融合知識的小片段代碼相似性比較模型
2023-09-13 03:07:04龐建民
計算機工程與設計 2023年8期
夏 冰,周 鑫,龐建民+,岳 峰,單 征,3
(1.信息工程大學 網絡空間安全學院,河南 鄭州 450001;2.中原工學院 前沿信息技術研究院,河南 鄭州 450007;3.信息工程大學 嵩山實驗室,河南 鄭州 450007)
0 引 言
二進制代碼相似性比較技術廣泛應用于無源代碼軟件安全分析中[1],如bug搜索、惡意軟件分析檢測、補丁生成分析和軟件竊取檢測等方面。以OpenSSL(open secure sockets layer)統計分析為例,二進制代碼中小于5條指令的基本塊數量占比53%,不超過5個基本塊組成的二進制函數占比70.69%。這些較少基本塊組成的小片段代碼,由于攜帶指令序列較短,控制流程圖簡單,有限的語義信息使得當前二進制代碼相似性比較方案準確性差,因此如何提升小片段代碼相似性比較準確率對軟件安全分析具有重要意義。
軟件是人類在工作中用特定語言創造出來的,是人類知識得以延續的新載體。軟件知識并不隨軟件編譯優化和跨平臺的改變而改變,因此知識的穩定性、可重復性和可預測性[2]能準確反映代碼間相似性比較結果。基于該思想,在二進制代碼知識分析基礎之上,融合代碼中的函數嵌入和知識嵌入,提出一種二進制小片段代碼相似性比較模型BSM(binary snippet code similarity model)。
本文貢獻如下:①提出一種二進制函數代碼知識學習方法。方法將切分后的函數代碼知識看作單詞,基本塊序列上攜帶的知識序列看作句子,送入序列神經網絡得到知識嵌入;②提出一種融合知識嵌入和函數嵌入的二進制代碼小片段相似性比較模型。實驗結果表明,相較于當前最優的函數嵌入方案,模型可顯著提升二進制小片段代碼相似性比較結果,驗證集上準確率達到98.37%。
1 相關工作
1.1 二進制代碼
二進制代碼是指源代碼經過編譯鏈接后,可被CPU直接執行的機器代碼。編譯生成的二進制目標文件通常由多個二進制函數組成并按照線性地址LA(linear address)存儲。一段線性地址范圍可表示一個二進制函數F(binary function),如圖1“Add”函數LA范圍為0x00401410-0x004014C4。LA范圍內的機器代碼稱之為二進制片段代碼。為討論方便,本文將二進制函數F等價于二進制片段代碼。二進制函數F由至少一個基本塊BB(basic block)組成并在控制流圖CFG(control flow graph)作用下表達函數功能。CFG可用一個二元組(N,E)描述,其中N是有窮節點集合,每個節點表示函數內一個基本塊BB;E是邊集合,表示基本塊之間的“True-False”調用連接關系。二進制函數既可用線性地址LA上的指令序列表示,也可以用CFG表示,兩種表示是等價的。以“Add”函數為例,圖右上半部是函數線性地址的指令序列表示,圖右下半部是函數流程圖CFG表示。二進制代碼的線性地址序列表示和流程圖表示如圖1所示。
