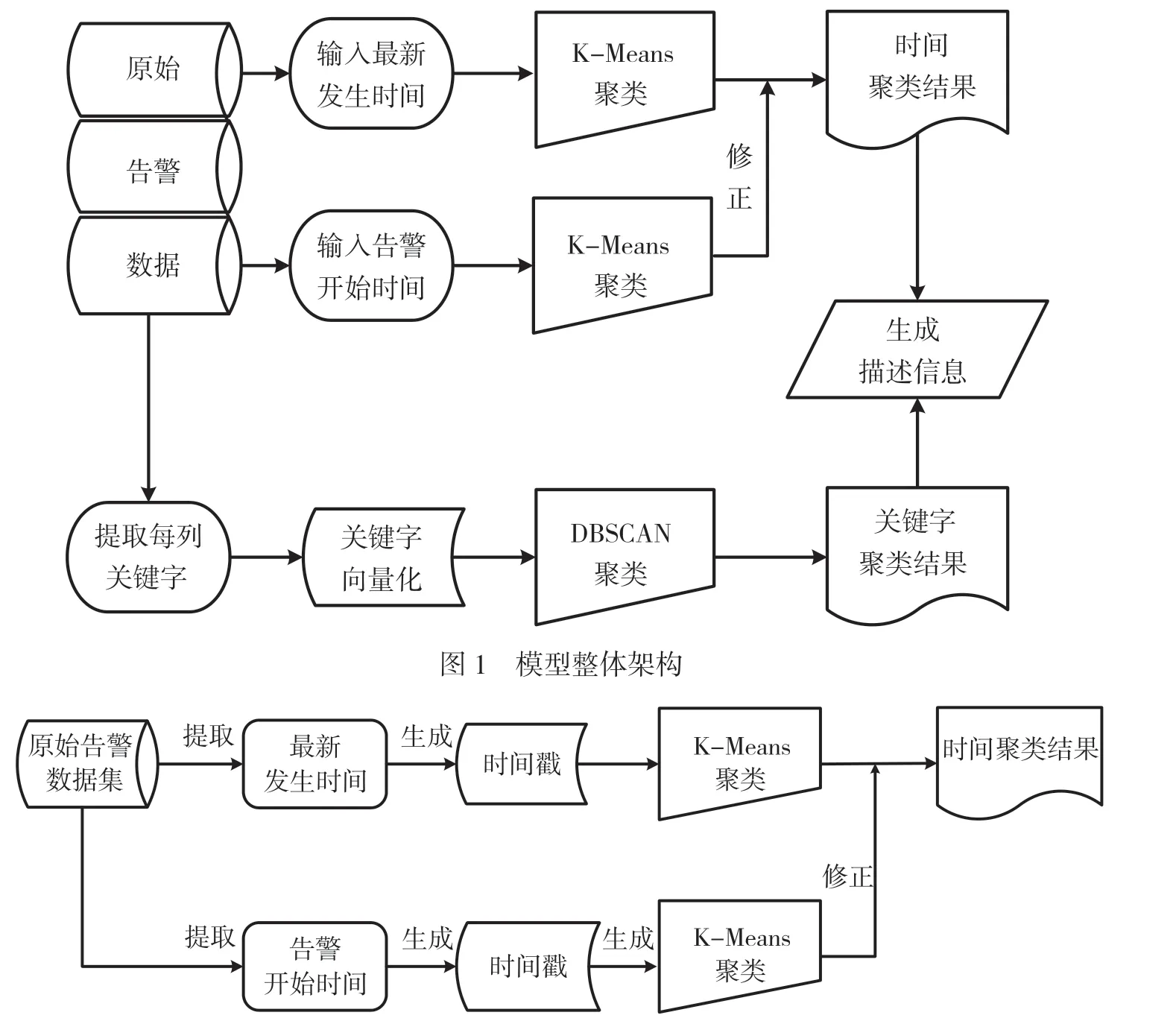
圖2 基于時間屬性的K-Means 聚類
此外,在進行兩次K-Means 聚類時,還需考慮初始的K值選取。K值的不同會極大地影響聚類的效果,具體K值的選取需要考慮聚類后時間維度的準確率。此處進行K值選取的規則定義:在對原始數據集的時間維度進行分析的基礎上,給出聚類后各類別的預期時間跨度Tk,即當按照某個K值對原始數據的時間維度進行K-Means 聚類后,每個類中的時間跨度都滿足tk≤Tk,此時稱時間維度的K-Means 聚類達到最優效果。同理,對K值選取時對應的準確率Acck定義如下:對于時間維度的K-Means 聚類,準確率Acck指聚類后滿足tk≤Tk的類別數量與所有類別數量的比值,即滿足預期時間跨度要求的類別與總類別的比值。原始數據集的時間跨度、聚類后各類別的預期時間跨度Tk、不同的初始K值都會影響聚類后時間維度的準確率,因此需要通過具體實驗來確定最優的參數進行K-Means 聚類,使聚類的壓縮率和準確率達到相對最優的結果。
2.2 基于特征關鍵詞的DBSCAN 聚類
在進行DBSCAN 聚類之前,需要將3.1 節中聚類后的結果進行基于關鍵詞的向量化操作,因此需要對S.level、S.content 等告警數據的屬性進行分析,給出關鍵詞向量化的基本規則。由于告警設備以及上報設備差異性較小,并且并非最終關聯性描述時的元素,因此直接用固定的數值代替S.dev_ale 和S.dev_up 兩個屬性原始字符串內容,其他7 列屬性的關鍵詞向量化規則如表1 所示。

