融合GA-CART和Deep-IRT的知識追蹤模型
2023-09-18 02:24:12何廷年李愛斌毛君宇
計算機工程與科學 2023年9期
郭 藝,何廷年,李愛斌,毛君宇
(西北師范大學計算機科學與工程學院,甘肅 蘭州 730070)
1 引言
在線教育系統通過練習和考試來收集學生學習過程中的交互信息,并利用收集的數據提供個性化教育。在這其中,教育數據挖掘是在線教育系統中不可或缺的一部分,而知識追蹤又是此領域中重要的研究方向。
知識追蹤的目標是通過分析學生的知識儲備以及知識狀態來預測學生對知識的掌握水平。知識追蹤問題可以描述為[1]:在練習集合Q={q1,q2,…,qn}中,通過學生與練習集合的交互操作,得到學生的觀測序列{x1,x2,x3,…,xn-1},通過對觀測序列的分析預測下次表現xn,通常xn={qn,rn},其中,qn表示回答的問題成分,也就是練習標簽;rn表示對應的回答是否正確,通常rn∈{0,1},0表示回答錯誤,1表示回答正確。
近年來,深度學習強大的表征能力,促使大量基于深度學習的知識追蹤模型涌現,極具代表性的有深度知識追蹤模型DKT(Deep Knowledge Tracing)[2]、動態鍵值記憶網絡DKVMN(Dynamic Key-Value Memory Network)[3]和深度項目反應理論Deep-IRT(Deep Item Response Theory)[4]等。DKT以循環神經網絡RNN(Recurrent Neural Network)為基礎結構[5],利用RNN中的隱藏狀態表示學生的知識狀態。DKVMN實現了對記憶增強網絡MANN(Memory-Augmented Neural Network)的優化,提出了使用鍵值對矩陣作為內存結構,鍵(key)矩陣是一個靜態矩陣,用來存儲題目的知識成分,值(value)矩陣是一個動態矩陣,用來存儲學生動態練習的知識狀態。
根據教育心理學中的成敗歸因論,學習者答題過程中會因為努力程度、身心狀態和心情等主觀因素而對答題結果產生一定的影響。傳統DKVMN模型未考慮到學生答題過程中的心理或行為特征對練習以及預測結果的影響,如答題過程中嘗試答題的次數越多,學生可能產生的消極情緒越復雜,因此對答題的正確率影響越大,甚至影響之后所有的學習行為。相反,答題過程中嘗試答題的次數越少,學生可能產生的積極情緒越多,因而答題的正確率越高。Sun等人[6]提出的加入決策樹的方法對行為特征進行預處理,有效提升了模型的預測概率,但分類與回歸樹CART(Classification And Regression Tree)所使用的分類規則容易導致算法的預測結果陷入局部最優的“陷阱”,遺傳算法GA(Genetic Algorithm)作為全局最優搜索算法之一[7],基于遺傳算法的CART優化算法(GA-CART)[8,9]可以有效改進傳統CART出現的局部最優問題,所以本文提出一種在Deep-IRT模型的基礎上加強對學習者行為特征預處理的方法,以提高模型的預測性能。
本文的主要工作有:
(1)使用基于遺傳算法的CART優化來對行為特征進行處理。這種方法可有效地對學生的行為特征進行個性化建模。
(2)將預處理優化后的模型與Deep-IRT模型相結合,提出了一種融合GA-CART和Deep-IRT的知識追蹤模型DKVMN-GACART-IRT。
