基于改進(jìn)聚類算法的交通事故多發(fā)點(diǎn)識(shí)別方法
2023-10-17 23:52:06王藝霖肖媛媛左鵬飛楊博劉悅霞段宗濤
計(jì)算機(jī)應(yīng)用研究 2023年10期
關(guān)鍵詞:數(shù)據(jù)挖掘
王藝霖 肖媛媛 左鵬飛 楊博 劉悅霞 段宗濤


摘 要:道路交通事故多發(fā)點(diǎn)事故發(fā)生頻率高且嚴(yán)重性突出,為提高道路通行的安全與效率,需要找到事故多發(fā)點(diǎn)所在位置。針對(duì)現(xiàn)有密度聚類算法對(duì)交通事故多發(fā)點(diǎn)識(shí)別時(shí)需要設(shè)置中心點(diǎn)個(gè)數(shù)以及容易擴(kuò)大聚類范圍等問題,提出一種限制簇?cái)U(kuò)展的自適應(yīng)搜索密度峰值聚類算法(limit cluster expansion and adaptive search clustering by fast search and find of density peaks,LA-CFDP)。LA-CFDP算法通過增加中心點(diǎn)限制條件自動(dòng)確定中心點(diǎn)個(gè)數(shù),引入?yún)?shù)擴(kuò)展因子限制簇?cái)U(kuò)展范圍,從而提高算法對(duì)事故多發(fā)點(diǎn)識(shí)別的適應(yīng)性和準(zhǔn)確性。在英國(guó)四個(gè)城市2019年交通事故數(shù)據(jù)集上的實(shí)例分析表明,LA-CFDP算法對(duì)四個(gè)城市聚類結(jié)果的輪廓系數(shù)值達(dá)到0.72~0.92,DBI值均降低到0.37以下。聚類結(jié)果符合事故多發(fā)點(diǎn)的定義及特征,能夠?yàn)榻煌ㄊ鹿识喟l(fā)點(diǎn)治理提供可靠依據(jù)。
關(guān)鍵詞:交通事故分析; 數(shù)據(jù)挖掘; 密度聚類; 事故多發(fā)點(diǎn)識(shí)別
中圖分類號(hào):TP391 文獻(xiàn)標(biāo)志碼:A 文章編號(hào):1001-3695(2023)10-017-2993-07
doi:10.19734/j.issn.1001-3695.2023.02.0086
Identifying method of traffic accident-prone spots based on
improved clustering algorithm
Wang Yilin, Xiao Yuanyuan, Zuo Pengfei, Yang Bo, Liu Yuexia, Duan Zongtao
(School of Information Engineering, Changan University, Xian 710018, China)
Abstract:Road traffic accidents occur frequently and seriously in the accident-prone spots. In order to improve the safety and efficiency of road traffic, it is necessary to find the location of accident-prone points. The existing density clustering algorithm needed to set the number of center points and was easy to expand the clustering range when identifying traffic accident-prone points, this paper proposed the limit cluster expansion and adaptive search clustering by fast search and find of density peaks(LA-CFDP) algorithm to solve these problems. LA-CFDP algorithm automatically determined the number of center points by increasing the restriction condition of center points, and introduced the parameter expansion factor to limit the cluster expansion range, so as to improve the adaptability and accuracy of the algorithm for accident-prone point identification. The case analysis on the 2019 traffic accident data set of four cities in United Kingdom shows that the Sihouette coefficient of the clustering results of LA-CFDP algorithm reaches 0.72~0.92, and the Davies-Bouldin index(DBI) are all reduced to below 0.37. The clustering results accord with the definition and characteristics of accident-prone spots, and can provide reliable basis for the management of accident-prone spots.
Key words:traffic accident analysis; data mining; density clustering; identification of accident-prone spot
0 引言
第16屆國(guó)際道路安全會(huì)議報(bào)告指出,事故多發(fā)點(diǎn)總長(zhǎng)度占路網(wǎng)總長(zhǎng)度的0.25%,發(fā)生在事故多發(fā)點(diǎn)的事故總數(shù)卻占整個(gè)路網(wǎng)事故總數(shù)的25%。交通事故多發(fā)點(diǎn)是指在一定時(shí)間段內(nèi)發(fā)生交通事故相對(duì)聚集的點(diǎn)[1],作為道路上交通事故相對(duì)集中的地方,事故多發(fā)點(diǎn)是交通事故防治的切入點(diǎn)。有效、準(zhǔn)確地識(shí)別交通事故多發(fā)點(diǎn)是提高道路交通安全的一項(xiàng)關(guān)鍵而富有挑戰(zhàn)性的任務(wù)[2]。
