基于加權值函數分解的多智能體分層強化學習技能發現方法
2023-10-18 05:40:08鄒啟杰李文雪高兵趙錫玲張汝波
計算機應用研究 2023年9期
鄒啟杰 李文雪 高兵 趙錫玲 張汝波


摘 要:
針對目前大多數多智能體強化學習算法在智能體數量增多以及環境動態不穩定的情況下導致的維度爆炸和獎勵稀疏的問題,提出了一種基于加權值函數分解的多智能體分層強化學習技能發現算法。首先,該算法將集中訓練分散執行的架構與分層強化學習相結合,在上層采用加權值函數分解的方法解決智能體在訓練過程中容易忽略最優策略而選擇次優策略的問題;其次,在下層采用獨立Q學習算法使其能夠在多智能體環境中分散式地處理高維復雜的任務;最后,在底層獨立Q學習的基礎上引入技能發現策略,使智能體之間相互學習互補的技能。分別在簡易團隊運動和星際爭霸Ⅱ兩個仿真實驗平臺上對該算法與多智能體強化學習算法和分層強化學習算法進行對比,實驗表明,該算法在獎勵回報以及雙方對抗勝率等性能指標上都有所提高,提升了整個多智能體系統的決策能力和收斂速度,驗證了算法的可行性。
關鍵詞:多智能體強化學習;分層強化學習;集中訓練分散執行;值函數分解;技能發現
中圖分類號:TP181?? 文獻標志碼:A??? 文章編號:1001-3695(2023)09-027-2743-06
doi:10.19734/j.issn.1001-3695.2022.12.0795
Research on multi-agent hierarchical reinforcement learning skill discovery
method based on weighted value function decomposition
Zou Qijie1, Li Wenxue1, Gao Bing1, Zhao Xiling1, Zhang Rubo2
(1. Dept. of Information Engineering, Dalian University, Dalian Liaoning 116622, China; 2. Dept. of Mechanical & Electrical Engineering, Dalian Nationalities University, Dalian Liaoning 116600, China)
Abstract:
Aiming at the problem of dimension explosion and sparse rewards caused by the increase in the number of agents and the dynamic instability of the environment in most multi-agent reinforcement learning algorithms, this paper proposed a multi-agent hierarchical reinforcement learning skill discovery algorithm based on weighted value function decomposition. Firstly, the algorithm combined the architecture of centralized training and decentralized execution with hierarchical reinforcement learning, and adopted the method of weighted value function decomposition in the upper level to solve the problem that agents tended to ignore the optimal strategy and chose the suboptimal strategy in the training process. Secondly, it adopted the independent Q learning algorithm in the lower level to enable it to deal with high-dimensional complex tasks in a multi-agent environment in a decentralized manner. Finally, it introduced a skill discovery strategy on the basis of independent Q learning at the lower level, so that agents could learn complementary skills from each other. Compared the algorithm with the multi-agent reinforcement learning algorithms and the hierarchical reinforcement learning algorithms on the two simulation experimental platforms of simple team movement and StarCraft Ⅱ respectively. The experiment shows that the algorithm has improved performance indicators such as rewards and the victory rate of both sides, improves the decision-making ability and convergence speed of the entire multi-agent system, and verifies the feasibility of the algorithm.