(3)將DKVMN-GACART-IRT模型在3個公開數據集上與DKT、DKVMN、Deep-IRT以及DKVMN-DT模型進行對比實驗,實驗結果表明DKVMN-GACART-IRT模型預測性能具有優勢。
2 相關工作
2.1 DKVMN
在深度知識追蹤模型的發展歷史中,極具代表性的是DKT模型,但是其出現的可解釋性差、長期依賴問題和學習特征少的問題[10-18],使得大量基于DKT模型的改進方案不斷涌現。其中就有Zhang等人[3]提出的動態鍵值記憶網絡DKVMN,該模型使用一對鍵值矩陣作為內存結構。靜態鍵矩陣存儲的是潛在知識概念,而動態值矩陣存儲的是學生對概念的掌握程度。DKVMN采用離散的練習標記qt,輸出響應概率p(rt|qt),然后使用練習和響應元組(qt,rt)更新內存,其中x1(q1,r1)表示一次交互信息,一次交互信息中包含有學生的練習標簽q1以及答題情況r1。在每道題中包含有與之相對應的概念信息,即知識成分。一道題中可能有許多的知識成分,而這些知識成分在題目中的權重各不相同,這就需要用到注意機制來對每道題中的知識成分進行處理。這種采用鍵值對矩陣以及簡單的注意機制的知識追蹤模型,緩解了DKT因隱藏層單一向量空間導致的無法準確確定學生擅長或不熟悉的知識成分KC(Knowledge Component)的缺點。
2.2 Deep-IRT
Yeung等人[4]受貝葉斯深度學習的啟發,綜合了學習模型和心理測試模型對DKVMN模型進行改進,提出了Deep-IRT模型。Deep-IRT模型利用DKVMN模型處理輸入數據,并返回IRT模型中有心理意義的參數。DKVMN模型執行特征工程任務,從學生的歷史交互問答中提取潛在特征。然后,提取的潛在特征用于推斷隨時間變化的每個KC的難度水平和學生能力。基于對學生能力的估計和KC難度水平,IRT模型預測學生正確回答KC的概率[19]。Deep-IRT模型保留了DKVMN模型的性能,同時利用IRT模型為學生和題目難度提供了直接的解釋。Deep-IRT模型使基于深度學習的知識跟蹤模型具有可解釋性。
2.3 DKVMN-DT
CART決策樹具有不需要進行對數運算、計算開銷相對較小、適合大數據等特點,Sun等人[6]受其啟發,選用CART算法作為學生做題行為特征的預分類方法,提升了DKVMN模型行為特征預處理能力。
3 DKVMN-GACART-IRT
DKVMN-GACART-IRT模型結構如圖1所示,該模型將GA-CART與Deep-IRT相融合,即結合行為特征預處理和心理測量學模型,預測學生正確答題的概率。
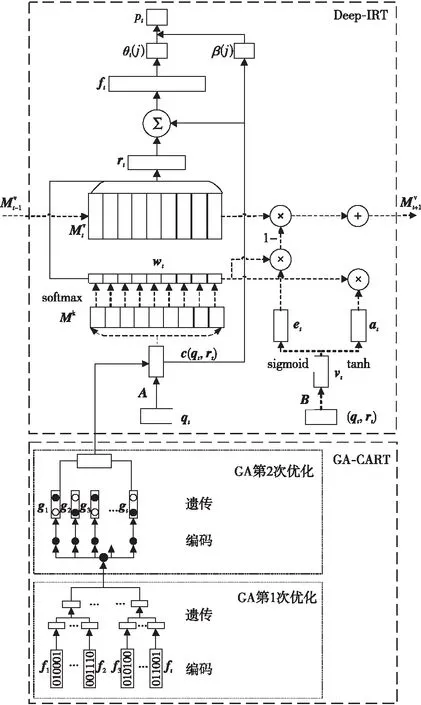
Figure 1 Structure of DKVMN-GACART-IRT model
3.1 行為特征預處理
數據預處理階段主要對嘗試次數、第1次響應和第1個動作等學生的行為特征進行基于遺傳算法的CART分析。本文基于遺傳算法的CART優化主要分為2步:第1步是對CART算法的上層進行GA優化,即將遺傳算法應用到特征分類中,從而找到最優的特征來提高分類精度;第2步是對CART進行GA雙層優化,即使用遺傳算法替代二分法,從而找到決策樹中的最優分叉點。
3.1.1 CART算法的上層GA優化
基于GA的CART上層優化主要是將遺傳算法應用到特征分類中,從而找到最優的特征來提高分類精度。
