基于集成學習及電阻層析成像的兩相流流型辨識
2023-09-26 04:17:52張立峰
動力工程學報 2023年9期
張立峰, 肖 凱
(華北電力大學 自動化系,河北保定 071003)
隨著我國工業不斷發展,對兩相流監測日趨重要。兩相流系統在電力、化工和石油等工業部門廣泛存在。兩相流根據構成系統的相態分為氣液兩相流、液液兩相流、液固兩相流和氣固兩相流等。氣液兩相流是各類兩相流中最常見、最復雜的兩相流動體系之一,氣液兩相流作為一種非平穩過程,其狀態的變化具有時變性、非線性和隨機性等復雜流動過程的特點,這些因素導致對氣液兩相流的狀態檢測十分困難[1-2]。流型是氣液兩相流最基本的特征參數,因此其他參數的準確測量需要依賴于對流型的了解,對兩相流流型的準確辨識具有重要意義[3]。
電阻層析成像(Electrical Resistance Tomography,ERT)是一種用于連續流動相為導電介質的兩相流可視化檢測方法,其原理為根據不同介質的電導率特性,通過測量敏感場邊界信號,反推內部電導率分布圖像,從而得到介質分布狀況[4],其具有非侵入、結構簡單及實時性高等特點[5]。
基于ERT的流型辨識方法可分為2類。一類是基于ERT重建圖像進行流型辨識:仝衛國等[6]提出一種基于Landweber迭代圖像重建算法和卷積神經網絡相結合的流型辨識方法,該方法先利用電容層析成像技術對管道內的氣液兩相流進行圖像重建,然后建立卷積神經網絡模型,對重建后的流型圖片進行分類,從而達到流型辨識的目的;翁潤瀅等[7]采用壓差傳感器對不同流型的壓差信號進行采集,在時頻分析后將其轉換為時頻譜圖,然后采用卷積神經網絡對時頻譜圖進行分類從而實現流型辨識。另一類則是利用ERT系統測量值,基于信號分析或特征提取結合某種分類方法進行辨識[8]:李凱鋒等[9]利用主成分分析法提取ERT測量數據,再通過K-均值聚類算法對泡狀流、層狀流和環狀流實現流型辨識,并驗證了該方法的可行性;陳德運等[10]采用主成分分析法對ERT系統中的邊界測量電壓數據進行特征提取,然后作為支持向量機的輸入,對油水兩相流的均勻流、層流、環狀流和核心流4種流型進行流型辨識,并通過實驗驗證了該方法的有效性。