交通事故多發(fā)點(diǎn)識(shí)別是交通事故防治的重要環(huán)節(jié),是道路交通安全管理措施的可靠依據(jù)[3]。目前常用的事故多發(fā)點(diǎn)識(shí)別方法主要包括事故數(shù)量法、質(zhì)量控制法、層次分析法、累計(jì)頻率法以及聚類方法等。事故數(shù)法和事故率法是最早提出的事故多發(fā)點(diǎn)識(shí)別方法。Wright等人[4]將事故數(shù)、死傷人數(shù)等綜合起來建立相對(duì)危險(xiǎn)度模型,以此作為事故多發(fā)點(diǎn)的依據(jù),但這種方法具有一定的局限性,只能表示危險(xiǎn)程度,不能區(qū)分具體路段。質(zhì)量控制法是運(yùn)用概率論與數(shù)理統(tǒng)計(jì)確定事故多發(fā)點(diǎn)段的方法,Dereli等人[5]建立了一個(gè)基于模型的空間統(tǒng)計(jì)方法確定交通事故多發(fā)點(diǎn),包括泊松回歸、負(fù)二項(xiàng)分布和經(jīng)驗(yàn)貝葉斯方法,通過比較得出經(jīng)驗(yàn)貝葉斯方法在準(zhǔn)確性和一致性方面都有最好的結(jié)果;質(zhì)量控制法雖然在實(shí)際操作中比較合理,但不能鑒別交通事故的嚴(yán)重性,也無法得到改善路段的順序[6]。孫元強(qiáng)[7]基于累計(jì)頻率曲線法分析不同路段單元?jiǎng)澐謱?duì)識(shí)別精確度的影響,給出路段單元長(zhǎng)度取值的合理建議,累計(jì)頻率法在識(shí)別事故多發(fā)點(diǎn)時(shí)具有一定的合理性,但該方法如果不能合理劃分單元,就容易漏掉一些事故多發(fā)點(diǎn),雖然改進(jìn)方法可以減少這種現(xiàn)象,但仍無法避免。層次分析法和模糊評(píng)價(jià)法也可以用于事故多發(fā)點(diǎn)的識(shí)別,張鵬[8]將模糊數(shù)學(xué)理論與層次分析法相結(jié)合對(duì)事故多發(fā)點(diǎn)進(jìn)行安全評(píng)價(jià),一定程度上實(shí)現(xiàn)了對(duì)高速公路的有效保護(hù),但該方法計(jì)算復(fù)雜,對(duì)參數(shù)的確定主觀性較強(qiáng)。
對(duì)于應(yīng)用聚類算法識(shí)別事故多發(fā)點(diǎn),國(guó)內(nèi)外學(xué)者也進(jìn)行了很多研究。耿超等人[9]將累計(jì)頻率法與DBSCAN算法相結(jié)合,按照相鄰原則對(duì)道路進(jìn)行動(dòng)態(tài)劃分,并利用DBSCAN算法對(duì)事故多發(fā)點(diǎn)進(jìn)行評(píng)價(jià);王鴻遙等人[10]引入DENCLUE聚類算法來實(shí)現(xiàn)更高效的識(shí)別目的,該算法可以有效避免對(duì)識(shí)別位置的預(yù)分割,實(shí)現(xiàn)具有隨機(jī)形狀的簇的生成;曹陽等人[11]從空間聚類算法與GIS結(jié)合的角度分析發(fā)掘道路事故多發(fā)點(diǎn)問題,并對(duì)DBSCAN算法增加空間連通性判別,增強(qiáng)了算法的空間適用性;張?jiān)品频热耍?2]考慮了事故周期性和交通事故嚴(yán)重程度,提供了一個(gè)基于空間密度聚類的高速公路事故多發(fā)路段識(shí)別方法,利用空間密度連接原理確定了不同空間維度的事故多發(fā)位置;Prasannakumar等人[13]借助地理信息技術(shù)研究事故多發(fā)點(diǎn)的定位和分布模式,根據(jù)空間自相關(guān)方法和核密度函數(shù)對(duì)事故進(jìn)行空間聚類分析。本文基于現(xiàn)有密度聚類算法DBSCAN(density-based spatial clustering of applications with noise)[14]與快速搜索密度峰值聚類算法(clustering by fast search and find of density peaks,CFDP)[15]提出一種用于交通事故多發(fā)點(diǎn)識(shí)別的限制簇?cái)U(kuò)展的自適應(yīng)搜索密度峰值聚類算法(LA-CFDP)。研究表明,DBSCAN算法在對(duì)交通事故數(shù)據(jù)聚類時(shí)容易擴(kuò)大事故多發(fā)點(diǎn)范圍,不符合事故多發(fā)點(diǎn)定義,CFDP算法在中心點(diǎn)選取時(shí)需要根據(jù)決策圖人為指定簇?cái)?shù),而在事故多發(fā)點(diǎn)識(shí)別中簇?cái)?shù)無法提前獲取,導(dǎo)致聚類效果不佳。因此,針對(duì)現(xiàn)有算法在中心點(diǎn)選取、簇?cái)U(kuò)展方式中存在的問題,通過自適應(yīng)中心點(diǎn)選取、限制簇?cái)U(kuò)展范圍改進(jìn)算法。實(shí)驗(yàn)結(jié)果表明,LA-CFDP算法各項(xiàng)指標(biāo)都高于現(xiàn)有算法,對(duì)不同分布的事故數(shù)據(jù)具有很好的適應(yīng)性,能夠有效識(shí)別事故多發(fā)點(diǎn)。
1 密度聚類算法
1.1 DBSCAN算法
DBSCAN算法是一種經(jīng)典的基于密度的聚類算法,通過尋找數(shù)據(jù)點(diǎn)密度相連的最大集合得到聚類的結(jié)果。
1.1.1 基本定義
給定數(shù)據(jù)集D={x1,x2,…,xn},距離半徑ε,點(diǎn)數(shù)閾值MinPts,其中ε和MinPts為用戶指定參數(shù),有如下定義:
定義1 ε鄰域。對(duì)xp∈D,若xp的ε鄰域表示為Nε(xp),則Nε(xp)={xi∈D|dist(xi,xp)≤ε},即數(shù)據(jù)集D中滿足到xp的距離小于ε的任意樣本點(diǎn)xi的集合。
定義2 核心對(duì)象。對(duì)xp∈D,若xp的ε鄰域內(nèi)的點(diǎn)的個(gè)數(shù)大于MinPts,即|Nε(xp)|≥MinPts,那么xp是一個(gè)核心對(duì)象。
定義3 直接密度可達(dá)。對(duì)xp,xq∈D,若xq在xp的ε鄰域內(nèi)且xp為核心對(duì)象,則稱xq由xp直接密度可達(dá)。
定義4 密度可達(dá)。對(duì)xp,xq∈D,若有樣本p1,p2,…,pn1∈D,其中p1=xp,pn1=xq且pi+1由pi直接密度可達(dá),那么稱xq由xp密度可達(dá)。
定義5 密度相連。對(duì)xp,xq∈D,若有xk∈D使得xp、xq均由xk密度可達(dá),則xp與xq密度相連。
