高架綠植智能灌溉系統架構及智能模型研究
2023-10-14 02:52:56李文波葛為偉袁新球劉良旭
科學技術創新 2023年23期
李文波,葛為偉,袁新球,劉良旭*
(1.寧波市政工程建設集團股份有限公司,浙江 寧波;2.寧波市產城生態建設集團有限公司,浙江 寧波;3.寧波工程學院,浙江 寧波)
隨著物聯網和智能化等技術的發展,研發適用于高架環境綠植灌溉的智能灌溉解決方案的條件已經逐漸成熟。本研究引用物聯網技術解決電磁閥控制系統的孤島現場,引入深度學習框架預測每個路段的最低需水量,實現定時按需灌溉。
人工神經網絡算法在各智能領域都有著不可或缺的地位,以神經網絡為基礎的需水量預測模型被廣泛應用到智能灌溉系統中,隨著各種預測模型的應用使得灌溉系統變得越來越智能化[1]。孟瑋[2]等人使用徑向基神經網絡對蘋果的需水量進行了相關預測,但徑向基神經網絡對數據的依賴性較高,在數據不足夠充分的時候該神經網絡將無法工作。張明岳[3]等人設計了一種基于改進的 Elman 神經網絡和模糊控制的智能灌溉系統,利用Elman 神經網絡對作物蒸發蒸騰量即作物需水量進行了相關預測研究。
1 高架綠植智能灌溉框架
按照系統功能,整個系統分為現場控制、物聯網管理、智能業務處理和預警四大模塊組成,見圖1。
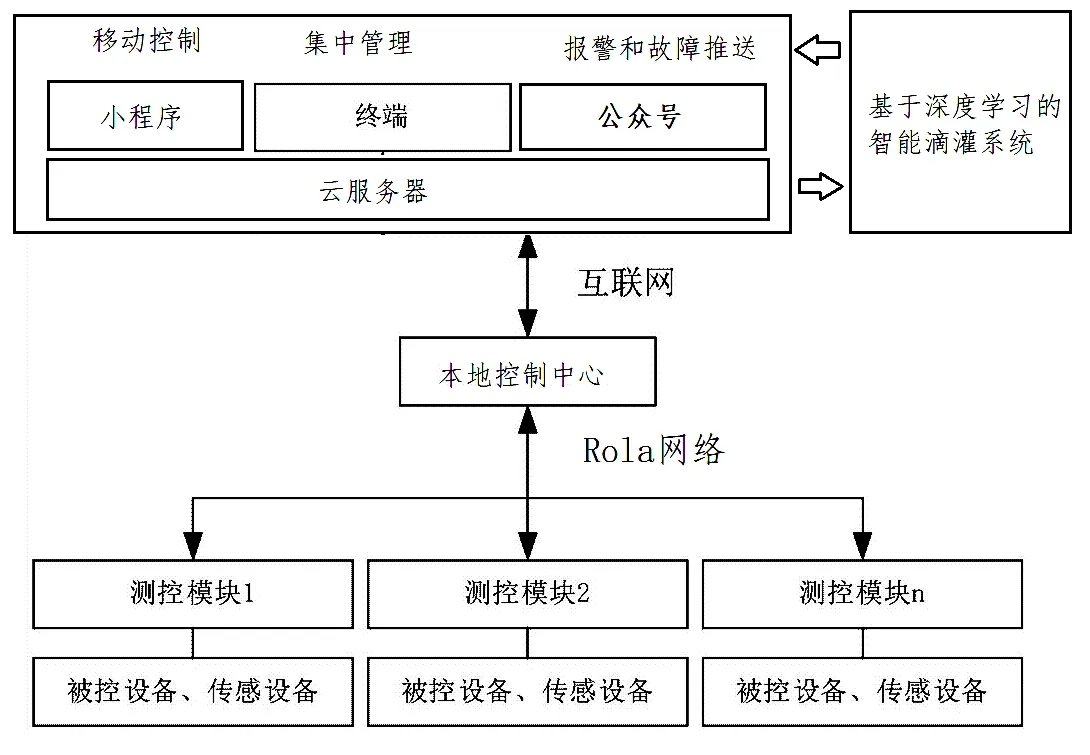
圖1 高架綠植智能灌溉系統架構
1.1 現場控制模塊
現場控制模塊采用物聯網邊緣控制中心架構設計,每個現場控制模塊包括一個主要功能、包括接收云服務器的控制命令、上傳現場環境狀態和報警、在網絡不通時按照本地存儲模式實現灌溉等。
1.2 物聯網管理模塊
物聯網設備管理子系統實現對高架綠植灌溉遠程設備和傳感器的統一管理和配置。由于高架灌溉需要管理成千上萬個現場控制系統,為了便于統一實現對現場設備的管理,系統還提供了分組管理和控制模式管理。分組管理就是將相同控制方式的設備分成一組。灌溉模式則是實現設定常用灌溉模式,例如圖2是灌溉模式的管理界面。圖3 顯示了添加一個灌溉模式的界面。
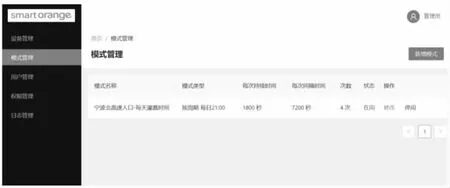
圖2 灌溉模式管理
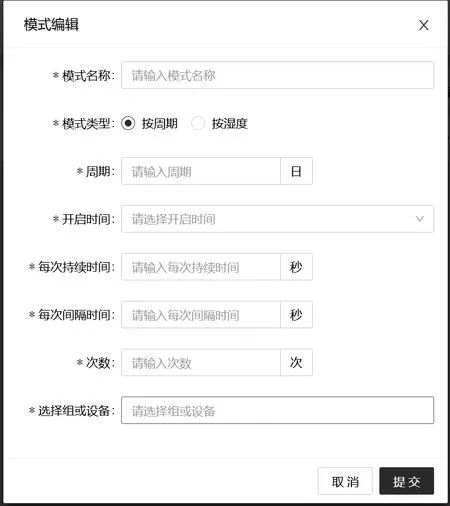
圖3 灌溉模式添加界面
1.3 智慧業務模塊
智慧業務模塊包括灌溉數據的管理、現場控制點的管理、天氣預報數據的管理和智能灌溉模型管理四個部分。