在之前的研究中,鮮有人將集成學習與流型辨識相結合,這種方法屬于機器學習中的一種,通過構建并結合多個學習器來完成學習任務[11],主要包含Boosting、Bagging及Stacking 3類算法,一般結構是先產生一組“個體學習器”,再用某種策略將它們結合起來[12],所用的策略主要有平均法、投票法和學習法3種。
極限梯度提升(eXtreme Gradient Boosting,XGBoost)是Boosting算法中的一種,由Chen等[13]于2016年提出,該算法在傳統GBDT(Gradient Boosting Decision Tree)算法上進行改進[14],基本思想是將多棵分類回歸樹(Classification And Regression Tree,CART)作為弱分類器,最終組合為一個強分類器,達到提升算法準確率的效果 。
AdaBoost算法也屬于Boosting算法中的一種。 其原理是根據前一個弱分類器的分類結果,調整下一個弱分類器的樣本權重和弱分類器權重,最后將多個弱分類器組合成一個強分類器,達到提高分類效果的目的[15]。由于AdaBoost算法可以使用不同的分類算法作為弱分類器,并且可以有效地提高算法效果,因此在各種研究中得到了廣泛的應用。
筆者先對實驗采集的泡狀流、彈狀流、段塞流和混狀流4種流型數據進行幀數均值化,然后利用XGBoost算法進行預訓練,并以增益值作為指標對特征進行選擇,保留重要特征,去除冗余特征,以此來降低分類模型的復雜度和提高實時性。最后將5個深度神經網絡(Deep Neural Networks,DNN)模型作為弱分類器,通過AdaBoost算法組成DNN-AdaBoost強分類器,輸入預處理好的數據進行流型辨識,并與其他算法進行比較,以驗證DNN-AdaBoost算法在流型辨識中的有效性。
