基于單模態的多尺度特征融合人體行為識別方法
2023-10-21 07:40:26劉鎖蘭田珍珍王洪元林龍王炎
計算機應用 2023年10期
劉鎖蘭,田珍珍,王洪元*,林龍,王炎
基于單模態的多尺度特征融合人體行為識別方法
劉鎖蘭1,2,田珍珍1,王洪元1*,林龍1,王炎1
(1.常州大學 計算機與人工智能學院 阿里云大數據學院 軟件學院,江蘇 常州 213164; 2.江蘇省社會安全圖像與視頻理解重點實驗室(南京理工大學),南京 210094)( ? 通信作者電子郵箱 hywang@cczu.edu.cn)
針對人體行為識別任務中未能充分挖掘超距關節點之間潛在關聯的問題,以及使用多模態數據帶來的高昂訓練成本的問題,提出一種單模態條件下的多尺度特征融合人體行為識別方法。首先,將人體的原始骨架圖進行全局特征關聯,并利用粗尺度的全局特征捕獲遠距離關節點間的聯系;其次,對全局特征關聯圖進行局部劃分以得到融合了全局特征的互補子圖(CSGF),利用細尺度特征建立強關聯,并形成多尺度特征的互補;最后,將CSGF輸入時空圖卷積模塊中提取特征,并聚合提取后的結果以輸出最終的分類結果。實驗結果表明,在行為識別權威數據集NTU RGB+D60上,所提方法的準確率分別為89.0%(X-sub)和94.2%(X-view);在具有挑戰性的大規模數據集NTU RGB+D120上,所提方法的準確率分別為83.3%(X-sub)和85.0%(X-setup),與單模態下的ST-TR(Spatial-Temporal TRansformer)相比,分別提升1.4和0.9個百分點,與輕量級SGN(Semantics-Guided Network)相比,分別提升4.1和3.5個百分點。可見,所提方法能夠充分挖掘多尺度特征的協同互補性,并有效提高單模態條件下模型的識別準確率和訓練效率。
人體行為識別;骨架關節點;圖卷積網絡;單模態;多尺度;特征融合
0 引言
隨著人工智能的興起和智能化時代的不斷推進,人體行為識別技術在智能安防、自動駕駛、異常行為監測、虛擬現實等方面有許多實際的應用。行為識別的本質是分類識別,即從視頻、RGB圖像或骨架序列中提取一系列人體活動時的動作信息,提取特征以識別它的分類類別。其中,骨架數據排除了視頻和RGB圖像所帶來的復雜背景、光照條件、不同視角和設備運動等的噪聲干擾,具有良好的抗干擾性;此外,深度采集設備的應用和先進的人體姿態估計算法使得獲取骨架數據變得更容易[1],因此基于骨架數據的行為識別技術得到了快速的發展。
基于傳統深度學習的方法將骨架手動構造為關節坐標向量序列或偽圖像,并將它輸入遞歸神經網絡(Recurrent Neural Network, RNN)[2]或卷積神經網絡(Convolutional Neural Network, CNN)[3]中建模[4]。然而,RNN和CNN只適用于處理具有一定順序的規則數據,忽略了人體關節節點之間的自然連接特征和人體動作之間的時空依賴關系,因此對人體行為特征的提取具有局限性。在現實生活中規則的結構占比較少,較多為具有復雜連接關系的不規則結構的拓撲圖,如人體骨骼結構、知識圖譜、社交網絡和貿易網絡等。骨架本質上是非歐幾里得結構的數據,在空間中表示為拓撲圖的形式,把關節節點視為圖的頂點,關節之間的自然連接視為圖的邊,圖卷積網絡(Graph Convolution Network,GCN)為此類拓撲圖問題提供了較好的解決方案。Yan等[5]提出了ST-GCN(Spatial-Temporal Graph Convolutional Network),該模型是GCN在人體骨架行為識別領域的首次應用。使用圖卷積方法構造人體骨架拓撲圖,模擬人體關節之間的自然連接,分別從時域和空域兩個維度提取特征,從而可以更好地挖掘骨架運動的特征信息。但是ST-GCN仍然存在許多不足:1)手工定義的拓撲圖結構忽略了非自然連接的關節之間的動態關聯,如跑步和行走對于手腳之間的協調運動很重要,在物理空間中不直接連接的手臂與腳有著非常強的關聯關系;2)分區策略關注身體部分之間的強關聯,注重局部的差異性;3)GCN通過卷積操作建模局部關系,使得ST-GCN對遠距離的關節點之間潛在關系的挖掘能力較弱。
針對上述問題,本文提出一種基于單模態的多尺度特征融合的人體行為識別方法。對原始人體骨架圖的每個關節點建立全連接,生成全局特征關聯圖,即為全局特征;根據人體固定物理結構將全局特征關聯圖劃分成若干子圖,得到互補子圖(Complementary Subgraphs with Global Features, CSGF),即為局部特征。子圖隱式地包含全局特征,同時顯式地包含局部特征,可以從不同尺度的特征充分挖掘骨架空間運動信息,全面且敏銳地捕獲相似動作的辨別性特征,提高行為識別的準確率。實驗結果表明,在使用單模態數據的條件下,本文方法取得了不錯的識別效果。
1 相關工作
1.1 圖卷積網絡
