
煤礦瓦斯爆炸事故致因選取與風險等級預測
2023-10-26 07:50:06郝秦霞尚海濤
煤礦安全 2023年10期
郝秦霞 ,尚海濤
(1.西安科技大學 通信與信息工程學院,陜西 西安 710054;2.西安科技大學 安全科學與工程學院,陜西 西安 710054)
煤礦的安全生產是煤礦行業健康有序發展的重要保證,以人民至上,生命至上,防范化解重大風險隱患為根本,我國提出將煤礦瓦斯風險事故防控工作的重點從事后響應向事前預防轉移的號召,通過對煤礦瓦斯風險隱患預測關口前移,防范瓦斯安全事故于未然,從而遏制煤礦瓦斯事故風險。已有大量學者對瓦斯爆炸風險預控進行研究,主要包括事故風險預測與評估的研究[1];事故致因指標與機理的研究[2];事故致災影響的研究[3]等。袁亮[4]通過大數據分析和數據挖掘提出煤礦動力災害風險判識和監控預警模型;李爽等[5]通過貝葉斯網絡提取多級預測指標構建煤礦風險變化趨勢多級預測模型;田水承等[6]對近年來煤礦瓦斯事故調查報告進行分析,得到4 項關鍵致因和27 項一般致因;徐美玲等[7]從人為因素、生產設施、環境條件和管理組織多個角度分析煤礦瓦斯爆炸風險因素;魯錦濤等[8]通過以往瓦斯爆炸案例提取影響因素,構建灰色-物元的瓦斯爆炸風險評估模型;DEY Prasanjit 等[9]構建了混合CNN-LSTM 預測模型,從礦山物聯網傳感器監測數據中提取空間和時間特征,有效預測不同的礦山災害;DURSUN A E[10]對近年來土耳其煤礦發生的瓦斯爆炸事故進行了統計分析,并針對瓦斯事故提出了相應的防控措施;JUGANDA A 等[11]采用計算流體動力學(CFD)模擬長壁礦井大規模爆炸,評估瓦斯爆炸對礦井通風的影響。
1 文獻分析
