基于集體離群點(diǎn)挖掘的城市交通異常檢測(cè)研究
2023-10-11 09:00:28黃曉地朱曉曦吳淑慧胡中峰
關(guān)鍵詞:檢測(cè)
黃曉地, 朱曉曦, 吳淑慧, 胡中峰
(1.合肥學(xué)院 經(jīng)濟(jì)與管理學(xué)院,安徽 合肥 230601; 2.合肥工業(yè)大學(xué) 管理學(xué)院,安徽 合肥 230009)
城市范圍內(nèi)交通擁堵分為偶發(fā)性和常發(fā)性擁堵[1],如何盡早識(shí)別和精準(zhǔn)定位城市路網(wǎng)系統(tǒng)中出現(xiàn)的偶發(fā)性擁堵,對(duì)于交通安全運(yùn)營(yíng)具有重要意義,圍繞該主題的研究工作主要分為交通流量異常檢測(cè)和交通軌跡異常檢測(cè)2類(lèi)。交通流量異常檢測(cè)是通過(guò)對(duì)環(huán)型感應(yīng)線(xiàn)圈監(jiān)測(cè)器、視頻監(jiān)測(cè)器等固定監(jiān)測(cè)器采集的交通流量、平均車(chē)速等數(shù)據(jù)進(jìn)行分析,挖掘表征交通異常的數(shù)據(jù)序列[2]。由于監(jiān)測(cè)器位置相對(duì)固定,流量異常檢測(cè)主要以時(shí)間序列數(shù)據(jù)為對(duì)象,目前對(duì)于交通流量異常檢測(cè)的研究已相對(duì)成熟[3-9],數(shù)據(jù)處理精度不斷提高,但對(duì)于交通異常的主動(dòng)干預(yù)能力不足。
交通軌跡異常檢測(cè)主要通過(guò)擬合車(chē)輛位置、城市區(qū)域流量、道路占有率等含有歷史交通數(shù)據(jù)的樣本,構(gòu)建城市路網(wǎng)軌跡數(shù)據(jù)庫(kù),再?gòu)脑诰€(xiàn)數(shù)據(jù)中挖掘與期望顯著偏離的軌跡序列[10]。根據(jù)空間屬性的標(biāo)定方法,相關(guān)研究主要分為基于區(qū)域交通數(shù)據(jù)的異常檢測(cè)和基于道路交通數(shù)據(jù)的異常檢測(cè)。基于區(qū)域交通數(shù)據(jù)的異常檢測(cè)需要將城市地圖按照一定標(biāo)準(zhǔn)進(jìn)行劃分,如按主干路劃分[11];其檢測(cè)方法[12-14]可以捕獲不同區(qū)域之間交通流量的相互影響關(guān)系,如因果關(guān)系、遞進(jìn)關(guān)系等,能夠根據(jù)城市整體交通態(tài)勢(shì)的演變盡早發(fā)現(xiàn)異常現(xiàn)象,并定位異常區(qū)域。其主要局限在于:劃分的路網(wǎng)區(qū)域相對(duì)固定,區(qū)域內(nèi)的交通信息會(huì)受到天氣、節(jié)假日及區(qū)域活動(dòng)等諸多因素影響;城市不同區(qū)域間的交通變化存在時(shí)滯,會(huì)對(duì)異常判定造成顯著影響。
基于道路交通數(shù)據(jù)的異常檢測(cè)首先將浮動(dòng)車(chē)(浮動(dòng)車(chē)泛指有定位系統(tǒng)和傳感設(shè)備的車(chē)輛)采集的數(shù)據(jù)按起訖路段、經(jīng)緯度坐標(biāo)等地理信息標(biāo)定到其行駛的道路上,再通過(guò)計(jì)算道路在分析間隔內(nèi)的交通運(yùn)行特征(如路面占有率等),判斷道路上是否出現(xiàn)了交通異常[15]。其檢測(cè)算法[16-18]多以數(shù)據(jù)融合模型為基礎(chǔ),關(guān)聯(lián)交通數(shù)據(jù)的時(shí)間屬性與空間屬性,受環(huán)境影響較小,能夠根據(jù)交通實(shí)時(shí)狀況及時(shí)識(shí)別并定位異常出現(xiàn)位置。其主要局限在于:浮動(dòng)車(chē)數(shù)據(jù)采集不均衡,部分道路可能由于數(shù)據(jù)稀疏而導(dǎo)致誤判;行駛速度、方向等數(shù)據(jù)容易受到駕駛習(xí)慣、機(jī)械故障等偶發(fā)性因素干擾,形成噪音。
針對(duì)上述問(wèn)題,本文提出一種將流量異常檢測(cè)與軌跡異常檢測(cè)相結(jié)合、基于集體離群點(diǎn)挖掘的城市交通異常檢測(cè)模型。首先,選擇路口作為固定監(jiān)測(cè)點(diǎn),通過(guò)對(duì)監(jiān)測(cè)點(diǎn)采集的不同交通工具的流量信息進(jìn)行單一分析和融合分析,利用流量檢測(cè)的方法檢測(cè)是否出現(xiàn)異常;同一區(qū)域內(nèi)不同媒介產(chǎn)生的交通流量信息可以相互增強(qiáng),因此融合后的流量信息能更加全面地反映該路段的交通狀態(tài),且能有效避免數(shù)據(jù)稀疏和噪音的影響。其次,采用以距離-密度-權(quán)重為度量的改進(jìn)聚類(lèi)(distance-density-weightk-medoids,DDWK-medoids)算法,在連續(xù)的時(shí)間間隔內(nèi),從所有路口監(jiān)測(cè)點(diǎn)中自適應(yīng)確定交通樞紐點(diǎn)的數(shù)量和位置,通過(guò)交通樞紐點(diǎn)流量和位置的變化,從軌跡異常檢測(cè)的角度判定是否出現(xiàn)異常;該算法打破以往區(qū)域劃分固定的邊界限制,可根據(jù)城市整體交通態(tài)勢(shì)變化靈活調(diào)整交通樞紐點(diǎn)的數(shù)量及其覆蓋范圍。最后,通過(guò)構(gòu)建“集體離群點(diǎn)-城市交通異常”度量規(guī)則,提高對(duì)處于潛伏期或早期階段交通異常的甄別能力,延長(zhǎng)預(yù)警時(shí)間,避免或降低可能造成的交通擁堵,增強(qiáng)城市路網(wǎng)系統(tǒng)的抗風(fēng)險(xiǎn)能力。