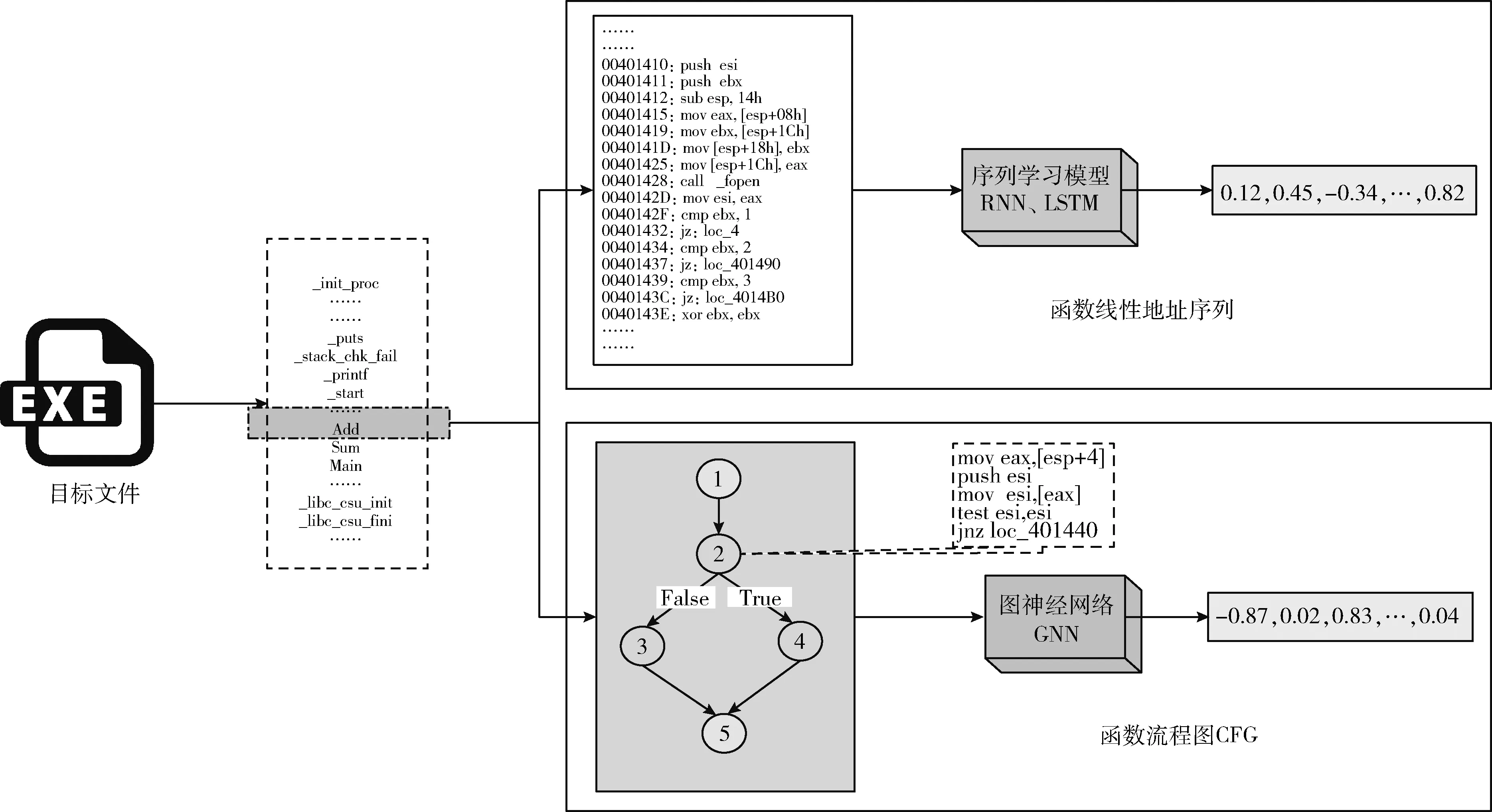
圖1 二進制代碼的線性地址序列表示和流程圖表示
本文將由較少數量基本塊組成的二進制函數稱之為小片段代碼S(snippet code)。小片段代碼S在二進制軟件中占比較高,以OpenSSL和Linux操作系統內核為例,基本塊數量范圍在[1,3]的函數數量分別占比二進制函數總量的56.60%和54.55%。基本塊數量范圍在[1,5]的二進制函數占比更高,分別高達67.84%和70.69%。基本塊占比見表1。

表1 基本塊占比/%
1.2 二進制代碼相似性比較
隨著自然語言處理和深度學習的興起,二進制代碼天然的線性地址布局為基于序列分析方案提供優勢,將線性地址上的指令序列喂入序列神經網絡模型得到函數嵌入向量,二進制代碼相似性計算就轉換為向量間比較。文獻[3]提出的αDiff方案對函數上的原始字節序列進行編碼生成函數嵌入;文獻[4]提出的ZEEK方案將二進制函數中的每個基本塊分割成多個串(strand)并向量化,利用全連接網絡判定兩個函數是否屬于同一類。文獻[5]在匯編指令級上捕獲連續基本塊內的程序行為集合并編碼為向量,采用基于樹的機器學習模型來預測兩個函數相似概率值。文獻[6]把指令看作單詞,基本塊看作句子,利用循環神經網絡RNN(recurrent neural network)實現基本塊間相似性比較。文獻[7]類似文獻[6]的思路,通過機器翻譯NMT(neural machine translation)技術實現基本塊間相似性比較。SAFE(self-attentive function embedding)方案[8]將函數指令序列喂入雙向循環神經網絡BRNN(bi-directional recurrent neural network)得到函數嵌入。文獻[9]將組成指令的操作碼和操作數看作詞,基本塊看作句子,基本塊間隨機游走路徑看作段落,加權不同路徑生成函數嵌入。
二進制代碼用CFG表示后,代碼相似性計算問題就轉換為圖相似性比較問題。Gemini[10]提出屬性控制流圖,采用人工方式抽取基本塊特征,利用structure2vec技術生成函數嵌入,但方案不考慮少于10個基本塊的函數;I2V(instruction 2 vector)[11]采用無監督方式生成基本塊嵌入,利用structure2vec技術生成函數嵌入,但方案將函數基本塊數量設置為150;文獻[12]提出指令依賴關系圖。文獻[13]融入語義感知、結構感知、順序感知等信息,使用BERT[14](bidirectional encoder representations from transformers)模型生成函數嵌入。
