結合改進用戶聚類與LFM 模型的協同過濾推薦算法
2023-09-17 12:25:54顧明星張夢甜
科技與創新 2023年17期
關鍵詞:用戶
顧明星,張夢甜
(1.昆山市未成年人素質教育校外實踐基地,江蘇 昆山 215300;2.昆山市千燈中心小學校,江蘇 昆山 215300)
隨著互聯網的快速發展,信息量呈爆炸式增長,人類進入了“信息過載”時代[1],解決信息過載最有效的方法是搜索引擎和推薦算法[2]。傳統協同過濾算法主要是尋找與目標用戶有相似品味的用戶,然后將相似用戶喜歡的項目推薦給目標用戶[3]。但是隨著用戶、物品數量增加,數據稀疏性問題使得傳統協同過濾推薦算法在實際應用中面臨推薦準確性較低的問題[4]。
為了提高推薦算法準確性,眾多相關學者從多個角度出發,對協同過濾算法進行優化。例如文獻[5]從用戶相似性度量和評分預測2 個方面進行了修正,首先在相似度計算中引入用戶評分均值差,其次在預測評分時引入用戶評分均值,從而降低因用戶評分尺度不同對推薦結果造成的影響。文獻[6]提出將K-means與隱語義模型相結合的推薦算法,首先利用K-means算法對用戶進行聚類得到目標用戶所在的集合,其次重新構建評分矩陣,在新矩陣中利用隱語義模型預測用戶評分。文獻[7]提出了一種改進的LFM 矩陣分解推薦算法,通過在批量學習方法中引入沖量和中間動量并結合增量學習,提高了推薦算法的精度和尋優速率。文獻[8]提出了一種線性加權的推薦算法,為了降低用戶興趣隨時間變化的影響,引入TimeRBM 模型預測評分;同時,利用ItemAC 算法對項目屬性聚類、相同簇內的項目屬性值加權進行預測評分,最后將2 次評分融合得到最終評分。
上述改進算法能有效提高傳統協同過濾算法的推薦質量,但未能充分利用已有數據信息。因此本文提出了一種混合推薦算法,在傳統協同過濾推薦算法的基礎上,挖掘影響評分相似度的多個因素來提高計算的精度,再利用用戶屬性信息進一步改善預測效果。算法的核心思想如下:①利用改進相似度公式的協同過濾算法預測目標用戶對未評分項目的評分;②將改進的AP 聚類算法與隱語義模型相結合預測目標用戶對未評分項目的評分;③將前2 步所得的預測評分進行合理的線性加權,為目標用戶推薦前N個評分較高的項目。
1 相關工作
1.1 改進相似度的協同過濾算法(I_CF*)
