基于提示學習的中文短文本分類方法
2023-10-24 14:54:22穆建媛周鑫柯強繼朋袁運浩
中文信息學報 2023年7期
穆建媛,朱 毅,周鑫柯,李 云,強繼朋,袁運浩
(揚州大學 計算機科學與技術系,江蘇 揚州 225127)
0 引言
隨著互聯網通信新時代的到來,每天都有海量的互聯網信息產生,并且這些信息以飛快的速度在更迭,如新聞標題[1]、微博推送[2]、論壇討論[3]、手機短信[4]等文本信息,這些大多是非結構化的短文本數據。與傳統的長文本數據相比較,這些短文本數據的最大特點在于語句較短,其中包含的詞匯較少,語義較為發散,容易產生歧義。這些特點導致了短文本數據的關鍵特征信息難以提取,所以,如何對短文本進行正確的分類處理,已成為熱門的研究方向。
短文本分類是自然語言處理(Natural Language Processing, NLP)的重要任務之一,已經有越來越多的國內外學者對比進行了大量的研究,并取得了很好的效果[5]。近年來,隨著深度學習的蓬勃發展,基于深度學習的分類模型應用到短文本分類任務上也取得了較好的效果[6]。如Kim[6]在2014年提出的基于卷積神經網絡(Convolutional Neural Networks, CNN)的TextCNN模型,首次將CNN應用到文本分類上。隨著研究的進一步推進,預訓練語言模型也被應用到自然語言處理的任務中,如Sun等[7]研究了BERT(Bidirectional Encoder Representation from Transformers)在文本分類任務上的不同微調方法,包括文本的預處理、逐層學習率和災難性遺忘等問題,在短文本分類任務上取得了較大的性能改進。
盡管傳統的神經網絡模型以及預訓練語言模型已經較為成熟地應用到短文本分類任務中,并且取得了良好的分類效果。但是,這些方法在訓練過程中通常需要大量的有標簽或無標簽的數據[8],且模型參數量較大。然而在實際應用中,訓練分類模型時,訓練數據的來源是最大的難題之一。我們經常面臨資源匱乏的數據問題,通常是因為訓練時所需的大量數據相對來說難以獲取,并且在對大量的數據進行訓練時成本較高[9]。因此如何在少樣本數據的情況下,對短文本進行準確的分類,已經成為實際應用中巨大挑戰。
