基于HYB格式SpMV在新一代申威架構上的實現與優化*
2023-10-24 02:52:48王鑫,彭健
計算機工程與科學 2023年10期
關鍵詞:優化
王 鑫,彭 健
(江南大學物聯網工程學院,江蘇 無錫 214122)
1 引言
稀疏矩陣向量乘法SpMV(Sparse Matrix-Vector multiplication)是科學計算與工程應用中一個廣泛使用的計算核心,在機器學習[1]、圖像分析[2]等領域中有著廣泛應用。SpMV涉及最多的應用就是大規模稀疏線性系統的迭代求解,求解過程中包含大量循環或者迭代的SpMV操作,這會帶來巨大的時間開銷,從而影響整個系統的求解效率。因此,對SpMV算法的加速與優化是至關重要的。
稀疏矩陣向量乘法是用于計算y=A×x等式的方法,其中,等式右側的矩陣A表示稀疏矩陣,x表示參與計算的稠密向量,左側的y則代表經過計算后得到的結果向量。稀疏矩陣中非零元素的分布情況復雜且很不規則,處理器計算架構又處于不斷升級的狀態,所以,SpMV并行算法的設計與優化實現是現在算法研究的熱點之一。目前,擁有強大并行計算能力的處理器得到了普遍使用,例如GPU(Graphics Processing Unit)[3]、Intel公司提供的眾核處理器Intel Xeon Phi[4]等,利用這些處理器的并行計算架構能迅速提升SpMV的計算性能,研究成果不在少數。隨著國產眾核處理器的不斷發展,研究在其上實現高效的SpMV算法具有現實意義,因此,本文選擇國產新一代申威異構眾核處理器SW26010P作為計算平臺,研究SpMV算法的并行化設計。
提高SpMV計算性能不僅跟處理器架構有關,還取決于如何選取一個合適的稀疏矩陣存儲格式。稀疏矩陣中非零元素占比低且分布不規則的特性,使得稀疏矩陣的存儲格式具有多樣性。最常見的稀疏矩陣存儲格式有COO(COOrdinate)格式、ELL(ELLPACK)格式、CSR(Compressed Sparse Row)格式和HYB(HYBrid)格式等。其中,COO格式采用三元組的形式對稀疏矩陣中非零元素進行存儲,三元組由行索引、列索引和數值構成,該存儲格式是最為簡單的一種存儲格式,比較直觀靈活,但不利于計算和并行化;CSR格式采用數值、列號、行偏移3類數據的編碼方式,數值和列號按照行順序存儲非零元素的值和列索引,行偏移存儲每一行的第一個元素在數值中的起始偏移位置,它是一種較為普遍使用的存儲格式;ELL格式采用m×k的矩陣存儲數據,其中k為稀疏矩陣中每行非零元素個數中的最大值,該格式與稠密矩陣較為相似,只是在矩陣的列數上進行了壓縮,適合并行化計算;HYB格式則結合了ELL和COO 2種格式的優點,對每行中超出給定閾值的非零元素使用COO格式存儲,以解決ELL格式由于每行之間非零元素個數差異過大導致過多的零值填充。
本文對SpMV算法的并行化設計是基于HYB存儲格式。HYB格式中閾值的選取是一個難點,常常采用經驗法來確定閾值。針對這個問題,本文提出了一種新的閾值劃分方法,并借助新一代申威異構眾核處理器強大的計算能力和高度的并行架構,設計出一種并行SpMV算法。
2 背景
2.1 申威眾核處理器SW26010P
