融合代碼靜態特征和頻譜的軟件缺陷定位技術
2023-10-18 08:11:14王浩仁岳雷李靜雯崔展齊
計算機應用研究 2023年9期
王浩仁 岳雷 李靜雯 崔展齊

摘 要:基于頻譜的缺陷定位(spectrum-based fault localization,SBFL)通過分析測試用例的覆蓋信息和執行結果信息進行快速定位,是目前最常用的缺陷定位技術。然而,該方法未能充分利用代碼中隱含的語義和結構信息。若能將缺陷預測中使用到的代碼結構信息和頻譜信息融合使用,將有助于進一步提升缺陷定位的效果。為此,提出了一種融合代碼靜態特征和頻譜的軟件缺陷定位(fault localization combing static features and spectrums,FLFS)技術。首先,從Halstead等度量元集合中選取度量元指標并進行修改,以適用于度量代碼的方法級特征;然后,根據選取的度量元指標提取程序中各個方法的靜態特征并用于訓練缺陷預測模型;最后,使用缺陷預測模型預測程序中各方法存在缺陷的預測可疑度,并與SBFL技術計算的頻譜可疑度進行融合,以定位缺陷所在方法。為驗證FLFS的有效性,將其與兩種定位效果最好的SBFL技術DStar和Ochiai在Defects4J數據集上進行了對比實驗。結果表明,FLFS具有更好的缺陷定位性能,對于Einspect@n指標,當n=1時,FLFS相比DStar和Ochiai分別多定位到16和10個缺陷;對于MRR指標,FLFS相比DStar和Ochiai分別提升了4.13%和1.08%。
關鍵詞:缺陷定位;缺陷預測;程序頻譜;代碼結構信息;可疑度
中圖分類號:TP311.5?? 文獻標志碼:A
文章編號:1001-3695(2023)09-035-2785-07
doi:10.19734/j.issn.1001-3695.2023.02.0054
Fault localization combing static features and spectrums
Wang Haoren,Yue Lei,Li Jingwen,Cui Zhanqi
(School of Computer Science,Beijing Information Science & Technology University,Beijing 100101,China)
Abstract:SBFL is the most commonly used fault localization technique,which performs fast localization by analyzing the coverage and execution result information of test cases.However,SBFL fails to fully utilize the implicit semantic and structural information of the code.If the code structure information used in fault prediction and the spectrum information can be fused,it will further improve the effectiveness of fault localization.To this end,this paper proposed a software FLFS method.Firstly,it selected feature from the metrics,including Halstead,CK,etc,and adapted them to measure the method-level features of the code.Then,it extracted the static features of each method in the program according to the metrics and used them to train the fault prediction model.Finally,it used the fault prediction model to predict the prediction suspiciousness of each method in the program and fused it with the spectrum suspiciousness calculated by SBFL to locate the faulty method.To verify the effectiveness of FLFS,this paper compared it with two most effective SBFL techniques,DStar and Ochiai,on the Defects4J dataset.The results show that FLFS outperforms SBFL in terms of Einspect@n,and MRR.For Einspect@n,when n=1,FLFS locates 16 and 10 more faults than DStar and Ochiai respectively.For MRR,FLFS improves by 4.13% and 1.08% compared to DStar and Ochiai respectively.
