計算機輔助配棉技術研究進展
2023-09-25 11:21:28王夢蕾王靜安高衛東
紡織學報 2023年8期
王夢蕾, 王靜安, 高衛東
(生態紡織教育部重點實驗室(江南大學), 江蘇 無錫 214122)
在制造強國建設持續推進下,數字化、網絡化、智能化制造已成為紡織行業轉型升級的重要力量。全面加速行業數字化轉型,優化生產工藝,提高生產效益,實現精益制造,是紡織行業“十四五”發展綱要對紡織智能制造提出的重要任務[1]。作為棉紡廠的一項基礎工作,配棉決定的原料選配對穩定生產、保證質量[2]、控制成本至關重要,與原料采購及檢驗、產品試制與生產、企業管理與運維等工作息息相關。在傳統的生產模式下,配棉工作主要依賴于人工經驗完成。在產品品種發生變化,或當前配棉方案中部分棉種即將耗盡時,配棉必須考慮到原棉選擇的連續性、穩定性,以及企業產品特點、庫存情況、生產工藝、訂單情況、機臺狀況等各方面因素,實現優棉優用、差棉巧用,減少性能過剩、保持質量穩定、降低原料成本。但棉紡過程具有工序多、周期長、信息反饋滯后、生產連續性強等特點,使得人工配棉存在著一定的片面性和偶然性。
早在20世紀70年代,有研究者提出采用計算機輔助技術替代或輔助人工配棉,但受限于當時紡織產業較低的信息化水平,并未形成系統性的研究成果與推廣應用[3]。隨著原棉供應體系的信息化程度不斷提高,以及新一代信息技術的加速創新與推廣應用[4],計算機輔助配棉迎來了新的發展契機。目前,國內外研究者采用機器學習、啟發式進化算法等先進人工智能技術建立紗線質量預測模型和配棉最優化模型。這些研究成果一方面有效地根據配棉方案預測成紗質量,減少了紡紗生產中的試錯成本;另一方面在充分考慮原料成本與產品質量需要的基礎上,實現配棉方案的計算機輔助制定,緩解了配棉工作對人員經驗的依賴。隨著產業信息化程度的不斷提高,當前研究成果在模型準確性、高效性與泛用性等方面仍須進一步提升[5-7]。
本文首先簡要介紹計算機輔助配棉的系統框架及技術內涵;其次對計算機輔助配棉過程中的2個關鍵模塊—紗線質量預測、配棉最優化模型中所采用的核心技術進行綜述與問題分析;最后,從計算機輔助配棉的方法創新、產業數據規范與互聯2個方面展望進一步研究方向,為紡織生產科學化指導、精益化生產、信息化管理提供具有啟迪意義的參考。
1 計算機輔助配棉系統框架
計算機輔助配棉系統能夠結合企業產品特點、庫存情況、生產工藝、訂單情況、機臺狀況、市場行情等信息,根據企業產品質量管理與原料成本控制的需要,制定合理的配棉方案,其中核心技術模塊包括紗線質量預測及配棉方案制定。紗線質量預測是依據企業實際生產的歷史數據,建立原棉指標到紗線質量指標的映射模型如圖1所示。
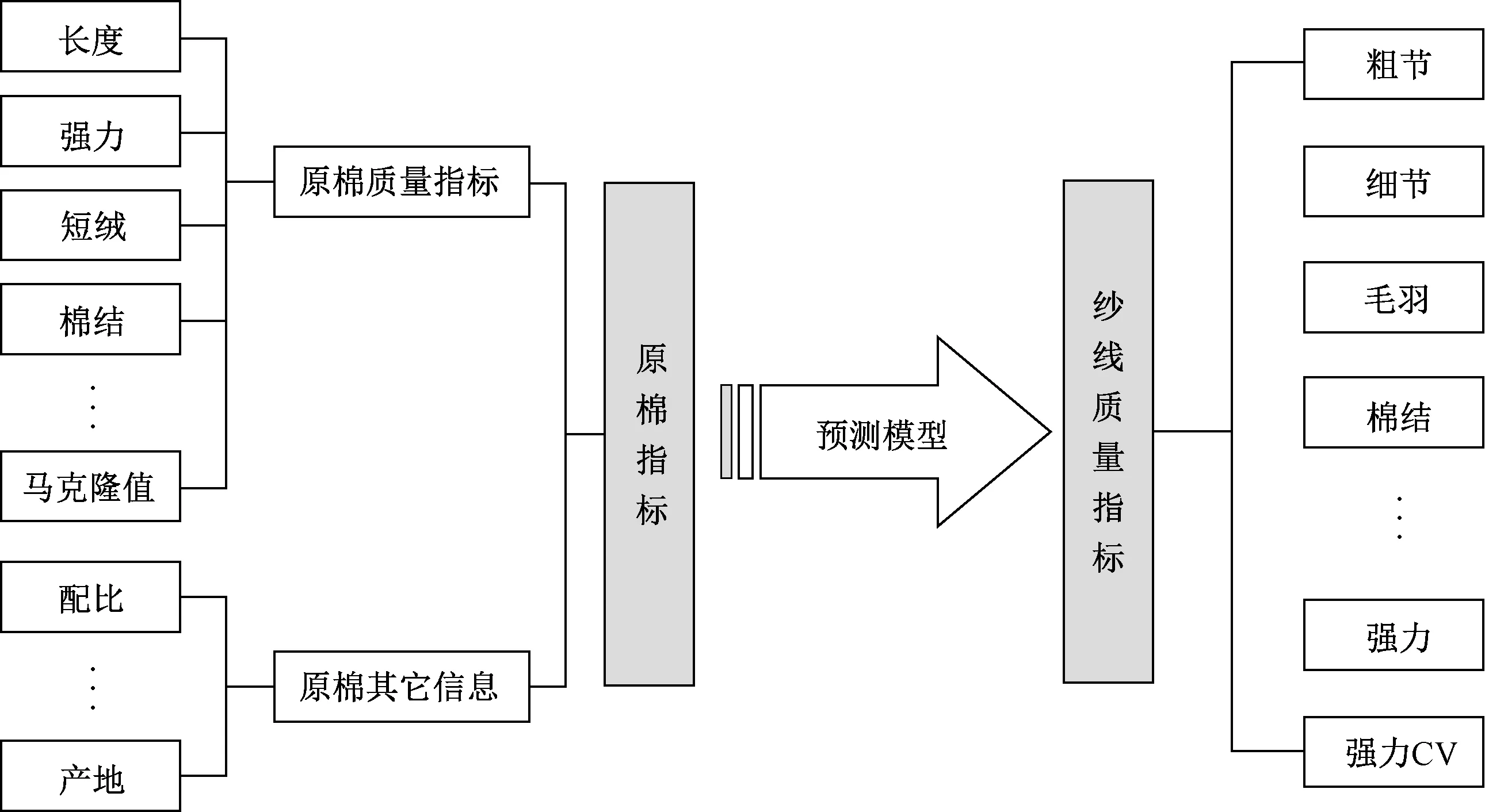
圖1 原棉指標到紗線質量指標的映射關系Fig. 1 Mapping relationship between raw cotton index and yarn quality index
