中文新聞文本多文檔摘要生成
2023-10-12 01:28:56李寶安佘鑫鵬常振寧呂學(xué)強(qiáng)游新冬
計算機(jī)工程與設(shè)計 2023年9期
李寶安,佘鑫鵬,常振寧,呂學(xué)強(qiáng),游新冬
(北京信息科技大學(xué) 網(wǎng)絡(luò)文化與數(shù)字傳播北京市重點(diǎn)實驗室,北京 100101)
0 引 言
隨著深度學(xué)習(xí)在文本摘要領(lǐng)域的不斷發(fā)展[1-5],基于深度學(xué)習(xí)的文本摘要技術(shù)[6],成為實現(xiàn)新聞自動化生產(chǎn)的方法之一。文本摘要技術(shù)始于抽取式摘要,近年逐漸發(fā)展為應(yīng)用深度學(xué)習(xí)技術(shù)的生成式摘要,而在生成式摘要的領(lǐng)域內(nèi),又逐漸由單文檔摘要發(fā)展為多文檔摘要。生成式摘要較抽取式摘要更簡潔連貫、概括性更強(qiáng),多文檔摘要較單文檔摘要可處理更多文獻(xiàn)、摘要信息更豐富。多文檔生成式摘要技術(shù)既可用于生成文摘,亦可用于聚合式寫作,是新聞自動化生產(chǎn)的核心技術(shù)。
本文針對新聞自動化生產(chǎn)的問題,基于Transformer[7]和指針生成網(wǎng)絡(luò)[8],提出了一種面向中文新聞文本的多文檔生成式摘要模型:Transformer-PGN,該模型利用融合段落注意力機(jī)制的Transformer模型對中文文本進(jìn)行特征表達(dá)和深層次的綜合特征抽取,捕獲跨文檔關(guān)系,再通過指針生成網(wǎng)絡(luò)生成聚合式新聞。實驗結(jié)果表明,該模型在中文多文檔摘要評測數(shù)據(jù)集WeiboSum上取得了良好的效果,Rouge-1、Rouge-2和Rouge-L分別提升了2.1%、2.4%和2.3%。
1 相關(guān)工作
在生成式摘要中,根據(jù)產(chǎn)生摘要的文檔數(shù)量可分為單文檔摘要、多文檔摘要。
單文檔生成式摘要指從一個文檔中生成一個摘要,摘要的句子由機(jī)器生成,生成方式接近于人的思考方式,摘要需簡潔凝練、具有一定的連貫性。近些年,生成式摘要的主流模型都是基于Seq2Seq框架[9]。Google提出基于指針生成網(wǎng)絡(luò)的單文檔生成式摘要模型[8]。該模型一方面通過Seq2Seq框架保持抽象生成摘要的能力,另一方面通過指針網(wǎng)絡(luò)從原文中取詞,提高了摘要的準(zhǔn)確度并解決了OOV問題。并使用覆蓋率機(jī)制來處理重復(fù)問題,提高生成摘要的準(zhǔn)確性。陳天池等[10]在傳統(tǒng)Seq2Seq框架的基礎(chǔ)上,解碼端融合了Attention機(jī)制,解決了Seq2Seq在解碼的時候無法獲得輸入序列足夠信息的問題。李大舟等[11]提出了基于編解碼器結(jié)構(gòu)的中文文本摘要模型,編碼器端將原始文本輸入到編碼器并結(jié)合雙向門控循環(huán)單元生成固定長度的語義向量,使用注意力機(jī)制分配每個輸入詞的權(quán)重來減少輸入序列信息的細(xì)節(jié)損失,解碼器端使用LSTM網(wǎng)絡(luò),融合先驗知識和集束搜索方法將語義向量解碼生成目標(biāo)文本摘要。從應(yīng)用的角度看,單文檔生成式摘要難以滿足從多篇文檔中生成摘要的場景,因為它無法從多個文檔中生成一個涵蓋不同中心點(diǎn)的、全面的摘要。