隨著深度學習方法的不斷演變和性能的不斷提高,行為識別得到了快速的發展。對于基于深度學習方法的行為識別模型,最初人們使用RNN將骨架數據表示為具有預定義遍歷規則的序列數據,并將它輸入基于RNN的模型[6],如長短時記憶(Long Short-Term Memory, LSTM)和門控循環單元(Gated Recurrent Unit, GRU)。但是由于RNN方法本身的局限性,只能獲取相鄰幾幀內人體動作的短期時間上下文關系,未考慮空間方面人體骨架的連接關系,行為識別表達十分有限。CNN的出現彌補了RNN對空間信息表達的不足,在處理歐幾里得數據(如圖像)方面取得了顯著的成果[7]。但是骨架數據的本質并不是歐幾里得數據,而是具有圖形拓撲結構的非歐幾里得數據。受GCN啟發,人們開始廣泛研究基于GCN方法的行為識別模型。
主流的GCN分為兩大類:光譜域GCN[8-9]和空間域GCN[10-11]。光譜域GCN利用于圖傅里葉變換在光譜域上執行圖卷積操作,由于此方法使用了圖拉普拉斯特征矩陣的特征值和特征向量,即對固定的鄰接矩陣使用特征分解操作,使得它只適用于特定結構的圖并且計算效率和圖的擴展都受到了限制。此方法的經典之作為Kipf等[12]提出的半監督分類的譜GCN。與光譜域GCN相比,空間域GCN處理不同鄰域中的節點的特征信息,更新每個節點的特征向量,再聚合自身和相鄰節點的特征,最后使用激活函數將合并的特征進行激活變換。本文采用空間域GCN的方法。GCN首先作為譜卷積的一階近似被引入[13],之后陸續出現了許多以此為基線的各種模型。ST-GCN描述了原始人體骨架結構,并首次將圖卷積運用于行為識別領域,構造了時空圖卷積模型。Cheng等[14]使用Shift算子替代普通卷積算子,提出了時空移位圖卷積模型Shift-GCN(Shift Graph Convolutional Network)。Song等[15]提出了RA-GCN(Richly Activated Graph Convolutional Network),將網絡設計成多流結構,旨在學習運動豐富的鑒別特征,最后使用Softmax激活函數將多分支聚合。Cho等[16]提出了一種自注意力網絡(Self-Attention Network, SAN),在時間域每個分片中結構化嵌入自注意力以建模長期語義信息,提升識別性能。
ST-GCN將時空圖卷積定義為:

式(1)可以用鄰接矩陣表示為:
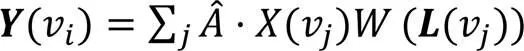
1.2 特征融合
在行為識別領域,基于單一特征訓練的網絡模型的性能有限,這是因為網絡挖掘單一特征的辨別性差異的能力有限。當兩個動作的區別在某種特征敏感特性上差異較小時,輸出的分類結果就可能產生偏差,導致分類準確率降低。
通常這類類內方差較小的問題的解決思路是使用特征融合的方法,提取不同尺度的特征,實現特征的互補,彌補單一特征對人體行為動作表達的不足。粗尺度特征用于度量語義相似度,具有較大的感受野,但會丟失事物部分與整體的關系;細尺度特征用于度量細粒度相似度[17],具有較小的感受野,能夠表征部分和整體的關系,但是會產生語義歧義和噪聲干擾。融合這兩種特征可以實現特征的優勢互補,提升模型的性能。
特征融合方法一般分為三類,分別是基于貝葉斯決策理論的算法、基于稀疏表示理論的算法和基于深度學習理論的算法。隨著深度神經網絡的快速發展,基于深度學習理論的特征融合算法逐漸成為主流,它的核心思想是在深度卷積神經網絡中加入特征融合過程,改進網絡模型[18]。ST-GCN將人體動作序列中的骨架關節點坐標信息流抽象為空域和時域兩個維度,在GCN中分別提取空域特征和時域特征進行特征融合,從而更全面地提升模型的識別準確率;2S-AGCN(two-Stream Adaptive Graph Convolutional Network)[19]在關節流[5]的基礎上增加了骨骼流,并將雙流的原始數據送入自適應圖卷積網絡中形成高層次的特征表達,最后在決策層進行特征融合。鑒于深度學習理論的蓬勃發展,本文亦采用基于深度學習理論的特征融合方法。
2 本文方法
本文方法的整體流程如圖1所示,首先,將人體的原始骨架圖進行全局關聯,得到具有全局關聯信息的特征圖;其次,在全局特征關聯圖的基礎上,根據人體行為特點和骨架的自然連接關系進行局部劃分;再次,將劃分后的子圖分別輸入空間圖卷積模塊中進行特征提取,聚合提取后的結果;最后,送入時間圖卷積模塊進行卷積,輸出最終的分類結果。

圖1 本文方法的整體流程
2.1 特征融合
2.1.1全局特征關聯圖
針對空間上超距的關節點間關聯性較弱的問題,本文設計了全局特征關聯圖以關聯人體中的所有關節點,即把感受野擴大到整個人體骨架圖,建立全局域的關節相關性,如圖2(a)所示。
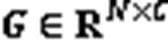
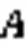
同時,人體行為可以被表述為一系列關節鉸鏈的復雜聯動系統。為了挖掘人體骨架各關節點在不同行為中的貢獻度,設置了可學習的掩碼,可以自適應地調整各關節點的權重,數學定義為:
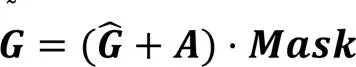