SW26010P處理器是我國自主研發的新一代神威超級計算機上所使用的處理器[5],圖1展示了其硬件架構。
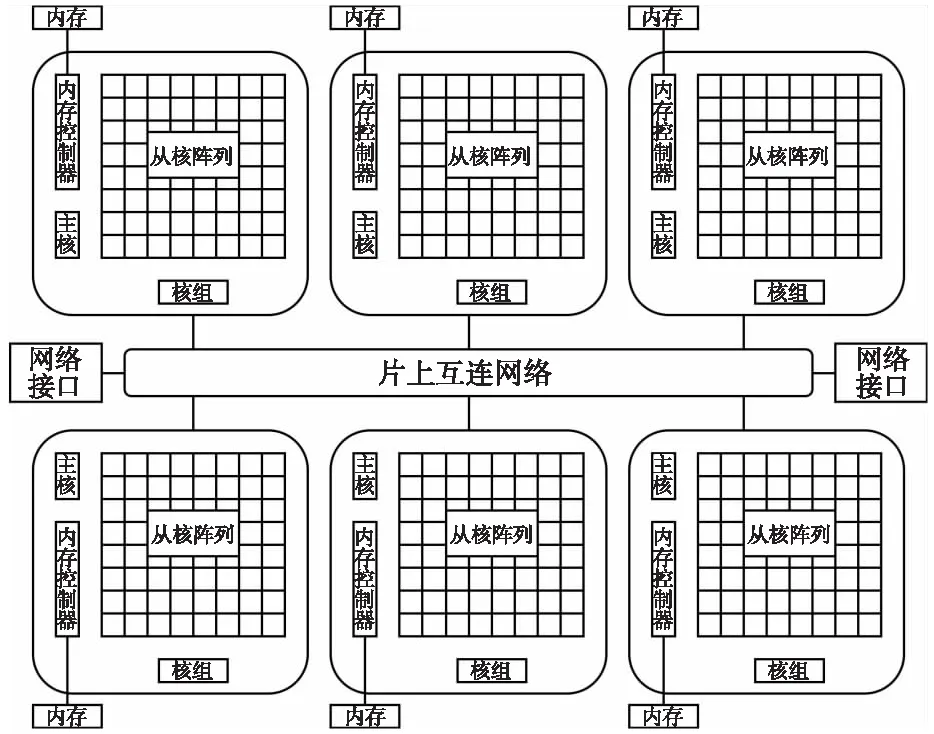
Figure 1 Architecture of SW26010P CPU
每個SW26010P異構眾核處理器集成了6個核心組CG(Core Group),每個CG包括1個主核MPE(Management Processing Element)與1個由64個從核組成的從核陣列CPE(Computing Processing Element),總共390個核心。眾核處理器每個核心組本地內存容量為16 GB,單個核組的內存帶寬為51.2 GB/s,總內存帶寬為307.2 GB/s。
每個主核包含1個L1指令緩存和1個L1數據緩存,以及1個數據和指令共用的L2緩存,這3類緩存都是由硬件控制的。每個從核包含一塊容量為256 KB的本地數據存儲空間LDM(Local Data Memory),其完全由軟件管理,其容量有限,訪存速度快,屬于處理器的珍惜資源。每個從核支持直接存儲器訪問DMA(Direct Memory Access),通過DMA操作可以實現LDM與主存之間粗粒度數據的快速訪問,以提高從核訪問主存的效率。處理器的另一個特性是從核支持遠程內存訪問RMA(Remote Memory Access),RMA取代了上一代處理器SW26010的寄存器通信技術[6],從核通過RMA操作實現本地LDM與其他從核LDM之間的高效數據傳輸,可以緩解LDM容量有限的問題。
2.2 相關工作
SpMV的并行實現和優化,一直是科學計算領域中的一個研究熱點。尤其當一款新的處理器問世時,基于該處理器的稀疏矩陣向量乘法的實現與優化工作就會持續不斷。Cardellini等人[7]基于多種稀疏矩陣存儲格式和負載均衡策略研究了適合異構CPU+GPU計算平臺的SpMV實現與優化。Sun等人[8]在GPU平臺上提出了一種基于索引壓縮的SpMV優化方法,該方法可以顯著減少索引的訪問次數,提高訪存性能。Zhang等人[9]針對多核結構上SpMV的內存帶寬高和負載不均衡的問題提出了解決方法。Elafrou等人[10]針對GPGPUs提出了一種SpMV瓶頸感知的自動調節器——BASMAT(Bottleneck-Aware Sparse matrix-vector Multiplication Auto-Tuner),可以根據輸入稀疏矩陣的結構特點自動優化SpMV內核,以解決GPGPUs上內存帶寬、內存延遲和線程不平衡的問題。Zhang等人[11]利用Intel?Xeon?Phi眾核架構上的向量單元,提出了一種切片ELLPACK稀疏矩陣存儲格式并設計了相應的SpMV并行算法。Liu等人[12]提出了一種新的存儲格式ESB(ELLPACK Sparse Block),該格式有助于改善Intel?Xeon?Phi處理器上SpMV向量化性能,并且能減少帶寬需求。除了常用CPU、GPU平臺外,還有許多是針對上一代申威處理器SW26010的研究。Sun等人[13]在SW26010處理器上針對CSR存儲格式設計了SWCSR-SpMV算法,并利用申威眾核架構特殊的局存通信技術優化了SpMV的訪存性能。