1 交通特征參數(shù)定義
1.1 交通數(shù)據(jù)流特征參數(shù)
城市交通是由人、車(chē)、路和環(huán)境等多種因素共同形成的復(fù)雜系統(tǒng),具有明顯的時(shí)空特性。對(duì)于各類(lèi)交通數(shù)據(jù)流,每個(gè)數(shù)據(jù)實(shí)例可抽象為由時(shí)間屬性、行為屬性、空間屬性構(gòu)成的三元組(t,b,l)。
1) 時(shí)間屬性t。該屬性包含2個(gè)參數(shù),即對(duì)數(shù)據(jù)流進(jìn)行分段處理的窗口寬度Twindow和反映各類(lèi)交通數(shù)據(jù)采集時(shí)點(diǎn)的時(shí)間矩陣T。相關(guān)研究中將城市交通實(shí)時(shí)預(yù)測(cè)定義為時(shí)間跨度不超過(guò)15 min的短時(shí)交通預(yù)測(cè)[19],因此,本文將窗口寬度設(shè)置為T(mén)window=10 min,如起始點(diǎn)時(shí)間標(biāo)定為5:00,則下一時(shí)間點(diǎn)為5:10。對(duì)不同城市的交通狀態(tài)進(jìn)行預(yù)測(cè),窗口寬度可靈活變化。時(shí)間矩陣T為:
(1)
其中,tij為第i類(lèi)交通數(shù)據(jù)流中第j個(gè)分析間隔的時(shí)間屬性,i=1,2,…,m;j=1,2,…,n。
2) 行為屬性b。本文以時(shí)間間隔內(nèi)交通媒介的平均流量表征交通數(shù)據(jù)的行為屬性,即bij=qij/Twindow,bij為第i類(lèi)交通數(shù)據(jù)流中第j個(gè)分析間隔的行為屬性,qij為第i類(lèi)交通數(shù)據(jù)流在第j個(gè)分析間隔內(nèi)的車(chē)流量。行為屬性矩陣B為:
(2)
3) 空間屬性l。交通數(shù)據(jù)空間屬性標(biāo)定如圖1所示。圖1中:x軸為經(jīng)度坐標(biāo);y軸為緯度坐標(biāo)。將城市地理邊界視為數(shù)據(jù)集邊界,設(shè)定城市中心點(diǎn)為坐標(biāo)原點(diǎn)O,標(biāo)定其空間屬性為lO=(0,0)。根據(jù)城市范圍內(nèi)所有交通監(jiān)測(cè)點(diǎn)與坐標(biāo)原點(diǎn)的相對(duì)位置,將實(shí)際地理位置信息轉(zhuǎn)換為坐標(biāo)信息,如任一監(jiān)測(cè)點(diǎn)a的空間屬性為la=(xa,ya),不僅可以對(duì)實(shí)際地理信息進(jìn)行歸一化處理,也顯著降低了空間屬性的復(fù)雜度。

圖1 交通數(shù)據(jù)空間屬性標(biāo)定
1.2 交通監(jiān)測(cè)點(diǎn)與樞紐點(diǎn)
1) 交通監(jiān)測(cè)點(diǎn)。交通監(jiān)測(cè)點(diǎn)是指城市路網(wǎng)系統(tǒng)中客觀(guān)存在的交通信息采集點(diǎn)(如配備電子設(shè)備的交通路口),以同一道路前后路口的平均流量差作為交通監(jiān)測(cè)點(diǎn)采集數(shù)據(jù)的行為屬性。
道路口為城市交通流量相對(duì)密集的地點(diǎn),路口的擁堵或順暢程度是城市交通態(tài)勢(shì)的有力表征,擬合交通監(jiān)測(cè)點(diǎn)的交通信息能夠更加真實(shí)地反映城市交通狀態(tài)的變化趨勢(shì),同時(shí)可以充分利用現(xiàn)有數(shù)據(jù),便于數(shù)據(jù)預(yù)處理。
2) 交通樞紐點(diǎn)。城市路網(wǎng)系統(tǒng)中的交通樞紐點(diǎn)如圖2所示。
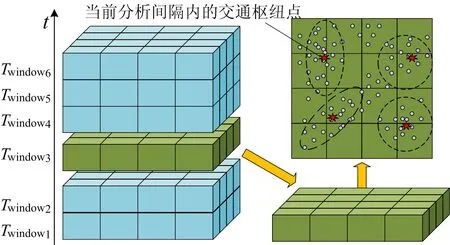
圖2 城市路網(wǎng)系統(tǒng)中的交通樞紐點(diǎn)
圖2中,正方體的橫截面是一個(gè)城市實(shí)際地理邊界的抽象表示,其上每個(gè)點(diǎn)代表1個(gè)交通監(jiān)測(cè)點(diǎn)。在1個(gè)Twindow內(nèi),每個(gè)監(jiān)測(cè)點(diǎn)采集的交通數(shù)據(jù)可表示為三元組(t,b,l)。

表1 4類(lèi)交通數(shù)據(jù)流的具體信息
將1個(gè)Twindow內(nèi)由所有交通監(jiān)測(cè)點(diǎn)生成的數(shù)據(jù)視為1個(gè)數(shù)據(jù)集,Di=(a1,a2,…,aQ),Q為城市邊界內(nèi)交通監(jiān)測(cè)點(diǎn)的數(shù)量。對(duì)數(shù)據(jù)集Di,以距離度量對(duì)交通監(jiān)測(cè)點(diǎn)地理位置信息進(jìn)行聚類(lèi),聚類(lèi)簇的中心點(diǎn)即交通樞紐點(diǎn),反映當(dāng)前分析間隔i內(nèi)城市路網(wǎng)系統(tǒng)中交通流量最密集的位置。本文設(shè)計(jì)的DDWK-medoids算法,可自適應(yīng)確定分析窗口內(nèi)滿(mǎn)足條件的交通樞紐點(diǎn)數(shù)量和位置。
2 檢測(cè)模型
2.1 集體離群點(diǎn)
