基于優化圖結構自編碼器的網絡表示學習
2023-10-21 07:03:58富坤郝玉涵孫明磊劉贏華
計算機應用 2023年10期
富坤,郝玉涵,孫明磊,劉贏華
基于優化圖結構自編碼器的網絡表示學習
富坤*,郝玉涵,孫明磊,劉贏華
(河北工業大學 人工智能與數據科學學院,天津 300401)( ? 通信作者電子郵箱fukun@hebut.edu.cn)
網絡表示學習(NRL)旨在學習網絡頂點的潛在、低維表示,再將得到的表示用于下游的網絡分析任務。針對現有采用自編碼器的NRL算法不能充分提取節點屬性信息,學習時容易產生信息偏差從而影響學習效果的問題,提出一種基于優化圖結構自編碼器的網絡表示學習模型(NR-AGS),通過優化圖結構的方式提高準確率。首先,融合結構和屬性信息來生成結構和屬性聯合轉移矩陣,進而形成高維表示;其次,利用自編碼器學習低維嵌入表示;最后,通過在學習過程中加入深度嵌入聚類算法,對自編碼器的訓練過程和節點的類別分布劃分形成自監督機制,并且通過改進的最大均值差異(MMD)算法減小學習得到的低維嵌入潛在表示層分布和原始數據分布的差距。此外,NR-AGS使用自編碼器的重構損失、深度嵌入聚類損失和改進的MMD損失共同優化網絡。應用NR-AGS對3個真實數據集進行學習,再使用得到的低維表示完成下游的節點分類和節點聚類任務。實驗結果表明,與深度圖表示模型DNGR(Deep Neural networks for Graph Representations)相比,NR-AGS在Cora、Citeseer、Wiki數據集上的Micro-F1值分別至少提升了7.2、13.5和8.2個百分點。可見,NR-AGS可以有效提升NRL的學習效果。
網絡表示學習;屬性信息;自編碼器;深度嵌入聚類;最大均值差異
0 引言
隨著信息技術的廣泛使用,分析社交網絡、生物網絡和引文網絡等信息網絡能夠提取社會生活的各方面潛在的信息,在許多學科的各種新興應用程序中發揮著重要的作用[1-3]。例如,在社交網絡中,將用戶分類為不同的社會群體有助于現實中的一些任務,如用戶搜索、有針對性的廣告和推薦等;在通信網絡中,檢測網絡的社區結構可以幫助更好地理解謠言的傳播過程。然而,對這些網絡的有效分析依賴于網絡的表示學習[4]。
網絡表示學習(Network Representation Learning, NRL)的目的是學習網絡頂點的潛在、低維嵌入表示,同時保留網絡拓撲結構、頂點內容和其他邊信息[5]。在學習了新的頂點低維嵌入表示后,可以輕松有效地執行網絡分析任務,如節點聚類、節點分類、鏈路預測等[6]。相關NRL模型有:基于結構信息的模型,如DeepWalk[7]、Node2Vec[8]、DNGR(Deep Neural Networks For Graph Representations)[9]、O2MAC (One2Multi graph Autoencoder for multi-view graph Clustering)[10]等;基于結構和屬性信息的模型,如TADW (Text-Associated DeepWalk)[11]、DFCN(Deep Fusion Clustering Network)[12]、變分圖自動編碼器(Variational Graph Auto-Encoder, GVAE)[13]等。但是,當前的NRL方法存在以下兩個關鍵問題:1)網絡中的屬性信息可以補償結構信息,因此有效提取屬性信息是很重要的[14];2)在生成低維表示的學習過程中存在一定的信息偏差,影響網絡表示學習的效果。
針對以上問題,本文提出了基于優化圖結構自編碼器的網絡表示學習模型(Network Representation learning model based on Autoencoder with optimized Graph Structure, NR-AGS),該模型能夠充分利用網絡中的結構和屬性信息,提高網絡節點的聚集性,減小低維嵌入表示與原始數據分布的差距,優化低維表示空間的結構。
本文主要工作如下:
1)通過隨機游走算法,將結構和屬性信息聯合形成結構和屬性聯合轉移矩陣PPMI(Positive Pointwise Mutual Information),該矩陣使結構和屬性信息的聯系更加緊密,并且相互補充、制約,能夠更加充分利用網絡的信息學習。
2)在運用自編碼器(Autoencoder)學習低維嵌入表示時,引入深度嵌入聚類損失和改進的最大均值差異(Maximum Mean Discrepancy, MMD)損失共同訓練網絡。深度嵌入聚類損失使學習得到的數據中同類別的節點更加聚集,將聚類和自動編碼器統一在一個框架中。使用聚類分布指導網絡表示的學習,反之,低維嵌入目標也監督聚類的生成,形成自監督機制,利用該機制優化網絡結構,增強網絡表示學習的效果。改進的MMD損失使學習到的低維嵌入表示分布更加接近原始數據分布,有利于保持它們的一致性。