其中:表示全局特征關聯圖;的數學定義為+1,表示可學習的掩碼。
2.1.2局部子圖
全局特征關聯圖可以從宏觀上識別人體行為,但是對局部細節感知較弱,如對于相似動作的識別,全局的關注信息不能很好地捕獲它們之間的差異。針對這個問題,本文設計了局部子圖以捕獲相似動作的差異性,同時建立人體物理連接的強相關性。
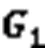
基于生活經驗可知,每個身體部分的重要性是不同的,而且人體行為動作具有協調對稱性。為了探索人體協調對稱的有效性,本文將頭頸和軀干合并,將左右臂合并,將左右腿合并,此時整個人體骨架圖被視為3個部分,表示為;為了探索頭頸和軀干的有效性,本文將左右手臂和左右腿分別視為1個部分,將頭頸和軀干分別視為1個部分,此時整體人體骨架圖被視為4個部分,表示為;為探索人體左側和右側單側的有效性,本文將頭頸和軀干合并為1個部分,將左手、右手、左腿、右腿分別視為1個部分,此時整個人體骨架圖被視為5個部分,表示為5subgraph:;為了探索每個身體部分的有效性,本文將頭頸、左臂、軀干、右臂、左腿、右腿分別視為1個部分,此時整個人體骨架圖被視為6個部分,表示為6subgraph:。
2.1.3特征融合模塊
人體行為動作通常與骨架關節的相互作用和組合有關,如走路與跑步需要四肢關節與骨骼的協調聯動以執行動作,在空間結構上并不直接相連的關節與肢體具有很強的動作關聯性;因此在關注局部肢體運動信息的同時,全局特征的關聯性也至關重要。據此,本文提出全局與局部特征融合策略,以提取不同尺度的空間特征。粗尺度的全局特征建立全局域的關節相關性,關注全局特征信息,在空間上將感受野擴大到整個人體骨架圖,挖掘遠距離關節點間的潛在關聯;細尺度的局部特征建立各肢體之間的運動相關性,關注局部特征信息,在空間上將感受野縮放至肢體部分,挖掘各肢體部分對人體行為的重要性,有效融合全局與局部特征,以實現特征的互補。與傳統特征融合策略相比,本文并不是將全局與局部特征進行簡單的連接或者相加操作,而是在全局特征關聯圖上挖掘局部特征信息,具體做法是:基于全局特征關聯圖劃分子圖,劃分方案見2.1.2節,根據物理上肢體與軀干的連接關系,將全局特征關聯圖劃分為6個部分子圖,由此得到的子圖被定義為融合了全局特征的互補子圖(CSGF)。該互補子圖隱式地融合了全局特征信息,具有低層次的關節語義信息;同時顯式地融合了局部特征信息,具有高層次的肢體語義信息。因此,本文通過提取不同尺度的空間特征,挖掘粗尺度的全局特征和細尺度的局部特征之間的互補屬性,從多尺度特征層次提高行為識別對相似動作的判別能力,提升模型的性能。
由式(3)得到全局特征關聯圖,在此基礎上根據2.1.2節的子圖劃分方案,得到融合了全局特征的互補子圖集合,形式上可以表示為:
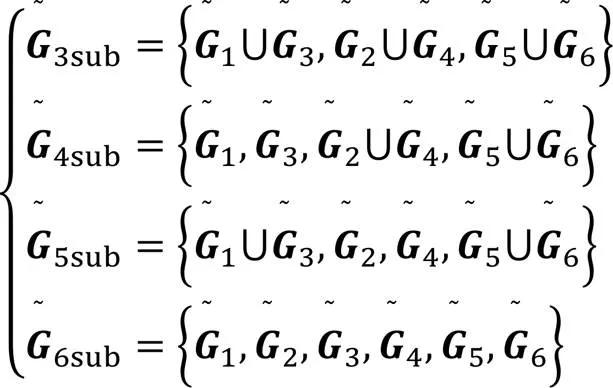
其中“~”代表全局信息。
2.2 時空圖卷積模塊結構
上述特征融合完成之后,將融合后的互補子圖輸入時空圖卷積模塊中訓練。本文的時空圖卷積的主干網絡來自ST-GCN,由9個時空圖卷積模塊組成,每個模塊如圖4所示,由空間子圖卷積和時間圖卷積這兩個模塊級聯構成:空間子圖卷積聚合提取的空間特征,再輸入時間卷積中提取時間特征。9個時空圖卷積模塊的輸出通道數分別為64、64、64、128、128、128、256、256、256,其中,在第4個和第7個模塊時間卷積之后設置下采樣,過濾貢獻度小或者冗余特征,保留重要的特征信息。最后將256維的特征向量送入Softmax激活函數中預測分類,預測的分類與實際標簽相同的概率即為該模型最終的識別準確率。
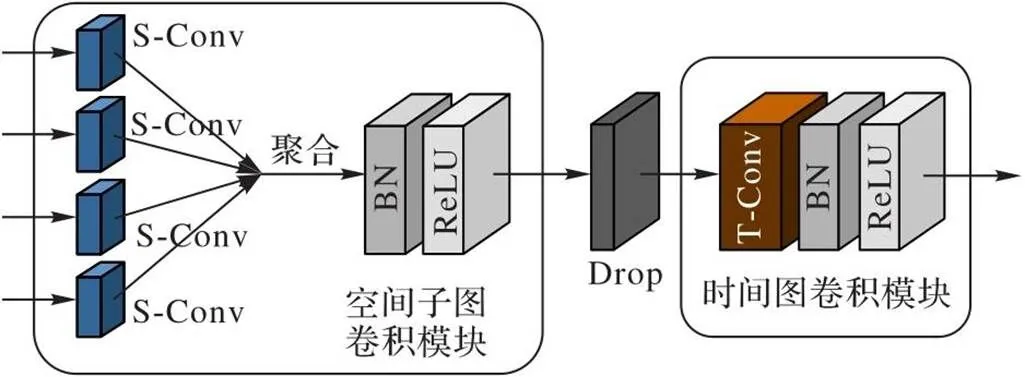
圖4 時空圖卷積模塊
在單幀中,融合了全局特征信息的互補子圖卷積可以將式(2)改寫為:

因此,時空圖卷積定義為:

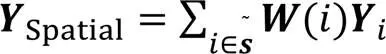
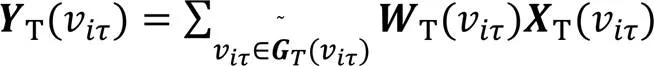
算法1 網絡訓練過程。
1) for=1 to 9 //遍歷9層網絡層
2) for=1 to//特征轉換過程
3) for=0 to
5) end for
6) end for
8) for=1 to
10) 執行式(7) //子圖卷積
11) 執行式(8) //子圖聚合
12) end for
13) 執行式(9) //時間卷積
14) end for
15)重復1)~14),直至網絡收斂
3 實驗與結果分析
3.1 數據集
本文在兩個行為識別領域公開的具有權威性和挑戰性的數據集上進行實驗。