根據(jù)離群點(diǎn)異常表現(xiàn)方式的特征,可將其分為點(diǎn)離群點(diǎn)、情景離群點(diǎn)和集體離群點(diǎn)[20]。集體離群點(diǎn)通常是由一系列相關(guān)數(shù)據(jù)實(shí)例組成,當(dāng)它們以某種模式共同出現(xiàn)時(shí),明顯偏離數(shù)據(jù)分布的正常期望,但每個(gè)數(shù)據(jù)實(shí)例單獨(dú)分析時(shí)不構(gòu)成離群點(diǎn)[21]。
2.2 基于集體離群點(diǎn)的異常交通狀態(tài)度量
在樣本數(shù)據(jù)可用性的基礎(chǔ)上,本文選擇4類(lèi)城市交通數(shù)據(jù)進(jìn)行分析,分別是公交車(chē)數(shù)據(jù)集s1、出租車(chē)數(shù)據(jù)集s2、非機(jī)動(dòng)車(chē)數(shù)據(jù)集s3及其他交通媒介數(shù)據(jù)集s4。在樣本數(shù)據(jù)中,數(shù)據(jù)集s3占比約10%,其精確程度對(duì)分析精度影響較小,因此,通過(guò)共享單車(chē)各停放點(diǎn)實(shí)時(shí)更新的流量數(shù)據(jù)f和其實(shí)際地理位置對(duì)應(yīng)的權(quán)重φ近似得到s3。數(shù)據(jù)集s4包括行人、客貨車(chē)、私家車(chē)等的流量信息,此類(lèi)數(shù)據(jù)來(lái)源繁雜且完整性不足,基于各類(lèi)別交通流量變化在同一城市區(qū)域內(nèi)具有一致性的特點(diǎn),本文在考慮地理因素基礎(chǔ)上,通過(guò)加權(quán)其他3類(lèi)數(shù)據(jù)集近似表示s4。在實(shí)際應(yīng)用中,可以根據(jù)城市實(shí)際情況,對(duì)權(quán)重做適當(dāng)調(diào)整,具體信息見(jiàn)表1所列。
注:φ1、φ2為s3的地理位置權(quán)重,φ1=2.0,φ2=1.5;ε1、ε2、ε3為s4的地理位置權(quán)重,ε1=0.55,ε2=0.30,ε3=0.15。
基于集體離群點(diǎn)的異常交通狀態(tài)度量主要分為4個(gè)層次:① 對(duì)交通監(jiān)測(cè)點(diǎn)采集的任意一類(lèi)交通數(shù)據(jù)流進(jìn)行異常檢測(cè);② 對(duì)交通監(jiān)測(cè)點(diǎn)上多類(lèi)交通數(shù)據(jù)融合后的累加變化程度進(jìn)行異常檢測(cè);③ 對(duì)交通樞紐點(diǎn)的數(shù)據(jù)變化趨勢(shì)進(jìn)行異常檢測(cè);④ 對(duì)多個(gè)交通樞紐點(diǎn)融合的流量變化趨勢(shì)進(jìn)行異常檢測(cè)。
2.3 模型架構(gòu)
本文集體離群點(diǎn)檢測(cè)模型主要分為線(xiàn)下擬合和實(shí)時(shí)檢測(cè)2個(gè)階段,模型框架如圖3所示。

圖3 本文檢測(cè)模型框架
1) 線(xiàn)下擬合階段。首先依據(jù)城市地理邊界,標(biāo)定各交通監(jiān)測(cè)點(diǎn)采集數(shù)據(jù)的時(shí)間屬性、行為屬性和時(shí)間屬性,擬合各監(jiān)測(cè)點(diǎn)上的單類(lèi)交通數(shù)據(jù)和整體交通流量變化趨勢(shì),由于監(jiān)測(cè)點(diǎn)物理位置固定,各類(lèi)交通數(shù)據(jù)的擬合不涉及空間屬性;然后,以DDWK-medoids算法自適應(yīng)確定各分析間隔內(nèi)的交通樞紐點(diǎn),擬合交通樞紐點(diǎn)地理位置和交通流量的變化趨勢(shì);最后,根據(jù)交通樞紐點(diǎn)計(jì)算中心點(diǎn),通過(guò)連續(xù)分析間隔的中心點(diǎn)變化趨勢(shì),擬合城市整體交通狀態(tài)的變化趨勢(shì)。
2) 實(shí)時(shí)檢測(cè)階段。基于線(xiàn)下擬合結(jié)果,判斷城市路網(wǎng)系統(tǒng)是否出現(xiàn)由集體離群點(diǎn)表征的交通異常。
3 算法框架
交通監(jiān)測(cè)點(diǎn)采集的單類(lèi)交通數(shù)據(jù)可表示為二元組(t,b),按精度要求以MATLAB函數(shù)進(jìn)行多項(xiàng)式擬合,即
p=polyfit(T,B,τ),
其中:p為階次從高到低的多項(xiàng)式系數(shù);T=[t1t2…tN],N為數(shù)據(jù)量;B=[b1b2…bN];τ為多項(xiàng)式階數(shù)。通過(guò)改進(jìn)的混合多元高斯函數(shù),對(duì)同一交通監(jiān)測(cè)點(diǎn)采集的多類(lèi)交通數(shù)據(jù)進(jìn)行擬合,以不動(dòng)點(diǎn)迭代法優(yōu)化函數(shù)參數(shù)[22]。
融合后的交通監(jiān)測(cè)點(diǎn)數(shù)據(jù)可表示為三元組(t,b,l)。本文設(shè)計(jì)一種DDWK-medoids算法,對(duì)城市路網(wǎng)系統(tǒng)中的交通數(shù)據(jù)進(jìn)行聚類(lèi)處理,從交通監(jiān)測(cè)點(diǎn)中自適應(yīng)確定當(dāng)前時(shí)間間隔內(nèi)的交通樞紐點(diǎn)位置與數(shù)量,并據(jù)此計(jì)算交通中心點(diǎn),算法框架由參數(shù)取值范圍自適應(yīng)確定、預(yù)備簇中心點(diǎn)挑選、初始簇中心點(diǎn)篩選、條件重定位迭代、參數(shù)對(duì)比擇優(yōu)5個(gè)部分組成,如圖4所示。

