海關大數據分析系統的研究與設計
2023-09-21 01:36:58王正剛
物聯網技術 2023年9期
王正剛,劉 忠,劉 偉,金 瑾
(1.中國科學院 成都計算機應用研究所,四川 成都 610041;2. 中華人民共和國成都海關,四川 成都 610041;3.中國科學院大學,北京 100049;4.成都信息工程大學,四川 成都 610103)
0 引 言
海關風險布控是海關入境檢疫和安全的重要保障,海關監管人員綜合各類風險信息數據,對照商品貨物報關單、艙單信息,分析商品貨物中可能存在的風險,依據經驗對某些高風險商品進行布控,進入人工查驗環節的過程。傳統風險布控流程智能化程度較低,風險分析和布控的標準無法統一,準確率和布控查獲率較低,無法滿足海量商品單證風險分析的需要。因此,迫切需要實現該工作流程的智能化和系統化,這一流程的智能化要解決海關表格數據的分類。對于數據分類問題,本質上是要構造一個函數,將連續型變量映射成離散型變量。假設D(X)是實例空間X上的一個概率分布,S是從眾多海關數據中抽取的訓練集,訓練集S中的每個實例都以概率分布D(X)從實例空間X中取得,x為S中的樣本。訓練集S被選中的概率P滿足如下公式:
海關智能化風險布控的目標如式(1)所示,根據訓練集S構造一個分類模型,預測實例空間X中實例的分類。假設c*是實例空間X的正確的分類函數,即對于任意的x∈X,c*(x)是它正確的分類。顯然,c*可以完全由集合{x∈X:c*(x)=1}確定。為了描述方便,可以令c*={x∈X:c*(x)=1}。然后,令h為由訓練集S構造的分類器,則分類器h的真正錯誤概率可以定義為:
式中,hΔc*={x∈X:h(x)≠c*(x)}是h和c*的異或集。同時,分類器h的實驗錯誤概率可以定義為:
根據海關數據的特點選用適當的分類模型,并將分類模型系統化,實現智能化風險布控是海關入境檢疫和安全的巨大進步。
1 應用系統結構
基于先進的B/S 架構即瀏覽器和服務器架構開發應用系統,由3 個模塊組成:Web 應用程序模塊、數據處理模塊、數據存儲與分類模塊。各模塊功能和數據流如圖1所示。

圖1 系統模塊功能框圖
將來自于H2010/H2018 系統、e-CIQ 下發庫、艙單管理系統的海關數據匯集到數據匯聚服務器中,通過數據的抽取、轉換、清洗、加載等處理過程,完成多種形式表格數據的轉化,并存入應用數據庫中。編寫Python 函數包,實現Python 與SQL 之間的調用,通過數據存儲和分類模塊對數據進行分類,并對系統的架構進行研究,實現較好的交互功能。
1.1 Web 應用程序模塊
Web 應用程序模塊的主要任務包括構建Web 頁面的上傳數據、模型選擇與分析、訓練過程、結果輸出等服務控件。從應用數據庫中提取數據文件,通過數據處理模塊的數據規則進行清洗,完成數據清洗以及語義替換后,根據文獻[1]所述完成模擬圖像轉化,將表格數據的處理轉化為計算機處理的形式。該模塊采用Deamweaver 10和Visual Studio 2012作為開發平臺[2],通過將Deamweaver與Visual Studio相結合,可以大大提高數據庫與Web 應用程序的集成效率,實現實時查詢和訪問更新數據庫的功能。
1.2 數據處理模塊