3)運用NR-AGS學習的低維嵌入在Cora(https://linqs-data.soe.ucsc.edu/public/lbc/cora.tgz)、Citseer(https://linqs-data.soe.ucsc.edu/public/lbc/citeseer.tgz)、Wiki(https://dumps.wikimedia.org/wikidatawiki/entities/)這3個公開經典數據集上的下游任務結果表明了NR-AGS的有效性,提升了網絡表示學習的結果。
1 相關工作
給定一個信息網絡(,,,),其中:是節點集合,是邊集合,是節點屬性,是節點標簽。網絡表示學習研究的目標是:面對大規模并且稀疏的網絡,設計能夠滿足保留網絡的局部和全局結構,并有效利用頂點屬性信息,最終得到的節點低維嵌入表示能夠高效地完成下游網絡分析任務,如節點分類、節點聚類、社區檢測等。
一部分網絡表示學習模型只學習結構信息:DeepWalk[7]利用隨機游走將網絡嵌入問題轉化為一個詞嵌入問題;Node2Vec[8]在DeepWalk的基礎上增加了廣度優先和深度優先以探索不同的節點鄰域,既考慮了局部信息又考慮了宏觀的信息,具有很高的適應性;DNGR[9]運用隨機游走算法計算節點拓撲結構的高維表示,再輸入去噪自編碼器學習低維表示;LINE(Large-scale Information Network Embedding)[14]不再采用隨機游走的方法,它在圖上定義了兩種相似度——一階相似度和二階相似度,并基于這兩種相似度獲得節點表示;GraRep(learning Graph Representations with global structural information)[15]改進LINE,提出一種獲取階關系信息的圖表示方法,可以更好地獲得節點的高階信息;SDNE(Structural Deep Network Embedding)[16]通過深層神經網絡自編碼器實現學習網絡節點表示,直接將一階相似度和二階相似度保留在嵌入表示中。
上述模型都只使用了拓撲結構信息,但是真實的社會網絡不僅有結構信息,還有豐富的屬性信息,屬性信息可以補償結構信息:TADW[11]運用矩陣分解的方法結合屬性信息和結構信息;AANE(Accelerated Attributed Network Embedding)[17]將屬性信息作為被分解的信息之一,使得矩陣分解能夠受到結構和屬性信息的共同影響;DVNE(Deep Variational Network Embedding in Wasserstein space)[18]在SDNE的基礎上考慮屬性信息并提出了一種新的度量,相較于SDNE學習效果更好;ANAE(Attributed Network Auto-Encoder)[19]從屬性化的局部子圖中聚合屬性信息,并將目標節點的表示擴散到局部子圖中的其他節點,以重建它們的屬性,更好地獲得了節點上下文信息。
為了優化網絡中的結構,有些模型引用聚類思想使網絡結構更加聚集,有些模型通過引入MMD損失減小目標分布和原始分布的差異優化圖結構。IDEC(Improved Deep Embedded Clustering with local structure preservation)[20]顯式地定義聚類損失,模擬監督深度學習中的分類誤差,通過學習表示和聚類聯合優化特征。結構化深度聚類網絡(Structural Deep Clustering Network, SDCN)[21]結合了自動編碼器和圖卷積算法的優點,將結構化信息明確地應用到深度嵌入聚類中。DFCN[12]在此基礎上將圖結構和節點屬性聯合建模,并捕獲了全局聚類結構。最大均值差異(MMD),即兩個概率分布之間的距離度量,在MMDnets[22]中,MMD被用于直接比較生成的樣本與真實樣本;DSNs(Domain Separation Networks)[23]將MMD融合到編碼?解碼的網絡中,減小源域和目標域的差異,提高模型性能;MMD-GAN(Maximum Mean Difference-Generative Adversarial Network)[24]則將它的作為損失函數擴展到GAN框架中,明顯改善性能。
根據以上研究,同時利用結構和屬性信息的模型普遍比只利用單個信息的模型學習效果更好,同時在網絡中融入聚類和MMD可以優化網絡結構,獲得更優的表示。
2 基于優化圖結構自編碼器
NR-AGS的總體框架如圖1所示。它的設計思路如下:首先,為了充分利用結構信息和屬性信息,引入了DNGR中的PPMI矩陣,并在此基礎上融合了屬性信息解決數據稀疏導致學習效率低的問題;其次,為了優化自編碼器學習到的表示結構,在使用自動編碼器學習低維嵌入表示的過程中,加入深度嵌入聚類和MMD共同優化深度網絡。綜上所述,本文在自編碼器重構損失的基礎上,添加了深度聚類損失和MMD損失兩個信息約束項。
