基于Mask R-CNN和關鍵點提取的抓取位姿估計方法
2023-10-11 09:00:12金圣潔林曉琛
合肥工業(yè)大學學報(自然科學版) 2023年9期
關鍵詞:關鍵點
吳 飛, 金圣潔, 林曉琛
(武漢理工大學 機電工程學院,湖北 武漢 430070)
在工件堆疊擺放的場景中,目標工件在空間中存在不同位姿、相互遮擋,增加了機器人抓取工件的難度。傳統(tǒng)三維設備掃描目標的整體環(huán)境,生成的點云數(shù)量龐大,直接作為源點云與參考點云配準,會導致運算時間過長,難以滿足機器人抓取所需的快速性。隨著工業(yè)智能化的快速發(fā)展,快速、準確地獲取目標工件的抓取位姿,對工業(yè)機器人的進一步發(fā)展有重要意義。
文獻[1]通過ORB(oriented fast and rotated brief)算法和模板匹配進行目標識別,利用改進的迭代最近點(iterative closest point,ICP)算法進行點云配準與位姿估計,實現(xiàn)了放射源物體相對相機的位姿估計;文獻[2]從圖像中提取出僅有抓取目標的局部圖像,運用卷積神經網絡(convolutional neural network,CNN)進行目標識別分類,該方法具有識別精度高、抗干擾能力強的特點;文獻[3]提出一種基于深度學習的機械臂最優(yōu)抓取位置檢測方法,該方法具有較強的泛化性和穩(wěn)定性;文獻[4]將抓取位姿轉化為抓取位置回歸與抓取角度分類的組合,實現(xiàn)了抓取位姿的單次預測,提升了檢測速度;文獻[5]提出一種基于級聯(lián)卷積神經網絡的平面抓取位姿快速檢測方法,針對背景多樣、光照不均、存在噪點的場景,能夠快速準確地計算得到末端執(zhí)行器位姿;文獻[6]對圖像的每個空間位置進行抓取檢測,能夠直接回歸獲得檢測結果,但并不適用于多對象的圖像數(shù)據(jù);文獻[7]將卷積神經網絡與支持向量機(support vector machine,SVM)等傳統(tǒng)機器學習算法相結合,進一步提高了位姿估計的準確率;文獻[8]提出一種基于圖像掩膜估計抓取位姿的方法,訓練神經網絡時不需要進行真實的位姿標注,保證了識別的效率,同時降低了系統(tǒng)的復雜度。
通過將更快速的區(qū)域卷積神經網絡(faster region-based convolutional neural network,Faster R-CNN)[9]等目標檢測網絡引入到位姿估計問題中,對于平面簡單放置的物體,實現(xiàn)了準確的位姿估計及抓取,但針對多個目標物體散亂堆疊的情況,難以達到抓取要求。基于上述問題以及工業(yè)現(xiàn)場中三通件和彎管件散亂堆疊、位姿任意的工況,本文提出一種基于掩膜區(qū)域卷積神經網絡(mask region-based convolutional neural network,Mask R-CNN)[10]和關鍵點提取混合的位姿估計方法,并通過仿真實驗分析了該方法的性能。位姿估計系統(tǒng)流程如圖1所示。
1 Mask R-CNN實例分割
1.1 制作數(shù)據(jù)集
利用Realsense d435i深度相機采集200張三通、彎管工件圖像,圖像像素大小為848×480。圖像采集環(huán)境如圖2所示。

圖2 圖像采集環(huán)境
深度相機通過固定三腳架安裝在固定高度,采用黑色吸光布作為拍攝背景,通過調節(jié)曝光參數(shù)和發(fā)光二極管的亮度,可采集到工件與背景對比明顯的數(shù)據(jù)集圖像。
圖像中包含不同傾斜角度的工件,同時采集部分含有不可抓取工件位姿的圖像,作為負樣本進行訓練,以模擬真實的散亂堆疊工件場景,提高模型的魯棒性,數(shù)據(jù)集如圖3所示。在機器人抓取過程中,將所有識別出的工件抓取后,通過振動裝置再次改變被識別為不可抓取工件的位姿,進行二次抓取。

