基于TextCNN 融合模型的離散情感分析
2023-09-12 00:50:38陳秀明
科學技術創新 2023年21期
程 鋼,陳秀明*,于 翔
(1.阜陽師范大學計算機與信息工程學院,安徽 阜陽;2.臺州學院電子與信息工程學院,浙江 臺州)
引言
文本情感分析是自然語言處理中的熱門研究方向,又稱作文本挖掘。它的主要工作,是對網絡各種媒體消息材料、社會媒體文章,尤其是對帶有情感色彩的主觀性信息,進行提取、分析處理、整合和判斷。
情感表達由觀點持有者、評論對象、情感種類及評論時間等四要素構成。其中評論時間和文字發布時間保持一致,通常按網頁發布時間來確定文章持有者與評論對象的提取通常由命名實體抽取和語義角色分析等方式在文章中獲取; 而對于文字中所表達的情感種類分析,根據其目的內涵的不同而選取為不同的情感類種類,在體系上一般包括褒貶、喜怒哀樂悲恐驚、情感評分(列如1-5 分)等類型。
情感分析領域在國外已經有了十幾年的歷程,但是我國的研究卻剛剛起步。由于語言的差異,部分國外的研究技術無法轉化到中文處理中。所以,對于中文處理領域的專家們來說,如何針對中文語言的特點將某些較為嫻熟的技巧與手段應用到中文情感研究領域,是一個值得積極探索的任務。
1 方法介紹
1.1 Jieba 分詞與隱馬爾可夫模型
Jieba 庫的主要作用為分詞、關鍵詞提取、添加自定義詞典和詞性標注,并有精確模式、搜索引擎模式和全模式三種分詞模式。
隱馬爾可夫模型是一種概率轉化模型, 如表1 所示:一個人換下一份工作的轉換可能性[1]。

表1 隱馬爾可夫模型轉化舉例說明
1.2 LDA 模型
LDA 主題分類法主要是用于預測文章的主題狀況,LDA 認為文章可根據主題這么表示:
《美妝日記》{美妝:0.8,美食:0.1,其他:0.1}
假設我們要制作一個文本,它里邊的所有單詞產生的概率是[2]:
1.3 TextCNN 模型
與傳統圖像的CNN 網絡相比,TextCNN 在網絡結構上幾乎沒有任何變化(甚至更加簡單了),TextCNN 其實是一層卷積,就是一個max-pooling,然后再把圖像進行外接softmax 來n 分類[3]。
1.4 改進算法TextRCNN 模型
在TextCNN 系統中,整體網路架構使用了卷積層+池化層的架構,在RCNN 中,基于卷積層的特征提取的功能逐漸被RNN 所替代,導致整體架構設計上成為了雙向的RNN+池化層架構,又稱為RCNN[4-5]。
1.5 多頭注意力機制
多頭注意力機制即將輸入數據進行多次映射,每次使用不同的作為注意力機制輸入的查詢,以捕捉不同的表示子空間的特征,從而可獲得更全面、更富有表現力的表示結果,如圖1 所示。
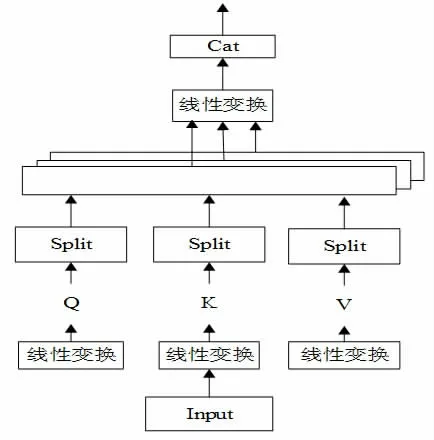
圖1 多頭注意力
2 實驗過程
2.1 數據來源
這里使用了阿里天池上的語料庫。共獲取了2500 條數據,并將原來的兩種情感,變為6 種情感:其中pos:開心pos1:信任neg:難受neg1:疑惑neg2:憤怒neg12:疑惑又憤怒,并將文件以純文字文檔進行保存。將其中的4/5 劃分為訓練數據,1/5 劃分為測試數據,表2 展示的是數據具體的分布情況[6-7]。