(1)編碼。本文采用二進制對所有個體進行基因編碼,基因串位數等同于特征數,即將特征表示為由0與1組成的二進制基因序列,相當于一個二進制一維數組,其中1表示個體中的某一特征被選中,相反,0表示個體中的某一特征未被選中。多個這樣的基因串組成初始種群,如圖2所示,a、b、c、d為一個種群,a表示一個染色體,即一串基因序列,1或0表示基因編碼。

Figure 2 Population
(2)適應度函數。遺傳算法通過適應度函數評判篩選個體,具有強適應性的個體中包含的高質量基因具有較高概率遺傳給后代,而具有適應性弱的個體的遺傳概率較低。本文中目標函數是以分類精度最大值為目標,故可直接利用目標函數值為個體的適應度值,準確率高的個體為最優個體。基于CART算法上層GA優化的適應度函數如式(1)所示:
fitness_s(xi)=acc_s(xi)
(1)
其中,xi表示種群中第i個個體,acc_s(xi)表示第i個個體xi在特征屬性中的分類精度。
(3)遺傳操作。遺傳算法的操作包括選擇、交叉和變異操作,選擇操作先計算每個個體的個體適應度值,然后計算每一代遺傳到下一代的概率以及累積概率,最后使用輪盤賭算法,被選中的個體進入子代種群。例如,通過計算圖2中4個個體的適應度值,根據式(2)得到每個個體的選擇概率{0.56,0.12,0.87,0.24},適應度值越大,該個體被選擇的概率也越大。
(2)
(3)
其中,L(xi)表示xi的累積概率,N表示種群的大小。
在選擇操作完成后,GA對選擇的個體進行交叉操作,如圖3所示,本文使用隨機多點交叉法,隨機選擇個體與另一個個體進行多點配對,并基因互換得到新個體。最后在個體中隨機挑選一個或者多個基因位的基因值完成變異操作,如圖4所示,其中,1表示保留特征,0表示舍棄特征。
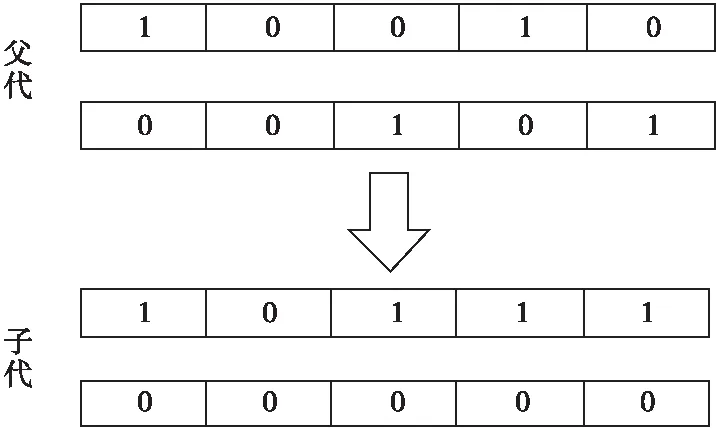
Figure 3 Random multipoint intersection
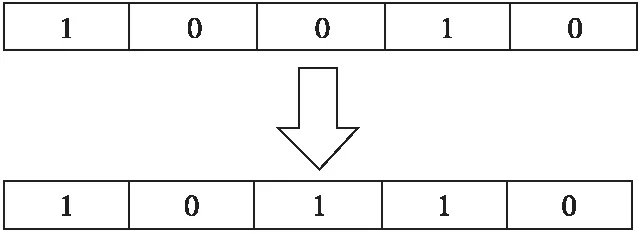
Figure 4 Gene mutation
(4)迭代終止。本文算法的迭代終止條件設置為100次。最終得到最優染色體。并通過該染色體確定其對應的最優特征。
3.1.2 CART算法的雙層GA優化
遺傳算法是全局優化算法,對于決策樹模型來說,它能夠找到最優的分裂點,取得最優的分類規則,從而進一步提升模型的分類精度。所以,本文利用雙層遺傳算法持續優化CART分類過程,以避免因CART算法中二分類過程所帶來的局部最優風險。基于GA的CART雙層優化主要是使用遺傳算法替代二分法,從而找到決策樹中的最優分叉點。根據基于GA的CART上層優化所得最優染色體,可以找到數據集的最優特征,即利用了較少的特征數據實現了高精度的樣本分類。而在第2次遺傳算法優化過程中,主要是針對經最優染色體選擇后的特征進行權重賦值,然后利用同樣的遺傳算法更新特征權重,并根據特征權重選取最靠前的3個特征,最后基于所選擇的3個備選分裂點進行建樹分類,實現樣本分類。
CART算法的雙層GA優化過程的適應度值定義為決策樹分類精度,如式(4)所示:
fitness_d(Dj)=acc_d(Dj)
(4)
其中,Dj表示數據集中的第j個特征,acc_d(Dj)表示利用第j個特征進行分類后的分類精度。
