基于Hadoop的電商大數據可視化設計與實現
2023-10-27 00:50:27李威邱永峰
現代信息科技 2023年17期
李威 邱永峰

摘? 要:為滿足眾多電商對電商大數據可視化的迫切需求,基于Hadoop開源大數據處理平臺,依托FineBi大數據分析工具設計一款大數據可視化分析系統,該系統可提供數據預處理、存儲、分析、可視化等一整套流程。測試結果表明,該系統能夠實現電商大數據的可視化分析,可為用戶提供高效、實用的信息處理,為其未來的業務經營指明方向,提高店鋪運營效率。
關鍵詞:Hadoop;Hive;HDFS;可視化分析;電商大數據
中圖分類號:TP311 文獻標識碼:A? 文章編號:2096-4706(2023)17-0046-04
Design and Implementation of E-commerce Big Data Visualization Based on Hadoop
LI Wei1, QIU Yongfeng2
(1.College of Computer Science, Hunan University of Technology, Zhuzhou? 412007, China;
2.Hunan Tianqiao Jiacheng Intelligent Technology Co., Ltd., Zhuzhou? 412007, China)
Abstract: To meet the urgent demand for E-commerce big data visualization in many E-commerce platforms, a big data visualization analysis system is designed based on the Hadoop open-source big data processing platform and FineBi big data analysis tool. The system can provide a complete set of processes such as data preprocessing, storage, analysis, and visualization. The test results indicate that the system can achieve visual analysis of E-commerce big data, provide efficient and practical information processing for users, point out the direction for their future business operations, and improve store operation efficiency.
Keywords: Hadoop; Hive; HDFS; visualization analysis; E-commerce big data
0? 引? 言
隨著信息技術的快速發展,目前的數據量呈幾何級增長[1]。中國信息通信研究院于2023年1月4日發布的《大數據白皮書》中顯示,我國大數據產業規模高速增長,2021年增加到了1.3萬億元,復合增長率超過30%。與此同時,電商領域產生的數據也不斷增長[2],越來越多的電商企業和組織意識到大數據的重要性。然而,電商大數據的處理和分析面臨著諸多挑戰,其中迫切需要解決的問題是如何將復雜海量的電商大數據通過可視化的方式進行呈現和分析。大數據可視化是一種通過圖形化方式呈現大數據的技術,幫助用戶發現數據中隱藏的規律和趨勢[3],文章使用此技術提高電商領域數據分析的準確性和效率。