Key words:multi-agent reinforcement learning; hierarchical reinforcement learning; centralized training decentralized execution; value function decomposition; skill discovery
0 引言
隨著分布式人工智能的不斷發展,多智能體系統(multi-agent system,MAS)需要面對更加復雜的應用場景[1]。然而隨著智能體數量的不斷增加,智能體狀態空間呈指數級增長,導致智能體對環境的探索不足,無法學習魯棒的策略。同時,在MAS中,每個智能體獲得的獎勵都與團隊其他智能體的動作相關[2],導致智能體在做出動作后無法立刻得到獎勵,也無法使某個智能體的獎勵最大化,因此多智能體在協作完成任務時會受到很大的約束。為了適應更多數量的智能體以及更加復雜的任務環境的需要,分層強化學習(hierarchical reinforcement learning,HRL)為分布式人工智能計算提供了新的研究思路。
在多智能體分層強化學習領域中,Dietterich[3]提出了一種典型的分級控制模型方法MAXQ,該算法通過將總任務向下逐層分解為不同的子任務,進而遞歸求解各個子任務,可以有效地解決狀態維度空間過大的問題。為了提高智能體之間的合作效率,Ahilan等人[4]在Feudal[5]方法和FuNs[6]方法的基礎上對管理者和工作者進行預定義,工作者根據管理者制定的目標執行相應的動作。Kim等人[7]提出讓智能體在頂層學習教學或者是傳遞知識,對于獎勵評估較低的動作給出建議并進行更新,從而加速協同智能體的學習進程。Vezhnevets等人[8]將分層多智能體強化學習擴展到馬爾可夫博弈中,在頂層選擇對對手的戰略響應,在底層實現響應原始動作行為的策略。
在技能發現領域中,Shankar等人[9]提出一種共同學習機器人技能的框架,以及學習如何在無監督的情況下從演示中使用這些技能來學習任務的時間分解。DIAYN[10]方法和DADs[11]方法都是基于互信息的目標函數來動態學習技能,并且提出將學習到的技能用于學習HRL的底層策略中。RODE[12]方法提出通過將聯合動作空間分解為受限的角色動作空間的方法來實現可擴展的多智能體學習。
目前也有研究者借鑒集中訓練分散執行的思想來實現多智能體分層,例如Tang等人[13]提出要求每個智能體都獨立地學習自身的分層策略,并且每個智能體只能關心本地信息,將其他智能體視做環境的一部分進行訓練和學習;Yang等人[14]提出一種集中訓練分散執行的雙層框架來訓練和協調個人技能。
但隨著環境的復雜程度不斷增大,多智能體環境存在著各種各樣復雜且多變的問題[15,16]。本文提出一種基于加權值函數分解的多智能體分層強化學習的方法(multi-agent hierarchical reinforcement learning method based on weighted QMIX,H-WQMIX)。該算法主要通過采用分層強化學習的思想來解決多智能體強化學習(multi-agent reinforcement learning,MARL)中出現的維度災難和獎勵稀疏的問題。針對維度災難問題,本文算法采用頂層集中訓練策略,底層分散執行各自任務的框架;同時在頂層訓練智能體協同策略的時候引入加權值函數,使智能體可以更準確、快速地選擇最優策略;在底層執行動作過程中加入技能發現的思想,使智能體根據環境觀測信息來選擇合適的技能執行動作。
1 背景知識
1.1 集中訓練分散執行的算法框架
最早,Oliehoek等人[17]提出了集中訓練分散執行(centra-lized training decentralized execution,CTDE)框架的一些范例。目前該框架已經被廣泛用于多智能體強化學習中,其中以MADDPG算法中的集中式的critic網絡和分散式的actor網絡結構最為常用[18]。多智能體集中critic網絡和分散actor網絡的結構如圖1所示,其中actor使用策略函數,負責生成動作ait與環境進行交互;而critic獲取外部環境的狀態信息St以及外部獎勵rt,使用策略函數π(h1,ε)評估actor的表現,并指導actor下一階段的動作。一個集中的critic可以從所有以聯合行動為條件的可用狀態信息中學習,并且每個智能體從它自己的觀察行動歷史oit中學習它的策略。集中的critic只在學習過程中使用,而在執行過程中只需要分散的actor。