1 電阻層析成像系統原理
電阻層析成像系統由ERT傳感器、數據采集系統及重建圖像計算機3部分構成[16],見圖1。

圖1 電阻層析成像系統原理圖
電阻層析成像系統工作原理是由重建圖像計算機對數據采集系統發出控制信號,控制ERT傳感器的激勵模式及測量模式,并采集測量值。16電極ERT傳感器采用相鄰激勵模式并進行相鄰電極電壓測量,共采集120個獨立邊界電壓測量值,經A/D轉換傳回計算機,采用圖像重建算法即可獲得管道截面電導率分布的重建圖像[17]。
2 流型辨識模型
2.1 CART算法
CART算法采用一種二分遞歸分割的技術,將當前的樣本集分為2個子樣本集,使得生成的每個非葉子節點都有2個分支。因此,CART算法生成的決策樹是結構簡潔的二叉樹[18]。
CART算法主要分為2步:第一步是將訓練樣本進行遞歸地劃分自變量空間并進行建樹,第二步是用驗證數據進行剪枝。建樹過程中引入基尼系數H(p),據此選擇最優特征,并決定該特征的最優二值切分點,其計算公式如下:
(1)
式中:a為當前類別;A為總類別數;pa為樣本點屬于第a類的概率。
具有最小基尼系數的屬性及其屬性值為最優。基尼系數值越小,說明二分之后的子樣本的“純凈度”越高,選擇該屬性作為分裂屬性的效果越好,以此完成建樹過程。為有效降低過擬合問題,提高模型的泛化能力,需對樹模型進行剪枝處理。經過建樹以及剪枝處理后即可生成一個CART模型,再將CART模型作為XGBoost算法的弱分類器,最終將多個CART弱分類器結合起來構成一個強分類器,形成XGBoost算法。
2.2 XGBoost算法
XGBoost算法是在GBDT算法上改進而來的,相比于傳統的GBDT算法,XGBoost算法無論是在模型精度還是在模型計算速度方面均得到較大改善。其基本思想是將多個CART模型組合,通過前一模型的預測結果來減少后一個模型的偏差,從而提高預測性能[19]。