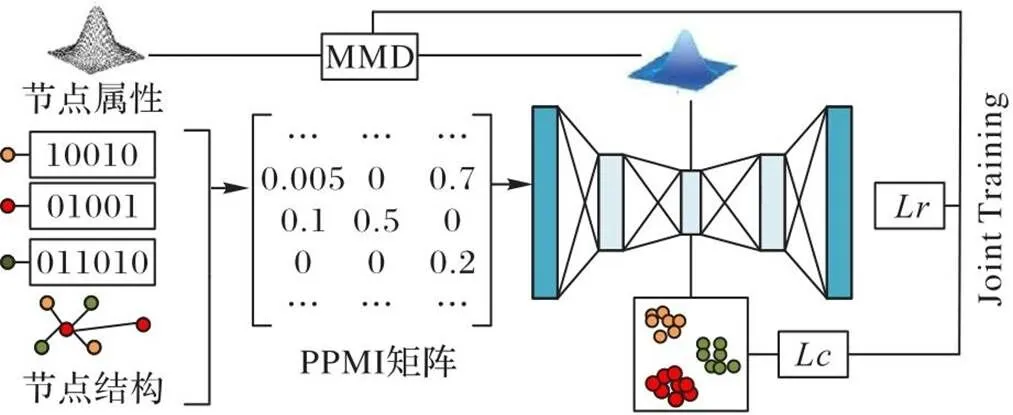
圖1 NR-AGS框架
2.1 PPMI矩陣構建
DNGR通過隨機游走算法構建的PPMI矩陣只融合了結構信息,本文在此基礎上又融入了屬性信息,利用結構和屬性信息共同提取特征信息,有助于獲得更好的節點表示。
在網絡表示學習過程中,首先結合結構信息和屬性信息形成結構?屬性聯合轉移矩陣,再通過隨機沖浪算法形成共現概率矩陣,最后轉化為高密度的PPMI矩陣。
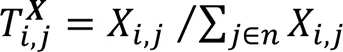
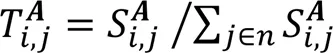
為了綜合運用節點的兩個信息源,結合結構轉移矩陣和屬性轉移矩陣形成結構和屬性聯合轉移矩陣,計算方法如下:
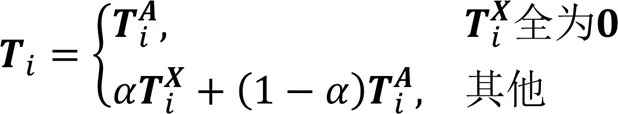
其中:表示各個轉移矩陣的第行;(0<<1)為平衡系數。該聯合方法通過以下方法使屬性網絡更加密集:1)如果在網絡中兩個節點間沒有連邊,但是它們的前個的節點屬性相似,則它們之間就會連上一條新邊,使網絡之間聯系更加緊密;2)如果兩個節點已經存在連邊,則將通過參數(0<<1)平衡結構和屬性信息在運用中的比重,值越小,屬性信息對最終的節點低維表示的影響越大[9]。
其次,沿用DNGR中的兩個步驟:1)通過步迭代,每次以的概率隨機沖浪轉化為共現概率矩陣;2)通過共現概率矩陣構造信息率密度較高的PPMI矩陣。
2.2 基于最大均值差異的結構優化
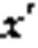
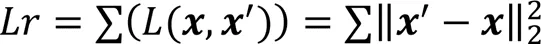
本文通過引入改進的MMD度量低維嵌入表示和輸入之間的差異,通過減小該差異優化自編碼器學到的低維嵌入表示。編碼器的中間層的潛在低維嵌入表示會保存原始數據的重要信息,從而形成兩個不同但相關的域,即源域(原始數據分布)和目標域(編碼器中間的低維嵌入表示分布),即最小化源域和目標域的差異,使目標域的結果更加準確。MMD就是通過核函數將一個分布映射到再生希爾伯特空間上,之后度量在再生希爾伯特空間中兩個分布的距離。MMD的損失如下:
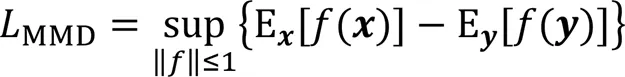
其中:sup表示求上界;E表示求期望;(?)表示映射函數,函數指在再生希爾伯特空間中的范數應該小于等于1;在本文中指原始數據,指編碼器產生的低維嵌入表示。MMD的核函數是高斯核函數:
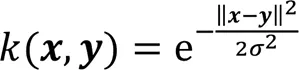
由于高斯核函數是非線性的,耗時長,所以本文對它進行改進,運用線性的二次有理核代替高斯核函數提高運算效率,改進的二次有理核通常具有和高斯核函數相同的效果,核函數如下所示:
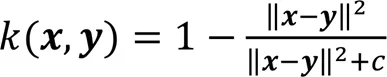
其中為二次有理核的超參數:較小的會使決策表面更平滑;較高的使結果更加準確,但可能會過擬合。在實際應用中會取多個值,分別求核函數后再取和,作為最后的核函數[26]。
本文通過引入改進的MMD使得兩個域之間的差距越來越小,使編碼器的低維嵌入表示越來越準確。其中,核方法的非線性映射具有面向具體應用問題設計的特性,因此便于集成問題相關的先驗知識;此外,線性學習器相較于非線性學習器具有更好的過擬合控制,可以更好地保證泛化性能。綜上,選擇MMD有明顯的優勢。
2.3 基于深度聚類的結構優化
在網絡中節點結構間具有內聚的宏觀特性,同類節點之間距離較近,不同類節點距離較遠,為了使得本文利用自編碼器學習節點的低維嵌入表示更加準確地反映這種宏觀特性,優化節點結構,需要增強網絡結構中節點的內聚性。本文在編碼過程中引入深度嵌入聚類算法指導監督編碼器,深度嵌入聚類作用在深度神經網絡形成的低維嵌入表示空間,具體步驟[27]如下。
1)計算由t分布測量的軟標簽分配矩陣。先運用傳統的-means算法求出聚類第個中心,q是以t分布測量的空間中的第個樣本與第個聚類中心的的相似性度量,又稱為軟標簽概率,q真實地反映了節點的數據類分布概率。q組成的矩陣即為∈R,為節點總數,為數據集類目數目。q的計算公式如下:

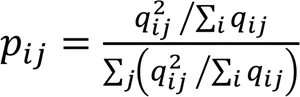
3)計算和的KL散度。在求得的軟標簽分配概率矩陣和目標分布概率矩陣后,運用KL散度(Kullback-Leibler Divergence)衡量它們之間的差距。KL散度可以衡量在選擇近似分布時損失的信息量,KL散度值越小,表示和的差距越小,越真實地衡量目標分布。聚類損失的計算公式如下。
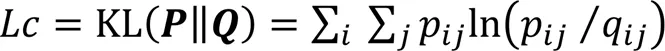
量化聚類損失是深度嵌入聚類的核心步驟,將加入統一的損失函數中訓練深度神經網絡,進一步強化監督低維嵌入表示的生成。在網絡訓練過程中,通過調整,使得更好地衡量真實的數據分布,更新低維嵌入表示空間的聚類中心和深度神經網絡的參數,使得該表示空間每個類中的樣本分布更加密集[28]。