3 仿真設計與結果分析
3.1 實驗環境平臺搭建
實驗硬件環境采用Intel Xeon Silver 4210R CPU+Quadro RTX 6000+32 GB內存;軟件環境使用Ubuntu 20.04+TensorFlow+Torch+pygame。為了驗證本文算法的性能,采用文獻[24]中推出的簡易團隊運動模擬器(simple team sports simulator,STS2)以及文獻[25]中提出的星際爭霸Ⅱ微觀管理(StarCraft Ⅱ micromanagement,SMAC)兩個實驗場景。
3.2 簡易團隊運動模擬器
3.2.1 實驗設計
STS2通過有用的技能模擬類似于人類玩家的智能體和傳統游戲AI玩家的合作。在模擬器的最底層上,智能體的動作和移動應該與真正的人類玩家相似;在最高層次上,智能體應該學習如何遵循頂層的游戲計劃;在中等層次上,智能體應該學會展示技能和協調彼此的動作。本文所涉及的訓練是在一個中級的模擬器上進行的,該模擬器將游戲規則和物理元素植入一個高層次的層面,并將低層次的戰術抽象出來。模擬器支持任意正整數N的N對抗 N匹配。兩支球隊顯示為紅色(主場)和白色(客場),如圖6所示(紅色為在左側球場得分的本地智能體,白色為在右側球場得分的AI玩家,被黑色圈住的智能體為控球者(見電子版))。傳統游戲AI玩家由少量規則和約束組成,這些規則和約束控制著智能體的游戲策略。模擬器的狀態信息主要包含每個隊球員的坐標位置和速度等,離散動作集合包含前進、后退、左移、右移、傳球、射門、什么都不做。
在本文實驗設置中,主要設置在3v3的模式下進行訓練,訓練回合數為50 000次。兩隊雙方各設置三個球員(智能體),通過人類智能體玩家和傳統游戲AI玩家的合作進球來獲取更高的團隊獎勵。智能體需要觀測除自身之外的其他智能體的動作和相對位置信息以及球門的位置。每個智能體在訓練過程中學習不同的技能,球員通過阻斷對方進球或者搶奪控球權或者進球獲得獎勵。團隊合作運動場景參數設置如表1所示。其中,Home-players表示我方戰隊,Away-players表示對方戰隊;α用于決定內在獎勵和外部團隊獎勵數量的動態權重。首先設置α=αthreshold,其中αthreshold表示閾值,在訓練評估過程中如果勝率超過這個閾值,則α值將會降低αstep。在α值較高時,底層的策略進行自主學習要執行的動作,通過選擇有用的動作來最大化團隊獎勵。隨著α的不斷降低,底層策略跟頂層的技能相關聯,在技能不同的情況下通過調整自己的動作行為來獲得更多的內在獎勵。
在本文所設置的團隊運動場景中,球隊雙方的獎勵主要來自以下兩個方面:
a)球隊雙方是否進球的獎勵定義,如式(12)所示。
R1=+1? 球隊進球-1? 對方球隊進球(12)
b)雙方球隊從對方手中奪得控球權的獎勵定義,如式(13)所示。
R2=+0.1? 球隊奪得控球權-0.1? 對方球隊奪得控球權(13)
球員(agent)每個回合獲得的總獎勵定義為RA=R1+R2。
3.2.2 實驗結果與討論
在本文算法中,頂層網絡輸入的是一個具體的狀態。經過兩層隱藏層,第一層的單元數設置為128,第二層的單元數設置為256。通過增加第二層的單元數,算法可以較之前更收斂,通過頂層的前向網絡輸出維數為64的全局Q值;底層網絡的兩個隱藏層每層的單元數為64,最后輸出當前智能體的動作。
同時設置一個記憶緩沖池將技能zi和軌跡τ存儲到緩沖池中,每次再從緩沖池中選擇zi和τ來更新訓練。實驗的基本參數設置如表2所示。其中:buffer_size表示的是緩沖池大小;batch_size表示的是批尺寸;gamma表示的是折扣因子;tau表示網絡超參數;lr_Q表示的是頂層的網絡學習率;lr_actor表示的是底層actor網絡的學習率。