圖3 數(shù)據(jù)集
由于采集的數(shù)據(jù)較少,直接進行訓練容易出現(xiàn)過擬合現(xiàn)象,需要通過數(shù)據(jù)增廣來提高實例分割模型的泛化能力。增廣方式包括翻轉、縮放、加噪、模糊、加減曝光等方式,但并非所有的增廣方式都適用于工件數(shù)據(jù)集,需要根據(jù)數(shù)據(jù)集的特征選擇合適的數(shù)據(jù)增廣方式。
本次數(shù)據(jù)增廣方式主要包括翻轉、加噪、模糊及加減曝光,數(shù)據(jù)增廣效果如圖4所示。通過數(shù)據(jù)增廣獲得圖像3 000張,其中2 400張作為訓練集,600張用于驗證集。

圖4 數(shù)據(jù)增廣效果
1.2 Mask R-CNN模型
Mask R-CNN是由Faster R-CNN逐漸改進而來的多任務卷積網絡模型,可以完成目標檢測、目標分類、像素級別的目標分割等多種任務,Mask R-CNN網絡框架圖如圖5所示。

圖5 Mask R-CNN網絡框架圖
本文目標是實現(xiàn)工件分割與位姿估計,檢測分割場景中含有許多同類的不同工件個體,無法采用語義分割模型。同時工件擺放位姿任意,存在堆疊遮擋的情況,難以從單一或者幾個有限的角度分析出有意義的物體特征,也不可能窮舉描述每一個特征,因此傳統(tǒng)物體識別方法難以在該問題中發(fā)揮作用,故采用Mask R-CNN實例分割模型對目標工件的不同個體進行分割。
1.3 Mask R-CNN訓練與驗證
基于遷移學習的方式,加快訓練的過程,以COCO(common objects in context)數(shù)據(jù)集的訓練權重作為初始化權重,在AMD 2600X @3.6 GHz,內存32 GiB,GPU NVDIA GTX-2070的Windows10平臺TensorFlow1.8.0環(huán)境下進行Mask R-CNN的訓練。模型訓練參數(shù)設置見表1所列。

表1 模型訓練參數(shù)
輸出掩膜結果如圖6所示,Mask R-CNN實例分割網絡能夠準確地識別出待抓取的目標工件以及位姿偏差過大的工件,同時能夠識別出部分被遮擋的工件。
1.4 表面點云的構建
通過Mask R-CNN對彩色圖進行分割,獲得的掩膜mask可對深度圖進行分割并提取深度信息,如圖7所示。

圖7 分割工件深度
利用深度相機的內參可建立工件表面點云,點云中每個點的坐標(X,Y,Z)的計算公式如下:
(1)
其中:u0、v0為相機光圈X、Y方向的中心點位置;fx、fy分別為x、y軸上的焦距;s為深度圖里的數(shù)據(jù)與實際距離的比例。
根據(jù)式(1)計算結果分割出待抓取工件表面點云,如圖8所示。

圖8 分割工件點云圖
2 點云配準方法
2.1 特征關鍵點對比
由于點云數(shù)據(jù)是三維坐標系中采樣點的數(shù)據(jù)集,且實際獲得的點云數(shù)據(jù)往往數(shù)量級較大,對不同坐標系下的所有點迭代計算剛性變換矩陣,不僅需要較長的運算時間,也極易造成局部收斂。因此,可采用點云的關鍵點去描述一個點鄰域內的點云,不但減少點云數(shù)量,還提高配準效率和配準精度。常用的點云關鍵點提取算子有三維尺度不變特征變換(3D scale invariant feature transform,3D SIFT)算子[11]、三維角點(3D Harris)檢測算子[12]等。
本文依次在體素下采樣后三通工件的計算機輔助設計(computer aided design,CAD)模板點云、無遮擋工件表面點云以及有遮擋工件表面點云測試3D Harris、3D SIFT 2種算子,CAD模板點云數(shù)量為6 621個,無遮擋工件表面點云數(shù)量為3 033個,遮擋工件表面點云數(shù)量為2 849個,關鍵點提取結果對比如圖9所示。