NTU RGB+D60[21]是目前應用最廣泛的大型行為識別RGB數據集,它包含在室內使用3個Microsoft Kinect v2攝像機捕獲的不同視圖的行為動作片段,由不同年齡段的40名志愿者演繹行為動作,包含60個動作類別,共計56 000個動作樣本。其中,最后10個類是2個對象之間的互動,其余都是單人視頻片段,并且每個視頻片段包含最多2個人體骨架,每個人體骨架由25個關節點構成。該數據集的作者提出了兩個評估協議:1)交叉對象(X-sub)協議將其中20個對象的40 320個視頻組成訓練集,其余20個對象的16 560個視頻組成測試集;2)交叉視圖(X-view)協議將攝像機2和攝像機3采集的37 920個視頻作為訓練集,而攝像機1采集的18 960個視頻作為測試集。值得注意的是,實驗中刪除了302個具有缺失或者不完整骨架數據的樣本。
NTU RGB+D120[22]是NTU RGB+D60的擴展版,也是目前最大的基于骨架的室內行為識別數據集。該數據集用3個攝像機拍攝不同視角的106名志愿者的行為動作,包含120個動作類別,共計114 480個動作樣本。該數據集作者提出了兩個評估協議:1)交叉對象(X-sub)將對象分成兩組,分別表示訓練集(63 026個視頻)和測試集(50 922個視頻);2)交叉設置(X-setup)根據相機設置ID進行劃分,偶數ID的樣本組成訓練集,奇數ID的樣本組成測試集。同樣地,實驗中刪除了該數據集中532個具有缺失或不完整骨架數據的不良樣本。
3.2 實驗設置
在實驗的過程中,批處理大小(batch size)設置為32,模型迭代次數(epoch)設置為120,初始學習率為0.1,分別迭代到第20、50、70、100輪時,學習率逐步衰減原來的1/10。使用SGD(Stochastic Gradient Descent)優化器優化模型,在訓練時設置Dropout為0.5,防止過擬合。選擇交叉熵作為反向傳播梯度的損失函數,選擇Softmax分類器分類。所有實驗使用2個Nvidia GTX 2080Ti GPU完成訓練,并且依托于PyTorch的深度學習框架[23],版本號為3.6。
3.3 實驗結果及分析
3.3.1單模態有效性分析
多模態包含多種不同模態的數據類型,可以實現模態間的信息互補,提高模型性能。但是多模態數據也存在諸多局限性:1)數據具有異質性,模態對齊困難;2)模態融合可能存在冗余和噪聲干擾,融合效果難以預測且可解釋性不強;3)模型參數量大且訓練需要消耗較大內存空間,對算力有更高的要求。近年來,行為識別領域的發展越來越趨于使用多模態構建網絡,實驗精度有所提高,但同時網絡參數量、算法復雜度成倍增長,對算力的要求也越來越高,造成了時間成本和資源成本的大幅提高。因此,本文使用單模態構造簡單高效的網絡模型,提出一種單模態下的多特征融合方法。雖然客觀上單模態數據雖只攜帶單一的信息量,但主觀上可以通過深度學習模型豐富單模態數據特征的層次,從而增強單模態數據的特征表達,同時降低時間和資源成本。
與其他方法相比,本文在單模態下實現了與多模態相當甚至更優的識別性能。如表1所示,對比方法有Shift-GCN[14]、RA-GCN[15]、ST-TR(Spatial-Temporal TRansformer)、PL-GCN(Part-Level Graph Convolutional Network)[24]、DGNN(Directed Graph Neural Network)[25]、PB-GCN(Part-Based Graph Convolutional Network)[26]。
在同等單模態下,本文方法的準確率與PL-GCN相當,但是參數量更少;與多模態的DGNN相比,本文方法的準確率降低了0.9個百分點,但是參數量低于DGNN的1/6,因此消耗的內存資源更少,對實驗算力的硬件條件要求更低,總體性價比較高。與多模態的RA-GCN相比,本文方法的準確率和參數量均具有明顯優勢。綜上所述,本文方法簡單高效,并且取得了不錯的效果,整體性價比更高。
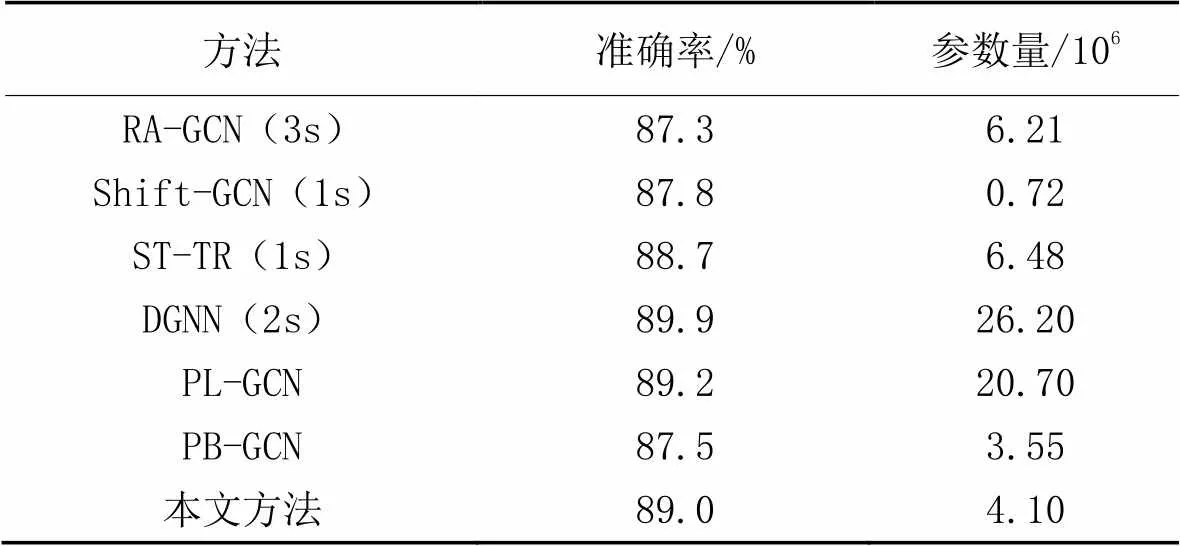
表1 NTU RGB+D60(X-sub協議)上不同方法的準確率對比
注:“s”表示流(stream)。
3.3.2單一特征有效性分析
為了探索全局與局部特征關聯圖的單特征有效性,本文在NTU RGB+D60數據集的兩個協議(X-sub和X-view)上進行了相應的消融實驗。
相較于ST-GCN將整個人體骨架圖輸入網絡訓練,本文分別將全局特征關聯圖(Global feature graph)和局部子圖(3subgraph、4subgraph、5subgraph、6subgraph)輸入網絡訓練,訓練結果如表2所示。從表2中可以看出,在兩個協議上,與ST-GCN相比,單特征全局特征關聯圖分別提升了5.2個百分點和4.8個百分點,單特征局部子圖(4subgraph)分別提升了5.9個百分點和5.4個百分點,表明了全局特征關聯圖可以突破人體骨架的固定連接,捕獲遠距離關節之間的全局關系;同時,表明局部子圖可以將模型的注意力集中人體局部特征,捕捉行為的細粒相似度,提升模型性能。從表2中還可以看出,在4種局部子圖劃分方案中,4subgraph的劃分方案效果最優,表明頭頸的運動對行為識別具有一定的影響,同時表明人體行為具有較強的協調對稱性。
3.3.3多特征融合的有效性分析