Key words:fault localization;fault prediction;program spectrum;code structure information;suspiciousness
0 引言
軟件缺陷定位通過定位程序中的缺陷所在位置為調試提供關鍵信息,從而提高軟件調試和修復的效率,是一種重要的軟件質量保障技術。基于頻譜的缺陷定位(SBFL)是目前應用為最為廣泛的缺陷定位技術[1],該類技術通過分析測試用例的覆蓋信息和執行結果信息計算出每個程序元素的可疑度值,可疑度值的大小與程序元素包含缺陷的可能性相關[1,2]。開發人員可以根據元素的可疑度值排名進行檢查,達到快速定位、提高缺陷定位效率的目的。SBFL技術常被應用于定位缺陷語句,然而程序員在確認缺陷位置時仍然需要結合缺陷語句的上下文及代碼結構才能修復缺陷。因此,與語句級缺陷定位相比,方法級的缺陷定位更有利于程序員理解和修復代碼,且方法級缺陷定位相比語句級缺陷定位具有更高的精度[3]。然而,DStar[4]作為定位效果最好的SBFL技術之一,其定位精度仍然有待提高,例如在對Defects4J[5]數據集進行缺陷定位時,檢查可疑度排名第一的方法也僅能定位到30.6%的缺陷。
而定位精度有限的原因之一是缺陷定位過程中通常僅使用了測試用例的覆蓋信息和執行結果,未能充分利用代碼中隱含的語義和結構信息。現有一些工作嘗試將更多的信息與程序頻譜進行結合,以提升軟件缺陷定位的性能。例如,姜淑娟等人[6]提出了一種基于路徑分析和信息熵的缺陷定位方法,通過對程序中所有執行路徑的數據依賴關系進行分析得到程序執行路徑的上下文信息,并利用信息熵理論將測試事件信息引入可疑度公式來提高缺陷定位的性能。Wen等人[7]提出了一種基于歷史譜的缺陷定位技術,該技術先從版本歷史記錄中識別導致缺陷的提交,用于構建歷史譜,并通過結合歷史譜和常規頻譜進行缺陷語句定位。Saha等人[8]考慮到代碼結構特征,利用代碼類名、方法名、注釋等信息與缺陷報告組合,通過分別計算每個組合的文本相似度得分將所有組合得分加權求和作為文件的最終得分進行缺陷定位。因此,若能夠合理利用代碼中隱含的語義和結構信息將有助于提升缺陷定位性能。
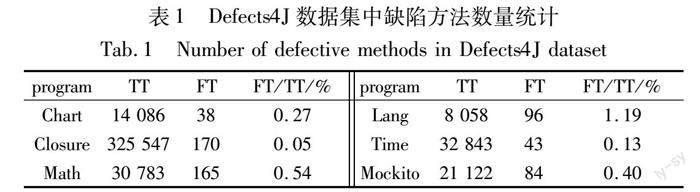
軟件缺陷預測根據代碼的語義和結構信息,借助隨機森林[9]、深度神經網絡[10]等機器學習方法對程序代碼中存在缺陷的傾向性和數量等進行預測。缺陷預測重點關注程序內部模塊級的缺陷情況,因此當其被用來預測更細粒度的方法級代碼時,預測精度往往會大幅降低,難以準確定位缺陷位置。例如,方法級缺陷預測技術IVDetect[11]在實際應用中的F1值均低于0.3,precision值也均低于0.25。若能將缺陷預測中使用到的代碼結構信息和SBFL的頻譜信息融合使用,將有助于提升缺陷定位的效果。在真實的應用場景中,包含缺陷的方法數量在方法總數中占比極少,存在嚴重的類不平衡問題,若直接用于訓練缺陷預測模型,將對缺陷預測模型的性能造成嚴重威脅。例如,在Defects4J的395個程序中,包含缺陷的方法只占所有方法的很小部分。如表1所示,TT(total test cases)和FT(failing test cases)列出了Defects4J各項目中所有方法的數量和包含缺陷的方法數量;FT/TT列表示缺陷方法數與所有方法數的比率;FT/TT列的值表明各項目中含有缺陷的方法僅占全部方法的0.05%~1.19%。嚴重的類不平衡問題將會降低缺陷預測模型的質量,影響軟件缺陷預測的性能。
為此,本文提出了一種融合代碼靜態特征和頻譜的軟件缺陷定位技術,稱做FLFS。首先,從Halstead、CK等度量元集合中選取度量元指標并進行修改,以適用于度量程序的方法級特征;然后根據度量元指標提取程序中各個方法的靜態特征,對方法靜態特征數據集中不存在缺陷的方法進行聚類,從不同類簇中選取代表性的方法,用于訓練缺陷預測模型以緩解類不平衡問題;最后,使用缺陷預測模型預測程序中各方法存在缺陷的預測可疑度,并與SBFL技術計算各方法的頻譜可疑度進行融合以定位缺陷所在方法。基于Defects4J數據集,將FLFS與現有缺陷定位效果最好的SBFL技術DStar和Ochiai[12]進行對比實驗。結果表明,對于Einspect@n指標,當n=1時,FLFS相比DStar和Ochiai分別多定位到16和10個缺陷;對于MRR指標,FLFS相比DStar和Ochiai分別提升了4.13%和1.08%。
本文提出一種融合代碼靜態特征和頻譜信息的軟件缺陷定位技術,提取代碼結構特征訓練缺陷預測模型,并將基于模型預測的各方法中存在缺陷的預測可疑度與基于頻譜計算的頻譜可疑度融合,以進行方法級的缺陷定位。
1 相關工作
1.1 基于頻譜的缺陷定位
國內外研究人員針對軟件缺陷定位進行了大量研究,常用技術包括基于頻譜的缺陷定位技術[1]、基于信息檢索的缺陷定位技術[13]等,本文重點關注基于頻譜的缺陷定位技術。