該模型能夠從配棉方案預測紗線質量,用于從產品質量的角度評價各種配棉方案的優劣。目前,普遍采用的紗線質量預測技術包括人工神經網絡、支持向量機、線性回歸方法等。
在紗線質量預測模型的基礎上,建立配棉最優化模型,用于描述在特定生產需求下最合理的配棉方案,該模型包含目標函數、約束條件、求解算法。其中目標函數和約束條件可根據企業實際生產側重進行權重分配,在采用優化算法實現目標函數的最優化后,形成一系列推薦配棉方案,并顯示各方案預測得的紗線質量參數,以供配棉人員參考。
最終,圖2示出一套配棉技術管理決策支持系統[6,8-9],集成原棉庫存數據庫維護、紗線質量預測與管理、配棉方案的制定、配棉與紗線質量檔案4個功能模塊,以及供使用者查詢、維護與反饋的人機交互界面,滿足棉紡企業對于紗線質量管理、質量監督的需求,實現原料成本的控制、配棉方案的優化以及生產效益的提升。

圖2 計算機輔助配棉系統框架示意圖Fig. 2 Framework of computer aided cotton blending system
2 紗線質量預測模型
紗線質量預測的目的是從原棉指標預測成紗后的各類紗線質量指標,方法是建模原棉指標與紗線質量指標間的復雜的非線性映射關系。長期以來,國內外學者關于紗線質量預測開展了大量工作,主要采用的建模方法包括線性回歸、支持向量機、人工神經網絡等。
2.1 線性回歸
紗線質量預測是一種多元線性回歸建模問題。多元線性回歸預測紗線質量的步驟主要包括:原棉指標提取、線性回歸方程建立、回歸模型的參數估計、模型參數的估計值檢驗;最優回歸方程的確定以及模型的實際預測檢驗。其中,回歸模型的參數估計常采用最小二乘法;回歸模型的檢驗可包括擬合度檢驗、估計標準誤差、回歸方程的顯著性檢驗、回歸系數的顯著性檢驗。
由于線性回歸方程中的權系數直觀地表達了各原棉指標在預測任務中的重要性,使得線性模型具有很好的可解釋性;且模型形式簡單、易于建模。早期關于紗線質量預測的方法主要集中在線性模型上。儲才元等[10]采用相關性分析和多元線性回歸方法建立了原棉指標與紗線質量指標之間的映射關系模型。Krupincova等[11]基于棉纖維HVI(high volume instrumen)數據,同時考慮紗線特數和紗線捻度的影響,建立了從纖維、紗線結構參數預測紗線毛羽的線性回歸模型。繼而,Ureye等[12]則引入包括特數、捻度的紗線結構參數,以及粗紗性能指標,通過線性回歸預測紗線質量,并以方差分析技術檢驗了模型的顯著水平。上述研究表明,除了原棉質量指標,紗線規格參數以及由紡紗工藝參數決定的粗紗性能指標對紗線質量指標也存在影響。但由于原棉指標與紗線質量指標之間是非線性映射關系,線性回歸方法難以準確表達,存在較大的預測誤差。
2.2 支持向量機
