Apriori算法及神經網絡在數控機床中應用研究
2023-10-12 03:08:22郭俊王穎李卓鄧國群
機床與液壓 2023年18期
關鍵詞:模型
郭俊,王穎,李卓,鄧國群
(湖南汽車工程職業學院信息工程學院,湖南株洲 412001)
0 前言
質量和效率是工業制造永恒的主題,在金屬切削加工智能制造中,影響質量和效率的關鍵裝備是數控機床。數控機床屬于精密制造裝備,雖然在出廠時自身的技術指標均能達到相應水準,但是應用在實際產線時,其加工精度會受夾具、刀具、環境溫度、振動、部件老化、工件材料一致性等因素影響[1]。而且,隨著機械設備的不斷使用,其穩定性及精準度逐步降低,勢必影響加工環節誤差,進而影響后續工藝[2-3]。
現階段,有關各類誤差補償方法的研究有很多。文獻[4]利用旋轉進給軸熱誤差對數控機床進行補償。文獻[5]分析了數控機床在檢測中觸發式測頭誤差的變速補償。文獻[6]引入符合阿貝原則的數控機床幾何誤差進行建模,并推導出XYFZ型三軸機床適用的HTM幾何誤差補償模型,以及給出模型正確使用的前提條件。文獻[7]提出了基于LSTM循環神經網絡的數控機床熱誤差預測方法,并利用聚類算法構建神經網絡模型。上述方法大多專注于某種設備類型的某項指標進行誤差補償,其補償效果有限、可復用性低。
而Apriori算法可快速發現海量數據集中的相關性,神經網絡算法對于處理大量非結構化的工業大數據有獨特的優勢,能夠有效補償產品實際加工中產生的誤差,大幅提升產品穩定性及精準度。因此,本文作者基于Apriori算法及神經網絡方法,利用生產實踐中產生的大量數據,找出不同狀態下最優的補充參數,為運行中的車床提供即時、智能、精確的參數補償策略,確保數控機床的穩定。
1 相關分析
1.1 關聯規則分析
關聯規則反映事物之間的關聯性[8],能夠從數據集中發現2個或多個數據之間的相關關系,即從數據集中找到出現高頻次數的項目集,也稱頻繁項集。關聯規則廣泛應用于數據挖掘中,其具體概念如下:
定義1:已知集合F={f1,f2,…,fk},集合中的每個元素稱為數據項,集合F稱為項集,集合F中的數據長度稱為項集長度,包含k個長度的項集稱為k-項集。事物數據庫集用D表示,對于每一個子事物集用T表示。設D是交易T的集合,T?F,設M是F的項集,如果M?T,稱T包含M。
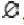
(1)
置信度fconfidence(M?N),表示包含M、N的交易數與包含M的交易數之比,如式(2)所示:
(2)
定義3:為了對關聯規則進行量化和評估,設定min_sup值(最小支持度)和min_conf(最小置信度),對于項集M,如果支持度不小于min_sup值,且置信度不小于min_conf值,則項集M即為頻繁項集。
1.2 Apriori算法分析
Apriori算法是實現關聯規則最經典的算法[9],其原理是逐層迭代搜索。首先對數據集進行掃描,得到一維候選項集,利用設定的最小支持度,對一維候選項集進行剪枝,得到新的頻繁項集,再由頻繁項集連接成新的二維候選項集。Apriori算法通過k-1項集尋找k項集,不斷重復剪枝步和連接步,直到最大頻繁項集為空時,結束迭代過程。其剪枝步和連接步原理如下:
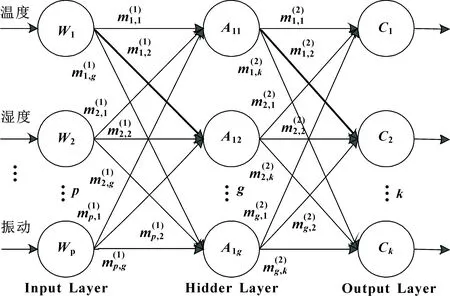
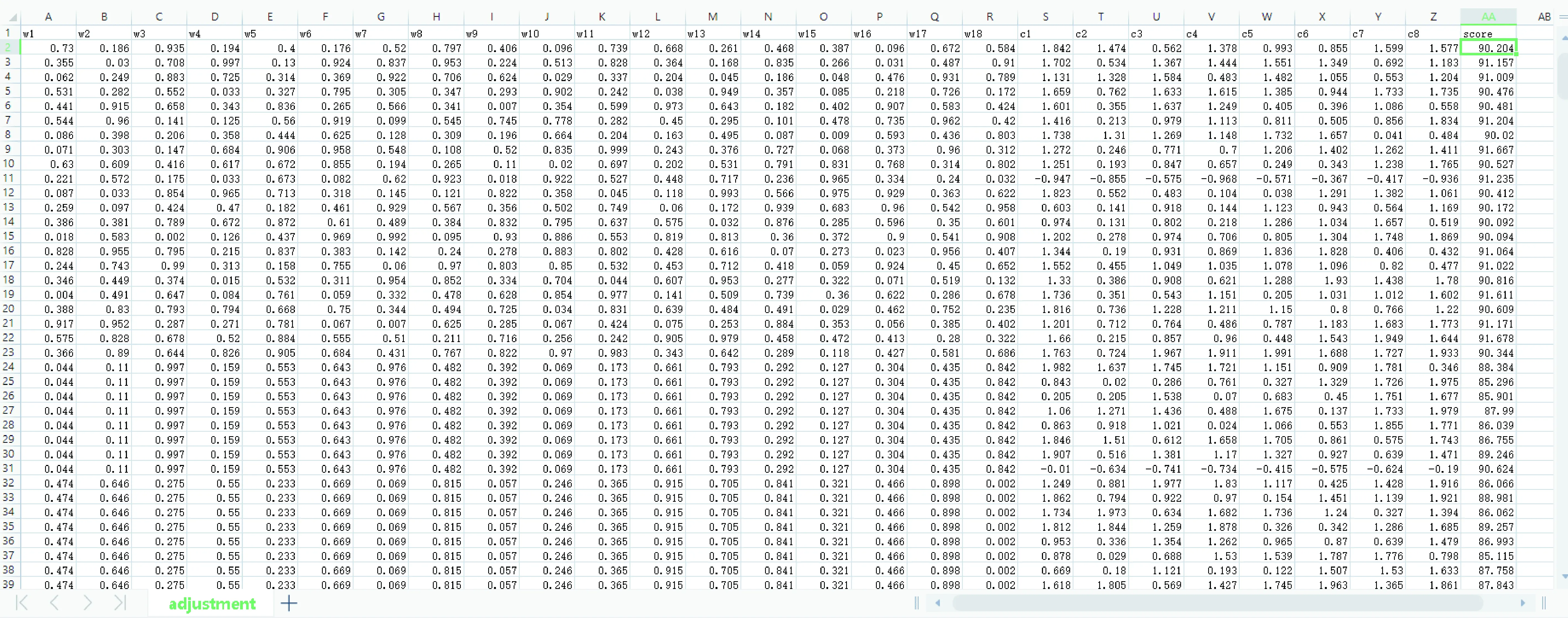
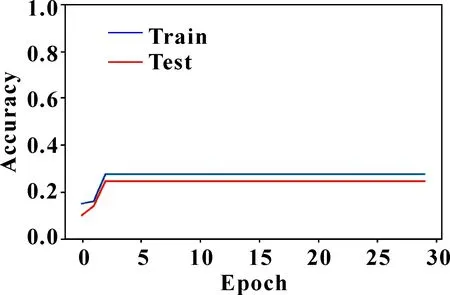
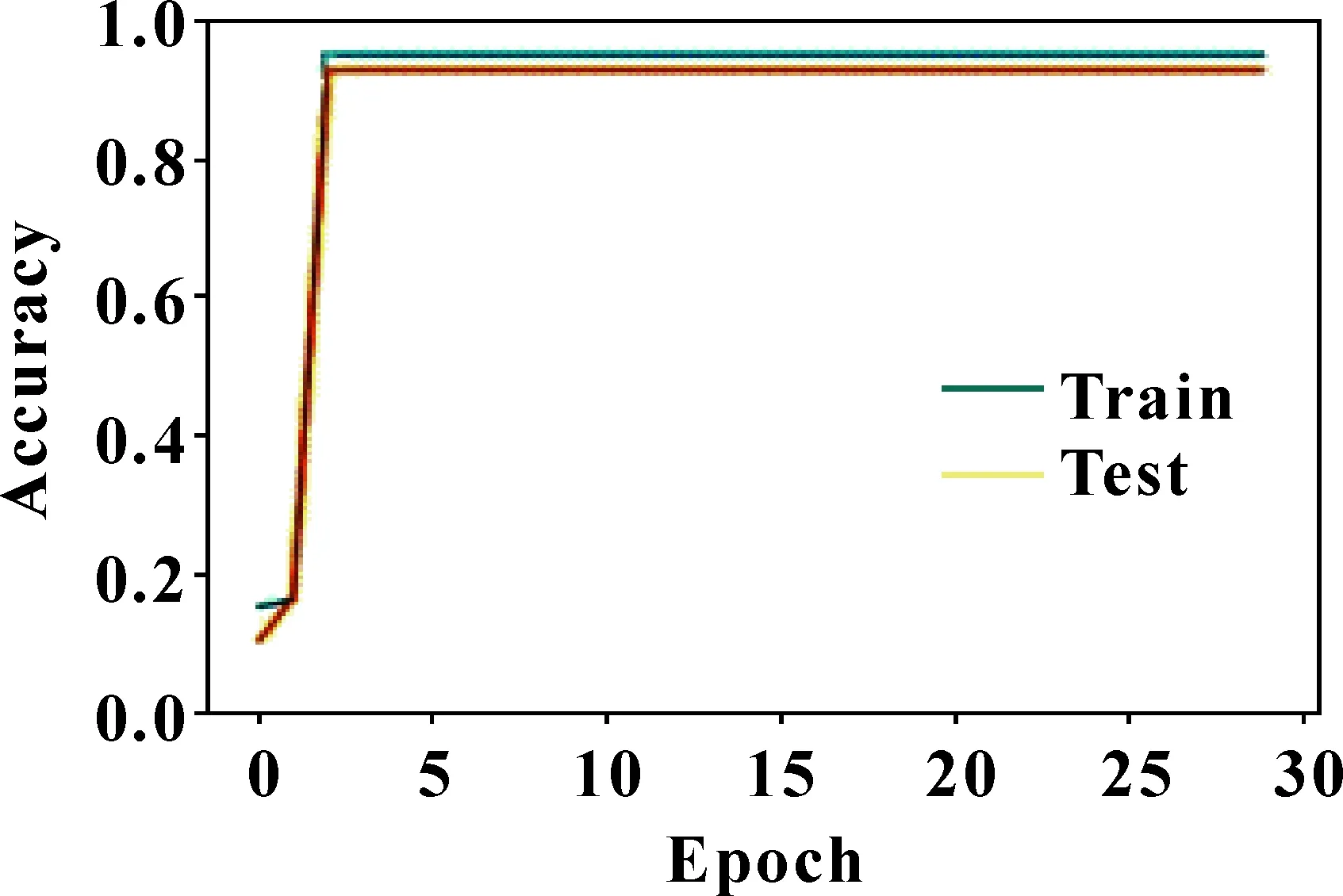
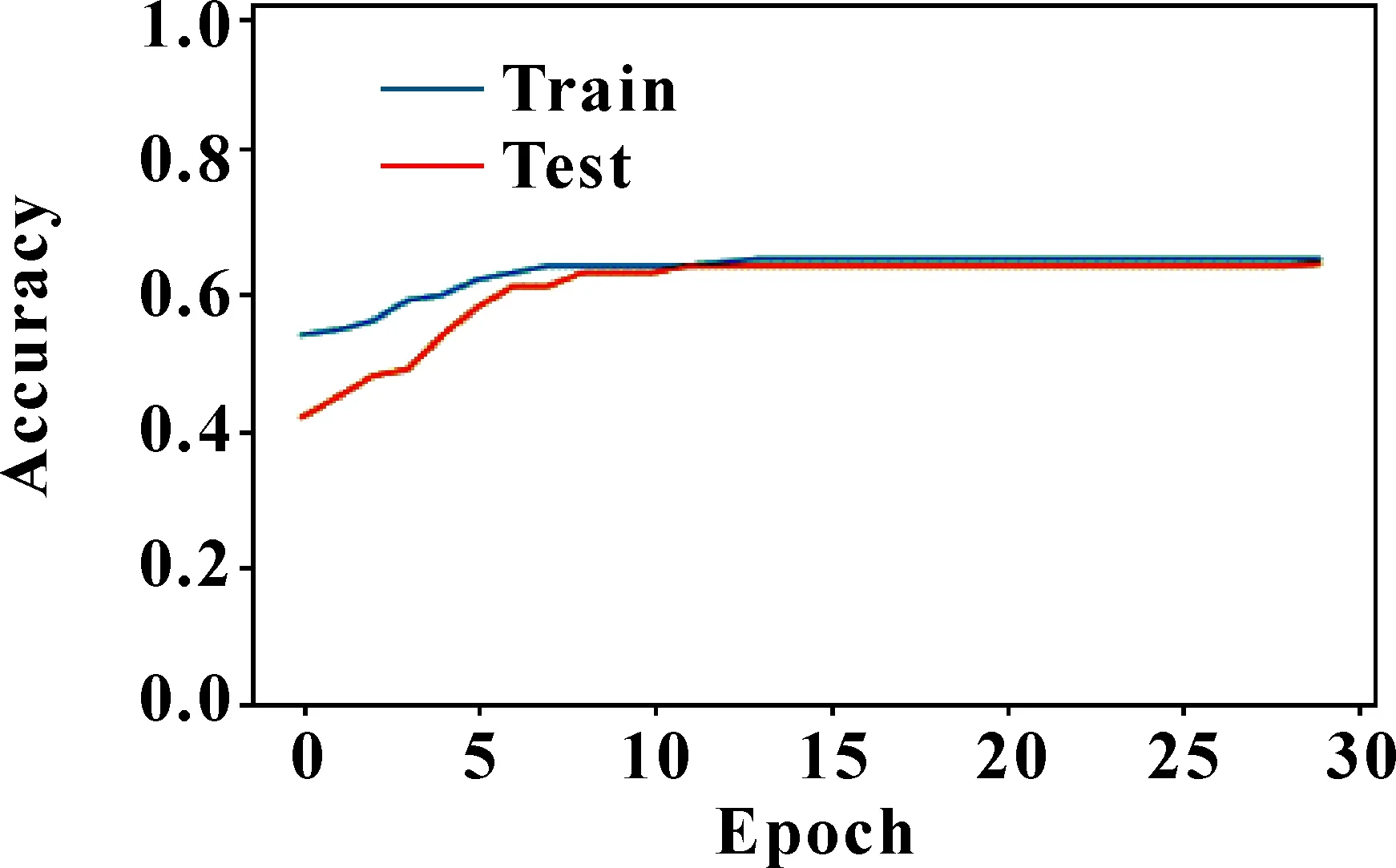
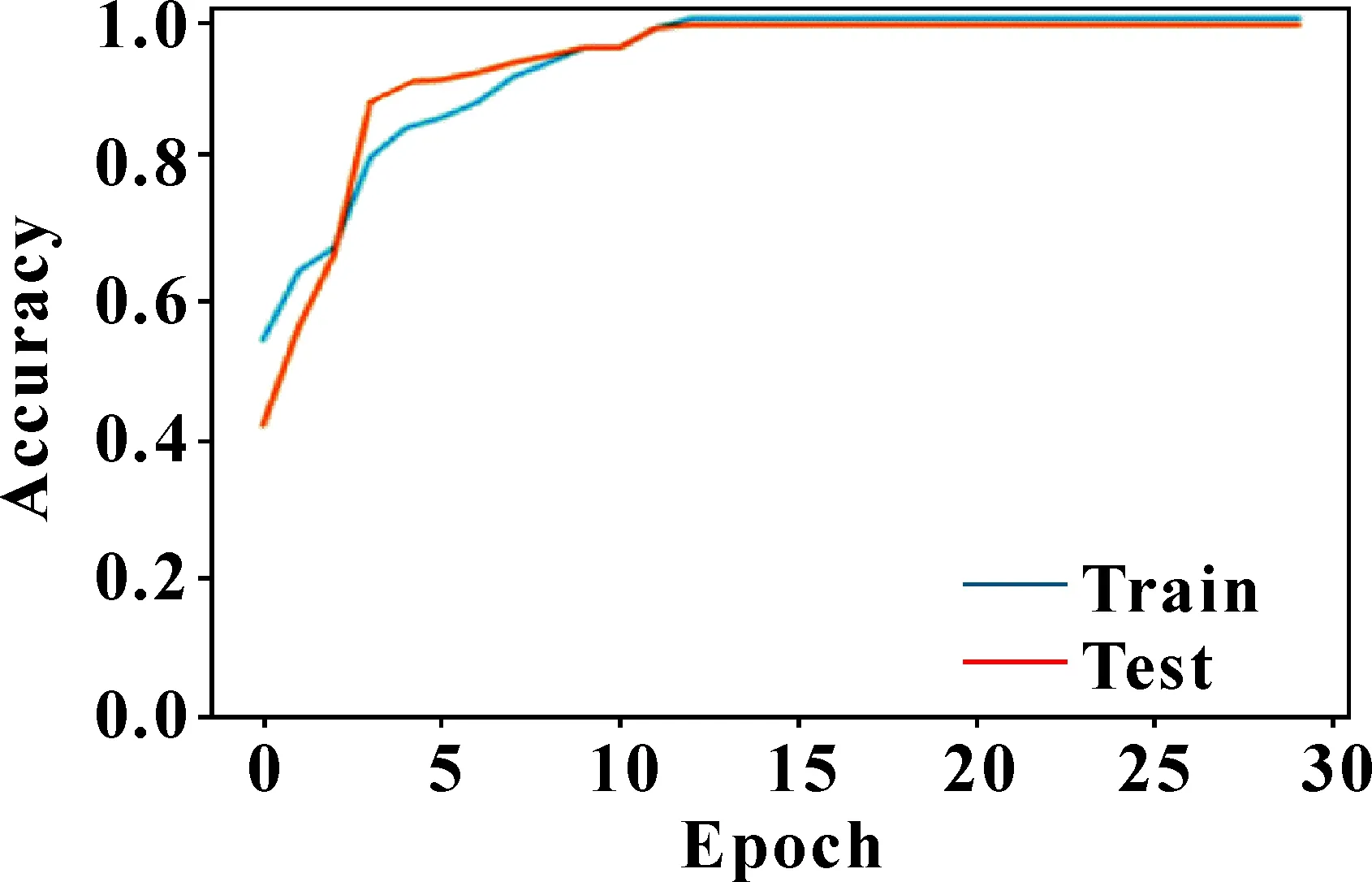