合適的稀疏矩陣存儲格式也是優化SpMV的一個關鍵之處。Liu等人[14]提出了一種新的存儲格式CSR5(Compressed Sparse Row 5),該格式對輸入稀疏矩陣的結構特性不敏感,易于從傳統的CSR格式轉換得到,并能夠在多個平臺上實現,通用性較強。Zhang等人[9]在COO格式的基礎上設計了一種新的稀疏矩陣存儲格式BCCOO(Blocked Compressed COO),用以緩解SpMV帶寬的限制,再通過對矩陣垂直切片將BCCOO格式改進為BCCOO+格式,以獲得更好的數據局部性;為了解決SpMV負載不均衡的問題,還提出一種高效的基于矩陣的SpMV分段/掃描算法。Bian等人[15]提出了一種適用于SIMD(Single Instruction Multiple Data)的稀疏矩陣存儲格式CSR2,該格式操作易于實現,轉換開銷小。另外,針對不同特性的稀疏矩陣,采用混合壓縮存儲格式更能適應不規則的稀疏特征。比如,Liang等人[16]提出的HCC(HydroCAD prefab Chamber data file)格式,采用了CSR+COO混合格式;陽王東等人[17]針對準對角矩陣的不規則性,采用DIA+CSR混合格式來提升SpMV性能;陽王東等人[18]基于混合COO和ELL格式的HYB格式,利用數據劃分策略實現SpMV在CPU+GPU上的異構計算。
3 稀疏矩陣存儲格式
3.1 COO存儲格式
COO格式采用三元組的編碼方式來存儲稀疏矩陣中的非零元素。三元組指的是rowindices、colindices和values3個數組,其中rowindices記錄非零元素所在的行索引,colindices記錄非零元素所在的列索引,values記錄非零元素的值。對于圖2a所示的稀疏矩陣A,其COO格式如圖2b所示。
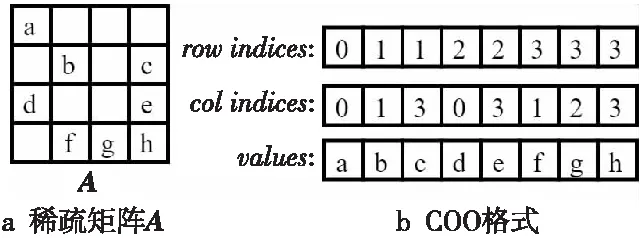
Figure 2 Example of the COO format
COO格式的存儲方式可以有效地存儲任何結構的稀疏矩陣,簡單直觀,但是數據訪問缺乏像稠密矩陣行列訪問的規則性,不適合在并行架構處理器上進行并行運算。
3.2 ELL存儲格式
ELL格式采用2個與原始矩陣行數相同的矩陣來存儲數據,列數為包含非零元素最多行的非零元素數。其中,values矩陣存儲非零元素的值,colindices矩陣存儲非零元素的列索引,對于values矩陣中的零元素可以由零值填充,colindices矩陣可以由-1填充。對于如圖2a所示的稀疏矩陣A,其ELL格式如圖3所示。
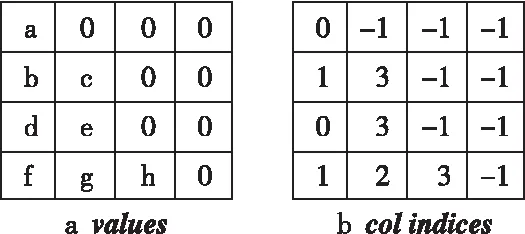
Figure 3 Example of the ELL format
ELL格式與稠密矩陣的存儲方式相似,相比COO格式更適合在并行架構處理器上運算,但當矩陣中每行非零元素個數差異較大時,就會導致ELL格式的存儲效率和計算效率驟降。
3.3 HYB存儲格式