本文首先研究了改變頂層權重函數參數的影響,當滿足式(8)中的條件,權重函數的參數為ω。如圖7所示,隨著ω值的不斷增加,球隊的勝率越來越低,性能也越來越差。當設置ω=0.7時,球隊的勝率最低達到了10%以下。當ω值不斷減小時,勝率的波動區間較大,但最高勝率也未超過50%。所以由圖7可得,當設置參數為ω=0.5時,性能最好,方差相較之下最小,球隊的勝率較其他的參數設置勝率更高。
為了評估在團體合作運動中各智能體的學習效率,本文算法在STS2模擬器中與HSD、QMIX、IQL方法進行對比。通過50 000回合的迭代評估來訓練該算法模型,得到的算法平均獎勵和總獎勵結果如表3所示。
從表3中可以看出,在相同的參數設置和環境條件下,本文算法的平均獎勵比HSD方法高了0.072,比QMIX方法高了0.078,比IQL方法高了0.165。其中,雖然HSD采取了分層的結構訓練策略,但是HSD并沒有很好地估計全局Q值,導致其探索的速率稍慢。并且本文方法的方差與其他三個方法相比更低,收斂更穩定,性能更好。
同時,記錄了每100步的平均獎勵并繪制出與其他算法相比的平均獎勵曲線,如圖8所示。
根據圖8可以看出,對比于另外三種方法,本文方法在5 000回合之后出現較明顯的上升趨勢,并且在大約10 000回合的時候開始收斂,而另外三種方法在大約17 000回合的時候開始逐漸收斂,本文方法比另外三種方法收斂得更快,且平均獎勵在另外三種方法之上。盡管QMIX和IQL方法在多智能體的協作中可以達到很好的效果,但是在此環境的團隊運動合作中,分層比非分層的學習效果更好。與HSD方法相比,本文方法在HSD方法的基礎上增加權重函數,可以更加準確地計算智能體的Q值,從而獲得更高的獎勵。
另外,記錄了每100個回合中球員(agent)擊敗對手隊伍的勝率,針對不同算法的勝率曲線如圖9所示。
從圖9可以看出,盡管在訓練前期,本文方法波動較大,但是在大約20 000回合之后本文方法的勝率基本上都會略高于其他三個方法,勝率最高可以達到70%。在20 000回合之后,H-WQMIX訓練的智能體逐漸能夠根據自己的位置信息選擇更合適的技能來更好地協調多個智能體之間的合作,進而提高在每個回合中擊敗對手的勝率。
為了進一步驗證本文算法的實驗性能,分別在STS2模擬器的參數設置中設置不同的人類智能體玩家和傳統AI玩家的智能體數量進行實驗驗證。算法的勝敗次數對比如表4所示。
從表4可以看出,在本文設置的約100個測試集中,盡管本文算法在全人類玩家訓練時性能不及QMIX,但是當隊伍中有一個或者兩個隊友被腳本機器人取代時,H-WQMIX仍然可以表現得很好,這是由于H-WQMIX的底層策略開始是獨立訓練的,在勝率達到一定的閾值之后與頂層相結合一起選擇合適的技能來訓練。而QMIX和IQL方法表現越來越差,這可能是由于未當經過訓練的機器人加入隊伍時,會給原本依靠完全集中訓練的智能體制造很大的困難,導致其性能低下。
3.3 Linux星際爭霸Ⅱ平臺
3.3.1 實驗設計
為了進一步驗證本文算法的性能,選擇星際爭霸Ⅱ平臺作為其豐富環境和高復雜性環境的測試平臺。在星際爭霸Ⅱ的常規完整游戲中,一個或多個人類相互競爭或與內置游戲AI進行競爭,以收集資源、建造建筑、組建軍隊來擊敗對手。SMAC由一組星際爭霸Ⅱ微場景組成,旨在評估獨立智能體協調解決復雜任務的能力。每一個場景都是兩個軍隊單位之間的對抗。本文設置每個智能體特工的行動可以向東南西北四個主要方向移動、停止、什么也不做或者在每個時間步選擇一個敵人進行攻擊。
本文將所有地圖的縮放因子λe設置為10,并收集實驗樣本,利用式(9)所述的損失函數分別訓練200萬個和500萬個時間步長的預測模型,同時設置batch_size為32進行訓練。
3.3.2 實驗結果與討論
SMAC地圖分為簡單模式、困難模式以及超難模式三種。為了驗證本文算法在復雜環境中的性能,主要測試算法在困難地圖模式(2c_vs_64zg)和超難地圖模式(3s5z_vs_3s6z、corridor、MMM2)下的性能。
在困難地圖模式(2c_vs_64zg)下,如圖10所示。算法在執行200萬步的時候效果就已經十分明顯并且逐漸趨于平穩,且H-WQMIX算法始終優于其他算法。