2.4 NR-AGS總體設計
NR-AGS在訓練過程中共考慮3部分損失:自動編碼器重構損失、MMD損失和聚類損失。自編碼器用于學習低維嵌入表示,學習到的低維表示可以較好地保留數據中的信息;MMD損失可以減小原始數據分布和編碼器中間的低維嵌入表示分布之間的差異;聚類損失可以調整嵌入空間的結構達到聚類效果,有利于學習到的低維嵌入的節點分布更加清晰,更好地體現網絡中節點間具有社區內聚的宏觀特性。NR-AGS的整體損失如下:
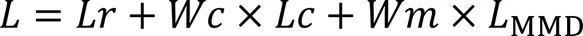
其中:和分別為深度嵌入聚類損失和MMD損失的權重。使用深度嵌入聚類損失和改進的MMD損失共同優化深度神經網絡,可以得到更加準確的低維嵌入表示。算法偽代碼如算法1所示。
算法1 NR-AGS。
輸入 鄰接矩陣、屬性信息矩陣、平衡系數、Top-值、隨機沖浪迭代步數、重啟概率、嵌入空間維度、簇中心個數、迭代次數;
輸出 特征向量矩陣。
1)初始化模型所有權重矩陣
8) for=1 todo
12) end for
由上面分析可以得出,NR-AGS的時間復雜度主要取決于PPMI矩陣、自編碼器、深度嵌入聚類和改進的MMD,令為低維嵌入維度,則NR-AGS的時間復雜度為(2)。
3 實驗與結果分析
為了測試NR-AGS的性能,將本文模型與幾種常用的方法在3個真實網絡數據集上進行比較,通過本文模型和它的變體學習的低維嵌入表示在下游任務的實驗,驗證本文模型在網絡表示學習方面的有效性。
本文實驗環境是基于64核、內存4 GB的CPU環境,編程語言為Python3.6,實驗框架為PyTorch1.8.1。
3.1 實驗設置
3.1.1數據集
本文選取研究網絡表示學習時常用的數據集進行實驗,分別是兩個引文網絡數據集Cora、Citeseer和一個網頁網絡數據集Wiki。
Cora數據集包含2 708篇機器學習論文和論文間的5 429篇鏈接,這些鏈接是文檔之間的引用關系,每個節點的屬性信息對應每篇論文的一個1 443維向量表示,節點的標簽按論文研究領域分為7個類別,分別為神經網絡、遺傳算法、基于案例、概率方法、強化學習、規則學習和理論。
Citeseer數據集包含3 312篇論文、4 732個鏈接和1 433個屬性,節點的標簽按論文研究領域分為數據庫、機器學習、代理、信息檢索、人工智能和人機交互這6類。
Wiki數據集是一個包含2 405個網頁和12 761個鏈接的網頁網絡數據集,每個網頁表示一個節點,節點之間的邊是連接到其他網頁的超鏈接,每個網頁的文本內容作為該網頁的屬性信息。按網頁類別賦予不同的標簽,如藝術、歷史、科學等,共17類。相較于Cora和Citeseer數據集,Wiki數據集的節點數少、連接多、類別多。具體數據信息如表1所示。
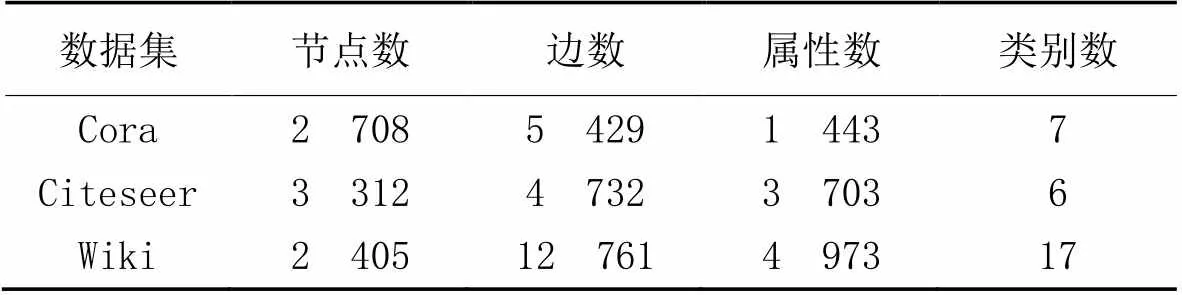
表1 網絡數據集詳情
3.1.2基準方法
本文運用SVD(Singular Value Decomposition)算法進行只利用網絡中屬性信息的網絡表示學習。與經典的網絡表示學習算法對比:1)DeepWalk[7]將網絡嵌入問題轉化為一個詞嵌入問題;2)Node2Vec[8]通過增加廣度優先和深度優先探索不同的節點鄰域,既考慮了局部信息又考慮了宏觀的信息,具有很高的適應性;3)DNGR[9]首先運用隨機沖浪算法獲取網絡的高維節點表示,其次使用去噪自編碼器學習節點的低維表示,但只融合了結構信息。
其他對比的先進網絡表示學習算法:1)TADW[11]是基于矩陣分解形式的DeepWalk算法,并在訓練過程中融合了節點的屬性信息;2)AANE[17]將屬性信息作為被分解的信息之一,使得學習到的表示結果能夠保持結構上距離相近和屬性相似的節點向量表示比較接近;3)ANAE[19]通過從屬性化的局部子圖中聚合屬性信息重建屬性,獲得了節點上下文信息;4)DFCN[12]利用深度嵌入聚類形成三重監督機制,能更有效地融合網絡中的信息,優化網絡結構;5)dSAFNE(dynamic Structure and vertex Attributes Fusion Network Embedding)[29]通過引入了一種屬性驅動的拉普拉斯空間優化方法收斂結構特征提取和屬性特征提取的過程,使得具有相似屬性但拓撲距離較遠的頂點在嵌入空間中也保持相鄰。
3.1.3實驗參數設置
由于DNGR也是網絡表示學習模型,同時也可將此模型用于本文實驗的數據集(具體情況可見文獻[30]),本文實驗也符合DNGR的環境,所以結構屬性聯合轉移矩陣時使用的屬性相似性調整參數Top-、平衡結構和屬性信息的超參數、隨機沖浪算法形成共現概率矩陣的重啟概率參數、隨機沖浪算法每次迭代步數的參數設置沿用DNGR模型相同的設置[9]。改進的MMD部分核函數的超參數,該參數在實際應用中會取多個值,本文取值集合為{2××0.1,2××0.2,2××0.5,2××1,2××2,2××5,2××10},為自編碼器形成的低維嵌入維度,再分別按照式(13)求出核函數,將所得的核函數求和,作為最后的核函數。深度嵌入聚類損失權重和MMD損失權重在模型運行中影響的具體分析見3.6節。