針對紗線質量預測問題的非線性特點,有研究者采用支持向量機SVM(support vector machine)方法。SVM能夠使用核函數技巧將特征映射到高維空間,以實現對非線性問題的建模。SVM模型的參數求解能夠獲取全局最優,對樣本量的依賴度較低,泛化能力較強,在小樣本預測中表現突出。關于SVM方法的紗線質量預測研究主要集中在樣本數據處理、模型超參數優化、核函數改良上。
在樣本數據處理上,Doran等[13]采用主成分分析和方差分析對樣本數據進行降維,使用平均絕對百分比誤差、平均絕對誤差和相關系數來評估SVM模型的預測能力,研究結果顯示該模型在棉/氨綸包芯紗的質量變異系數和毛羽的預測上都表現出較高的準確率。王東平等[14]采用灰色關聯分析得到原棉成熟度、斷裂強度、均勻度等7個灰色關聯度最大的指標作為SVM模型的輸入,預測紗線的強力和條干CV,獲得了良好的預測結果。進一步地,項前等[15]的研究表明基于灰色關聯分析的SVM在小樣本和“噪聲”數據環境下仍能保持一定的預測精度,驗證了該方法的魯棒性。
典型的SVM包含若干超參數,如正則化項、核寬度。為選擇最佳的超參數組合,有研究者采用網格搜索法、交叉驗證法等傳統方法對模型參數尋優,如前文王東平等的研究[14]。此外,亦有采用智能算法進行超參數尋優的研究,如宋楚平[16]、呂志軍等[17]使用遺傳算法,有效提高了SVM模型的預測精度。
在核函數改良方面,Abakar等[18]建立基于Pearson VII核函數的SVM紗線質量指標預測模型,從棉纖維的強度、長度、含雜量等11個指標預測紗線強力,研究結果表明,與徑向基函數的SVM模型相比,該模型具有更高的預測精度。
2.3 人工神經網絡
另一類常用于紗線質量預測的機器學習方法為人工神經網絡ANN(artificial neural network)。人工神經網絡是由具有適應性的簡單單元(神經元)組成的廣泛并行互連的網絡,它的組織能夠模擬生物神經系統對真實世界物體所做出的交互反應。Hornik等[19]研究證明只需一個包含足夠多神經元的隱層,多層前饋網絡就能以任意精度逼近任意復雜度的連續函數。由于人工神經網絡強大的表示能力,在各類非線性預測任務中得到廣泛應用。目前在紗線質量預測領域,研究者主要從網絡結構設計和優化方法2個方面開展研究,以保障模型的預測精度和泛用性。最常見的神經網絡結構是多層感知機MLP(multi-layer perceptron)單隱層結構[20],隱藏層的神經元個數決定了模型的擬合能力。Mwasiagi等[21]構建了預測環錠紗斷裂伸長率的ANN模型,并研究了不同的網絡結構、權重/偏差學習函數、激活函數、反向傳播訓練函數和隱藏層神經元數量對模型精度的影響,獲得了一組最優的模型結構參數。查劉根等[22]提出了具有雙隱藏層的四層前饋神經網絡來預測棉紗成紗質量,進一步提高了前饋神經網絡在紗線質量預測時的精度和訓練速度。Hao等[23]研究了采用隨機向量函數鏈接神經網絡RVFLNN(random vector functional link neural network)預測紗線的不勻率,研究結果表明,RVFLNN有效地消除了多層神經網絡訓練過程過長的缺點,同時也保證了函數逼近的泛化能力。