然后同樣通過選擇、交叉和變異操作,在決策樹的第1層特征中迭代尋優,迭代完成之后輸出最優的個體和最優的適應度值,算法終止。通過上述過程可以找到第1層的最優分裂點,之后每一層重復此操作便能生成決策樹。
本文利用基于遺傳算法的CART優化算法依據嘗試次數、第1次響應和第1個動作等特性對數據進行預處理[20]。將基于遺傳算法的決策樹分類器與知識追蹤模型DKVMN相結合,以提升底層模型對行為特征的處理能力。
3.2 交叉特征
通過預處理階段,學生的行為響應特征被轉化為決策樹的響應,如圖1所示,利用練習標簽qt與決策樹響應gt得到輸入向量,它表示每個學生的練習以及練習時行為特征信息的輸入,如式(1)所示:
c(qt,gt)=qt+max(q+1)*gt
(5)
其中,q表示最大練習數,qt表示學生t階段的練習標簽,gt表示學生的決策響應,即決策樹預測的結果,c(qt,gt)表示練習及其決策響應的交叉特征。
3.3 相關權重
相關權重主要體現在注意力權重wt上,即使用嵌入向量kt來查詢DKVMN模型中的Mk,查詢結果是對每個知識點關注程度的加權,表示練習和每個潛在概念之間的相關性,這個注意力權重wt是求得Mk和kt的內積后借助softmax函數激活得到的,如式(6)~式(8)所示:
wt=softmax(Mkkt)
(6)
kt=c(qt,gt)×A
(7)
(8)
其中,靜態矩陣Mk大小為N×dk,其存儲的數據為潛在的概念信息,也就是整個知識空間中N個知識點的嵌入表示,每個行向量對應一個知識點的嵌入表示;kt為嵌入向量;A為嵌入矩陣。
3.4 讀過程
讀過程主要通過分析概念信息對答題情況進行概率預測,如式(9)~式(13)所示:
(9)
(10)
θt=tanh(wθft+bθ)
(11)
β=tanh(wβc(qt,gt)+bβ)
(12)
pt=σ(3.0×θt(j)-β(j))
(13)
其中,γt為學生對練習的掌握程度的總結;將閱讀內容γt和輸入的練習特征Kt連接起來,通過tanh激活來獲得一個摘要向量ft,摘要向量內容包含學生對知識的掌握水平和問題的難度以及學習特征,矩陣W1和向量b1分別表示全連接層的權重與偏置;θt表示學生在t階段對所有知識點的能力,β表示所有知識點的難度,知識點難度通過交叉特征c(qt,gt)的嵌入計算得出,即題目中的學生能力水平越高,其解決問題的能力越強,反之,學生能力水平越低,其解決問題的能力越弱;wθ和wβ分別表示學生能力和知識點難度的權重矩陣,bθ和bβ表示對應的偏置向量。σ(·)是sigmoid函數,本文將學生的能力擴大3倍,這樣做是為了更加精確地預測,具體實驗細節見4.4節。最后得到標量pt,即正確回答qt的概率。
3.5 寫過程
根據艾賓浩斯遺忘曲線規律,人們對掌握的知識概念在一定的時段后會出現一定程度的遺忘。寫過程主要是根據學生回答問題后,對答案的正確性進行更新值矩陣操作。先將(qt,rt)嵌入一個矩陣B中,以獲得學生在完成本練習后的知識增長vt。寫過程主要包括2個主要操作,即擦除內存和增加內存。擦除內存表示學生對知識概念遺忘的過程,如式(14)~式(16)所示:
et=sigmoid(ETvt+be)
(14)
(15)
(16)
其中,et表示擦除內存向量;E表示變換矩陣;be表示偏置向量;vt表示學生在完成本練習后的知識點增長;動態矩陣Mv大小為N×dv,每個行向量表示學生對于知識點的掌握情況。