1.1.2 算法描述
輸入:數(shù)據(jù)集D={x1,x2,…,xn},距離半徑ε,點(diǎn)數(shù)閾值MinPts。
a)掃描數(shù)據(jù)集,從中任意找到一個(gè)核心對(duì)象;
b)對(duì)該核心對(duì)象進(jìn)行擴(kuò)展,尋找從該核心點(diǎn)出發(fā)的所有密度相連的數(shù)據(jù)點(diǎn);
c)遍歷該核心對(duì)象ε鄰域內(nèi)的全部核心點(diǎn),找到與這些核心點(diǎn)密度相連的點(diǎn),直到無法擴(kuò)充;
d)重新掃描數(shù)據(jù)集,尋找仍未聚類的核心對(duì)象,重復(fù)上述步驟,擴(kuò)充該核心對(duì)象,直到?jīng)]有滿足條件的核心對(duì)象為止;
e)截至目前未被劃分到簇中的點(diǎn)即為噪聲點(diǎn);
f)輸出簇劃分結(jié)果。
1.2 快速搜索密度峰值聚類算法
CFDP算法結(jié)合密度聚類和劃分聚類的方法,通過密度和距離來確定聚類中心,再用劃分方法對(duì)非聚類中心進(jìn)行分配,得到聚類結(jié)果[16]。CFDP聚類算法的核心是確定聚類中心,聚類中心應(yīng)當(dāng)符合高密度和遠(yuǎn)距離兩個(gè)條件。具體來說,高密度是指該點(diǎn)周圍的數(shù)據(jù)點(diǎn)數(shù)量越多,密度越高;遠(yuǎn)距離是指該點(diǎn)到密度更高的點(diǎn)的距離越遠(yuǎn),越有可能成為聚類中心[17]。
1.2.1 基本定義
定義6 局部密度ρ。ρ表示點(diǎn)周圍所處區(qū)域的樣本點(diǎn)分布的密集程度,一般有兩種方式來表示局部密度,截?cái)嗪嗣芏群透咚购嗣芏龋財(cái)嗪嗣芏鹊亩x為
其中:trB(k)表示簇間平方誤差和;trW(k)表示簇內(nèi)誤差平方和。CH指標(biāo)越大,表示聚類效果越好。
2 限制簇?cái)U(kuò)展的自適應(yīng)搜索密度峰值聚類算法
DBSCAN和CFDP算法是兩種常用的基于密度的聚類算法,然而傳統(tǒng)聚類算法對(duì)交通事故多發(fā)點(diǎn)的識(shí)別存在問題。
DBSCAN算法應(yīng)用在交通事故多發(fā)點(diǎn)識(shí)別時(shí),其參數(shù)鄰域半徑ε和點(diǎn)數(shù)閾值MinPts恰好符合交通事故多發(fā)點(diǎn)對(duì)范圍及最少事故數(shù)的定義,并且能夠識(shí)別任意形狀和大小的簇,對(duì)噪聲數(shù)據(jù)具有較好的魯棒性;但是DBSCAN算法在事故多發(fā)點(diǎn)識(shí)別過程中也存在一定的問題:a)DBSCAN算法在簇?cái)U(kuò)展過程中將所有密度相連的點(diǎn)都聚為一類,這種簇?cái)U(kuò)展方式會(huì)擴(kuò)大事故多發(fā)點(diǎn)的范圍,偏離事故多發(fā)點(diǎn)定義,影響交通事故多發(fā)點(diǎn)識(shí)別的精確性;b)DBSCAN算法通過遍歷數(shù)據(jù)集判斷是否為核心點(diǎn),然后擴(kuò)展該核心點(diǎn),這種先來者原則在處理簇的跨界點(diǎn)時(shí)會(huì)使一些跨界點(diǎn)不屬于最佳簇[18],在識(shí)別事故多發(fā)點(diǎn)時(shí)可能將高密度區(qū)域劃分為兩個(gè)不同的簇。
CFDP算法對(duì)交通事故多發(fā)點(diǎn)識(shí)別的適應(yīng)性主要在于其中心點(diǎn)選擇與剩余點(diǎn)分配方式,算法選擇密度大且距離其他密度大的點(diǎn)較遠(yuǎn)的點(diǎn)作為聚類中心點(diǎn),避免將高密度區(qū)域分開,剩余點(diǎn)分配到距離其最近的密度大于自己的中心點(diǎn)所在簇,很好地解決了邊界點(diǎn)的分配問題[19]。交通事故多發(fā)點(diǎn)的識(shí)別需要在事故多發(fā)點(diǎn)定義范圍內(nèi)找到高密度區(qū)域,CFDP算法符合這一要求。CFDP算法應(yīng)用在事故多發(fā)點(diǎn)識(shí)別中存在的問題包括:a)CFDP算法在聚類過程中需要根據(jù)截?cái)嗑嚯x選擇簇的個(gè)數(shù),而在交通事故多發(fā)點(diǎn)識(shí)別中,難以預(yù)先設(shè)定事故多發(fā)點(diǎn)的個(gè)數(shù);b)在識(shí)別事故多發(fā)點(diǎn)時(shí),事故多發(fā)點(diǎn)定義之外的事故數(shù)據(jù)點(diǎn)應(yīng)該被標(biāo)記為噪聲點(diǎn),而CFDP算法對(duì)噪聲的識(shí)別不夠敏感,剩余點(diǎn)分配過程中會(huì)將其余點(diǎn)分配到距離其最近的中心點(diǎn)。
本文結(jié)合DBSCAN與CFDP算法在交通事故識(shí)別中的優(yōu)勢(shì),針對(duì)兩種算法的局限性,分別從中心點(diǎn)選擇與簇?cái)U(kuò)展方式兩個(gè)方面進(jìn)行改進(jìn)以提升交通事故多發(fā)點(diǎn)的識(shí)別效果。
2.1 基本定義
給定數(shù)據(jù)集、距離半徑ε、點(diǎn)數(shù)閾值MinPts、擴(kuò)展因子exp,其中ε和MinPts為用戶指定參數(shù),exp為實(shí)驗(yàn)得出,有如下定義:
定義9 ε鄰域。同定義1。
定義10 擴(kuò)展因子exp。控制簇?cái)U(kuò)展范圍大小的因素,可以根據(jù)實(shí)際情況設(shè)定,也可根據(jù)實(shí)驗(yàn)得出最優(yōu)取值。
定義11 擴(kuò)展半徑expradio。表示核心對(duì)象ε鄰域內(nèi)的點(diǎn)擴(kuò)展的范圍,如式(7)所示。
2.2 中心點(diǎn)選擇
DBSCAN算法在選擇核心點(diǎn)時(shí)通過遍歷數(shù)據(jù)集判斷是否為核心點(diǎn),若是核心點(diǎn),則將該點(diǎn)鄰域內(nèi)的樣本集合以及與其密度相連的所有點(diǎn)劃分為一個(gè)簇,這種方式在處理多個(gè)簇的跨界點(diǎn)時(shí)會(huì)使一些跨界點(diǎn)不屬于最佳簇。CFDP算法通過設(shè)置截?cái)嗑嚯x,根據(jù)決策圖人工設(shè)置簇?cái)?shù),但在事故多發(fā)點(diǎn)聚類中,簇?cái)?shù)無法提前獲取,且CFDP算法不能識(shí)別噪聲點(diǎn),會(huì)將所有點(diǎn)分配到距離最近的中心點(diǎn)所在的簇[20]。