協同過濾推薦算法的步驟是:先利用已有數據,構建用戶-項目評分矩陣,然后計算用戶之間相似度并選取近鄰集,最終進行評分預測并按照Top-N原則向用戶推薦[9]。算法流程如圖1 所示。

圖1 協同過濾算法流程圖
本文構建的用戶-項目評分矩陣Cmn,User:{u1,u2,…,um}為具有m個用戶的集合;Item:{i1,i2,…,in}為具有n個項目的集合;cij為用戶i對項目j的實際評分,若未評分,則cij記為0。矩陣Cmn如下所示:
傳統算法常用余弦相似性計算項目之間的相似度,余弦相似性將m個用戶對項目i和項目j的評分視作2 個n維向量,物品i和j的相似度則為2 個向量的夾角余弦值[10],如下所示:
式中:User為所有用戶集合;cui和cuj分別為u對i和j的實際評分的數值。
余弦相似性只是簡單根據用戶評分數值計算物品相似度,未考慮以下3 個因素:①評分網站對用戶打分的影響。例如有些網站的頁面布局規整美觀,用戶更愿意打高分;而有些網站的頁面布局差,用戶更愿意打低分。②項目本身屬性的影響。例如在電影評分項目中,電影質量較差的得分低,電影質量高的得分高。③用戶自身打分習慣的影響。有些用戶較寬容,普遍評分較高;有些則嚴格,普遍評分較低。
為了降低上述3種情況對項目相似度計算的影響,本文將對余弦相似性公式添加μ、bi、bu這3 個影響因子,改進公式如下所示:
式中:Uij為共同給i和j評分的用戶集;μ為所有樣本的平均分的數值,體現第一種影響因素;bi為i的平均分的數值,體現第二種影響因素;bu為用戶u的評分均分的數值,體現第三種影響因素。
根據改進的余弦相似性,目標用戶u對項目i的評分預測評分如下所示:
式中:pu,i為u對i的預測評分的數值;Gi為i的最近鄰項目集合;為項目i的平均分的數值。
1.2 改進的AP 聚類算法(AP*)
AP 聚類算法是一種基于數據點間“信息傳遞”的聚類算法[11]。首先,算法計算每一個數據點之間的相似度,構造相似度矩陣S;然后,根據相似度矩陣更新吸引度矩陣R和歸屬度矩陣A;最后,利用阻尼系數λ對矩陣R和矩陣A進行收斂直至最大迭代次數(一般取1 000)或聚類中心連續多次迭代不再發生改變(一般取50 次連續迭代)時終止計算[12]。
吸引度矩陣R的更新公式如下所示:
式中:Rt+1(i,k)為下一次迭代中點i和點k的吸引度值;S(i,k)為點i和點k的相似度值;At(i,j)為當前迭代中點i和點j的歸屬度值;Rt(i,j)為當前迭代中點i和點j的吸引度值。
歸屬度矩陣A的更新公式如下所示:
式中:At+1(i,k)為下一次迭代中點i和點k的歸屬度值;Rt+1(j,k)為下一次迭代中點j和點k的吸引度值。
根據阻尼系數λ對矩陣R和矩陣A進行收斂,公式如下所示:
式中:Rt(i,k)為當前迭代點i和k的吸引度值;At(i,k)為當前迭代中點i和k的歸屬度值。
原始AP 聚類算法中,在利用阻尼系數λ對矩陣R和矩陣A進行收斂的時候,若λ過大,會使原始算法收斂速度過慢,降低算法效率;反之λ過小則容易出現算法的震蕩,聚類難以收斂。因此,本文對λ的取值進行如下改進。
定義聚類增量率aug為每次聚類數量增長的變化程度,公式如下所示:
式中:Iter,i、Iter,i-1和Iter,i-2分別為本次、前一次和前2 次簇的數量。
定義震蕩頻數e:當aug>1 時,表示當前聚類的增量變大,算法出現震蕩。設定算法每迭代l次后,計算aug>1 的次數e,記作震蕩頻數。
為了避免由于震蕩次數過多而導致的算法無法快速收斂的情況出現,在算法每迭代次時,對阻尼系數進行一次更新,公式如下所示:
式中:λ′為更新后的阻尼系數;λ為當前的阻尼系數;?為λ的增長幅度,本文設置為0.01。
輸入:用戶-用戶屬性矩陣Q,阻尼系數λ=0.6,吸引度矩陣R和歸屬度矩陣A,迭代次數m=0,最大迭代次數t=1 000。
輸出:F個聚類。
在矩陣Q中利用余弦相似性計算每個用戶之間的相似度,得到用戶相似度矩陣S;初始吸引度矩陣A和歸屬度矩陣R為0 矩陣;根據式(4)、式(5)更新矩陣R和A;根據式(6)、式(7)對矩陣R和A進行收斂,m=m+1;ifm=50 then;根據式(8)統計震蕩頻數e;根據式(9)更新阻尼系數λ;l=0;until達到最大迭代次數或聚類中心連續多次迭代不再發生改變;得到F個用戶-用戶屬性簇并輸出。
1.3 LFM 矩陣分解模型
LFM矩陣分解模型[13]本質是利用矩陣分解的方式得到用戶與隱含用戶特征、物品特征之間的關系,將用戶評分矩陣Cmn分解為用戶隱特征矩陣Pmf與項目隱特征矩陣Znf,并且兩矩陣乘積會盡可能擬合現有評分數據,從而實現對未評分項目的預測。LFM 模型通過式(10)預測用戶u對項目i的評分。
