基于協同訓練與Boosting的協同過濾算法
2023-10-21 08:37:02楊曉菡郝國生張謝華楊子豪
計算機應用 2023年10期
關鍵詞:模型
楊曉菡,郝國生,張謝華,楊子豪
基于協同訓練與Boosting的協同過濾算法
楊曉菡,郝國生,張謝華*,楊子豪
(江蘇師范大學 計算機科學與技術學院,江蘇 徐州 221116)( ? 通信作者電子郵箱6019980030@jsnu.edu.cn)
協同過濾(CF)算法基于物品之間或用戶之間的相似度能實現個性化推薦,然而CF算法普遍存在數據稀疏性的問題。針對用戶?物品評分稀疏問題,為使預測更加準確,提出一種基于協同訓練與Boosting的協同過濾算法(CFCTB)。首先,利用協同訓練將兩種CF集成于一個框架,兩種CF互相添加置信度高的偽標記樣本到對方的訓練集中,并利用Boosting加權訓練數據輔助協同訓練;其次,采用加權集成預測最終的用戶評分,有效避免偽標記樣本所產生的噪聲累加,進一步提高推薦性能。實驗結果表明,在4個公開數據集上,所提算法的準確率優于單模型;在稀疏度最高的CiaoDVD數據集上,與面向推薦系統的全局和局部核(GLocal-K)相比,所提算法的平均絕對誤差(MAE)降低了4.737%;與ECoRec(Ensemble of Co-trained Recommenders)算法相比,所提算法的均方根誤差(RMSE)降低了7.421%。以上結果驗證了所提算法的有效性。
推薦算法;協同過濾;數據稀疏;協同訓練;Boosting
0 引言
面對網絡中的海量信息,推薦系統能夠幫助用戶過濾信息,實現個性化推薦。協同過濾(Collaborative Filtering, CF)是構建個性化推薦系統的關鍵技術,它基于用戶與物品的歷史交互信息(包括顯式的和隱式的)向用戶推薦偏好物品。
在實際應用中,用戶與物品的交互信息矩陣數據稀疏,改善數據稀疏性問題是推薦系統的一個重要內容。改善數據稀疏的方法主要有3種方法:偏好數據填補、基于多源信息的偏好預測和基于分歧的半監督學習。Ren等[1]提出自適應插補屬于第一種方法,該方法結合多種相似性度量方法,如皮爾遜相關系數和余弦相似性。理論上,基于偏好數據填補的CF優于基于鄰域的CF[2]。
利用多源信息的偏好預測改善稀疏問題是第二種方法。基于內容信息和上下文信息,Gong等[3]通過圖卷積網絡學習實體的表示與推薦。Rashed等[4]提出了非線性共嵌入模型GraphRec(Graph-based features Recommender),它通過用戶?項目共現圖的拉普拉斯算子構造通用內部屬性,以優化評分預測任務。利用用戶行為、項目屬性等多源信息,Zhu等[5]提出了一種基于用戶行為軌跡的情感感知移動應用推薦方法。此外,從特定的場景中獲取的知識圖偏好注意力網絡[6]、文本評論[7]和視覺信息[8]等多源數據,也有助于改善數據稀疏。