對于已有的瓦斯爆炸風險的研究發現,在瓦斯爆炸事故的風險預測研究中,存在以下問題:
1)以往對于瓦斯爆炸事故致因的分析多以經驗分析法,如:客觀權重分配法、主觀層次分析法或二者結合。對實際情景、知識體系與經驗分析的綜合考慮不足。
2)以往對于瓦斯爆炸風險的預警大多基于時序、空間實時監測信息的預警,但瓦斯爆炸的隱患來自“人-機-環-管”等多方面彼此獨立或相互影響的事故致因。
3)煤礦企業中對于風險的預警大多是基于算法模型的判斷,但因地質環境、開采情況、監測條件等實際情景的差異,算法給出的預測值會出現虛警、誤判,造成煤礦企業安全監管人員的懈怠思想。
綜合以上問題,對于煤礦瓦斯爆炸事故致因的選取需結合煤礦實際情景、相關知識體系以及歷史經驗,從可能產生隱患的人員行為、監測數據等多角度考慮事故致因。對于瓦斯爆炸風險的預警,需要符合煤礦實際情景做出風險等級的分類評判,為了進行準確的風險類別預警,需采用模式分類性能較優的神經網絡,以便煤礦企業安全監管人員針對風險的等級給出相應的安全防范措施。
2 基于灰色關聯分析的事故致因選取
產生煤礦瓦斯爆炸的原因多樣,企業采取的防控措施多以專家經驗為主,但不同煤礦具有不同生產條件與特征,且在生產過程中積攢了大量具有可供參考的歷史紀錄。因而在分析煤礦瓦斯爆炸事故致因時,需多方面考慮并結合煤礦瓦斯安全防控的知識體系,形成多維度的事故致因。
根據以上對事故致因選擇的要求,采用陜西省彬縣某礦2012 年12 月至2021 年12 月間的監測數據,結合煤礦安全生產網、國家礦山安全監察局、國家礦山安全局、各省級局官方網站以及全國煤礦事故調查資料,收集近10 年來煤礦瓦斯爆炸事故案例調查報告并整理為文本集。事故致因提取的具體步驟如圖1。
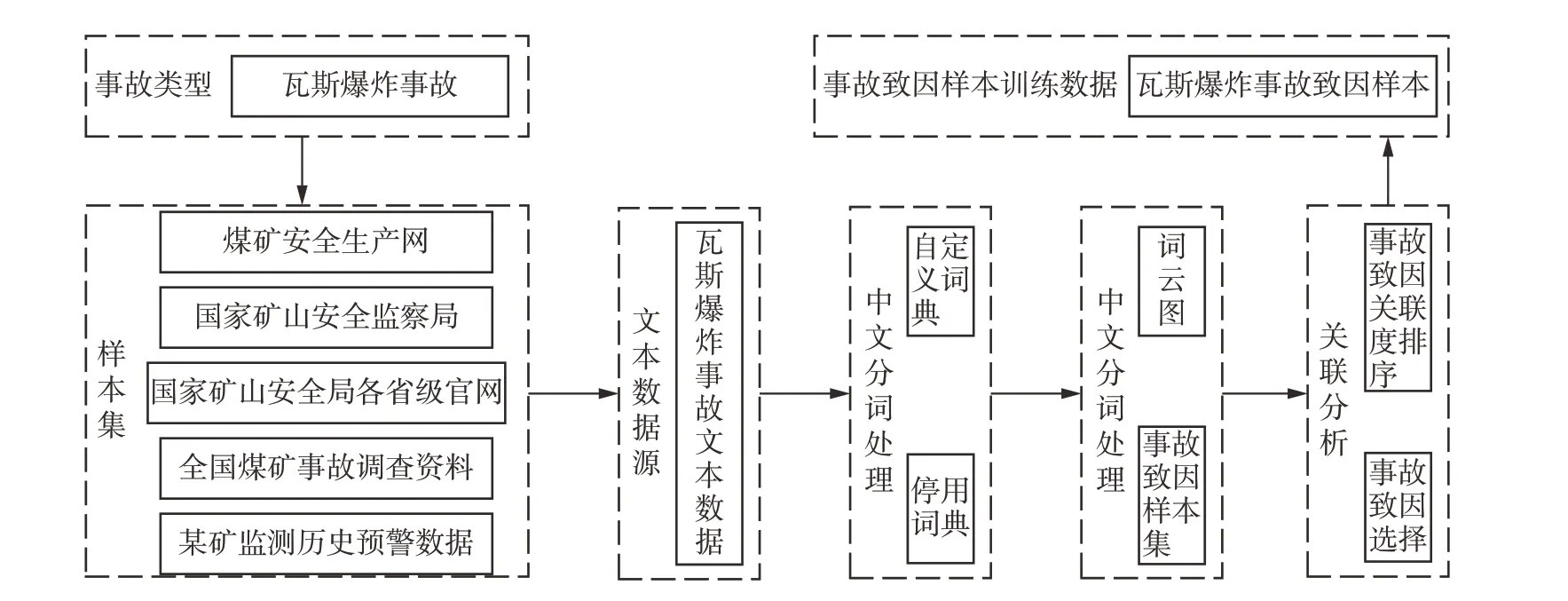