式中:Pu為矩陣P中用戶u所在行;Zi為矩陣Z中項目i所在行。
最后優化損失函數得到P、Z矩陣:
2 結合改進用戶聚類與LFM 模型的推薦算法(I_ALFM)
針對傳統Item_CF 算法推薦準確性較低的現象,本文提出了一種結合協同過濾與用戶屬性聚類的混合推薦算法(I_ALFM)。算法從以下方面進行了改進:首先,算法利用I_CF*預測目標用戶對未評分項目的評分;然后,在用戶-屬性矩陣中利用AP*對用戶進行聚類獲得目標用戶所在簇,并在所在簇內使用LFM 預測目標用戶對未評分項目的評分;最后,將2 次評分結果進行線性加權,將加權后的評分值作為目標用戶對未評分項目的預測得分。評分線性加權公式如下所示:
本文算法步驟如下:①利用用戶-項目評分信息和用戶-屬性信息構建用戶-項目評分矩陣C、用戶-屬性矩陣Q;②在C中,利用I_CF*算法對目標用戶未評分的項目進行預測,得到第一預測得分;③在Q中,利用AP*算法對用戶進行聚類,得到目標用戶所在簇s,將簇s映射至矩陣Q中,得到簇s對應的用戶-項目評分矩陣Q′;④在矩陣Q′中利用LFM 模型對項目進行預測,得到目標用戶對未評分項目的第二預測評分;⑤利用式(12),將第一和第二預測評分進行線性加權得到第三預測評分;⑥根據第三預測評分,將預測評分最高的N個項目推薦給用戶。
具體流程如圖2 所示。

圖2 I_ALFM 算法流程圖
3 實驗結果及對比分析
3.1 數據集和評價指標
本文采用的是由GroupLens 提供的ml-100k 數據集[14]。數據集包含用戶與電影共10 萬條評分記錄,以及用戶屬性信息。本文將80%的數據作為訓練樣本、20%的數據作為測試樣本。
部分用戶-項目評分數據如表1 所示。
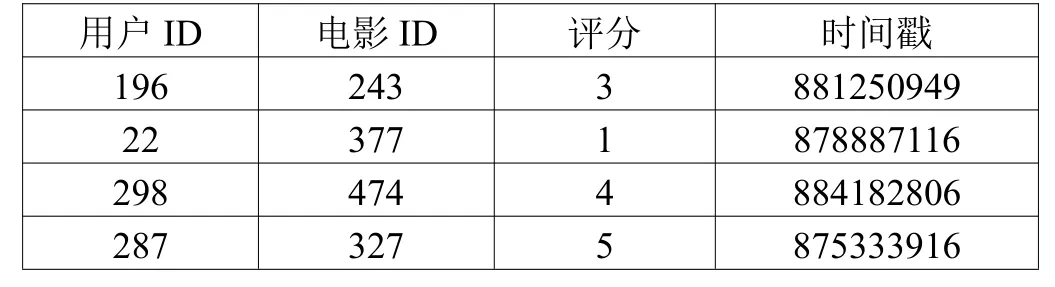
表1 用戶-項目評分數據
用戶-用戶屬性數據(部分)如表2 所示。原始數據集中,性別列男性用M 表示,女性用F 表示,因聚類需要,將M 替換為1,F 替換為0。
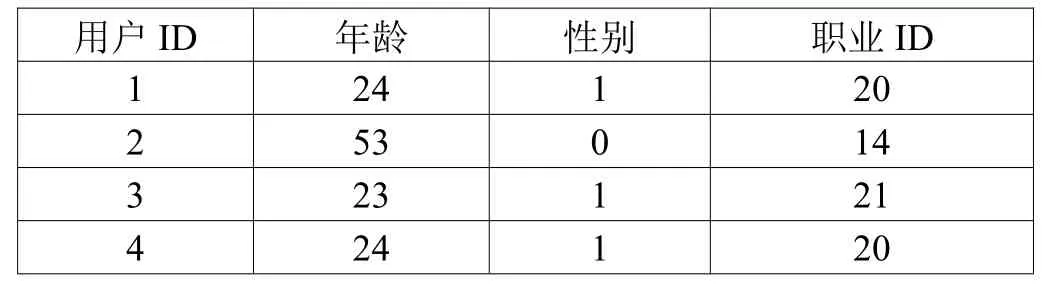
表2 用戶-用戶屬性矩陣數據