XGBoost算法最終的強分類器數學模型如下:
(2)
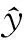
模型的目標優化函數S為:
(3)
(4)
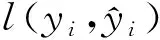
再對損失函數進行二階泰勒展開,將式(4)代入式(3)得到近似優化目標函數:
(5)
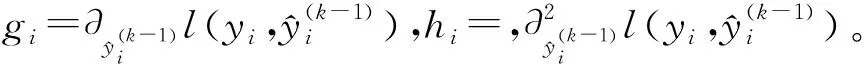
利用XGBoost算法進行預訓練,根據預訓練的結果可以計算特征的重要性程度,根據特征重要性進行排序后再進行特征選擇,以此來達到數據降維的目的。
2.3 DNN神經網絡
本文構建的DNN弱分類器模型分為輸入層、隱藏層和輸出層3部分。隱藏層有 4 層,每層包含 500個神經元節點。ReLU激活函數R(x)用于去線性化,以交叉熵作為損失函數,反向傳播用于學習訓練調整和更新神經元之間的權重。R(x)表達式為:
(6)
交叉熵損失函數L為:
(7)
式中:N為樣本個數;M為類別個數;yic為符號函數,如果第i個樣本的真實類別為c,則值為1,否則為0;pic為樣本i屬于c類的概率。
DNN神經網絡的框架圖如圖2所示。
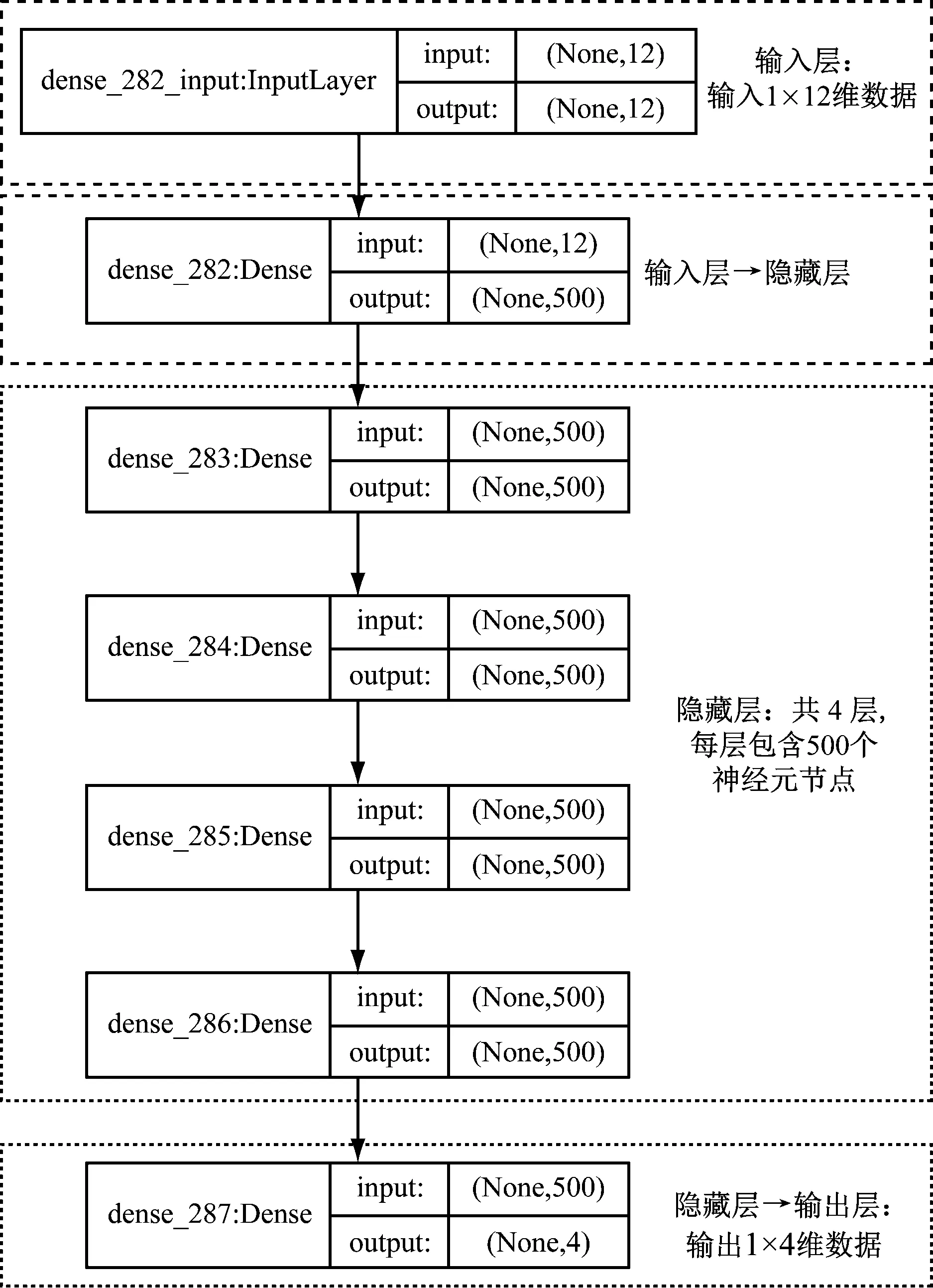
圖2 DNN網絡框架圖
2.4 DNN-AdaBoost算法
本文構建的DNN-AdaBoost算法模型使用5個DNN模型作為AdaBoost算法的弱分類器,原理是依次訓練多個DNN模型,根據上一個DNN分類器的結果調整下一個DNN分類器的樣本權重,從而達到自適應提升的效果,最后根據每個DNN分類器分類效果確定其在最終強分類器中的權重[20]。其算法過程如下:
(1) 輸入訓練樣本。
(2) 初始化權值分布Di。
Di=(w1,w2,…,wN)
(8)
式中:wi為第i個樣本的權值,每個樣本賦予相同的初始權值,為1/N。