圖4 DDWK-medoids算法框架
3.1 自適應(yīng)算法參數(shù)取值范圍
將期望聚類(lèi)簇?cái)?shù)的取值范圍等分,以等分段的上邊界值作為區(qū)間代表值。引入循環(huán)判斷準(zhǔn)則對(duì)參數(shù)區(qū)間劃分的合理性進(jìn)行判斷,提高算法準(zhǔn)確率。具體過(guò)程見(jiàn)規(guī)則1和規(guī)則2。

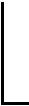
(3)
在算法參數(shù)對(duì)比擇優(yōu)環(huán)節(jié),若按照規(guī)則1確定的算法參數(shù)的聚類(lèi)效果均不滿(mǎn)足度量指標(biāo)的閾值要求,則按照規(guī)則2進(jìn)行參數(shù)二次選擇。
規(guī)則2選擇質(zhì)量最佳的2個(gè)期望聚類(lèi)簇?cái)?shù)作為新的參數(shù)選擇范圍區(qū)間[kbest1,kbest2]。在新區(qū)間內(nèi),計(jì)算新的期望聚類(lèi)簇?cái)?shù)k′,即
(4)
由k′取值得到新集合K′,基于K′,確定新鄰域半徑ε′與密度閾值ρ′。在參數(shù)對(duì)比擇優(yōu)環(huán)節(jié),若聚類(lèi)質(zhì)量滿(mǎn)足度量指標(biāo)閾值要求,算法終止;否則繼續(xù)按規(guī)則2迭代。
3.2 預(yù)備簇中心挑選
最佳聚類(lèi)結(jié)果應(yīng)滿(mǎn)足簇內(nèi)對(duì)象高度相似且簇間對(duì)象最大程度相異的標(biāo)準(zhǔn),即簇中心點(diǎn)之間的距離應(yīng)盡可能遠(yuǎn),避免集中在較小范圍,陷入局部最優(yōu);同時(shí),為避免噪聲、離群數(shù)據(jù)的影響,簇中心點(diǎn)應(yīng)具備相對(duì)較高的鄰域密度。
推論1 數(shù)據(jù)集最佳聚類(lèi)結(jié)果應(yīng)使得各個(gè)簇中心點(diǎn)的鄰域密度相對(duì)較高且不同簇中心點(diǎn)之間的距離相對(duì)較遠(yuǎn)。
根據(jù)推論1,以“距離-鄰域密度”為度量標(biāo)準(zhǔn)選取預(yù)備簇中心,通過(guò)刪除已形成簇縮小數(shù)據(jù)集規(guī)模,減少數(shù)據(jù)間的重復(fù)計(jì)算,具體步驟如下。
1) 在數(shù)據(jù)集中,挑選鄰域密度最大的數(shù)據(jù)c1,作為第1個(gè)預(yù)備簇中心,將其鄰域半徑內(nèi)的S1個(gè)數(shù)據(jù)聚到一起,形成第1個(gè)簇C1。
2) 將C1從原數(shù)據(jù)集D中刪除,形成新數(shù)據(jù)集D1,數(shù)據(jù)規(guī)模為|D|-|S1|。
3) 在數(shù)據(jù)集D1中,以歐式距離為度量,搜尋距離c1最遠(yuǎn)的數(shù)據(jù),若該數(shù)據(jù)的鄰域密度滿(mǎn)足密度閾值要求,則將其作為第2個(gè)預(yù)備簇中心;否則選擇距離c1次遠(yuǎn)的數(shù)據(jù)進(jìn)行鄰域密度度量,依此類(lèi)推,選擇滿(mǎn)足密度閾值要求且距離c1足夠遠(yuǎn)的c2作為第2個(gè)預(yù)備簇中心。將c2鄰域半徑內(nèi)的S2個(gè)數(shù)據(jù)聚到一起,形成第2個(gè)簇C2。
4) 將C2從數(shù)據(jù)集D1中刪除,形成新數(shù)據(jù)集D2,數(shù)據(jù)規(guī)模為|D1|-|S2|。
5) 計(jì)算數(shù)據(jù)集D2中任意數(shù)據(jù)α到c1、c2的相對(duì)距離Rd,計(jì)算公式為:
Rd=min{dist(α,c1),dist(α,c2)}
(5)
搜尋滿(mǎn)足密度要求且相對(duì)c1、c2距離均足夠遠(yuǎn)的數(shù)據(jù)作為第3個(gè)預(yù)備簇中心c3。聚集c3鄰域半徑內(nèi)的S3個(gè)數(shù)據(jù)作為第3個(gè)簇C3。
6) 將C3從數(shù)據(jù)集D2中刪除,形成新數(shù)據(jù)集D3,數(shù)據(jù)規(guī)模為|D2|-|S3|。
7) 重復(fù)上述步驟,直到數(shù)據(jù)集D中任意數(shù)據(jù)都不滿(mǎn)足密度閾值要求,終止計(jì)算,輸出所有的預(yù)備簇中心集合{c1,c2,…,ck}。
3.3 初始簇中心篩選
在挑選預(yù)備簇中心過(guò)程中,由于對(duì)比空間縮小,后續(xù)選出的特征樣本相對(duì)質(zhì)量弱于先選出的。
推論2 首個(gè)篩選出的預(yù)備簇中心點(diǎn)質(zhì)量最好,隨著數(shù)據(jù)集規(guī)模逐漸縮小,后續(xù)篩選出的中心點(diǎn)質(zhì)量可能呈現(xiàn)遞減趨勢(shì)。
因此,引入慣性權(quán)重思想,進(jìn)一步篩除預(yù)備簇中心點(diǎn)集中的劣質(zhì)簇中心,具體步驟如下。
1) 按預(yù)備簇中心產(chǎn)生順序賦予線(xiàn)性遞減權(quán)重。對(duì)先選出的初始簇中心賦予更大的權(quán)重,加快局部收斂,控制求解精度與迭代次數(shù);對(duì)排序靠后的預(yù)備簇中心賦予較小權(quán)重,增強(qiáng)全局搜索能力,避免收斂于劣質(zhì)簇中心形成的局部最優(yōu)解。權(quán)重w計(jì)算公式為:
(6)
其中:nmax為預(yù)備簇中心點(diǎn)總數(shù);n為當(dāng)前預(yù)備簇中心點(diǎn)產(chǎn)生順位編號(hào);wmax=0.9;wmin=0.4。