在大數據可視化方面,Hadoop分布式計算平臺[4,5]是最近興起的熱門工具,具有高效率、高可靠性和可擴展性的特點[6,7],同時支持大規模的數據挖掘和分析[8]。因此,文章基于Hadoop分布式計算平臺,設計和實現了一種電商大數據可視化分析方案。
1? 技術分析
1.1? Hadoop平臺核心技術
Hadoop是一個開源的分布式計算框架,旨在處理大規模數據集,其核心是分布式文件系統 (Hadoop Distributed File System, HDFS)和Map Reduce(并行處理架構)。要實現電商數據可視化,除了Hadoop本身的核心框架(HDFS+Map Reduce),還需要Hive數據倉庫工具和FineBi大數據分析工具的協同配合。
1.2? FineBi數據分析工具
FineBi是一款國產的數據分析工具,能夠對原始數據進行抽取、轉換、加載,通過豐富的圖表進行展示,并且能為用戶提供可交互的處理模式。本系統將根據應用場景,將前期電商大數據處理的結果,采用FineBi進行可視化展示,以直觀、易懂的方式展示這些信息。
本系統中電商大數據可視化的處理流程如下:第一,采集數據并導入到HDFS中;第二,通過Hive數據倉庫工具進行數據處理;第三,對數據進行篩選、預處理等,并將結果數據存入數據庫;第四,對數據進行分析統計,導入到FineBi大數據分析工具中實現電商大數據的圖表或動畫模式呈現。
2? 系統的設計與實現
2.1? 系統設計流程與核心需求
電商大數據可視化是基于電商企業的業務數據構建的,需要先將數據進行采集和處理,存儲到分布式數據庫中,再把分散的數據集成到Hadoop集群中,完成初始數據收集。根據可視化需求構建數據空間,并以此搭建Hive預處理數據庫,將數據加載到便于檢索、查詢的Hive數據庫中,然后利用類SQL語句對數據進行查詢分析,并將查詢結果存入HBase數據庫中,接下來將相應的查詢結果與可視化的設計主題相結合,構造相應的數據庫、數據表以便展示,最后使用FineBi可視化分析工具對分析模型進行圖形可視化呈現。
2.2? Hadoop平臺的搭建及處理
采用集群模式安裝部署Hadoop,這種模式也叫作分布式模式,具體的工作流程如下:
1)集群角色規劃。根據軟件工作特性和服務器硬件資源情況合理分配,比如依賴內存工作的NameNode應該部署在大內存機器上;資源上有搶奪沖突的,盡量不要部署在一起;工作上需要互相配合的,盡量部署在一起。
2)服務器基礎環境準備。多臺機器構成的集群,相互之間的防火墻應該關閉,因為在內網或者局域網環境當中,如果將防火墻打開,許多端口將會被屏蔽,分布式軟件之間通信會中斷,為了防止通信中斷,我們需要將每個節點的防火墻都關閉。除此之外,還需要對各個節點進行時間同步,如果節點之間時間不同將會導致一些不必要的錯誤。至此完成服務器基礎環境準備。
3)上傳安裝包,配置環境變量。本系統選擇的是JDK 1.8版本的安裝包,上傳之后配置好環境變量,使得在任何環境下都可以使用相關命令。之后上傳、解壓Hadoop安裝包,選擇的是Hadoop 3.3.0版本的安裝包,解壓完之后編輯、配置Hadoop環境變量。
當配置好之后,輸入命令start-all.sh,啟動Hadoop集群,一個命令即可啟動DataNode、NodeManager、NameNode和ResourceManager,這樣Hadoop集群就啟動成功了。使用jps命令驗證Hadoop集群是否成功啟動,如圖1所示,Hadoop集群運行成功。
2.3? Hive數據倉庫的搭建及處理
Hive是一款基于Hadoop的數據倉庫軟件,通常部署運行在Linux系統之上,在啟動Hive之前必須先啟動Hadoop集群。
