基于細粒度信息集成的意圖識別和槽填充聯合模型
2023-10-18 05:06:59周天益范永全杜亞軍李顯勇
計算機應用研究 2023年9期
周天益 范永全 杜亞軍 李顯勇


摘 要:意圖識別和槽位填充是構建口語理解(SLU)系統的兩項主要任務,兩者相互聯合的模型是對話系統的研究熱點。這兩個任務緊密相連,槽位填充通常高度依賴于意圖信息。針對最近聯合模型中:固定閾值很難在不同領域中選擇出正向的投票,且復雜的意圖信息不能充分地引導槽位填充的問題。提出了一種基于細粒度信息集成的意圖識別和槽填充聯合模型。其中,將由意圖解碼器獲取的意圖信息與各單詞的編碼表示拼接,形成意圖引導的集成編碼表示,從而為單詞級槽位填充提供細粒度的意圖信息。同時,通過計算最大意圖得分和最小意圖得分的中間值獲得邏輯自適應閾值,并用其代替固定閾值。邏輯自適應閾值可隨不同意圖標簽的得分分布而變化。通過在兩個多標簽數據集上的實驗結果驗證了提出的模型的性能。
關鍵詞:意圖識別; 槽位填充; 聯合模型; 雙向LSTM
中圖分類號:TP311?? 文獻標志碼:A
文章編號:1001-3695(2023)09-017-2669-05
doi:10.19734/j.issn.1001-3695.2023.01.0015
Joint model of intent detection and slot filling based on
fine-grained information integration
Zhou Tianyi, Fan Yongquan, Du Yajun, Li Xianyong
(School of Computer & Software Engineering, Xihua University, Chengdu 610039, China)
Abstract:Intent detection and slot filling are two main tasks for building a spoken language understanding(SLU) system, the joint model of the two tasks is the research hotspot of the dialogue system. These two tasks are closely tied and the slots often highly depend on the intent. For the recent joint model: the fixed threshold is difficult to extract the positive votes in different domains. And the complex intent information guides the slot filling insufficiently. This paper proposed a fine-grained information integrated model for multiple intent detection and slot filling. Among this model, the intent information obtained by the intent decoder was concatenate with the encoding representation of each token to form an intent guided integrated encoding representation, so as to offer fine-grained intent information for the token-level slot prediction. At the same time, calculating the median of the maximum intent score and the minimum intent score to obtain the logic-adaptive threshold, and used it replace the fixed threshold. The logic-adaptive threshold can vary with the score distribution of different intent labels. Experimental results on two multi-label datasets verifies the performance of the proposed model.
Key words:intent detection; slot filling; joint model; Bi-LSTM
0 引言