數據處理模塊需要完成不同來源、格式和特點的數據在邏輯上或物理上的集中,提供3 個主要業務數據庫,包含H2010H2018 報關單管理數據庫、e-CIQ 下發數據庫以及艙單管理數據庫的數據共享,運用ETL(Extract-Transform-Load)工具[3]實現不同數據庫之間海關數據的抽取、轉換和加載。ETL 的基本流程如圖2 所示。
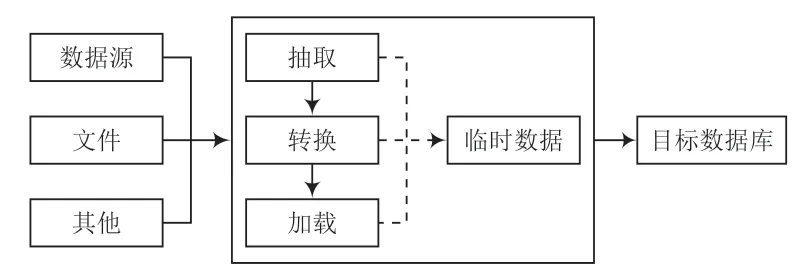
圖2 ETL 數據抽取和加工過程
1.2.1 增量數據抽取
抽取是在數據庫中抽取表中新增或修改的數據,抽取要求準確性和穩定性。準確性是能夠將業務系統中的變化數據按一定的頻率(系統設計抽取時間為12 h)準確地捕獲到;穩定性是不能對現有業務系統造成太大的壓力,影響現有業務開展。因此,從現實使用效率和整體虛擬機集群的穩定性考慮,海關大數據分析系統相關數據庫抽取選用增量抽取方式。
1.2.2 數據轉換
將從3 個源數據庫抽取的數據按照海關數據分類需求,對不同數據庫抽取的表頭、表體數據進行關聯,為每條單證構建一張包含全部數據字段的數據表格。對不滿足目的庫海關數據分類要求的數據進行數據轉換、清洗和加工,并對表格數據進行二維化,為神經網絡提供訓練數據集。
1.2.3 數據加載
將轉換和加工后的數據裝載到目的庫中是ETL 過程的最后步驟。由于目的庫是關系數據庫,因此采用批量裝載方法,運用sqlldr 等命令實現,采用這種方法進行的日志記錄是可恢復的,具備更好的可追溯性和可靠性。
1.3 數據存儲與分類模塊
數據存儲與分類模塊是海關大數據分析系統的核心組成部分。運用Python tensorflow 3.7 架構,通過“數據加載—模型加載—模型訓練和保存”3 個步驟,完成Resnet50[4]、Xception[5]、Mobilenet-V2[6]、BF-Net[1]等4 種網絡訓練模型的保存。該模塊包含4 種使用原始海關數據訓練完成的模型文件,以及在系統使用過程中對新抽取的海關數據進行訓練的模型文件,具備增量數據訓練功能和實時數據分類功能。網絡模型編譯由Python tensorflow 3.7 完成,為了實現Python 與SQL 之間的高效調用,我們對模型與數據庫連接的編程做了相應研究。
數據庫駐留表上的應用程序在盡可能接近數據的地方執行計算,通過對這些表的查詢來表示計算。由于這些計算內容是即時性的,并可能首先占用應用程序的堆棧空間,因此在編程時需要利用現代數據庫內核最新設計的數據處理能力,并避免提取太多具有一定規模的表內容。在數據庫編程的過程中,難以一直堅持這樣的規則,如果計算很復雜,大部分的應用程序就會用命令式的常規程序來實現。程序執行是在數據庫內核之外執行的,與數據存在一定的距離;然后,這些程序通過嵌入式SQL 查詢與數據綁定,并查詢、識別和提取與下一個計算步驟相關的數據部分。Python 解釋器和SQL 引擎的相互作用如圖3 所示。

圖3 Python 解釋器和SQL 引擎的相互作用
為了提升數據庫與網絡模型之間的交互效率,編寫Python 函數包,函數包包含while 嵌套和for 迭代,包括早期退出(break)、條件執行(if/else)、語句排序和變量引用/更新等命令式編程范式的特征結構。該函數包嵌入通過SQL語句發出的SQL 查詢等操作,實現Python 與數據庫之間的調用。任何編程語言和數據庫后端都存在連接和部署的問題。在本系統中,主要用到Python3 和Python3 的Psycopg2 和pymysql 庫[7],針對PostgreSQL 后端運用庫實現廣泛的數據庫部署。