增加內存表示學生通過練習和回答問題對相關概念的知識掌握的更新,如式(17)~式(19)所示:
at=tanh(DTvt+ba)T
(17)
(18)
(19)
其中,at是一個行向量,即增加內存向量,D表示變換矩陣,ba表示偏置向量。
這種先擦除后添加的機制符合學生在學習過程中遺忘和強化概念的知識變化狀態。
4 實驗
4.1 數據集
本文在3個公開數據集ASSIST2009[21]、ASSIST2012[21]和Algebra 2005-2006[22]上對知識追蹤模型進行對比實驗。數據集詳情如表1所示。數據集ASSIST2009和ASSIST2012均來自ASSISTMENTS在線輔導系統,數據集Algebra 2005-2006來自KDD(Knowledge Discovery and Data mining)杯2010年教育數據挖掘挑戰賽,其中分為開發數據集和挑戰數據集,本文使用的是開發數據集。
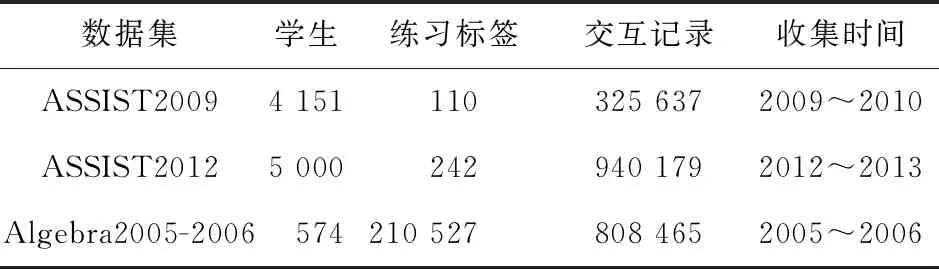
Table 1 Statistics of datasets
(1)ASSIST2009。由于存在重復記錄問題,官方發布了更新版本,本文使用更新后的版本進行實驗。實驗中的記錄數量使用的是Zhang等人[3]處理后的數據,共計4 151名學生回答325 637個練習以及110個不同的練習標簽。使用技能標簽作為模型的輸入。其中選擇做題次數、第1次響應、第1個動作和嘗試次數作為預處理階段的特征輸入。做題次數指學生完成一道題提交系統的次數。第1次響應指學生第1次響應的時間,單位為ms。第1次動作指學生第1次是否請求幫助。嘗試次數指學生嘗試練習的次數。
(2)ASSIST2012。由于該數據集較大,本文刪除了記錄數小于3的學生數據和技能標簽為空的數據,并從中抽取5 000名學生信息,最終處理后的數據包括5 000名學生回答940 179個練習以及242個不同的練習標簽,并用技能標簽作為模型的輸入。其中選擇是否要求提示、第1次響應、第1次動作和嘗試次數作為特征輸入。是否要求提示指學生做題過程中是否要求所有提示。
(3)Algebra 2005-2006。此數據集是從卡內基學習平臺收集的,包含574名學習者、210 527個練習標簽和8 008 465次學習交互。本文選擇提示響應、更正次數和機會次數作為特征輸入。提示響應指學生為步驟請求的提示總數。更正次數指學生對該步驟的正確嘗試次數,僅當多次遇到該步驟時才增加。機會次數指每次學生遇到具有所列KC的步驟時增加1次的計數。具有多個KC的步驟將有多個計數,由~~來分隔。
4.2 實驗參數及評價指標
4.2.1 實驗參數
模型中的學習率初始化為0.005,批處理大小為32,采用Adam優化器。此外,使用均值和標準偏差為0的高斯分布隨機生成的方法對參數初始化。迭代次數設置為100。遺傳算法中的參數設置如表2所示。

Table 2 Parameter settings in genetic algorithm
對于DKT模型,隱藏層大小從{10,50,100,200}中選擇。對于DKVMN、Deep-IRT、DKVMN-DT以及DKVMN-GACART-IRT模型,靜態鍵矩陣和動態值矩陣的維數也從{10,50,100,200}中選擇。本文還從{5,10,20,50,100}中選擇DKVMN、Deep-IRT、DKVMN-DT以及DKVMN-GACART-IRT模型的內存維度。為了減少參數數量,設置dk=dv。最后,在訓練集上使用5重交叉驗證法驗證模型準確度,并在測試集上評估模型性能。