(3) 訓練弱分類器,共進行TN次迭代,TN為弱分類器的總數。
選擇一個DNN神經網絡,作為第t個弱分類器Ht并計算該弱分類器在權值分布Dt上的分類誤差et:
(9)
式中:wt(i)為第t次迭代中第i個被錯誤分類樣本的權值。
計算當前DNN神經網絡在最終強分類器中的權重αt:
(10)
更新下一次迭代的樣本權值Dt+1:
(11)
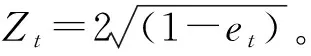
(4) 將各個DNN神經網絡弱分類器Ht及其權重αt組合為一個強分類器Hfinal。
(12)
通過符號函數sign的作用,得到最終的強分類器:
(13)
(5) 將測試樣本輸入強分類器,輸出分類結果。
基于集成學習的流型辨識模型框圖見圖3。
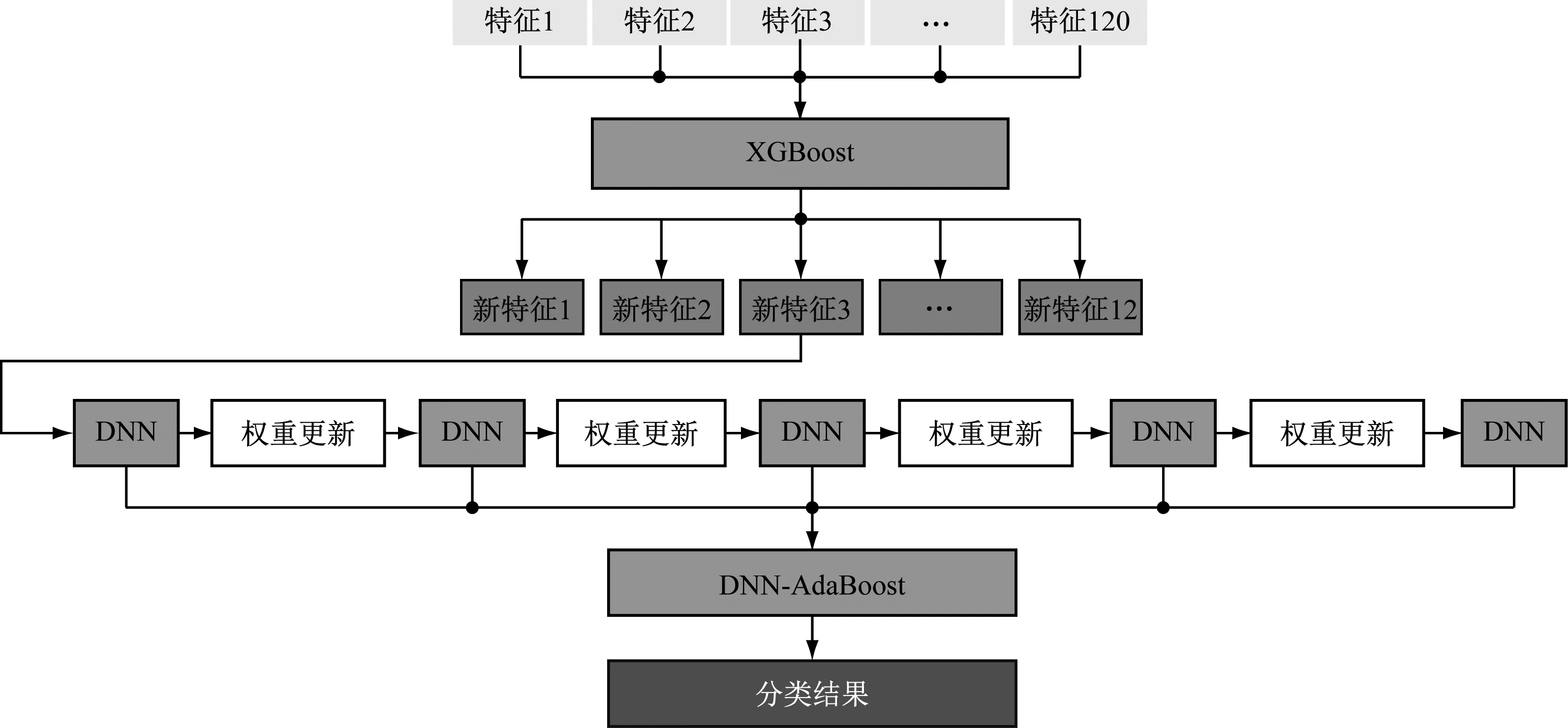
圖3 基于集成學習的流型辨識模型框圖
3 實驗過程及結果分析
3.1 數據采集
使用華北電力大學先進測量實驗室的可移動氣水兩相流實驗裝置進行實驗數據采集,實驗裝置實物圖和示意圖分別如圖4和圖5所示。

圖4 實驗裝置實物圖
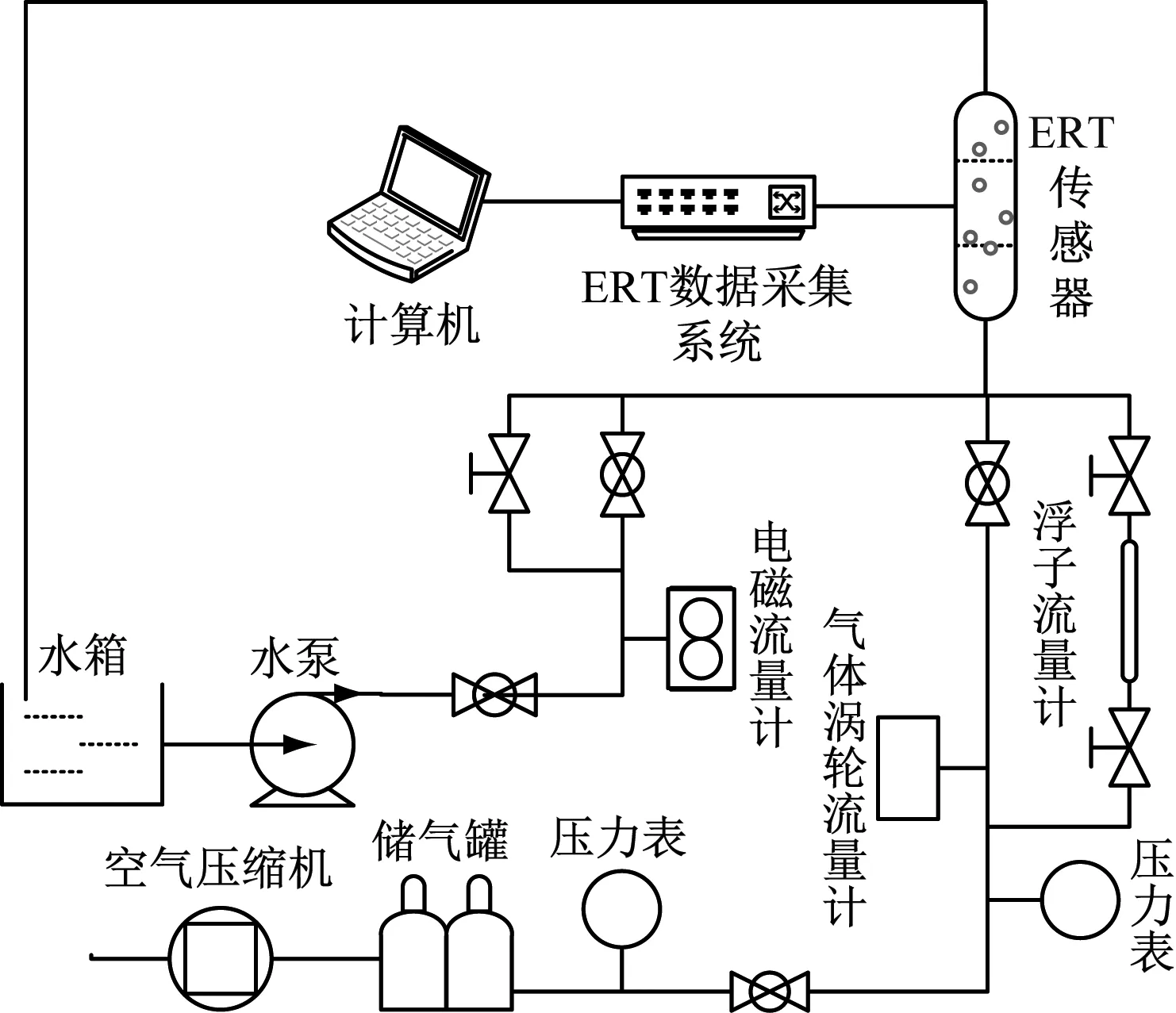
圖5 實驗裝置示意圖
此裝置主要由水路循環、氣路循環及電阻層析成像三部分組成。首先由空氣壓縮機壓入儲氣罐里的氣體經過壓力表、氣體渦輪流量計、浮子流量計到達ERT傳感器。同時水箱里的水由水泵抽取經過電磁流量計、閥門到達ERT傳感器與氣體混合形成氣液兩相流。在水流量不變的情況下,通過調節氣相路的閥門開度來改變氣量,可以得到不同的氣液兩相流流型。最后由ERT傳感器采集不同流型的信息。參考垂直管道氣液兩相流的Taitel流型圖進行氣相及液相的流量配比,當水與氣的比例在一定的范圍內時,即可得到一種典型流型,同時亦可觀察有機玻璃透明管段記錄當前流型,得到不同的氣液兩相流流型。