多文檔生成式摘要的目的是在一組主題相關(guān)的文檔中生成一個簡短而信息豐富的摘要。多文檔生成式摘要比單文檔生成式摘要更復(fù)雜、更難處理。這是因為在多文檔生成式摘要任務(wù)中,文檔之間有更多不同和沖突的信息。文檔通常較長,文檔之間的關(guān)系更加復(fù)雜。對于模型來說,保留復(fù)雜輸入序列中最關(guān)鍵的內(nèi)容,同時生成相關(guān)的、非冗余的、非事實錯誤和語法可讀的摘要是很有挑戰(zhàn)性的。Google提出基于Transformer的T-DMCA[12](transformer decoder with memory-compressed attention)多文檔生成式摘要模型,該模型包含一個抽取式模型和一個生成式模型,首先通過抽取式模型生成有序的段落列表,再通過生成式模型生成文本。該模型還提出memory-compressed注意力機(jī)制,該機(jī)制通過卷積神經(jīng)網(wǎng)絡(luò)壓縮多頭自注意力提高計算效率。但該模型未能捕獲跨文檔之間的關(guān)系。耶魯大學(xué)構(gòu)建了新聞領(lǐng)域第一個大規(guī)模多文檔摘要數(shù)據(jù)集Multi-News[13],并提出Hi-MAP(hierarchical MMR-attention pointer-generator model)多文檔生成式摘要模型。該模型通過集成的MMR(maximal marginal relevance)模塊計算句子的相關(guān)性和冗余性,從而計算候選句子的排名,然后通過指針生成網(wǎng)絡(luò)生成摘要。百度提出基于圖的多文檔生成式摘要模型GraphSum[14]。該模型包含Transformer編碼器、圖編碼器和圖解碼器。得益于圖形建模,該模型可以從長文檔中提取重要信息,并能夠更有效地生成連貫的摘要。在大規(guī)模多文檔摘要數(shù)據(jù)集WikiSum和MultiNews上的實驗結(jié)果表明,GraphSum相對于已有的生成式摘要方法具有較大的優(yōu)越性,在自動評價和人工評價兩種方式下的結(jié)果均有顯著提升。
雖然現(xiàn)有的工作為多文檔生成式摘要奠定了堅實的基礎(chǔ),但與單文檔生成式摘要和其它自然語言處理主題相比,它仍然是一個較少見的研究課題。目前,許多現(xiàn)有的基于深度學(xué)習(xí)的多文檔生成式摘要模型未考慮文檔之間的關(guān)系,從而忽略了多文檔中可能包含的相同、互補(bǔ)或矛盾的信息。捕獲跨文檔關(guān)系,有助于模型提取關(guān)鍵信息,提高摘要的相關(guān)性并降低冗余度。本文提出的Transformer-PGN模型利用融合段落注意力機(jī)制的Transformer結(jié)構(gòu)對中文文本進(jìn)行特征表達(dá)和深層次的綜合特征抽取,并捕獲跨文檔關(guān)系;然后,通過結(jié)合coverage機(jī)制的PGN網(wǎng)絡(luò)生成更有效的摘要。
2 Transformer-PGN模型
