基于改進(jìn)YOLOv4 的輸電線路目標(biāo)檢測算法
2023-10-17 01:59:52熊君偉葉世順胡志祥
電器工業(yè) 2023年10期
王 統(tǒng) 熊君偉 葉世順 胡志祥 舒 冬
(湖南三一智慧新能源設(shè)計(jì)有限公司)
1 YOLOv4 算法介紹
YOLOv4 圖像識別算法與YOLOv3 算法[1-2]相比,改進(jìn)了網(wǎng)絡(luò)結(jié)構(gòu)和模型訓(xùn)練技巧等多個(gè)方面。YOLOv4 利用CSP 與Darknet-53 殘差網(wǎng)絡(luò)相結(jié)合,能夠提取圖片深層次網(wǎng)絡(luò)特征數(shù)據(jù),同時(shí)減小計(jì)算量;增加SPP 網(wǎng)絡(luò)模塊,增大感受野,提取更高層次的語義特征,能夠適應(yīng)不同尺寸和背景特征的目標(biāo)識別。
YOLOv4 網(wǎng)絡(luò)結(jié)構(gòu)主要包括主干網(wǎng)絡(luò)、Neck 模塊[3]。主干網(wǎng)絡(luò)采用CSPDarknet53 結(jié)構(gòu)形式,將CSPNet 網(wǎng)絡(luò)結(jié)構(gòu)應(yīng)用于Darknet-53 中殘差模塊,使上層的特征圖一個(gè)分支進(jìn)行殘差運(yùn)算,同時(shí)另外一個(gè)分支和經(jīng)過殘差運(yùn)算后的特征圖相結(jié)合[4]。
Neck 模塊包括SPP 網(wǎng)絡(luò)結(jié)構(gòu)和PANet 網(wǎng)絡(luò)結(jié)構(gòu)。其中,SPP 網(wǎng)絡(luò)結(jié)構(gòu)采用1×1、5×5、9×9、13×13最大池化層分別對上層特征圖進(jìn)行處理,PANet 采用高低層特征融合方法實(shí)現(xiàn)3 個(gè)不同大小的特征圖Y1、Y2、Y3 輸出,用于不同大小的目標(biāo)識別[5-6]。
2 基于YOLOv4 輸電線路外破隱患目標(biāo)識別的改進(jìn)
本文為改善自身因素的影響, 提出基于K-means++聚類算法,領(lǐng)域自適應(yīng)和注意力機(jī)制的改進(jìn)YOLOv4 輸電線路外破隱患目標(biāo)檢測算法。
2.1 改進(jìn)K-means++聚類算法
YOLOv4 采用的K-means 算法每次選取k個(gè)隨機(jī)值作為初始簇中心,這使得每次運(yùn)算結(jié)果存在一些差異,導(dǎo)致目標(biāo)框定位的穩(wěn)定性較差。本文采用K-means++算法對數(shù)據(jù)集進(jìn)行目標(biāo)框聚類,該方法優(yōu)化一次性選取所有k個(gè)簇中心的方案,減少初始簇值對算法結(jié)果的影響,使得每個(gè)簇盡可能地分散從而獲取更為精確的目標(biāo)聚類框,具體算法如下:
1)統(tǒng)計(jì)數(shù)據(jù)集中所有樣本的尺寸然后進(jìn)行歸一化操作;
2)隨機(jī)從樣本中選取1個(gè)樣本作為初始的簇中心;
3)計(jì)算每個(gè)簇中心和各個(gè)樣本之間的距離,公式如下:
式中,d(box,C)為簇與樣本中心距離;IOU(box,C)為目標(biāo)框與簇中心的交并比。
4)挑選距離最大的樣本作為新的簇中心,距離越大說明當(dāng)前樣本和簇中的相似度較低;
5)重復(fù)步驟3 和步驟4 直到獲取k個(gè)簇中心,直到簇中心不再變化或者變化很小的時(shí)候結(jié)束聚類算法。
2.2 CBAM 注意力模塊
為了降低干擾,本文在YOLOv4 算法主干網(wǎng)絡(luò)結(jié)構(gòu)中加入注意力機(jī)制模塊以提升算法模型的特征提取能力[7]。
CBAM 本質(zhì)上是通道注意力與空間注意力的融合,以中間特征圖F=RH×W×C為輸入,沿著兩個(gè)獨(dú)立的維度(通道和空間),依次計(jì)算出注意圖,然后將注意圖乘以輸入特征圖進(jìn)行自適應(yīng)特征細(xì)化。在特征圖信息提取時(shí)同時(shí)使用全局平均池化和最大池化,減少信息丟失。
通道注意力模塊利用特征圖通道間的關(guān)系,采用全局平均池化和最大池化聚合特征圖空間信息,再經(jīng)過多層感知器MLP 和Sigmoid 激活函數(shù)處理,生成通道注意圖,側(cè)重于提取檢測目標(biāo)的輪廓信息特征,通道注意圖Mc計(jì)算公式為:
式 中,δ為Sigmoid 激活函數(shù);分別為利用平均池化和最大池化在空間上生成的特征映射;MLP 為CBAM 的共享網(wǎng)絡(luò);W1、W0分別為MLP 的隱藏權(quán)重和輸出權(quán)重。
通道注意力模塊之后,再引入空間注意力模塊,提取目標(biāo)特征圖的空間位置信息作為通道注意特征圖的補(bǔ)充。通過卷積操作,并同樣使用兩種池化方法聚合位置信息,拼接之后再利用卷積及Sigmoid 激活函數(shù)得到一個(gè)具有空間注意力的空間矩陣,得到新的特征圖。計(jì)算公式為:
式中,δ為激活函數(shù);F'為F與Mc相乘得到的模塊輸入。
將引入CBAM 模塊前后效果可視化后,前后對比如圖1 所示,引入CBAM 模塊后,圖像特征覆蓋了更多位置。

圖1 CBAM 效果可視化圖
3 實(shí)驗(yàn)結(jié)果及分析
本文實(shí)驗(yàn)部分所使用的硬件平臺是聯(lián)想高性能計(jì)算服務(wù)器ThinkServer SR658,配備兩塊GPU 顯卡NVIDIA GeForce RTX 2080Ti。 軟件平臺使用Ubuntu18.04 系統(tǒng),CUDA10.2、cudnn8.1、Anaconda3軟件版本,在此基礎(chǔ)上搭建基于開源框架darknet 的深度學(xué)習(xí)環(huán)境,通過對YOLOv4 算法進(jìn)行改進(jìn)最終實(shí)現(xiàn)架空輸電線路通道環(huán)境內(nèi)外破目標(biāo)的檢測和預(yù)警[8-9]。
3.1 數(shù)據(jù)集預(yù)處理