3.2 節點分類實驗
節點分類是評價網絡表示學習模型的一個重要下游任務,本文在3個數據集上先運用本文模型學習低維嵌入表示之后,再進行下游節點分類的實驗。在節點分類實驗中抽出一定比率帶標記的節點嵌入表示,作為訓練集,其余作為測試集,其中訓練集比例分別為10%、30%、50%、70%、90%,做10次實驗,實驗結果取均值。表2~4中分別為不同模型在3個數據集節點分類任務中的Micro-F1指標的結果。
從表2~3可以看出,在Cora和Citeseer數據集上,在不同比例的訓練集下,NR-AGS均優于基準方法;從表4可以看出,在Wiki數據集上訓練比例為10%和50%時,NR-AGS的Micro-F1值略差于其他對比基準模型,其余訓練比例的Micro-F1值均優于其他對比基準模型。具體地,與DNGR相比,在Cora、Citeseer和Wiki數據集上,NR-AGS的Micro-F1分別提升了7.2~8.8、13.5~25.3和8.2~12.1個百分點。
數據結果顯示,由于NR-AGS有效地結合了節點結構和屬性信息,使得它們相互補充和制約;聯合深度嵌入聚類損失共同優化網絡,使得不同類別節點分布更加聚集;引入MMD損失,使得學習到的低維嵌入表示能夠更加接近真實的數據。通過以上兩個損失約束使得NR-AGS取得了比其他基準模型在大多數節點分類的實驗中更好的效果并且較為穩定。由于Wiki數據集類別較多,數據較復雜,對節點分類的效果有一定的影響,NR-AGS的學習效果存在個別不穩定的情況。
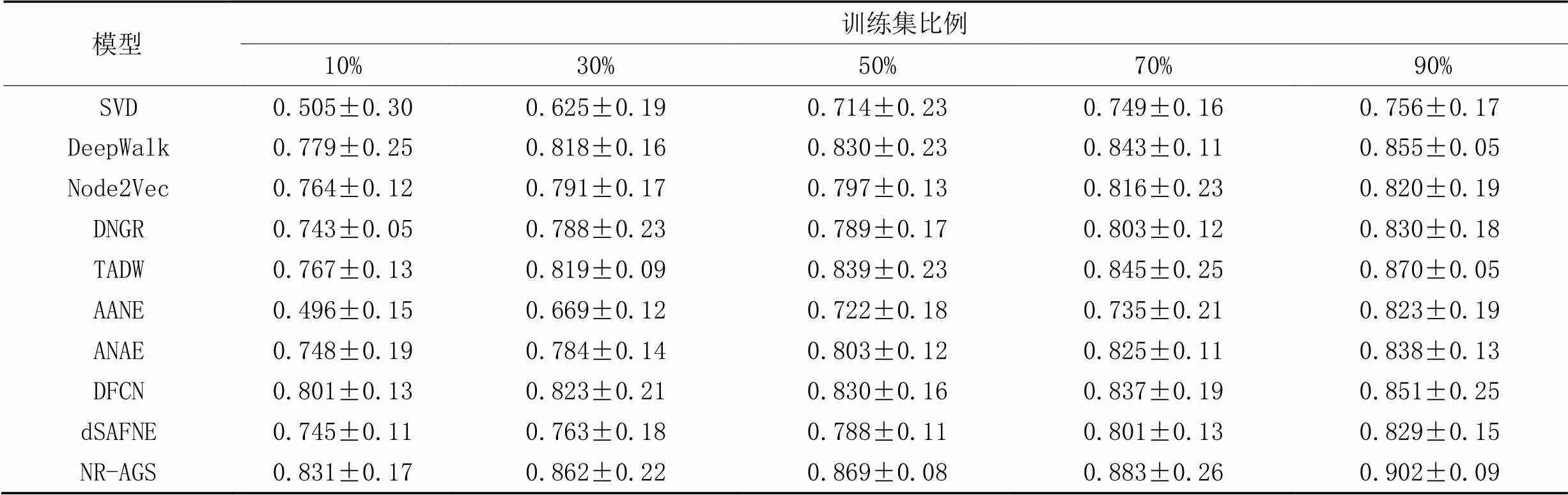
表2 Cora數據集上的節點分類結果的Micro-F1值

表3 Citeseer數據集上的節點分類結果Micro-F1值
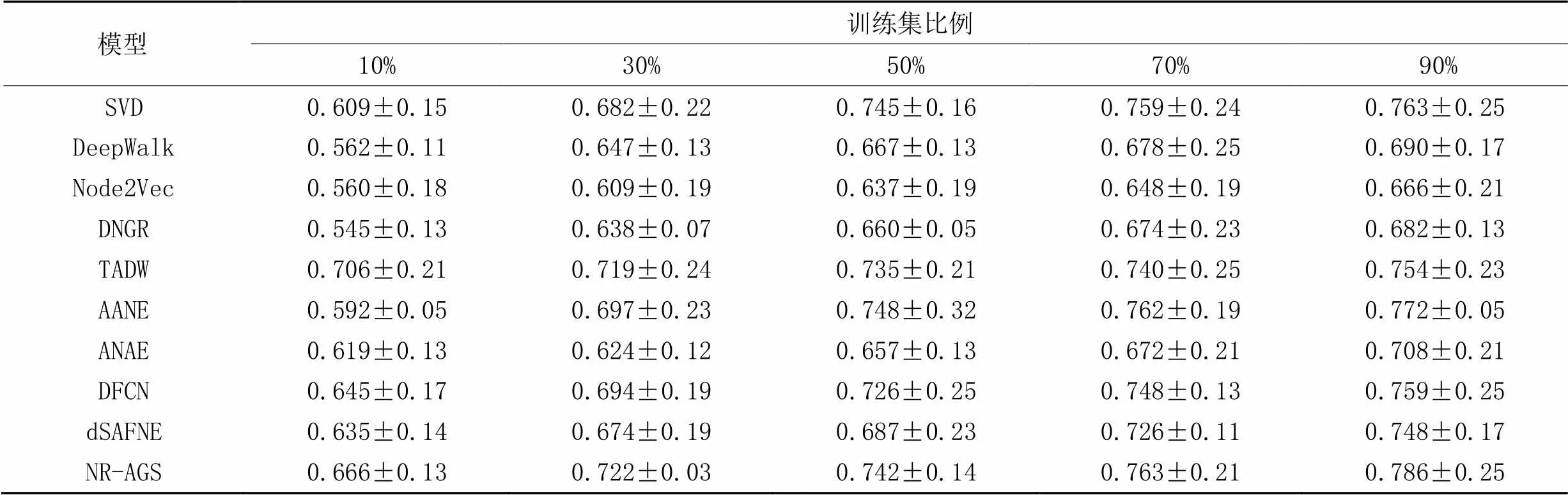
表4 Wiki數據集上的節點分類結果的Micro-F1值
3.3 可視化實驗
本節運用t-SNE(t-distributed Stochastic Neighbor Embedding)工具[31]可視化Cora和Citeseer數據集的下游節點分類實驗結果。圖2展示了DeepWalk、TADW、AANE和NR-AGS在Cora數據集上的效果,其中,不同顏色的點表示數據集的不同類別。Cora數據集有7個類別,從圖2可以看出,DeepWalk各個類別的數據點界限不清晰,分布較為混亂,而TADW、AANE的每個類別的分布結果較平均,但是邊界不夠清晰,而NR-AGS能夠清晰地體現每類數據的界限,對應結構更緊湊,呈現較好的可視化效果。圖3展現了上述4種模型在Citeseer數據集上的可視化效果,Citeseer具有6個類別,從圖3可以看出,DeepWalk、TADW、AANE的圖示中各個類別節點分布混亂,邊界也不清晰,而NR-AGS呈現出同類節點明顯聚集的效果。從上述可視化的實驗結果可以看出,NR-AGS由于引入了深度嵌入聚類與自編碼器形成自監督,在學習的過程中優化了圖結構,使網絡中節點的聚集性更加顯著,可視化效果優于其他基準模型。
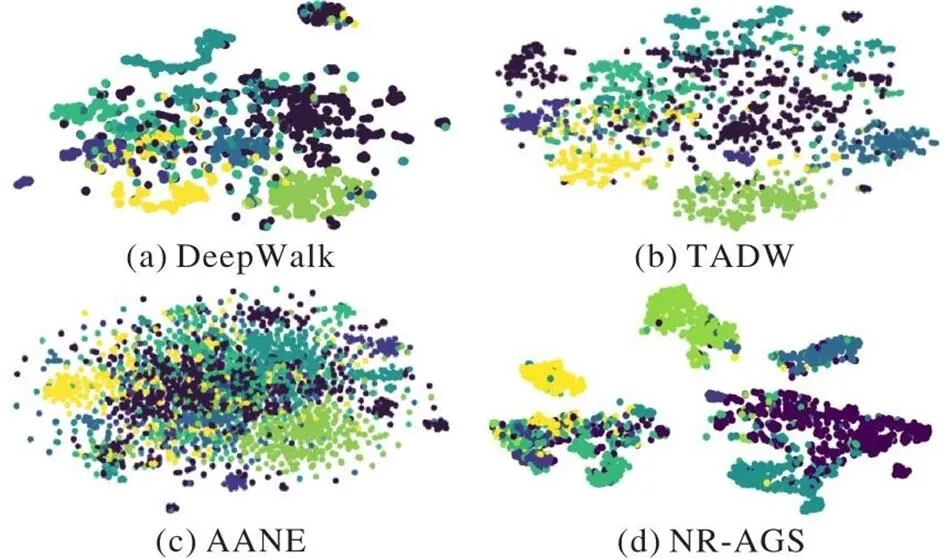
圖2 Cora數據集的可視化
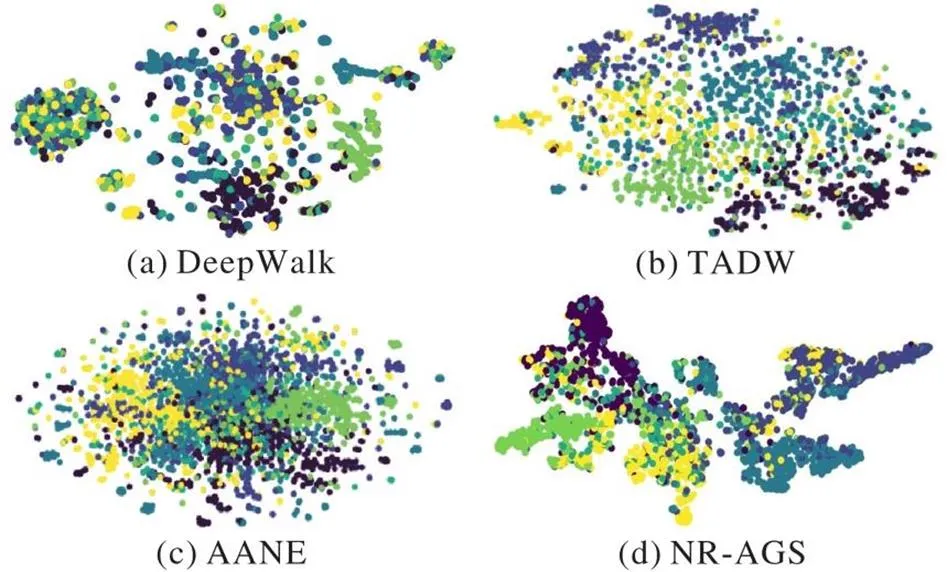
圖3 Citeseer數據集的可視化
3.4 消融實驗
為了驗證添加深度嵌入聚類損失和改進的MMD損失的有效性,本節提出3個NR-AGS的變體模型,進行消融實驗。3個NR-AGS的變體模型分別為:1)NR-AGS-a,表示無深度嵌入聚類損失和MMD損失;2)NR-AGS-ac,表示僅使用深度嵌入聚類損失;3)NR-AGS-am,表示僅使用MMD損失。NR-AGS表示同時使用深度嵌入聚類損失和MMD損失的完全體。分別在3個數據集上先運用上述4種模型學習低維嵌入表示之后,進行訓練集比例為50%的節點分類實驗,Micro-F1、Macro-F1作為評價指標,實驗結果如表5所示。
從表5可以看出:
1)在Cora和Citeseer數據集上,同時使用深度嵌入聚類損失和MMD損失的完全體NR-AGS的Micro-F1、Macro-F1值均優于其他3個變體模型,表明了同時使用這兩種約束會提升模型的分類性能。
2)在Wiki數據集上的節點分類實驗中,同時使用深度嵌入聚類損失和MMD損失的完全體NR-AGS的Micro-F1、Macro-F1值低于NR-AGS-ac、NR-AGS-am;這是因為Wiki數據集較大,類別數較多,影響深度嵌入聚類損失和MMD損失共同約束的效果,調參更加復雜,導致共同約束的節點分類效果較不穩定。