本文使用WeiboSum數(shù)據(jù)集,模型的輸入為一組主題相關(guān)的多文檔,輸出為該組多文檔對應(yīng)的摘要。摘要來源于微博用戶參考消息、環(huán)球時報等發(fā)布的微博,多文檔來源于Google搜索引擎返回的前5個結(jié)果(檢索詞為摘要的前20個字符),每個文檔按換行符被切分為多個段落。由于輸入模型的段落較多且單個段落可能冗長,本文采用Rouge-2和Single-pass聚類算法選擇K個句子串聯(lián)作為模型輸入。對于所有的輸入段落 {P1,…,PL}, 采用Rouge-2計算每個段落與參考摘要的召回率,所有段落按召回率大小降序得到 {R1,…,RL}; 然后,對前L′個段落進(jìn)行Single-pass聚類,得到K個段落組成的簇 {SP1,…,SPK}, 對于每個簇Si, 取簇內(nèi)一個段落,組成段落 {S1,…,SK}; 最后,將K個段落串聯(lián)為模型輸入。
本文的摘要模型如圖1所示。模型的基本結(jié)構(gòu)由編碼器和解碼器組成,編碼器將輸入文本表示成若干帶有語義向量的輸入序列,解碼器則從輸入序列中提取重要內(nèi)容,生成文本摘要輸出。模型的編碼器采用融合段落注意力機(jī)制的Transformer及雙向LSTM結(jié)構(gòu),模型的解碼器采用Vanilla Transformer、單向LSTM及指針網(wǎng)絡(luò),同時采用coverage機(jī)制避免生成重復(fù)內(nèi)容。

圖1 總體結(jié)構(gòu)
2.1 編碼器

2.1.1 嵌入層
嵌入層由詞嵌入層、詞位置嵌入層和段落位置嵌入層組成。嵌入層結(jié)構(gòu)如圖2所示。其中,位置嵌入層采用Sinusoidal位置編碼,Sinusoidal位置編碼通過使用不同頻率的正弦、余弦函數(shù)生成,公式如下

圖2 嵌入層結(jié)構(gòu)
epos[2i]=sin(pos/100002i/dmodel)
(1)
(2)

peij=[ei;ej]
(3)
(4)
2.1.2 Local Transformer層
Local Tranformer層對每個段落內(nèi)的詞進(jìn)行編碼,其結(jié)構(gòu)同vanilla transformer[3]層,由以下兩個子層組成
h=LayerNorm(xl-1+MHAtt(xl-1))
(5)
xl=LayerNorm(h+FFN(h))
(6)
其中,LayerNorm為歸一化層;FFN為以ReLU為隱藏激活函數(shù)的兩層前饋神經(jīng)網(wǎng)絡(luò);MHAtt為Vaswani等介紹的多頭注意力機(jī)制,其結(jié)構(gòu)[7]如圖3所示,公式如下
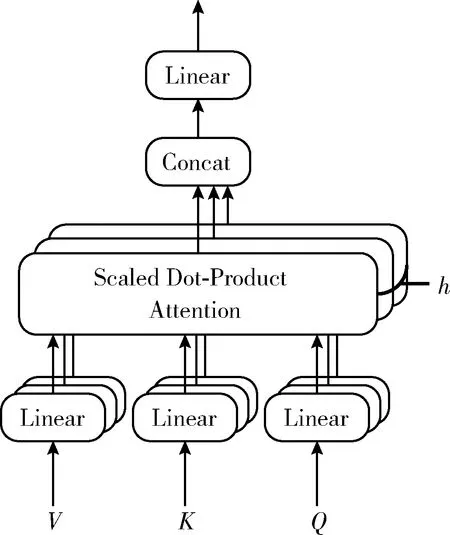
圖3 multi-head attention結(jié)構(gòu)
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(7)
(8)

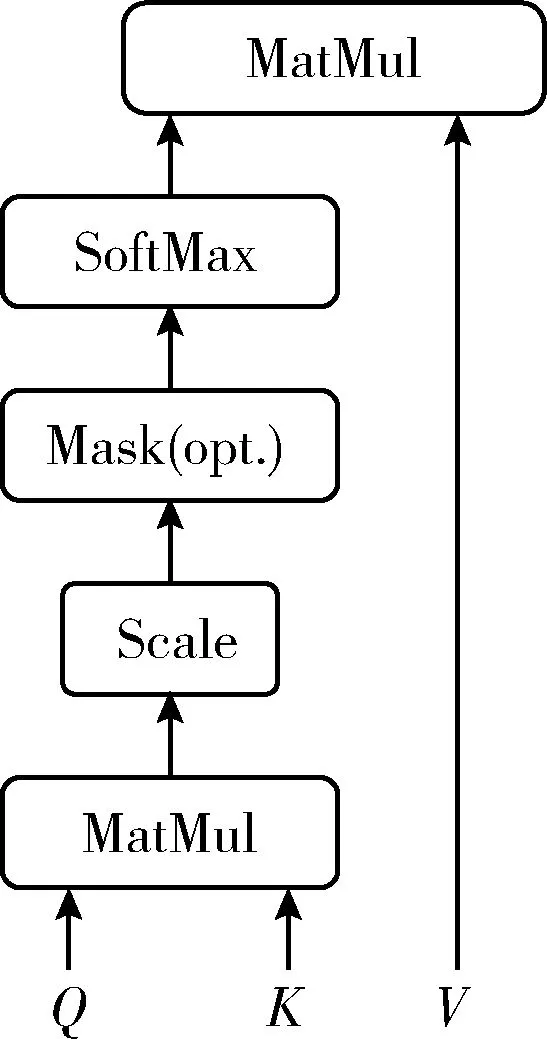
圖4 Scaled Dot-Product Attention結(jié)構(gòu)
(9)
其中,dk指key的維度,softmax函數(shù)公式如下
(10)
2.1.3 Global Transformer層
Global Transformer層用于多個段落間交換信息。首先對每個段落采用段落注意力機(jī)制,使每個段落可以通過自注意力機(jī)制獲取其它段落的信息,從而生成一個可以捕獲所有上下文信息的上下文向量。然后,上下文向量經(jīng)線性變換,疊加至每個詞向量,并輸入至前饋神經(jīng)網(wǎng)絡(luò),全局性地更新每個詞的向量表示。
段落注意力機(jī)制與自注意力機(jī)制同理,每個段落通過計算注意力分布獲取其它段落的文本信息。