Turhan等[24]引入徑向基函數RBF(radial basis function)神經元計算結構進行模型改進,有效提高了網絡的預測精度。胡臻龍[25]提出通過增加網絡深度提升模型的擬合能力,為此將模型輸入參數構建成矩陣形式,引入卷積神經元結構,以在增加網絡深度的同時避免過多的模型參數;同時引入廣義回歸神經結構,建立了隱藏層數超過5層的卷積神經網絡CNN(convolutional neural network)模型,在避免模型“過擬合”的同時取得了性能的提升;為了緩解CNN模型對訓練數據樣本量的依賴,引入了對抗學習技術,實現數據樣本量的擴增。
通常ANN模型參數優化采用誤差反向傳播技術BP(back-propagation),利用梯度法進行迭代尋優。梯度法在搜索過程中優化方向可控,但是容易陷入局部最優,且模型超參數選取較為困難。為此,很多研究者提出采用群體智能算法替代梯度法。針對紗線質量預測問題,Zhang Baowei[26]、熊經緯[27]、項前[28]、王軍[29]、劉貴[30]、Amin[31]、Soltani P[32]、Hadavandi[33]等分別采用粒子群算法、遺傳算法、蝴蝶優化算法、灰狼算法來訓練ANN,研究表明這些群體智能算法均明顯地提高了模型訓練速度與預測性能[34]。群體智能算法雖然能夠在一定程度上避免模型陷入局部最優,但其優化方向不可控,局部搜索能力與穩定性欠佳。因此,有研究者提出將群體智能算法與梯度法相結合,通過混合訓練算法來優化ANN模型,實現兩者的優勢互補。Mwasiagi等[35]提出采用微分進化算法的全局尋優能力,首先在全局范圍求取ANN參數,繼而以此作為初值,利用Levenberg-Marquardt算法對參數進行局部尋優,獲得了模型預測精度與訓練穩定性的綜合提升。
2.4 紗線質量預測存在的問題
當前研究中采用的各類建模方法均屬于有監督機器學習模型,在實踐中表現出一定的預測效果。但有監督機器學習模型的訓練依賴于大量的數據樣本,以及有效的輸入數據特征表達。當前很多企業仍面臨數據采集不充分與訓練樣本不足的問題。
此外,當前研究中的預測模型未充分考慮配棉方案。在實際生產中,配棉方案中包含了各原棉的產地、批次、種類、配比等信息。但是,當前研究僅采用各原棉指標的加權平均值作為混合棉指標,再輸入模型進行預測,忽略了配棉方案中的大量信息,在一定程度上影響模型精度及實用性。造成該問題的主要原因是,當前研究所采用的機器學習模型只能輸入定長特征,無法對長度變化的配棉方案進行通用性的預測;同時如何從維度較高且長度變化的配棉方案提取有效的特征表達仍缺乏探討。
3 配棉方案制定
原棉的主要物理性質,如上半部分長度、整齊度、斷裂比強度、馬克隆值等與對紗線質量有很大影響[7]。棉紡企業關注的原棉指標也有很大差異,配棉時要根據產品需求、原棉庫存、原棉特點制定出原棉用量及混合比。