在超難地圖模式(3s5z_vs_3s6z)下,算法在訓練后期才會出現較為明顯的訓練結果。如圖11所示,在地圖中,3名潛行者和5名狂熱者試圖擊敗3名敵方潛行者和6名敵方狂熱者。盡管前期沒有很快地學習到好的策略,但是在后期H-WQMIX算法勝率始終高于其他算法。
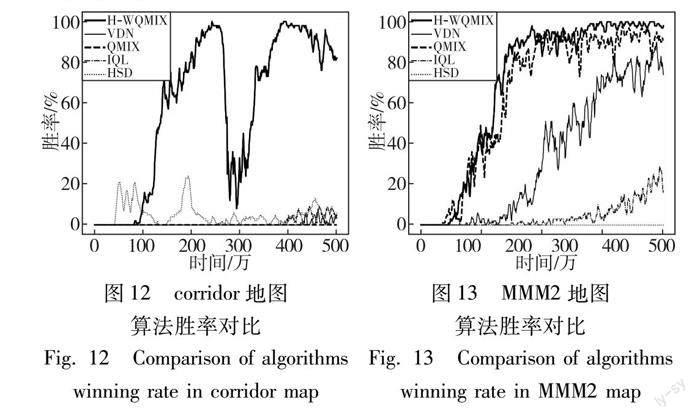
與3s5z_vs_3s6z 地圖不同的是,在超難地圖模式(corridor)中,6名狂熱者面對24名敵方蟲族,所有的攻擊動作都具有相似的效果,因為敵人都是同質的。如圖12所示,算法在訓練的前期效果并不是很理想,盡管在訓練后期沒有達到收斂的效果,但本文算法的勝率仍然遠遠高于其他算法。
在超難地圖模式(MMM2)中,雙方軍隊由1個醫療救護隊,2個掠奪者和7個陸戰隊員對戰1個醫療救護隊,3個掠奪者和8個陸戰隊員,只有當醫療救護隊出現之后,對抗才開始具備戰斗力。
如圖13所示,H-WQMIX算法雖然相較于QMIX方法并沒有十分明顯的優勢,但是較于其他幾個算法仍然具有很大的優勢。
同時,根據以上數據可以得出,H-WQMIX算法在困難地圖模式中的勝率比其他算法平均提高了約18%;在超難地圖模式中的勝率比其他算法平均提升了約23%。盡管在MMM2地圖中與QMIX方法性能相差不大,但是從收斂效果看,本文算法仍然優于其他幾個算法,并且與HSD方法相比具有更好的遷移性。總的來說,本文方法在SMAC場景中仍然可以保持較好的性能。
4 結束語
本文提出了一種基于加權值函數分解的多智能體分層強化學習方法來發現在團隊活動中有用的技能。本文通過集中訓練分散執行的框架分別訓練算法的頂層策略和底層策略,并通過內外獎勵結合機制來解決智能體之間的獎勵稀疏以及信度分配的問題。通過對值函數進行加權來提高智能體動作的有效性,更加準確地評估智能體的行為動作,從而獲得更高的獎勵,加快了智能體的學習和探索效率。分別在STS2模擬器和星際爭霸Ⅱ平臺上驗證了本文算法的性能和有效性,從實驗結果可以看出,本文算法在較為簡單和稍加復雜的場景中仍然可以保持較好的訓練性能,獲得更高的勝率。實驗結果表明,該算法在不同的操作系統以及實驗平臺上都表現出了較好的性能,具有十分重要的應用價值,為后期將其應用在實際開發環境中奠定了十分重要的基礎。近些年來,DeepMind、OpenAI等人工智能實驗室以及國外著名大學研究實驗室,清華大學智能技術與系統國家重點實驗室以及華為諾亞方舟實驗室等多個國內外實驗室針對多智能體強化學習和分層強化學習的多項研究成果在星際爭霸Ⅱ以及團隊運動游戲實驗平臺上都展現了很好的效果,并將其應用在解決智能決策、資源智能化調配、交通控制等民用領域中,同時也應用在可以解決異構的多智能體各類戰略協同的軍事領域中。
在未來,將進一步研究子任務分配的問題,以簡化和加快智能體的訓練步驟。同時可以引入課程學習和策略遷移的思想,將分層強化學習擴展到解決更多更復雜大型的多智能體任務中。
參考文獻:
[1]殷昌盛,楊若鵬,朱巍,等. 多智能體分層強化學習綜述 [J]. 智能系統學報,2020,15(4): 646-655. (Yin Changsheng,Yang Ruopeng,Zhu Wei,et al. A survey on multi-agent hierarchical reinforcement learning [J]. CAAI Trans on Intelligent Systems,2020,15(4): 646-655.)
[2]Gronauer S,Diepold K. Multi-agent deep reinforcement learning: a survey [J]. Artificial Intelligence Review,2022,55(2): 895-943.
[3]Dietterich T G. Hierarchical reinforcement learning with the MAXQ value function decomposition [J]. Journal of Artificial Intelligence Research,2000,13(1): 227-303.