輸電線路防外破預(yù)警的核心是對通道環(huán)境內(nèi)可能的外破目標(biāo)進(jìn)行識別和檢測,需要原始的數(shù)據(jù)集樣本和一一對應(yīng)的數(shù)據(jù)標(biāo)注文件[10]。本文所使用的數(shù)據(jù)集樣本均來自電網(wǎng)某項(xiàng)目所安裝的智能可視化監(jiān)拍裝置拍攝后的結(jié)果,原始拍攝結(jié)果中涵蓋多種天氣狀況、光照條件、拍攝角度下的拍攝效果。收集整理后數(shù)據(jù)集中包含施工機(jī)械、塔吊、吊車這3 種常見的外破隱患目標(biāo),共計(jì)3867 張。各類別的數(shù)量依次為施工機(jī)械類1370 張,吊車類1196 張,塔吊類1301 張,各類別間的圖片數(shù)量比接近1:1:1。
數(shù)據(jù)標(biāo)注文件的產(chǎn)生借助Labelimg 軟件,得到與訓(xùn)練數(shù)據(jù)同名且唯一的xml 文件,該文件中包含目標(biāo)的標(biāo)簽和位置信息。為了加速訓(xùn)練過程,對輸入目標(biāo)的位置信息進(jìn)行歸一化處理,歸一化公式如下:
式中,x和y為歸一化后目標(biāo)框的中心點(diǎn)位置橫縱坐標(biāo)值;w和h為歸一化后目標(biāo)框的寬度和高度;xmin,ymin,xmax,ymax分別為xml 文件中目標(biāo)框左上角和右下角的橫坐標(biāo)和縱坐標(biāo)值;width 和height 為xml 文件中目標(biāo)框所在圖像的寬度和高度值。
將訓(xùn)練集中歸一化操作后的(x,y,w,h)作為K-means++算法的輸入,經(jīng)過聚類分析后,可以得到最能反映樣本中框的尺寸的9 個(gè)錨框,將獲得的9 個(gè)(w,h)分別乘以原圖的寬度和高度值獲得錨框的實(shí)際尺寸。
3.2 模型訓(xùn)練與測試
針對本項(xiàng)目數(shù)據(jù)集特點(diǎn)及硬件條件相關(guān)限制,修改開源框架darknet 的部分參數(shù)值,如表1 所示。將上述K-means++算法聚類分析后獲得9 個(gè)錨框替換darknet 框架配置文件中的相應(yīng)錨框。然后加載預(yù)訓(xùn)練模型,將歸一化后的(x,y,w,h)和對應(yīng)的數(shù)據(jù)集樣本送入網(wǎng)絡(luò)進(jìn)行訓(xùn)練。

表1 配置文件主要參數(shù)值
完成上述訓(xùn)練流程后,可以獲得模型文件,結(jié)合數(shù)據(jù)集中測試集樣本,可以進(jìn)行模型性能的測試。測試集樣本涵蓋不同光照、不同背景以及目標(biāo)不同姿態(tài)、多個(gè)目標(biāo)同時(shí)出現(xiàn)等多種情況。圖2 為實(shí)際場景中多個(gè)檢測目標(biāo)同框時(shí)模型的檢測效果,表明模型具備多目標(biāo)檢測的能力。

圖2 實(shí)際場景中多個(gè)檢測目標(biāo)同框時(shí)模型的檢測效果
3.3 結(jié)果分析
本文中實(shí)驗(yàn)部分采用的評價(jià)指標(biāo)是精確率(precision)、召回率(recall)、均值平均精度(mAP),具體公式如下:
式中,TP 代表的是預(yù)測結(jié)果為正樣本的集合中確實(shí)為正樣本的數(shù)量;FP 代表的是預(yù)測結(jié)果為正樣本的集合中實(shí)際是負(fù)樣本的數(shù)量;FN 代表的是預(yù)測結(jié)果為負(fù)樣本的集合中確實(shí)為負(fù)樣本的數(shù)量;n代表的是預(yù)測類別的數(shù)量,本文中n=3,代表的是第i個(gè)類別的精確率,本文中實(shí)驗(yàn)部分采用的是各類別輸出閾值為0.6 時(shí)的統(tǒng)計(jì)結(jié)果。
為了進(jìn)一步研究本文提出的算法改進(jìn)措施對于模型檢測效果的影響,實(shí)驗(yàn)部分設(shè)計(jì)了消融實(shí)驗(yàn),具體結(jié)果如表2 所示。表格中“*”號表示添加了該措施,可以看到,在添加了改進(jìn)措施的YOLOv4 算法中,算法精確度precision 實(shí)現(xiàn)了4.1%的提升。在加入CBAM 領(lǐng)域自適應(yīng)網(wǎng)絡(luò)后,算法召回率recall 實(shí)現(xiàn)了3.1%的提升。單獨(dú)加入CBAM 領(lǐng)域自適應(yīng)網(wǎng)絡(luò)后,精確率和召回率獲得了2.9%和1.5%的提升,證明了自注意力機(jī)制的有效性。
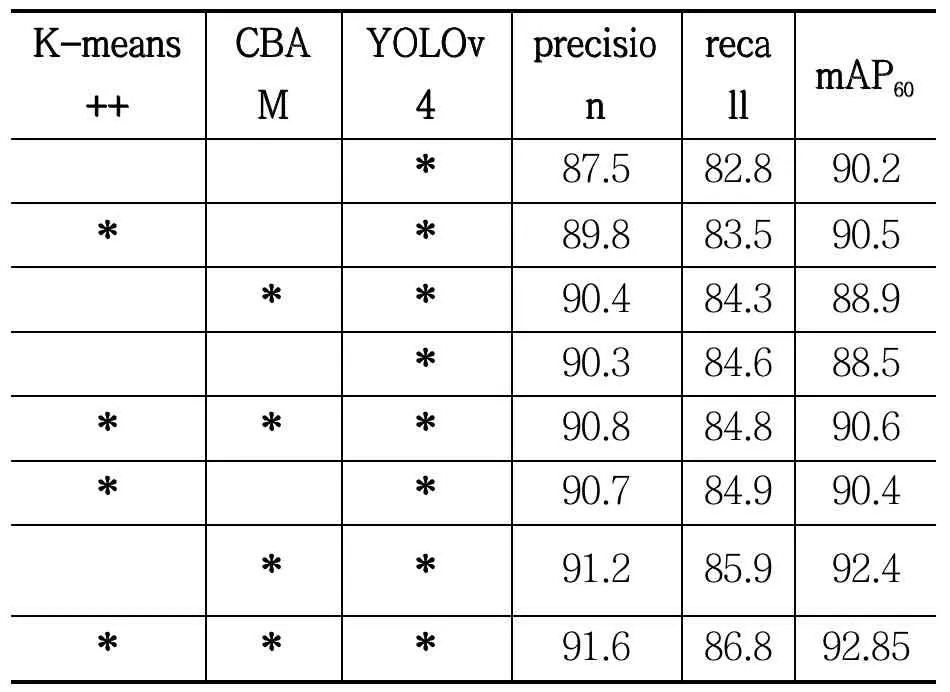
表2 算法消融實(shí)驗(yàn)結(jié)果
將本文中改進(jìn)的YOLOv4 算法與常用的目檢測算法FasterRCNN、SSD 相比較,結(jié)果如表3 所示。

表3 不同算法對比結(jié)果
可以看出,改進(jìn)后的算法在施工機(jī)械、吊車、塔吊類別上獲得了性能指標(biāo)AP 和mAP 的提升。由于本文借助開源框架darknet,其底層代碼使用C 語言來實(shí)現(xiàn),編譯運(yùn)行效率高,在實(shí)際工程應(yīng)用中單張圖片的檢測時(shí)間更短,檢測速度獲得了明顯提升。
4 結(jié)束語
文中提出基于YOLOv4 的輸電線路外破隱患識別算法,采用 CSPDarknet-53 殘差網(wǎng)絡(luò)提取圖片深層次網(wǎng)絡(luò)特征數(shù)據(jù),結(jié)合SPP 算法對特征圖進(jìn)行處理增加感受野,提取更高層次的語義特征。其次,在算法改進(jìn)策略中,采用改進(jìn)K-means++算法對圖片樣本集目標(biāo)的大小進(jìn)行聚類分析,篩選出針對檢測目標(biāo)特征分析的錨框,用于模型訓(xùn)練及檢測,引入 CBAM 自注意力結(jié)構(gòu),增強(qiáng)模型在復(fù)雜背景下對目標(biāo)檢測物的特征提取能力,提高模型檢測精度。最后,采用本文算法和其他兩種常用的圖像識別算法對實(shí)際的輸電線路現(xiàn)場圖片樣本集進(jìn)行測試,實(shí)驗(yàn)結(jié)果表明本文算法具有更高的識別準(zhǔn)確率,且平均單張圖片識別速度更快,滿足模型前端部署的要求,驗(yàn)證了該算法的優(yōu)越性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