ERT傳感器部分透明直管段的管徑為50 mm,其周圍安裝16電極ERT陣列傳感器,采用四電極激勵測量策略,采樣頻率為120 Hz,共可獲得120個獨立測量值,通過數字化ERT系統將模擬信號轉化為數字信號保存至計算機。實驗中將水相體積流量固定為1.7 m3/h,通過閥門調節氣相流量的大小,進而改變氣液兩相流的流型狀態。經實驗觀察,選取氣相體積流量為0.3 m3/h、0.5 m3/h、1.2 m3/h和2.5 m3/h,分別對應泡狀流、彈狀流、段塞流及混狀流4種流型,如圖6所示。

(a) 泡狀流
3.2 數據預處理
在實驗采集的樣本預處理方面,由于每幀數據只包含了極短時間內氣液兩相流的流型信息,并不能很好地表征其在時間序列下整體流型的流動特征。因此,進行了幀數均值化處理。不同幀數均值化的平均辨識準確率如圖7所示。
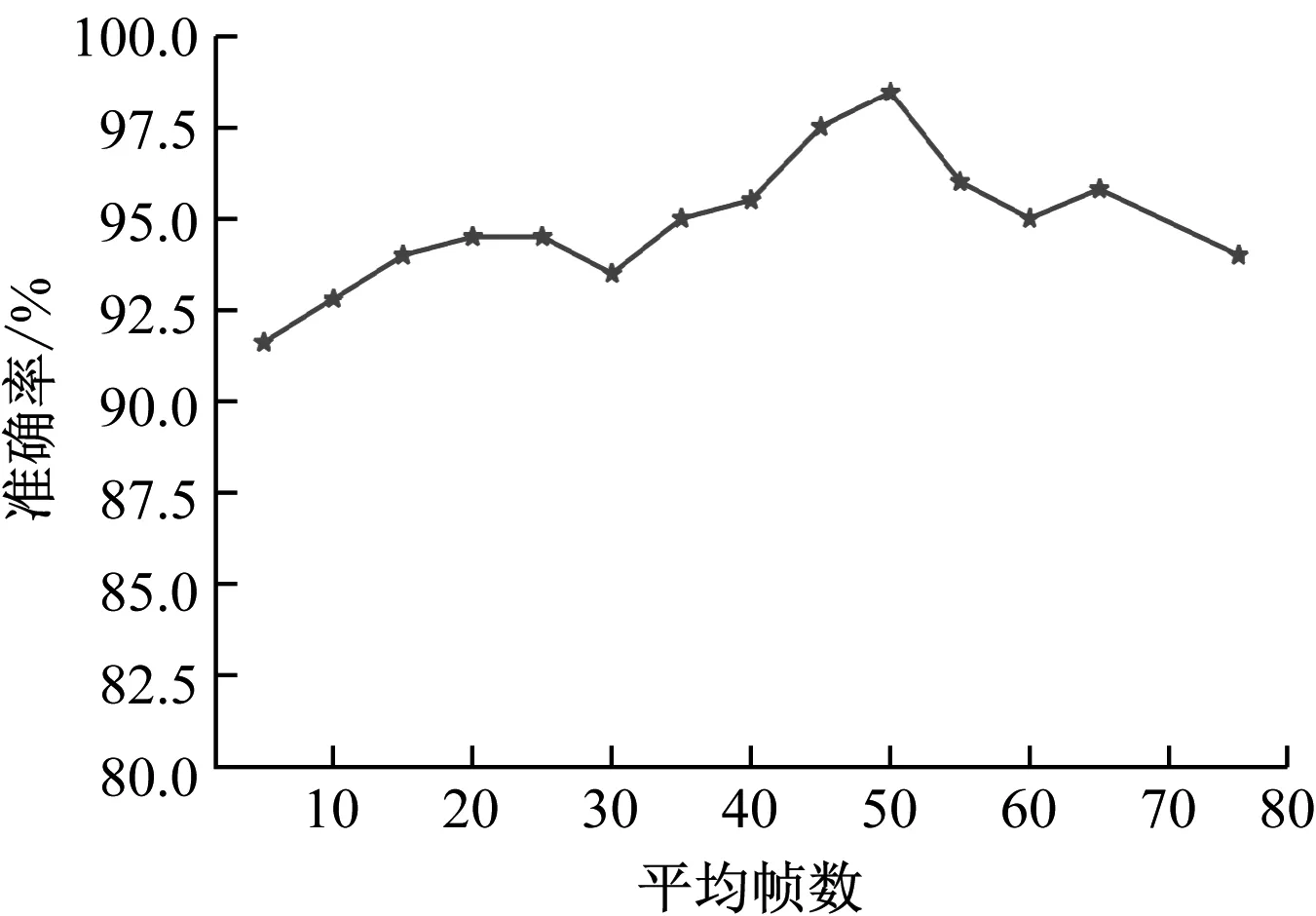
圖7 平均辨識準確率
由圖7可以看出,對5幀至50幀均值化處理后的流型辨識準確率總體呈逐漸升高的趨勢,但繼續增加均值化的幀數,又會導致準確率下降,其原因為均值化處理后的數據綜合考慮了多個截面的平均信息,極大地降低了用單一截面信息評估整體的局限性,增加了動態流型的整體特征,但過多幀數的均值化又會導致各個流型之間的特征差異變小,從而出現各個流型之間易于混淆的結果。因此,本文選擇以每50幀數據均值化的方式對數據進行預處理。
由于采集的數據特征維度為120維,為有效降低模型復雜程度及提高實時性,需對數據進行降維處理。先用XGBoost算法對數據進行預訓練,得到每個特征的重要性,然后設置閾值進行特征選取。特征重要性根據gain值β進行評價,其計算公式如下:
(14)
根據式(14)計算每個特征的gain值,如圖8所示。由圖8可以看出,120個特征所對應的gain值各不相同,即特征重要性不同,綜合考慮對算法實時性的要求和精度要求,按照特征重要性進行排序,并設置特征選擇的閾值為0.02,據此對特征進行選擇,最終選出12個特征組成新的數據特征。為了對比特征選擇前后對流型辨識效果的影響,對比了特征選擇前后的訓練時間、預測時間及4種流型平均辨識準確率,如表1所示。