研究人員已經提出了很多基于頻譜的缺陷定位技術,其中,Jone等人[14]最先提出Tarantula,使用覆蓋率和測試用例執行結果來度量語句的可疑度值。隨后,通過改進可疑度公式,研究者相繼提出了一些效果更佳的SBFL技術。Abreu等人[12]受聚類分析中相似度系數的啟發提出了Ochiai,提高了軟件缺陷定位性能;Wong等人[4]通過進一步分析測試用例在程序實體上成功執行的數量對缺陷定位結果的影響,得出了被成功測試用例覆蓋次數越多的程序實體其覆蓋次數對可疑值的貢獻度越小這一結論。隨后為了突出在成功用例數量較多時失敗用例對定位結果的影響,又提出了DStar,并且通過實驗對比發現DStar的缺陷定位效果優于其他同類缺陷定位技術。此外,Xie等人[15]提出了一種基于蛻變切片(metamorphic slice,MS)SBFL技術,通過蛻變測試和程序切片生成MS,并使用蛻變關系(metamorphic relation)生成更多測試用例以用于缺陷定位,此方法的特點在于無須測試用例的測試預言(test oracle),并取得了與現有SBFL相近的性能。
除僅使用程序頻譜信息進行缺陷定位外,還有研究嘗試通過引入代碼中隱含的其他信息來提升缺陷定位的性能。Saha等人[8]考慮到代碼結構特征,將缺陷報告分為標題和描述兩個部分,將代碼分為類名、方法名、注釋等,并與缺陷報告組合,通過分別計算每個組合的文本相似度得分,將所有組合得分加權相加作為文件的最終得分。因此,合理利用代碼的結構信息可以提升缺陷定位的準確性。本文提出技術也將代碼結構信息加入到缺陷定位中以提高定位效果。不同于上述SBFL僅使用語句覆蓋信息進行缺陷定位,本文提出技術通過將缺陷預測中使用到的代碼結構信息和SBFL的頻譜信息融合,以緩解SBFL使用代碼信息較少、定位精度有限的問題。
1.2 軟件缺陷預測
靜態軟件缺陷預測可以將程序模塊的缺陷傾向性、缺陷數量作為預測目標[16]。本文將重點關注軟件缺陷預測中預測代碼缺陷傾向性的技術。該技術首先分析軟件程序代碼,從中抽取出程序元素,并根據實際應用場景,元素的粒度可分別為文件、類或函數等;然后提取出程序元素的各類度量元特征,并將是否包含缺陷作為程序元素的標簽,以構建缺陷預測數據集;最后,對缺陷預測數據集進行必要的數據預處理后使用分類和回歸等機器學習方法構建缺陷預測模型。已有研究嘗試使用不同機器學習方法構建缺陷預測模型的性能進行比較。例如,Elish等人[17]基于NASA數據集,將支持向量機與樸素貝葉斯、隨機森林等其他八種機器學習方法構建的缺陷預測模型進行了系統比較,實驗結果表明,SVM在總體評價上要優于其他八種方法構建的缺陷預測模型。
還有研究人員通過研究對缺陷預測模型性能的影響條件,以判斷機器學習方法應用于缺陷預測時的性能差異。例如。Catal等人[18]基于NASA數據集,以AUC值為評價指標,深入分析了數據集規模、度量元和特征子集選擇方法對缺陷預測模型性能的影響,結果表明隨機森林法在大規模數據集上性能最優,而樸素貝葉斯則在小規模數據集上的性能最優。除此之外,已有研究提出了多種基于深度神經網絡的方法來進行缺陷預測。例如,Russell等人[19]提出了一種基于RNN的架構來自動提取源代碼的特征以進行缺陷預測;Dam等人[20]提出了一種基于LSTM的架構來自動學習源代碼的語義和句法特征。
不同于上述缺陷預測技術主要在文件級或類級對代碼中存在缺陷的傾向性進行預測。本文提出的FLFS通過將缺陷預測中使用到的代碼結構信息和頻譜信息融合,以更充分地利用代碼結構信息取得更好的軟件缺陷定位效果。
2 FLFS方法設計
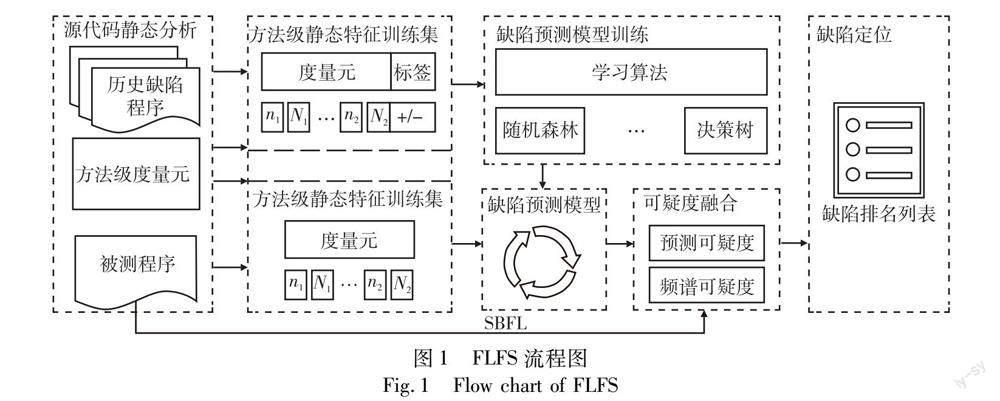
現有基于頻譜的缺陷定位技術中的突出問題之一是未充分利用代碼結構信息,導致定位精度受限,人工檢查和調試開銷較高。為此,本文提出了一種融合代碼靜態特征和頻譜的軟件缺陷定位技術,其流程如圖1所示。
2.1 方法級靜態特征
分析軟件歷史倉庫、設置與軟件缺陷存在強相關性的度量元是構建高質量缺陷預測模型的關鍵。因此,度量元的設計一直是軟件缺陷預測研究中的一個核心問題[16]。本文從現有的研究中選取適用的方法級度量元指標,這些度量元信息將用于訓練方法級缺陷預測模型,進而為缺陷定位提供指導。缺陷預測領域經常使用的靜態特征有Halstead度量元[21]、CK(Chidamber Kemerer)度量元[22]、Martin度量元[23]和McCabe圈復雜度(cyclomatic complexity)[24]等。其中,Halstead度量元主要通過統計程序內操作符和操作數的數量來度量代碼的閱讀難度,并假設代碼的閱讀難度越高,代碼含有缺陷的可能性也越高;CK度量元和Martin度量元集合則是為面向對象程序設計的,通常代碼中類的復雜度越高,存在缺陷的概率也越高;McCabe圈復雜度關注的是程序的控制流復雜度,該度量元假設程序的控制流復雜度越高,則其含有缺陷的可能性也越高。參考上述度量元集,通過去除Halstead、CK、Martin和McCabe度量元中部分不適用的度量元、合并具有相同含義的度量元,并將其中模塊級、類級的度量元進行修改,以適用于方法級,構建了一套適用于度量方法級代碼特征的度量指標集合,包括注釋代碼行數、代碼行數、方法調用數量、圈復雜度等,如表2所示,共包含21種度量元。其中,從Halstead度量元中選擇了12種,包括方法中分支的個數、操作符種類數等;從CK度量元中選擇了4種,包括方法被其他方法調用次數、方法調用其他方法的次數等;從Martin度量元中選擇了3種,如方法中參數的個數等;從McCabe度量元中選擇了2種,為圈復雜度和代碼行數。被選取的21種度量元中有14種是將原用于模塊級或類級的度量元應用于方法級,另外7種則需要進行適當修改以適用于度量方法級特征。
