基于輸入變量篩選與卷積神經網絡的黃河流域高精度灌溉用水空間柵格研究
2023-10-28 06:56:02張敏
節水灌溉 2023年10期
張 敏
(太原理工大學建筑設計研究院有限公司,太原 030000)
0 引 言
水是維系生態系統和人類生活、生產活動的基本要素,隨著社會經濟的發展以及人口的增長,用水需求呈現出不斷增加的趨勢[1],而氣候變化的影響使得水資源供需矛盾更加突出[2],因此合理優化配置以實現更高效地利用水資源成為緩解水資源短缺問題的關鍵[3]。水資源優化配置的關鍵在于明晰來水條件、用水狀況以及水利工程能力,隨著分布式水文模型的發展與研究,來水條件在不同時空尺度上均得到了有效的模擬和預測[4-6];亦有眾多學者提出了不同情景下的水資源多目標優化配置方案與算法[7,8]。然而,用水狀況的研究仍然停留在以行政區為單元的統計調查尺度[9]。來水條件的空間尺度往往是具有流域特征的水資源分區,導致用水狀況與來水條件之間存在著的空間尺度不匹配問題,這給水資源的配置帶來了挑戰,增加了供水的不確定性和缺水風險[10]。
農業灌溉是我國的用水大戶,根據《2021 年中國水資源公報》,我國用水總量為5 920.2 億m3,其中農業用水量3 644.3 億m3,占總用水量的61.5%,因此研究農業灌溉用水的空間柵格化以保障精準灌溉對于我國農業的穩定穩產尤為重要。目前已有較多學者針對農業灌溉用水的用水效率[11,12]、用水定額[13]、影響要素[14]、用水預測[15]等方面開展研究,缺少對灌溉用水在空間分布上的研究。黃河流域在我國經濟高質量發展和農業生產安全方面具有十分重要的地位,改革開放以來經濟社會高速發展,水資源消耗不斷增加,在保障黃河流域綠色發展的前提下維穩農業生產尤為關鍵[16]。
基于此,本文以黃河流域為研究對象,基于地理變量相互關系的思想,篩選與灌溉用水相關性強的地理變量(輸入變量),利用卷積神經網絡構建地理變量與灌溉用水(輸出變量)的相互關系,通過輸入變量的空間分布以及輸入變量與輸出變量的關系來實現灌溉用水的空間柵格化。以此為基礎,分析黃河流域灌溉用水柵格的時空分布特性,以期為黃河流域灌溉用水的合理調配提供科學支撐,為黃河流域實現高質量發展提供決策參考。
1 研究區域與數據
1.1 研究區域
黃河發源于青藏高原巴顏喀拉山北麓,從西到東依次流經青海、四川、甘肅、寧夏、內蒙古等9 個省(自治區),全長5 464 km,流域總面積為79.5 萬km2,在我國經濟社會發展和農業生產安全方面具有十分重要的地位。黃河流域范圍及流域內地級市邊界如圖1所示。
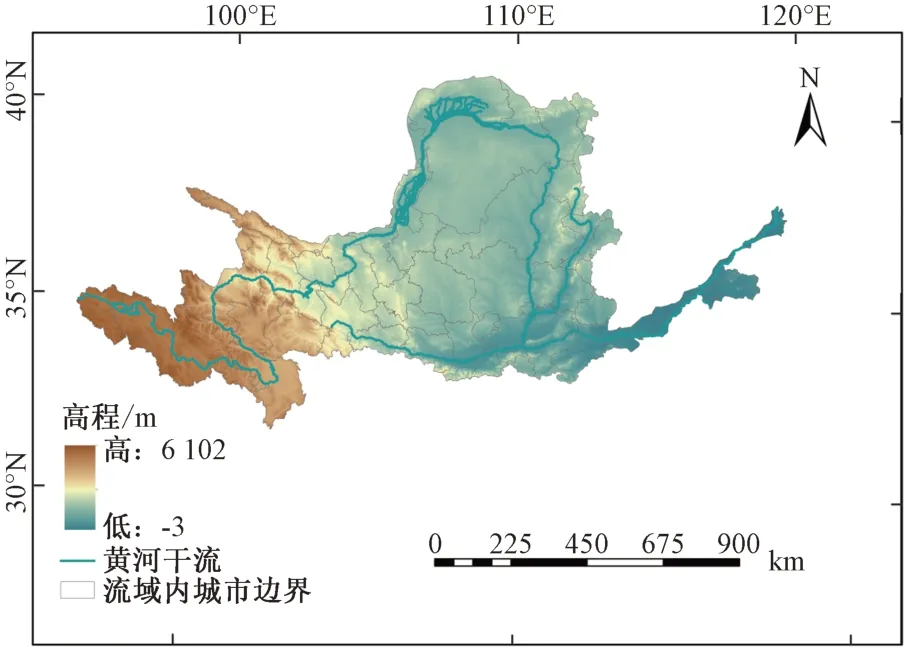
圖1 黃河流域及流域內城市邊界圖Fig.1 Urban boundary map of the Yellow River Basin and its interio
1.2 數據來源與數據預處理