連接步:由k-1項集Lk-1與本身相連得到頻繁項集Ck,記L1、L2為Lk-1前2個項集,設Li,[j]為任意子集第j項,如果兩子集前k-2項相同,即(L1,[1]=L2,[1]∧L1,[2]=L2,[2]∧…∧L1,[k-2]=L2,[k-2]∧L1,[k-1] 剪枝步:Apriori算法的超集Ck可能是頻繁,也可能不頻繁,但所有頻繁k-項集必在Ck中,因此,對k-項集Ck中所有(k-1)進行剪枝,刪除所有非頻繁(k-1)項子集,再由支持度得到Lk。 圖1 全連接神經網絡模型 神經網絡的訓練在于調整隱藏層的層數及各層權重,輸出層節點的取值即為每層加權和,比如圖1中A11、C1值分別如公式(3)、(4)所示: (3) (4) 同理,可求出A12,…,A1g的值及C2,…,Ck的值,具體如公式(5)(6)所示: [A11,A12,…,A1,g]=[W1,W2,…,Wp]· (5) [C1,C2,…,Ck]=[A11,A12,…,A1g]· (6) 誤差補償模型可分為兩部分,第一部分為智能誤差補償模塊。由于數據集中各特征值相差較大,先對數據集做0-1歸一化處理,使它落入一個特定區間,以消除數值因大小不一造成挖掘效果偏差,從而提高數據收斂速度,有利于尋找全局最優解;再利用Apriori算法對生產企業提供的數據集進行篩選,得到更具針對性的數據集;之后利用神經網絡方法調整參數,通過不斷更新神經網絡模型參數,構建合適的智能誤差補償模型;最后將訓練好的誤差補償算法模型部署至云平臺,用于加工誤差精度補償,從而減少機床加工誤差。第二部分為視覺檢測模塊。先把合格與不合格2類樣本圖片作為訓練數據上傳至云平臺;之后將圖片縮放到合適尺寸,得到高質量的圖片數據;再利用神經網絡方法,訓練選取的圖片,使計算機掌握分辨工件合格與否的能力;最后將訓練好的模型部署至云平臺,用于驗證工件是否合格。 利用誤差補償模型生產的工件,通過視覺檢測模塊辨別,區分為合格或不合格工件。如果不合格工件過多,則應重新調整誤差補充算法。 系統整體設計如圖2所示。 圖2 系統整體設計 某企業提供的adjustment文件中,對于相同w1,w2,…,w18特征值,會對應不同c1,c2,…,c8補償參數,具體如圖3所示。另外,每一個補償參數值在c1,c2,…,c8中出現次數有所不同,比如1.842在c1,c2,…,c8中出現次數分別為13次、3次、2次、1次、1次、0次、11次、6次。