本文采用平均絕對誤差作為實驗的評價指標。平均絕對誤差是計算數據中已有的評分和實驗預測的評分之差來衡量算法的準確性,其值越小,則算法性能越好,公式如下所示:
3.2 實驗結果及分析
實驗1:用戶屬性特征聚類。實驗選取性別、年齡和職業作為用戶特征進行聚類,共劃分為10 個聚類,結果如圖3 所示。
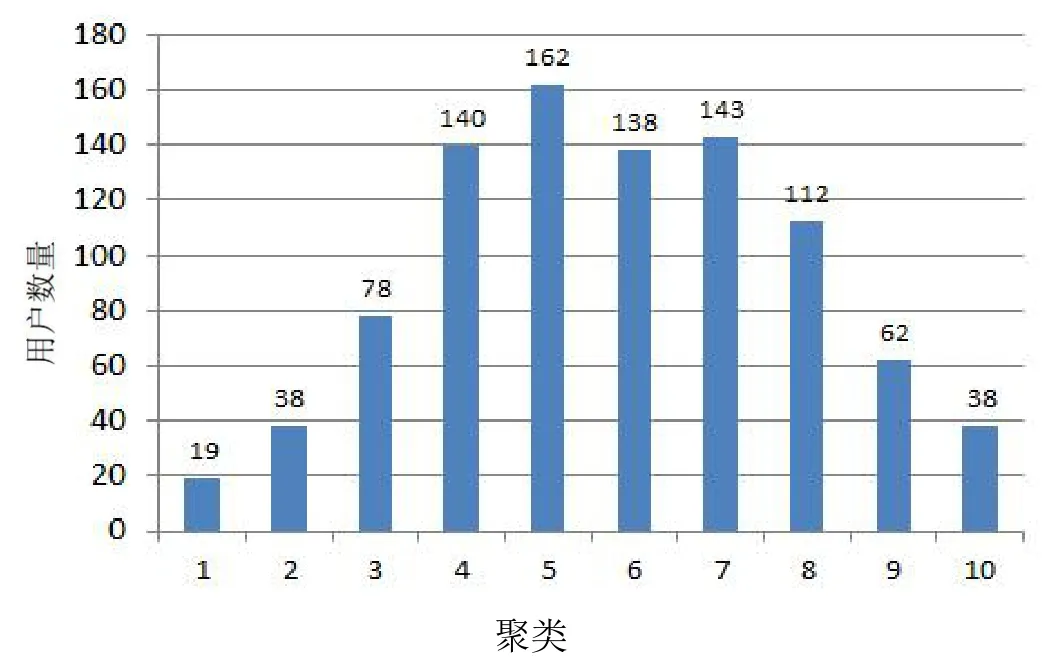
圖3 聚類結果
實驗2:選取最優加權因子。分別取α=0.1,0.2,…,0.9,計算平均絕對誤差來確定α和β的最優值。實驗將I_ALFM 算法重復運行10 次,取10 次實驗結果的平均值作為不同α值對應的平均絕對誤差值,實驗結果如圖4 所示。
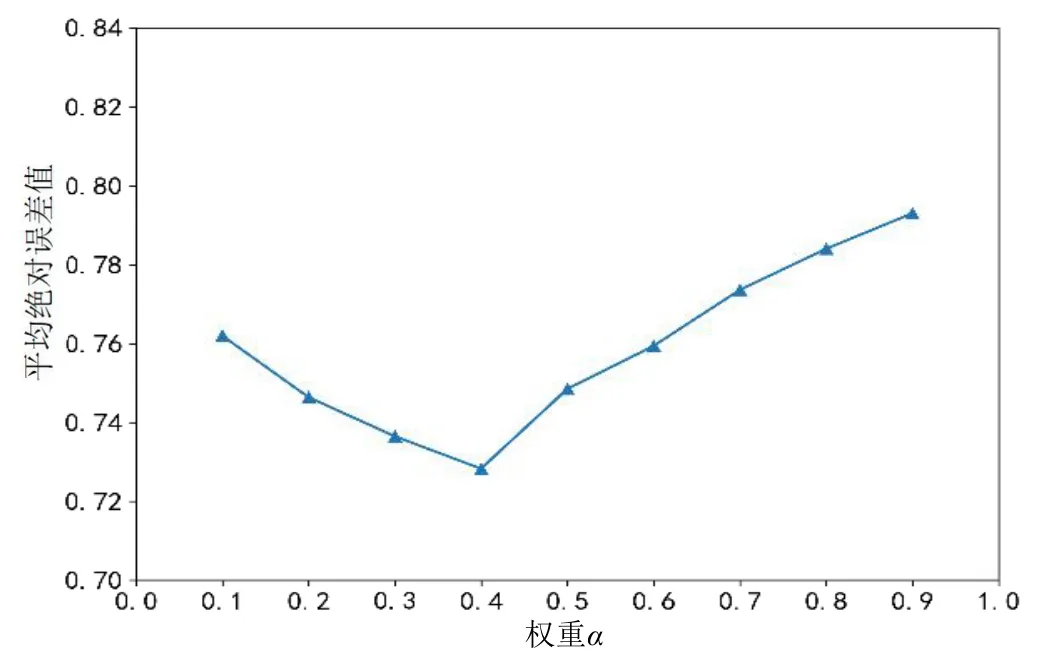
圖4 權值α對算法平均絕對誤差值的影響
由圖4 可知,當α=0.4 時,平均絕對誤差值為最小,表明此時算法的預測效果達到最優,故本文的最優線性加權因子為α=0.4,β=0.6。
實驗3:算法對比實驗。為了驗證I_ALFM 算法在推薦準確性方面的優勢,與基于項目的協同過濾推薦算法(I_CF),隱語義模型推薦算法(LFM)以及結合AP 與LFM 模型的推薦算法(AP_LFM)進行對比實驗,結果如圖5 所示。

圖5 不同近鄰數下各個算法的平均絕對誤差值比較
由圖5 可知,當最近鄰數k>30 時,算法的平均絕對誤差值基本上趨于穩定,且在實驗范圍內的近鄰數目下,I_ALFM 算法的平均絕對誤差值要低于其他對比算法。當最近鄰數為30~50 時,本文算法相比于I_CF,LFM 和AP_LFM 算法,分別降低了3.6%、2.2%和1.6%。
4 結束語
針對傳統協同過濾算法推薦質量不足問題,提出了一種混合推薦算法I_ALFM,算法通過線性加權的方式,將協同過濾算法、AP 聚類和隱語義模型的算法相結合。在協同過濾算法中,本文對余弦相似度公式添加3 個影響因子,提高了相似度計算的準確性;在AP 聚類算法中,定義聚類增量率和震蕩頻數,根據震蕩頻數的變化動態地獲取阻尼系數,提高了收斂效率。實驗表明,所提的混合推薦算法能夠挖掘隱含數據信息,提高推薦質量。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