3)NR-AGS-ac、NR-AGS-am和NR-AGS在所有數據集上的節點分類結果均優于NR-AGS-a,表明了單獨使用或同時使用兩個約束均會提升模型的分類性能,結果驗證了這兩個損失約束的有效性。

表5 NR-AGS及其變體模型的節點分類結果
3.5 節點聚類實驗
在3個數據集上先運用本文模型學習得到低維嵌入表示之后,再進行下游節點聚類[32]的實驗,評估指標選用標準化互信息(Normalized Mutual Information, NMI)和正確率(ACC),實驗結果如圖4所示。從圖4中可以得出以下結論:1)利用節點結構信息和屬性信息的網絡表示學習模型大部分比只運用節點結構信息的模型能獲得更好的節點聚類效果,說明節點屬性信息能為節點聚類任務提供有效支持信息;2)相較于其他利用了結構和屬性信息的基準模型,NR-AGS取得了更好或者相當的效果,說明NR-AGS可以獲得更高質量的節點低維嵌入表示,進而有益于節點聚類任務。
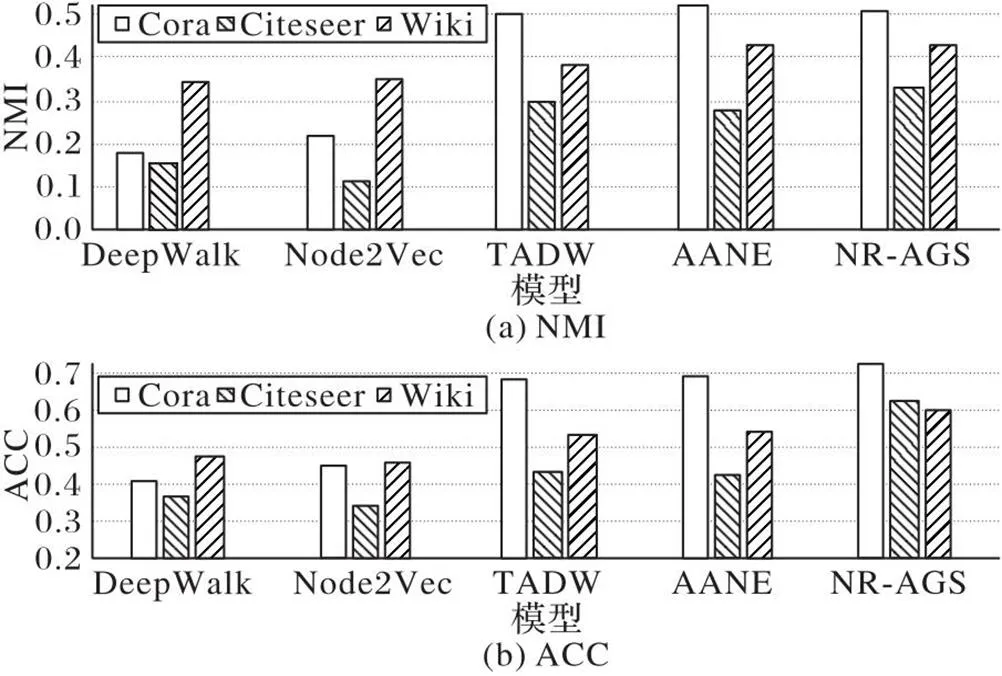
圖4 在3個數據集上的節點聚類結果
3.6 參數敏感性分析
本節通過實驗分析NR-AGS中自編碼器的低維嵌入表示的維數、MMD的參數、深度嵌入聚類損失權重和MMD損失權重對下游節點分類任務性能的影響。當分析一個參數時,固定其他非分析參數,改變該分析參數的數值研究它的影響。
自編碼器生成的低維嵌入表示的維度對模型的學習效果有一定的影響,在3個數據集上先運用本文模型學習低維嵌入表示之后,再進行下游節點分類的實驗。訓練集比例為50%,Micro-F1作為評價指標,分別設置=64、128、192、256、320、324、448、512維,結果如圖5(a)所示。從圖5(a)可以看出,Micro-F1值逐漸上升,但在256維時,存在較為明顯的拐點,即當低維嵌入表示的維度高于256維時,節點分類的效果沒有穩步上升,反而有所下降。由實驗結果可知NR-AGS在=256時性能較好。
MMD的參數依照DSNs中的經驗,較小的會使決策表面更平滑,而較大的使結果更加準確,但可能過擬合。為了保持穩定性,在實際應用中會取多個值,分別求核函數。本文實驗中以維度的兩倍為基數,以1為中心點,取{0.1,0.2,0.5,1,2,5,10},再另={0.1,0.2,0.5,1,2,5,10}形成多核進行網絡學習,從圖5(b)中可以看出,當取時,實驗結果比取單個核函數效果更好。
圖5(c)顯示深度嵌入聚類損失權重對節點分類性能的影響,實驗中將它的取值從0.01調整到10。可以發現,在3個數據集上,隨著權重的增加,NR-AGS的Micro-F1值會發生變化,說明模型對參數的敏感性較高。綜合考慮,在深度嵌入聚類損失的權重取1時,在3個數據集上的節點分類性能都相對較好。
圖5(d)展示了MMD損失權重對模型節點分類性能的影響。在10-3至103時,NR-AGS的分類表現都較穩定,說明NR-AGS對參數的敏感性較低。在3個數據集上,取值為1時,模型分類效果較好。
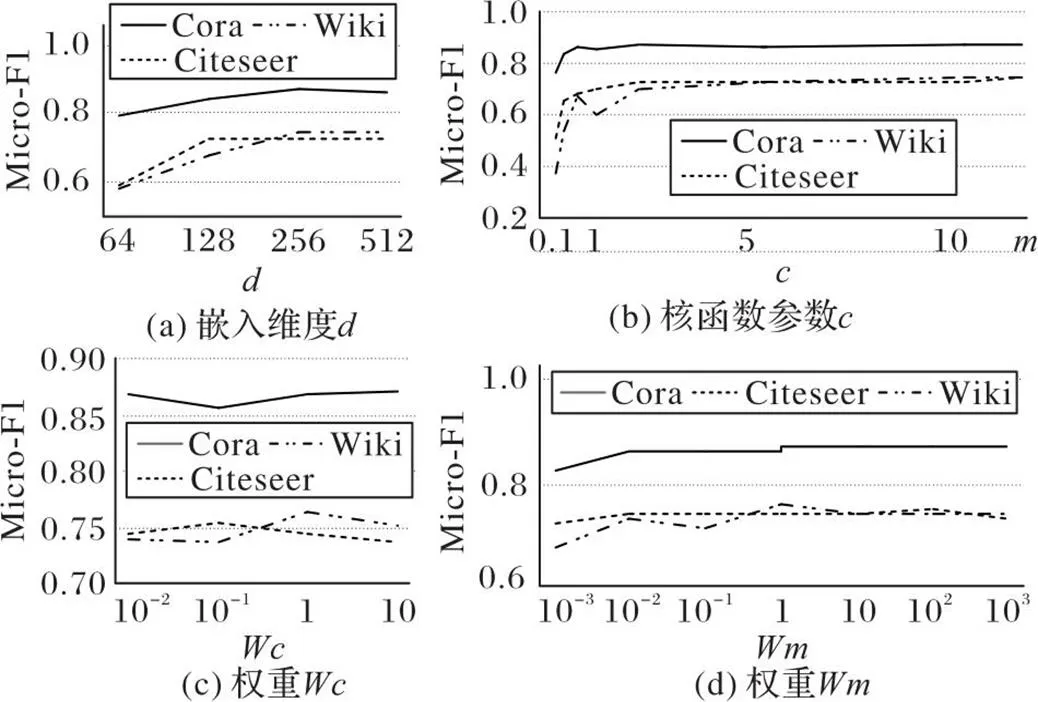
圖5 不同參數對Micro-F1值的影響
4 結語
為了充分利用網絡中的結構和屬性信息,本文提出基于優化圖結構自編碼器的網絡表示學習模型(NR-AGS)。引入PPMI矩陣將結構和屬性信息相融合,得到數據的高維嵌入表示,再利用自編碼器學習低維嵌入表示,在學習過程中融合深度嵌入聚類和改進的最大均值差異共同優化學習過程。使用NR-AGS學習得到的低維嵌入表示進行下游的節點分類實驗、可視化實驗和節點聚類等實驗,實驗結果驗證了NR-AGS具有較好的網絡表示學習效果。實驗結果表明使用PPMI矩陣將結構和屬性信息結合的學習方法能更加高效率地利用網絡的真實信息,在學習過程中融合聚類算法可以更好地使用數據分布的內聚性優化數據結構,改進的最大均值差異使學習到的低維嵌入表示更加接近真實數據,通過聯合優化以上3種損失,改善了學習到的低維表示在下游任務上的性能。在未來的研究中,可以將該模型進一步應用于大規模的網絡數據,還可以將模型應用于稀疏或缺失數據集,進一步改進模型,提高它的學習能力。
[1] 孫金清,周慧,趙中英. 網絡表示學習方法研究綜述[J]. 山東科技 大學學報(自然科學版), 2021, 40(1):117-128.(SUN J Q, ZHOU H, ZHAO Z Y. A survey of network representation learning methods[J]. Journal of Shandong University of Science and Technology (Natural Science), 2021, 40(1): 117-128.)