圖1 煤礦瓦斯爆炸事故致因提取流程Fig.1 Extraction process of causes of coal mine gas accidents
首先對文本集數據進行清洗,將未記錄事故致因的內容刪除,保留事故發生時間、地點、影響結果以及原因等內容。通過R 語言Jieba 程序包對文本集進行分詞處理,采用自定義詞典和停用詞典提高分詞的準確性,提取案例報告中的事故致因。自定義詞典內容主要是百度輸入法詞庫中的煤礦術語、采礦專業領域詞匯和搜狗輸入法細胞詞庫中采礦工程、安全工程、煤礦災害預防、煤礦工作、煤礦分析、煤炭能源、煤炭行業等領域專業詞匯,停用詞典主要是去除分詞處理后數據中存在的一些沒有實際意義而詞頻較高的詞。
以礦區的煤礦瓦斯爆炸事故案例為例,經過分詞處理得到源于人、環境、機器以及管理等61項事故致因。煤礦瓦斯爆炸事故致因見表1,所提取事故致因符合《煤炭工業企業職工傷亡事故報告和統計規定》。
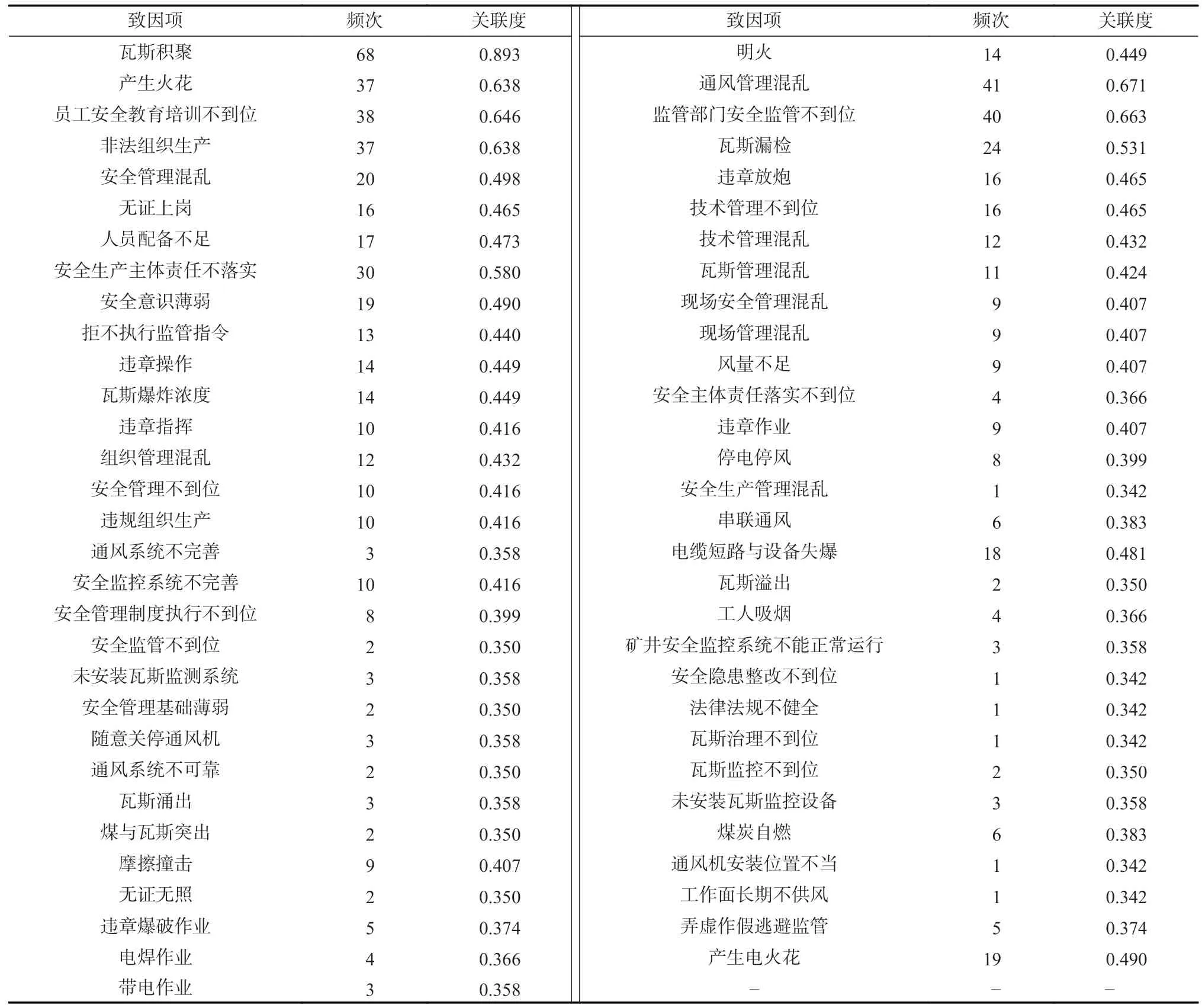
表1 煤礦瓦斯爆炸事故致因Table 1 Causes of gas explosion accidents in coal mines
鑒于事故致因條目過多,且不具備連續變量數值的特征,因而利用GRA 減少信息不對稱性,降低維度,并通過量化關聯度大小選取更符合實際情景的事故致因。
由于歷史案例樣本報告來源的不唯一性,因而設置狀態標志位“0”“1”,1 條案例數據樣本中對事故產生影響的事故致因設置為“1”,未產生影響的事故致因設置為“0”。煤礦瓦斯爆炸事故致因(F1~F6)狀態設置見表2。
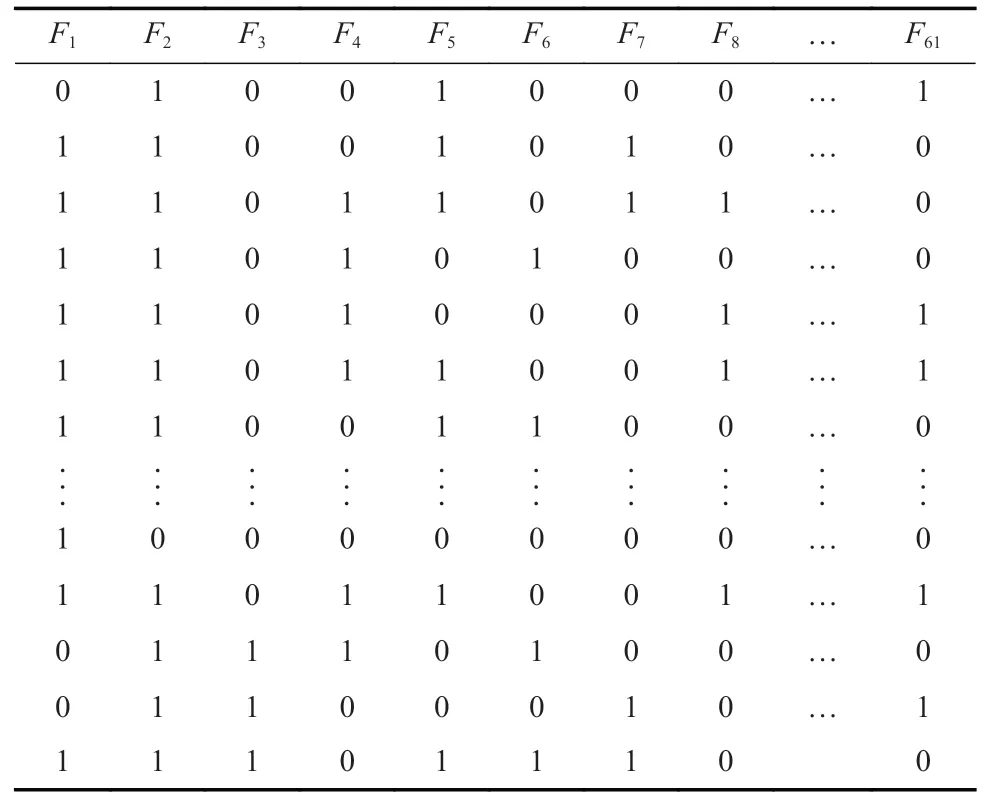