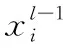
(11)
αij=softmax(eij)
(12)
(13)
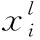
(14)
(15)
其中,Wo1和Wo2是模型參數(shù)。
2.2 解碼器
模型的解碼器采用Transformer層和指針生成網(wǎng)絡(luò),同時采用coverage機(jī)制避免生成重復(fù)內(nèi)容。解碼器使用的指針生成網(wǎng)絡(luò)包含指針網(wǎng)絡(luò)、單向LSTM和注意力機(jī)制。Transformer層采用Vanilla Transformer結(jié)構(gòu),Transformer層的輸出編碼狀態(tài)hi作為單向LSTM網(wǎng)絡(luò)的輸入向量,在時間步t得到解碼狀態(tài)序列st。 該時間步輸入序列中第i個詞的注意力分布為at, 公式如下
(16)
(17)
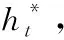
(18)
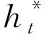
(19)

(20)
其中,wh、ws、wx、bptr、σ、xt定義請參見文獻(xiàn)[8]。生成單詞w的概率分布計算公式如下
(21)
覆蓋率機(jī)制可以解決重復(fù)性問題,將先前時間步的注意力權(quán)重加到一起得到覆蓋向量ct, 用先前的注意力權(quán)重決策來影響當(dāng)前注意力權(quán)重的決策,這樣就避免在同一位置重復(fù),從而避免重復(fù)生成文本。覆蓋向量ct計算公式如下
(22)

(23)
其中,Wc為模型參數(shù)。
3 實驗與分析
3.1 實驗數(shù)據(jù)
本文的實驗數(shù)據(jù)采用WeiboSum中文多文檔摘要評測數(shù)據(jù)集,包含訓(xùn)練集新聞主題8000個,驗證集新聞主題1000個,測試集新聞主題1000個,其中,每個主題包含一篇新聞?wù)椭辽賰善侣勎臋n。
3.2 評價指標(biāo)
目前,多文檔摘要任務(wù)的評價指標(biāo)主要有Rouge和基于信息理論的評價標(biāo)準(zhǔn)。Rouge是一個評估指標(biāo)的集合,是許多自然語言處理,如機(jī)器翻譯、單文檔摘要和多文檔摘要任務(wù)等最基本的度量方法之一。通過將自動生成的摘要與一組相對應(yīng)的人工編寫的參考文獻(xiàn)逐詞進(jìn)行比較,獲得預(yù)測/基準(zhǔn)事實的相似性評分。其評價原理是計算生成的摘要與參考摘要重疊的n-gram的召回率來衡量生成摘要質(zhì)量,值越大,生成的摘要質(zhì)量越高。常用指標(biāo)有Rouge-1,Rouge-2,其計算公式如下
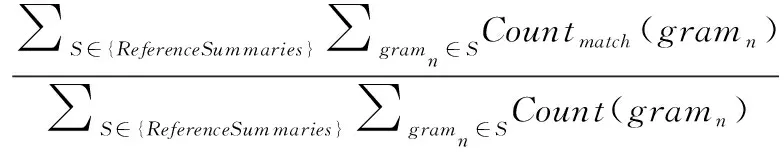
(24)
其中,分子中的Countmatch(gramn) 表示生成摘要中與參考摘要中相同n元數(shù)目,分母中的Count(gramn) 為參考摘要中總的n元數(shù)目。
為了更好評價摘要,本文還采用了Rouge-L評價指標(biāo),Rouge-L指標(biāo)表達(dá)的是匹配兩個文本單元之間的最長公共序列,其計算公式如下
(25)
其中,LCS(X,Y) 是X和Y的最長公共子序列的長度,m表示參考摘要長度。
3.3 實驗環(huán)境及參數(shù)設(shè)置