各個度量元的具體含義為:a)n1,該度量元用來統計方法中的操作符種類數,操作符包括關鍵字、函數調用、運算符,該特征的具體數值為關鍵字、函數調用和運算符種類的和;b)N1,該度量元用來統計方法中的操作符種個數,具體數值為關鍵字、函數調用和運算符個數的和;c)n2,該度量元用來統計方法中的操作數的種類,操作數包括常數、常量、變量,其中變量的類型有整數型的byte、short、int、long,浮點類型的float和double等;d)N2,該度量元用來統計方法中的操作數的個數,具體為方法中常數、常量和變量個數的和;e)N,該度量元在Halstead度量元中表示程序長度,應用到方法級中為每個方法所有操作符和操作數的和,即N=N1+N2;f)n,該度量元表示每個方法中所有操作符種類和操作數種類的和,即n=n1+n2;g)BranchCount,該度量元用來統計方法中所有分支的個數;h)Volume,該度量元參考Halstead度量元中體積的計算公式Volume=N log2n,表示方法的規模;i)Difficulty,該度量元表示復雜度,使用公式Difficulty=(n1/2)×(N2/n2)計算方法的復雜度;j)Level,該度量元表示可理解程度,使用公式Level=(2/n1)×(n2/N2)計算方法的可理解程度;k)Effort,該度量元表示工作量,使用公式Effort=Volume×Difficulty計算方法的工作量;l)Time,該度量元表示開發方法所需耗費的時間,參考Halstead度量元,使用公式Time=Effort/18來計算;m)FunIn,該度量元表示方法被其他方法調用的次數;n)FunOut,該度量元表示方法調用其他方法的次數;o)CBO,該度量元表示方法之間的耦合關系,具體公式為CBO=FunIn+FunOut,即該方法被調用和調用其他方法次數的和;p)Length,該度量元表示方法名的長度;q)LongParameter,該度量元參考Martin度量元,表示過長參數列表,即一個方法需要傳遞太多的參數時更有可能包含缺陷,將其修改為方法的參數個數;r)SwitchCount,該度量元表示方法中switch語句的個數;s)Comments,該度量元記錄方法中注釋的行數,程序語言中通常有單行注釋、多行注釋和文檔注釋三種注釋,本文將方法包含注釋行數的和作為該度量元的值;t)CycComplexity,該度量元表示方法的圈復雜度,圈復雜度用來衡量一個模塊判定結構的復雜程度,數量上表現為線性無關的路徑條數,即所需測試的最少路徑條數;u)LOC,該度量元表示方法中包含語句(非空行)的數量。
2.2 融合代碼靜態特征和頻譜的軟件缺陷定位技術
首先,使用所提取的代碼靜態特征(如行數、方法調用次數等)組成方法級靜態特征數據集,并通過對方法級靜態特征數據集中不包含缺陷的方法進行聚類,從不同類簇中選取代表性的方法,與包含缺陷的方法靜態特征組合,以訓練缺陷預測模型;然后使用SBFL計算方法中所有語句的可疑度值,將方法中所有語句可疑度的最大值作為方法的頻譜可疑度,并與模型預測每個方法存在缺陷的預測可疑度進行融合,通過增加分析程序的靜態特征信息以進一步提升SBFL的缺陷定位性能。在融合預測可疑度和頻譜可疑度時,借鑒文獻[25]中將詞頻和逆文本頻率指數進行數值相乘得到詞頻—逆文件頻率的方式,通過將預測可疑度與頻譜可疑度相乘得到方法融合可疑度。
M(i)=spectrum(i)×prediction(i)(1)
其中:spectrum(i)表示第i個方法的頻譜可疑度值;而prediction(i)表示模型對第i個方法預測的預測可疑度值,即該方法預測為缺陷的概率;M(i)表示第i個方法通過將預測可疑度與頻譜可疑度相乘得到的融合可疑度值。
2.3 類不平衡問題處理
在分類學習任務中常會遇到類不平衡問題,即數據集中不同類樣本的數據量差距較為懸殊[26],使用類不平衡的數據集訓練所得的模型,往往對少數類數據的預測精度較低。對于類不平衡的數據集,可通過對負類樣本進行過采樣和對正類樣本進行欠采樣來改善數據分布,使數據集趨向類平衡。但需要注意的是隨機過采樣方法容易導致過度擬合問題,而隨機欠采樣方法常常會引起信息丟失。為了彌補隨機欠采樣過程中可能丟失有用信息樣本的缺點,對方法靜態特征數據集中的數據使用基于聚類的欠采樣方法[27]進行處理。聚類是一種無監督學習方法,按照劃分思想以簇內相似、簇間相異原則通過迭代將數據劃分到不同的簇中,并使生成的簇盡可能地緊湊和獨立。通常,聚類算法常被用于數據壓縮和信息檢索,可通過聚類達到降低數據維度來完成數據劃分等目的[27]。
在構建方法靜態特征數據集的過程中,發現數據集存在非常嚴重的類不平衡現象。在Defects4J的395個程序中,包含缺陷的方法只占所有方法的很小部分,各項目中含有缺陷的方法僅占全部方法的0.05%~1.19%,即包含缺陷的方法極少而不存在缺陷的正確的方法占絕大多數。為緩解此問題,將去除方法靜態特征數據集中重復的方法,并對不存在缺陷的方法進行聚類,再通過從不同類簇中選取代表性方法以達到減少重復數據、緩解類不平衡問題的目的,經過處理后將得到類分布更平衡的數據集,并用于訓練缺陷預測模型。
2.4 實例分析