2) 進(jìn)行權(quán)重聚類(lèi),對(duì)迭代后新形成簇的中心點(diǎn)進(jìn)行鄰域密度判斷,若存在劣質(zhì)簇,即新中心點(diǎn)鄰域密度不滿(mǎn)足要求,轉(zhuǎn)入步驟4);若不存在劣質(zhì)簇,轉(zhuǎn)入步驟3)。任意數(shù)據(jù)α與當(dāng)前簇中心點(diǎn)的加權(quán)距離度量計(jì)算公式為:
(7)
3) 計(jì)算權(quán)重聚類(lèi)后新形成簇的中心點(diǎn),將這些中心點(diǎn)作為初始簇中心,進(jìn)入條件重定位迭代環(huán)節(jié)。
4) 刪除形成劣質(zhì)簇的原始預(yù)備簇中心點(diǎn),對(duì)其余的原始預(yù)備簇中心進(jìn)行權(quán)重迭代,判斷是否存在劣質(zhì)簇,若不存在,轉(zhuǎn)入步驟3);若出現(xiàn)劣質(zhì)簇,繼續(xù)迭代計(jì)算,直至篩除全部劣質(zhì)預(yù)備簇中心。
3.4 條件重定位迭代
在每次簇中心重定位迭代后加入密度度量,標(biāo)記不滿(mǎn)足閾值要求的劣質(zhì)簇中心。若被標(biāo)記的劣質(zhì)簇中心在后續(xù)迭代過(guò)程中,聚類(lèi)質(zhì)量呈下降趨勢(shì)(簇密度持續(xù)下降),則刪除該劣質(zhì)簇中心,從而盡早篩除可能出現(xiàn)的劣質(zhì)簇中心,避免冗余迭代,加快算法收斂速度與穩(wěn)定性。具體步驟如下:
1) 基于當(dāng)前簇中心點(diǎn)集,進(jìn)行重定位迭代,對(duì)新形成的簇進(jìn)行密度度量。
2) 若聚類(lèi)簇的簇內(nèi)密度均滿(mǎn)足密度閾值要求,則清空劣質(zhì)簇標(biāo)記,繼續(xù)按步驟1)處理,直至算法收斂或達(dá)到最大迭代次數(shù);若出現(xiàn)不滿(mǎn)足密度閾值要求的聚類(lèi)簇,則標(biāo)記其為劣質(zhì)簇,轉(zhuǎn)入步驟3)。
3) 若該簇第1次被標(biāo)記,則記錄當(dāng)前簇內(nèi)密度后,繼續(xù)按步驟1)處理;若該簇已存在標(biāo)記,則記錄當(dāng)前簇內(nèi)密度,轉(zhuǎn)入步驟4)。
4) 設(shè)定控制精度ζ,若某簇連續(xù)低于密度閾值且聚類(lèi)質(zhì)量呈下降趨勢(shì),則刪除該簇,轉(zhuǎn)入步驟1)。參數(shù)ζ表示某個(gè)簇被允許標(biāo)記為劣質(zhì)簇的最大次數(shù)。
3.5 算法參數(shù)對(duì)比擇優(yōu)
選擇標(biāo)準(zhǔn)互信息(normalized mutual information,NMI)作為度量指標(biāo)對(duì)不同參數(shù)對(duì)應(yīng)的聚類(lèi)結(jié)果進(jìn)行對(duì)比,確定最優(yōu)聚類(lèi)參數(shù)。
3.6 針對(duì)多簇?cái)?shù)據(jù)集的算法改進(jìn)

4 算法實(shí)驗(yàn)
4.1 數(shù)據(jù)集
選擇UCI(University of California,Irvine)數(shù)據(jù)庫(kù)(http://archive.ics.uci.edu/ml/datasets.php)中6個(gè)數(shù)據(jù)集Iris、Seeds、Survival、Knowledge(即Knowledge Modeling)、Perfume、Absenteeism進(jìn)行測(cè)試,所有數(shù)據(jù)集都經(jīng)過(guò)歸一化預(yù)處理,數(shù)據(jù)集具體信息見(jiàn)表2所列。分別用傳統(tǒng)K-medoids算法與DDWK-medoids算法,對(duì)5個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集進(jìn)行對(duì)比;采用按3.6節(jié)改進(jìn)的DDWK-medoids算法和傳統(tǒng)K-medoids算法,對(duì)Absenteeism、Perfume 2個(gè)多簇?cái)?shù)據(jù)集進(jìn)行對(duì)比。每個(gè)數(shù)據(jù)集處理50次,計(jì)算50次聚類(lèi)結(jié)果評(píng)價(jià)的最大值、最小值和均值。
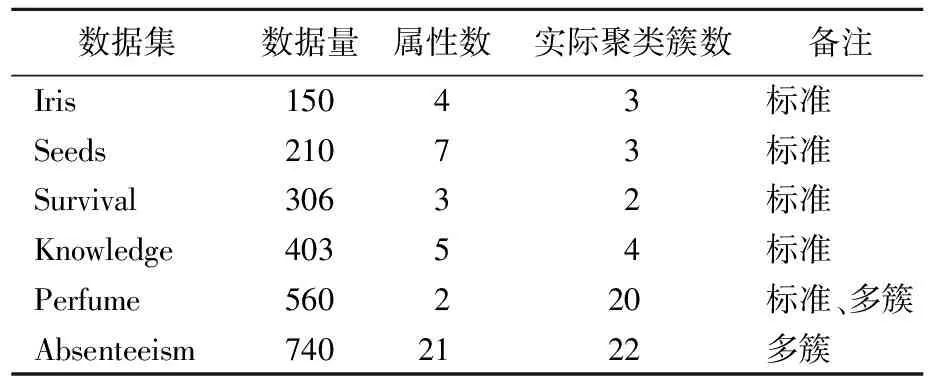
表2 數(shù)據(jù)集具體信息
4.2 聚類(lèi)質(zhì)量評(píng)價(jià)指標(biāo)
1) 采用輪廓系數(shù)(silhouette coefficient,SC),結(jié)合內(nèi)聚度和分離度2種因素,通過(guò)計(jì)算數(shù)據(jù)集中所有對(duì)象的SC平均值對(duì)聚類(lèi)結(jié)果進(jìn)行評(píng)價(jià),SC的取值越接近1,聚類(lèi)結(jié)果越合理;若SC取值接近-1,則聚類(lèi)結(jié)果不合理。
2) 采用NMI,通過(guò)對(duì)比數(shù)據(jù)集的實(shí)際標(biāo)簽分布和聚類(lèi)后的分布,對(duì)聚類(lèi)結(jié)果進(jìn)行評(píng)價(jià)。合理聚類(lèi)結(jié)果的NMI取值范圍為[0,1],取值越大,聚類(lèi)結(jié)果與真實(shí)情況越吻合。
4.3 測(cè)試結(jié)果分析