為了解決這個問題,本文提出了一種基于提示學習的中文短文本分類方法,在僅有少樣本數據的情況下取得了良好的中文短文本分類效果。提示學習是自2021年開始自然語言處理領域掀起的一股新的浪潮[10],提示學習為了更好地利用預訓練語言模型的知識,改變了輸入數據的格式,通過加入模板和構建標簽詞表的方式,將分類問題轉化為一個預測和標簽詞相關的問題[11]。本文對以新聞標題、外賣評論等為代表的中文短文本進行分類,手動設計了不同的模板,通過實驗選擇效果較好的模板對輸入的數據進行了新的構造,變成了一個帶有mask的短文本,通過詞向量的方式輸入提示學習的模型,最后將模型的輸出映射到該短文本所屬的真實標簽后進行預測。據我們所知,這是第一次將提示學習運用到中文短文本分類上,并且與其他常用的分類方法相比,分類效果良好。
本文的主要貢獻總結如下:
(1) 提出了一種新的基于提示學習的中文短文本分類方法,充分利用了預訓練語言模型的知識,分類效果較為理想。
(2) 不同于以往的需要大量有標簽或無標簽的訓練數據的分類器模型,本文方法僅僅需要很少的訓練樣本就能實現良好的分類。
(3) 實驗結果證明,本方法在微博評論這種中文短文本數據集中,分類的準確率明顯優于現有的幾種方法,在僅有40個訓練樣本的情況下比BERT預訓練語言模型使用740個樣本的準確率高出近6%。
1 相關工作
由于社交網絡以及互聯網應用的大范圍普及,文本數據的交互已成為傳播信息的主要方式。在這個背景下,短文本數據大量出現在我們的視野中并正在爆炸式地增長。不同于較為規范的長文本,短文本通常具有稀疏性、即時性、不規范性,以及噪聲特征較多、更新迭代較快的特點[12]。這些特征都給短文本分類增加了很大難度,為了更好地解決這個問題,研究人員投入了大量的精力。現有的短文本分類方法可以大致分為基于傳統機器學習、基于深度神經網絡以及基于預訓練語言模型三種方法。
早期的短文本分類研究集中在傳統機器學習模型上,如樸素貝葉斯[13]、K近鄰[14]以及支持向量機(Support Vector Machine, SVM)[15]等算法。Peng等[16]提出了將N-gram[17]與樸素貝葉斯結合起來的方法,克服了樸素貝葉斯獨立假設的不足,增強了屬性間的聯系。Lin等[18]結合KNN與SVM算法,利用反饋改進分類器預測的概率來提高其性能。但是這些方法往往忽略了文本中詞語和詞語之間的聯系,同時特征工程的構建也較為復雜。并且由于數據的稀疏性問題,傳統機器學習在短文本分類上效果不佳。