本文實驗環(huán)境及參數(shù)設(shè)置見表1。

表1 實驗環(huán)境及參數(shù)設(shè)置
3.4 實驗結(jié)果與分析
為了驗證coverage機(jī)制對于基于指針生成網(wǎng)絡(luò)的多文檔生成式摘要的有效性,設(shè)置實驗2和實驗3;為了驗證在多文檔生成式摘要任務(wù)中指針生成網(wǎng)絡(luò)較Transformer模型的優(yōu)越性,設(shè)置實驗1和實驗3;為了驗證在指針生成網(wǎng)絡(luò)中采用Transformer結(jié)構(gòu)進(jìn)行特征提取的有效性,設(shè)置實驗3和實驗4;為了驗證融合段落注意力機(jī)制的Transformer-PGN模型的有效性,設(shè)置實驗4和實驗5。具體實驗內(nèi)容如下:
實驗1:采用Transformer模型在WeiboSum數(shù)據(jù)集上進(jìn)行多文檔生成式摘要任務(wù),實驗名稱記為Transformer。
實驗2:采用融合注意力機(jī)制的指針網(wǎng)絡(luò)在WeiboSum數(shù)據(jù)集上進(jìn)行多文檔摘要任務(wù),實驗名稱記為PGN(wo coverage)。
實驗3:采用See等[8]提出的融合coverage機(jī)制的指針生成網(wǎng)絡(luò)在WeiboSum數(shù)據(jù)集上進(jìn)行多文檔摘要任務(wù),實驗名稱記為PGN。
實驗4:采用本文提出的基于Transformer(未融合段落注意力機(jī)制)和指針生成網(wǎng)絡(luò)的多文檔生成式摘要模型WeiboSum數(shù)據(jù)集上進(jìn)行多文檔摘要任務(wù),實驗名稱記為Transformer-PGN(wo paragragh attention)。
實驗5:采用本文提出的基于Transformer(融合段落注意力機(jī)制)和指針生成網(wǎng)絡(luò)的多文檔生成式摘要模型WeiboSum數(shù)據(jù)集上進(jìn)行多文檔摘要任務(wù),實驗名稱記為Transformer-PGN。
5組實驗的結(jié)果如圖5和表2所示。

表2 各模型實驗結(jié)果
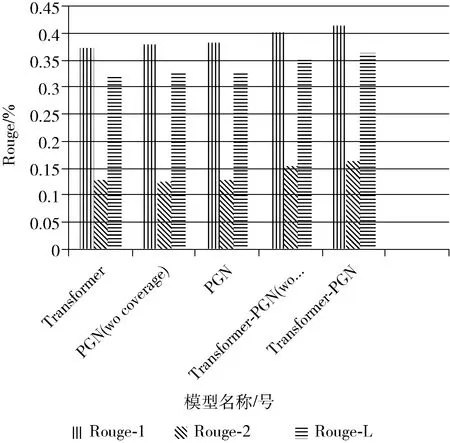
圖5 各模型實驗結(jié)果
為了驗證coverage機(jī)制對于基于指針生成網(wǎng)絡(luò)的多文檔生成式摘要的有效性,進(jìn)行實驗2(PGN wo coverage)和實驗3(PGN)的對比實驗,實驗3(PGN)在實驗2(PGN wo coverage)的基礎(chǔ)上增加了coverage機(jī)制。增加coverage機(jī)制的指針生成網(wǎng)絡(luò)模型在Rouge-1、Rouge-2和Rouge-L上較未采用coverage機(jī)制的指針生成網(wǎng)絡(luò)模型都有略微提升,說明coverage機(jī)制可以提高基于指針生成網(wǎng)絡(luò)的多文檔生成式摘要的效果。
為了驗證在多文檔生成式摘要任務(wù)中指針生成網(wǎng)絡(luò)較Transformer模型的優(yōu)越性,設(shè)置實驗1(Transformer)和實驗3(PGN)的對比實驗。實驗結(jié)果表明,指針生成網(wǎng)絡(luò)在Rouge-1上較Transformer模型提升了0.9%,在Rouge-L上較Transformer模型提升了0.6%,在Rouge-2上于Transformer模型效果相同,說明在WeiboSum數(shù)據(jù)集上的多文檔生成式摘要任務(wù)中,指針生成網(wǎng)絡(luò)優(yōu)于Transformer模型。