表1 關鍵詞向量化規則
使用正則化表達式對原始數據集中每條日志數據進行關鍵字搜索與匹配,接著根據上述規則將關鍵詞所在列轉換為數學向量,同時將S.dev_ale、S.dev_up、S.time_beg 和S.time_new 這4 列直接轉換為固定的數字,用于保證整體數據的規格統一。
3 實驗及結果分析
3.1 實驗數據集與參數設置
選取電力監控系統近一個季度的歷史告警數據,分為30 個地市,每個地市的數據單獨存儲,總條目數為4 739 條。實驗先基于最新發生時間,使用K-Means 對原始數據集進行聚類。以其中某地市的告警數據為例,該地市近一季度的告警數據總條目數numb為108 條,最新發生時間的時間跨度為2021.08.29 05:28:48—2021.11.27 18:39:04,則初始K值的選取方法為:獲取最新發生時間的時間跨度時間戳形式為1 630 186 128~1 638 009 544,因此時間跨度T=1 638 009 544-1 630 186 128=7 823 416。根據要求設定聚類后各類別的預期時間跨度Tk為(2.5,3)天,時間戳形式下Tk為(216 000,259 200),同時規定K的范圍為[10%×numb,30%×numb]。對于該地市,即K屬于[10.8,32.4],并且K為正整數。同理獲取告警開始時間的時間跨度,給出對應的K值 范圍。
通過多次實驗驗證K的取值與準確率Acck之間的關系,具體實驗結果如圖3 所示。