為了驗證新型多特征融合策略的有效性,本文在NTU RGB+D數據集的X-sub和X-view協議上進行實驗。
根據2.1.2節的劃分方案將全局特征關聯圖劃分為不同數量的互補子圖,對應表2所示的多特征融合列舉的4個方法。
從表2可以看出,多特征融合后的實驗結果均高于單特征的Global feature graph方法的結果。同時,在X-sub和X-view協議上,與單特征3subgraph方法的實驗結果相比,多特征融合Global feature graph+3subgraph方法分別提升了2.0和0.9個百分點;與4subgraph方法的實驗結果相比,Global feature graph+4subgraph方法分別提升了1.6和0.5個百分點;與5subgraph方法的實驗結果相比,Global feature graph+5subgraph方法分別提升了1.3和0.7個百分點;與6subgraph方法的實驗結果相比,Global feature graph+6subgraph方法分別提升了1.7和0.4個百分點。由此可以看出,多特征融合的4個方法的實驗結果均高于單特征的4種子圖方法,表明了多特征融合的效果比單特征效果有更高的識別準確率,驗證了全局和局部特征具有互補性。與此同時,再次證明了4個子圖劃分方案的有效性,因此,本文采用4個子圖劃分方案作為最終的實驗結果。
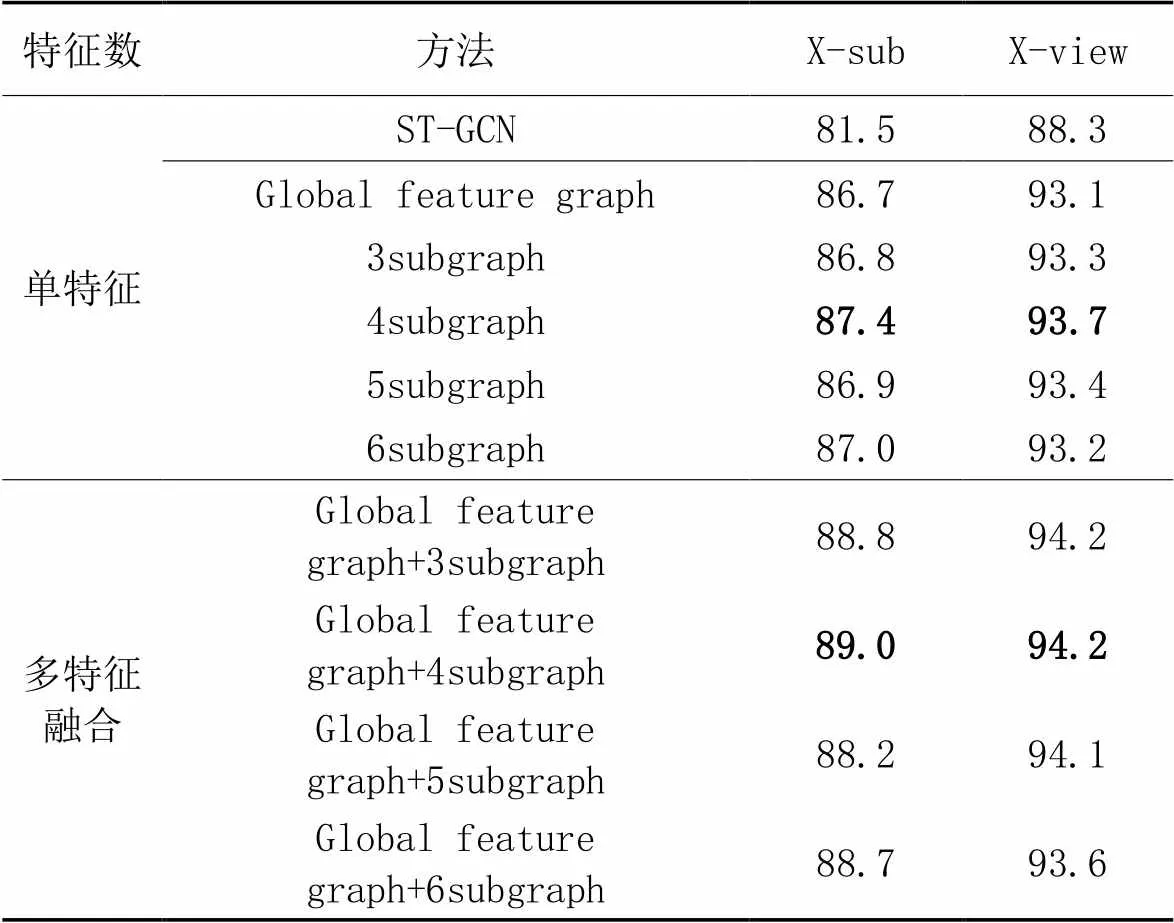
表2 NTU RGB+D60數據集上的消融實驗結果 單位:%
3.3.4與其他方法的對比
為了驗證方法的有效性,本文在NTU RGB+D60和NTU RGB+D120兩個數據集上進行了對比實驗。對比方法有ST-GCN[5]、PB-GCN[26]、Shift-GCN[14]、SAN[16]、RA-GCN[15]、PGCN-TCA(Pseudo Graph Convolutional Network with Temporal and Channel-wise Attention)[27]、ST-TR[28]、SGN(Semantics-Guided Network)[29]、SkeleMixCLR(Contrastive Learning of visual Representation with a spatio-temporal Skeleton Mixing augmentation)[30]、MST-GCN(Multi-scale Spatial Temporal Graph Convolutional Network)[31]。如表3所示,本文方法在NTU RGB+D60數據集的兩個通用協議X-sub和X-view上的準確率分別為89.0%和94.2%。
從表3中可以看出,在無其他數據流的情況下,僅選擇關節點相對坐標作為單數據流輸入,在X-sub協議上,本文方法的準確率比ST-GCN高7.5個百分點,比PB-GCN高1.5個百分點,比Shift-GCN(1s)高1.2個百分點,比ST-TR高0.3個百分點。與其他輸入額外的多種數據流的方法相比,本文方法的識別準確率也優于其他對比方法。在X-view協議上,本文方法優于大部分方法,但略低于Shift-GCN(1s)、ST-TR、SGN、MST-GCN。Shift-GCN(1s)方法中的時間圖卷積和空間圖卷積部分均使用了Shift卷積算子,本文僅在空間圖卷積中運用Shift卷積算子,時間圖卷積部分使用常規Conv卷積算子(因為基于本文的特征融合方法不適用時間Shift卷積算子,沿時間維度的通道移位會破壞原有的空間特征關聯結構,從而導致模型的識別準確率下降),但本文方法在NTU RGB+D120的兩個協議上的實驗效果均優于Shift-GCN(1s)方法;ST-TR中的Transformer注意力機制具有出色的全局特性和模態融合能力,但缺點是計算效率低,且開銷巨大;SGN和MST-GCN模型都是輕量,在NTU RGB+D60數據集上達到了不錯的識別效果,但是模型輕量和準確率不能兼得,所以它在更大的NTU RGB+D120數據集上的實驗效果不佳。
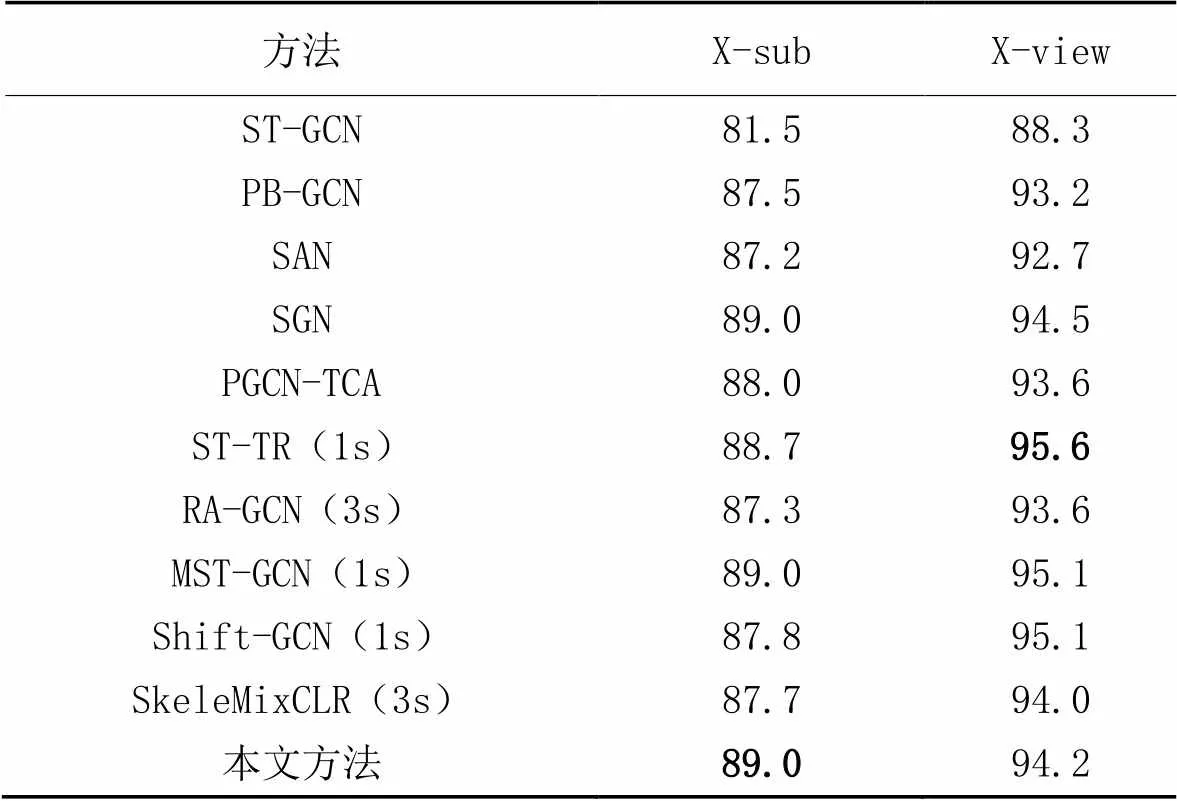
表3 不同方法在NTU RGB+D60數據集上的識別準確率 單位:%
綜上所述,本文方法在NTU RGB+D60數據集上有不錯的實驗效果,表明全局與局部特征能夠從更高層次的語義信息理解人體行為,敏銳地捕獲相似動作的辨別性差異。