口語理解(SLU) [1]是面向任務對話系統的關鍵組成部分。它通常包括意圖識別[2]和槽位填充[3]兩個子任務。意圖識別任務主要是識別用戶的意圖,槽位填充任務主要是從自然語言中提取語義成分。通常,意圖識別和槽位填充是分開實現的,但直觀地說這兩個任務并不是獨立的,槽位填充通常高度依賴于意圖信息[4]。給定一個與音樂相關的話語“listen to classical music”,其中每個單詞都有不同的槽位標簽,而整個話語則對應一個意圖標簽。該話語的意圖標簽為listen_to_music,則話語更可能包含槽位標簽music_name而非槽位標簽movie_name。因此,如何正確且有效地建模意圖識別與槽位填充之間的交互是目前探索的重點。由于意圖識別和槽位填充之間的強相關性,許多基于多任務學習框架的聯合模型被提出。Liu等人[5]提出了一個基于注意力的RNN模型,但其僅應用了一個聯合損失函數來隱式鏈接這兩個任務,模型實際上并未使用意圖信息來引導槽位填充。王宇亮等人[6]提出了基于意圖—槽位注意機制的意圖理解算法。此算法通過槽位選通機制建模意圖和槽位之間的顯式關系,在單標簽場景中取得了成功,而本文的工作則聚焦于多標簽場景下的聯合建模。
多標簽意圖識別可以識別話語中的多個意圖,因此引起了越來越多的關注。Xu等人[7]探索多標簽意圖識別,然而,文獻[7]僅考慮了意圖識別,而忽略了槽位填充任務。Gangadharaiah等人[8]首次使用具有槽門機制的多任務框架來聯合建模多標簽意圖識別和槽位填充,但其僅將多個意圖信息整合為一個復雜的意圖信息來引導所有的槽位填充,而并未提供準確且有效的意圖信息。Qin等人[9]提出了一種自適應交互模型(AGIF),槽位填充由AGIF中的多意圖信息指導,但其仍使用固定閾值篩選對意圖標簽的正向投票。盡管以上模型實現了不錯的性能,但仍面臨兩個問題:a)這些模型采用固定的閾值進行意圖識別,但在不同的領域,每個單詞的意圖分類得分分布是不同的,在某些領域,大多數單詞的意圖分類得分太低,而在其他領域,單詞的意圖分類得分太高,因此固定閾值很難在不同領域有效地選擇正向的投票;b)這些模型簡單地將多個意圖信息整合為一個復雜的意圖信息來引導槽位填充,并沒有為單詞級槽位填充提供準確有效的意圖信息。
本文提出了一種基于細粒度信息集成的多意圖識別和槽位填充聯合模型。在兩個公共數據集MixSNIPS[10]和MixATIS[11]的實驗結果表明本文模型獲得了實質性的改進。本文引入了一種新的閾值確定方法,以選擇適合于各領域的閾值。本文提出的邏輯自適應閾值通過適應不同意圖標簽的得分分布來計算出合適的閾值,從而進行有效的投票選擇,并且其比固定閾值更加通用;提出一個細粒度信息集成模塊,其中細粒度意圖信息與話語的編碼表示相結合來引導單詞級槽位填充;通過在兩個公開的多標簽數據集MixATIS和MixSNIPS上進行的實驗,表明模型的性能實現了實質性的提升。
1 模型框架
模型的結構如圖1所示,其中包含一個共享的自注意力編碼器[12]、一個單詞級意圖識別解碼器、一個基于細粒度信息集成的槽位填充解碼器。共享的自注意力編碼器由兩部分組成。其中之一是雙向LSTM,用于前向和后向理解輸入話語以生成帶有序列特征的隱藏狀態;另一個是自注意力機制,用于感知長度可變序列的上下文信息。最后將雙向LSTM的隱藏狀態和自注意力結果拼接作為輸入話語的編碼表示。多標簽意圖識別由基于邏輯自適應閾值的單詞級意圖識別解碼器實現。在細粒度信息集成模塊中意圖信息被用來引導槽位填充。本文用意圖標簽和輸入話語的編碼表示來計算意圖—單詞相關性分數。接著,將意圖標簽、意圖—單詞相關性分數和輸入話語編碼表示三者結合起來,形成意圖引導的集成編碼表示。最后,將攜帶細粒度意圖信息的集成編碼表示用于槽位預測。
1.1 自注意編碼器
在口語理解中,單詞的標簽不僅由自身含義決定,還由上下文決定。為了捕獲此類依賴關系,意圖識別和槽位填充使用相同的自注意力編碼器。在自注意力編碼器中,使用雙向LSTM和自注意力機制來獲得話語的序列特征和上下文信息,這些特征和信息對序列標記任務均有幫助。
2 實驗
2.1 數據集
本文在兩個公開的多標簽數據集上進行了實驗。一個關于音樂和天氣的數據集MixSNIPS、一個關于航空旅行的數據集MixATIS。數據集的劃分如表1所示。
2.2 基線模型
本文模型與以下主流的基線模型進行了比較:
a)Attention BiRNN[5]。Liu等人提出了一種基于對齊RNN的槽填充和意圖識別聯合模型。
b)Slot-Gated Atten[4]。Goo等人提出了一種槽位門控聯合模型,考慮了槽位填充和意圖識別之間的相關性。
c)Bi-Model[15]。Wang等人提出了雙向模型來模擬意圖識別和槽位填充之間的雙向交互。
d)SF-ID Network[16]。E等人建立了SF-ID網絡在兩個任務之間建立直接連接。
e)Stack-Propagation[17]。 Qin等人采用棧傳播的框架,顯式地將意圖信息引導槽填充。
f)Joint Multiple ID-SF[8]。Gangadharaiah等人提出了一種具有槽位門控機制的多任務框架,用于多意圖識別和槽位填充。