最大迭代次數(shù)預(yù)先設(shè)置為100次。對(duì)于DDWK-medoids算法,設(shè)置精度控制參數(shù)NMI取值為0.55、ζ=3。基于SC和NMI,對(duì)2種算法在6個(gè)數(shù)據(jù)集上50次聚類(lèi)結(jié)果的評(píng)價(jià)結(jié)果見(jiàn)表3所列。

表3 2種算法在6個(gè)數(shù)據(jù)集上的聚類(lèi)結(jié)果對(duì)比
由表3可知,在5個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集上,與傳統(tǒng)K-medoids算法相比,除Perfume數(shù)據(jù)集外,DDWK-medoids算法的聚類(lèi)質(zhì)量有顯著優(yōu)勢(shì)。這是由于DDWK-medoids算法能夠消除初始參數(shù)選擇的隨機(jī)性,使得聚類(lèi)結(jié)果總是唯一的,聚類(lèi)過(guò)程更加穩(wěn)定。對(duì)比樣本標(biāo)簽,Perfume數(shù)據(jù)集為多簇?cái)?shù)據(jù)集,DDWK-medoids算法在SC與NMI 2個(gè)評(píng)價(jià)指標(biāo)上均弱于傳統(tǒng)K-medoids算法。
由表3可知,按3.6節(jié)改進(jìn)的DDWK-medoids算法在SC和NMI 2個(gè)評(píng)價(jià)指標(biāo)上均明顯優(yōu)于傳統(tǒng)K-medoids算法,且聚類(lèi)結(jié)果依然穩(wěn)定,由此可見(jiàn) DDWK-medoids算法處理多簇?cái)?shù)據(jù)集的有效性。
對(duì)于多簇?cái)?shù)據(jù)集,改進(jìn)的DDWK-medoids算法聚類(lèi)效果更佳,但挑選出的預(yù)備簇中心數(shù)量較多,在迭代次數(shù)和收斂速度等指標(biāo)上弱于原DDWK-medoids算法。因此,對(duì)于有先驗(yàn)知識(shí)的數(shù)據(jù)集,可選擇有針對(duì)性的參數(shù)設(shè)置策略;對(duì)于沒(méi)有先驗(yàn)知識(shí)的數(shù)據(jù)集,可通過(guò)對(duì)比2種參數(shù)設(shè)置策略下的聚類(lèi)質(zhì)量,擇優(yōu)確定最終的聚類(lèi)結(jié)果。
5 實(shí)例測(cè)試
基于本文檢測(cè)模型對(duì)合肥市2019—2020年的歷史交通數(shù)據(jù)進(jìn)行擬合,并據(jù)此對(duì)2021年5月交通數(shù)據(jù)進(jìn)行預(yù)測(cè),識(shí)別其中可能存在的由集體離群點(diǎn)表征的異常交通狀態(tài)。城市路網(wǎng)交通模型地理邊界由合肥市區(qū)與肥西縣、肥東縣、長(zhǎng)豐縣的邊界及繞城高速公路圈定,在邊界內(nèi)有16 786個(gè)數(shù)據(jù)可用的交通監(jiān)測(cè)點(diǎn)。
5.1 測(cè)試過(guò)程可視化示例
1) 監(jiān)測(cè)點(diǎn)單類(lèi)交通數(shù)據(jù)異常狀態(tài)檢測(cè)。基于單類(lèi)交通數(shù)據(jù)的異常交通狀態(tài)預(yù)測(cè)結(jié)果如圖5所示。對(duì)比樣本數(shù)據(jù)擬合出的歷史變化趨勢(shì),時(shí)刻t1、t2的實(shí)時(shí)交通流量明顯超出歷史流量最高線(xiàn),可判定該分析時(shí)刻內(nèi)監(jiān)測(cè)點(diǎn)采集的交通數(shù)據(jù)構(gòu)成集體離群點(diǎn),區(qū)域交通可能出現(xiàn)異常。

圖5 基于單類(lèi)交通數(shù)據(jù)的異常交通狀態(tài)預(yù)測(cè)結(jié)果
2) 監(jiān)測(cè)點(diǎn)多類(lèi)交通數(shù)據(jù)異常狀態(tài)檢測(cè)。基于歷史數(shù)據(jù)擬合出多類(lèi)交通數(shù)據(jù)變化趨勢(shì)如圖6所示。對(duì)比實(shí)時(shí)采集的交通數(shù)據(jù),[t1,t2]時(shí)間段內(nèi)的各類(lèi)交通流量融合后的變化幅度明顯超過(guò)該時(shí)段的流量歷史最高線(xiàn),因此可判定在該時(shí)段內(nèi)監(jiān)測(cè)點(diǎn)采集的各類(lèi)交通數(shù)據(jù)構(gòu)成集體離群點(diǎn),當(dāng)前區(qū)域的交通狀態(tài)可能出現(xiàn)異常。
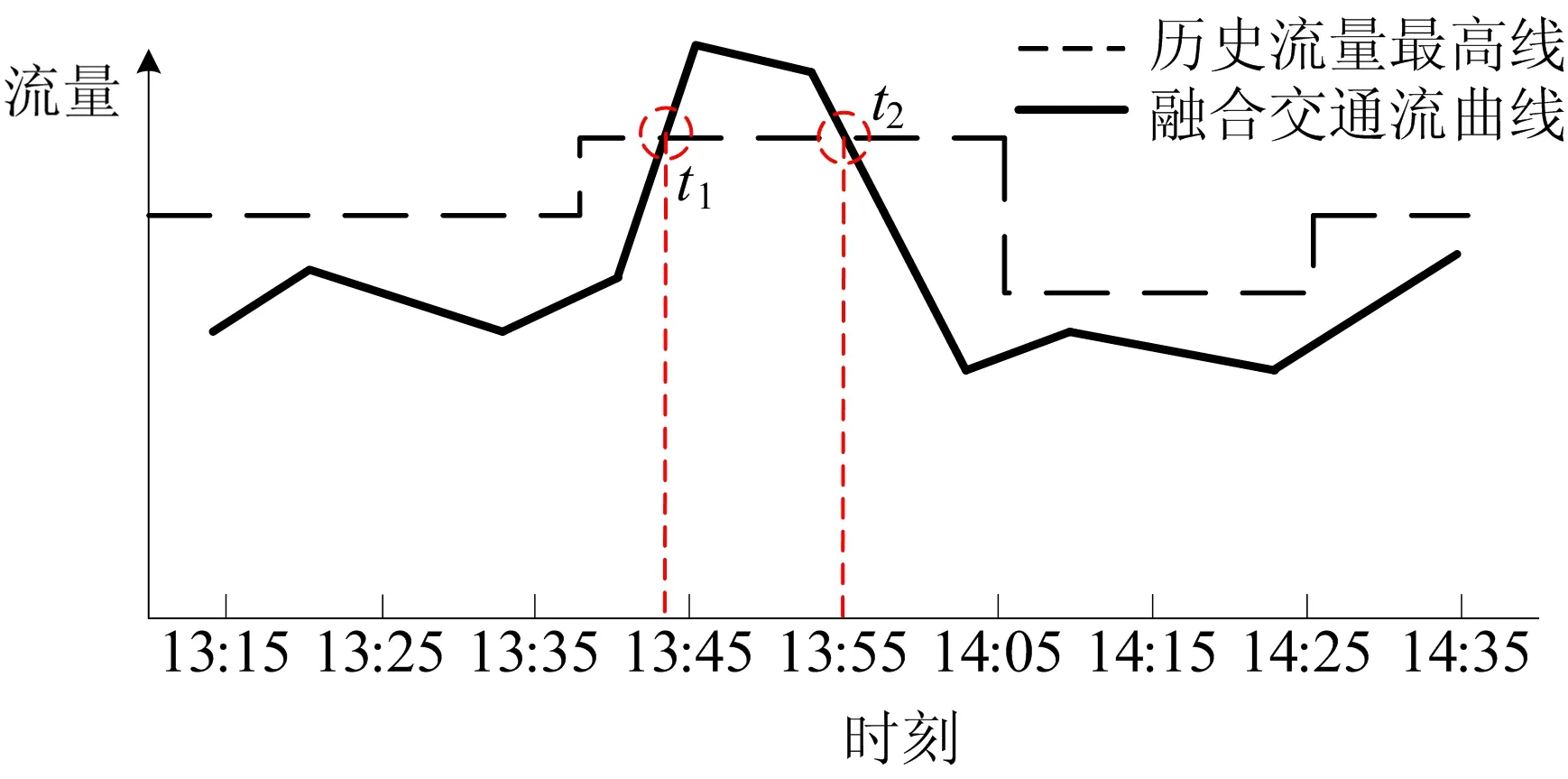
圖6 基于多類(lèi)交通數(shù)據(jù)的異常交通狀態(tài)預(yù)測(cè)結(jié)果
3) 交通樞紐點(diǎn)異常交通狀態(tài)檢測(cè)。基于DDWK-medoids算法確定各時(shí)間間隔內(nèi)的交通樞紐點(diǎn),擬合樞紐點(diǎn)覆蓋范圍內(nèi)交通狀態(tài)的實(shí)時(shí)變化趨勢(shì)。通過(guò)對(duì)比相同時(shí)間內(nèi)交通樞紐點(diǎn)的歷史變化趨勢(shì),檢測(cè)該交通樞紐點(diǎn)覆蓋范圍內(nèi)的交通數(shù)據(jù)中是否存在由多個(gè)監(jiān)測(cè)點(diǎn)共同構(gòu)成的集體離群點(diǎn),并據(jù)此判斷是否出現(xiàn)異常交通狀態(tài)。