如表4所示,本文方法在NTU RGB+D120數據集的兩個通用協議X-sub和X-setup上的準確率分別為83.3%和85.0%。對比方法為GVFE+AS-GCN with DH-TCN(Graph Vertex Feature Encoder and Actional-Structural Graph Convolutional Network with Dilated Hierarchical Temporal Convolutional Network)[32]、Gimme Signals[33]、SGN、Shift-GCN、RA-GCN、ST-TR、SkeleMixCLR和MST-GCN。在無其他數據流的情況下,僅選擇關節點坐標作為單數據流輸入,在X-sub協議上本文方法比Shift-GCN(1s)的準確率高2.4個百分點,比單模態下的ST-TR的準確率高1.4個百分點;在X-setup協議上比Shift-GCN(1s)的準確率高1.8個百分點,比ST-TR的準確率高0.9個百分點。與輕量級模型SGN相比,在兩個協議上的準確率分別高4.1和3.5個百分點;與輕量級模型MST-GCN(1s)相比,在兩個協議上的準確率均高0.5個百分點。綜上分析,驗證了本文方法的有效性。

表4 不同方法在NTU RGB+D120數據集上的識別準確率 單位:%
4 結語
為了提高人體關節點之間的全局建模能力,彌補卷積操作以及人體固有連接的局限性,本文提出了一種單模態條件下的基于多尺度特征融合的人體行為識別方法,從粗尺度的全局方面捕獲遠距離的關節點之間的關系,同時從細尺度的局部方面關注人的身體部分的強關聯,對人體行為識別從不同尺度特征形成互補關系,敏銳捕捉相似行為之間的差異性,提高識別性能。在具有挑戰性的兩個大型數據集NTU RGB+D60和NTU RGB+D120上的實驗結果表明,本文方法能達到較高的識別精度。近年行為識別領域蓬勃發展,識別精度也越來越高,但是網絡的規模和參數量也成倍增長,對實驗算力也提出了更高的要求,在保證識別精度的前提下,探索更輕量級的、更少參數量的、訓練更快的網絡模型是下一步值得深入研究的課題。
[1] SI C, CHEN W, WANG W, et al. An attention enhanced graph convolutional LSTM network for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 1227-1236.
[2] OORD A van den, KALCHBRENNER N, KAVUKCUOGLU K. Pixel recurrent neural networks[C]// Proceedings of the 33rd International Conference on Machine Learning. New York: JMLR.org, 2016: 1747-1756.
[3] DEFFERRARD M, BRESSON X, VANDERGHEYNST P. Convolutional neural networks on graphs with fast localized spectral filtering[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2016: 3844-3852.
[4] YANG H, YAN D, ZHANG L, et al. Feedback graph convolutional network for skeleton-based action recognition[J]. IEEE Transactions on Image Processing, 2022, 31: 164-175.
[5] YAN S, XIONG Y, LIN D. Spatial temporal graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2018: 7444-7452.
[6] SHI L, ZHANG Y, CHENG J, et al. Decoupled spatial-temporal attention network for skeleton-based action recognition[C]// Proceedings of the 2020 Asian Conference on Computer Vision, LNCS 12626. Cham: Springer, 2021: 38-53.
[7] CHEN Y, ZHANG Z, YUAN C, et al. Channel-wise topology refinement graph convolution for skeleton-based action recognition[C]// Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2021: 13339-13348.
[8] LI C, CUI Z, ZHENG W, et al. Action-attending graphic neural network[J]. IEEE Transactions on Image Processing, 2018, 27(7): 3657-3670.