LA-CFDP算法從參數(shù)設(shè)置方面限制中心點(diǎn)的選擇,事故多發(fā)點(diǎn)聚類理想的中心點(diǎn)是密度大、與距離其他密度大的點(diǎn)距離相對(duì)遠(yuǎn)的點(diǎn),并且密度要大于閾值(ε鄰域半徑內(nèi)MinPts以上的點(diǎn))。所以對(duì)中心點(diǎn)的選取增加限制條件——密度必須大于MinPts/ε。此外,CFDP算法是先確定中心點(diǎn)個(gè)數(shù)再進(jìn)行聚類,事故多發(fā)點(diǎn)聚類時(shí)難以確定聚類個(gè)數(shù),所以選擇中心點(diǎn)和聚類同時(shí)進(jìn)行。中心點(diǎn)選擇條件為滿足ρ>MinPts/ε 的點(diǎn)的ρ×δ 取值從大到小降序排列,從中不斷取出點(diǎn)聚類,直到遍歷完所有點(diǎn)。
2.3 簇?cái)U(kuò)展方式
如果不對(duì)簇進(jìn)行擴(kuò)展,可能會(huì)使距離相近的兩個(gè)點(diǎn)被分到不同簇中,或有些點(diǎn)被認(rèn)為是噪聲點(diǎn);如果按照DBSCAN算法中簇?cái)U(kuò)展方式,所有密度相連的點(diǎn)都會(huì)被聚為一類,擴(kuò)大了事故多發(fā)點(diǎn)范圍,不符合事故多發(fā)點(diǎn)的定義。因此需要設(shè)置一個(gè)參數(shù)限制簇?cái)U(kuò)展的范圍,在合理范圍內(nèi)對(duì)簇進(jìn)行擴(kuò)展,從而在滿足現(xiàn)實(shí)定義的情況下得到更好的聚類效果。簇?cái)U(kuò)展改進(jìn)方式主要是限制簇?cái)U(kuò)展的范圍,距離核心點(diǎn)越近的數(shù)據(jù)點(diǎn)擴(kuò)展范圍越大,越遠(yuǎn)的點(diǎn)擴(kuò)展范圍越小。簇?cái)U(kuò)展方式的改進(jìn)使用式(4),其中exp為人為指定,數(shù)值的選取通過繪圖觀察各聚類效果評(píng)價(jià)指標(biāo)來判定,或根據(jù)實(shí)際情況設(shè)定。
2.4 算法流程
給定數(shù)據(jù)集D={x1,x2,…,xn},使用LA-CFDP算法進(jìn)行聚類的過程如下:a)根據(jù)距離計(jì)算公式計(jì)算數(shù)據(jù)集的距離矩陣;b)根據(jù)數(shù)據(jù)集的距離矩陣和參數(shù)ε與MinPts計(jì)算所有數(shù)據(jù)點(diǎn)的密度ρi、最小距離δi以及每個(gè)數(shù)據(jù)點(diǎn)的上級(jí);c)將ρi×δi的大小降序排列,選擇其中最大值作為類簇中心(cluster center),標(biāo)記為一個(gè)簇;d)遍歷每一個(gè)數(shù)據(jù)點(diǎn),將上級(jí)是當(dāng)前中心點(diǎn)且與當(dāng)前中心點(diǎn)距離小于鄰域半徑ε的點(diǎn)標(biāo)記為當(dāng)前簇;e)簇?cái)U(kuò)展,遍歷簇內(nèi)點(diǎn),按照式(4)擴(kuò)展簇,將擴(kuò)展后的點(diǎn)標(biāo)記為該簇;f)選擇下一個(gè)ρi×δi最大的點(diǎn)作為下一個(gè)中心點(diǎn),重復(fù)步驟c~f),直到所有點(diǎn)都被標(biāo)記;g)遍歷所有簇,將簇中點(diǎn)數(shù)小于MinPts的簇的所有點(diǎn)都標(biāo)記為噪聲點(diǎn),聚類完成。
2.5 算法主要函數(shù)偽代碼
1)聚類過程偽代碼
輸入:數(shù)據(jù)集D={x1,x2,…,xn},中心點(diǎn)集合centers,上級(jí)nearest_neiber,鄰域半徑ε,點(diǎn)數(shù)閾值MinPts,擴(kuò)展半徑exp。
輸出:簇劃分結(jié)果,即xi∈D,cluster(xp)。
初始化簇標(biāo)號(hào)k=0,對(duì)xi∈D,訪問標(biāo)記visited(xi)=0(0代表未訪問,1代表已訪問);
for center∈centers,visited(center)=0
k=k+1;
將center標(biāo)記為中心點(diǎn),visited(center=1),cluster(center)=k;
for xj∈D,xjcenters
if visited(xj)=0,nearest_neiber(xj)=center,deltas(xj)<ε
cluster(xj)=k,visited(xj)=1;
cluster_expand(all_points,xj,ε,exp,k);
end if
end for
end for
重復(fù)運(yùn)行以上步驟,直到滿足xi∈D,visited(xi)=1。
2)簇?cái)U(kuò)展函數(shù)偽代碼
計(jì)算當(dāng)前點(diǎn)擴(kuò)展半徑exp_radio=(ε-dists[:xj])*exp;
for xk∈D,xkcenters
if visited(xk)=0,dists[:xj]<=exp_radio
visited(xk)=1;
cluster(xk)=k;
end if
end for
3 算法應(yīng)用與結(jié)果分析
本文中聚類算法所使用的實(shí)驗(yàn)環(huán)境:系統(tǒng)為Windows 10,處理器為Intel CoreTM i7-6700 CPU@3.40 GHz,內(nèi)存為16 GB,算法基于Python 3.8實(shí)現(xiàn)。
實(shí)驗(yàn)使用英國(guó)2019年交通事故數(shù)據(jù)集,選擇事故數(shù)據(jù)分布的不同城市來分析對(duì)于不同分布數(shù)據(jù)各算法的適應(yīng)性。選取city1威斯敏斯特(Westminster)、city8南華克(Southwark)、city300伯明翰(Birmingham)和city390劍橋(Cambridge)這四個(gè)城市的交通事故數(shù)據(jù)進(jìn)行實(shí)驗(yàn)。首先對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,篩除有空白字段以及沒有標(biāo)明具體位置的數(shù)據(jù),預(yù)處理后剩余事故數(shù)據(jù)情況如表1所示。
英國(guó)對(duì)道路交通事故多發(fā)點(diǎn)段及地區(qū)的定義是:0.1 km2范圍內(nèi),1年發(fā)生超過4次交通事故的地區(qū)叫做危險(xiǎn)點(diǎn);0.3 km長(zhǎng)的路段,3年發(fā)生超過12次交通事故的地區(qū)稱為事故多發(fā)路段;1 km2范圍內(nèi),1年發(fā)生超過40次交通事故的地方稱為事故多發(fā)地區(qū)。本文選擇事故多發(fā)點(diǎn)的定義作為標(biāo)準(zhǔn),對(duì)事故數(shù)據(jù)進(jìn)行聚類。