研究選取2000-2013 年黃河流域內77 個地級市(自治州)的灌溉用水量數據作為輸出變量數據,數據來自于由Zhou等[17]構建的中國用水量數據集NLWUD(National Long-term Water Use Dataset of China)。數據主要來源于第一次和第二次全國水資源調查評價資料、省級行政區的水資源公報,具有較好的時間連續性和可靠性。
收集的地理變量包含土壤含水量數據、社會經濟數據(GDP、人口)、氣象站點數據、遙感影像數據(歸一化植被指數)、土地利用/覆蓋數據、DEM 數據等。其中土壤含水量數據來源于He 等[18]發布的VIC 水文模型模擬數據,社會經濟數據來源于中國科學院資源環境科學與數據中心(www.resdc.cn),氣象站點數據來源于中國氣象數據網(data.cma.cn)。
由于收集的地理變量在時空尺度上存在多樣性,為了實現時空尺度的統一(年尺度,空間尺度1 km),需要對數據進行預處理。預處理的方法包含兩類:時間尺度的升/降尺度,空間尺度的升/降尺度。土壤含水量數據原始空間尺度為0.25°×0.25°,采用一種基于地理變量的機器學習算法[19]降尺度到1 km×1 km;社會經濟數據則在時間上進行線性內插,土地利用/覆蓋數據與DEM 數據采用最鄰近法進行重采樣升尺度,氣象站點數據則采用反距離加權法進行空間插值。數據詳情與預處理方法如表1所示。

表1 地理變量數據詳情與預處理方法Tab.1 Details of geographic variable data and preprocessing methods
2 研究方法
2.1 地理變量相互關系法與地理變量篩選
地理變量相互關系法,簡單來說就是建立目標變量和輸入變量的相互關系。通過輸入變量的空間分布,利用輸入變量與目標變量的關系來展現目標變量的空間分布。這一方法在社會數據空間化的研究中應用廣泛,隨著GIS 與遙感數據發展,研究的趨勢也從單一數據源逐漸向多元復合數據源前進。
對收集到的地理變量,采用Spearman 相關分析篩選地理變量,Spearman相關系數的計算如下:
式中:n 為2000-2013 年77 個地級市的總樣本數;di為通過排序得到的第i個奇偶樣本之間的位置偏差。
根據各地理變量與輸出變量(灌溉用水)的相關系數,最終篩選地理變量作為之后模擬模型的輸入變量。
2.2 卷積神經網絡的工作原理及流程
通過地理變量篩選確定輸入變量后,采用卷積神經網絡構建輸入變量與灌溉用水的關系并實現灌溉用水的空間柵格化模擬。
卷積神經網絡(Convolutional neural network,CNN) 是一種具有交替卷積層和子采樣層的前饋神經網絡[20]。卷積神經網絡的典型架構由輸入層、卷積層、池化層、全連接層和輸出層組成。卷積層學習輸入變量的卷積,并為特征提取提供最佳性能。池化層降低了輸入變量中特征的維數,而不改變這些輸入變量的信息從而提高CNN 的計算效率。完全連接層可以重新組織提取的特征,以減少輸入變量中的信息損失。CNN 在面對不同維度的輸入變量時具有自適應能力,由于本研究中采用的輸入數據具有二維形式,且CNN-2D 架構已被證明能夠有效映射時間連續的二維形式輸入變量[21],因此,本文采用CNN-2D 架構進行黃河流域灌溉用水的空間柵格化。