基于分歧的半監督學習[9]是改善數據稀疏的第三種方法。da Costa等[10]提出了一種基于多推薦器協同訓練方法的集成方案ECoRec(Ensemble of Co-trained Recommenders),該方案驅動多個推薦器評價填補數據,從而提高推薦的準確率。進一步,Nan等[11]提出推薦模型加權混合集成,提高了推薦準確性。Wu等[12]提出了一種利用多模型半監督集成過濾(Semi-Supervised Ensemble Filtering, SSEF)方法,通過分析對已標記樣本的影響,選擇填補樣本。
雖然上述方法有效改善了協同過濾中的數據稀疏問題,但是文獻[10-12]方法在數據層面未通過改變數據集樣本的分布平衡數據集,在算法層面未考慮加權集成迭代過程中的所有模型;而且文獻[10]中協同訓練過程中偽標記樣本的添加會產生噪聲累加,影響模型性能。
針對上述不足,本文提出基于協同訓練與Boosting的協同過濾算法(CF algorithm based on Collaborative Training and Boosting, CFCTB)。該算法屬于第三種方法,它將Boosting與協同訓練相結合,實例化兩個基推薦模型,通過加權訓練數據改進協同訓練方法。首先,兩個模型在初始權重相同的同一個訓練集上訓練,對預測誤差小的訓練樣本賦予更大的權重,重新采樣。其次,用協同訓練方法將置信度較高的偽標記樣本放到對方模型的訓練數據集中,用新的訓練集重新訓練兩個模型。為了減少噪聲影響,偽標記數據在迭代過程中不會累加,訓練結束則刪除偽標記樣本。最后,集成迭代生成的所有模型,進行精準預測。
本文的主要工作如下:
1)提出改善數據稀疏的算法,使得兩個模型的準確率均有所提升。
2)利用Boosting更新樣本權重,加權集成協同訓練迭代過程中的所有模型。
3)為了避免偽標記數據的噪聲疊加,使用偽標簽作為訓練樣本,在模型迭代過程中不保留至下一輪,避免噪聲疊加。本文算法集成結果優于單模型的準確率,可以應用于多種CF的推薦模型。
1 相關工作
1.1 基于模型的協同過濾
協同過濾推薦算法可分為基于記憶的協同過濾、基于模型的協同過濾和混合協同過濾[13]。本文主要研究基于模型的協同過濾,該算法利用機器學習算法,在數據中找出模式,并將用戶與物品間的評分模式化,其中線性模型和矩陣分解是最常用的兩種方法。
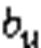