3.1 DBSCAN算法事故數(shù)據(jù)聚類
使用DBSCAN算法對(duì)四個(gè)城市的事故數(shù)據(jù)city1、city8、city-300、city390進(jìn)行聚類。DBSCAN算法需要指定鄰域半徑ε和點(diǎn)數(shù)閾值MinPts這兩個(gè)參數(shù),同時(shí)還需要根據(jù)實(shí)驗(yàn)需求選擇合適的距離度量方式。
a)距離度量方式。聚類算法常用的距離度量方式為歐氏距離,在交通事故多發(fā)點(diǎn)識(shí)別時(shí),使用的是經(jīng)緯度數(shù)據(jù),距離是實(shí)際地理位置之間的距離,因此在實(shí)驗(yàn)過程中采用半正矢公式,將經(jīng)緯度距離轉(zhuǎn)換為兩點(diǎn)之間的距離來替換歐氏距離,便于對(duì)參數(shù)的設(shè)置。
b)鄰域半徑ε。參考英國(guó)交通事故多發(fā)點(diǎn)定義,“0.1 km2范圍內(nèi)”表示距離范圍,DBSCAN算法中鄰域半徑ε為圓的半徑,因此將0.1 km2范圍轉(zhuǎn)換為圓的面積,根據(jù)公式S=πr2將0.1 km2范圍轉(zhuǎn)換為圓的面積得到r=178 m,因此將鄰域半徑ε設(shè)置為178。
c)點(diǎn)數(shù)閾值MinPts。參考英國(guó)交通事故多發(fā)點(diǎn)定義,“1年發(fā)生超過4次交通事故”表示交通事故多發(fā)點(diǎn)最少包含的事故數(shù)量,因此將點(diǎn)數(shù)閾值MinPts設(shè)置為4。
圖1為四個(gè)城市聚類結(jié)果圖,圖中每種顏色和形狀分別代表一個(gè)聚類簇,黑色點(diǎn)表示噪聲點(diǎn)(參見電子版)。表2為四個(gè)城市聚類效果評(píng)價(jià)指標(biāo),列出簇?cái)?shù)、輪廓系數(shù)、CHI、DBI四個(gè)值驗(yàn)證實(shí)驗(yàn)效果。從圖1和表2所示結(jié)果以及各城市事故數(shù)據(jù)分布特點(diǎn)可以看出,DBSCAN算法對(duì)city300和city390這樣分布較為分散、密度相連的數(shù)據(jù)點(diǎn)較少的數(shù)據(jù)集聚類效果較好,輪廓系數(shù)能達(dá)到0.5以上,DBI值降低到0.5以下,CHI也明顯高于其他兩個(gè)城市;而對(duì)于city1和city8這樣數(shù)據(jù)分布較密集且大量數(shù)據(jù)點(diǎn)密度相連的數(shù)據(jù)集而言,DBSCAN算法的聚類效果很差,輪廓系數(shù)為負(fù)值,DBI接近1,說明聚類結(jié)果不合理,將不應(yīng)該在同一個(gè)簇中的點(diǎn)劃分到一個(gè)簇中,或?qū)⒈驹搫澐衷谝粋€(gè)簇中的點(diǎn)分開。
DBSCAN算法在簇?cái)U(kuò)展時(shí),容易將密度相連的大多數(shù)數(shù)據(jù)點(diǎn)聚為一個(gè)簇,如圖1(a)中紅色方塊部分以及圖1(b)中粉色圓部分,大面積的數(shù)據(jù)點(diǎn)被聚類為同一個(gè)簇,這樣會(huì)降低聚類準(zhǔn)確率。事故多發(fā)點(diǎn)是指一定時(shí)間、一定距離范圍內(nèi)發(fā)生事故數(shù)量的累計(jì)程度,大范圍的擴(kuò)展使結(jié)果背離事故多發(fā)點(diǎn)的定義。
在實(shí)際應(yīng)用中,DBSCAN算法的重點(diǎn)在于尋找密度相連的最大集合,而交通事故多發(fā)點(diǎn)識(shí)別的重點(diǎn)在于指定范圍內(nèi)精準(zhǔn)尋找事故多發(fā)點(diǎn)的位置。由于DBSCAN算法在數(shù)據(jù)點(diǎn)密度相連的情況下會(huì)不斷擴(kuò)大簇的范圍,其在事故多發(fā)點(diǎn)識(shí)別中存在一定的局限性,在識(shí)別事故多發(fā)點(diǎn)時(shí)范圍不應(yīng)該被無限擴(kuò)大,所以應(yīng)用DBSCAN算法進(jìn)行交通事故多發(fā)點(diǎn)識(shí)別時(shí),需要對(duì)DBSCAN算法的簇?cái)U(kuò)展方式進(jìn)行一定的改進(jìn)和優(yōu)化。
3.2 CFDP算法事故數(shù)據(jù)聚類
使用CFDP算法對(duì)四個(gè)城市的事故數(shù)據(jù)city1、city8、city-300、city390進(jìn)行聚類。CFDP算法的參數(shù)包括截?cái)嗑嚯x以及根據(jù)決策圖選定的簇?cái)?shù)。
a)距離度量方式。同DBSCAN算法距離度量方式。
b)截?cái)嗑嚯xdc。CFDP算法中數(shù)據(jù)點(diǎn)密度為與樣本點(diǎn)i的距離小于截?cái)嗑嚯xdc的點(diǎn)的數(shù)量,截?cái)嗑嚯x與DBSCAN算法中鄰域半徑ε含義相近,因此將截?cái)嗑嚯xdc設(shè)置為178,與DBSCAN算法鄰域半徑ε設(shè)置原理類似。
c)簇?cái)?shù)。CFDP算法在運(yùn)算過程中需要由用戶根據(jù)決策圖及實(shí)際情況來指定簇的個(gè)數(shù),對(duì)于這幾個(gè)城市的事故數(shù)據(jù),使用輪廓系數(shù)、CHI以及DBI三個(gè)聚類評(píng)價(jià)指標(biāo),根據(jù)指標(biāo)大小選擇最優(yōu)簇?cái)?shù),選擇使兩個(gè)指標(biāo)最優(yōu)的簇?cái)?shù)作為CFDP算法聚類簇?cái)?shù)。
根據(jù)DBSCAN算法聚類結(jié)果,簇?cái)?shù)范圍應(yīng)當(dāng)在200以內(nèi),因此設(shè)定初始簇?cái)?shù)區(qū)間為[0,200],通過實(shí)驗(yàn)觀察指標(biāo)變化趨勢(shì),選擇指標(biāo)最大的范圍縮小簇?cái)?shù)區(qū)間,得到四個(gè)城市的簇?cái)?shù)最佳區(qū)間分別為[25,30],[30,35],[190,200],[75,80]。圖2為四個(gè)城市事故數(shù)據(jù)簇?cái)?shù)最佳區(qū)間內(nèi)指標(biāo)變化圖,在這個(gè)區(qū)間內(nèi)選擇使評(píng)價(jià)指標(biāo)最優(yōu)的參數(shù)。觀察圖中曲線趨勢(shì),可得簇?cái)?shù)設(shè)置為表3中列出的數(shù)據(jù)時(shí),聚類效果最好。