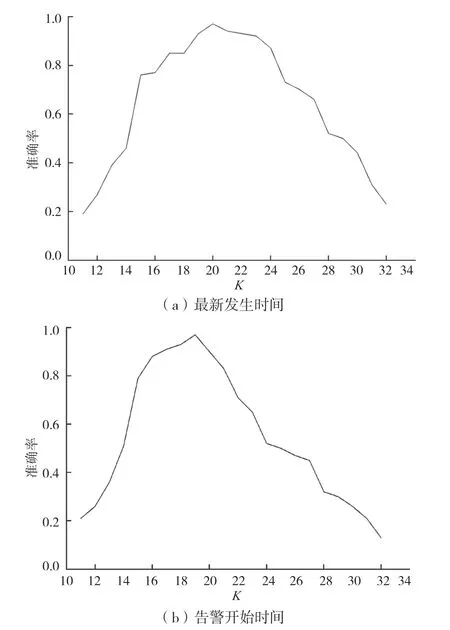
圖3 最新發生時間和告警開始時間的K 值與準確率的關系
由圖3(a)可知,當K值選取20 時,針對該地市的最新發生時間進行K-Means 聚類,可以達到最高的準確率,使得聚類后準確率達到97%。由 圖3(b)可知,當K值選取19 時,針對該地市的告警開始時間進行K-Means 聚類,可以達到最高的準確率,使得聚類后時間跨度滿足要求的類別數與總類別數的比例達到97%。
使用Calinski-Harabaz 指標(簡稱CH 指標)對K的取值進行驗證,CH 指標通過類間方差和類內方差之比計算得分,得分越大表示效果越好。對最新發生事件的K值進行CH 指標計算,由圖4(a)可知,K值選取20 或30 左右時,CH 指標值相較于其他K值數值較大。綜合圖3(a)和圖4(a)的結果,選取K=20 作為針對該地市的第1 次K-Means 聚類。
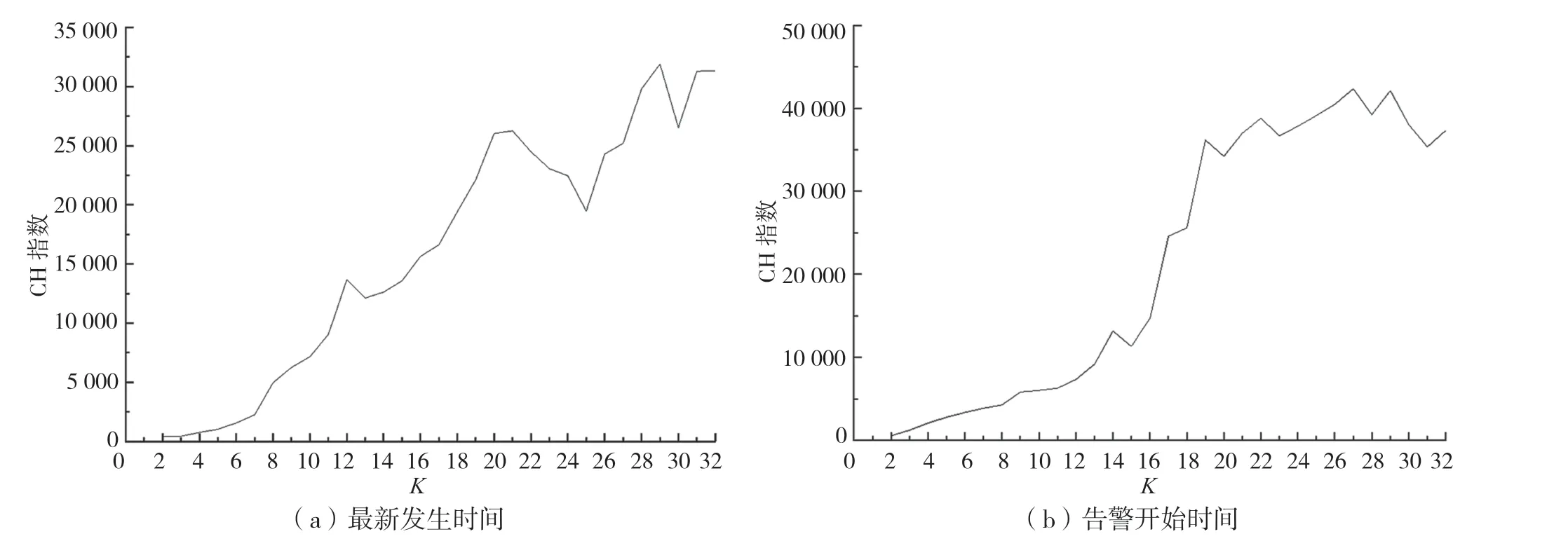
圖4 最新發生時間和告警開始時間的K 值與CH 指標的關系
由圖4(b)可知,第2 次基于告警開始時間的聚類,K大于或等于19 時可以達到最高的準確率和較好的聚類結果。綜合圖3(b)和圖4(b)的結果,選取K=19 作為針對該地市的第2 次K-Means 聚類。
實驗第2 階段采用DBSCAN 算法。對于該地市的數據,考慮鄰域半徑ε與噪聲率之間的關系,進行多次實驗,最終得到的關系如圖5 所示。
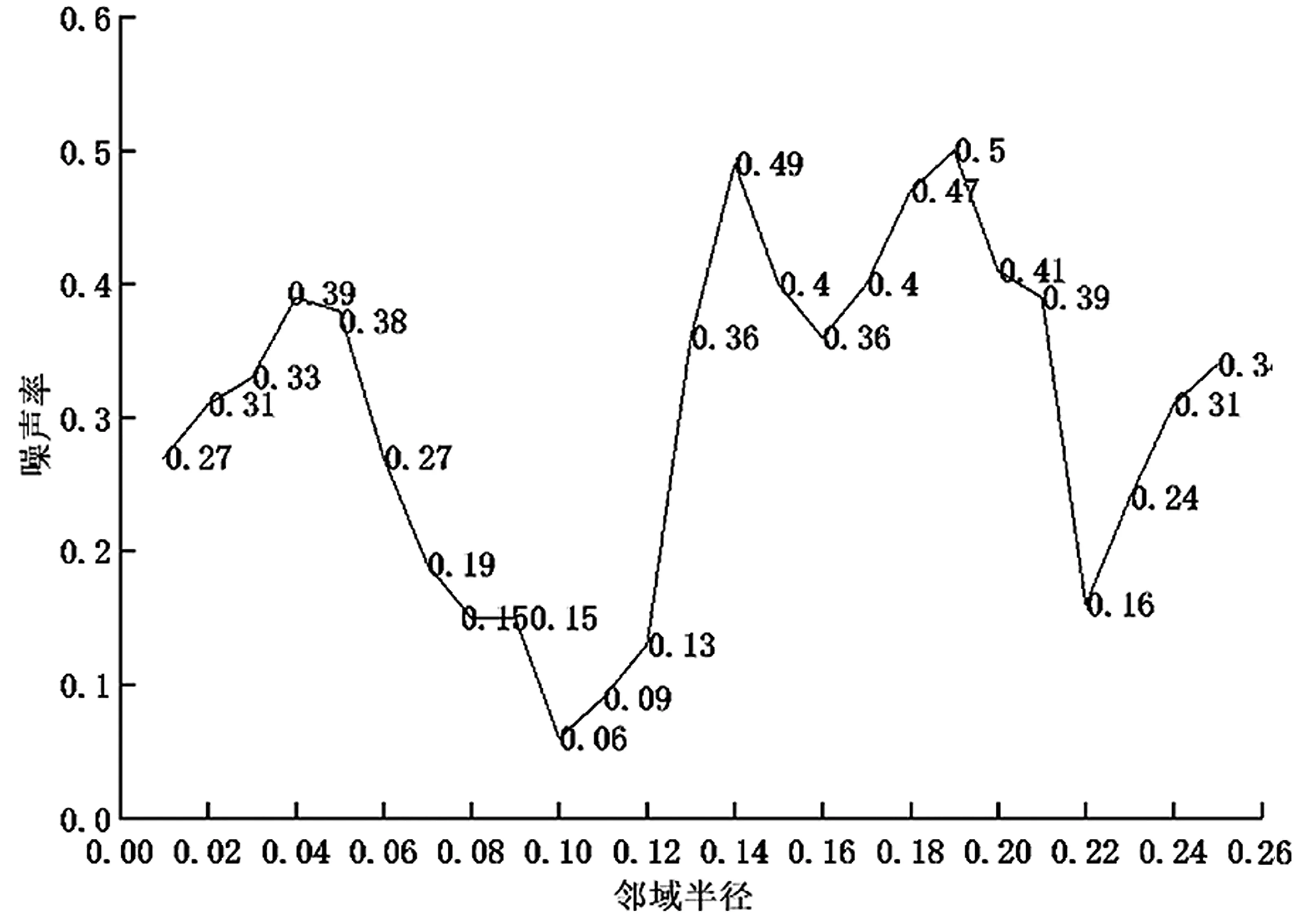