當1.842出現次數為13次和11次時,score值大于等于90,當1.842出現次數在11次以下時,score值小于90。因此,利用第1.1節中關聯規則及第1.2節中Apriori算法,通過設定最小支持度,對于1.842作為c1,c2,…,c8補償參數,c1和c7兩列具有相關性,這兩列對于1.842予以保留,其余列對于1.842予以刪除。同理,利用關聯規則及Apriori算法找出其余補償數據在c1,c2,…,c8間的關聯性,從而得到更具針對性數據集。 圖3 相同特征值不同補償參數所得結果不同 Apriori算法偽代碼如下: Input:某企業工件生產事物數據庫DataBase。最小支持度閾值min_sup。 Output:DataBase中最大頻繁項集L。 (1)L1=find_frequent_1-itemsets(DataBase) (2)for(k=2;Lk-1≠f;k++) (3)Ck=apriori_gen(Lk-1,min_sup) (4)for each transactiont∈DataBase do{ (5)Ct=subset(Ck,t); (6)for each candidatec∈Ct (7)c.count++;} (8)Lk={c∈Ck|c.count>=min_sup} (9)returnL=UkLk; 其中:L是頻繁項集;C是候選項集;apriori_gen是實現由頻繁項集Lk-1生成候選項集Ck的過程。 依據某企業提供的相關文件adjustment.csv,利用第1.3節神經網絡算法,對誤差補償算法進行訓練部署,使數控系統具有誤差自動補償功能,在實際加工中,能有效提高工件生產合格率。adjustment.csv文件中共有9 999條數據,部分數據如圖4所示。 圖4 adjustment文件中部分數據 上圖中:w1,w2,…,w18分別表示刀具磨損、溫度、濕度等外部影響因素;c1,c2,…,c8為外部補償參數;score值為工件合格評判標準,若score大于等于90分則工件合格,若score小于90分則工件不合格。 