歷史灌溉數據是每個灌溉控制點采集的花箱土壤濕度、溫度、光照等歷史數據,圖4 顯示了該模塊保存的某個控制點的濕度和溫度變化曲線。從圖4 中可以發現,由于花箱土壤以沙土為主,濕度越高,其濕度下降速度越快。因此,過渡灌溉除了造成水資源浪費之外并沒有任何作用。而且過渡灌溉會導致灌溉時間變長,從而造成更大的水資源浪費。
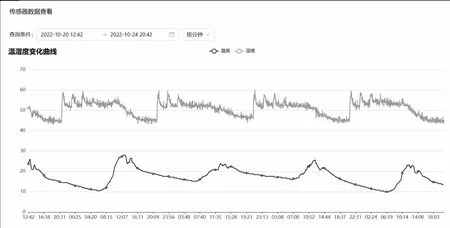
圖4 花箱土壤濕度變化曲線
在日常業務中,工作人員對灌溉設備的管理以控制點為單位。因此,控制點管理就是以控制點為單位對物聯網設備進行管理,方便工作人員的管理和報警處理。
1.4 報警模塊
高架綠植灌溉系統控制成千上萬個電磁閥。為了有效對電磁閥狀態進行管理,本系統設計了基于微信公眾號和小程序相結合的灌溉報警子系統。公眾號實現物聯網設備實時預警反饋,運維人員只要關注公眾號,就可以實時接收灌溉系統的預警和狀態反饋。小程序則是實現所有故障和報警信息的管理和處理流程,使得相關管理人員可以根據預警的位置和設備信息,實時掌控每個傳感器、控制器的運行狀態,避免出現電磁閥故障而導致大面積綠植枯死。
2 智能需水預測模型
2.1 Transformer 框架
Transformer 是一個具有編碼器-解碼器結構的最具競爭力的神經序列模型。與LSTM 或RNN 不同,Transformer 不是使用遞歸和卷積,而是利用輸入嵌入中添加的位置編碼來對序列信息進行建模。Transformer 整體架構為左右兩個部分,左側為Encoder,右側為Decoder。Encoder 與Decoder 各自都堆疊了N 層。
2.2 基于Transformer 的需水量預測模型
為了實現對每個電磁閥控制路段的花箱實現按需灌溉。系統引入Transformer 框架構建需水量預測模型,該模型分成兩步實現,第一步,利用路段環境數據和未來天氣預報數據,使用基于Transformer 的預測模型預測下一次灌溉時路段的花箱濕度。第二步,根據每個花箱的濕度以及環境因素,使用基于Transformer模型預測使得下一次濕度不低于濕度閾值的花箱濕度,從而設置本次灌溉時花箱土壤濕度需要達到的目標值。
(1) 位置編碼
無論是花箱溫濕度和花箱環境參數、還是天氣預報信息都是按天為單位的時間序列數據。為了進一步提取時間序列的位置信息,筆者采用時間戳編碼方式,將數據的當前時間戳與灌溉周期開始時間戳之間相對距離編碼成自注意力機制相關性的一種重要因素,以體現數據的順序特征。
(2) 編碼器-解碼器框架