如圖4 所示,PostgreSQL 從用戶輸入查詢到最后結果的輸出可以分為兩大部分:前臺處理和后臺執行。其中后臺執行又包含4 個部分:Parser、Rewriter、Planner、Executor。
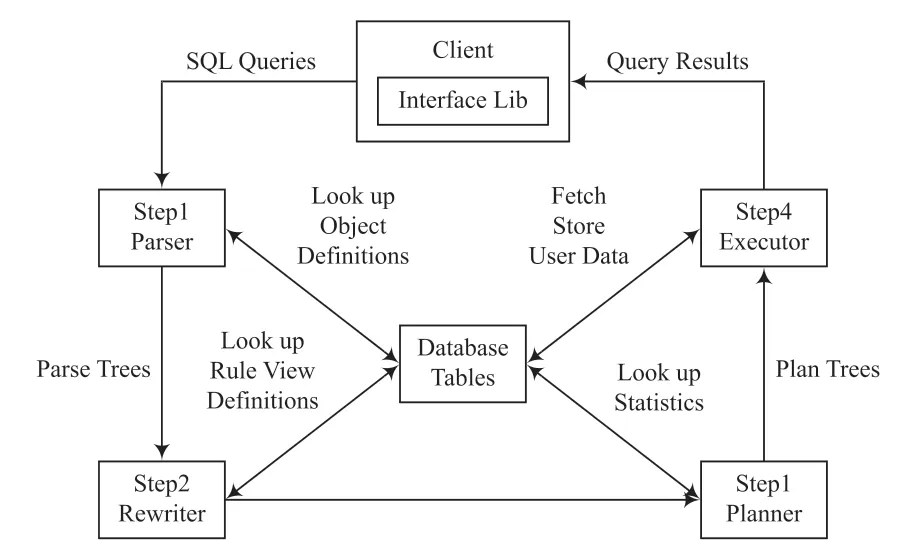
圖4 PostgreSQL 查詢
基于函數包的應用程序在運行時,其性能通常可以達到調用的效果[8]。每次調用函數包都會在Python 解釋器和SQL 數據庫引擎之間產生一個常量。執行由Python 端啟動,它遵循函數體的控制流。當嵌入式查詢SQL(Qi, [v1, ...,vn])時,數據庫引擎計劃查詢Qi(或從緩存中檢索以前構造的計劃),實例化計劃參數v1, ...,vn操作,評估計劃,然后將結果返回給Python 之前拆卸臨時計劃的數據結構。
圖3(a)描述系統反復地為Qi的任務觸發拆卸,如果SQL 查詢是迭代的,則代價比較大,一個函數調用往往會導致計劃和評估兩位數以上的SQL 查詢。基于函數包的方式可以有效地避免這種冗余情況,如圖3(b)所示。
由于數據分類任務的實時性要求,將復雜的計算駐留在數據庫系統[9]之外,采用函數包的編程方式實現Python 與SQL 之間的調用是非常有效的解決方案。
2 系統體系架構
海關大數據分析系統體系架構包含系統部署、系統數據和系統安全架構。系統部署架構如圖5 所示。

圖5 海關大數據分析系統部署架構
2.1 系統部署架構
應用和數據庫獨立部署在海關管理網Vmware虛擬平臺。數據庫獨立部署采用讀寫分離,同時采用獨立的存儲保障數據的安全,提高系統的穩定性和可靠性。
2.1.1 數據流
通過ETL(Extract-Transform-Load)工具對增量數據進行抽取,完成表格數據抽取、清洗、合并過程,再通過內網交換平臺匯聚到數據匯聚服務器,實現數據轉換,生成模擬圖像,并傳輸到數據庫服務器。應用服務器通過API 接口調用模擬圖像,進行海關數據分類識別,最后由系統計算每一條單證數據的分類結果。
2.1.2 可靠性
對海關大數據分析系統的應用和數據接口實現統一,對數據實現集中存儲。基于海關內網已有虛擬化平臺和服務器操作系統運行要求,該系統需兼容Vmware、KVM、QEMU等多種虛擬化平臺環境,同時適用于x86 和Linux 等不同架構的操作系統。
2.1.3 擴展性
針對海關風險管理部門對系統的擴展性需求,該系統預留水平或垂直擴展條件,以充分利用硬件系統的資源,滿足海關大數據分析業務場景擴展要求,提升系統對新出現表格數據類型的兼容性和適用性。
2.2 系統數據架構
海關數據信息主要包括海關管理的貿易態勢以及綜合業務、打擊走私、關稅征收、衛生檢疫、動植檢疫、食品安全、商品檢疫、口岸監管等業務信息。在數據架構設計時,以海關報關和艙單數據為主,充分考慮模擬圖像數據的處理和存儲,以及數據庫的使用性能,合理規避數據庫的瓶頸,以此對數據進行分類分庫處理。
2.2.1 數據管理