隨著研究的深入,深度神經網絡被廣泛地應用到短文本分類的任務中[19-20]。如Kalchbrenner等[21]在卷積神經網絡[22]的基礎上提出了基于動態的卷積神經網絡模型DCNN,該模型能處理不同長度的文本并取得了較好的性能表現。Lai等[23]將循環卷積神經網絡(Recurrent Neural Networks, RNN)用于文本分類上。相比于CNN模型來說,RNN這種序列模型更容易捕捉到短文本的特征信息。Hochreiter等[24]對RNN進行改進,提出了長短時記憶網絡(Long Short Term Memory Network, LSTM)模型,很好地解決了其梯度消失的問題。隨后的雙向長短時記憶網絡[25]比起RNN以及LSTM模型可以更好地獲取上下文信息。Zhou等[26]提出C-LSTM模型,這種混合模型將CNN與LSTM的優勢結合起來,可以更好地提取句子中的全局信息。為了解決數據稀疏性的問題,Wang等[27]提出了一種結合顯式表示和隱式表示的深度CNN模型,通過詞嵌入、概念嵌入和字符嵌入來捕獲細粒度語義信息。Alam等[28]提出了一種基于CNN的方法,該方法使用單詞和實體來生成短文本表示。
近年來,預訓練語言模型已在短文本分類的實際應用中獲得了更好的語言表示能力[29-30]。Devlin等[31]提出了基于雙向Transformer的BERT預訓練模型,通過基于遮掩的語言模型更好地理解了上下文之間的語義。受BERT模型的啟示,Sun等[32]提出了ERNIE模型,該模型是知識增強的語義表示模型,同時在詞向量的表示方面比前者具有更好的泛化能力,并且適應性較好,在中文的自然語言處理任務上取得了較好的性能表現。Lan等[33]提出了ALBERT模型,在縮減了BERT參數的基礎上性能不變,并且大大縮短了模型的訓練時間。OpenAI團隊提出的第一代生成式預訓練語言模型GPT-1[34]、GPT-2[35]以及改進后的GPT-3[36],它們隨著模型的增加以及訓練數據規模的加大而實現較強的泛化能力,在自然語言生成任務上表現得更為突出。Raffel等[37]利用遷移學習的知識,通過引入一個統一的框架來將所有基于文本語言的問題轉換成文本到文本的格式,例如,分類任務的輸出是單詞而不是標簽。
盡管基于深度神經網絡以及預訓練語言模型的短文本分類方法已經取得了較好的分類效果,但由于這些模型往往依賴大量的標注或無標注語料,在缺乏大規模訓練數據時很難取得較好的效果。