[9] PENG W, HONG X, CHEN H, et al. Learning graph convolutional network for skeleton-based human action recognition by neural searching[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 2669-2676.
[10] ZHAO R, WANG K, SU H, et al. Bayesian graph convolution LSTM for skeleton based action recognition[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 6882-6892.
[11] GAO J, HE T, ZHOU X, et al. Focusing and diffusion: bidirectional attentive graph convolutional networks for skeleton-based action recognition[EB/OL]. (2019-12-24). [2022-08-13].https://arxiv.org/pdf/1912.11521.pdf.
[12] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks[EB/OL]. (2017-02-22). [2022-09-10].https://arxiv org/pdf/1609.02907.pdf.
[13] LIU Z, ZHANG H, CHEN Z, et al. Disentangling and unifying graph convolutions for skeleton-based action recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 143-152.
[14] CHENG K, ZHANG Y, HE X, et al. Skeleton-based action recognition with shift graph convolutional network[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 180-189.
[15] SONG Y F, ZHANG Z, SHAN C, et al. Richly activated graph convolutional network for robust skeleton-based action recognition[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2021, 31(5): 1915-1925.
[16] CHO S, MAQBOOL M H, LIU F, et al. Self-attention network for skeleton-based human action recognition[C]// Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision. Piscataway: IEEE, 2020: 624-633.
[17] YU W, YANG K, YAO H, et al. Exploiting the complementary strengths of multi-layer CNN features for image retrieval[J]. Neurocomputing, 2017, 237: 235-241.
[18] 劉渭濱,鄒智元,邢薇薇. 模式分類中的特征融合方法[J]. 北京郵電大學學報, 2017, 40(4): 1-8.(LIU W B, ZOU Z Y, XING W W. Feature fusion method in pattern classification[J]. Journal of Beijing University of Posts and Telecommunications, 2017, 40(4): 1-8.)
[19] SHI L, ZHANG Y, CHENG J, et al. Two-stream adaptive graph convolutional networks for skeleton-based action recognition[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 12018-12027.
[20] CHEN Y, ROHRBACH M, YAN Z, et al. Graph-based global reasoning networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 433-442.