1)安裝MySQL數據庫。因為這里采用遠程模式,不再使用內置的Derby,而是使用數據庫進行元數據的存儲。在這里MySQL只需要在一臺機器中安裝即可,不需要每臺機器都安裝,通過Hadoop集群共享資源。安裝好MySQL之后,就可以上傳解壓Hive安裝包。
2)安裝Hive。同樣的,Hive不需要在每臺機器中都安裝,只需要在集群當中挑選一臺安裝即可,因為Hive雖然本身不是分布式的軟件,但是卻具有分布式的能力。
3)啟動Hive。當配置好Hive之后,啟動Hive,這里使用遠程模式,不能自動啟動,需要單獨啟動,Hadoop官方提供了兩種啟動方式,一種為前臺啟動,另一種為后臺啟動。所謂前臺啟動,啟動之后進程會一直占據終端,使用“ctrl+c”可以結束進程、關閉服務,使用此種方法可以獲取詳細日志信息,便于排錯。后臺啟動不會占據終端,啟動方式也更加簡單,在一般情況下使用后臺啟動的方式來啟動Hive,其命令為:
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore&
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
4)對數據進行操作。在Hive數據倉庫中,最底層便是每個數據表中的記錄,比如訂單記錄、消費記錄等,在數據表的上面便是數據庫。啟動Hive后,使用Hive對各個數據庫進行增刪改查。雖然可以直接在Hive自帶的客戶端beeline中對數據進行操作,但在實際的開發環境當中,一般會選擇Hive的第三方可視化客戶端,主流的有DataGrip、Dbeaver、SQL Client等,這些軟件都可以在Windows、Mac平臺上運行,通過JDBC協議訪問HiveServer2服務,實現對數據的操作。這類第三方可視化客戶端相比于Hive自帶的客戶端beeline,操作更加簡潔,智能化程度更高。
2.4? 上傳數據至HDFS
開啟Hadoop集群后,在瀏覽器中輸入node1:9870,即可打開HDFS的Web界面,從而可以上傳符合要求的輸入數據。
2.5? 數據可視化分析
本文使用FineBi可視化分析工具進行圖像繪制。同時,為了滿足某些特殊需求,在可視化工具無法實現的情況下,可以采用自定義的可視化算法去實現。其中大數據分析流程部分如圖2所示。
整個可視化分析具體步驟如下:
1)鏈接Hive,并獲取數據,根據具體可視化需求,通過類SQL語句查詢數據。
2)根據可視化需求,利用相關數據庫表和數據集得到樣本相關信息并繪制圖表,從而進行可視化展示。
下面分析某電商網站數據:
1)每年的下單總金額分析,操作原理是從eCommerce_msg.tb_msg_etl表中選取每天的下單金額,以年為分組進行求和,其命令操作如下所示:
create table if not exists tb_rs_total_amount_sum
comment "每年總下單金額"
as
select
yearInfo,
sum(order_amount) as order_amount_sum
from eCommerce_msg.tb_msg_etl
group by yearInfo;
分析結果如圖3所示。
從圖中可以看出,該網站在19年下單總金額暴增,大約是18年的三倍,到了20年銷量較為平緩,且有輕微下降趨勢。
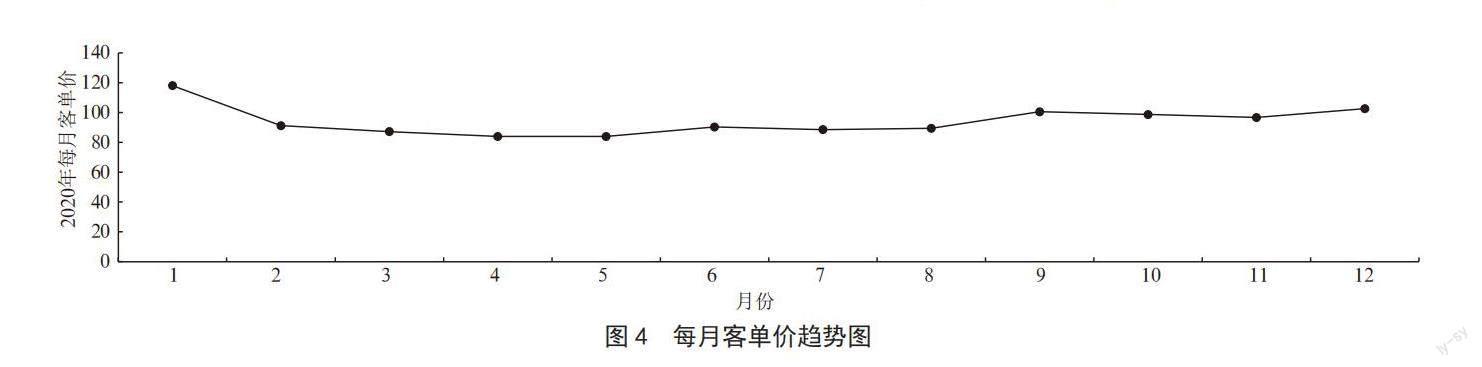
2)每月客單價分析,操作原理是從eCommerce_msg.tb_msg_etl表中選取每天的客單價,以月為分組求平均值,選取數據的年份為2020年,其命令操作如下:
create table if not exists per_ticket_2020