表2 煤礦瓦斯爆炸事故致因狀態設置Table 2 Setting of the cause state of gas explosion accidents
對事故致因 Fi(i=1,2,···,61)與瓦斯爆炸事故等級的關聯關系采用GRA 進行分析,分辨系數取值0.50,根據關聯系數公式計算出關聯系數值,關聯系數計算如下:
式中:Fi(k)為 第i條 案例報告中第k項事故致因狀態值;Y(k)為 第k條 案例報告中事故等級; ρ為分辨系數; ξi(k)為 在k條 記錄Fi對事故等級的關聯系數。
根據關聯系數值計算出關聯度值進行評價參考, 關聯度計算如下:
式中:Ri為各事故致因與煤礦瓦斯事故之間的相似關聯程度,由關聯系數進行計算平均值得出。
關聯度越大表示事故致因與煤礦瓦斯事故相關性越強。結合關聯度大小,對所有事故致因進行排序,可以得到對煤礦瓦斯爆炸事故影響較大的事故致因,在此基礎上結合煤礦的實際情景選取輸入到PNN 網絡中的特征向量。
3 瓦斯爆炸風險等級預測
3.1 預測模型設計
煤礦瓦斯風險等級預測是分析事故致因狀態后預測風險存在的可能性,并將其按照風險等級的類別劃分。PNN 總收斂于貝葉斯最優解,分類性能上與最優貝葉斯分類器等價,因而選用概率神經網絡,將多種狀態特征的事故致因做為預測模型的輸入特征向量,進行瓦斯爆炸風險等級的分類預測。瓦斯爆炸風險等級預測模型如圖2。
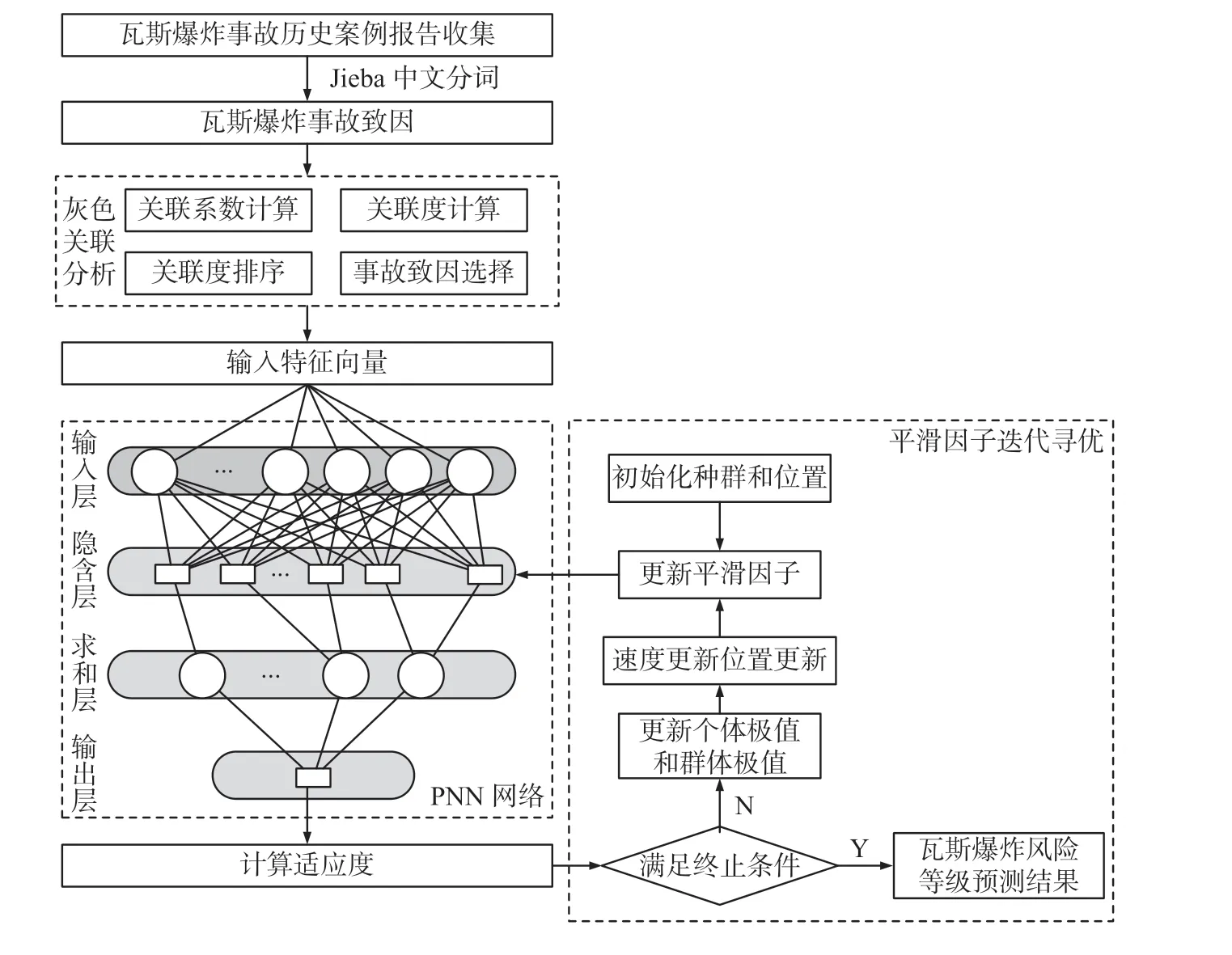
圖2 瓦斯爆炸風險等級預測模型Fig.2 Prediction model of gas explosion risk grade