以上方案在基本塊較多的代碼上具有較高相似性結果,但是在小片段代碼比較上卻具有較低準確率[1,15]。由于小片段代碼指令序列較短,深度學習的不可解釋特性使得兩個不相似的小片段函數產生高度相似結果。同時,圖節點數量較少,節點間調用邏輯簡單,節點屬性可利用較少,再加上同一份源代碼可編譯到不同平臺上,因此需要引入穩定的外部信息,增強并提升跨平臺代碼相似性比較的準確性。
2 問題定義和函數知識學習
本章主要給出二進制代碼相似性定義,提出一種二進制函數知識學習方法。
2.1 二進制代碼片段相似性
兩個二進制函數F1和F2相似是指相同的源代碼s編譯生成的結果F1s和F2s是相似的,記作F1≈F2。 二進制代碼相似性挑戰在于編譯轉換過程的多樣性。轉換過程可利用不同的編譯器c如gcc、clang,可攜帶不同的編譯選項-O[0,1,2,3],可生成不同平臺(如X86、ARM)的二進制函數。
在指令、基本塊的表示學習實現上,可通過word2vec等詞向量生成模型將指令用向量表示;基于指令學習表示,將基本塊內的指令序列喂入RNN等序列學習模型后可得到基本塊嵌入。一旦得到指令嵌入或基本塊嵌入,函數可借助序列學習或者圖神經網絡學習生成最終函數嵌入。
2.2 函數知識學習
知識在軟件體上無處不在,通過開源或者版本更新等方式傳承下來。有經驗的軟件開發者,為了調試和調用方便,通常給函數取一個代表其功能含義的名字如SendData、Sort,并在函數內調用應用程序接口API(application programming interface)或者其它已實現的函數來加速實現軟件功能。這些函數名和API名,是軟件開發者將人類工作經驗通過語言賦能在軟件體上,清晰地表達了函數的高級語義功能。為描述方便,本文將函數名和API名統稱為函數名,將軟件開發者工作經驗稱之為函數代碼知識。
為保持函數命名風格一致,編譯器會對函數名進行特殊處理,如名為“_ZNSt22condition_variable_anyD2Ev”的函數,其中字符串_ZNSt22、D2Ev是編譯器在編譯過程中增加的內容。對于這些函數名,需借助第三方工具如cxxfilt、undname等,使其恢復為“condition_variable_any”。有經驗的軟件開發者通常采用兩種函數名命名風格。一種是首字母小寫,后面單詞首字母大寫,這種命名風格稱之為camelCase駱駝拼寫法(如setFlagWithResult)。一種是通過“_”分隔符將每個單詞拼接在一起,這種命名風格稱之為SnakeCase蛇形命名法(如Set_Flag_With_Result,即用下劃線將單詞連接起來)。函數名稱越長,攜帶的知識越多。