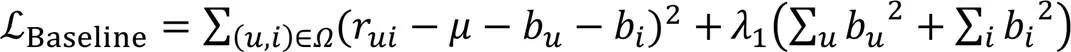
協同過濾中傳統的矩陣分解方法要求矩陣是稠密的。為了避開缺失值的問題,Funk[15]提出只考慮已有評分記錄的隱語義模型的矩陣分解方法。該方法將評分矩陣分解成兩個矩陣,即
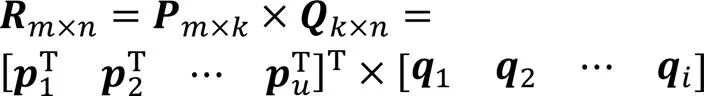
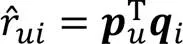
SVD(Singular Value Decomposition for recommender systems)[16]是在此基礎上的改進版之一,它在隱語義模型的矩陣分解方法上引入了偏置項特征。綜上,可以將預測評分看作偏置部分加上用戶對物品的喜好部分。

SVD++(Singular Value Decomposition Plus Plus)[17]在SVD算法的基礎上改進,在用戶向量部分引入隱性反饋信息:
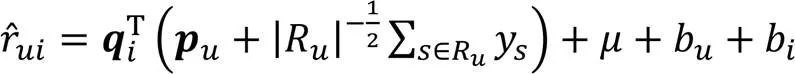
上述這些經典的協同過濾算法需要大量的用戶?物品交互信息,容易遇到數據稀疏問題。本文算法通過互相添加偽標記樣本,降低數據稀疏度,提高了協同過濾算法的有效性。
1.2 半監督學習
在半監督學習中,協同訓練是一種基于分歧的雙視圖半監督算法[8]。與常見的單視角相比,它關注用兩個獨立且冗余的數據視圖同時訓練兩個模型,從這些冗余的視角可以訓練多個具有差異性的弱學習器。HRSM(Hybrid Recommendation approach based on deep Sentiment analysis of user reviews and Multi-view collaborative fusion)[18]基于協同訓練融合多個推薦視圖,實現了對稀疏的用戶評分矩陣的循環填充和修正,顯著提高預測精度;但是該算法提取、處理和加工評論文本和物品的內容描述信息的計算成本較高,影響算法效率。Matuszyk等[19]提出基于流的半監督推薦框架,利用協同訓練方法,使用大量的未標記信息提高推薦質量;但是該框架依賴于矩陣分解算法,不適用于各種不同的推薦算法。
本文算法不需要其他額外信息,僅使用評分數據。此外,本文算法允許在協同訓練中使用不同的推薦算法,從而消除了上述限制。
1.3 Boosting
作為Boosting的代表,Adaboost(Adaptive Boost)[20]的基本原理是結合多個弱分類器,成為一個強分類器。在推薦系統中,運用Boosting的研究工作較少。Schclar等[21]介紹了一種用于推薦任務的AdaBoost同質集成算法,它采用了一種簡單有效的回歸算法,通過求解誤差代價函數的梯度最小化預測誤差。Bar等[22]提出將幾種集成方法改進后用于協同過濾算法,采用幾種單一模型生成協同過濾模型的同質集合。