對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行分析發(fā)現(xiàn),交通樞紐點(diǎn)的數(shù)量和位置會(huì)隨著不同的時(shí)間發(fā)生變化,主要分為工作日和節(jié)假日期間。標(biāo)定的合肥市路網(wǎng)交通模型如圖7所示(https://map.baidu.com/search/合肥市)。從圖7a可以看出,工作日期間的交通樞紐點(diǎn)有14個(gè);從圖7b可以看出,節(jié)假日期間的交通樞紐點(diǎn)有9個(gè)。
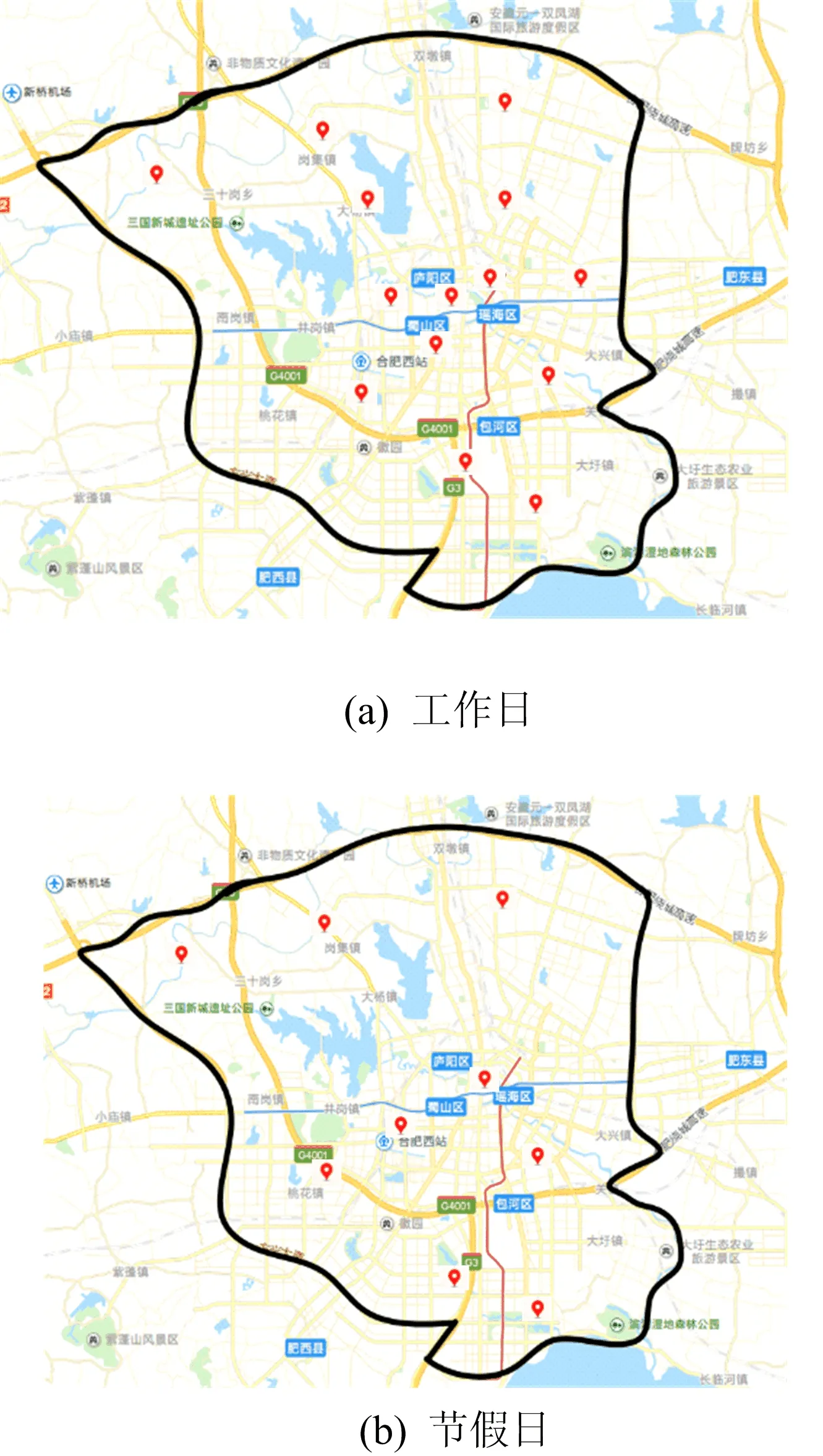
圖7 城市路網(wǎng)交通模型邊界內(nèi)不同時(shí)間下的交通樞紐點(diǎn)分布
基于歷史數(shù)據(jù)擬合出某交通樞紐點(diǎn)的變化趨勢(shì)如圖8所示。

圖8 基于交通樞紐點(diǎn)的異常交通狀態(tài)預(yù)測(cè)結(jié)果
在縱坐標(biāo)上,交通樞紐點(diǎn)往城市中心方向的流量變化標(biāo)記為“+”,背離城市中心方向的流量變化標(biāo)記為“-”。對(duì)比實(shí)時(shí)采集的交通數(shù)據(jù),該交通樞紐點(diǎn)在[t1,t2]和[t3,t4]時(shí)間段內(nèi)對(duì)應(yīng)的交通流量明顯超過(guò)歷史流量最高線(xiàn)。該樞紐點(diǎn)覆蓋范圍內(nèi)的各監(jiān)測(cè)點(diǎn),在該時(shí)間段內(nèi)采集的交通數(shù)據(jù)共同構(gòu)成集體離群點(diǎn),該交通樞紐點(diǎn)覆蓋范圍內(nèi)的交通狀態(tài)可能出現(xiàn)異常。
4) 交通中心點(diǎn)異常交通狀態(tài)檢測(cè)。計(jì)算交通樞紐點(diǎn)的中心點(diǎn),根據(jù)歷史交通數(shù)據(jù)擬合交通中心點(diǎn)位置變化趨勢(shì),如圖9所示。圖9中:虛線(xiàn)為基于歷史數(shù)據(jù)擬合出的交通中心點(diǎn)位置的變化趨勢(shì);在縱坐標(biāo)上,將中心點(diǎn)往城市中心方向的距離變化標(biāo)記為“+”,背離城市中心方向的距離變化標(biāo)記為“-”。
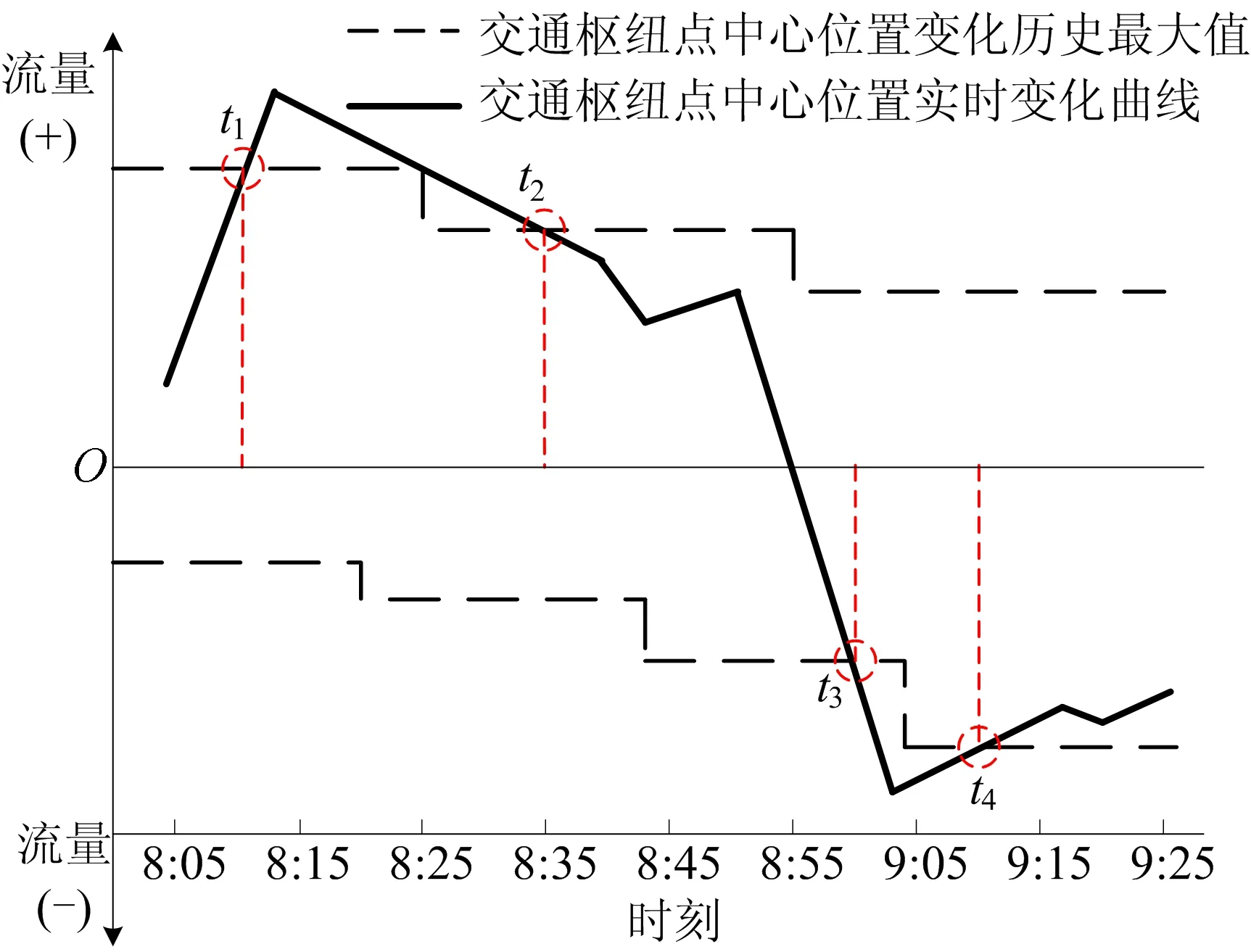
圖9 基于交通中心點(diǎn)的異常交通狀態(tài)預(yù)測(cè)結(jié)果
對(duì)比實(shí)時(shí)采集的交通中心點(diǎn)位置變化數(shù)據(jù),中心點(diǎn)在[t1,t2]和[t3,t4]時(shí)間段內(nèi)的位置偏移量明顯超過(guò)歷史最高值,即表明存在由多個(gè)交通樞紐點(diǎn)共同構(gòu)成的集體離群點(diǎn)。通過(guò)進(jìn)一步判斷中心點(diǎn)位置異常變化的方向,可識(shí)別出現(xiàn)交通狀態(tài)異常的具體樞紐點(diǎn)及其覆蓋范圍。
5.2 測(cè)試結(jié)果
通過(guò)擬合2019—2020年的歷史交通數(shù)據(jù)樣本,對(duì)2021年5月交通數(shù)據(jù)進(jìn)行預(yù)測(cè)。樣本標(biāo)注的異常交通狀態(tài)指對(duì)城市交通流暢性產(chǎn)生顯著影響的交通故障,即在城市路網(wǎng)中出現(xiàn)明顯的交通能力下降、交通流失效、磁滯等現(xiàn)象,并非實(shí)際交通事故報(bào)警統(tǒng)計(jì)。5月單日內(nèi)不同時(shí)間段交通異常度量的箱線(xiàn)圖分布如圖10所示。
從圖10可以看出,工作日出現(xiàn)的交通異常遠(yuǎn)多于周末或節(jié)假日,尤其是時(shí)間段[7,9)、[13,15)、[19,21)。其中[7,9)為早高峰時(shí)間段,[13,15)為午飯和上班、上學(xué)時(shí)間段,[19,21)為晚高峰時(shí)間段,均與實(shí)際交通狀況相符。
5月逐5 d預(yù)測(cè)結(jié)果準(zhǔn)確率與誤報(bào)率見(jiàn)表6所列,預(yù)測(cè)的平均準(zhǔn)確率為91.46%,平均誤報(bào)率為4.46%。預(yù)測(cè)準(zhǔn)確率是指與實(shí)際故障標(biāo)簽對(duì)比,正確預(yù)測(cè)的交通故障概率,為預(yù)測(cè)的交通故障標(biāo)簽數(shù)與標(biāo)定的實(shí)際交通故障標(biāo)簽數(shù)的比值。誤報(bào)率是指將正常交通狀態(tài)誤識(shí)別為異常狀態(tài)的概率,為誤識(shí)別次數(shù)與正確預(yù)測(cè)次數(shù)的比值。

表6 5月逐5 d檢測(cè)結(jié)果與實(shí)際標(biāo)簽對(duì)比結(jié)果
5.3 對(duì)比實(shí)驗(yàn)
對(duì)比實(shí)驗(yàn)選擇北京城市交通數(shù)據(jù)(https://www.beijingcitylab.com/),實(shí)驗(yàn)主要對(duì)比線(xiàn)上檢測(cè)結(jié)果的效率,對(duì)比算法選擇狄利克雷過(guò)程混合模型(Dirichlet process mixture model,DPMM)[23]、主成分分析 (principal component analysis,PCA) 法[4]及流量矩陣法SETMADA (Simultaneously Estimate Traffic Matrix and Detect Anomaly)[24]。