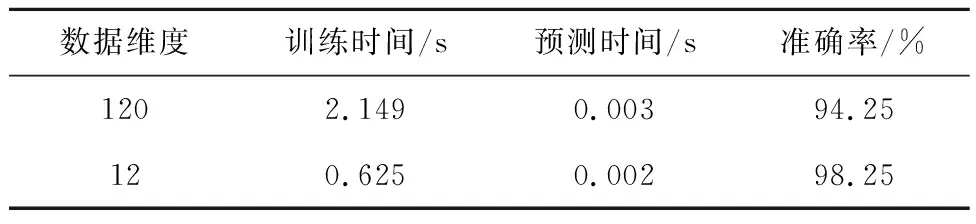
表1 特征選擇前后各參數的對比
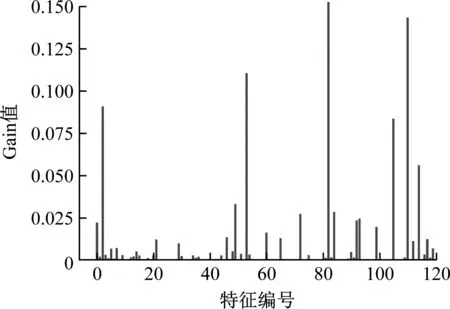
圖8 特征重要性
由表1可以看出,在將特征為120維的數據降維到12維后,其訓練時間從2.149 s減至0.625 s,預測時間從0.003 s減至0.002 s,準確率從94.25%提高到98.25%,其原因為通過特征選擇實現降維,保留了重要特征,去除冗余特征,從而降低了模型復雜程度,提高了算法實時性,并且冗余特征的去除有效降低了過擬合對算法精度的影響,因此算法的實時性和精度均得到了提高。
3.3 流型辨識及結果分析
數據預處理完成后的數據樣本共有800個,每個樣本維度為12維,將其以4∶1的分布隨機劃分出640個訓練樣本及160個測試樣本。然后將其輸入DNN-AdaBoost算法中進行流型辨識。
DNN-AdaBoost算法中有一些參數(見表2)對模型的整體性能有重要影響。 因此,本文使用網格搜索算法對 DNN-AdaBoost 算法中的參數進行優化。

表2 超參數調優
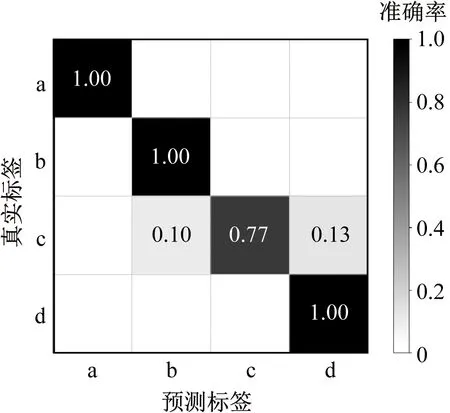
為了驗證AdaBoost算法的提升效果,對比了單獨采用DNN算法進行流型辨識與采用自適應提升后的DNN算法(即DNN-AdaBoost算法)對同一批數據的分類效果,結果如圖9所示,其中a~d分別對應泡狀流、彈狀流、段塞流及混狀流。
(a) DNN算法