智能誤差補償算法具體實現步驟如下: 步驟1,數據清洗。數控機床加工中,會產生許多有問題的數據,比如殘缺數據、噪聲數據和冗余數據,這些臟數據對數據分析會有較大影響。而文中所用數據集,w1,w2,…,w18特征值中有很多Null值,即空值。因此,對于這些殘缺值,使用均值a代替,具體如公式(7)所示: a=(w1+w2+…+w18)/18 (7) 步驟2,數據歸一化處理。神經網絡中數據之間往往具有不同的量綱,為了消除不同量綱的數據影響,需要對數據進行歸一化處理,使它落定在一個特定區間。數據歸一化能夠提高收斂速度,有利于尋找全局最優解。常見的數據歸一化有最大-最小標準化、0-1標準化、零-均值標準化。由于步驟1采用均值填充空值,因此文中采用0-1標準化。具體如公式(8)(9)所示: s2=[(w1-a)2+(w2-a)2+...+(w18-a)2]/18 (8) x*=[(w1+w2+w3...+w18)-a]/s (9) 其中:s2表示方差;s表示標準差;x*表示歸一化后的數據。 步驟3,誤差補償算法模型訓練。利用第1.3節神經網絡模型,構建神經網絡誤差補償算法模型,模型輸入層節點18個,分別為特征值w1,w2,…,w18;輸出層節點8個,分別對應r1,r2,…,r8,利用pycharm中TensorFlow的 tf.keras.Sequential函數,通過不斷更新網絡參數,得到最優模型。誤差補償算法模型偽代碼如下: model = tf.keras.Sequential([ layers.Dense(512,input_dim=train_features.shape[1],activation="relu"), layers.Dense(512,activation="relu"), layers.Dense(512,activation="relu"), layers.Dense(train_labels.shape