為了驗證在指針生成網(wǎng)絡(luò)中融合Transformer結(jié)構(gòu)進(jìn)行特征提取的有效性,設(shè)置實驗3(PGN)和實驗4(Transformer wo paragraph attention)的對比實驗。實驗結(jié)果表明,融合Transformer結(jié)構(gòu)的指針生成網(wǎng)絡(luò)較僅使用指針生成網(wǎng)絡(luò)在Rouge-1、Rouge-2和Rouge-L上均提升2%以上,說明在LSTM網(wǎng)絡(luò)的基礎(chǔ)上,融合Transformer結(jié)構(gòu)可以進(jìn)行更深層次的特征提取。
為了驗證融合段落注意力機(jī)制的Transformer-PGN模型的有效性,設(shè)置實驗4(Transformer wo paragraph attention)和實驗5(Transformer-PGN)的對比實驗。增加段落注意力機(jī)制的Transformer-PGN模型較未使用段落注意力的模型在Rouge-1上提升了1.2%,在Rouge-L上提升了1.3%,在Rouge-2上提升了0.9%,說明了段落注意力機(jī)制可以實現(xiàn)對中文文本特征的更深層次抽取和對跨文檔關(guān)系的有效表達(dá),使得模型對原文的理解更加充分,從而在多文檔生成式摘要任務(wù)中能夠有效提升模型性能。
綜上所述,融合段落注意力機(jī)制的Transformer-PGN模型在Rouge-1、Rouge-2和Rouge-L上均高于其它4個模型。采用融合段落注意力機(jī)制的Transformer結(jié)構(gòu)對中文文本進(jìn)行編碼,可以對原文的上下文理解更加充分,生成語義信息更豐富的上下文向量;指針網(wǎng)絡(luò)可以更好的逐詞生成摘要;覆蓋率機(jī)制可以有效解決生成摘要詞語重復(fù)問題。顯然,本文提出的模型在所有實驗方法中效果最優(yōu),能夠結(jié)合上下文和段落關(guān)系對多文檔充分建模,更適合于多文檔生成式摘要任務(wù),較Transformer模型在3個指標(biāo)上均提升了3個百分點(diǎn)以上,充分驗證了本文所提方法的可行性和有效性。
4 結(jié)束語
本文針對中文新聞多文檔摘要文本特征抽取不充分、無法捕獲跨文檔關(guān)系和生成摘要內(nèi)容重復(fù)問題,提出了一種面向中文新聞文本的多文檔生成式摘要模型Transfor-mer-PGN,使用融合段落注意力機(jī)制的Transformer結(jié)構(gòu)和指針生成網(wǎng)絡(luò),最后結(jié)合coverage機(jī)制避免重復(fù)問題。實驗結(jié)果表明,Transformer-PGN模型在中文新聞多文檔摘要任務(wù)中,Rouge評測分?jǐn)?shù)均高于其它4個模型,生成的摘要結(jié)果更接近標(biāo)準(zhǔn)摘要,同時能有效減少生成重復(fù)內(nèi)容的問題,具有更高的正確性。未來將嘗試結(jié)合強(qiáng)化學(xué)習(xí)提升模型性能[15]。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