為抽取的數據建立統一的數據倉庫,數據倉庫支持數據服務管理和元數據管理,同時集成BI(Business Intelligence)工具支撐服務和組件,為元數據管理提供完整數據字典。數據倉庫根據數據的生命周期,考慮了數據訪問、數據傳輸、數據存儲到數據銷毀各環節的數據安全。
2.2.2 數據訪問
海關監管人員日常訪問操作需通過身份鑒別。數據庫管理員的運維操作均須雙因素認證,操作權限須經安全審批并進行命令級規則固化。系統會對違規操作進行實時報警。
2.2.3 數據存儲
所有數據均采用碎片化技術進行保存,將數據分割成眾多數據片段,并遵循不一樣的隨機算法將數據存儲在服務器上。
2.2.4 數據銷毀
采用內存釋放和數據清空手段在需要清除數據時對所有數據進行徹底刪除,數據庫管理員應對數據庫服務器和存儲情況進行實時監控。
2.3 系統安全架構
針對系統涉及的應用和數據資源開展定期備份,并定期巡檢備份日志和狀態。同時,為確保數據和網絡安全,需要對系統進行3 個方面的安全設計和管理:安全審計、訪問控制、數據加密[10]。對接入系統的設備進行統一管理,對登錄系統的用戶身份進行識別和管理;加強用戶權限的管理,實現特權用戶的權限分離;對所有系統運維人員的全部操作行為進行記錄;對物理資源和虛擬資源進行統一調度和分配。涉及對相關數據進行操作和使用時需要向相關業務主管部門進行申請審批。
2.4 系統軟硬件運行環境
系統運行的軟硬件環境為:Vmware 虛擬化平臺,版本號為VmwarevCenter6.7;承載虛擬機的物理機集群為聯想ThinkSystem SR850 +IBM V5000+EMC 存儲網關,分配3 臺服務器虛擬機資源用于該系統的部署維護。3 臺服務器配置見表1 所列。
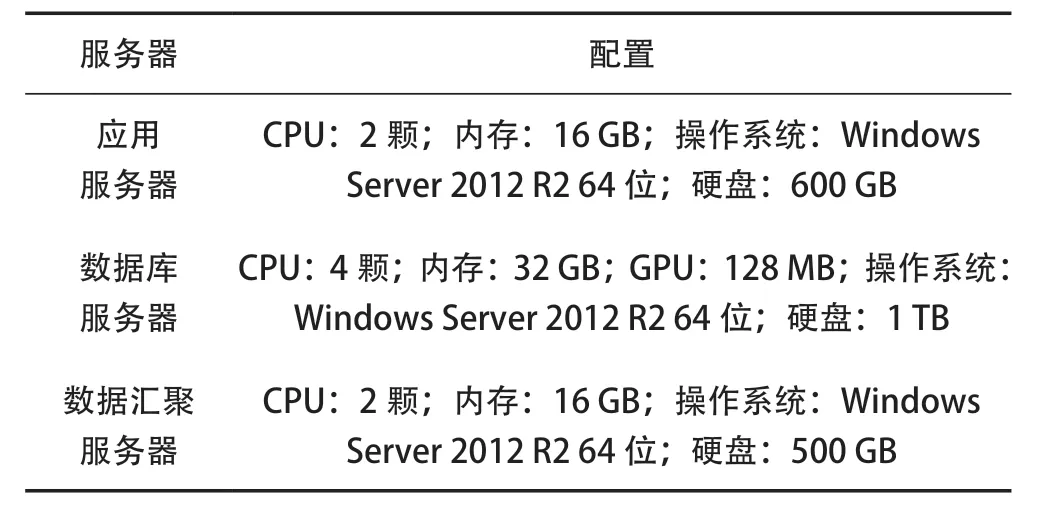
表1 虛擬機服務器配置參數
3 海關大數據分析系統
在傳統方式下,海關監管人員需要逐一對近期需要通關的每一單進出口商品特別是進口商品開展風險分析,下達風險布控指令,工作壓力巨大,且風險分析的效率和準確度較低。而風險布控的商品越多,一線海關查驗人員的查驗壓力也越大。依托海關大數據分析系統,海關監管人員只需要點擊分類的數據項,再在右邊“選擇模型&分析”欄目中選擇用于分類的神經網絡模型,點擊“訓練模型”,即可實現海關表格數據的自動風險分類。
海關監管人員依托該系統過濾掉大量的可以直接放行的低風險商品單證(一般情況下,1 000 條報關數據可以直接過濾掉800 條左右的低風險商品信息),大大提高了海關風險布控的效率。同時,根據高風險商品的分類信息下達相應的風險布控指令,進入查驗環節,由此基本實現了海關智能化風險布控。另外,海關監管人員還可以對不同模型的風險判別結果進行交叉驗證,根據國家政策調整和海關總署令的要求以及對外貿易的形勢變化,選擇嚴格或寬松的風險布控尺度,更好地實現人機交互。海關大數據分析系統如圖6所示。

圖6 海關大數據分析系統
4 結 語
本文提出用Web 應用程序、數據處理、數據存儲與分類等3 個模塊構建海關大數據分析系統。研究了應用系統體系架構,包括部署、數據、安全運維架構體系;分析了系統承載的軟硬件環境。海關監管人員應用海關大數據分析系統可以大大提高風險布控的精準度和效率,減輕一線查驗人員的負擔,實現海關智能化風險布控。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