函數名稱太長不利于構建知識字典,因此需要進行知識切分。假定較長函數知識主要通過兩種不同的命名風格進行描述,分析其規律可使其長名字切分成多個token。如二進制函數內部調用了函數“Set_Flag_With_Result”和API“SetSockOpt”,該函數代碼知識切分后則有“set flag with result set sock opt ”7個token組成。這樣,通過少數常用token的組合可表達多個函數知識,如“set”出現在上述函數名和API名中。切分不僅能保持命名的不變性,又有助于構建知識字典防止OOV(out of vocabulary)問題出現。將函數代碼知識切分生成的token序列看作一行句子,借助word2vec詞向量生成模型,可將各個token知識轉換成向量表示。
這樣,函數知識學習算法流程描述如下:首先提取CFG上簡單路徑,路徑上的每個點代表基本塊;接著提取基本塊包含的函數代碼知識(如API序列、引用函數名);隨后將一條簡單路徑上所有函數代碼知識進行切分形成一個序列;最后,將序列看作句子,喂入詞向量生成模型得到知識學習表示結果。具體實現見3.4節。
采用簡單路徑提取、切分和學習函數知識,有下列好處:一是token序列形成的句子可反映某一執行時刻函數的動態特性;二是遍歷得到的所有執行路徑可以充分表達函數功能的全面性;三是每個token都能夠學習到函數知識序列的前后上下文語義,保持其命名的完整性。第4章實驗與結果分析表明,二進制代碼融合知識學習表示后,可顯著提升代碼相似性比較的準確性。
3 實現和訓練
3.1 整體方案
BSM模型整體方案由函數嵌入和知識嵌入兩部分組成。BSM模型結構如圖2所示。
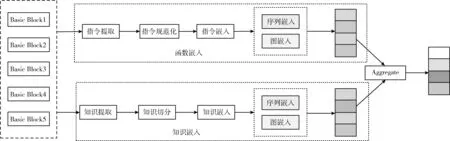
圖2 BSM模型結構

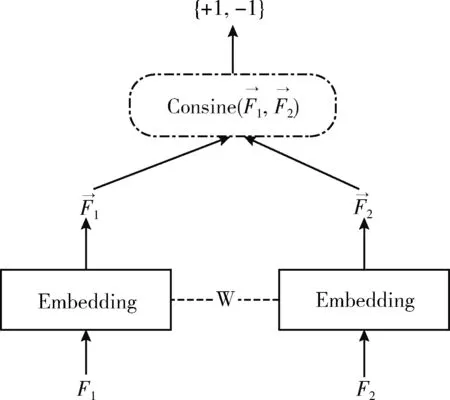
圖3 孿生網絡架構
3.2 數據集
類似Gemini、SAFE和I2V方案,本文采用OpenSSL作為基礎數據集。選擇OpenSSL1.1兩個版本(f、m)的源代碼,采用gcc編譯器并攜帶不同的編譯選項-O[0,1,2,3],分別編譯到X86平臺、ARM平臺上;接著利用Radare2逆向分析工具分別提取函數基本塊和函數代碼知識,將來自相同源代碼的兩個二進制函數定義為相似并標記為+1,形成一對函數。為保持數據集平衡,通過隨機方式構建相同數量的不相似函數對并標記為-1,共計得到401 050對X86平臺函數,900 490對跨平臺函數。
小片段代碼數據集是滿足一定條件的基礎數據集的子集。在小片段代碼數據集構建上,僅僅保留X86平臺基礎數據集中不超過3個基本塊的函數對、X86平臺基礎數據集中不超過5個基本塊的函數對和跨平臺基礎數據集中不超過5個基本塊的函數對,分別得到Dataset_A、Dataset_B和Dataset_C數據集。小片段代碼數據集見表2。
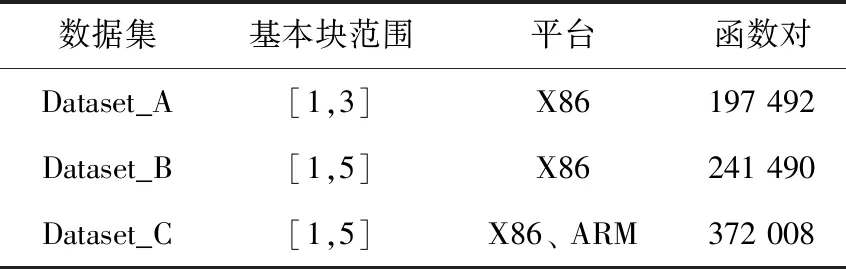