在PNN 中預設平滑因子 σ易造成模型識別率低、誤分類等問題, σ取值需符合實際樣本數據特征。RWPSO 能有效改善 σ僅憑經驗取值所帶來的缺陷,因而用其對PNN 的 σ取值進行迭代尋優,提高網絡模型的預測準確率。
預測過程如下:
1)在瓦斯爆炸文本數據源中提取事故致因并采用GRA 選取模型輸入特征向量。
2)采用RWPSO 對PNN 中的 σ進行迭代尋優,實現 σ的自適應調整。
3)結合最優 σ對瓦斯爆炸風險等級進行分類預測,得到最優的預測準確率。
選取網絡實際輸出與理論輸出的總數比值作為模型的評價指標f,計算公式為:
式中:Y?為網絡實際輸出與期望輸出相同的樣本個數;Y為網絡實際輸出的樣本總數。
由于煤礦瓦斯風險事故致因特征包括數據類型多樣,但數據表現形式僅為“0”“1”,因而模型可以拓展運用到數據樣本具有連續數值特征的預測中,如:電動汽車故障診斷[12]、電網分區故障診斷[13]等領域中 。
3.2 基于隨機權重策略的粒子群算法
RWPSO 隨機選取慣性權重 ω,隨機產生粒子歷史速度對當前速度的影響。
若S維搜索空間內存在由n個粒子組成的群體X,X=[x1,···,xn]。群體中粒子速度和位置更新方式:
式中:c1、c2為學習因子;vis為當前粒子的變化速度;xis為當前粒子的變化位置;pis為當前粒子搜尋的最優位置;pgs為當前種群搜尋的最優位置; ω為隨機選取慣性權重因子;r1、r2分別為0~1 之間的隨機數。
ω更新公式如下:
式中: μ為權重因子; μmax、 μmin為權重因子的變化范圍; θ為權重隨機變化的大小;N(0,1)為標準正態分布的隨機數; rand(0,1)為0~1 范圍內的隨機數。
通過引入 ω改善了種群在迭代初期局部搜索能力不足和后期全局搜索能力不足問題,提高了算法的收斂速度[14]。能有效應對PNN 中 σ的自適應調整。