本文算法與對(duì)比算法在測(cè)試數(shù)據(jù)集上的運(yùn)行時(shí)間如圖11所示。
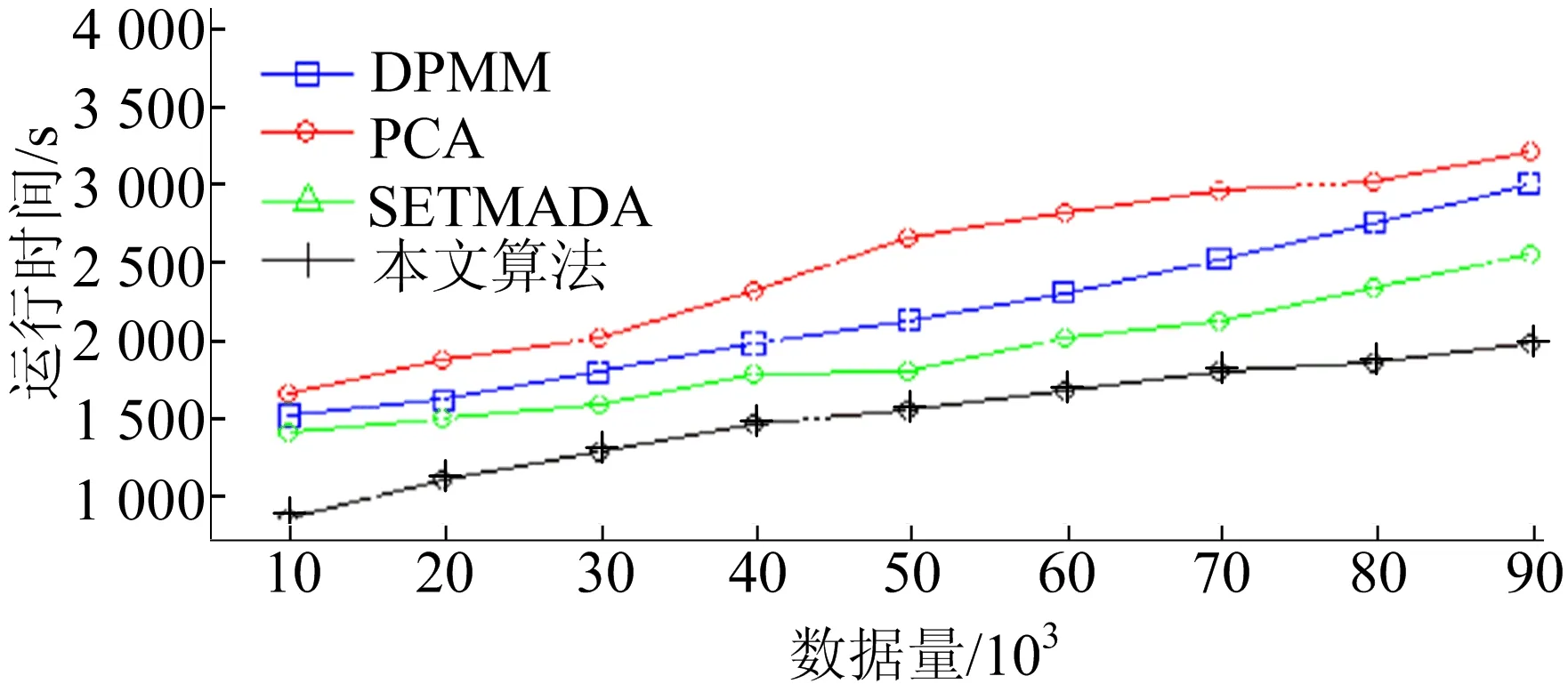
圖11 本文算法與對(duì)比算法在測(cè)試數(shù)據(jù)集上的運(yùn)行時(shí)間曲線(xiàn)
在本文檢測(cè)模型中,數(shù)據(jù)的時(shí)間屬性,如某個(gè)交通數(shù)據(jù)產(chǎn)生的具體時(shí)刻信息,未直接參與到模型計(jì)算中,其地理位置的空間屬性也通過(guò)坐標(biāo)轉(zhuǎn)換的方式降低了復(fù)雜度,因此,在不同數(shù)據(jù)量上的運(yùn)行速度明顯優(yōu)于3種對(duì)比算法。
4種算法不同數(shù)據(jù)量下檢測(cè)的準(zhǔn)確率如圖12所示。從圖12可以看出,本文檢測(cè)模型在大規(guī)模數(shù)據(jù)處理上具有明顯優(yōu)勢(shì),能夠從大量樣本數(shù)據(jù)集中不斷完善數(shù)據(jù)擬合程度。
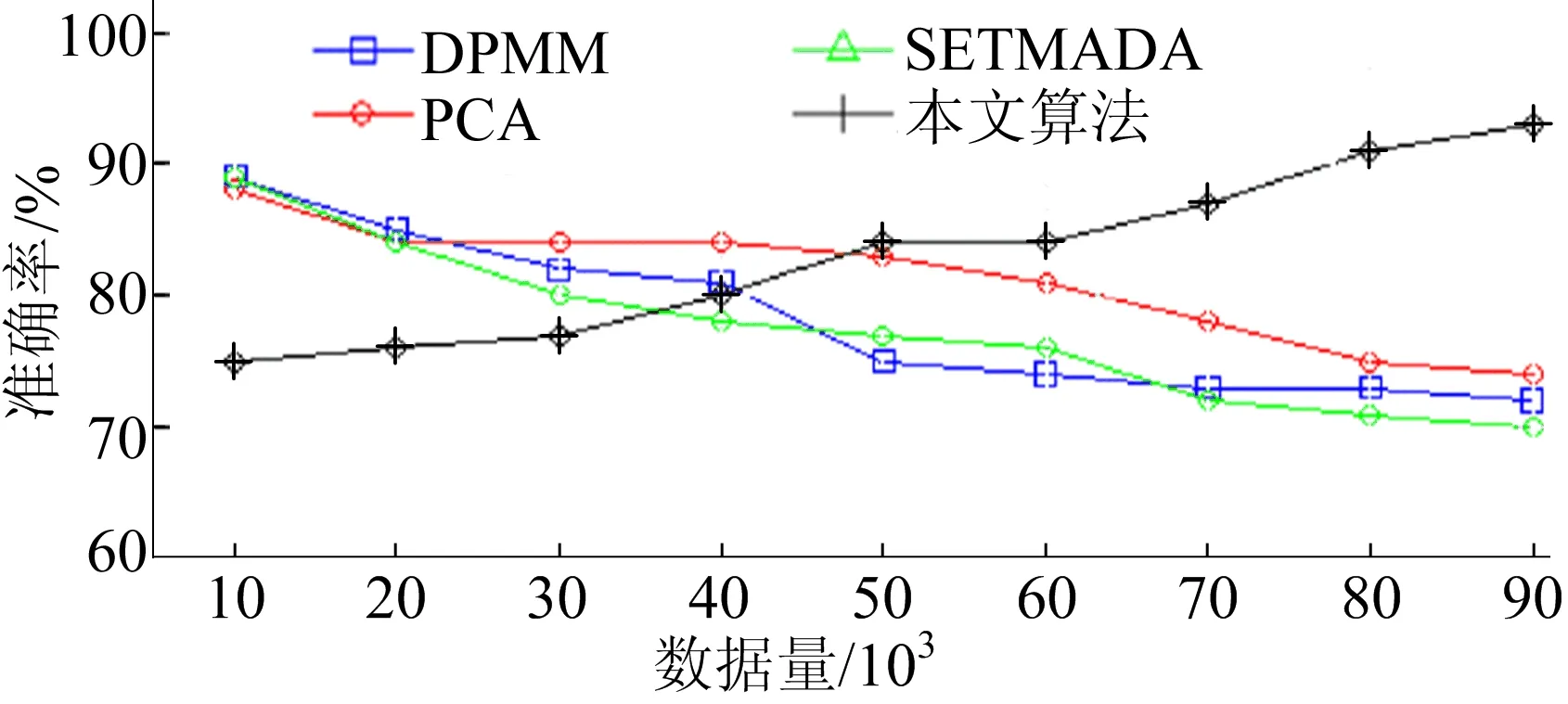
圖12 本文算法與對(duì)比算法在測(cè)試數(shù)據(jù)集上的準(zhǔn)確率曲線(xiàn)
6 結(jié) 論
本文提出基于集體離群點(diǎn)挖掘的城市交通異常檢測(cè)方法,其核心思想是將城市交通異常模式檢測(cè)問(wèn)題轉(zhuǎn)換為面向多源交通數(shù)據(jù)流的集體離群點(diǎn)挖掘問(wèn)題,實(shí)例測(cè)試和對(duì)比實(shí)驗(yàn)結(jié)果表明,本文算法具有以下優(yōu)勢(shì):
1) 提高異常檢測(cè)準(zhǔn)確性。從多個(gè)粒度對(duì)城市交通數(shù)據(jù)進(jìn)行融合分析時(shí),變化程度的疊加效應(yīng)有助于更加準(zhǔn)確地發(fā)現(xiàn)潛在交通異常。基于集體離群點(diǎn)挖掘,不僅可識(shí)別單一監(jiān)測(cè)點(diǎn)上由多數(shù)據(jù)流共同反映的集體異常,還可識(shí)別交通樞紐點(diǎn)覆蓋范圍內(nèi)多個(gè)監(jiān)測(cè)點(diǎn)共同構(gòu)成的集體異常。結(jié)果表明本文算法對(duì)交通異常狀態(tài)預(yù)測(cè)的平均準(zhǔn)確率為91.46%,平均誤報(bào)率為4.46%;在對(duì)比實(shí)驗(yàn)中,隨樣本數(shù)據(jù)量增大,檢測(cè)準(zhǔn)確率呈上升趨勢(shì)。
2) 降低模型計(jì)算復(fù)雜度。在DDWK-medoids算法模型中,數(shù)據(jù)的時(shí)間屬性與空間屬性未以數(shù)值的形式直接參與計(jì)算,有效降低了運(yùn)算復(fù)雜度,檢測(cè)效率顯著提高。實(shí)驗(yàn)表明,對(duì)于不同數(shù)據(jù)量的樣本數(shù)據(jù)集,本文算法處理速度均明顯高于對(duì)比算法。
3) 線(xiàn)下與線(xiàn)上相結(jié)合提高檢測(cè)效率。擬合階段屬于線(xiàn)下處理,既保留了大數(shù)據(jù)實(shí)證分析帶來(lái)的高精度優(yōu)勢(shì),也不影響基于集體離群點(diǎn)挖掘的交通狀態(tài)實(shí)時(shí)預(yù)測(cè)效率。實(shí)時(shí)檢測(cè)階段可以將流量異常檢測(cè)與軌跡異常檢測(cè)結(jié)合起來(lái),進(jìn)一步提高檢測(cè)的有效性。實(shí)驗(yàn)表明,樣本數(shù)據(jù)量越大,本文算法的線(xiàn)下擬合越準(zhǔn)確,檢測(cè)準(zhǔn)確率越高。
猜你喜歡
中國(guó)設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:36
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年9期)2019-11-25 07:34:34
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:50
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年12期)2019-05-21 02:53:48
 合肥工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版)2023年9期
合肥工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版)2023年9期
- 合肥工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版)的其它文章
- 《合肥工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版)》歡迎投稿
- 《合肥工業(yè)大學(xué)學(xué)報(bào)(自然科學(xué)版)》專(zhuān)欄征稿啟事
- 基于冰川流速的喀喇昆侖地區(qū)典型冰川厚度反演與冰儲(chǔ)量估算
- 流體慣性效應(yīng)和裂隙幾何屬性對(duì)非達(dá)西系數(shù)的影響
- 用于手部康復(fù)的熱塑性聚氨酯軟體驅(qū)動(dòng)器研究
- 基于HS-SPME-GC-MS與OAV對(duì)5種臭鱖魚(yú)產(chǎn)品特征風(fēng)味的分析