使用CFDP算法對(duì)四個(gè)城市的事故數(shù)據(jù)集進(jìn)行聚類,用表3中的簇?cái)?shù)作為聚類簇?cái)?shù),聚類結(jié)果如圖3所示。圖中每種顏色和形狀分別代表一個(gè)聚類簇(參見電子版),“+”表示聚類中心。表4為各個(gè)城市聚類結(jié)果評(píng)價(jià)指標(biāo)。
實(shí)驗(yàn)結(jié)果表明,CFDP算法對(duì)幾個(gè)城市數(shù)據(jù)聚類結(jié)果相似,輪廓系數(shù)在0.3~0.4,DBI超過0.65時(shí)聚類效果較差。實(shí)際應(yīng)用中,CFDP算法在對(duì)交通事故數(shù)據(jù)進(jìn)行聚類時(shí)需要指定簇的個(gè)數(shù),而對(duì)于交通事故多發(fā)點(diǎn)來說,簇的個(gè)數(shù)難以提前設(shè)定。此外,CFDP算法在為聚類中心分配剩余點(diǎn)時(shí),將每個(gè)點(diǎn)分配到距離最近的中心點(diǎn)所在簇,沒有考慮到該點(diǎn)與中心點(diǎn)間的距離,不符合事故多發(fā)點(diǎn)的定義。
3.3 LA-CFDP算法事故數(shù)據(jù)聚類
使用LA-CFDP算法對(duì)四個(gè)城市的事故數(shù)據(jù)city1、city8、city300、city390進(jìn)行聚類。LA-CFDP算法需要設(shè)置鄰域半徑ε和點(diǎn)數(shù)閾值MinPts兩個(gè)參數(shù),同時(shí)還需要根據(jù)聚類效果評(píng)價(jià)指標(biāo)設(shè)置擴(kuò)展因子值。
a)距離度量方式。同DBSCAN算法距離度量方式。
b)鄰域半徑ε和點(diǎn)數(shù)閾值MinPts。同DBSCAN算法。
c)擴(kuò)展因子。擴(kuò)展半徑表示核心對(duì)象ε鄰域內(nèi)的點(diǎn)擴(kuò)展的范圍,擴(kuò)展因子用來限制簇的擴(kuò)展,使簇在一定范圍內(nèi)擴(kuò)展,距離中心點(diǎn)越近的點(diǎn)擴(kuò)展范圍越大,反之越小,如式(7)所示。擴(kuò)展因子的設(shè)置可以依據(jù)實(shí)際值,也可以根據(jù)聚類效果選擇使聚類效果達(dá)到最好的值作為擴(kuò)展因子。本文根據(jù)三個(gè)聚類評(píng)價(jià)指標(biāo)值來設(shè)置,將擴(kuò)展因子設(shè)置為使聚類效果評(píng)價(jià)指標(biāo)中兩個(gè)以上達(dá)到最優(yōu)的值。
首先,將初始擴(kuò)展因子范圍設(shè)置為[0,2],通過實(shí)驗(yàn)觀察指標(biāo)輪廓系數(shù)、CHI、DBI的變化趨勢(shì),選擇指標(biāo)最大的范圍縮小擴(kuò)展因子區(qū)間,得到city1、city8、city300、city390的擴(kuò)展因子最佳區(qū)間分別為[0,0.5],[0.15,0.25],[0.1,0.4],[0.1,0.4]。圖4為四個(gè)城市事故數(shù)據(jù)擴(kuò)展因子最佳區(qū)間內(nèi)指標(biāo)變化圖,在這個(gè)區(qū)間內(nèi)選擇使評(píng)價(jià)指標(biāo)最優(yōu)的參數(shù),由此得到擴(kuò)展因子最優(yōu)取值,當(dāng)擴(kuò)展因子取值如表5所示時(shí)聚類效果最好。
設(shè)置擴(kuò)展因子后對(duì)事故數(shù)據(jù)進(jìn)行聚類,得到如圖5所示的聚類圖。圖中灰色點(diǎn)為噪聲點(diǎn),其余每種顏色與形狀表示一個(gè)事故簇(參見電子版)。從聚類結(jié)果圖可以看出,LA-CFDP算法避免了將大部分?jǐn)?shù)據(jù)歸為一類,能夠有效根據(jù)定義識(shí)別交通事故多發(fā)點(diǎn),同時(shí)能從事故數(shù)據(jù)中識(shí)別出噪聲數(shù)據(jù),避免噪聲點(diǎn)對(duì)實(shí)驗(yàn)結(jié)果的影響,提高事故多發(fā)點(diǎn)識(shí)別的準(zhǔn)確性。
表6為L(zhǎng)A-CFDP算法聚類效果評(píng)價(jià)指標(biāo),在四個(gè)數(shù)據(jù)集上,LA-CFDP算法都得到較好的實(shí)驗(yàn)結(jié)果,各項(xiàng)指標(biāo)明顯提高。
表7列出了DBSCAN、CFDP以及LA-CFDP算法的實(shí)驗(yàn)結(jié)果對(duì)比,從對(duì)比結(jié)果可以看出,相比DBSCAN算法,LA-CFDP算法的輪廓系數(shù)增長(zhǎng)了48%以上,CHI值增長(zhǎng)了4.6倍以上,DBI值至少降低了55%,且對(duì)于DBSCAN算法聚類效果較差的城市如city1,輪廓系數(shù)值由-0.31增長(zhǎng)到0.73,CHI值提高了62倍,DBI值降低了63%。輪廓系數(shù)、CHI、DBI都是通過樣本點(diǎn)與聚類中心之間的距離來衡量聚類結(jié)果的優(yōu)劣,DBSCAN算法在簇?cái)U(kuò)展過程中擴(kuò)大了簇的范圍,同時(shí)擴(kuò)大了簇內(nèi)各樣本點(diǎn)與聚類中心之間的距離,導(dǎo)致評(píng)價(jià)指標(biāo)較低;而LA-CFDP算法限制簇的擴(kuò)展范圍,增加了簇的凝聚度,從而提高了評(píng)價(jià)指標(biāo)值。此外,簇?cái)U(kuò)展范圍的限制也滿足交通事故多發(fā)點(diǎn)的定義,LA-CFDP算法有效提高了交通事故多發(fā)點(diǎn)識(shí)別結(jié)果的準(zhǔn)確性。相比CFDP算法,LA-CFDP算法的輪廓系數(shù)增長(zhǎng)了1.3倍以上,CHI值增長(zhǎng)了1.9倍以上,最高增長(zhǎng)了11.4倍,DBI值至少降低了129%,最高達(dá)378%。CFDP算法在剩余點(diǎn)分配時(shí)沒有限制中心點(diǎn)與剩余點(diǎn)之間的距離,致使評(píng)價(jià)指標(biāo)較低,而LA-CFDP算法限制了分配距離,有效識(shí)別出噪聲點(diǎn),提高了評(píng)價(jià)指標(biāo)值。在交通事故多發(fā)點(diǎn)識(shí)別中,簇內(nèi)的點(diǎn)應(yīng)當(dāng)符合交通事故多發(fā)點(diǎn)定義范圍,其余點(diǎn)則被識(shí)別為噪聲點(diǎn),因此對(duì)剩余點(diǎn)分配的改進(jìn)同樣適用于交通事故多發(fā)點(diǎn)的識(shí)別,同時(shí)LA-CFDP算法無須設(shè)定簇的個(gè)數(shù),對(duì)交通事故多發(fā)點(diǎn)識(shí)別具有很好的適用性。