本節使用Defects4J中Chart項目的第14個版本作為示例,以介紹FLFS的實際使用過程。a)通過使用DStar計算程序中的所有方法的頻譜可疑度,表3中,Spectrum表示方法的頻譜可疑度值,Spectrum-Rank表示方法的頻譜可疑度排名,可以看出含有缺陷的方法removeRangeMarker按照頻譜可疑度值被排為第四;b)使用缺陷預測模型預測程序中各方法的預測可疑度,表3中Prediction列表示缺陷預測模型預測方法為缺陷的預測可疑度值;c)使用式(1)將SBFL技術計算的各方法的頻譜可疑度與預測可疑度進行融合以定位缺陷所在方法。定位結果如表3所示,其中,FLFS列表示方法的融合可疑度值,FLFS-Rank表示方法的融合可疑度值排名;Faulty表示該方法是否存在缺陷,1為含有缺陷的方法,0為無缺陷方法。可以看出,通過FLFS進行缺陷定位,能夠將包含缺陷的方法removeRangeMarker排到第一。
由上述示例可以看出,SBFL僅使用頻譜信息計算可疑度,將覆蓋更多錯誤測試用例的方法賦以更高的頻譜可疑度,但未能充分利用代碼中隱含的語義和結構信息,導致缺陷方法的可疑度值低,定位效果較差。而在SBFL中加入缺陷預測的結果后,通過增加靜態特征信息,如方法的圈復雜度、參數個數等信息來提高缺陷定位的效果。含有缺陷的方法removeRangeMarker因其規模、圈復雜度等特征相比其他方法更高,將得到較高的預測可疑度值,進而導致融合可疑度值排名更高,所以比SBFL的定位效果更好。
3 實驗與結果
為了檢驗FLFS的有效性,將在Defects4J(V1.4.0)數據集上進行實驗。在實現FLFS過程中,使用了第三方機器學習庫Scikit-learn(https://scikit-learn.org/stable/)中的K-means算法和RF模型對方法靜態特征數據集進行聚類和缺陷預測。具體來講,首先匯總數據集中不包含缺陷方法的靜態特征信息,使用K-means算法對這些方法的靜態特征信息進行聚類,其中,在聚類算法中設置的類簇數量為當前訓練數據集中正樣本的數量,以保持包含缺陷的方法和不包含缺陷的方法數量相同,而最大迭代次數等其他參數則保持默認參數;然后,從聚類的不同類簇中各隨機選取一條方法的靜態特征數據作為代表性數據,與包含缺陷的正樣本數據組合為訓練集,以緩解類不平衡問題;基于RF訓練缺陷預測模型,以預測程序中各方法存在缺陷的預測可疑度,并與SBFL技術計算出的各方法的頻譜可疑度進行融合。由于缺陷預測模型的直接輸出僅為方法是否包含缺陷,為了更充分地利用缺陷預測模型的結果,使用Scikit-learn中的predict_proba方法來得到語句的估計概率(estimated probabilities),作為預測可疑度,與頻譜可疑度結合以提高缺陷定位的準確性。
實驗運行硬件環境為Intel Xeon E5-2678 v3 @ 2.50 GHz、64 GB物理內存;軟件環境為Windows 10、JDK 1.8.0、Python 3.7.0。
3.1 實驗設計
3.1.1 研究問題
a)為了評估FLFS的缺陷定位性能,本文將其與SBFL中定位效果最好的技術DStar和Ochiai進行對比,以分析本文所提技術的有效性。
b)通過對比使用聚類算法對數據預處理后和不使用聚類方法預處理的方法靜態特征數據集訓練模型的性能來驗證解決方法級靜態特征數據集中的類不平衡問題是否會提高FLFS的缺陷定位效果。
3.1.2 數據集
表4給出了Defects4J數據集的相關統計信息,包括來自6個開源項目的395個含有缺陷的版本,Chart(26個缺陷版本)、Closure(133個缺陷版本)、Lang(65個缺陷版本)、Math(106個缺陷版本)、Mockito(38個缺陷版本)和Time(27個缺陷版本)。在表4中,第二列是各項目存在缺陷的版本數量,每個缺陷版本包含至少一個缺陷;第三列是每個項目的平均代碼行數。第四列是每個項目的平均測試用例數量。
實驗中基于Eclipse的JDT庫和所編寫的語法分析器,根據2.1節設計的度量元指標,提取Defects4J數據集中6個項目的方法靜態特征以構建方法靜態特征數據集并進行實驗。其中,訓練集和測試集的劃分方式為輪流選取一個項目作為測試集,剩余五個項目數據則作為訓練集。
3.1.3 評價指標
為評價FLFS的有效性,本文采用Einspect@n和MRR(mean reciprocal rank)兩個被廣泛使用的評價指標。
Einspect@n是指可疑度值排在前n的方法中存在缺陷的數量,n越小且Einspect@n的值越大,缺陷定位技術的性能就越好。與語句級缺陷定位的評估過程類似,本文通過統計可疑度值排在前n的方法中存在的缺陷數量對不同技術進行評估。
MRR也是一種對缺陷定位技術進行評估的通用評價指標,通過查找可疑列表中第一個包含缺陷的方法,并計算其排名的倒數值來評估缺陷定位技術的性能,MRR值越高,說明定位技術的準確率越高。MRR計算公式如式(2)所示。其中R為該程序所有含有缺陷方法的集合,|R|表示集合中缺陷方法的數目,ranki表示定位出的與第i個缺陷方法最靠前排名[28]。
MRR=1|R|∑Ri=11ranki(2)
3.2 實驗結果分析
表5為DStar、Ochiai、FLFSDStar和FLFSOchiai對Defects4J數據集進行缺陷定位的效果對比,其中FLFSDStar表示將缺陷預測模型預測的預測可疑度與DStar計算的頻譜可疑度值進行融合,FLFSOchiai表示與Ochiai計算的頻譜可疑度值進行融合。實驗使用的評價指標為Einspect@n(n=1,3,5)和MRR。