表2 數據分布情況
2.2 數據預處理
去除數字,字母,分詞,去除停用詞。由于數據集的內容經常會出現一些非中文與不用的字符以及標點符號等[8]。文本數據預處理后結果如表3 所示。
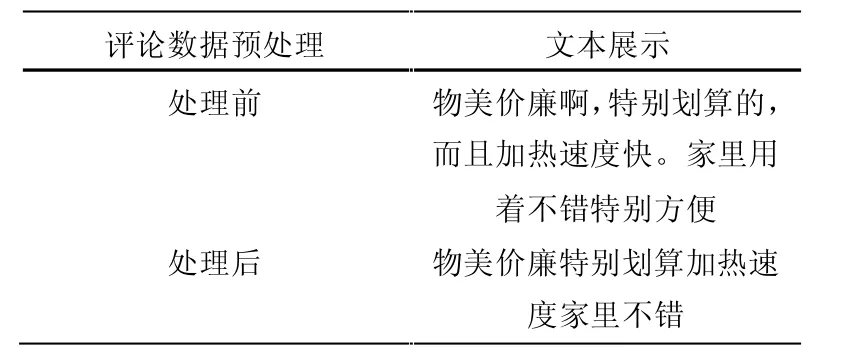
表3 數據預處理展示
2.3 舉例說明構建開心和疑惑又憤怒的情感的詞云圖[6]
快樂情感詞云見圖2,疑惑又憤怒詞云見圖3。

圖2 快樂情感詞云

圖3 疑惑又憤怒詞云
2.4 從每種情感的詞云圖中挖掘主題
各種情感的主體見表4。

表4 各種情感的主題
通過對比:開心的主題是價格和快遞方面,信賴的主題是物流價格與產品不錯,難受的主要主題是售后沒有免費,只免費了材料費,疑惑的主要主題是售后的態度比較差,憤怒的主要主題是安裝費,憤怒疑惑混合的主要主題是安裝收費這方面,因為這種情緒最為強烈,所以這種情感反應的問題也是最急切的。
2.5 實驗依據
采用分類精確率precision、召回率recall、平衡F分數f1-score 作為評價實驗好壞的指標,其表示方法如下:TP:將正類預測為正類數;TN:將負類預測為負類數;FP:將負類預測為正類數誤報;FN:將正類預測為負類數,如下依次表示為精確率P,召回率R,平衡F分數F1[9-10]。
2.6 實驗結果
TextCNN 各情感效果對比見表5,TextRCNN 各情感效果對比見表6,TextRCNN-Attention 各情感效果對比見表7。

表5 TextCNN 各情感效果對比
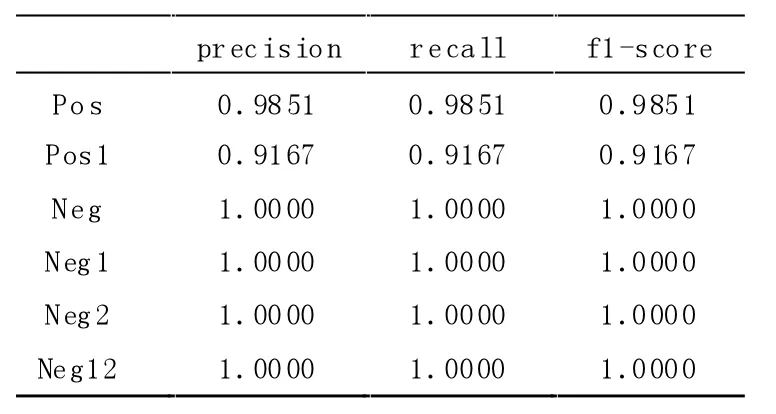
表6 TextRCNN 各情感效果對比

表7 TextRCNN-Attention 各情感效果對比
通過觀察TextRCNN-Attention 的預測效果較好。
結束語
為了數據背后的故事,對文本做情感分析是一種可行的方式,但它還是不能完全挖掘數據背后的故事。我國漢字博大精深,一詞能代表許多的意思,它涉及對詞匯、句法和語義規則的深刻理解,所以對情感的準確分析還有很長的一段路要走。在大數據背景下,自然語言的廣度和復雜度得到進一步的發展,同時也帶來了更大的挑戰,其發展仍需要很長一段時間,望砥礪前行。
猜你喜歡
中老年保健(2021年12期)2021-11-30 02:58:01
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
攝影之友(影像視覺)(2019年2期)2019-03-05 08:27:14
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
中華詩詞(2018年11期)2018-03-26 06:41:34
Coco薇(2016年8期)2016-10-09 02:11:50