4.2.2 評價指標
本文使用AUC指標來對知識追蹤模型的預測表現進行評估。AUC取值在0~1。其中AUC為0.5時表示其模型性能與隨機猜測一樣。AUC值越大,表示模型的性能越好。
4.3 實驗結果與分析
本文將數據集劃分為測試集、驗證集和訓練集3個部分,分別占30%,20%和70%,其中驗證集從訓練集中抽取得到。
參加比較的5個模型如下所示:
(1)DKT:以循環神經網絡為基本結構,將隱藏狀態解釋為學生的知識狀態。該模型成為知識追蹤領域使用最廣泛的模型之一。
(2)DKVMN:通過對MANN的改進,加入動態鍵值記憶矩陣來追蹤學生的知識狀態。
(3)Deep-IRT:以DKVMN為基礎模型,將IRT與深度學習相結合。
(4)DKVMN-DT:將CART應用于DKVMN知識追蹤模型預處理。
(5)DKVMN-GACART-IRT:將基于遺傳算法的CART優化算法和IRT項目反應理論與DKVMN模型相結合,提高了模型的預處理能力和預測準確率。
因決策樹對噪聲數據的易敏感,在這3個數據集上DKVMN-GACART-IRT和DKVMN-DT均出現了過擬合現象,通過剪枝后的實驗數據如圖5~圖7所示。
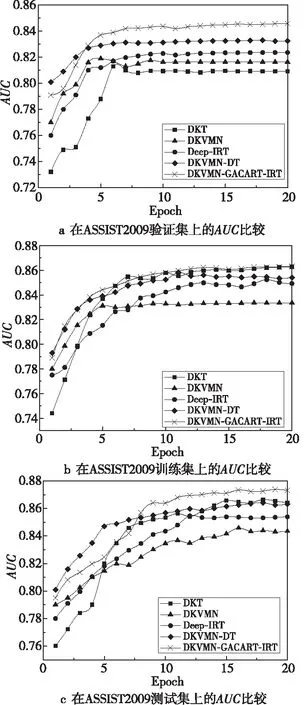
Figure 5 AUC comparison on ASSIST2009 dataset
4.3.1 ASSIST2009實驗結果
從ASSIST2009數據集中抽取30%數據組成測試集,其余70%數據組成訓練集,從訓練集中抽取20%數據組成驗證集,比較各個模型在該數據集上的AUC表現。如圖5a所示,DKVMN-GACART-IRT模型的AUC相比其他模型的雖無明顯提升,但曲率平滑,具有較好的穩定性。而在訓練集上,如圖5b所示,DKVMN-GACART-IRT模型隨著迭代次數的增加AUC表現較好。如圖5c所示,DKVMN-GACART-IRT模型的AUC表現穩定并與其他原始模型的相比有略微的優勢。
4.3.2 ASSIST2012實驗結果
從ASSIST2012數據集中抽取30%數據組成測試集,70%數據組成訓練集,從訓練集中抽取20%數據組成驗證集,比較各個模型在該數據集上的AUC表現。如圖6a所示,由于該數據集較大,所有對比模型前7輪迭代情況相近,而隨著迭代次數的增加,Deep-IRT模型與DKVMN模型的AUC表現相近,而DKVMN-GACART-IRT模型的AUC為77.08%,優于其他模型的。在訓練集上,如圖6b所示,DKVMN-GACART-IRT模型的AUC比Deep-IRT模型的高出3.1%、較DKVMN-DT模型的高出1.2%。如圖6c所示,DKVMN-GACART-IRT模型呈現出較大優勢,比DKVMN-DT模型的AUC高出1.48%,比DKVMN模型的AUC高出2.53%。
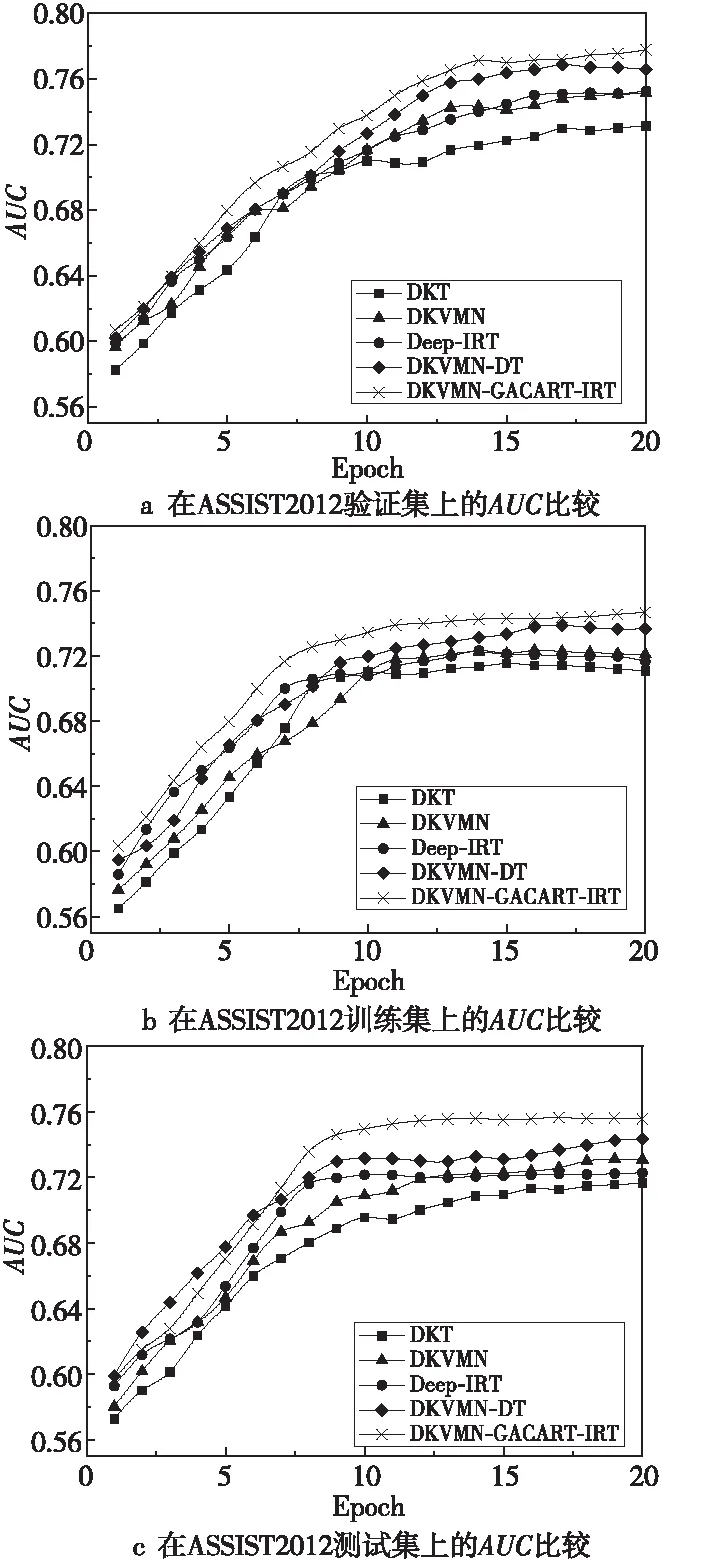
Figure 6 AUC comparison on ASSIST2012 dataset
4.3.3 Algebra2005-2006實驗結果