圖9 關鍵點提取結果對比
根據(jù)上述關鍵點提取結果,針對CAD模板點云,3D Harris關鍵點分布較為均勻,能夠描述整體點云的特征,符合關鍵點提取要求,3D SIFT關鍵點主要分布在工件邊緣處,不利于后續(xù)與表面點云的配準。針對工件的表面點云,存在無遮擋表面點云和有遮擋情況下表面點云2種情況,如圖9結果所示,3D Harris關鍵點相較于3D SIFT關鍵點主要集中在工件邊緣處,且關鍵點數(shù)量相對較少,難以體現(xiàn)表面點云的整體特征。關鍵點提取數(shù)量見表2所列,關鍵點提取時間見表3所列,配準時間以關鍵點提取10次的平均時間為準。

表2 關鍵點提取數(shù)量 單位:個

表3 關鍵點提取時間 單位:s
由統(tǒng)計結果可知,3D Harris算子相比3D SIFT算子在關鍵點提取上所需時間更短,結合圖9關鍵點提取結果可知,由于CAD模板點云數(shù)量較多,可選用3D Harris提取算法,減少計算時間。針對分割工件表面點云,3D SIFT關鍵點提取時間與3D Harris相差1 s左右,但關鍵點提取更均勻,故可選用3D SIFT提取算法。
2.2 初步位姿估計
本文采用采樣一致性初始配準算法(sample consensus initial alignment,SAC-IA)[13]對模板點云和目標工件表面點云進行初始位姿配準,該算法以點云的快速點特征直方圖(fast point feature histogram,FPFH)作為輸入,通過計算特征之間的對應關系,完成初始配準。算法主要流程如下所述。
設定最小距離閾值ds,從模板點云P中選取n個采樣點,每個采樣點之間的距離需大于閾值ds,確保采樣點具有不同的FPFH。同理,計算目標點云Q的FPFH,查找與點云P中采樣點具有相似FPFH的1個或多個點,將其作為模板點云P中采樣點在目標點云Q中的對應點。計算對應點之間旋轉、平移變換矩陣,求解對應點變換后的配準誤差來判斷當前配準變換的性能。采用Huber公式計算配準誤差Es,即
(2)
(3)
其中:lm為預先設定的距離閾值;li為第i組對應點變換后的距離差。重復上述操作直至誤差函數(shù)的值最小,即可求得所需的最佳變換矩陣。
SAC-IA求得的變換矩陣并不準確,因此只能用于粗配準,初始點云如圖10所示,無關鍵點提取粗配準效果如圖11所示。

圖10 初始點云

圖11 無關鍵點提取的SAC-IA粗配準效果
2.3 精配準位姿估計
通過粗配準兩點云大致重合到一起,為ICP算法[14]提供了良好的初始位姿。將粗配準后的兩點云P′和Q作為ICP的初始點云集,算法實現(xiàn)的主要流程如下所述。
對于模板點云P′中的每個采樣點矢量pi,在目標工件表面點云Q中尋找距離最近點矢量qi,確定初始最近對應點對(pi,qi)。計算對應點對之間旋轉、平移變換矩陣R、T,使得對應點集之間的均方誤差最小,均方誤差計算公式如下:
(4)
將求解得到的R、T變換矩陣作用于模板點云P′,得到變換后的點云P″。設定閾值ε=dk-dk-1和最大迭代次數(shù)Nmax,計算變換后的模板點云P″和目標工件點云Q的均方誤差,若誤差小于閾值ε或者當前迭代次數(shù)超出最大迭代次數(shù)Nmax,則停止計算;否則將粗配準獲得的模板點云更新為P″,繼續(xù)重復上述步驟,直至滿足收斂條件。
以SAC-IA的輸出結果作為ICP精配準初始點云位姿,配準結果如圖12所示。