傳統棉紡企業使用的配棉方案制定方法是分類排隊法[36]和組合方案法[37]。分類排隊法是根據原棉的特性和各種紗線的不同要求把適合紡制某類紗的原棉劃分為一類,排隊即是將同一類的原棉,按照地區、性質、質量基本接近的排在一隊中,以便交替使用。最后與配棉日程相結合編制成配棉排隊表[38]。組合方案法是一種排列組合方法,即對多種可選原棉的多種可用混合比進行組合。早期的計算機輔助配棉工作,是將這種方法的操作流程數字化,由計算機查表輔助人工完成配棉,并未實現配棉方案的智能化制定。繼而研究者提出構建配棉最優化模型,結合實際生產需要制定約束條件,采用最優化方法進行求解。這種配棉最優化模型包括目標函數、約束條件及求解方法。
3.1 配棉目標函數
從企業的實際生產需要考慮,配棉方案應實現質量與成本的統一,研究者常采用2種目標函數來描述配棉目標,一種為原棉成本最小目標,一種為原棉質量成本控制目標。
原棉成本最小目標是指配棉方案中涉及的各原棉成本之和最小,可依據配棉方案中各項原棉的成本及其用量求得[39]。為了保證紗線質量達到指定要求且避免過剩造成浪費,研究者提出原棉質量成本控制目標。該目標通過限定混合棉的指標范圍來實現,即控制混合棉指標與標準棉指標間的差值最小,其中標準棉指標通過反向求解紗線質量預測模型的最優輸入獲取[40]。
此外,有研究者對原棉質量成本控制評價方法作了進一步改進。通過原棉指標與紗線質量指標的相關性分析,對混合棉指標進行賦權,即對混合棉指標影響紗線質量指標的程度進行評價,此方法能夠更好地描述原棉質量的成本控制[41]。
在實際建立配棉最優化模型時,研究者通常有2種思路:一是將原棉成本最小目標作為單一目標函數,質量成本控制作為模型中的一種約束[40];二是將原棉成本最小目標與原棉質量成本控制目標作為一類多目標問題進行優化[41]。多目標的優化通常采用優先等級法或加權系數法將其轉化為單目標進行求解。優先等級法是將各目標按照其重要程度賦予不同的優先等級,轉化為多個單目標模型再逐步求解。加權系數法是為每一個目標賦一個權系數,把多目標模型轉化為單目標模型,其難點在于權系數的合理化選定,通常是根據配棉人員的經驗確定[42]。
3.2 配棉約束條件
配棉的過程還需考慮紗線質量控制、原棉庫存控制、配棉總量控制等問題,因此配棉最優化模型中還需包含相應的各項約束,以滿足不同企業的生產與管理需求。當前研究提出的關于配棉最優化模型的約束條件主要包括以下幾種[40-42],可依據實際需求指定優先級。
紗線質量約束:根據配棉方案紡制的紗線各項質量指標需滿足產品需求。紗線各質量指標由紗線質量預測模型進行預測,模型輸入為混合棉質量指標。
配棉庫存約束:配棉方案中每種原棉的用量必須小于其庫存量。
配棉總量約束:配棉方案中單種原棉的總量可以不加限定,但要求各原棉所使用的總量必須與設定的配棉總量保持一致,或配棉方案中各批棉所占的比重之和為1。
配棉種類約束:為了方便快捷地調度庫存原棉,配棉方案中所使用的原棉種類不宜過多,最大種類數應小于設定的數量。