對于Einspect@n,當n=1、3、5時,FLFS均取得了更好的定位效果,相比DStar、Ochiai分別能夠多定位到5~16個缺陷,且當n=1時,FLFS能夠表現出更有效的缺陷定位性能。具體地,當n=1時,FLFSDStar、FLFSOchiai相比DStar、Ochiai分別能夠多定位16和10個缺陷;當n=3時,FLFSDStar、FLFSOchiai相比DStar、Ochiai分別能夠多定位到12和8個缺陷;當n=5時,FLFSDStar、FLFSOchiai相比DStar、Ochiai分別能夠多定位到8和5個缺陷。對于MRR,FLFSDStar在除Lang外的五個項目上相比DStar的MRR值均更高;FLFSOchiai在Chart、Math、Time三個項目上相比Ochiai的MRR值均更高。其中,DStar和Ochiai在Lang項目上相比FLFS均有更好的定位效果,原因是DStar和Ochiai在Lang項目上已經取得了比其他五個項目更好的缺陷定位效果,導致在融合代碼結構信息后定位性能提升空間有限,甚至可能會降低缺陷定位效果。此外還可以發現FLFS技術的定位效果會受到所融合技術定位效果的影響,通過實驗結果可以看出,FLFS與所融合的SBFL技術的定位效果呈正相關。例如,對于Chart、Math和Closure項目,Ochiai的定位效果均優于DStar,因此FLFSOchiai相比FLFSDStar的性能也更好。
實驗結果表明,針對問題a),對于Einspect@n(n=1),FLFS相比DStar和Ochiai均取得了更好的定位效果,分別多定位到16和10個缺陷,提升了13.22%和7.63%;對于MRR,FLFS相比DStar和Ochiai分別提升了4.12%和1.09%。此外,FLFS的性能與所融合的SBFL技術的缺陷定位性能正相關。
為了評價方法靜態特征數據集中存在的類不平衡問題對FLFS缺陷定位效果的影響,本文將不通過聚類選取方法靜態特征數據集中不存在缺陷方法的FLFS表示為FLFS w/o clustering,并與FLFS進行比較,結果如表6所示。其中FLFSDStar w/o Clustering和FLFSOchiai w/o Clustering分別表示使用DStar和Ochiai計算頻譜可疑度。
從表5、6中可以看出,對于Einspect@n和MRR指標,FLFSDStar和FLFSOchiai分別取得了比FLFSDStar w/o Clustering和FLFSOchiai w/o Clustering更好的定位效果。對于Einspect@n指標,除n=1時,FLFSDStar w/o Clustering比DStar多定位到1個缺陷外,FLFSDStar w/o Clustering和FLFSOchiai w/o Clustering的定位效果甚至弱于DStar和Ochiai。例如,當n=3時,FLFSDStar w/o Clustering比DStar、FLFSDStar分別少定位到2和14個缺陷;FLFSOchiai w/o Clustering比Ochiai和FLFSOchiai分別少定位到5和13個缺陷。當n=1時,緩解方法靜態特征數據集中存在的類不平衡問題對FLFS定位效果提升最為明顯,FLFSDStar比FLFSDStar w/o Clustering提高了12.30%,FLFSOchiai比FLFSOchiai w/o Clustering提高了10.16%。而對于MRR指標,FLFSDStar比FLFSDStar w/o clustering提高了7.87%,FLFSOchiai比FLFSOchiai w/o Clustering提高了5.14%。
綜合以上分析,針對問題b),使用聚類方法處理數據集的類不平衡問題能夠有效提升缺陷預測模型的性能,進而提升缺陷定位效果。若不對數據集的類不平衡問題進行處理,直接將預測可疑度和頻譜可疑度融合,將不能提高SBFL的缺陷定位性能。
4 分析討論
4.1 FLFS使用不同融合方式時缺陷定位的性能
FLFS通過式(1)使用數值相乘的方式來融合缺陷預測模型的預測可疑度與SBFL的頻譜可疑度,得到各方法的融合可疑度值。除了這種方式外,還可以使用其他方式將頻譜可疑度和預測可疑度進行融合。例如,參考缺陷定位領域中融合歷史譜和頻譜可疑度的工作HSFL[7]以及融合代碼異味和文本相似度的工作BLI[29],對頻譜可疑度和預測可疑度使用權重相加方式進行融合,計算方式如式(3)所示。
M′(i)=k×spectrum(i)+(1-k)×prediction(i)(3)
其中:M′(i)表示第i個方法通過不同權重相加計算的融合可疑度值,而spectrum(i)和prediction(i)分別表示該方法的頻譜可疑度和預測可疑度;k是用來融合頻譜可疑度和預測可疑度的權重。參考HSFL和BLI的實驗設置,本文將k分別設置為0.1、0.3、0.5、0.7、0.9,通過實驗和FLFS進行對比。
本文將使用權重相加的方式計算融合可疑度的FLFS技術表示為FLFS′,其缺陷定位結果如表7、8所示。表中數據為FLFS′在不同項目上Einspect@n(n=1)和MRR的評估表現,FLFS′DStar和FLFS′Ochiai分別表示使用權重相加方式將缺陷預測模型預測的預測可疑度與DStar、Ochiai的頻譜可疑度進行融合。可以看出,k的取值越高,FLFS′的定位效果越好,當k=0.9時,對于Einspect@1,FLFS′DStar雖然比DStar多定位到8個缺陷,但仍比FLFSDStar少定位到8個缺陷;而FLFS′Ochiai雖然比Ochiai多定位到3個缺陷,但仍比FLFSOchiai少定位到7個缺陷。此外,對于MRR,FLFS′DStar和FLFS′Ochiai的MRR平均值分別低于DStar、FLFSDStar和Ochiai、FLFSOchiai。實驗結果表明,融合可疑度方式的差異會影響FLFS的缺陷定位效果,雖然FLFS′對于Einspect@1指標也能在一定程度上提高基線技術的定位效果,但是當使用相乘的方式來融合預測可疑度和頻譜可疑度時,能取得更好的缺陷定位效果。