本文算法與上述方法的區別是本文算法基于異質集成,結合了不同推薦模型的預測結果,而且通過協同訓練方法在不同預測模型之間進行信息交互,使得預測結果更加準確。
2 本文算法
本文提出基于協同訓練與Boosting的協同過濾算法(CFCTB)的總體框架如圖1所示。首先,初始化基預測模型,通過不同的CF從標記的樣本中獨立生成兩個預測模型;其次,兩個預測模型在不同的訓練集上訓練,分別預測未標記數據集;再次,將新標記的數據集放到對方模型的訓練數據集中,更新訓練樣本權重,用新的訓練集重新訓練兩個模型;最后,集成迭代過程生成的所有模型,得到最終的預測結果。

圖1 CFCTB的總體框架
2.1 訓練預測模型
首先,初始化訓練數據的權值分布:
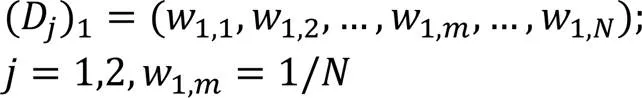
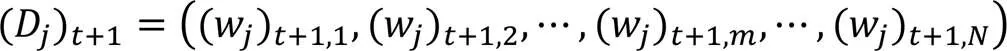
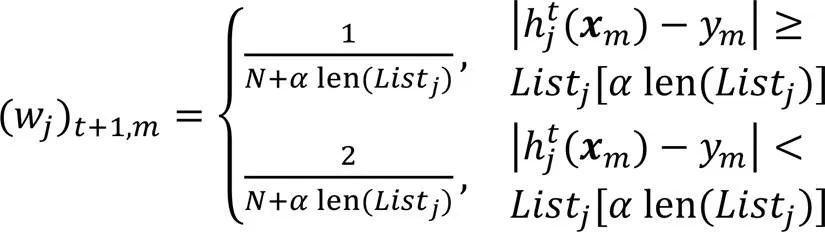
2.2 協同訓練
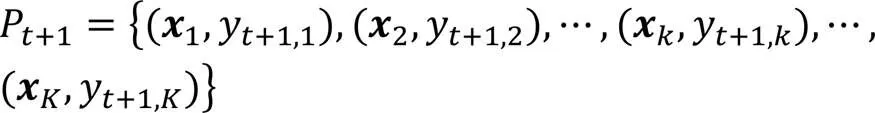
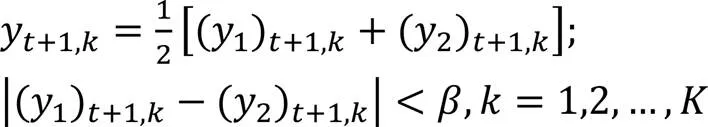
雖然加入大量偽標記樣本改善了數據稀疏性,但是可能引入了噪聲和偏差。本文在次迭代后,將訓練集重置為初始狀態,以減少偽標記樣本產生的噪聲影響,更新集合如下:
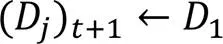

2.3 加權集成

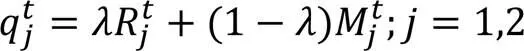
因為RMSE和MAE這兩個指標與準確率成反比,故兩個預測模型的加權集成公式如下:
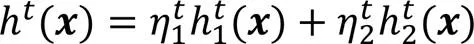

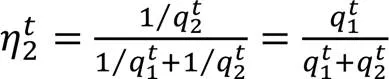
2.4 算法框架
本文算法(CFCTB)的偽代碼如算法1所示。
算法1 CFCTB。
forfrom 1 to
for=1,2
else
退出迭代
3 實驗與結果分析
3.1 數據集
為了評估本文算法的性能,使用4個常用的數據集:ML-100K[24]、ml-latest-small[25]、Filmtrust[26]和CiaoDVD[27]。表1給出了以上數據集的統計信息,評分稀疏度范圍為93.695%~99.974%,涵蓋了評級預測任務的廣泛數據稀疏水平。