表2 小片段代碼數據集

3.3 基準Baseline
為便于分析對比,用BSMSAFE表示本文BSM模型是在SAFE函數嵌入基礎之上通過融合知識嵌入的方式得到。同樣,可得到對應的比較模型BSMi2v和BSMGemini。
同SAFE、Gemini、I2V一樣,將準確率作為衡量模型的對比標準。每訓練一輪,則在驗證數據集上計算當前驗證準確率Val Auc。如果當前驗證準確率最高,則進行測試數據集計算,得到測試準確率Test Auc。通過這種方式,得到每種模型的最優驗證集準確率Val Auc和最優測試集準確率Test Auc。
3.4 參數設置與訓練
為生成token向量,本文采用基于Skip-gram策略的word2vec詞向量模型將每個token轉換為向量形式。利用2.2節的方法對文獻[16]中提供的464個二進制文件,利用Radare2工具提取并生成二進制函數控制流程圖CFG后,借助NetworkX提取圖中簡單路徑,將其一條路徑上攜帶的函數代碼知識切分后看作一行句子。將生成的8400萬行句子作為數據集,喂入word2vec詞向量模型進行詞向量訓練,最終得到包含8756個token的知識詞向量詞典。word2vec全局參數設置如下:token詞向量設置為96維,滑動窗口大小設置為5,詞頻設置為5。
為做到在相同實驗條件下開展方案間對比,基于表2小片段代碼數據集,模型采用SAFE[8]提供的指令詞向量詞典和本文訓練得到的token知識詞向量詞典,將Adam作為優化器,均方誤差MSE(mean square error)作為損失函數。
4 實驗與結果分析
本章在單平臺序列表示學習相似性任務、單平臺圖表示學習相似性任務和跨平臺相似性任務上給出模型間比較結果。
4.1 單平臺序列表示學習相似性任務對比
本任務選擇Dataset_A作為數據集,從序列學習角度對比BSMSAFE和SAFE模型。在序列長度設置上,Dataset_A設置指令序列長度60,30個token知識(超出部分截斷,不足部分補齊)。指令序列學習模型采用攜帶注意力機制的雙向GRU,函數嵌入結果64維。模型訓練50輪,每批數據大小為250。基本塊范圍[1-3]序列表示學習模型間比較見表3。
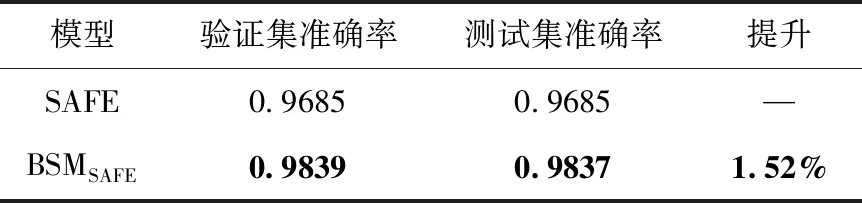
表3 基本塊范圍[1-3]序列表示學習模型間比較
從表3的BSMSAFE與SAFE對比來看,融合知識表示學習的BSMSAFE模型提升了準確率,在Dataset_A測試集上準確率高達98.37%。鑒于SAFE采用攜帶注意力機制的GRU方案,因此BSM同時對比了RNN、BiLSTM等序列神經網絡模型。與SAFE不同的是,這些模型不攜帶注意力機制。未攜帶注意力機制的序列表示學習模型間比較見表4。
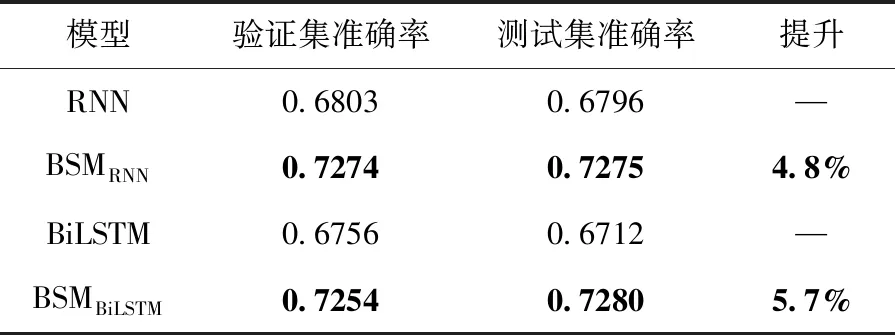