圖5 鄰域半徑與噪聲率的關系
由圖5 可知,DBSCAN 聚類選取0.1 作為最優的鄰域半徑ε,而鄰域中數據對象數目閾值MinPts則為每個地市單獨文件下日志子類型的種類數量,此時進行DBSCAN 聚類可以達到最優效果。
3.2 評估指標
實驗對于聚類結果的評價,主要采用以下3 個指標。
(1)壓縮率(Compression rate)。壓縮率指聚類后數據形成的類數量與聚類前所有條目數量的 比值。
(2)噪聲率(Noise rate)。噪聲點指未成功完成聚類的條目,噪聲率指聚類后出現的噪聲點數量與聚類前所有條目數量的比值。
(3)準確率(Accuracy)。準確率指聚類后滿足tk≤Tk的類別數量與所有類別數量的比值,即滿足預期時間跨度要求的類別與總類別的比值。
由上面的定義可知,壓縮率越高、噪聲率越低、準確率越高的聚類結果是最優結果。
3.3 實驗與結果分析
按照上述方法,首先對輸入的某地市近半年告警數據進行聚類,采用K-Means 聚類算法,統計該地市告警數據文件中數據條目數numb為108 條,計算初始K值為20。接著基于告警數據的最新發生時間進行K-Means 聚類,具體過程為:提取每條數據的最新發生時間并轉化成標準時間形式,再生成對應的時間戳,接著選取20 個不同的時間戳作為初始聚類中心,對任意一條數據,求其時間戳到20 個聚類中心的距離,將其歸類到距離最小的中心的聚類。不斷迭代并在每次迭代過程中利用均值法更新各聚類的中心點,最終將所有108 條數據進行聚類,分為20 大類,作為K-Means 第一次聚類的結果。聚類結果如圖6 所示。