評分稀疏度的公式如下:
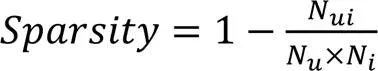
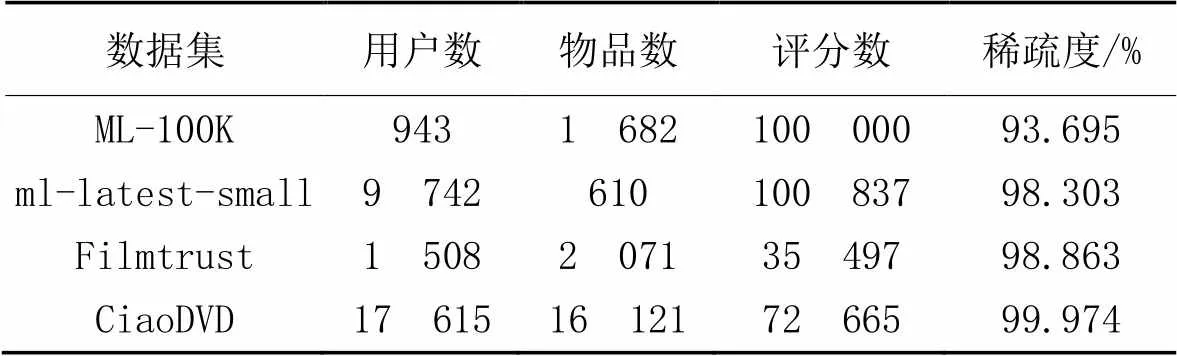
表1 數據集評分數據統計
3.2 評價指標
個性化推薦系統的主要任務是預測評分并依據評分推薦,對于預測評分準確性的評價,一般采用測試集上的均方根誤差(RMSE)和平均絕對誤差(MAE)[23],計算公式為:
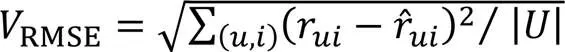

3.3 實驗設置
評分數據隨機分為訓練集(90%)和測試集(10%)。基推薦模型選擇線性模型近鄰(-Nearest Neighbor,NN)Baseline(NNBaseline)[28]和矩陣分解模型SVD[16]、SVD++[17],評測由這3種基推薦模型兩兩組成的3種組合算法,實驗結果用不同的隨機種子重復5次,并記錄測試集的RMSE和MAE的均值和標準差。
3.4 對比實驗
將CFCTB與7個協同過濾算法進行比較,包括SVD[16]、SVD++[17]、NNBaseline[28]、GraphRec[4]、ECoRec[10]、SSEF[12]和面向推薦系統的全局和局部核(Global and Local Kernels for recommender systems, GLocal-K)[29]。相應的關于RMSE和MAE的定量結果列于表2~5。
從表2~4可以看出,CFCTB在兩種指標上的標準差集中在0.002 6~0.010 4,不同隨機種子的結果較穩定。在4個數據集上的實驗結果可以發現,CFCTB在所有數據集上的性能均優于原推薦算法,尤其在MAE上優勢更加明顯,驗證了將多個協同過濾模型組合用于推薦任務的有效性。
從表2~4中可以看出,SVD與SVD++組合的推薦性能最優,原因可能是CFCTB利用式(10)重點將置信度高的樣本放入對方的訓練集,因此需要兩個基預測模型之間的預測結果差異較大;同時利用式(15)加權集成兩個基預測模型,最終預測結果受基預測模型本身在2個指標上的表現的影響。在稀疏度最高的CiaoDVD數據集上,相較于SVD++,CFCTB在RMSE和MAE指標上降低了1.626%、2.494%,這可能得益于迭代過程沒有噪聲疊加,表明CFCTB利用偽標記樣本,降低噪聲影響,有助于減小預測誤差。綜上,本文使用SVD與SVD++組合模型協同訓練。

表2 SVD與SVD++組合下3種推薦算法的性能比較
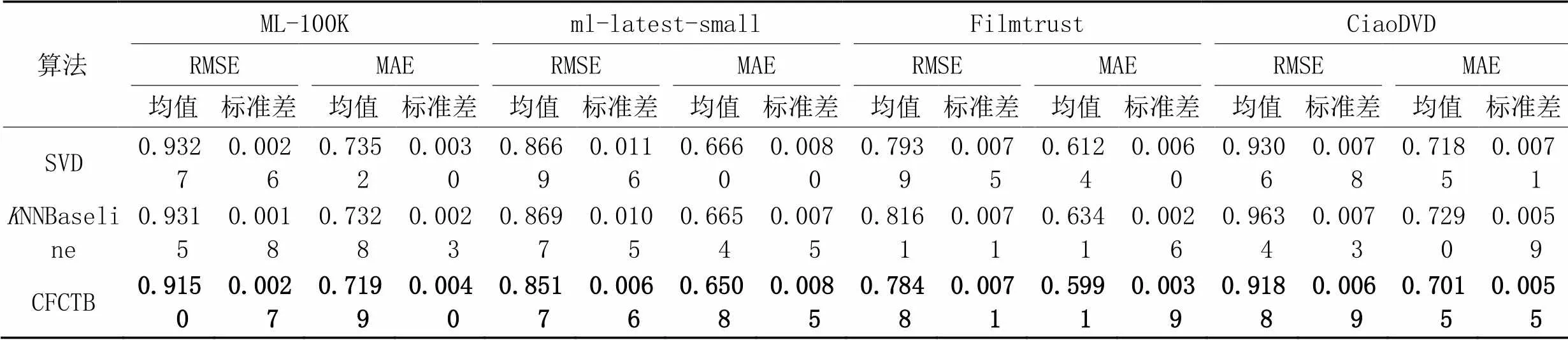
表3 SVD與KNNBaseline組合下3種推薦算法的性能比較