HYB格式是采用ELL格式和COO格式混合的存儲格式,根據閾值將稀疏矩陣劃分為ELL格式和COO格式2個部分存儲,對于每行元素個數小于閾值的部分采用ELL格式存儲,大于閾值的部分采用COO格式存儲。對于圖2a所示的稀疏矩陣A,其HYB格式如圖4所示。
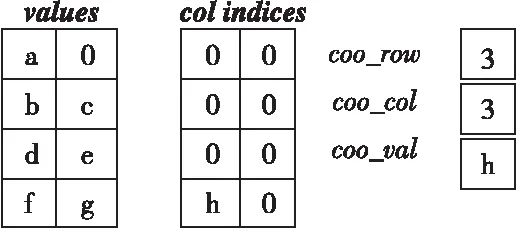
Figure 4 Example of the HYB format
對于HYB格式,其ELL格式存儲部分由數值矩陣values和列索引矩陣colindices存儲,COO格式存儲部分由coo_row、coo_col和coo_val數組分別存儲超出閾值部分非零元素的行索引、列索引和值。HYB格式彌補了ELL格式由于非零元素數量差異過大導致的存儲空間過于冗余的缺陷,但是閾值的選取是一個難點。
4 SpMV算法并行設計
4.1 SpMV并行設計整體框架概述
基于HYB存儲格式的SpMV算法實現主要涉及2個方面的內容:其一是HYB格式閾值的確定方法;其二是基于HYB格式的SpMV在SW26010P處理器上的設計。圖5展示了其整體的框架結構。
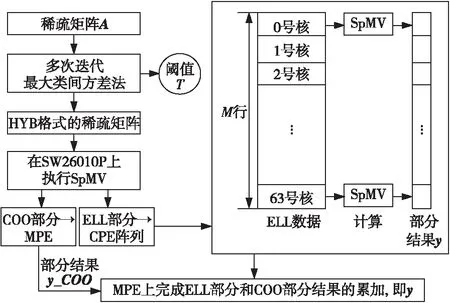
Figure 5 Overall framework of the SpMV design
針對HYB格式閾值選取的難點,本文提出了一種多次迭代最大類間方差法的方法來確定HYB格式的閾值。
閾值確定后,HYB格式由ELL格式和COO格式2個部分構成。針對并行架構友好的ELL格式采用從核陣列進行并行處理,COO格式則采用主核進行串行處理,2個部分的結果進行累加即為最終的計算結果。
4.2 HYB格式的閾值劃分算法
對于HYB格式,通常是基于經驗法選取閾值作為ELL和COO之間的分割值,這導致ELL和COO部分非零元素所占比例存在很大的不確定性,容易影響SpMV計算的性能。為了解決HYB格式所存在的問題,本節提出了一種新的閾值劃分算法。
本文提出的閾值劃分算法基于最大類間方差法(Otsu)[19]。Otsu是由日本學者大津展之(Nobuyuki Otsu)在1979年提出的,它是一種處理圖像二值化的非參數、自適應閾值分割方法,也稱大津算法。假設稀疏矩陣A包含M行、N列以及NNZ個非零元數量,x為輸入向量,y為輸出向量,T為HYB格式的閾值。假設t={1,2,…,N}為閾值選取范圍,nnz_left是以t為分割線矩陣左邊的非零元素個數,nnz_right是以t為分割線矩陣右邊的非零元素個數,nnz_left_all是以t為分割線矩陣左邊的所有元素個數,nnz_right_all是以t為分割線矩陣右邊的所有元素個數,假設以t為分割線矩陣左邊非零元素占左邊總元素的比例稱為左區均值,其定義如式(1)所示:
(1)
以t為分割線矩陣右邊非零元素占右邊總元素的比例稱為右區均值,其定義如式(2)所示:
(2)
以t為分割線矩陣左邊元素占矩陣總元素的比例ω0的定義如式(3)所示:
(3)
以t為分割線矩陣右邊元素占矩陣總元素的比例的定義如式(4)所示:
(4)
則整個矩陣的均值如式(5)所示:
u=ω0u0+ω1u1
(5)