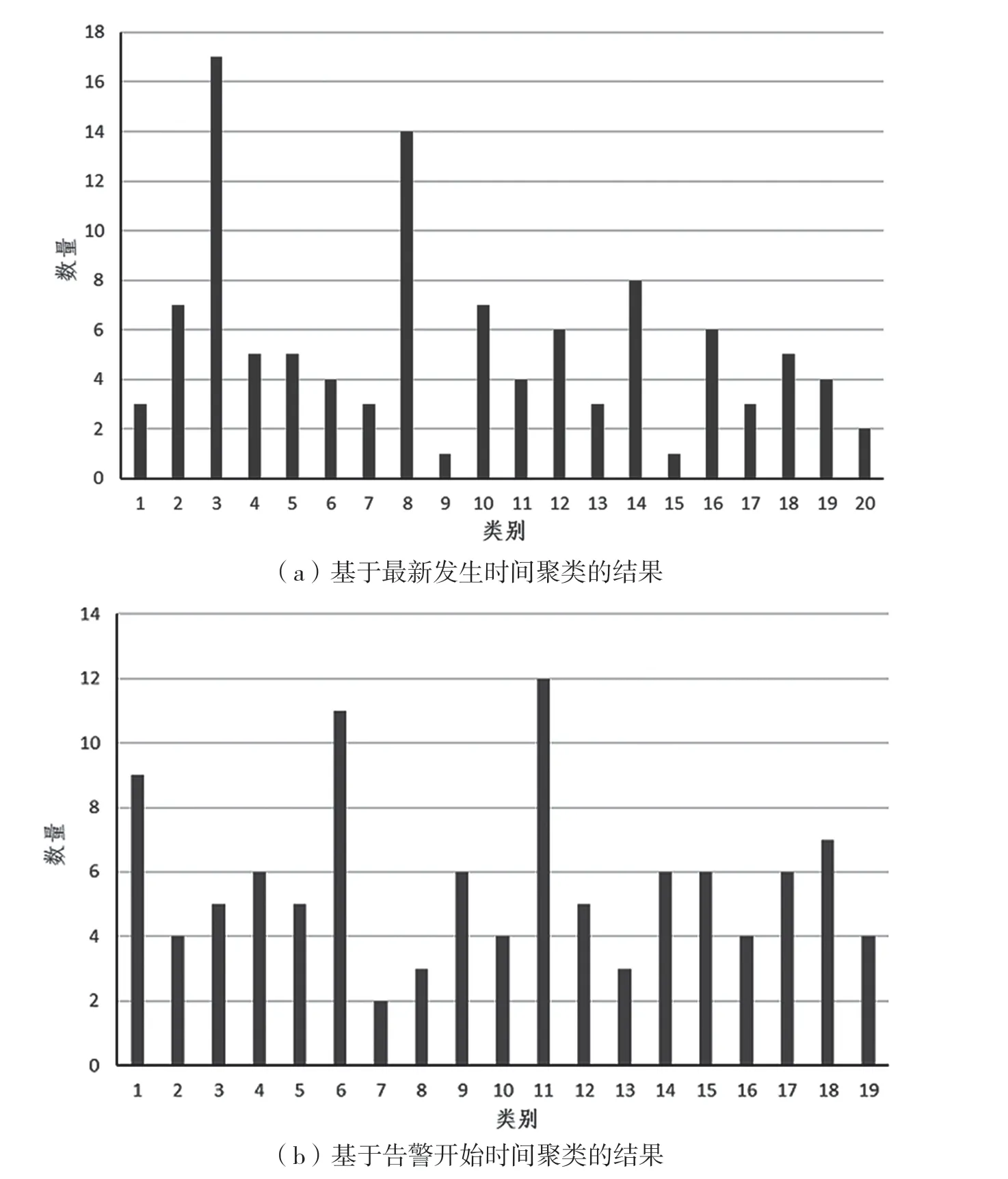
圖6 基于告警數據最新發生與開始時間進行聚類的結果
圖6(a)為基于告警數據最新發生的聚類分布,分析發現,依據最新發生時間進行聚類時,存在部分數據告警開始時間相同但未處于同一類的情況,主要原因是第一次聚類只考慮了最新發生時間這一屬性,而未考慮告警開始時間,因此在時間維度上還有優化空間。基于告警數據的開始時間進行K-Means 二次聚類,此時輸入數據集依舊為該地市對應的告警數據原始文件,K值選取19。聚類結果如圖6(b)所示,可以發現二次聚類能夠修正第一次聚類后出現的異常情況,并且壓縮率更高。最終匯總K-Means 兩次聚類的結果,作為第一階段K-Means 的輸出。
模型第二階段利用DBSCAN 算法對告警數據的關鍵字維度進行再次聚類,首先按照3.2 節的關鍵詞向量化規則,對該地市所有數據進行向量化操作,其次設置鄰域半徑ε為0.1,鄰域中數據對象數目閾值MinPts為該地市告警文件中日志子類型的種類數量4。在對輸入維度進行降維操作之后,對聚類結果進行可視化,結果如圖7 所示。從聚類結果可以看出,在所有的108 條數據中只存在7 個噪聲點,意味著只有7 條數據沒有完成 聚類。
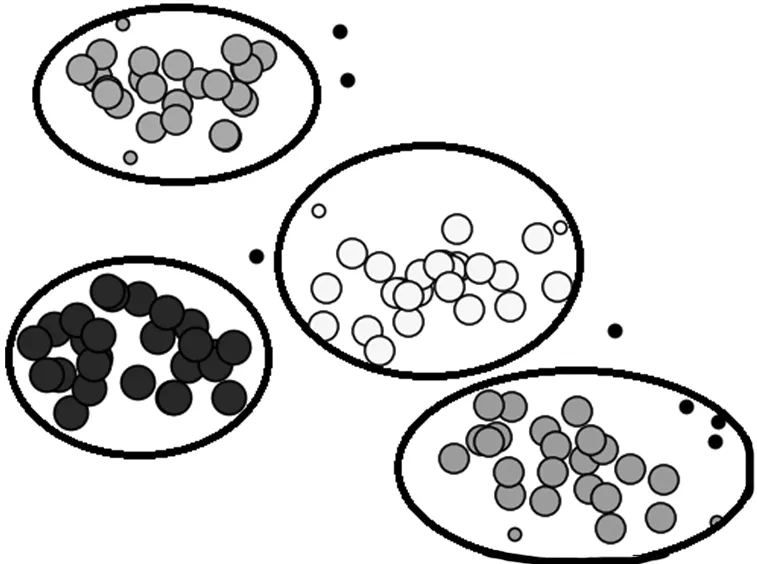
圖7 DBSCAN 聚類結果