表4 未攜帶注意力機制的序列表示學習模型間比較
對比未融合函數知識表示的RNN和BiLSTM模型,BSM在Dataset_A上準確率分別提升4.8%和5.7%。同時進一步發現,攜帶注意力機制的BSMSAFE序列模型準確率在二進制小代碼片段上為98.37%,高于RNN模型30.4%。這說明注意力機制能夠聚焦二進制代碼相似性比較任務更為關鍵的信息,提升任務準確率。
4.2 單平臺圖表示學習相似性任務對比
本次任務選擇Dataset_B作為數據集,在X86單平臺上從圖嵌入學習角度,對比BSMGemini和Gemini模型,BSMI2V和I2V模型。圖嵌入訓練參數設置如下:基本塊指令序列最大長度為20,基本塊數量為5,函數最多30個token知識,函數嵌入結果64維,訓練10輪,每批數據大小為250。單平臺圖表示學習方案間比較見表5。
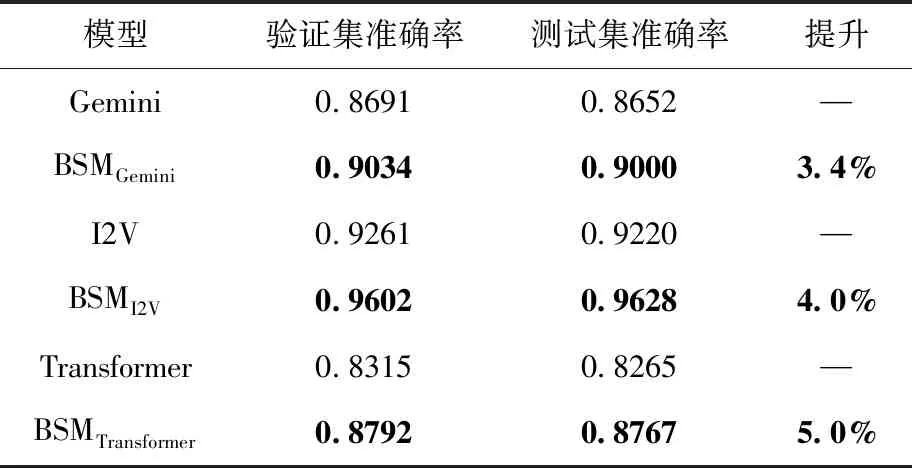
表5 單平臺圖表示學習方案間比較
如表5實驗結果所示,融合知識嵌入的BSM模型準確率均有顯著提升。BSMGemini模型準確率比Gemini模型提升3.4%,BSMI2V模型準確率比I2V模型上提升4.0%。Transformer作為當前比較火熱的編碼模型,本文也進行了對比,發現基本塊上采用Transformer編碼方案,在準確率上不如I2V采用的攜帶注意力機制的BiLSTM方案。分析其原因可能在于Transformer機制在于僅僅考慮注意力,而基本塊上的指令天然具有序列含義。也或許Transformer在編碼和解碼同時采用的時候性能最佳。這也進一步說明最優的、最先進的神經模型,還需要在二進制代碼相似性比較任務上給出最佳實踐。
對比表3和表5,發現序列學習表示模型優于圖嵌入表示模型,如BSMSAFE模型準確率高于BSMGemini模型8%,BSMSAFE模型準確率高于BSMI2V模型2%,說明利用節點鄰居更新節點表示的圖神經網絡GNN在簡單結構圖上并不足以捕獲函數豐富的語義。從表5發現,BSM未在Dataset_A數據集上做驗證比較。這是因為,數據集分析發現基本塊數量范圍[1-3]中,85%的函數僅僅攜帶一個基本塊,對于包含2個基本塊的函數可用一個序列表示,包含3個基本塊的函數最多表現為2條序列。
4.3 跨平臺相似性任務對比
為驗證函數知識不隨平臺改變而改變,代碼越相似性知識越穩定的特性,BSM模型在跨平臺相似性任務上分別對比SAFE模型、Gemini模型和I2V模型。即在跨平臺數據集Dataset_C上,從序列嵌入學習角度對比SAFE,從圖嵌入學習角度對比Gemini和I2V。模型全局參數和單平臺保持一致。跨平臺方案間比較見表6。
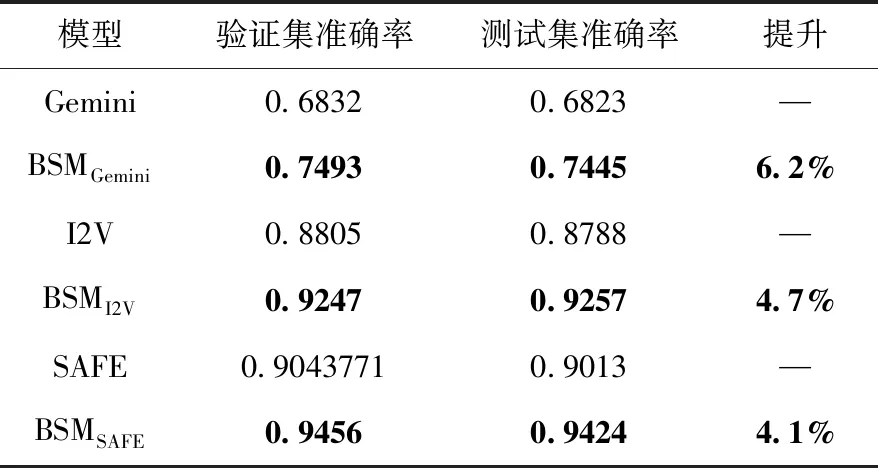
表6 跨平臺方案間比較