[2] ZHANG D, YIN J, ZHU X, et al. Network representation learning: a survey[J]. IEEE Transactions on Big Data, 2020, 6(1): 3-28.
[3] WU Z, PAN S, CHEN F, et al. A comprehensive survey on graph neural networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24.
[4] HOU Y, CHEN H, LI C, et al. A representation learning framework for property graphs[C]// Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2019: 65-73.
[5] AHMED N K, ROSSI R A, LEE J B, et al. Role-based graph embeddings[J]. IEEE Transactions on Knowledge and Data Engineering, 2022, 34(5): 2401-2415.
[6] 劉昱陽,李龍杰,單娜,等. 融合聚集系數的鏈接預測方法[J]. 計算機應用, 2020, 40(1): 28-35.(LIU Y Y, LI L J, SHAN N, et al. Link prediction method fusing clustering coefficients[J]. Journal of Computer Applications, 2020, 40(1): 28-35.)
[7] PEROZZI B, AL-RFOU R, SKIENA S. DeepWalk: online learning of social representations[C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2014: 701-710.
[8] GROVER A, LESKOVEC J. node2vec: scalable feature learning for networks[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 855-864.
[9] CAO S, LU W, XU Q. Deep neural networks for learning graph representations[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2016: 1145-1152.
[10] FAN S, WANG X, SHI C, et al. One2Multi graph autoencoder for multi-view graph clustering[C]// Proceedings of the Web Conference 2020. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2020: 3070-3076.
[11] YANG C, LIU Z, ZHAO D, et al. Network representation learning with rich text information[C]// Proceedings of the 24th International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2015: 2111-2117.
[12] TU W, ZHOU S, LIU X, et al. Deep fusion clustering network[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 9978-9987.
[13] BEHROUZI T, HATZINAKOS D. Graph variational auto-encoder for deriving EEG-based graph embedding[J]. Pattern Recognition, 2022, 121: No.108202.
[14] TANG J, QU M, WANG M, et al. LINE: large-scale information network embedding[C]// Proceedings of the 24th International Conference on World Wide Web. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2015:1067-1077.