近期,提示學習作為自然語言處理的第四范式走進了研究人員的視野。提示學習的基本思想是將輸入的文本信息按照特定的模板進行處理,把任務重構成一個更能充分利用預訓練語言模型的形式,減少模型對大規模數據的依賴。通過借助合適的prompt減少了預訓練和微調之間的差異,進而使得模型在少量樣本上微調即可取得不錯的效果[38]。如Schick等[11]形式化地提出了提示學習的范式,并且對少樣本進行了實驗。Shin等[39]提出了基于梯度自動化搜索模板的方法,可以根據具體任務自動構造模板,比手動構造模板更為高效。Li等[40]提出參數化的提示,改善了原先離散的提示難以優化的問題,可以根據不同的模型結構定義不同的提示拼接方式,常用于生成任務。經實踐發現,提示的變化對實驗的性能有較大的影響,Liu等[41]使用非自然語言的提示,將模板的構建轉化為連續參數優化問題,可以實現模板的自動構建。不同于前人在微調階段使用提示的方法,Gu等[42]首次提出提示預訓練過程,對預訓練任務進行調整,使其在后續的少樣本中獲得更好的性能。Han等[43]使用邏輯規則來構建提示。考慮到前人工作中的映射基本上都是人工構建或基于模型自動搜索獲得,容易帶來高偏差,Hu等[44]通過引入外部知識來擴展標簽詞的搜索空間,取得了較好的效果。大量的實驗表明,基于提示學習的方法能夠較好地處理自然語言處理領域的下游任務。
2 方法
本節將介紹本文提出的基于提示學習的中文短文本分類方法。
2.1 提示學習
近代自然語言處理領域技術的發展可以分為四種范式,分別是非神經網絡時代的完全監督學習、神經網絡的完全監督學習、預訓練-微調范式以及近期熱門的預訓練-提示-預測范式[10]。在提示學習這一第四范式產生之前,基于預訓練語言模型的分類模型使用預訓練-微調范式,這個范式利用那些已經在大規模未標記數據上通過自監督學習完成預訓練的模型,在下游任務上使用少量人工標記的數據進行微調,這比起傳統的全監督學習更加省時省力高效。而我們利用提示學習的分類方法,不需要對預訓練模型的參數進行調整,而是把下游任務的輸入輸出形式改造成適合預訓練模型的形式。它可以統一預訓練和微調的優化目標,并實現輕量、高效的下游任務微調,從而更好地完成任務[45]。
整個提示學習分類方法可以大致分為以下流程: 為輸入設計一個模板,構造答案空間的映射,將輸入文本放入模板中,使用預訓練語言模型進行預測,最后將預測的結果映射回真實的標簽。
圖1為該方法的整體框架圖,我們將根據圖1在以下部分詳細闡述本文方法。
2.2 模板生成
在實際應用中,一般在句中或句末設計模板填充答案。如果位于句中,稱為完型填空提示,適用于預測任務(或稱掩碼語言模型任務);如果位于句末,稱為前綴提示,較適用于生成任務。因此,在中文短文本分類任務中,我們選擇完型填空提示。