表6對比發現,融合知識嵌入的BSM方案在跨平臺上有較大準確率提升,BSMGemini在準確率方面優于Gemini方案6.2%,BSMI2V在準確率方面優于I2V方案4.7%,BSMSAFE在準確率方面優于SAFE方案4.1%。這說明知識的不變特性有助于縮小跨平臺指令帶來的語義鴻溝。
同時,對比表5和表6發現,融合知識表示學習的BSM方案在準確率提升幅度上跨平臺要高于單平臺,如BSMGemini和Gemini方案對比中跨平臺準確率提升是6.2%,單平臺提升是3.4%,說明知識不隨平臺改變而改變,相對指令巨大差異來講知識具有跨平臺穩定特性。
4.4 不同知識學習表示對比
將提取到的函數代碼知識分別從序列學習表示和圖學習表示角度生成知識嵌入,驗證不同知識表示學習方式給模型帶來的影響。在圖學習表示實現上,采用補齊或者截斷的方式,設置基本塊token知識序列長度為5,將其得到的基本塊嵌入利用structure2vec技術生成知識嵌入。在序列學習表示實現上,按照基本塊線性地址存儲順序提取函數代碼知識,并設置函數token知識序列長度為30(采用補齊或者截斷的方式),采用攜帶注意力機制的BiLSTM技術生成知識嵌入。經過實驗驗證,知識圖學習表示在提升模型準確率上不如知識序列學習表示,存在2%左右的差距。
綜上,3個任務實驗結果表明,本文提出的BSM模型對比基于線性地址序列函數嵌入和基于基本塊邏輯調用圖函數嵌入均表現出色,知識表示學習可提升二進制小代碼片段相似性比較結果,驗證了知識并不隨軟件編譯優化和跨平臺的改變而改變。融合知識表示可更準確反映代碼間相似性比較結果。
5 結束語
本文借鑒軟件攜帶并傳承人類知識經驗的思想,提取二進制代碼片段上的函數代碼知識,利用知識的跨平臺遺傳穩定特性,提出一種融合知識嵌入和函數嵌入的二進制代碼小片段相似性比較模型。在3個數據集上進行單平臺和跨平臺對比實驗,結果表明模型能提升小片段代碼相似性比較結果的準確性。當前本文函數代碼知識僅考慮函數名和API,作為軟件開發者工作經驗的知識還包括變量名、變量類型,因此,從二進制代碼中提取這些表達軟件開發者經驗的高級知識有助于代碼相似性比較。在下一步研究工作中,將借助調試信息預測[17]、函數命名推理[18]和多文件函數交互[19]等高級語義或語用信息,為完成代碼相似性、代碼搜索等下游任務提供知識增強服務。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年5期)2018-12-09 09:04:26
測控技術(2018年9期)2018-11-25 07:44:58
電子測試(2018年18期)2018-11-14 02:30:34
光學精密工程(2016年6期)2016-11-07 09:07:19
電測與儀表(2015年21期)2015-04-09 11:52:08
電機與控制應用(2015年1期)2015-03-01 03:49:19