[15] CAO S, LU W, XU Q. GraRep: learning graph representations with global structural information[C]// Proceedings of the 24th ACM International Conference on Information and Knowledge Management. New York: ACM, 2015: 891-900.
[16] WANG D, CUI P, ZHU W. Structural deep network embedding[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2016: 1225-1234.
[17] HUANG X, LI J, HU X. Accelerated attributed network embedding[C]// Proceedings of the 2017 SIAM International Conference on Data Mining. Philadelphia, PA: SIAM, 2017:633-641.
[18] ZHU D, CUI P, WANG D, et al. Deep variational network embedding in Wasserstein space[C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM, 2018: 2827-2836.
[19] CEN K, SHEN H, GAO J, et al. ANAE: learning node context representation for attributed network embedding[EB/OL]. (2020-07-06) [2022-07-12]. https://arxiv.org/pdf/1906.08745.pdf.
[20] GUO X, GAO L, LIU X, et al. Improved deep embedded clustering with local structure preservation[C]// Proceedings of the 26th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2017: 1753-1759.
[21] YANG Y. SDCN: a species-disease hybrid convolutional neural network for plant disease recognition[C]// Proceedings of the 2022 International Conference on Artificial Neural Networks, LNCS 13532. Cham: Springer, 2022: 769-780.
[22] LI Y, SWERSKY K, ZEMEL R. Generative moment matching networks[C]// Proceedings of the 32nd International Conference on Machine Learning. New York: JMLR.org, 2015: 1718-1727.
[23] BOUSMALIS K, TRIGEORGIS G, SILBERMAN N, et al. Domain separation networks [C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 343-351.
[24] WANG W, SUN Y, HALGAMUGE S. Improving MMD-GAN training with repulsive loss function[EB/OL] (2019-02-08) [2022-07-12].https://arxiv.org/pdf/1812.09916,pdf.
[25] KINGMA D P, WELLING M. Auto-encoding variational Bayes[EB/OL]. (2014-05-01) [2022-07-12].https://arxiv.org/pdf/1312.6114.pdf.
[26] TZENG E, HOFFMAN J, ZHANG N, et al. Deep domain confusion: maximizing for domain invariance[EB/OL]. (2014-12-10) [2022-07-12].https://arxiv.org/pdf/1412.3474.pdf.
[27] TANG Y, REN F, PEDRYCZ W. Fuzzy C-Means clustering through SSIM and patch for image segmentation[J]. Applied Soft Computing, 2020, 87: No.105928.
[28] 尤坊州,白亮. 關鍵節點選擇的快速圖聚類算法[J]. 計算機科學與探索, 2021, 15(10): 1930-1937.(YOU F Z, BAI L. Fast graph clustering algorithm based on selection of key nodes[J]. Journal of Frontiers of Computer Science and Technology, 2021, 15(10): 1930-1937.)
[29] HU S, ZHANG B, LV H, et al. Improving network representation learning via dynamic random walk, self-attention and vertex attributes-driven Laplacian space optimization[J]. Entropy, 2022, 24(9): No.1213.
[30] 張蕾,錢峰,趙姝,等. 利用變分自編碼器進行網絡表示學習[J]. 計算機科學與探索, 2019, 13(10):1733-1744.(ZHANG L, QIAN F, ZHAO S, et al. Network representation learning via variational auto-encoder[J]. Journal of Frontiers of Computer Science and Technology, 2019, 13(10):1733-1744.)
[31] WANG Y, SONG Z, ZHANG R, et al. An overview of t-SNE optimization algorithms[J]. International Core Journal of Engineering, 2021, 7(2): 422-432.
[32] LI X, KAO B, REN Z, et al. Spectral clustering in heterogeneous information networks[C]// Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2019: 4221-4228.
Network representation learning based on autoencoder with optimized graph structure
FU Kun*, HAO Yuhan, SUN Minglei, LIU Yinghua
(,,300401,)
The aim of Network Representation Learning (NRL) is to learn the potential and low-dimensional representation of network vertices, and the obtained representation is applied for downstream network analysis tasks. The existing NRL algorithms using autoencoder extract information about node attributes insufficiently and are easy to generate information bias, which affects the learning effect. Aiming at these problems, a Network Representation learning model based on Autoencoder with optimized Graph Structure (NR-AGS) was proposed to improve the accuracy by optimizing the graph structure. Firstly, the structure and attribute information were fused to generate the joint transition matrix, thereby forming the high-dimensional representation. Secondly, the low-dimensional embedded representation was learnt by an autoencoder. Finally, the deep embedded clustering algorithm was introduced during learning to form a self-supervision mechanism in the processes of autoencoder training and the category distribution division of nodes. At the same time, the improved Maximum Mean Discrepancy (MMD) algorithm was used to reduce the gap between distribution of the learnt low-dimensional embedded representation and distribution of the original data. Besides, in the proposed model, the reconstruction loss of the autoencoder, the deep embedded clustering loss and the improved MMD loss were used to optimize the network jointly. NR-AGS was applied to the learning of three real datasets, and the obtained low-dimensional representation was used for downstream tasks such as node classification and node clustering. Experimental results show that compared with the deep graph representation model DNGR (Deep Neural networks for Graph Representations), NR-AGS improves the Micro-F1 score by 7.2, 13.5 and 8.2 percentage points at least and respectively on Cora, Citeseer and Wiki datasets. It can be seen that NR-AGS can improve the learning effect of NRL effectively.
Network Representation Learning (NRL); attribute information; autoencoder; deep embedded clustering; Maximum Mean Discrepancy (MMD)
This work is partially supported by National Natural Science Foundation of China (62072154).
FU Kun, born in 1979, Ph. D., associate professor. Her research interests include social network analysis, network representation learning.
HAO Yuhan, born in 1997, M. S. candidate. Her research interests include network representation learning.
SUN Minglei, born in 1992, M. S. candidate. His research interests include network representation learning.
LIU Yinghua, born in 1996, M. S. candidate. His research interests include social network analysis.
1001-9081(2023)10-3054-08
10.11772/j.issn.1001-9081.2022101494
2022?10?12;
2023?02?10;
國家自然科學基金資助項目(62072154)。
富坤(1979—),女,遼寧遼陽人,副教授,博士,主要研究方向:社會網絡分析、網絡表示學習; 郝玉涵(1997—),女,河北張家口人,碩士研究生,主要研究方向:網絡表示學習; 孫明磊(1992—),男,河北承德人,碩士研究生,主要研究方向:網絡表示學習; 劉贏華(1996—),男,河北邯鄲人,碩士研究生,主要研究方向:社會網絡分析。
TP391
A
2023?02?15。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
中華手工(2017年2期)2017-06-06 23:00:31
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
現代企業(2015年9期)2015-02-28 18:56:50
中外會展(2014年4期)2014-11-27 07:46:46