3.4 交通事故多發(fā)點(diǎn)應(yīng)用分析
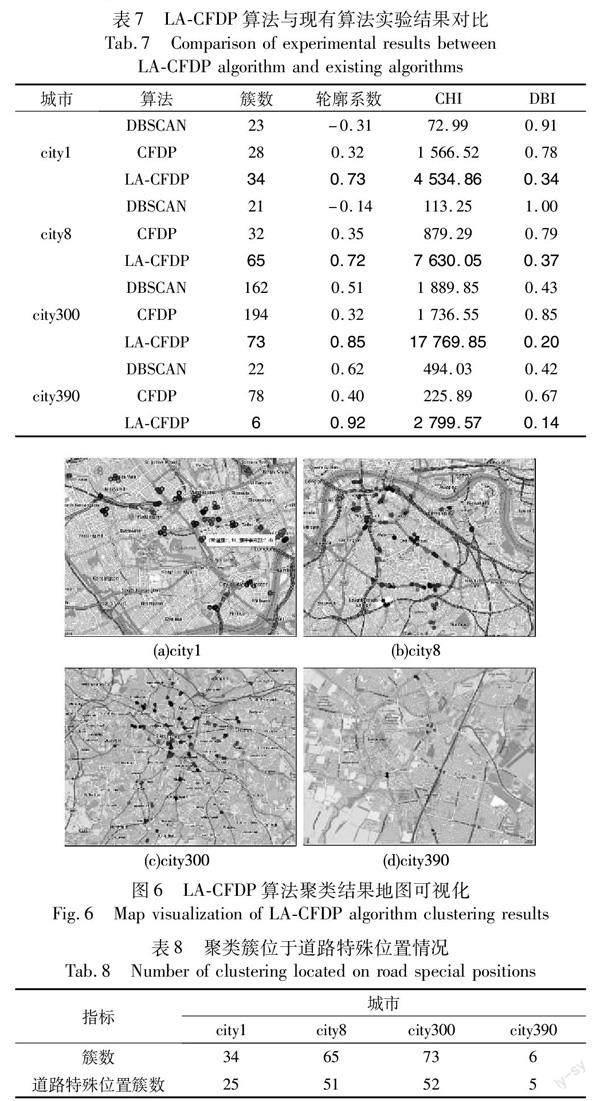
將聚類結(jié)果可視化在地圖上(圖6)可以看出,交通事故多發(fā)點(diǎn)位置大多位于交叉口、十字路口等位置。通過分析事故數(shù)據(jù)其余字段驗(yàn)證聚類結(jié)果(表8)可以得出,在聚類得到的事故多發(fā)點(diǎn)中,位于道路特殊位置的簇?cái)?shù)占總簇?cái)?shù)的70%以上,道路特殊位置包括交叉口、十字路口、環(huán)島、T型交錯(cuò)口等特殊交通位置,說明聚類結(jié)果與現(xiàn)實(shí)情況相符,證明了LA-CFDP算法識(shí)別交通事故多發(fā)點(diǎn)段的合理性。
識(shí)別出交通事故多發(fā)點(diǎn)之后,可以結(jié)合事故數(shù)據(jù)其他字段對(duì)交通事故多發(fā)點(diǎn)的原因進(jìn)行深入分析,包括道路設(shè)計(jì)不合理、交通信號(hào)不暢、駕駛員行為不當(dāng)?shù)确矫妫页鍪鹿拾l(fā)生的主要原因,交管部門根據(jù)這些原因可以制定相應(yīng)的解決方案,包括加強(qiáng)交通信號(hào)的設(shè)置、完善道路設(shè)計(jì)、加強(qiáng)對(duì)駕駛員的監(jiān)管等;還可以基于歷史交通事故數(shù)據(jù)和交通狀態(tài)數(shù)據(jù),結(jié)合交通事故多發(fā)點(diǎn)位置建立交通事故多發(fā)點(diǎn)預(yù)測(cè)模型,為交通管理提供科學(xué)依據(jù)。
4 結(jié)束語
本文提出了一種適用于交通事故多發(fā)點(diǎn)識(shí)別的聚類算法,將DBSCAN算法的參數(shù)及簇?cái)U(kuò)展思想引入到CFDP算法中,使CFDP算法能夠自適應(yīng)確定簇?cái)?shù)。LA-CFDP算法的參數(shù)對(duì)應(yīng)交通事故多發(fā)點(diǎn)的定義,具有很好的適用性。本文實(shí)例使用英國(guó)交通事故數(shù)據(jù)集,分別用DBSCAN、CFDP以及LA-CFDP算法對(duì)英國(guó)四個(gè)城市的事故數(shù)據(jù)進(jìn)行聚類,并且使用輪廓系數(shù)、CHI、DBI三個(gè)評(píng)價(jià)指標(biāo)來評(píng)價(jià)各算法的實(shí)驗(yàn)結(jié)果,結(jié)果表明,LA-CFDP算法可以克服DBSCAN和CFDP算法存在的局限性,在對(duì)不同分布的交通事故數(shù)據(jù)進(jìn)行聚類時(shí)有很好的聚類效果。分析實(shí)驗(yàn)結(jié)果與事故數(shù)據(jù)其他字段可以得出聚類得到事故易發(fā)位置大多位于道路上交通狀況較為復(fù)雜的位置,確定事故多發(fā)點(diǎn)后可以利用多發(fā)點(diǎn)其他字段信息進(jìn)行不同角度的分析。本研究后續(xù)將聚焦事故多發(fā)點(diǎn)事故多發(fā)原因分析,使用事故數(shù)據(jù)其他字段信息,結(jié)合數(shù)據(jù)挖掘、機(jī)器學(xué)習(xí)與深度學(xué)習(xí)方法,全面挖掘事故數(shù)據(jù),從中發(fā)現(xiàn)事故多發(fā)的原因,為交通事故多發(fā)點(diǎn)治理提供科學(xué)依據(jù)。
參考文獻(xiàn):
[1]Aziz S, Ram S. A meta-analysis of the methodologies practiced worldwide for the identification of road accident black spots[J].Transportation Research Procedia,2022,62:790-797.
[2]Wang Dianhai, Huang Yulang, Cai Zhengyi. A two-phase clustering approach for traffic accident black spots identification: integrated GIS-based processing and HDBSCAN model[J].International Journal of Injury Control and Safety Promotion,2023,30(2):270-281.
[3]Cui Hongjun, Dong Jianguo, Zhu Minqing, et al. Identifying accident black spots based on the accident spacing distribution[J].Journal of Traffic and Transportation Engineering,2022,9(6):1017-1026.
[4]Wright C C, Abbess C R, Jarrett D F. Estimating the regression-to-mean effect associated with road accident black spot treatment: towards a more realistic approach[J].Accident Analysis & Prevention,1988,20(3):199-214.
[5]Dereli M A, Erdogan S. A new model for determining the traffic accident black spots using GIS-aided spatial statistical methods[J].Transportation Research Part A:Policy and Practice,2017,103(9):106-117.
[6]顏茜,吳志敏,李明國(guó).高速公路事故多發(fā)路段的鑒別及成因分析[J].廣東公路交通,2018,44(5):28-30,53.(Yan Qian, Wu Zhimin, Li Mingguo. Identification and cause analysis on expressway accident-prone sections[J].Guangdong Highway Communications,2018,44(5):28-30,53.)