[21] SHAHROUDY A, LIU J, NG T T, et al. NTU RGB+ D: a large scale dataset for 3D human activity analysis[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 1010-1019.
[22] LIU J, SHAHROUDY A, PEREZ M, et al. NTU RGB+ D 120: a large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684-2701.
[23] PASZKE A, GROSS S, CHINTALA S, et al. Automatic differentiation in PyTorch[EB/OL]. (2017-10-29) [2020-12-01].https://openreview.net/pdf?id=BJJsrmfCZ.
[24] HUANG L, HUANG Y, OUYANG W, et al. Part-level graph convolutional network for skeleton-based action recognition[C]// Proceedings of the 34th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020: 11045-11052.
[25] SHI L, ZHANG Y, CHENG J, et al. Skeleton-based action recognition with directed graph neural networks[C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 7904-7913.
[26] THAKKAR K, NARAYANAN P J. Part-based graph convolutional network for action recognition[EB/OL]. (2018-09-13) [2022-08-13].https://arxiv.org/pdf/1809.04983.pdf.
[27] YANG H, GU Y, ZHU J, et al. PGCN-TCA: pseudo graph convolutional network with temporal and channel-wise attention for skeleton-based action recognition[J]. IEEE Access, 2020, 8: 10040-10047.
[28] PLIZZARI C, CANNICI M, MATTEUCCI M. Skeleton-based action recognition via spatial and temporal transformer networks[J]. Computer Vision and Image Understanding, 2021, 208/209: No.103219.
[29] ZHANG P, LAN C, ZENG W, et al. Semantics-guided neural networks for efficient skeleton-based human action recognition[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 1109-1118.
[30] CHEN Z, LIU H, GUO T, et al. Contrastive learning from spatio-temporal mixed skeleton sequences for self-supervised skeleton-based action recognition[EB/OL]. (2022-07-07) [2022-10-23].https://arxiv.org/pdf/2207.03065.pdf.
[31] CHEN Z, LI S, YANG B, et al. Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition[C]// Proceedings of the 35th AAAI Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2021: 1113-1122.
[32] PAPADOPOULOS K, GHORBEL E, AOUADA D, et al. Vertex feature encoding and hierarchical temporal modeling in a spatial-temporal graph convolutional network for action recognition[C]// Proceedings of the 25th International Conference on Pattern Recognition. Piscataway: IEEE, 2021: 452-458.
[33] MEMMESHEIMER R, THEISEN N, PAULUS D. Gimme signals: discriminative signal encoding for multimodal activity recognition[C]// Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2020: 10394-10401.
Human action recognition method based on multi-scale feature fusion of single mode
LIU Suolan1,2, TIAN Zhenzhen1, WANG Hongyuan1*, LIN Long1, WANG Yan1
(1,,,,213164,;2(),210094,)
In order to solve the problem of insufficient mining of potential association between remote nodes in human action recognition tasks, and the problem of high training cost caused by using multi-modal data, a multi-scale feature fusion human action recognition method under the condition of single mode was proposed. Firstly, the global feature correlation of the original skeleton diagram of human body was carried out, and the coarse-scale global features were used to capture the connections between the remote nodes. Secondly, the global feature correlation graph was divided locally to obtain the Complementary Subgraphs with Global Features (CSGFs), the fine-scale features were used to establish the strong correlation, and the multi-scale feature complementarity was formed. Finally, the CSGFs were input into the spatial-temporal Graph Convolutional module for feature extraction, and the extracted results were aggregated to output the final classification results. Experimental results show that the accuracy of the proposed method on the authoritative action recognition dataset NTU RGB+D60 is 89.0% (X-sub) and 94.2% (X-view) respectively. On the challenging large-scale dataset NTU RGB+D120, the accuracy of the proposed method is 83.3% (X-sub) and 85.0% (X-setup) respectively, which is 1.4 and 0.9 percentage points higher than that of the ST-TR (Spatial-Temporal TRansformer) under single modal respectively, and 4.1 and 3.5 percentage points higher than that of the lightweight SGN (Semantics-Guided Network). It can be seen that the proposed method can fully exploit the synergistic complementarity of multi-scale features, and effectively improve the recognition accuracy and training efficiency of the model under the condition of single modal.
human action recognition; skeleton joint; Graph Convolutional Network (GCN); single mode; multi-scale; feature fusion
This work is partially supported by National Natural Science Foundation of China (61976028), Open Project of Jiangsu Key Laboratory of Image and Video Understanding for Social Security (J2021-2).
LIU Suolan, born in 1980, Ph. D., associate professor. Her research interests include computer vision, artificial intelligence.
TIAN Zhenzhen, born in 1997, M. S. candidate. Her research interests include computer vision, pattern recognition.
WANG Hongyuan, born in 1960, Ph. D., professor. His research interests include image processing, computer vision, artificial intelligence, pattern recognition.
LIN Long, born in 1998, M. S. candidate. His research interests include computer vision, data augmentation.
WANG Yan, born in 1999, M. S. candidate. His research interests include computer vision, pattern recognition.
1001-9081(2023)10-3236-08
10.11772/j.issn.1001-9081.2022101473
2022?10?11;
2022?12?29;
國家自然科學基金資助項目(61976028);江蘇省社會安全圖像與視頻理解重點實驗室開放課題(J2021?2)。
劉鎖蘭(1980—),女,江蘇泰州人,副教授,博士,CCF會員,主要研究方向:計算機視覺、人工智能; 田珍珍(1997—),女,河南鄭州人,碩士研究生,主要研究方向:計算機視覺、模式識別; 王洪元(1960—),男,江蘇常熟人,教授,博士,CCF會員,主要研究方向:圖像處理、計算機視覺、人工智能、模式識別; 林龍(1998—),男,四川德陽人,碩士研究生,主要研究方向:計算機視覺、數據增強; 王炎(1999—),男,江蘇連云港人,碩士研究生,主要研究方向:計算機視覺、模式識別。
TP391.41
A
2023?01?03。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