圖12 無關鍵點提取的ICP精配準效果
相較于圖11b中粗配準效果,通過ICP精配準可以獲得更為準確的位姿估計。
3 配準結果與分析
為了驗證本文所提出方法的性能,對比分析了無關鍵點提取、3D Harris關鍵點提取、3D SIFT關鍵點提取、本文3D Harris-3D SIFT關鍵點提取混合的點云配準效率以及配準結果,點云實驗的硬件環(huán)境為Intel(R)Core(TM)i5-9400 CPU@2.90 GHz處理器,16 GiB內存。
以體素下采樣后的三通件和彎管件點云作為算法對比的輸入點云,無關鍵點提取精配準結果如圖11、圖12所示,關鍵點提取算法的相關粗、精配準結果如圖13~圖18所示。
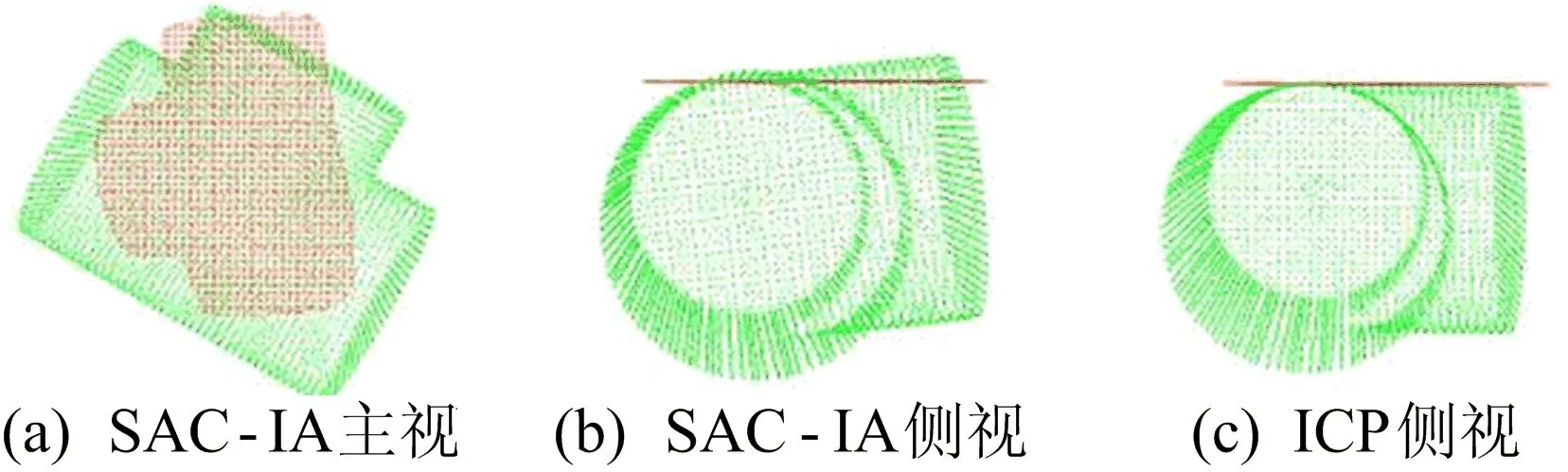
圖13 三通件3D Harris關鍵點提取結果