g)AGIF[9]。 Qin等人提出了一種自適應交互網絡來實現多標簽意圖識別,實現了目前最好的性能。
2.3 主要結果
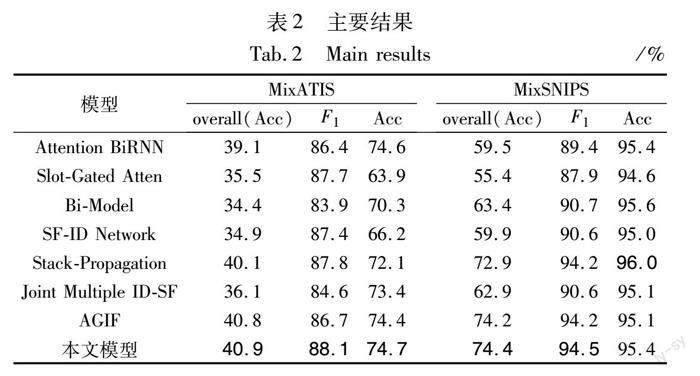
本文使用F1值來評估槽填充的性能表現。意圖識別的性能通過accuracy來評估,句子級的語義分析水平通過overall accuracy來評估。overall accuracy表示意圖識別結果和槽位填充結果同時正確的比率。表2給出了實驗結果,可以看出:a)對于意圖識別,本文模型在accuracy上優于基線AGIF,這意味著所提出的邏輯自適應閾值成功地為特定領域選擇了適當的閾值,因此可以提高意圖識別性能;b)與AGIF相比,本文的模型分別在 MixATIS 和 MixSNIPS上實現了overall accuracy的提升,表明本文提出的細粒度信息集成模型可以更好地捕捉意圖和槽位之間的相關性,從而提高模型對口語理解的性能。
2.4 結果分析
2.4.1 聯合訓練
為驗證聯合訓練的有效性,意圖識別和槽位填充使用獨立的編碼器。細粒度信息集成模塊中的意圖標簽被隨機初始化。意圖—單詞相關性得分均設置為0.5。其他組件保持不變,稱此模型為模型-IL。由表3可得,模型-IL在沒有共享參數的情況下表現不佳,并且在兩個數據集上的總體性能都有所下降。盡管MixSNIPS上的accuracy幾乎不變,但overall accuracy和F1值仍在下降。這一結果可以從兩個方面解釋:a)具有相關性的任務可以通過聯合學習相互促進;b)準確且有效的意圖信息可以引導槽位填充,從而進一步提升模型性能。
2.4.2 細粒度信息集成
去除細粒度信息集成模塊,并將話語編碼表示直接輸入到槽感知的雙向LSTM中來進行消融實驗。將其稱為表3中的模型-FGII。由表3可得,在MixATIS和MixSNIPS數據集上,F1分別下降了1.3%和0.8%。表明細粒度信息集成可以獲得準確有效的意圖信息,從而引導槽位填充。
2.4.3 邏輯自適應閾值
直接使用固定閾值來代替邏輯自適應閾值進行意圖識別,以驗證邏輯自適應閾值的效果,本文將其稱為表3中的模型-LAT。由表3可得,缺乏邏輯自適應閾值分別導致兩個多標簽數據集上的overall accuracy下降了1.0%和0.7%。這意味著邏輯自適應閾值可以選擇適當的閾值以適應特定的話語和領域。
2.4.4 可視化
為直觀地理解細粒度信息集成模塊的功能,對其中的意圖—單詞相關性得分進行了可視化。如圖5所示,豎軸為預測的意圖標簽,橫軸為輸入話語。顏色越深,即相關度越高。紿定話語“Rate this album 5 points and when is just before night- fall playing”和其意圖標簽“RateBook”和 “SearchScreeningEvent”。可以清晰地發現意圖—單詞相關性得分成功地集中在正確的意圖上,這意味著細粒度信息集成模塊可以將與槽位相關的意圖信息結合起來。簡而言之,本文模型恰當地將意圖信息“RateBook”用于槽位“Rate,this, album, 5, points”的預測。類似地,將“SearchScreeningEvent”的意圖信息用于槽位“when,is,just,before,nightfall,playing”的預測。
2.4.5 實例研究
如圖6所示,圖(a)為來自MixATIS的實例,圖(b)為來自MixSNIPS的實例。當意圖—單詞相關性分數大于0.5時,即相關性較強時,將意圖標簽與單詞相連。由圖6可得,各意圖標簽均為其相關的單詞提供了準確且有效的細粒度意圖信息,從而克服了以往模型提供復雜意圖信息而導致歧義的問題,并且對兩個實例預測的槽位標簽均得到了正確的結果,表明本文的模型性能得到了實質性的提升。
3 結束語
本文提出了一種基于細粒度信息集成的意圖識別和槽填充聯合模型,在意圖識別解碼器中使用邏輯自適應閾值以選擇適合于不同話語的閾值,克服固定閾值的問題;提出的邏輯自適應閾值能隨著不同的意圖得分分布而變化,并且比固定閾值更加通用。通過細粒度信息集成獲得的集成編碼表示可以建模槽位和意圖之間的交互,有效地為單詞級槽位填充提供細粒度的意圖信息。此外,意圖—單詞相關性分數的可視化為本文模型提供了一定的可解釋性。在兩個公開的多標簽數據集上的實驗結果表明,本文模型的性能有實質性的提升。未來計劃結合更多的知識并探索新的架構,以更好地模擬單詞、意圖、槽位和其他文本特征之間的交互,從而獲得更好的口語理解性能。
參考文獻:
[1]魏鵬飛, 曾碧, 汪明慧, 等. 基于深度學習的口語理解聯合建模算法綜述[J]. 軟件學報, 2022,33(11):4192-4216. (Wei Pengfei, Zeng Bi, Wang Minghui, et al. A survey of joint modeling algorithms for oral comprehension based on deep learning[J]. Journal of Software, 2022,33(11): 4192-4216.)