原棉品質指標約束:配棉方案中原棉質量指標平均值或者基于配比的加權平均值必須在規定的范圍內。即將上述配棉目標函數中的原棉質量成本控制的目標函數轉化為約束條件。
3.3 配棉模型求解
配棉最優化模型的求解是典型的多目標多約束非線性優化問題,無法采用線性規劃法實現快速求解,為此研究者普遍采用啟發式算法或機器學習技術進行求解。
1)啟發式算法。啟發式算法是一種基于直觀或經驗構造的算法,在可接受的計算時間和空間下給出待解決組合優化問題每一個實例的一個可行解,該可行解與最優解的偏離程度一般不能被預計。張增強[42]、Das S[43]、杜兆芳[39]等分別采用粒子群算法(PSO)、模擬退火算法(SA)、微分進化算法求解配棉問題的目標函數,研究結果表明,在保證紗線質量的前提下,啟發式算法有效地降低了原棉成本。圍繞所構建的配棉最優化模型的特點,研究者對典型的啟發式算法提出了一系列改進。例如,宋楚平等[41]通過改進遺傳算法的初始種群生成策略、遺傳算子和進化收斂條件,將配棉約束條件動態融合到種群進化過程中,在保證配棉約束條件的前提下,兼顧求解的效率和效果。陳懷忠等[44]采用慣性權重遞減和學習因子自適應策略改進粒子群算法,使得改進的PSO在配棉問題尋優過程中更快更精,局部和全局尋優能力都得到了有效提高。易文峰等[45]采用一種螢火蟲-粒子群混合算法對配棉問題進行求解,結果表明,混合算法的求解效率優于傳統的粒子群算法。
2)機器學習技術。機器學習技術是通過學習算法從配棉經驗數據建立優化模型,在面對新的紡紗需求時,制定新的配棉方案。Majumdar A等[46]通過使用人工神經網絡建立紗線到纖維的“反向”模型,采用所需紗線質量作為ANN的輸入,“反向”預測所需的混合棉指標,繼而使用線性規劃法對配棉方案進行最優化求解。
3.4 配棉最優化模型存在的問題
在目標函數與約束條件的構建上,當前研究圍繞實際生產對原棉成本、原棉庫存、紗線質量的需求提出了一系列方法,但具體目標與約束的選用及權重分配仍依賴于主觀判斷,尚未形成智能化模型構建方法。此外,當前研究采用的配棉方案表示方法均為混合棉質量指標,對變化原棉品種與配比的表示能力欠佳,導致模型對原棉種類及配比變化的優化求解能力受限。
在模型的求解方法上,啟發式算法強大的全局搜索能力表現出顯著優勢,但隨著原棉品種的增加與產品需求的豐富,此類方法的優化效率還需進一步提升。采用人工神經網絡“反向”模型的優化方法雖然能夠解決效率問題,但是靈活性和普適性不足。
4 計算機輔助配棉技術發展趨勢
隨著信息技術的不斷發展,計算機輔助配棉技術在效率和精度上都有了明顯地提升,未來可從以下方面進一步開展研究。
4.1 紗線質量預測
在建模方法上,當前研究圍繞模型結構與優化方法開展了一系列探索。隨著人工智能技術的不斷發展,更多建模與優化方法的創新將進一步提高預測模型的精度與效率。此外,當前研究采用的訓練與驗證數據還較為局限,隨著生產信息化程度的提高,采用更充分的實際生產數據對各類模型進行訓練與實踐驗證亦是一個發展方向。