在我們提出的基于提示學習的中文短文本分類方法中,通過對輸入增加提示信息,我們將輸入的中文短文本形式化為自然的表達,即增加了手工設計的模板。例如,要對新聞標題進行分類,如圖1所示,假設需要將輸入的句子x=“國際油價4日繼續下跌”分類到類別y1=“經濟”或是y2=“教育”中,那么這個模板xp可以設置為如式(1)所示。
這里的[CLS]指的是分類,BERT模型在文本前插入一個[CLS]符號,并將該符號對應的輸出向量作為整個短文本的語義表示,然后用于分類。在原始文本中加入模板之后,將作為新的輸入數據進入預訓練語言模型。
2.3 類別預測
給定一組輸入的數據x={x1,…,xn},它們都將會被分類到類別y∈Y中,類別標簽的集合記作Vy={v1,…,vn},其中,V是整個類別的集合。Vy中每個單詞v被填入[MASK]中的概率表示為p([MASK]=v∈Vy|xp),隨后文本分類任務可以轉化為類別標簽詞的概率計算問題,如式(2)所示。
p(y∈Y|x)=p([MASK]=v∈Vy|xp)
(2)
如在短文本“國際油價4日繼續下跌”的分類過程中,如果屬于y1=“經濟”類別的概率大于y2=“教育”類別的概率,那么該文本就會被分類到“經濟”中。
2.4 標簽詞映射
所有的類別標簽詞概率計算好以后,我們需要將每個標簽詞上預測好的概率映射到對應的類別中。假定映射時每個標簽詞對于預測結果重要性相同,那么預測分數的均值可以用來進行分類。即可以使用目標函數f進行分類,如式(3)所示。
(3)
最終得到分類結果。
3 實驗
3.1 數據集
本實驗的數據集采用THUCNews新聞數據集[46]、Chinese News Titles[1]數據集、中文外賣數據集以及微博評論數據集,以下簡記為THUC、CNT、WaiMai、WeiBo數據集,具體信息如表1所示。
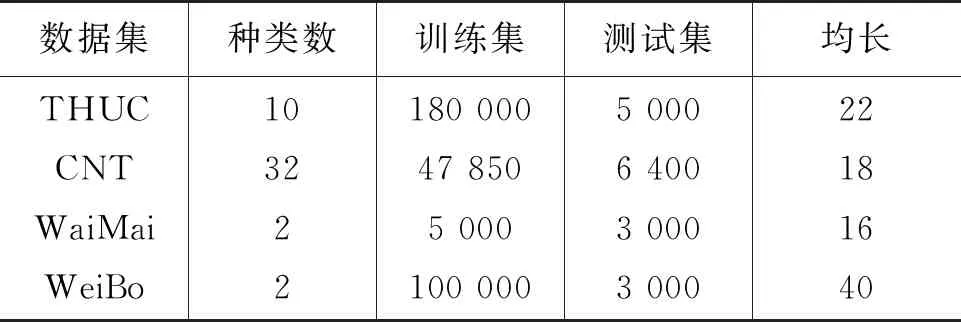
表1 4個數據集的具體信息
3.2 對比實驗
通過與P-tuing[41]、TextCNN[47]以及預訓練語言模型BERT[31]、ERNIE[32]基線方法進行對比實驗,驗證了本文方法的有效性。
(1)P-tuning: 將模板的構建轉化成參數優化問題,實現模板的自動生成。
(2)TextCNN: 把詞嵌入后的詞向量再通過卷積層和池化層來更好地構造特征向量。
(3)BERT: 利用預訓練模型,將文本嵌入為詞向量,再送到分類器中進行分類。
(4)ERNIE: 將外部知識引入預訓練語言模型中,對掩碼機制進行了改進,更加適用于中文自然語言處理任務。
3.3 實驗設置