4.2 有效性分析
外部有效性與本文實驗使用的數據集有關。本文使用Defecst4J作為實驗對象,它包括來自6個開源項目的395個缺陷。該數據集被廣泛用于評估缺陷定位方法的性能[25]。Defects4J數據集雖然具有一定的代表性,但無法保證FLFS在其他數據集上能得到相同的結果。此外,本文僅在實驗中使用了性能最好的SBFL技術(DStar和Ochiai)、常用的缺陷預測模型(RF)和被廣泛使用的聚類算法。上述技術雖然具有一定的代表性,但不能確保融合其他SBFL技術和缺陷預測技術進行軟件缺陷定位時具有相同效果。
內部有效性主要體現在方法實現及實驗過程的正確性。為緩解內部有效性威脅,使用第三方機器學習庫Scikit-learn實現的K-means算法對方法級靜態特征數據集中正確的數據進行聚類。由于DStar和Ochiai都未開源且方法易于實現,所以本文對其復現后在Defects4J數據集上進行了實驗,并將實驗結果與相關研究進行對比驗證,以確保實驗的正確性。此外,在實驗過程中對所編寫的代碼進行了多次檢查和測試,盡可能減少內部有效性威脅。構造有效性主要與實驗使用的評價指標有關。本文使用Einspect@n和MRR作為本文方法有效性的評價指標。其中,將Einspect@n用于統計缺陷定位的絕對排名,因為開發人員在檢查給定的可疑元素列表時更關注排名靠前的缺陷元素,所以實驗中重點關注了Einspect@n(n=1);而MRR則用于統計缺陷定位的相對排名。兩種評價指標已被廣泛應用在軟件缺陷定位領域[30]。
5 結束語
針對現有基于頻譜的缺陷定位方法中分析代碼信息不足導致精度和定位效果有限的問題,本文提出了一種融合代碼靜態特征和頻譜的軟件缺陷定位技術FLFS,通過將缺陷預測中使用到的代碼結構信息和SBFL的頻譜信息融合使用,以提升缺陷定位技術的性能。在Defects4J數據集上進行的實驗結果表明,對于Einspect@n和MRR,FLFS比SBFL技術均取得了更好的缺陷定位效果。在下一步工作中,嘗試將更多聚類方法應用于FLFS,同時融合更多SBFL技術并深入分析FLFS用于軟件多缺陷定位的效果;此外,還將嘗試在更多更大規模的數據集上進行實驗,以進一步驗證FLFS的有效性。
參考文獻:
[1]陳翔,鞠小林,文萬志,等.基于程序頻譜的動態缺陷定位方法研究[J].軟件學報,2015,26(2):390-412.(Chen Xiang,Ju Xiaolin,Wen Wanzhi,et al.Review of dynamic fault localization approaches based on program spectrum[J].Journal of Software,2015,26(2):390-412.)
[2]朱潤凝,趙逢禹.一種基于謂詞分層覆蓋矩陣的缺陷定位方法[J].計算機應用研究,2016,33(8):2375-2380,2395.(Zhu Running,Zhao Fengyu.Fault localization method based on predicate hierarchical coverage matrix[J].Application Research of Computers,2016,33(8):2375-2380,2395.)
[3]張文,李自強,杜宇航,等.方法級別的細粒度軟件缺陷定位方法[J].軟件學報,2019,30(2):195-210.(Zhang Wen,Li Ziqiang,Du Yuhang,et al.Fine-grained software bug location approach at method level[J].Journal of Software,2019,30(2):195-210.)
[4]Wong W E,Debroy V,Gao Ruizhi,et al.The DStar method for effective software fault localization[J].IEEE Trans on Reliability,2013,63(1):290-308.
[5]Just R,Jalali D,Ernst M D.Defects4J:a database of existing faults to enable controlled testing studies for Java programs[C]//Proc of International Symposium on Software Testing and Analysis.New York:ACM Press,2014:437-440.
[6]姜淑娟,張旭,王榮存,等.基于路徑分析和信息熵的錯誤定位方法[J].軟件學報,2021,32(7):2166-2182.(Jiang Shujuan,Zhang Xu,Wang Rongcun,et al.Fault localization approach based on path analysis and information entropy[J].Journal of Software,2021,32(7):2166-2182.)