在數據特征表達上,紗線質量預測模型的輸入包括生產工藝參數、產品規格參數以及配棉方案信息三類數據。前兩類數據均可向量化表達,但配棉方案信息結構復雜,當前研究普遍采用原棉平均質量指標或加權平均質量指標作為其特征,配棉方案信息表達不完整。未來,可尋找有效的配棉方案信息表達方法,包括各原棉質量指標、配比、產地、批次等信息的表達方法,結合預測模型結構的改進,進一步實現紗線質量預測的精度和效率的提升。如何選擇并引入生產工藝參數與產品規格參數也是重要的研究內容。
4.2 配棉方案制定
配棉方案的制定關鍵在于智能化的配棉最優化模型。在建模方法上,當前研究仍面臨個性化與普適性之間的矛盾,研究個性化需求的規范性建模形式可有效支撐技術的推廣,是未來的重要發展方向。另一方面,在原料品種不斷增加,產品需求復雜度不斷提高的背景下,當前普遍采用的啟發式算法的效率面臨巨大挑戰,構建兼顧效率與精度的優化方法將是未來的研究熱點。
目前配棉研究的對象普遍針對紡紗廠自身庫存。若將原棉庫存與市場數據聯通,一方面能夠增加原料選擇面,提高配棉方案的綜合效益,另一方面可基于配棉工作科學地“反向”指導原棉采購。但這也必將帶來問題復雜度的增加,當前方法難以直接適用。未來研究可借助深度強化學習技術,建立高效智能化配棉策略模型,或可先解決原棉采購方案優化問題,再整合至配棉最優化模型中。
4.3 產業數據規范與互聯
計算機輔助配棉技術的適用性很大程度上取決于原棉數據的規范性,以及對個性化數據的通用表達。如何從配棉與生產實際需要出發,構建更具通用性的原棉標準化指標,并針對不同企業的個性化需求建立原棉指標的篩選及表征方法,是進一步的研究方向。
隨著產業數據的規范化與通用化,計算機輔助配棉系統將在產業互聯平臺中成為原棉供應與紗線用戶間的媒介,發揮重要的供需調配作用,促進解決精準購棉和精確用棉的行業難題,實現原棉供應、紡紗生產、產品用戶的宏觀統籌,為構建智慧工廠體系打下基礎。
5 結束語
計算機輔助配棉系統既為棉紡企業穩定生產、保證質量、控制成本提供可行方案,也為紡織行業降低人員依賴、提高生產效益,實現精益制造提供新思路。此外,計算機輔助配棉系統圍繞對原棉大數據的深度運用,一方面持續推動原棉質檢的標準化發展;另一方面有望加速推動紡織產業的智能化轉型升級。目前,計算機輔助配棉系統研究仍然處于發展階段,隨著大數據與人工智能技術的不斷進步,未來研究有望在以下方面取得實質性進展:
1)在紗線質量預測的方法上,構建更具通用性的原棉標準化指標,針對企業個性化生產模式建立原棉指標篩選及配棉方案特征表達方法,改進預測模型結構與模型優化算法,進一步提升模型的預測精度和泛用性。
2)在配棉方案的制定上,一方面研究具有普適性且兼顧個性化生產需求的配棉最優化模型,同時探索更具準確性與高效性的優化方法,另一方面將原棉庫存與市場數據聯通并引入最優化模型中,增加原料選擇面的同時,“反向”指導原棉采購。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