為了模擬真實應用中訓練樣本不足的情況,實驗過程中,我們進行了5-shot、10-shot以及20-shot的k-shot少樣本實驗,最終以準確率來評估模型的分類效果。實驗參數的設置如下: 我們對訓練輪數選取迭代輪次數為5,對于THUC以及CNT數據集,訓練集的批大小設為32,學習率設為0.000 3;對于外賣評論以及微博評論數據集,批大小設為5,學習率設為0.000 3。
同時對模型進行了調整,選擇了具有較好性能的其他參數進行實驗,如選取實驗效果最優的模板,這將在3.5節進行展示。對于參數批大小、迭代輪次、學習率對實驗結果的影響將在3.6節進行展示。
下面是對于實驗訓練樣本的說明: 在本文的模型中對于每一個k-shot實驗,我們從原始的訓練集中抽取每個類的k個樣本數據來形成少量的shot訓練集,并在每個類中抽取另外的k個樣本數據來構成驗證集。由于這些少樣本訓練集和驗證集選擇的不同對于實驗結果有一定的影響,所以我們重復了三次隨機采樣,并對三次隨機采樣實驗后的結果取平均值。
由于TextCNN、BERT以及ERNIE各自性能的原因,我們也分別進行了手動隨機采樣。以下是具體的采樣說明:
(1) 在TextCNN的對比實驗中,我們從THUC原始的180 000訓練集中分別隨機采樣700(70×10)條、800(80×10)條以及900(90×10)條;從CNT原始的47 850訓練集中隨機采樣1 920(60×32)條、2 240(70×32)條以及2 560(80×32)條;從WaiMai原始的5 000訓練集中分別隨機采樣140(70×2)條、160(80×2)條、200(100×2)條;從WeiBo原始的100 000訓練集中分別隨機采樣800(400×2)條、900(450×2)條、1 000(500×2)條樣本進行實驗,為了避免較大的誤差,各自進行三次不同的采樣后實驗的結果取平均值。對照本文所提的模型中的5-shot、10-shot、20-shot樣本數。
(2) 在BERT的對比實驗中,我們從THUC原始的訓練集中分別隨機采樣1 200(120×10)條、1 300(130×10)條以及1 400(140×10)條;從CNT原始的訓練集中隨機采樣640(20×32)條、800(25×32)條以及960(30×32)條;從WaiMai原始的訓練集中分別隨機采樣440(220×2)條、460(230×2)條、500(250×2)條;從WeiBo原始的訓練集中分別隨機采樣680(340×2)條、700(350×2)條、740(370×2)條樣本進行實驗。同樣,對三次不同隨機采樣后的實驗結果取平均值。對比本文的模型中的5-shot、10-shot、20-shot樣本數。