由圖9可以看出,DNN模型對4種流型的平均辨識準確率為94.25%,對段塞流的辨識準確率最差,僅為77%,其中10%的樣本被錯分為彈狀流,13%的樣本被錯分為混狀流。 DNN-AdaBoost算法的平均辨識準確率達到98.25%,其中有2%的彈狀流樣本被錯分為段塞流,而段塞流的樣本中有3%的樣本被錯分為彈狀流,3%的樣本被錯分為混狀流。2種算法對段塞流流型的辨識效果較差,其原因為段塞流是彈狀流至混狀流的過渡流型,其流型特征與彈狀流、段塞流比較相似,因此易被錯分為這兩種流型。從2種算法的平均辨識準確率可知,相比DNN算法,由DNN和AdaBoost組成的DNN-AdaBoost算法的辨識精度有所提升,其辨識精度由94.25%提高到98.25%。
為了比較DNN-AdaBoost算法與其他算法的流型辨識精度,使用相同數據輸入BP神經網絡、SVM、決策樹及GBDT算法模型進行流型辨識。由表3可以看出,DNN-AdaBoost 算法模型對泡狀流、彈狀流、段塞流和混狀流的辨識精度均優于BP神經網絡、SVM、決策樹、GBDT算法和DNN算法模型,其對泡狀流、混狀流的辨識準確率可達到100%,平均辨識精度可達98.25%。
4 結 論
(1) 流型辨識前對數據進行預處理十分必要。選擇不同幀數均值化處理對辨識結果的準確性有較大影響。 經過XGBoost算法特征選擇后,可以提高算法的實時性和準確性。
(2) AdaBoost算法對DNN模型的提升效果較為明顯,對4種流型的平均辨識準確率從94.25%提高到98.25%。
(3) 經過XGBoost算法特征選擇后的DNN-AdaBoost算法對流型辨識的準確率高于BP神經網絡、SVM、決策樹、GBDT算法和DNN算法,該算法的平均辨識準確率可以達到98.25%。
(4) 所采用的DNN-AdaBoost算法在流型辨識方面取得了較好的效果,但也存在一定的局限性。首先,該算法弱分類器的數目不易確定,需花費較長時間進行尋優;其次,由于組合了多個DNN弱分類器,在數據訓練時需耗費較長時間。因此,采用更高效的參數尋優方法及進行模型優化以減少訓練時間是后續需要解決的問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