采用同樣的方法對該省其他29 個地市的告警數據進行聚類分析,最終得到所有地市的聚類情況如圖8 所示。30 個地市中,有19 個地市的壓縮率達到20%以下,30個地市的壓縮率都達到30%以下,平均壓縮率為23.62%。準確率方面,27 個地市都達到80%以上,平均準確率為88.34%。噪聲率方面,25 個地市都低于20%,平均噪聲率為15.06%。
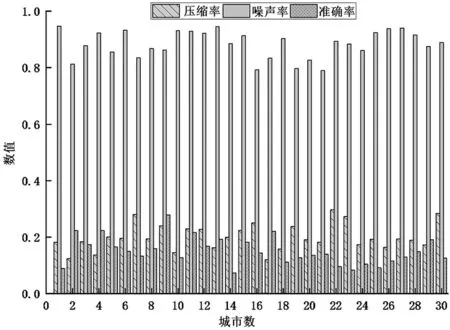
圖8 30 個地市的聚類結果
最后基于聚類后的結果,采用關聯性結果描述,具體描述的信息為:某地市的第××條至××條日志在yyyy-mm-dd hh:mm:ss 至yyyy-mm-dd hh:mm:ss 期間內發生了××事件,即根據日志最新發生時間和日志子類型的聚類結果,分段描述告警數據的具體信息,具體實例如下文所示。
(1)第1 條日志在2021-08-29 05:28:48 時刻發生了主機開放危險端口事件;
(2)第2 到6 條日志在2021-09-01 18:39:04至2021-09-01 21:18:10 期間內,發生了USB 存儲設備接入;
(3)第7 到12 條日志在2021-09-04 21:26:10至2021-09-04 21:31:42 期間內,發生了數據網危險端口訪問;
(4)第13 到18 條日志在2021-09-16 20:47:55 至2021-09-18 12:11:15 期間內,發生了USB 存儲設 備接入、數據網危險端口訪問;
(5)第19 到26 條日志在2021-09-23 09:28:47 至2021-09-24 10:31:09 期間內,發生了數據網危險端口訪問、串口訪問。