[7]Wen Ming,Chen Junjie,Tian Yongqiang,et al.Historical spectrum based fault localization[J].IEEE Trans on Software Engineering,2019,47(11):2348-2368.
[8]Saha R K,Lease M,Khurshid S,et al.Improving bug localization using structured information retrieval[C]//Proc of the 28th IEEE/ACM International Conference on Automated Software Engineering.Piscataway,NJ:IEEE Press,2013:345-355.
[9]Jain A,Zongker D.Feature selection:evaluation,application,and small sample performance[J].IEEE Trans on Pattern Analysis and Machine Intelligence,1997,19(2):153-158.
[10]LeCun Y,Bengio Y,Hinton G.Deep learning[J].Nature,2015,521(7553):436-444.
[11]Li Yi,Wang Shaohua,Nguyen T N.Vulnerability detection with fine-grained interpretations[C]//Proc of the 29th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering.New York:ACM Press,2021:292-303.
[12]Abreu R,Zoeteweij P,Golsteijn R,et al.A practical evaluation of spectrum-based fault localization[J].Journal of Systems and Software,2009,82(11):1780-1792.
[13]Zhou Jian,Zhang Hongyu,Lo D.Where should the bugs be fixed? More accurate information retrieval-based bug localization based on bug reports[C]//Proc of the 34th International Conference on Software Engineering.Piscataway,NJ:IEEE Press,2012:14-24.
[14]Jones J A,Harrold M J.Empirical evaluation of the tarantula automatic fault-localization technique[C]//Proc of the 20th IEEE/ACM International Conference on Automated Software Engineering.New York:ACM Press,2005:273-282.
[15]Xie Xiaoyuan,Wong W E,Chen T Y,et al.Metamorphic slice:an application in spectrum-based fault localization[J].Information and Software Technology,2013,55(5):866-879.
[16]陳翔,顧慶,劉望舒,等.靜態軟件缺陷預測方法研究[J].軟件學報,2016,27(1):1-25.(Chen Xiang,Gu Qing,Liu Wangshu,et al.Survey of static software defect prediction[J].Journal of Software,2016,27(1):1-25.)
[17]Elish K O,Elish M O.Predicting defect-prone software modules using support vector machines[J].Journal of Systems and Software,2008,81(5):649-660.
[18]Catal C,Diri B.Investigating the effect of dataset size,metrics sets,and feature selection techniques on software fault prediction problem[J].Information Sciences,2009,179(8):1040-1058.
[19]Russell R,Kim L,Hamilton L,et al.Automated vulnerability detection in source code using deep representation learning[C]//Proc of the 17th IEEE International Conference on Machine Learning and Applications.Piscataway,NJ:IEEE Press,2018:757-762.
[20]Dam H K,Tran T,Pham T,et al.Automatic feature learning for vulnerability prediction[EB/OL].(2017-08-08).https://arxiv.org/abs/1708.02368.
[21]Halstead M H.Elements of software science[M].New York:Elsevier Science Inc.,1977.
[22]Chidamber S R,Kemerer C F.A metrics suite for object oriented design[J].IEEE Trans on Software Engineering,1994,20(6):476-493.
[23]Martin R.OO design quality metrics:an analysis of dependencies[EB/OL].(1994-10-28).https://www.cin.ufpe.br/~alt/mestrado/oodmetrc.pdf.
[24]McCabe T J.A complexity measure[J].IEEE Transactions on Software Engineering,1976,SE-2(4):308-320.
[25]張卓,雷晏,毛曉光,等.基于詞頻-逆文件頻率的錯誤定位方法[J].軟件學報,2020,31(11):3448-3460.(Zhang Zhuo,Lei Yan,Mao Xiaoguang,et al.Fault localization using term frequency-inverse document frequency[J].Journal of Software,2020,31(11):3448-3460.
[26]Tanha J,Abdi Y,Samadi N,et al.Boosting methods for multi-class imbalanced data classification:an experimental review[J].Journal of Big Data,2020,7(9):article No.70.
[27]胡小生,張潤晶,鐘勇.兩層聚類的類別不平衡數據挖掘算法[J].計算機科學,2013,40(11):271-275.(Hu Xiaosheng,Zhang Runjing,Zhong Yong.Two-tier clustering for mining imbalanced datasets[J].Computer Science,2013,40(11):271-275.)
[28]Voorhees E M.The TREC-8 question answering track report[EB/OL].(2000-12-11).https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=151495.
[29]Takahashi A,Sae-Lim N,Hayashi S,et al.A preliminary study on using code smells to improve bug localization[C]//Proc of the 26th Conference on Program Comprehension.New York:ACM Press,2018:324-327.
[30]Zou Daming,Liang Jingjing,Xiong Yingfei,et al.An empirical study of fault localization families and their combinations[J].IEEE Trans on Software Engineering,2021,47(2):332-347.
收稿日期:2023-02-20;修回日期:2023-04-13? 基金項目:國家自然科學基金資助項目(61702041);北京市教委科技計劃資助項目(KM201811232016);北京信息科技大學“勤信人才”培育計劃資助項目(QXTCPC201906)
作者簡介:王浩仁(1997-),男,河北石家莊人,碩士,CCF會員,主要研究方向為軟件缺陷定位;岳雷(1998-),男,甘肅蘭州人,碩士研究生,主要研究方向為軟件缺陷定位;李靜雯(1999-),女,河北滄州人,碩士研究生,主要研究方向為軟件缺陷定位;崔展齊(1984-),男(通信作者),貴州金沙人,教授,碩導,博士,主要研究方向為軟件分析與軟件測試技術(czq@bistu.edu.cn).