[7]孫元強(qiáng).基于改進(jìn)累計(jì)頻率曲線法的交通事故黑點(diǎn)鑒別及智能識(shí)別平臺(tái)構(gòu)建[D].西安:長(zhǎng)安大學(xué),2021.(Sun Yuanqiang. Identification of black spots in traffic accidents based on improved cumulative frequency curve method and intelligent recognition platform construction[D].Xian:Changan University,2021.)
[8]張鵬.基于模糊層次分析法的某高速公路事故多發(fā)路段安全性綜合評(píng)價(jià)[J].黑龍江交通科技,2021,44(7):199-200.(Zhang Peng. Comprehensive safety evaluation of accident-prone section of a freeway based on fuzzy analytic hierarchy process[J].Communications Science and Technology Heilongjiang,2021,44(7):199-200.)
[9]耿超,彭余華.基于動(dòng)態(tài)分段和DBSCAN算法的交通事故黑點(diǎn)路段鑒別方法[J].長(zhǎng)安大學(xué)學(xué)報(bào):自然科學(xué)版,2018,38(5):131-138.(Geng Chao, Peng Yuhua. Identification method of traffic accident black spots based on dynamic segmentation and DBSCAN algorithm[J].Journal of Chang an University:Natural Science Edition,2018,38(5):131-138.)
[10]王鴻遙,孫璐,游克思.基于DENCLUE聚類算法的交通事故多發(fā)點(diǎn)鑒別方法[J].交通運(yùn)輸工程與信息學(xué)報(bào),2013,11(2):5-10.(Wang Hongyao, Sun Lu, You Kesi. Accident-prone location identification method based on DENCLUE clustering algorithm[J].Journal of Transportation Engineering and Information,2013,11(2):5-10.)
[11]曹陽,陳天滋,柴勇.基于GIS的道路事故黑點(diǎn)聚類應(yīng)用研究[J].微計(jì)算機(jī)信息,2006,22(31):253-255.(Cao Yang, Chen Tianzi, Chai Yong. Study on application of clustering in highway accident spot based on GIS[J].Microcomputer Information,2006,22(31):253-255.)
[12]張?jiān)品疲瑥垵尚瘢旆肩?利用時(shí)空密度聚類的高速公路交通事故黑點(diǎn)路段鑒別[J].測(cè)繪通報(bào),2022(10):73-79.(Zhang Yunfei, Zhang Zexu, Zhu Fangqi. Identification of highway accident black spots based on spatio-temporal density clustering[J].Bulletin of Surveying and Mapping,2022(10):73-79.)
[13]Prasannakumar V, Vijith H, Charutha R, et al. Spatio-temporal clustering of road accidents:GIS based analysis and assessment[J].Procedia-Social and Behavioral Sciences,2011,21(2):317-325.
[14]Ester M, Kriegel H P, Sander J, et al. A density-based algorithm for discovering clusters in large spatial databases with noise[C]//Proc of the 2nd International Conference on Knowledge Discovery and Data Mining.Palo Alto,CA:AAAI Press,1996:226-231.
[15]Rodriguez A, Laio A. Machine learning: clustering by fast search and find of density peaks[J].Science,2014,344(6191):1492-1496.
[16]Guan Junyi, Li Sheng, He Xiongxiong, et al. Clustering by fast detection of main density peaks within a peak digraph[J].Information Sciences,2023,628(5):504-521.
[17]黃學(xué)雨,向馳,陶濤.基于MapReduce和改進(jìn)密度峰值的劃分聚類算法[J].計(jì)算機(jī)應(yīng)用研究,2021,38(10):2988-2993,3024.(Huang Xueyu, Xiang Chi, Tao Tao. Partition clustering algorithm based on MapReduce and improved density peak[J].Application Research of Computers,2021,38(10):2988-2993,3024.)
[18]Zhang Runfa. An adjusting strategy after DBSCAN[J].IFAC-Papers OnLine,2022,55(3):219-222.
[19]王森,邢帥杰,劉琛.密度峰值聚類算法研究綜述[J].華東交通大學(xué)學(xué)報(bào),2023,40(1):106-116.(Wang Sen, Xing Shuaijie, Liu Chen. Survey of density peak clustering algorithm[J].Journal of East China Jiaotong University,2023,40(1):106-116.)
[20]劉美,王全民.基于密度可達(dá)的密度峰值聚類算法[J].計(jì)算機(jī)仿真,2022,39(11):371-375.(Liu Mei, Wang Quanmin. Density peak clustering algorithm based on density reachable[J].Computer Simulation,2022,39(11):371-375.)
收稿日期:2023-02-24;修回日期:2023-04-28
基金項(xiàng)目:陜西省特支計(jì)劃科技創(chuàng)新領(lǐng)軍人才資助項(xiàng)目(TZ0336)
作者簡(jiǎn)介:王藝霖(1999-),女(通信作者),山西太原人,碩士研究生,CCF會(huì)員,主要研究方向?yàn)閿?shù)據(jù)挖掘、交通事故分析(wylin@chd.edu.cn);肖媛媛(1997-),女,陜西西安人,博士研究生,主要研究方向?yàn)闄C(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘;左鵬飛(1997-),女,山西大同人,碩士研究生,主要研究方向?yàn)闄C(jī)器學(xué)習(xí);楊博(1999-),男,山西運(yùn)城人,碩士研究生,主要研究方向?yàn)闄C(jī)器學(xué)習(xí)、數(shù)據(jù)挖掘;劉悅霞(1999-),女,山西臨汾人,碩士研究生,主要研究方向?yàn)閿?shù)據(jù)挖掘;段宗濤(1977-),男,陜西鳳翔人,教授,博導(dǎo),博士,CCF會(huì)員,主要研究方向?yàn)榇髷?shù)據(jù)智能、交通大數(shù)據(jù)分析.
猜你喜歡
艦船科學(xué)技術(shù)(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國(guó)交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國(guó)中醫(yī)藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(shù)(2015年6期)2015-12-26 01:16:46
西安工程大學(xué)學(xué)報(bào)(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:13
電子設(shè)計(jì)工程(2014年18期)2014-02-27 12:00:12

- 計(jì)算機(jī)應(yīng)用研究的其它文章
- 基于Prim-DMGA算法的閉環(huán)供應(yīng)鏈網(wǎng)絡(luò)魯棒優(yōu)化研究
- 混合哈里斯鷹優(yōu)化算法求解帶模糊需求的低碳多式聯(lián)運(yùn)路徑規(guī)劃問題
- 基于時(shí)空殘差張量學(xué)習(xí)的城市路網(wǎng)交通數(shù)據(jù)修復(fù)
- 基于圖卷積網(wǎng)絡(luò)融合依存信息的事件檢測(cè)方法
- 基于Spark和AMPSO的并行深度卷積神經(jīng)網(wǎng)絡(luò)優(yōu)化算法
- 融合一致性社交關(guān)系的協(xié)同相似嵌入推薦模型