[4]Ahilan S,Dayan P. Feudal multi-agent hierarchies for cooperative reinforcement learning [C]// Proc of the 4th Multidisciplinary Confe-rence on Reinforcement Learning and Decision Making. Cambridge,MA: JMLR Press,2019: 57.
[5]Dayan P,Hinton G E. Feudal reinforcement learning [J]. Advances in Neural Information Processing Systems,1992,5: 271-278.
[6]Vezhnevets A S,Osindero S,Schaul T,et al. Feudal networks for hie-rarchical reinforcement learning [C]// Proc of the 34th International Conference on Machine Learning. Edmore,MI: JMLR Press,2017: 3540-3549.
[7]Kim D K,Liu Miao,Omidshafiei S,et al. Learning hierarchical tea-ching in cooperative multiagent reinforcement learning [EB/OL]. (2019) [2022-11-15]. https://arxiv. org/pdf/1903. 03216v2. pdf.
[8]Vezhnevets A,Wu Yuhuai,Eckstein M,et al. Options as responses: grounding behavioural hierarchies in multi-agent reinforcement lear-ning [C]// Proc of the 37th International Conference on Machine Learning. Edmore,MI: JMLR Press,2020: 9733-9742.
[9]Shankar T,Gupta A. Learning robot skills with temporal variational inference [C]// Proc of the 37th International Conference on Machine Learning. Edmore,MI: JMLR Press,2020: 8624-8633.
[10]Eysenbach B,Gupta A,Ibarz J,et al. Diversity is all you need: lear-ning skills without a reward function [C]// Proc of the 6th Internatio-nal Conference on Learning Representations. Edmore,MI: JMLR Press,2018: 1-22.
[11]Sharma A,Gu S,Levine S,et al. Dynamics-aware unsupervised discovery of skills [C]// Proc of the 7th International Conference on Learning Representations. Berkeley,CA: PMLR Press,2019: 1-21.
[12]Wang Tonghan,Gupta T,Mahajan A,et al. RODE: learning roles to decompose multi-agent tasks [EB/OL]. (2020) [2022-11-20]. https://arxiv. org/pdf/2010. 01523. pdf.