根據最大類間方差法建立的目標函數如式(6)所示:
g=ω0(u0-u)2+ω1(u1-u)2
(6)
其中,g就是當分割閾值為t時矩陣左右兩邊的類間方差表達式。遍歷整個閾值選取范圍t,使得t為某個值時類間方差最大,則這個值就是HYB格式的分割閾值T。
計算閾值之前,需要對稀疏矩陣A進行預處理。先將稀疏矩陣A按照ELL方式存儲,但不壓縮稀疏矩陣的列,重新排布后的稀疏矩陣記為A′,包含M行、N列。根據經驗,采用一次基于最大類間方差法確定的閾值,COO部分占的比例依然比較大,所以,針對HYB格式最終的閾值選取方法采用的是多次迭代最大類間方差法。一般認為當COO部分的非零元素個數比例低于P時(P定義為COO部分非零元素個數占總非零元素個數的比例)就停止迭代,此時,將多次迭代過程中確定的閾值累加后即為最終的閾值。
多次迭代最大類間方差法的偽代碼如下所示:
輸入:ELL存儲格式稀疏矩陣A′;稀疏矩陣的行數M與列數N;非零元素數量NNZ。
輸出:HYB分割閾值T。
1:floatu0,u1,ω0,ω1;
2:floatg[N];
3:intTtmp=0;
4:initiatet[N];
5:do
6:intNtmp=N-Ttmp;
7:fori=0 toNtmpdo
8: calculateu0,u1,ω0,ω1;
9: calculateg[i];
11:intindex=0;
12:fori=0 toNtmpdo
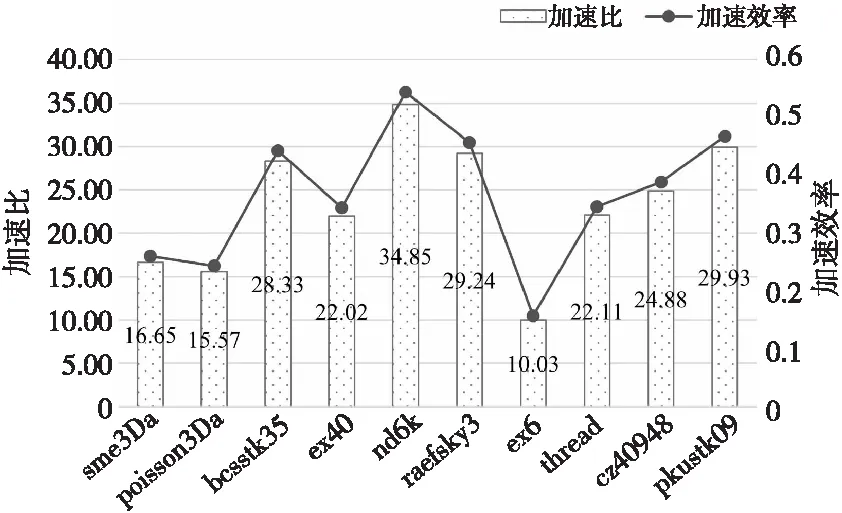
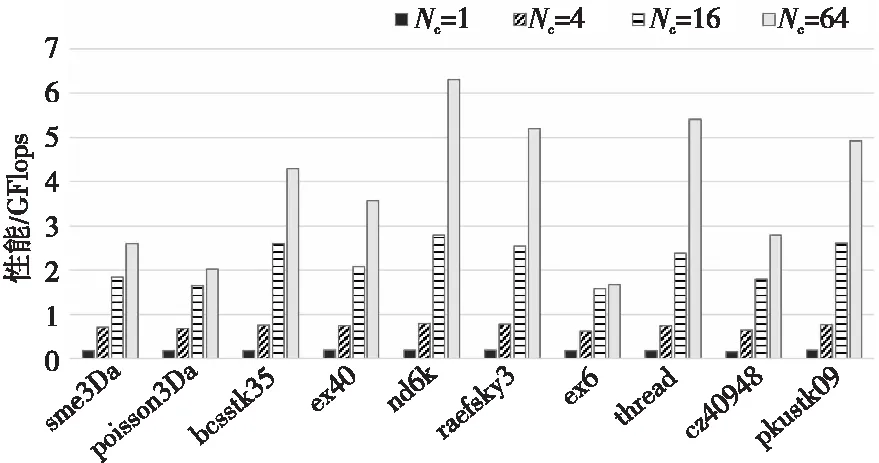
13:ifg[index] 14:index=i; 15:endif 16:endfor 17:Ttmp=index+1; 18:T+=Ttmp; 19: calculatep; 兩權分離度與企業技術創新實證研究——兼論產權性質與業績偏離的調節效應..................................................................................................................................劉 玉 盛宇華(60) 20:ifp 21:break; 22:endif 23:while(1) 24:returnT; 第1~4行:定義一些臨時變量。比如g[N]表示遍歷整個閾值選取范圍t得到的類間方差數組,Ttmp表示每次迭代的臨時閾值。 第6行:Ntmp表示每次迭代過程中稀疏矩陣的列數。 第8~9行:遍歷計算類間方差,結果存放在g[N]數組中。 第11~17行:根據數組g[N]得到最大類間方差所對應的臨時閾值Ttmp。 第18行:將臨時閾值Ttmp累加到閾值T中。 第19~24行:計算COO部分的非零元素數占總非零元素數的比例,結果存放在p中。若小于設定的比例P,則停止迭代,并返回最終的閾值。 HYB格式是由ELL格式和COO格式構成的,其中,ELL格式適合并行處理,COO格式數據分布比較松散,不宜并行處理。因此,針對HYB格式中的ELL部分,采用SW26010P處理器中的從核陣列進行并行SpMV運算,COO部分則在主核上進行串行運算。 