后續結果與上述描述類型一致,具體內容不再列出。
從結果可以看出,綜合K-Means 和DBSCAN算法的結果,能夠對原始告警數據進行高效壓縮,并給出每個時間段內具體發生的告警事件類型,大大降低了原始數據的復雜度以及閱讀難度,提高了對于告警數據關鍵信息的抽取能力。
3.4 算法對比試驗
為了展示本模型對電網告警數據分析處理的優勢,本文進行了K-Means 時間聚類配合DBSCAN關鍵字聚類與經典DBSCAN 聚類的對比試驗。從數據集中隨機抽取了一個電站的告警數據,共32 條。首先在選取合適的參數后,對告警數據按照本模型進行K-Means 時間聚類配合DBSCAN 關鍵字聚類,輸出第一次聚類結果;其次將兩個時間維度加入DBSCAN 聚類的輸入當中,選取與第1 次聚類相同的參數,得到第2 次的聚類結果,兩次聚類結果的噪聲率結果如表2 所示。

表2 兩種算法噪聲率對比
4 結語
本文首先建立了電力監控系統網絡安全事件告警數據綜合分析模型;其次選取了真實的電網告警數據進行實驗;最后通過對不同類別的告警數據進行多維度聚類降維,尋找到多維數據間的統計特征,最終通過壓縮率、噪聲率及準確率等指標對模型的聚類效果進行評價。實驗結果表明,本文所建立的模型可以快速準確地抽取出大量告警數據的統計特征,并對數據進行降維壓縮,在K-Means 的壓縮率、DBSCAN 的噪聲率及兩者結合的準確率上都有較好的表現,解決了現有告警系統數據雜亂、關鍵信息難以提取等問題,極大地提高了電網告警系統分析和處理數據的能力。