[1])]) model.compile(optimizer=tf.keras.optimizers. SGD(learning_rate=lr,momentum=0.9, loss="mse",nesterov=True,clipvalue=0.5, decay=lr/epochs_number),metrics=['acc']) 步驟4,誤差補償算法模型訓練部署。將訓練好的誤差補償算法模型部署至云平臺,用于加工誤差精度補償,從而減少機床加工誤差。 通過工業視覺進行工件訓練,采集合格與不合格樣本,并進行數據預處理、云平臺存儲,利用第1.3節神經網絡算法,通過設定相應參數進行模型訓練和部署。訓練好的模型能夠返回待測工件和標準件的相似度,使設備具有識別合格品和不合格品工件的功能。 視覺檢測算法具體實現步驟如下: 步驟1,數據采集。利用視覺系統進行若干工件圖像數據采集,確定工件樣本圖像數據庫。 步驟2,數據預處理。對圖片進行相關處理,選擇質量高的圖片進行訓練。 步驟3,視覺檢測模型訓練。調用Pycharm中TensorFlow的 tf.keras.Sequential函數,通過不斷更新網絡參數,得到最優模型。視覺檢測模型偽代碼如下: model=tf.keras.Sequential([ layers.experimental.preprocessing.Rescaling(1./127.5,offset=-1), layers.MaxPooling2D(), layers.Conv2D(64,3,activation=‘relu’), layers.MaxPooling2D(), layers.Conv2D(128,3,activation=‘relu’), layers.MaxPooling2D(), layers.Conv2D(256,3,activation=‘relu’), layers.Conv2D(512,3,activation=‘relu’), layers.MaxPooling2D(), layers.Flatten(), layers.Dense(128,activation=‘relu’), layers.Dense(num_classes),]) model.compile(optimizer=‘adam’, loss=‘sigmoid’,metrics=[‘accuracy’]) 其中:activation=‘relu’為神經網絡激活函數;loss=‘sigmoid’為損失函數;optimizer=‘adam’為選擇器。 步驟4,視覺檢測模型部署。將訓練好的視覺檢測模型部署至云平臺,用于識別合格與不合格的工件。 (1)誤差補償模型仿真測試 將數據集分為訓練集數據和測試集數據,訓練集數據用于模型訓練,測試集數據用于模型驗證。利用Pyhton框架下的神經網絡模型進行仿真測試,通過循環迭代,直至尋找到神經網絡模型各參數最優解。仿真測試可分為2種情況:一種不對數據進行任何處理,得到圖5所示結果;另一種對數據進行關聯分析、歸一化等數據預處理,得到圖6所示結果。 對比圖5、6可以看出:如果不對數據做任何處理,隨著訓練次數的增加,訓練集數據和測試集數據精度雖然都有增加,但訓練集數據和測試集數據最高精度也只有0.275、0.247;如果對數據集進行關聯性、歸一化處理,且利用第3.2節訓好練的神經網絡智能誤差補償算法,則訓練集數據集和測試集數據集的最高精度分別可達0.97和0.96,精度較之前分別提高0.695和0.713。由此可見,神經網絡智能誤差補償算法能夠提高加工精度穩定性。 圖5 數據不做任何處理結果 圖6 對數據集處理后結果 (2)視覺檢測模型仿真測試 通過工業視覺進行工件訓練對合格與不合格樣本數據采集,可分2種情形:一種是采集圖片數量較少、圖片質量較差,得到圖7所示結果;另一種是采集圖片數量多、圖片質量好,且通過不斷進行神經網絡模型訓練,得到圖8所示結果。 對比圖7、8可以看出:如果不對圖片做任何處理,隨著模型訓練次數的增加,訓練數據集和測試數據集的精度最高可達0.65和0.635;如果對圖片進行相關處理,且利用第3.3節視覺檢測算法,則訓練集和測試集數據的精度分別可達0.99和0.91,精度較之前分別提高0.34和0.275。