在表5中,將CFCTB與4種協同過濾算法進行比較,實驗結果總體穩定,尤其在CiaoDVD數據集上CFCTB表現顯著。在RMSE指標上,CFCTB在2個數據集上表現最優,在1個數據集上表現次優,在CiaoDVD上優勢最明顯,比次優的對比算法降低1.384%,與ECoRec相比,降低了7.421%;可能的原因是CFCTB通過兩個模型在無標記樣本上的預測的差值選擇可靠的偽標記樣本,并應用了Boosting加權訓練數據,有助于發現更多的數據分布特征,從而充分體現結合協同訓練與Boosting的效果。在MAE指標上,CFCTB在3個數據集上都得到了最優結果。在CiaoDVD數據集上,相較于GLocal-K,降低了4.737%,相較于半監督算法ECoRec和SSEF,本文算法通過式(12)在改善了數稀疏的情況下沒有造成噪聲疊加,同時利用對方預測模型的訓練集作為驗證集判斷模型是否退化,使算法適時收斂。
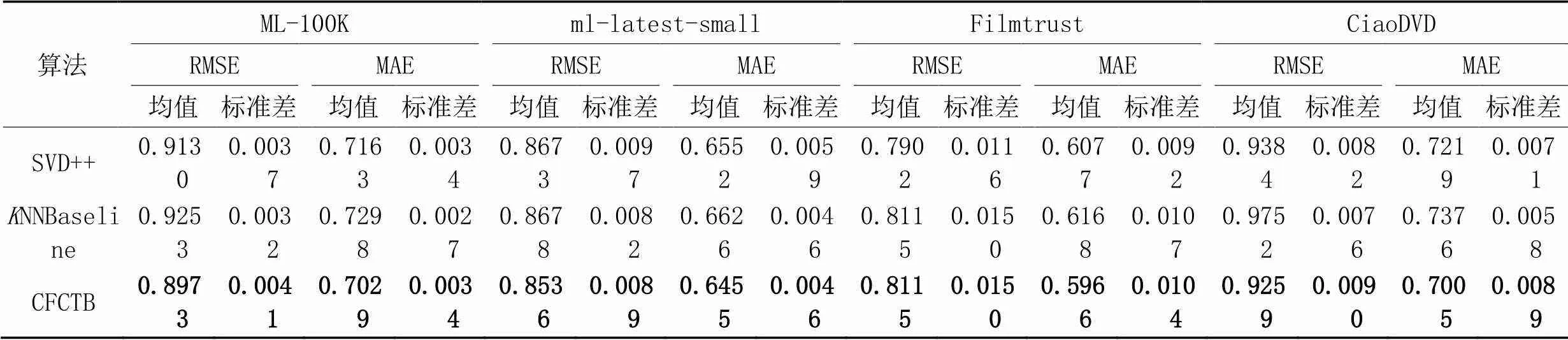
表4 SVD++與KNNBaseline組合下3種推薦算法的性能比較

表5 本文算法與半監督集成的推薦算法的性能比較
3.5 參數調節實驗
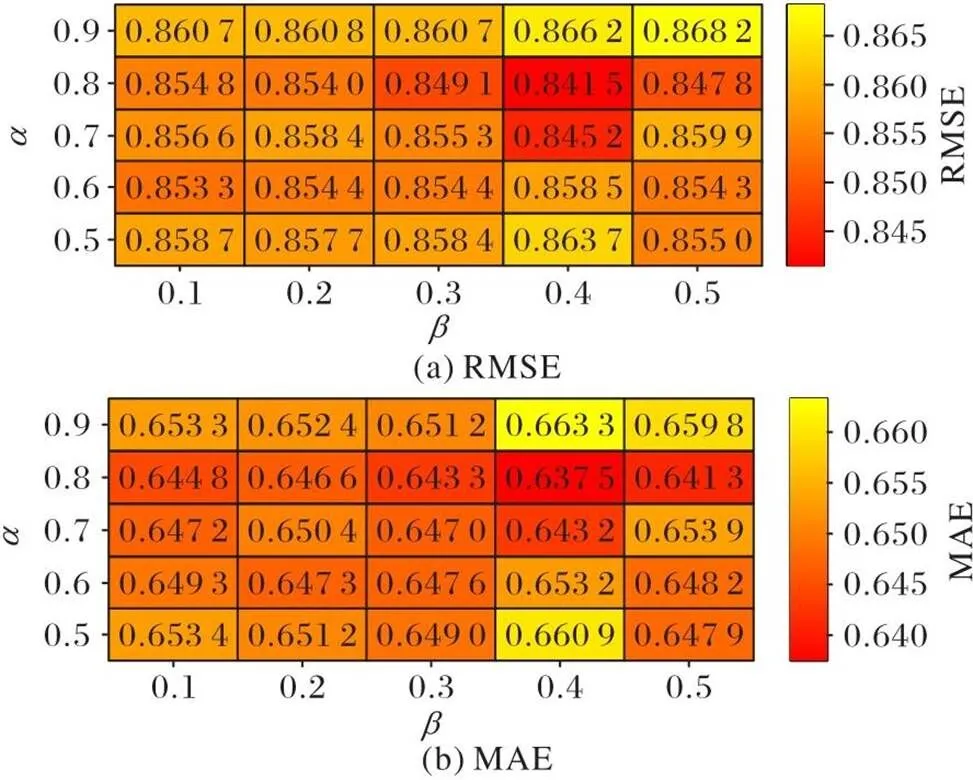
圖2 ml-latest-small上的超參數實驗結果

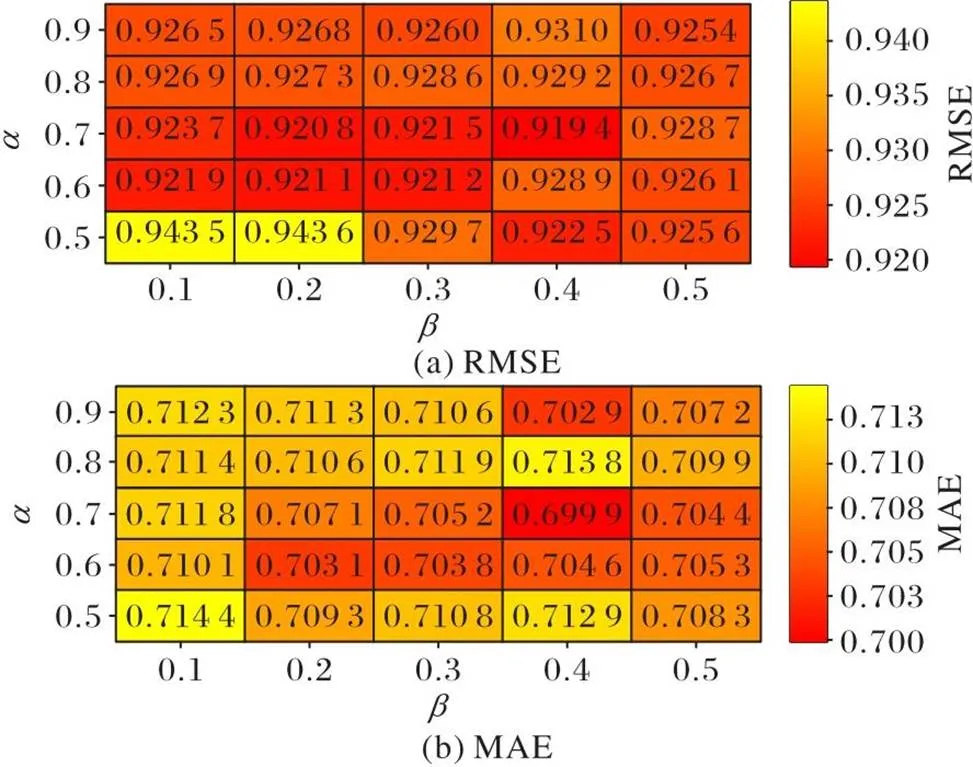
圖3 CiaoDVD上的超參數實驗結果
4 結語
本文提出了基于協同訓練與Boosting的協同過濾算法,該算法將兩種流行的協同過濾推薦算法集成在一個協同過濾框架中提高推薦算法性能。將本文算法與多種協同過濾的推薦模型對比,實驗結果表明,本文算法優于單模型的準確率;與其他包括半監督的、集成的協同過濾的方法相比實驗結果也驗證了本文算法的有效性。未來可以引入更多的模型,從集成學習的角度,更多的模型意味著更好的穩定性,也意味著需要耗費更多的額外訓練以換取更好的性能。此外,本文算法可以繼續集成基于輔助信息的推薦方法,以期獲得更好的推薦效果。
[1] REN Y, LI G, ZHANG J, et al. The efficient imputation method for neighborhood-based collaborative filtering[C]// Proceedings of the 21st ACM International Conference on Information and Knowledge Management. New York: ACM, 2012: 684-693.