圖14 三通件3D SIFT關鍵點提取結果

圖15 三通件3D Harris-3D SIFT關鍵點提取結果

圖16 三通件遮擋點云3D Harris-3D SIFT關鍵點提取結果

圖17 彎管件3D Harris-3D SIFT關鍵點提取結果

圖18 彎管件遮擋點云3D Harris-3D SIFT關鍵點提取結果
三通件配準數(shù)據(jù)統(tǒng)計結果見表4所列,配準對比分析結果見表5所列,配準時間以10次運行結果的平均值為準。由對比分析結果可知,無關鍵點提取輸入的點云數(shù)量較大,配準時間長,不符合機器人抓取動作所要求的快速性;僅使用3D Harris關鍵點提取,針對模板點云,關鍵點提取較為均勻,而工件表面點云關鍵點提取數(shù)量少,粗配準效果差,但3D Harris關鍵點提取時間短,相較于無關鍵點提取,計算時間有明顯的下降;僅使用3D SIFT關鍵點提取,針對模板點云,關鍵點主要集中在工件的邊緣處,而工件表面點云提取較為均勻,導致配準結果出現(xiàn)在工件邊緣處,位姿估計錯誤;而本文所提出的混合算法能夠同時兼顧2種關鍵點提取算法的優(yōu)點,點云特征明顯,雖然比僅使用3D Harris關鍵點提取算法的配準時間略有上升,但點云的配準精度有顯著提升,相較于僅使用3D SIFT關鍵點提取算法,配準時間更短,配準效果更好。

表4 三通件配準點云數(shù)量 單位:個
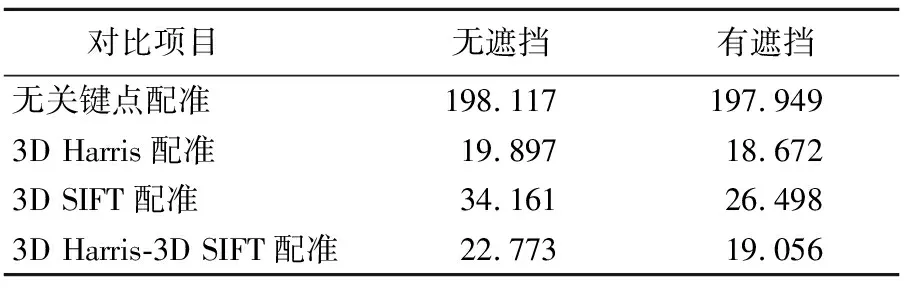
表5 三通件配準時間 單位:s
4 結 論
針對工業(yè)現(xiàn)場中散亂工件的檢測和位姿估計問題,本文提出了一種基于Mask R-CNN和關鍵點提取混合的位姿估計算法。通過Mask R-CNN能夠準確地識別出待抓取的目標工件以及位姿偏差過大的不可抓取工件。通過對模板點云進行3D Harris關鍵點提取,目標工件表面點云進行3D SIFT關鍵點提取,將模板點云與目標工件表面點云縮至特征點集,既保留了點云的主要特征,又能夠提高點云配準效率。以三通和彎管工件為實驗對象,實驗對比分析了無關鍵點提取、3D Harris關鍵點提取、3D SIFT關鍵點提取以及本文關鍵點提取混合算法,結果表明,本文算法能夠顯著降低點云配準時間,提高配準精度,為后續(xù)的機器人抓取提供更加快速準確的位姿估計。
猜你喜歡
建材發(fā)展導向(2022年3期)2022-04-19 12:51:16
中學生數(shù)理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(yè)(2021年8期)2021-11-28 05:07:50
建材發(fā)展導向(2021年11期)2021-07-28 06:58:02
石油化工建設(2018年1期)2018-07-10 09:49:50
廣東教育·高中(2017年10期)2017-11-07 10:17:51
河南畜牧獸醫(yī)(2016年24期)2016-11-29 01:28:30
新高考·高一物理(2015年5期)2015-08-18 18:46:06
創(chuàng)業(yè)家(2015年3期)2015-02-27 07:52:43
中國衛(wèi)生(2014年2期)2014-11-12 13:00:16