3.3 RWPSO 迭代尋優平滑因子
PNN 網絡中的隱含層用于計算輸入數據與各模式的歐式距離, σ的取值直接影響瓦斯爆炸風險預測準確率。隱含層的輸入/輸出定義如式(7)。
式中: σ為平滑因子;d為樣本維數;xi j為 第i類樣本中第j個樣本值。
PNN 中的 σ是Parzen 窗估計方法中高斯核帶寬控制的參數,控制徑向作用的范圍,不同 σ的高斯核函數對樣本數據映射范圍如圖3。
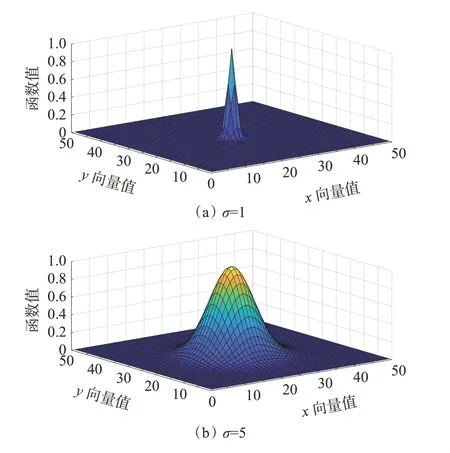
圖3 σ對高斯核函數的影響Fig.3 The influence of σ on Gaussian kernel function
由圖3 可以看出,高斯核函數的局部影響范圍隨著 σ取值的增大而增大。隨機選取的 σ會引起PNN 不能正確判斷遠離輸入樣本的未知模式,容易引起網絡識別率低等問題,從而影響瓦斯爆炸風險等級分類預測的準確率。因此實際樣本訓練中,需采用優化算法迭代選取適合當前訓練樣本數據的 σ。
RWPSO 優化PNN 中的 σ步驟如下:①初始化種群中各個粒子的vi和xi;②將網絡模型預測準確率作為RWPSO 的適應度函數,選取最優適應度粒子的xi作 為種群的位置;③更新粒子的vi和xi;④計算粒子更新后個體的適應度,若更新后的適應度優于之前的個體適應度,則將更新后的適應度記為當前粒子的個體最優適應度;⑤若更新后粒子的適應度優于之前時刻種群所有粒子的適應度,則將更新后適應度記為當前種群的群體最優適應度;⑥判斷是否滿足終止條件,未滿足返回步驟3,滿足條件則輸出最優解。
4 模型仿真