[2] BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[C]// Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence. San Francisco: Morgan Kaufmann Publishers Inc., 1998: 43-52.
[3] GONG J, WANG S, WANG J, et al. Attentional graph convolutional networks for knowledge concept recommendation in MOOCs in a heterogeneous view[C]// Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. New York: ACM, 2020: 79-88.
[4] RASHED A, GRABOCKA J, SCHMIDT-THIEME L. Attribute-aware non-linear co-embeddings of graph features[C]// Proceedings of the 13th ACM Conference on Recommender Systems. New York: ACM, 2019: 314-321.
[5] ZHU K, XIAO Y, ZHENG W, et al. A novel context-aware mobile application recommendation approach based on users behavior trajectories[J]. IEEE Access, 2021, 9: 1362-1375.
[6] 顧軍華,樊帥,李寧寧,等. 基于知識圖偏好注意力網絡的長短期推薦模型及其更新方法[J]. 計算機應用, 2022, 42(4): 1079-1086.(GU J H, FAN S, LI N N, et al. Long- and short-term recommendation model and updating method based on knowledge graph preference attention network[J]. Journal of Computer Applications, 2022, 42(4): 1079-1086.)
[7] BEN KHARRAT F, ELKHLEIFI A, FAIZ R. Recommendation system based contextual analysis of Facebook comment[C]// Proceedings of the IEEE/ACS 13th International Conference of Computer Systems and Applications. Piscataway: IEEE, 2016: 1-6.
[8] LIN Y R, SU W H, LIN C H, et al. Clothing recommendation system based on visual information analytics[C]// Proceedings of the 2019 International Automatic Control Conference. Piscataway: IEEE, 2019: 1-6.
[9] ENGELEN J E van, HOOS H H. A survey on semi-supervised learning[J]. Machine Learning, 2020, 109(2): 373-440.
[10] DA COSTA A F, MANZATO M G, CAMPELLO R J G B. Boosting collaborative filtering with an ensemble of co-trained recommenders[J]. Expert Systems with Applications, 2019, 115: 427-441.
[11] NAN Z H, ZHAO F. Research on semi-supervised recommendation algorithm based on hybrid model[C]// Proceedings of the 2nd International Conference on Machine Learning, Big Data and Business Intelligence. Piscataway: IEEE, 2020: 344-348.
[12] WU J, SANG X, CUI W. Semi-supervised collaborative filtering ensemble[J]. World Wide Web, 2021, 24(2): 657-673.
[13] SU X, KHOSHGOFTAAR T M. A survey of collaborative filtering techniques[J]. Advances in Artificial Intelligence, 2009, 2009: No.421425.
[14] KOREN Y. Factor in the neighbors: scalable and accurate collaborative filtering[J]. ACM Transactions on Knowledge Discovery from Data, 2010, 4(1): No.1.
[15] FUNK S. Netflix update: try this at home [EB/OL]. (2006-12-11) [2022-09-01].https://sifter.org/simon/journal/20061211.html.
[16] KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30-37.
[17] SHI W, WANG L, QIN J. User embedding for rating prediction in SVD++-based collaborative filtering[J]. Symmetry, 2020, 12(1): No.121.
[18] 張宜浩,朱小飛,徐傳運,等. 基于用戶評論的深度情感分析和多視圖協同融合的混合推薦方法[J]. 計算機學報, 2019, 42(6): 1318-1333.(ZHANG Y H, ZHU X F, XU C Y, et al. Hybrid recommendation approach based on deep sentiment analysis of user reviews and multi-view collaborative fusion[J]. Chinese Journal of Computers, 2019, 42(6): 1318-1333.)
[19] MATUSZYK P, SPILIOPOULOU M. Stream-based semi-supervised learning for recommender systems[J]. Machine Learning, 2017, 106(6): 771-798.
[20] FREUND Y, SCHAPIRE R E. A decision-theoretic generalization of on-line learning and an application to boosting[J]. Journal of Computer and System Sciences, 1997, 55(1): 119-139.
[21] SCHCLAR A, TSIKINOVSKY A, ROKACH L, et al. Ensemble methods for improving the performance of neighborhood-based collaborative filtering[C]// Proceedings of the 3rd ACM Conference on Recommender Systems. New York: ACM, 2009: 261-264.