定義Np為SW26010P處理器上核組的個數,Nc為每個核組上從核的個數。定義矩陣At為經過閾值劃分后ELL部分的數值矩陣。基于HYB格式的SpMV并行設計分為以下幾個部分: (1)對于單個核組的從核陣列,將矩陣At按行劃分為Nc個塊矩陣(block),每塊含有M/Nc行。每塊矩陣的數值和索引部分和輸入向量x都分配到一個從核上。 (2)由于每個從核256 KB的私有存儲限制,每個塊矩陣又被進一步劃分為多個含有τ行的子塊(subblock)。子塊矩陣的數值和索引部分、輸入向量x以及計算含有τ行的結果向量所占的存儲空間不應超過256 KB。圖6展示了一個基于HYB格式在SW26010P處理器上的SpMV算法并行設計的例子。如圖6所示,A是一個8×8稀疏矩陣,包含26個非零元素,即M=8,N=8,NNZ=26。假設核組的個數Np設置為1,從核的個數Nc設置為2,每個子塊的行τ設置為2,T=3為HYB的劃分閾值。 Figure 6 Example of parallel SpMV design 首先,每個從核需要加載輸入向量x、子塊矩陣的數值和索引部分到LDM空間上;其次,從核進行子塊矩陣與輸入向量x的SpMV計算;最后,將部分計算結果向量寫回到主存中。 如圖6所示,每個從核的子塊矩陣計算后的結果向量記為ycpe,包含τ個元素,將每個從核計算的結果合并成整個向量,記為ycg,ycg就是HYB格式中ELL部分并行計算的結果。從核陣列完成ELL部分的并行計算后,主核完成COO部分的串行運算,并與ycg進行累加后返回最終的計算結果。 對于HYB格式中的并行計算部分,從核先通過DMA的方式加載計算數據到從核LDM上,加載完成后才開始進行SpMV計算,計算完成后再把計算后的數據寫回到主存中,上述過程其實是一個串行執行的過程,在一定程度上會影響SpMV性能,所以,本文采用了雙緩沖機制進行優化。 如圖7所示,雙緩沖機制本質上是一種并行流水技術,它能使計算開銷和通信開銷相互隱藏,從而取得良好的加速效果。具體來說,就是在從核的LDM空間上申請2倍于通信數據大小的存儲空間,以便存放2份同樣大小且互為對方緩沖的數據。對于每個從核,塊矩陣劃分成幾個子塊,一個塊矩陣的SpMV運算就需要幾個輪次子塊的加載、計算和寫回。在串行執行階段,后一個子塊的加載、計算和寫回需要前一個子塊加載、計算和寫回完成后才能進行,采用雙緩沖優化后,除了第1個子塊的加載和最后1個子塊的寫回外,其余子塊的計算和通信存在重疊過程,從而節省一定的時間開銷,提高了SpMV的性能。 Figure 7 Sketch map of double buffers mechanism 根據SW26010P處理器架構,DMA處理部件會把DMA請求拆分成128 B的多次請求來訪問主存數據。非128 B對界的地址,DMA會拆出更多的請求。因此,當主存中的數據地址與128 B對齊,且傳輸的數據量是128 B的倍數時,DMA的傳輸性能就會得到提高。 SW26010P處理器上一個整數占用的內存大小是4 B,一個單精度浮點數占用的內存大小也是4 B。