[2]鄭思露, 程春玲, 毛毅. 融合實體信息和時序特征的意圖識別模型 [J]. 計算機技術與發展, 2022,32(11): 171-176. (Zheng Silu, Cheng Chunling, Mao Yi. Intention recognition model integrating entity information and temporal features[J]. Computer Technology and Development, 2022,32(11): 171-176.)
[3]劉振元, 許明陽, 王承濤. 基于數據增強和字詞融合特征的實體槽位識別[J]. 華中科技大學學報:自然科學版, 2022,50(11): 101-106. (Liu Zhenyuan, Xu Mingyang, Wang Chengtao. Entity slot recognition based on data enhancement and word fusion features[J]. Journal of Huazhong University of Science and Technology:Natural Science Edition, 2022, 50(11): 101-106.)
[4]Goo C W, Gao Guang, Hsu Y K, et al. Slot-gated modeling for joint slot filling and intent prediction[C]//Proc of Conference of North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018.
[5]Liu Bing, Ian L. Attention-based recurrent neural network models for joint intent detection and slot filling[C]//Proc of the 17th Annual Conference of International Speech Communication Association.2016: 685-689.
[6]王宇亮, 楊觀賜, 羅可欣. 基于意圖—槽位注意機制的醫療咨詢意圖理解與實體抽取算法[J]. 計算機應用研究,2023,40(5):1402-1409. (Wang Yuliang, Yang Guanci, Luo Kexin. Intention understanding and entity extraction algorithm for medical consultation based on intention-slot attention mechanism[J]. Application Research of Computers, 2023,40(5):1402-1409.)
[7]Xu Puyang, Sarikaya R. Convolutional neural network based triangular CRF for joint intent detection and slot filling[C]//Proc of IEEE Workshop on Automatic Speech Recognition and Understanding. Piscataway,NJ:IEEE Press,2013.
[8]Gangadharaiah R, Narayanaswamy B. Joint multiple intent detection and slot labeling for goal-oriented dialog[C]//North American Chapter of Association for Computational Linguistics. 2019.
[9]Qin Libo, Xiao Xu, Che Wanxiang, et al. AGIF: an adaptive graph-interactive framework for joint multiple intent detection and slot filling[C]//Proc of IEEE Workshop on Automatic Speech Recognition and Understanding. Piscataway,NJ:IEEE Press, 2020.
[10]Coucke A, Saade A, Ball A, et al. Snips voice platform: an embedded spoken language understanding system for private-by-design voice interface[EB/OL]. (2018). https://arxiv.org/abs/1805.10190.
[11]Hemphill C T, Godfrey J J, Doddington G R. The ATIS spoken language systems pilot corpus[C]//Proc of Darpa Speech & Natural Language Workshop. 1990.
[12]Qin Libo, Wei Fuxuan, Xie Tianbao, et al. GL-GIN: fast and accurate non-autoregressive model for joint multiple intent detection and slot filling[EB/OL]. (2021-06-03). https://arxiv.org/abs/2106.01925.
[13]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[EB/OL].(2017). https://arxiv.org/abs/1706. 03762.
[14]Yang Peng,Ji Dong,Ai Chengming,et al. AISE: attending to intent and slots explicitly for better spoken language understanding[J]. European Journal of Medicinal Chemistry: Chimie Therapeutique, 2021, 211(1):106537.
[15]Wang Yu, Shen Yilin, Jin Hongxia. A bi-model based RNN semantic frame parsing model for intent detection and slot filling[C]//Proc of Conference of North American Chapter of Association for Computatio-nal Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018.
[16]E Haihong, Niu Peiqing, Chen Zhongfu, et al. A novel bi-directional interrelated model for joint intent detection and slot filling[C]//Proc of the 57th Annual Meeting of Association for Computational Linguistics. 2019: 5467-5471.
[17]Qin Libo, Che Wanxiang, Li Yangming, et al. A stack-propagation framework with token-level intent detection for spoken language understanding[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019: 2078-2087.
收稿日期:2023-01-13;修回日期:2023-03-17? 基金項目:國家自然科學基金資助項目(61872298,61802316,61902324);四川省科技廳資助項目(2023YFQ0044,2021YFQ008)
作者簡介:周天益(1998-),男,江蘇常州人,碩士研究生,主要研究方向為意圖識別;范永全(1976-),男(通信作者),河南淅川人,副教授,碩導,博士,主要研究方向為大數據與人工智能(fyq@mail.xhu.edu.cn);杜亞軍(1967-),男,四川巴中人,教授,碩導,博士,主要研究方向為大數據與人工智能;李顯勇(1984-),男,四川達州人,副教授,碩導,博士,主要研究方向為Web信息挖掘、社交網絡分析.