[22] BAR A, ROKACH L, SHANI G, et al. Improving simple collaborative filtering models using ensemble methods[C]// Proceedings of the 2013 International Workshop on Multiple Classifier Systems, LNCS 7872. Berlin: Springer, 2013: 1-12.
[23] HERLOCKER J L, KONSTAN J A, TERVEEN L G, et al. Evaluating collaborative filtering recommender systems[J]. ACM Transactions on Information Systems, 2004, 22(1): 5-53.
[24] HARPER F M, KONSTAN J A. The MovieLens datasets: history and context[J]. ACM Transactions on Interactive Intelligent Systems, 2015, 5(4): No.19.
[25] AHN H J. A new similarity measure for collaborative filtering to alleviate the new user cold-starting problem[J]. Information Sciences, 2008, 178(1): 37-51.
[26] LIU H, HU Z, MIAN A, et al. A new user similarity model to improve the accuracy of collaborative filtering[J]. Knowledge-Based Systems, 2014, 56: 156-166.
[27] HIMABINDU T V R, PADMANABHAN V, PUJARI A K. Conformal matrix factorization based recommender system[J]. Information Sciences, 2018, 467: 685-707.
[28] 楊凱欣,李雅瑋. 基于協同過濾算法的移動智能學習平臺的開發與設計[J]. 軟件工程與應用, 2019, 8(3): 104-114.(YANG K X, LI Y W. Development and design of mobile intelligent learning platform on collaborative filtering[J]. Software Engineering and Applications, 2019, 8(3): 104-114.)
[29] HAN S C, LIM T, LONG S, et al. GLocal-K: global and local kernels for recommender systems[C]// Proceedings of the 30th ACM International Conference on Information and Knowledge Management. New York: ACM, 2021: 3063-3067.
Collaborative filtering algorithm based on collaborative training and Boosting
YANG Xiaohan, HAO Guosheng, ZHANG Xiehua*, YANG Zihao
(,,221116,)
Collaborative Filtering (CF) algorithm can realize personalized recommendation on the basis of the similarity between items or users. However, data sparsity has always been one of the challenges faced by CF algorithm. In order to improve the prediction accuracy, a CF algorithm based on Collaborative Training and Boosting (CFCTB) was proposed to solve the problem of sparse user-item scores. First, two CFs were integrated into a framework by using collaborative training, pseudo-labeled samples with high confidence were added to each other’s training set by the two CFs, and Boosting weighted training data were used to assist the collaborative training. Then, the weighted integration was used to predict the final user scores, and the accumulation of noise generated by pseudo-labeled samples was avoided effectively, thereby further improving the recommendation performance. Experimental results show that the accuracy of the proposed algorithm is better than that of the single models on four open datasets. On CiaoDVD dataset with the highest sparsity, compared with Global and Local Kernels for recommender systems (GLocal-K), the proposed algorithm has the Mean Absolute Error (MAE) reduced by 4.737%. Compared with ECoRec (Ensemble of Co-trained Recommenders) algorithm, the proposed algorithm has the Root Mean Squared Error (RMSE) decreased by 7.421%. The above rasults verify the effectiveness of the proposed algorithm.
recommendation algorithm; Collaborative Filtering (CF); data sparsity; collaborative training; Boosting
This work is partially supported by National Natural Science Foundation of China (62277030), Postgraduate Scientific Research and Practical Innovation Program of Jiangsu Normal University (2022XKT1536).
1001-9081(2023)10-3136-06
10.11772/j.issn.1001-9081.2022101489
2022?10?11;
2023?01?13;
國家自然科學基金資助項目(62277030);江蘇師范大學研究生科研與實踐創新計劃項目(2022XKT1536)。
楊曉菡(1995—),女,江蘇徐州人,碩士研究生,主要研究方向:機器學習、推薦系統; 郝國生(1972—),男,河北萬全人,教授,博士,主要研究方向:機器學習、進化計算、個性化學習; 張謝華(1977—),女,安徽宿松人,副教授,博士,主要研究方向:機器學習、運動目標檢測與跟蹤; 楊子豪(1998—),男,陜西咸陽人,碩士研究生,主要研究方向:機器學習、計算機視覺。
TP181
A
2023?01?16。
YANG Xiaohan, born in 1995, M. S. candidate. Her research interests include machine learning, recommender system.
HAO Guosheng, born in 1972, Ph. D., professor. His research interests include machine learning, evolutionary computation, personalized learning.
ZHANG Xiehua, born in 1977, Ph. D., associate professor. Her research interests include machine learning, moving target detection and tracking.
YANG Zihao, born in 1998, M. S. candidate. His research interests include machine learning, computer vision.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