依據《煤礦生產安全事故報告和調查處理規定》將事故等級按照所造成的傷亡人數劃分為:一般事故(對應輸出值2)、較大事故(對應輸出值3)、重大事故(對應輸出值4)和特別重大事故(對應輸出值5)。實驗選取100 組數據進行驗證,將70 組數據用作模型的訓練樣本,30 組數據用作模型的測試樣本,取關聯度在0.416 及以上的共27項事故致因作為特征向量對PNN 進行樣本訓練和測試,進行瓦斯爆炸風險等級的分類預測。當 σ值為1 時,PNN 的預測效果如圖4。
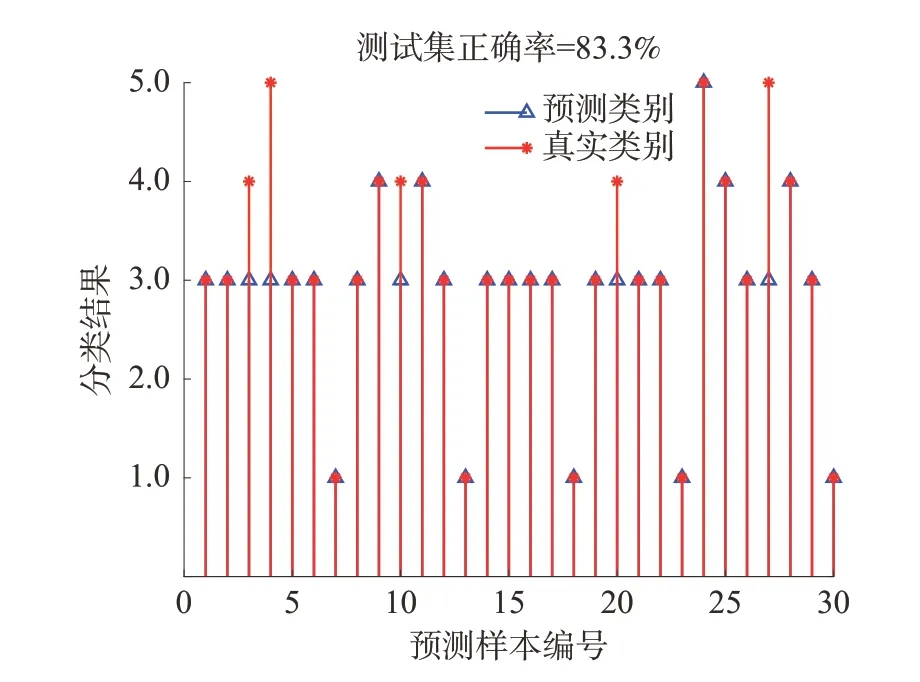
圖4 PNN 預測效果Fig.4 PNN prediction effect
當選取 σ為1 時,預測準確率為83.3%,30 組測試樣本中錯誤預測5 組,并且訓練誤差中出現負值,表明 σ選取較大。采用RWPSO 對PNN 的 σ選取進行優化,迭代次數選擇為40,粒子個數為20,學習因子設置為2,優化后的預測效果如圖5。
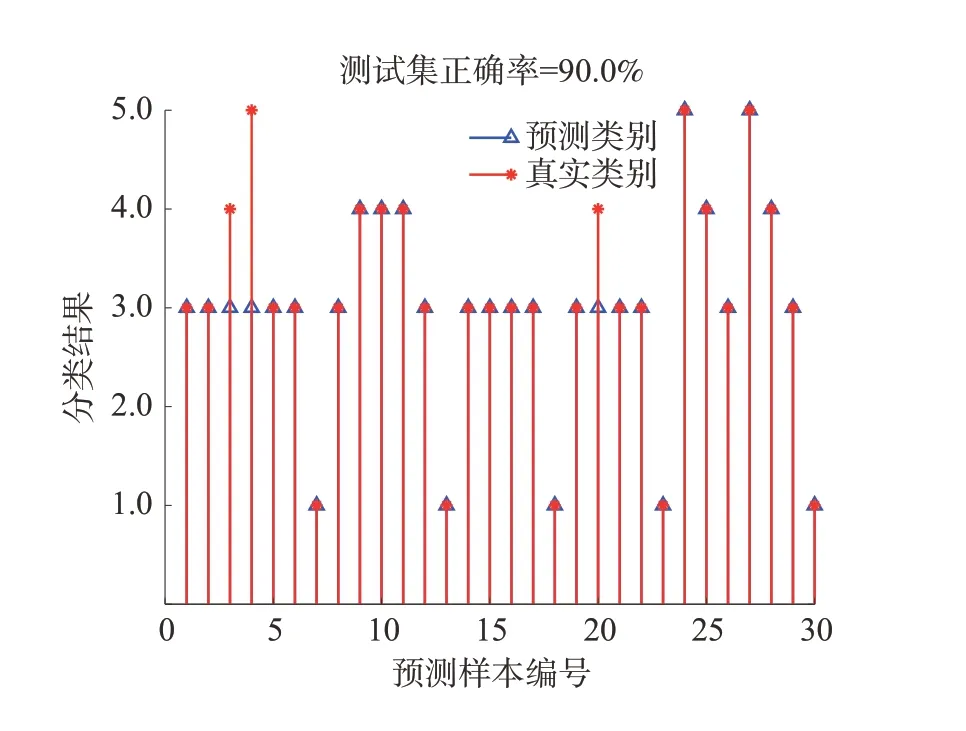
圖5 σ優化后預測效果Fig.5 Prediction effect after σ optimization
此時 σ值為0.814,RWPSO-PNN 預測準確率為90.0%,30 組測試樣本中錯誤預測3 組,有效實現分析事故致因狀態后對瓦斯爆炸風險等級的分類預測,煤礦安全監管人員可根據模型預測的風險等級做出相應的安全防控措施。
PSO 算法的時間復雜度由迭代次數N和問題規模M共同決定,因而在N與M給定情況下,RWPSO與PSO 算法的時間復雜度為O(M?N),且RWPSO對隨機初始種群參數進行了調節,提高了算法收斂速度,證明此算法滿足實際應用需求。在實際應用過程中可對N與M進行調節,縮減算法運行時間,增加模型實用性。選取瓦斯爆炸預測中較為常用的BP 神經網絡、極限學習機ELM、支持向量機SVM 算法作為對比算法,分別對煤礦瓦斯爆炸風險等級進行分類預測。RWPSO-PNN 與對比算法在煤礦瓦斯爆炸風險等級分類預測的準確率見表3。