Transformer 由masked self-attention 模塊、編碼器-解碼器模塊和前饋神經網絡三個模塊組成。按照GPT2 的decoder-only Transformer 思想,編碼器輸入是一個每次目標向右移動一個位置的花箱濕度時間序列。例如,假設有x1,x2,x3,x4,x5,x6等六個需要預測的花箱濕度時間序列數據(見圖5),按照時間序列預測思想,編碼器中,輸入為x100000 對應預測輸出為0x2’0000, 當輸入是x1x20000 時,對應的預測為00x3’000。
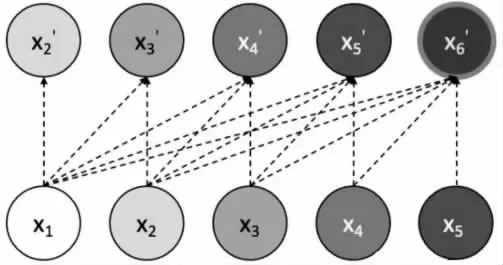
圖5 時間序列預測過程
(3) 訓練階段中改進的教師強制
使用教師強制的模型學習能力很強,因為預測錯誤會被實時糾正,使得下一個預測更加準確。但它的缺點也是明顯的。模型每次的預測錯誤都會被忽略,這意味著這些錯誤不會對損失產生影響,即模型僅是學習如何預測下一個步長的輸出。另一方面,在預測階段,模型必然需要預測更長的步長,不能再依賴頻繁的修正。
為了彌補訓練和預測之間的差距,模型需要慢慢學習糾正這類錯誤。本項目采用逐漸為模型提供上一次預測結果代替真實值作為模型輸入。開始選擇真實值的高概率開始,即采用教師強制盡快穩定模型,并隨著模型的成熟,逐漸收斂到純粹從模型輸出中采用,以實現模擬預測任務。
(4) 基于需水量預測的智能模型
筆者訓練的預測模型旨在利用采集的歷史數據環境數據和花箱土壤溫濕度的時間序列數據、天氣預報的氣象數據,訓練花箱在環境數據下的花箱濕度變化預測模型。由于本項目實驗環境從搭建到數據采集共6 個月,去除無效數據后生成訓練樣本160 個。經過訓練得到模型。模型經過后續生成的測試數據進行測試,實驗結果基本滿足實際變化。
3 結論
針對現有高架綠植環境,設計了針對高架綠植環境的智能灌溉系統,設計的高架綠植智能灌溉系統,解決當前高架綠植灌溉運維存在的灌溉模式調整復雜等問題。
(1) 系統極大降低了運維人員設置和巡檢的工作量,提高了工作效率。
(2) 本系統實現了電磁閥故障的主動識別,降低了大面積綠植死亡的可能性,從而減少了綠植死亡帶來的巨大更換工作量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年15期)2022-09-20 06:56:20
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
光學精密工程(2016年6期)2016-11-07 09:07:19
雜文月刊(2016年1期)2016-02-11 10:35:51