(3) 在ERNIE的對比實驗中,我們從THUC原始的訓練集中分別隨機采樣800(80×10)條、900(90×10)條以及1 000(100×10)條;從CNT原始的訓練集中隨機采樣960(30×32)條、1 600(50×32)條以及1 920(60×32)條;從WaiMai原始的訓練集中分別隨機采樣240(120×2)條、260(130×2)條、300(150×2)條;從WeiBo原始的訓練集中分別隨機采樣400(200×2)條、500(250×2)條、560(280×2)條樣本進行實驗,對三次隨機不同采樣后的實驗結果取平均值。對照本文所提的模型中的5-shot、10-shot、20-shot樣本數。
3.4 實驗結果
表2及圖2~圖5詳細記錄了4個數據集的所有實驗結果,從實驗中可以得出以下結論。
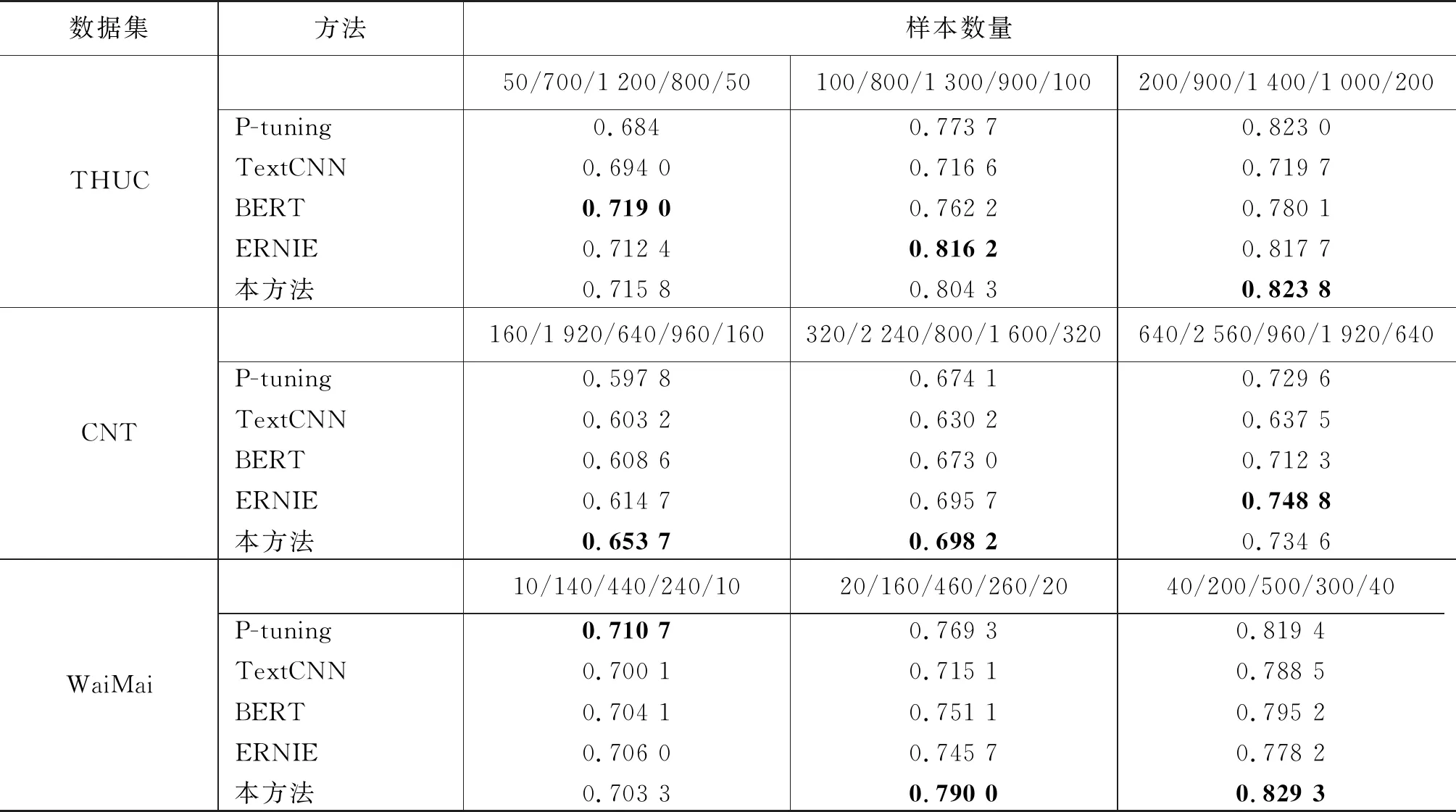
表2 4個數據集上不同模型的結果
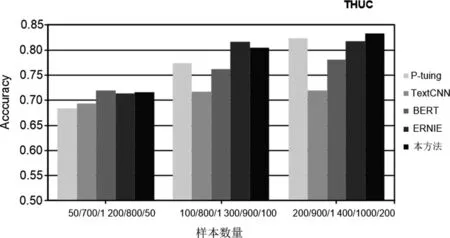
圖2 數據集為THUC時各模型的結果
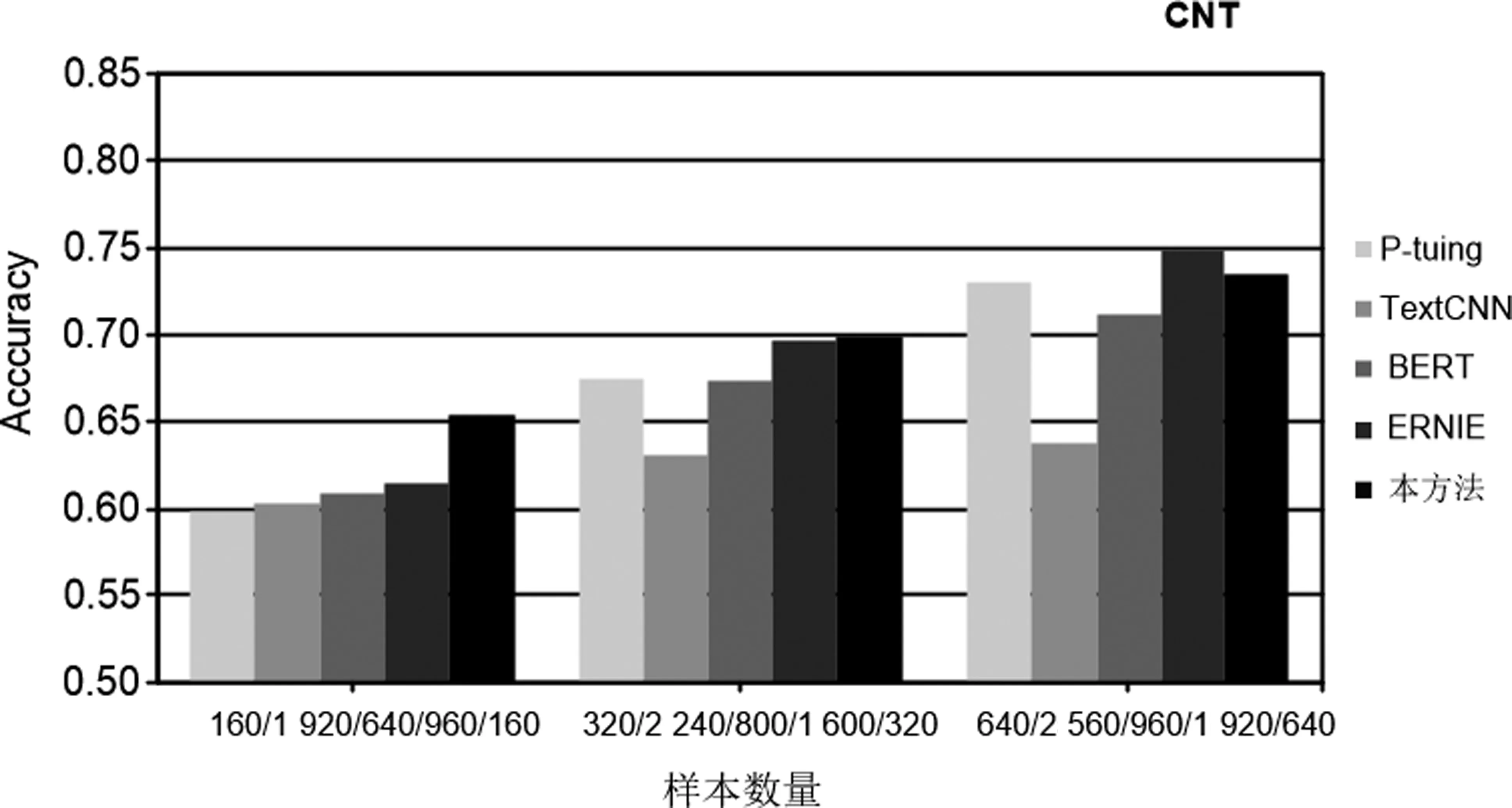
圖3 數據集為CNT時各模型的結果
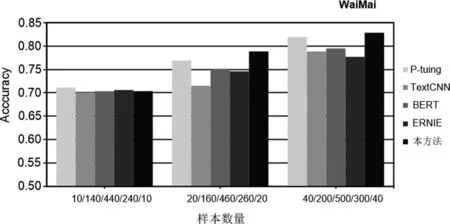
圖4 數據集為WaiMai時各模型的結果
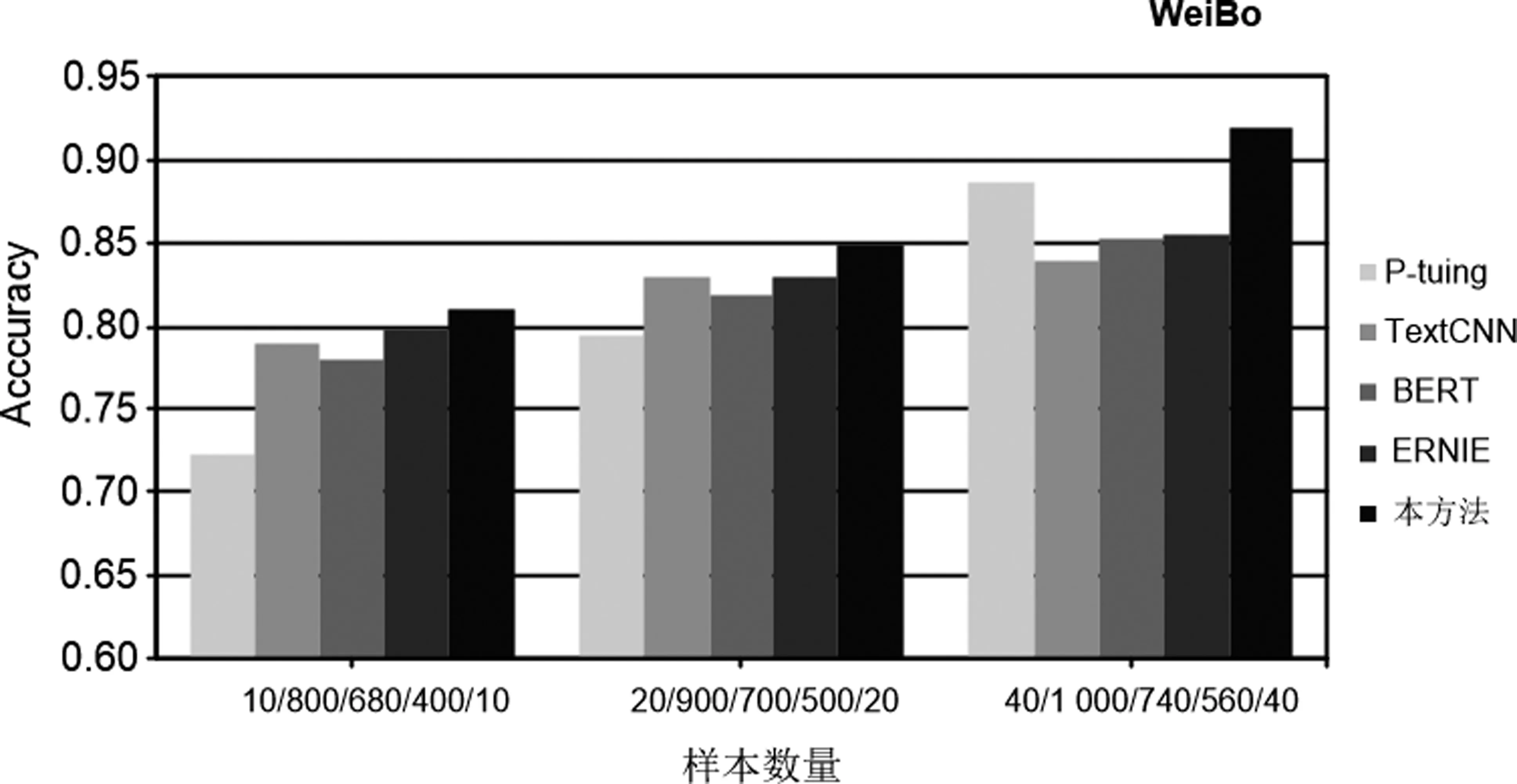
圖5 數據集為WeiBo時各模型的結果
(1) 本實驗所用的樣本數量不等,但是在樣本數增加的過程中,所有模型的實驗性能都有所提高,這說明增加訓練樣本的數量可以在少樣本的分類過程中提高分類效果。
(2) 與TexTCNN以及BERT相比,本文方法在訓練樣本數量相差巨大的情況下,仍取得了更好的分類效果。如在THUC和WeiBo數據集中,TextCNN訓練樣本數分別達到提示學習所用樣本數的14和80倍;在WaiMai數據集中,BERT模型所用樣本數達到提示學習所用樣本數的44倍。
(3) 在4個數據集中,ERNIE模型所用樣本數最高達到提示學習所用樣本數的40倍。這些實驗結果說明在絕大多數情況下,本文的模型與以上三個對比方法相比取得了更為理想的分類效果,這就證明本文方法在少樣本的情況下是有效的。