對于并行SpMV設計,每個從核需要加載一個子塊(subblock)的ELL 2個矩陣,矩陣大小為τ行、T列。由于T無法改變,且為了保證ELL 2個矩陣中的元素個數為128/4的倍數,所以,將τ設置為128/4的倍數,以保證數據對齊內存訪問,進一步提高SpMV的性能。 本文實驗使用的測試平臺是SW26010P處理器的單個核組,其訪存帶寬為51.2 GB/s,擁有1個主核和8×8的從核陣列。測試選擇的稀疏矩陣樣例都來自于UF Sparse Matrix Collection[20],即佛羅里達大學的稀疏矩陣集合。表1展示了測試用的10個稀疏矩陣樣例。 Table 1 Test examples of sparse matrices 在本文實驗中,通常將P設置為0.5%,但是為了獲得更好的性能,P值可以進一步調整。為了驗證本文設計的SpMV算法的加速效果,使用加速比(Speedup)和加速效率作為評價標準,同時采用GFlops作為性能測試單位。其中,加速比定義為算法的并行執行時間與串行執行時間的比值,加速效率定義為加速比與從核個數的比值,GFlops定義為2倍的稀疏矩陣非零元素的個數與算法的并行執行時間的比值。GFlops數值越大,表明算法性能越好。 圖8展示了基于HYB格式的并行SpMV設計在單個核組(CG)上實現的加速比和加速效率,使用了64個從核(CPE)。加速比是通過計算基于HYB格式在單個CG上的并行SpMV計算時間與在一個主核上的串行計算時間的比值獲取的,加速效率則是加速比與從核個數的比值。 Figure 8 Speedup and efficiency of the parallel SpMV design on single CG 如圖8所示,本文所設計的并行SpMV算法在單個CG上可以獲得平均23.36的加速比,平均的加速效率為36.50%,其中,在稀疏矩陣nd6k上獲得最高加速比34.85,加速效率為54.45%;在稀疏矩陣ex6上獲得最低加速比10.03,加速效率為15.67%。結合圖8的加速比、加速效率和表1中測試矩陣的規模,可以看出,在稀疏矩陣規模比較大的情況下,本文設計的并行SpMV算法加速效果優于規模比較小的情況。除此之外,算法的平均加速效率偏低,這主要受制于ELL部分數據在主從核之間的通信開銷。 圖9展示了主核上串行SpMV算法、使用64個從核的并行SpMV算法以及采用雙緩沖優化和DMA傳輸帶寬優化技術后的并行算法的性能對比。串行SpMV算法的性能由標簽“MPE”表示,使用64個從核的并行SpMV算法的性能由標簽“MPE+CPE”表示,采用雙緩沖優化后的性能由標簽“MPE+CPE with DB”表示,采用DMA傳輸帶寬優化后的性能由標簽“MPE+CPE with TB”表示。采用DMA傳輸帶寬優化技術后,設計的并行SpMV算法性能平均提升了5.93%,最高提升了13.26%,最低提升了1.55%。采用雙緩沖優化技術后,設計的并行SpMV算法性能平均提升了16.30%,最高提升了44.44%,最低提升了2.48%。ex6和ex40稀疏矩陣性能提升比較小,這是因為數據規模比較小時,分到每個從核的數據運算速度快,而數據加載與寫回動作的發起需要耗費時間,從而無法有效地進行計算訪存重疊,因此,采用雙緩沖優化的效果不顯著。 