從Algebra 2005-2006數據集中抽取30%數據組成測試集,其余70%數據組成訓練集,從訓練集中抽取20%數據組成驗證集,比較各個模型在該數據集上的AUC表現。如圖7a所示,DKVMN-DT模型的AUC表現更好,而DKVMN-GACART-IRT模型與DKVMN-DT模型均優于其他模型。在訓練集上,如圖7b所示,DKVMN-GACART-IRT模型的AUC比Deep-IRT模型的高出3.8%、較DKVMN-DT模型的高出0.7%。如圖7c所示,DKVMN-GACART-IRT模型與DKVMN-DT模型具有相似的AUC性能,且都高于其他模型的AUC,但DKVMN-GACART-IRT具有更好的穩定性。
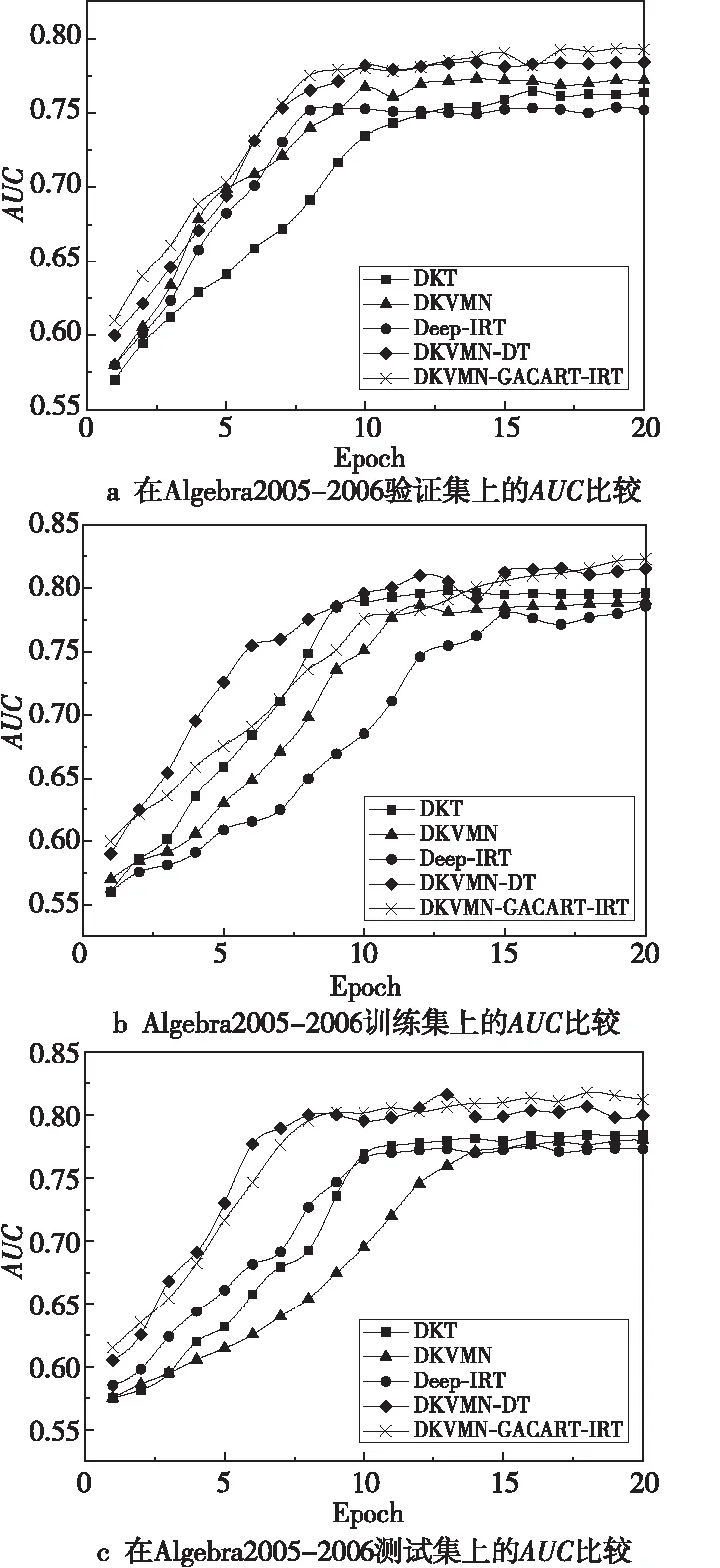
Figure 7 AUC comparison on Algebra2005-2006 dataset
DKVMN-GACART-IRT與經典模型DKT、DKVMN、Deep-IRT和DKVMN-DT的對比實驗結果如表3所示,可以看出,本文的DKVMN-GACART-IRT模型在ASSIST2009數據集上的AUC性能指標高達84.57±0.08,而作為基線的DKVMN模型的AUC達到81.63±0.07。DKVMN-DT模型的AUC達到83.23±0.1。DKVMN-GACART-IRT的AUC比DKVMN的高出2.84%,比DKVMN-DT的AUC高出1.34%。在ASSIST2012數據集上,本文模型的AUC達到77.01±0.06,比DKVMN的AUC高出3.9%,比Deep-IRT的AUC高出3.37%。而相較于DKVMN-DT模型的AUC高出1.99%。在Algebra2005-2006數據集上,DKVMN-GACART-IRT模型的AUC達到78.66±0.12。而DKVMN模型的AUC達到77.36±0.12,DKVMN-DT模型的AUC達到78.42±0.1。DKVMN-GACART-IRT的AUC比DKVMN的高出1.3%,比DKVMN-DT的高出0.24%。從以上數據可以客觀得出,本文所提出的DKVMN-GACART-IRT模型在3個公開數據集上均優于DKT模型、DKVMN模型、Deep-IRT模型及DKVMN-DT模型,表明本文所提出的DKVMN-GACART-IRT模型通過對學習者行為特征的預處理以及加入心理測量學IRT模型,提升了預測性能。

Table 3 AUC comparison of DKT,DKVMN,Deep-IRT,DKVMN-DT and DKVMN-GACART-IRT
4.3.4 消融實驗
本文模型包括基于GA的CART預處理模塊和心理測量學模塊2個主要部分,為了分析不同部分對知識追蹤預測性能的影響。本節在ASSIST2009數據集上進行消融實驗。本節設置以DKVMN為底層模型,與分別加入基于GA的CART預處理模塊和心理測量學IRT模型進行對比實驗,分析2個模塊對預測性能的影響,在ASSIST2009數據集的上實驗結果如表4所示。從表4可以看出,相較于DKVMN基線模型,加入基于GA的CART預處理模塊和心理測量學IRT模型的預測準確率都有一定提升。通過心理測量學IRT模型,增加底層模型讀操作中的可解釋性,預測準確率相較于DKVMN基線網絡有大約0.14%的提升。基于GA的CART預處理通過對學習者的不同行為特征進行分析,將預處理后的行為特征與學習特征交叉,相較于基線模型有 1.69%的提升。基于GA的CART預處理與心理測量學IRT模型的共同作用相較于基線模型提高了3.01%的準確率,說明本文模型在預測性能上更優。