comment "2020年每月的客單價"
as
select
monthInfo,
round(avg(per_ticket),2) as per_ticket_month
from eCommerce_msg.tb_msg_etl
where (yearInfo) = "2020"
group by monthInfo;
分析結果如圖4所示。
從圖中可以看到,客單價在第一個月是最高的,后續較為平緩,且在年末有回升跡象。
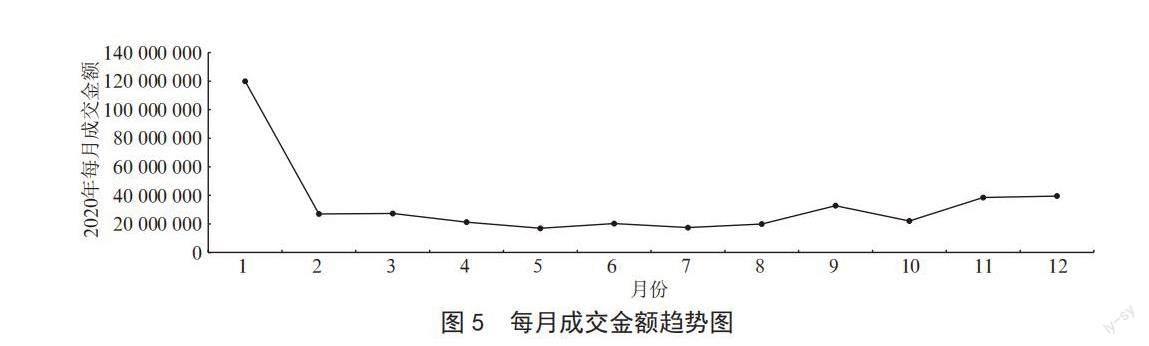
3)每月的成交金額統計,操作原理是從eCommerce_msg.tb_msg_etl表中選取每天的成交金額,以月為分組求和,選取數據的年份為2020年,關鍵代碼為:round(sum(amount),2) as amount_month_sum
分析結果如圖5所示。從圖中可以看出,銷售金額在第一個月也是最高的,并且遠遠高于其他月份的銷量。
4)商品銷售種類分析,操作原理是從eCommerce_msg.tb_msg_etl表中選取每天銷售商品的類型和數量求和,利用FineBi設置銷售量多的商品類型進行放大顯示,銷售量少的商品類型縮小顯示。選取的年份為2020年。詞云圖如圖6所示。
從商品銷售種類詞云圖中可以直觀地看出,“食品”“家電”“內衣”“家居”和“男裝”等詞語最為突出,表明用戶在該電商網站最喜歡購置這些物品。結合每年下單總金額、客單價以及每月成交金額的可視化分析,買方和賣方可以實時監控產品情況,商家可以根據清晰的可視化圖像和曲線,適時制定促銷活動或優惠政策,消費者也可以根據這些可視化圖表,在合適的時機購買所需商品。
3? 結? 論
本論文研究基于Hadoop的電商大數據可視化設計與實現。提出了一種基于Hadoop的電商大數據可視化分析框架,并在實驗中對該框架進行了驗證。使用Hadoop技術框架及其組件對大規模的電商數據集進行了處理和分析,并使用了FineBi可視化工具將數據可視化。結果顯示,本論文設計的框架可以有效地幫助用戶從大量的電商數據中挖掘出有價值的信息,并以直觀、易懂的圖表方式展示。
參考文獻:
[1] 李大洲.基于大數據的用戶行為日志系統設計與實現 [D].南京:南京郵電大學,2020.
[2] 陳娥祥.基于Hadoop電商大數據的挖掘與分析技術研究 [J].科技經濟市場,2021(1):7-9.
[3] 張晴峰.基于Hadoop的大學圖書館服務平臺設計 [J].科學技術創新,2021(23):83-84.
[4] 袁愛平,陶志勇,鄧河,等.云計算環境中HDFS數據塊存儲策略研究 [J].電腦知識與技術,2020(26):33-35.
[5] 秦東旭,徐瑾,呂明,等.基于 Hadoop 的用戶行為數據分析系統的設計 [J].工業控制計算機,2019(10):137-138.
[6] COHEN J,DOLAN B,DUNLAP M,et al. MAD skills: new analysis practices for big data [J].Proceedings of the VlDB Endowment,2009,2(2):1481-1492.
[7] 王電輕.基于hadoop的網站用戶行為分析系統設計與實現 [D].北京:中國科學院大學(工程管理與信息技術學院),2016.
[8] 童瑩,楊貞卓.Hadoop和Spark在Web系統推薦功能中的應用 [J].現代信息科技,2020,4(19):87-89.
作者簡介:李威(1999—),男,漢族,湖南岳陽人,研究生在讀,研究方向:工業大數據;通訊作者:邱永峰(1985—),男,漢族,湖南婁底人,高級工程師,博士,研究方向:工業大數據、控制系統、智能制造等。