圖10展示了設計的并行算法在從核上的并行可擴展性,并給出了并行算法在不同從核數量下的性能對比。設置的從核數量Nc分別為1,4,16和64。當從核個數為64時,本文設計的算法在稀疏矩陣nd6k上最高可獲得6.31 GFlops的性能。隨著從核個數的增加,基于HYB格式的異構并行SpMV算法的性能也在逐步提升,這是因為從核數量越多,同一時間內處理的矩陣數據就越多,所消耗的時間就越少,并行性能越好。然而,隨著從核個數的增加,性能雖在不斷提高,但是增長比例卻在逐漸下降,這主要是主核與從核之間的通信開銷以及從核之間爭奪計算資源導致的額外開銷造成的。 Figure 10 Performance of the parallel SpMV design with different CPEs 稀疏矩陣向量乘法在高性能計算領域中占有重要地位,是數據分析、深度學習等應用領域中非常重要的核心算法之一。本文根據新一代申威處理器SW26010P的計算架構和內存模式,提出了一種基于HYB格式的異構并行設計方案,并對HYB格式的并行計算部分采用了通信與計算相互隱藏的優化技術,同時,針對HYB格式閾值選取難的問題,提出了一種多次迭代的自適應閾值確定方法。測試結果表明,在單個核組下,本文提出的異構并行SpMV算法最高可以獲得6.31 GFlops的性能,采用DMA傳輸帶寬優化技術后,最高可獲得13.26%的性能提升,采用雙緩沖優化技術后,最高可獲得44.44%的性能提升。但是,目前實現的算法都是基于單個核組的,面向SW26010P處理器的多核組結構的并行SpMV設計還有待研究,并且針對其他稀疏矩陣存儲格式在SW26010P處理器上的實現和優化也是一個值得探究的問題。4.3 HYB格式的SpMV并行設計
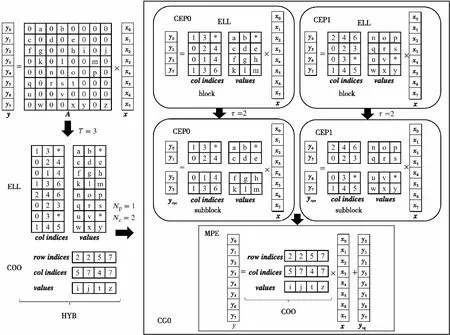
5 SpMV并行設計優化技術
5.1 雙緩沖優化
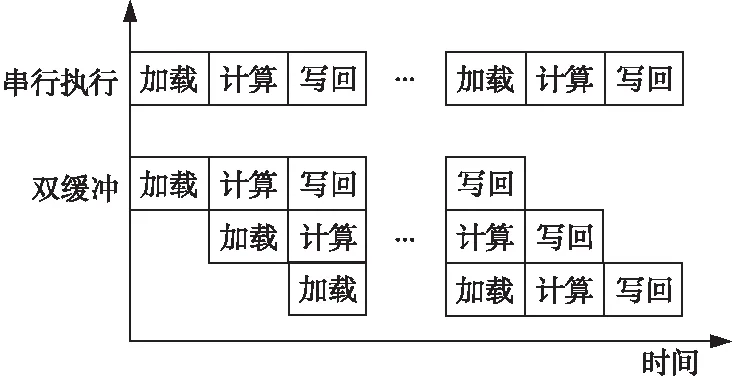
5.2 DMA傳輸帶寬優化
6 實驗與結果分析
6.1 實驗環境
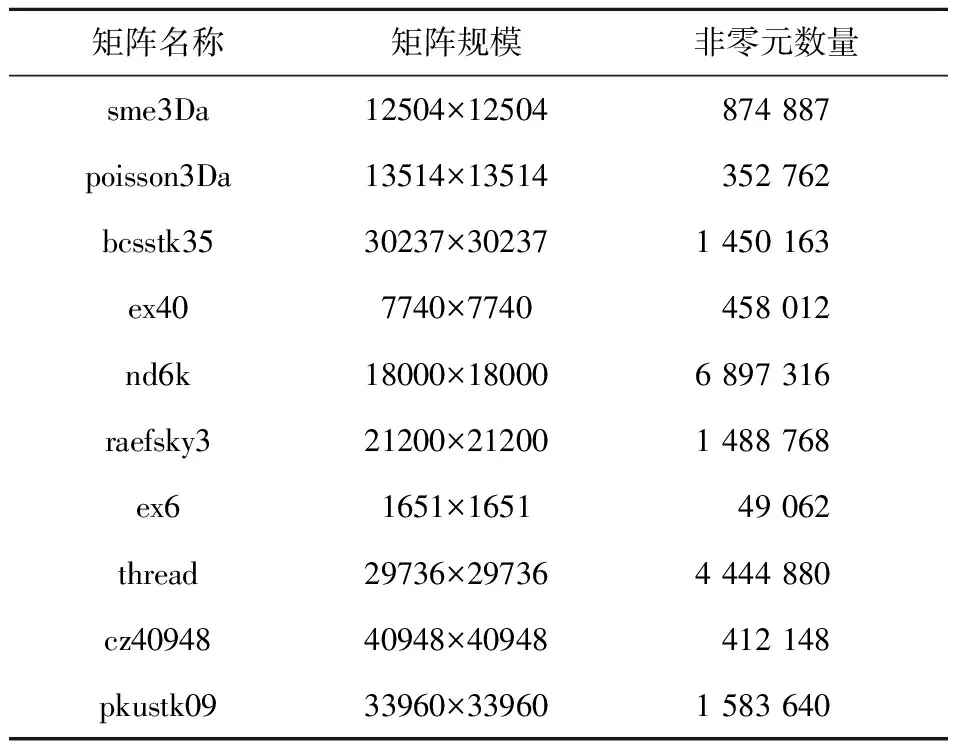
6.2 實驗結果分析
7 結束語
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14能源工程(2022年1期)2022-03-29 01:06:28建材發展導向(2021年12期)2021-07-22 08:06:48建材發展導向(2021年7期)2021-07-16 07:07:52中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50今日農業(2020年16期)2020-12-14 15:04:59消費導刊(2018年8期)2018-05-25 13:20:08家庭影院技術(2018年4期)2018-05-09 07:07:41電子制作(2017年20期)2017-04-26 06:57:45