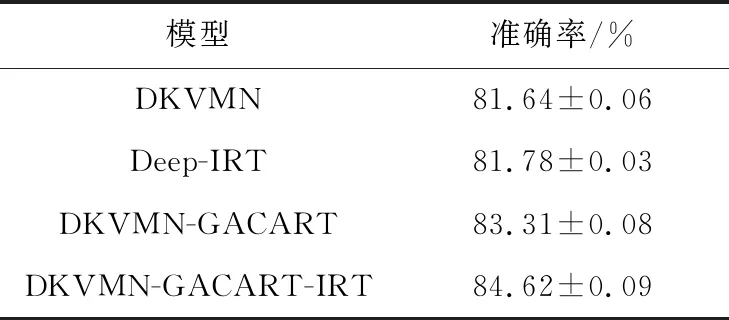
Table 4 Ablation experimental results on ASSIST2009 dataset
4.4 參數解析
本文3.4節中,在對學生答題情況進行概率預測時,將學生的能力擴大3倍,如式(13)所示,θtj的取值為(-1,1),βj的取值為(-1,1)。為了得到更加精確的預測,本節針對不同擴大倍數的學習能力在ASSIST2009數據集上進行實驗。在實驗中設置學習最小能力θtj≈-1,習題最大難度βj≈1,使pt逼近于0。設置學習最大能力θtj≈1,習題最小難度βj≈-1,使pt逼近于1。
實驗結果如表5所示。當學習能力擴大倍數為1時,預測最小概率pt≈0.119,最大概率pt≈0.881,AUC值為81.937%。當學習能力擴大倍數為2時,預測最小概率pt≈0.0474,最大概率pt≈0.953,AUC值為83.328%。從表5的結果中可以看出,pt的取值范圍過小。一方面,pt歸縮范圍較窄,不符合模型預測范圍;另一方面,這會導致預測結果模糊,使不同學生的學習能力無法精確拉開差距。
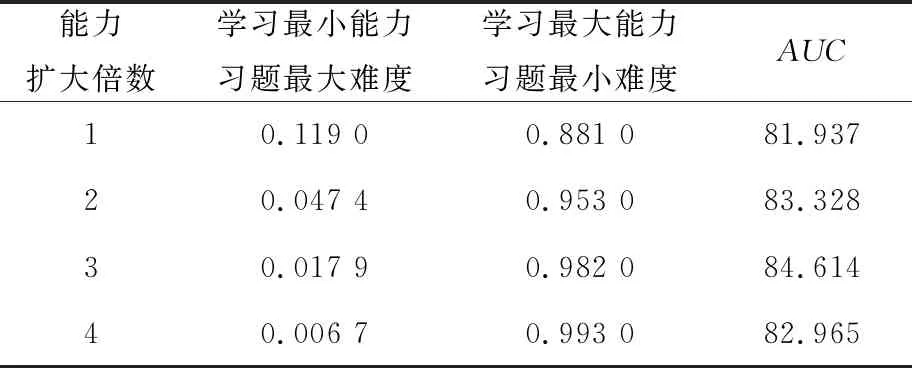
Table 5 Experiment of the expansion of learning ability
當學習能力擴大倍數為4時,預測最小概率pt≈0.0067,最大概率pt≈0.993,AUC值為82.965%。從表5的結果中可以看出,pt的取值范圍過大。原因有2個方面:一方面,學習能力是動態變化的,當學生學習能力產生微弱波動時,在較大倍數作用下會導致預測結果發生很大改變;另一方面,學生答題過程中難免會出現猜測和失誤的情況,參數倍數過大也會使結果與實際產生較大偏差。這些都會造成預測結果不精確。
綜上所述,本文通過針對學習能力擴大不同倍數的實驗后,在式(13)中使用擴大3倍的學習能力,使預測結果更加精確。
5 結束語
本文針對行為特征預處理對整個模型的影響,提出了一個將基于遺傳算法的CART優化算法與Deep-IRT相結合的優化模型。該模型通過GA-CART決策樹對學習者的行為特征進行預處理,即對特征信息分類篩選后再將特征向量融合到DKVMN底層模型中,而在DKVMN的讀過程中加入了IRT項目反應理論,保留了DKVMN模型的性能,同時能夠評估KC難度和學生的能力水平。本文所提出的DKVMN-GACART-IRT模型在3個數據集上分別與DKT、DKVMN、Deep-IRT和DKVMN-DT進行了對比實驗,在預測的預處理階段和讀過程中,既提升了預測性能又保留了對難度水平和學生能力的分析,也表明了本文模型在公開數據集上的有效性和可解釋性。在未來的工作中作者將從2個方向進一步開展研究:一方面,將不同年齡或者領域的學習者用戶畫像與知識追蹤相融合;另一方面根據教育心理學中的成敗歸因論,通過分析學習者的動態心理狀態提高模型預測能力。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