(4) P-tuing是在提示學習中自動生成模板的方法,經過實驗,分類效果整體上優于TextCNN以及BERT模型, 但是不及本文方法中手動設計模板的實驗結果,這就說明通過我們手工設計的模板進行實驗的方法是更加有效的。
3.5 模板選取
模板的設計與選取在很大程度上也影響了提示學習的實驗效果,使用好的模板可以得到較高的準確率。在表3中列出了實驗過程中手動設計的模板。
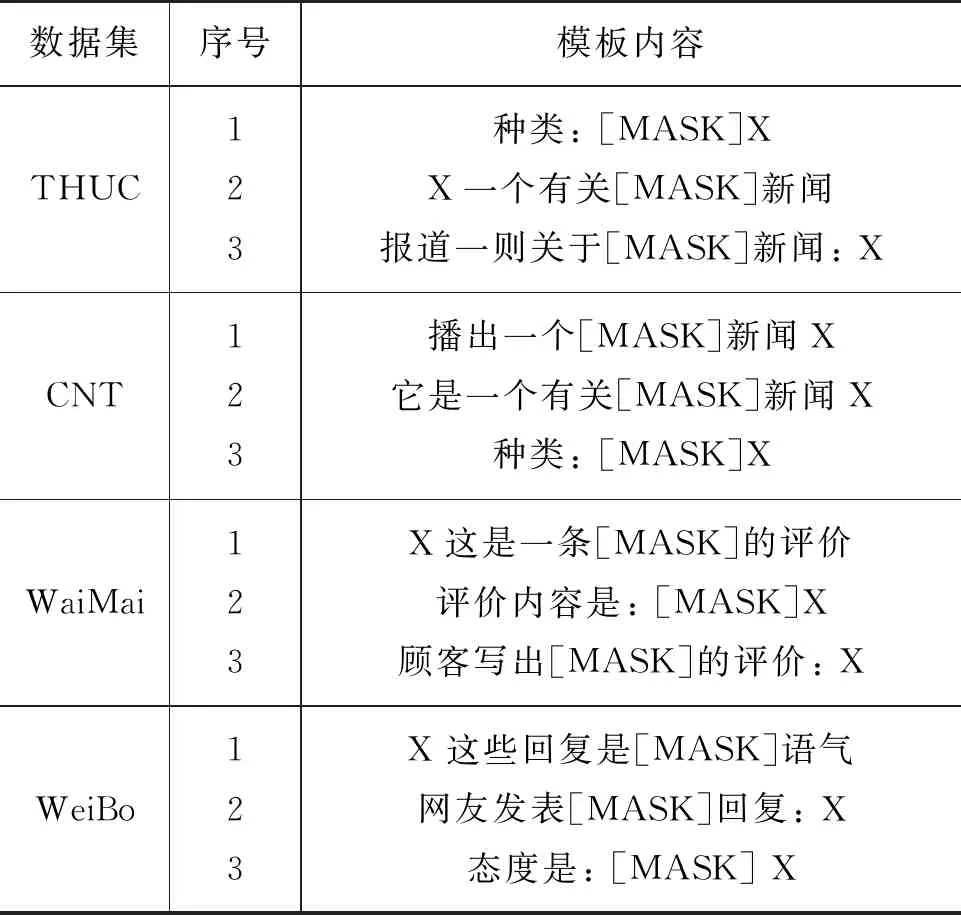
表3 模板的具體內容
經過對不同模板多次隨機實驗,我們發現并使用了分類效果較好的模板。表4列出了我們在 10-shot 樣本數時不同模板的實驗結果。
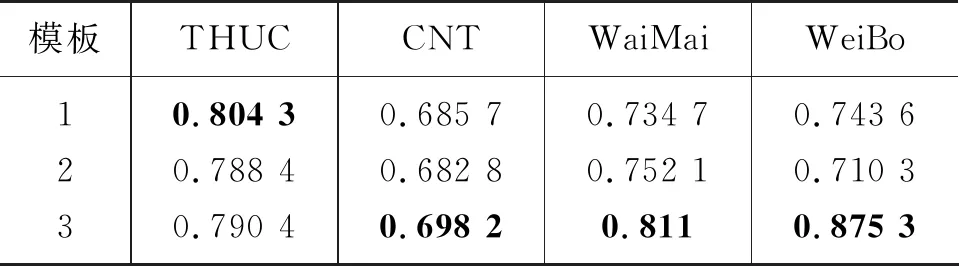
表4 10-shot時不同模板的準確率
3.6 參數敏感度
在這一部分,本文研究所提方法中不同的參數對實驗結果的影響,選取實驗輪數、學習率以及批大小作為考察因素,在THUC數據集上選取100個樣本進行實驗。經過實驗我們發現,隨著迭代輪次數量的增加分類的正確率在整體上呈現上升趨勢,這表明適當地增加訓練輪數可以提高分類效果,但是隨著輪數的增加,所有模型的實驗效果都有所提高,同時也會增加時間復雜度,所以主實驗中我們只選擇了迭代輪次輪數為5。對于批大小的選擇,我們發現在32時得到較好的效果,由實驗結果可知,批大小的選擇對實驗結果有一定程度的影響。并且隨著模型的學習率的變化,實驗結果也在一定范圍內波動。圖6~圖8展示了具體的實驗結果。
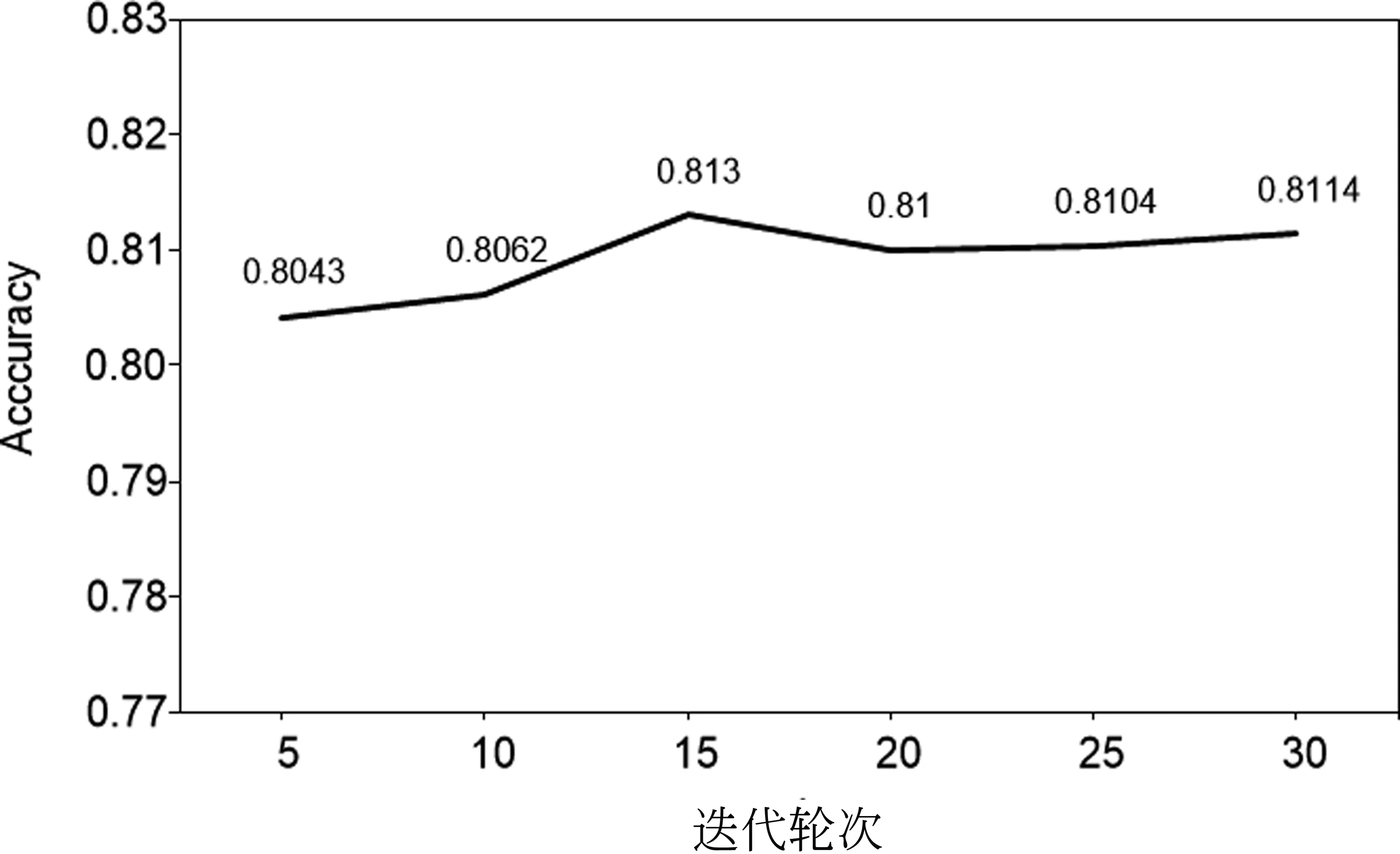
圖6 10-shot時不同迭代輪次下模型的實驗結果
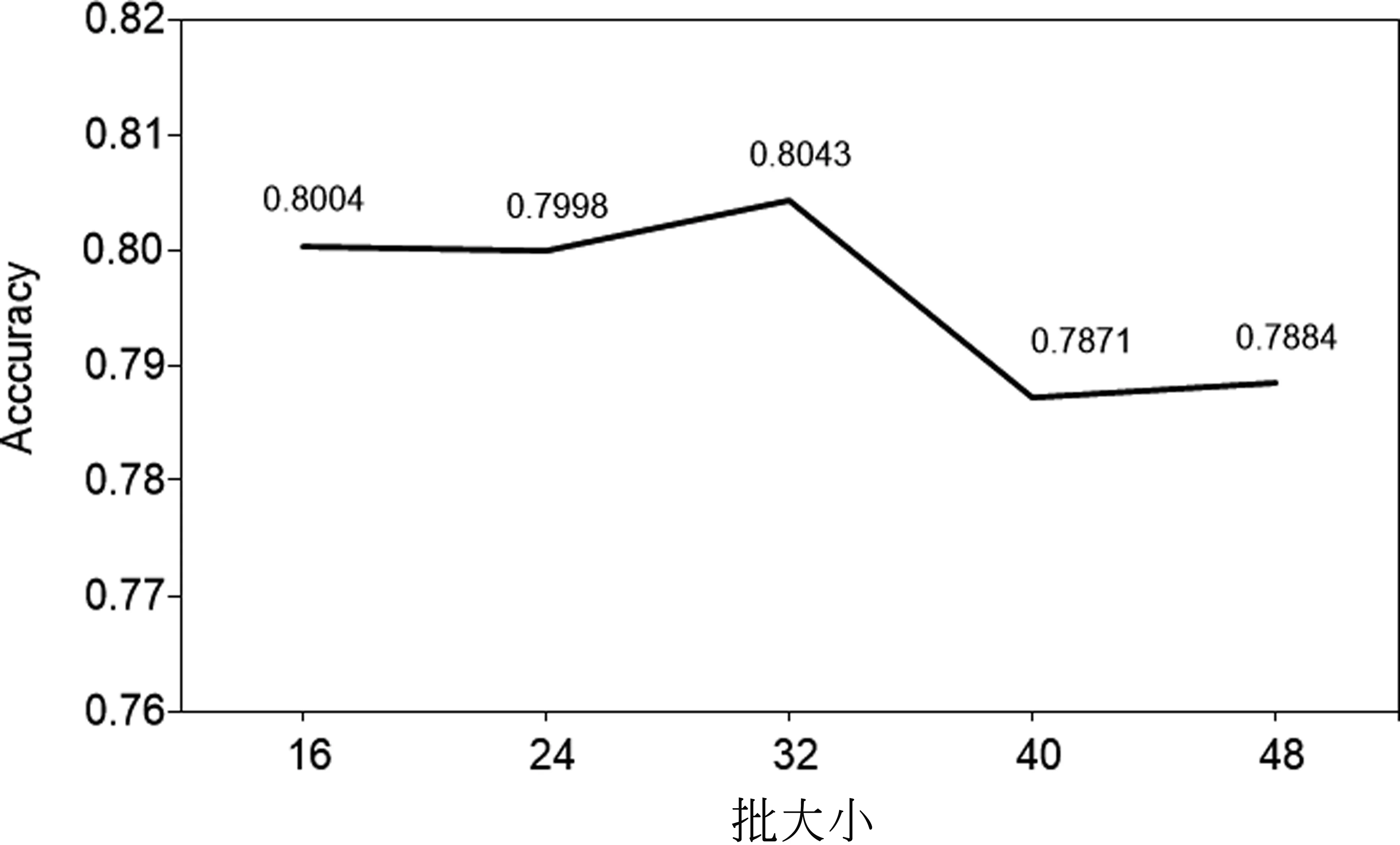
圖7 10-shot時不同批大小下模型的實驗結果
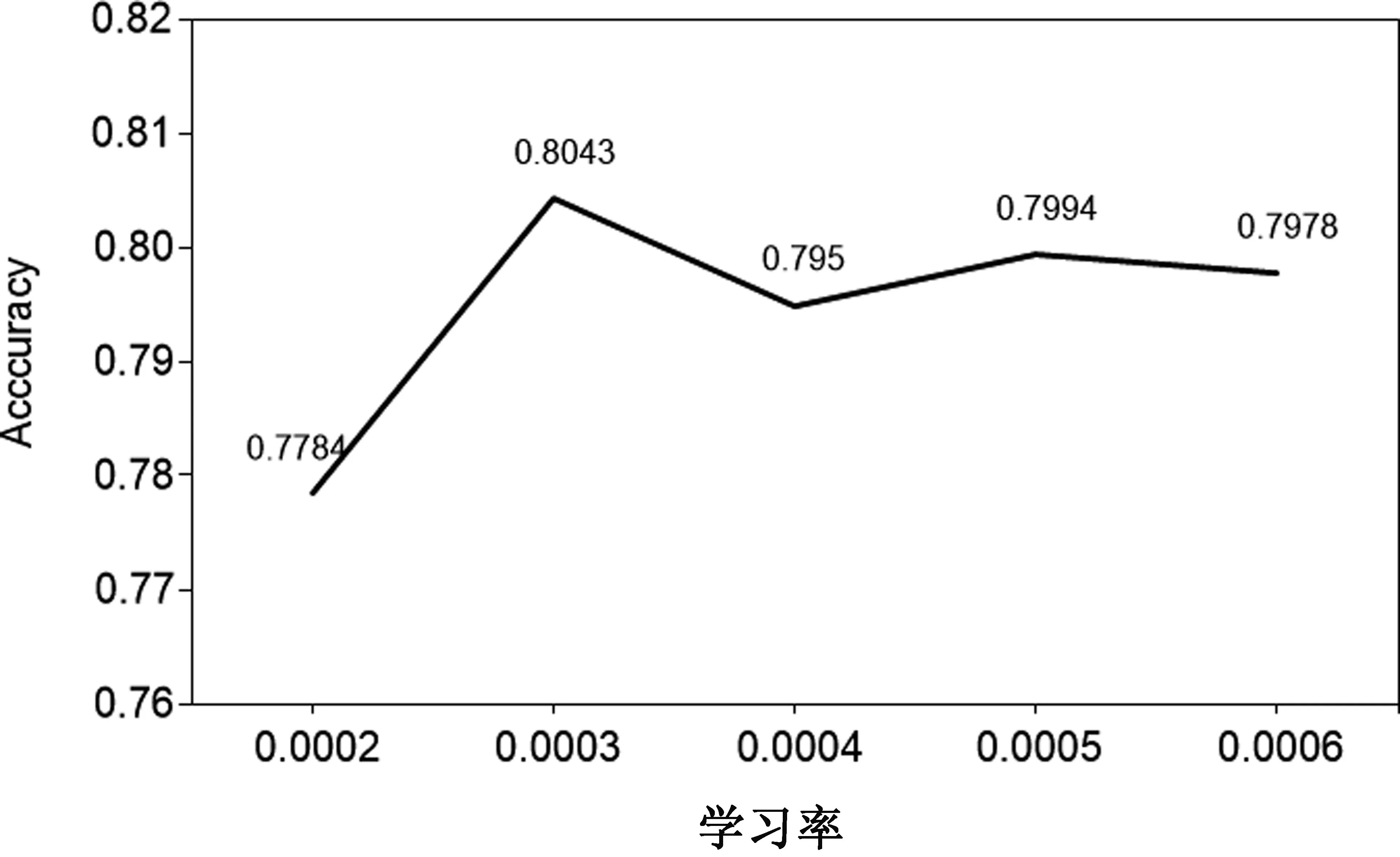
圖8 10-shot時不同學習率下模型的實驗結果
4 結論
本文提出了一種基于提示學習的中文短文本分類方法,該方法不需要大量的訓練數據,充分利用了預訓練語言模型的強大泛化能力,僅在少樣本的情況下即可解決短文本的分類問題,減少了對下游任務有監督數據的依賴,經過實驗證明,該方法有效。下一步工作中,我們將嘗試使用高效的方法對分類標簽的空間進行擴展,以便在不同的下游任務中取得更好的性能表現。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