[13]Tang Hongyao,Hao Jianye,Lyu Tangjie,et al. Hierarchical deep multiagent reinforcement learning with temporal abstraction [EB/OL]. (2018) [2022-12-01]. https://arxiv. org/pdf/1809. 09332. pdf.
[14]Yang Jiachen,Borovikov I,Zha Hongyuan. Hierarchical cooperative multi-agent reinforcement learning with skill discovery [C]// Proc of the 19th International Conference on Autonomous Agents and Multi-agent Systems.2020: 1566-1574.
[15]曹潔,邵紫旋,侯亮. 基于分層強化學習的自動駕駛車輛掉頭問題研究 [J]. 計算機應用研究,2022,39(10): 3008-3012,3045. (Cao Jie,Shao Zixuan,Hou Liang. Research on autonomous vehicle U-turn problem based on hierarchical reinforcement learning [J]. Application Research of Computers,2022,39(10): 3008-3012,3045.)
[16]Zhang Kaiqing,Yang ZhuoranT. Multi-agent reinforcement learning: a selective overview of theories and algorithms [J]. Stu-dies in Systems,Decision and Control,2021,325: 321-384.
[17]Oliehoek F A,Spaan M T J,Vlassis N. Optimal and approximate Q-value functions for decentralized POMDPs [J]. Journal of Artificial Intelligence Research,2008,32(1): 289-353.
[18]Lowe R,Wu Y,Tamar A,et al. Multi-agent actor-critic for mixed cooperative-competitive environments [C]// Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY: Curran Associates Inc.,2017: 6382-6393.
[19]Tan Ming. Multi-agent reinforcement learning: independent vs. coo-perative agents [C]// Proc of the 10th International Conference on Machine Learning. San Francisco,CA: Morgan Kaufmann Publi-shers,1993: 330-337.
[20]Sunehag P,Lever G,Gruslys A,et al. Value-decomposition networks for cooperative multi-agent learning based on team reward [C]// Proc of the 17th International Conference on Autonomous Agents and Multiagent Systems. 2018: 2085-2087.
[21]Rashid T,Samvelyan M,Schroeder C,et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning [C]// Proc of the 35th International Conference on Machine Lear-ning.2018: 4295-4304.
[22]Rashid T,Farquhar G,Peng Bei,et al. Weighted QMIX: expanding monotonic value function factorisation for deep multi-agent reinforcement learning [J]. Advances in Neural Information Processing Systems,2020,33: 10199-10210.
[23]Ding Fan,Zhu Fei. HLifeRL: a hierarchical lifelong reinforcement learning framework [J]. Journal of King Saud University-Computer and Information Sciences,2022,34(7): 4312-4321.
[24]Zhao Yunqi,Borovikov I,Rupert J,et al.On multi-agent learning in team sports games[EB/OL].(2019)[2023-02-19].https://arxiv.53yu.com/pdf/1906.10124.pdf.
[25]Samvelyan M,Rashid T,De Witt C S,et al. The StarCraft multi-agent challenge [C]// Proc of the 18th International Conference on Auto-nomous Agents and Multiagent Systems. Rech Land,SC: IFAAMAS.org,2019: 2186-2188.
收稿日期:2022-12-10;修回日期:2023-02-22? 基金項目:國家自然科學基金資助項目(61673084);2021年遼寧省教育廳項目(LJKZ1180)
作者簡介:鄒啟杰(1978-),女,山東黃縣人,副教授,碩導,博士,主要研究方向為智能駕駛、計算機視覺、智能規劃與決策;李文雪(1997-),女(通信作者),山東臨沂人,碩士,主要研究方向為多智能體深度強化學習、分層強化學習(li_wenx@163.com);高兵(1976-),男,遼寧鐵嶺人,副教授,碩導,博士,主要研究方向為大數據分析、知識圖譜;趙錫玲(1999-),女,山東濟南人,碩士研究生,主要研究方向為分層強化學習;張汝波(1963-),男,吉林人,教授,院長,主要研究方向為強化學習、智能規劃
.