由此可見,神經網絡視覺檢測算法能大大提高物件合格與不合格檢測率。 圖7 圖片未作處理 圖8 圖片相關處理 (3)實際測試 準備30個物料,用于實際加工,物料加工槽如圖9所示。通過傳送帶,把物料傳送至雕刻臺,逐一雕刻,如圖10所示。在雕刻過程中,云平臺會通過智能誤差補償算法,用于加工誤差精度補償,從而提高產品合格率。雕刻完成后,通過視覺檢測算法,驗證工件圖片是否合格。結果表明:30個雕刻物料都合格,合格率100%,具體如圖11所示。 為解決數控機床加工精度穩定性問題,提出了一種基于Apriori算法及神經網絡的智能模型。為提高數據有效性,采用Apriori算法進行數據關聯性挖掘。為解決實際加工中加工精度受機床零部件、外部環境等因素的影響,采用神經網絡構建智能誤差補償模型,提供即時、智能、精確的補償方案。 為驗證誤差補償模型對數控機床穩定性影響,采用神經網絡構建視覺檢測模型,對加工產品進行識別,判斷其是否合格,并統計合格率。仿真結果表明:文中構建的誤差補償模型能夠使訓練集數據和測試集數據的精準度分別達到0.97和0.96,并且文中構建的視覺檢測模型能夠對測試集數據和訓練集數據進行了有效識別,精度分別為0.99和0.91。實驗結果表明:所有產品都符合精度要求,上述模型能夠解決數控機床加工中穩定性問題。下一步的研究可以考慮加入聚類算法,結合神經網絡訓練數據集,并引入更大的數據集進行實驗測試,分析其穩定性。1.3 神經網絡算法分析
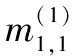
2 誤差補償模型
3 算法實現
3.1 基于Apriori算法的關聯規則實現

3.2 基于神經網絡智能誤差補償算法實現
3.3 基于神經網絡視覺檢測算法實現
4 結果測試
5 結語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