表3 預測準確率對比Table 3 Comparison of prediction accuracy
由表3 知:RWPSO-PNN 錯誤預測為3 次,預測準確率達到90%,平均絕對誤差(MAE)為0.133 明顯優于對比算法。
5 結 語
根據煤礦瓦斯爆炸事故報告、案例以及知識體系選取多種狀態的特征數據,作為煤礦瓦斯爆炸風險等級預測的事故致因,從多角度實現煤礦安全預警。基于RWPSO-PNN 建立風險等級的判定,使煤礦安全監察人員可以根據風險等級的預測制定相應的安全防控措施。預測模型中,利用隨機權重策略改進粒子群算法后,迭代尋優平滑因子,有效實現概率神經網絡中平滑因子的自適應調整。縱向對比常用的BP 神經網絡、極限學習機ELM、支持向量機SVM 算法,實驗結果顯示RWPSO-PNN 在預測準確率高于其他算法。實驗證明RWPSO-PNN 在煤礦瓦斯爆炸風險等級分類預測中的準確率更優。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
工業設計(2016年4期)2016-05-04 04:00:23
核科學與工程(2015年4期)2015-09-26 11:59:03
現代企業(2015年8期)2015-02-28 18:55:34
現代企業(2015年6期)2015-02-28 18:51:50
河南科技(2014年8期)2014-02-27 14:08:07
河南科技(2014年8期)2014-02-27 14:07:44