研究方法流程圖如圖2所示。
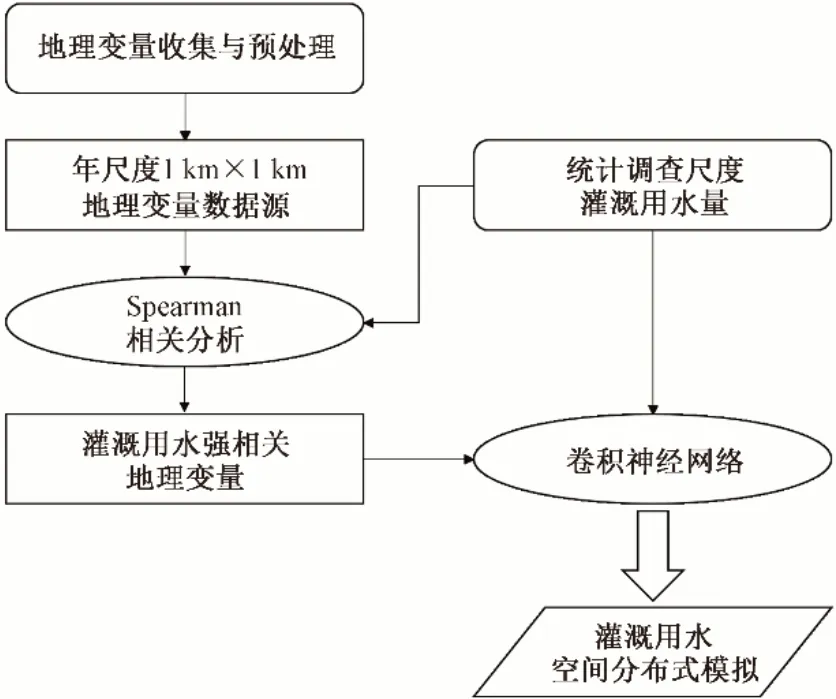
圖2 研究流程圖Fig.2 Flowchart of research
3 結果分析
3.1 地理變量篩選結果
利用Spearman 相關分析方法,最終從收集的10 個地理變量(降水、土地利用/覆蓋、農田生產潛力、歸一化植被指數、GDP、人口、DEM、坡度、潛在蒸散發、土壤含水量)中篩選出6個輸入變量,分別為:潛在蒸散發(PET),降水(P),歸一化植被指數(NDVI),土壤含水量(SM),凈初級生產力(NPP)和農田生產潛力(Pcrop)。
這6 個輸入變量與輸出變量(灌溉用水IWU)之間的Spearman相關系數熱力圖如圖3所示。

圖3 輸入變量與灌溉用水Spearman相關系數熱力圖Fig.3 Thermal diagram of spearman correlation coefficient between input variables and irrigation water
由Spearman相關系數熱力圖可得6個輸入變量與灌溉用水的相關系數,其中潛在蒸散發[22]和農田生產潛力與灌溉用水的相關系數較高,達到0.82 以上;凈初級生產力和歸一化植被指數次之,在0.75 以上;降雨和土壤含水量與灌溉用水的關系為負相關,且相關系數在0.76以上。
出現此類結果的原因在于,灌溉用水主要用于作物在降雨量及土壤含水量之外正常生長發育所需的額外水量,故而灌溉用水與降雨和土壤含水量呈負相關;同時,作物生產力越高、植被覆蓋率越大,則構成植物體所需的水量之和也就越大,灌溉用水量就越大,因而,灌溉用水與凈初級生產力和歸一化植被指數呈正相關;而灌溉用水在正常生長發育過程中,主要用于作物蒸騰、棵間蒸發以及構成植株體的水量之和,因次,潛在蒸散發和農田生產潛力與灌溉用水的相關系數最高,并呈正相關。
3.2 灌溉用水空間柵格模擬精度評價
采用均方根誤差(Root Mean Squared Error,RMSE)、納什效率系數(Nash-Sutcliffe Efficiency,NSE) 與相對誤差(Relative Error,RE)3 個指標對模擬的灌溉用水空間柵格進行精度評價,將黃河流域灌溉用水的空間柵格在地級市邊界內統計,與各地級市統計調查的2000-2013年灌溉用水量進行對比,各評價指標如圖4~圖6所示。

圖4 黃河流域灌溉用水空間柵格RMSE空間分布圖Fig.4 Spatial grid RMSE spatial distribution map of irrigation water use in the Yellow River Basin

圖5 黃河流域灌溉用水空間柵格相對誤差Fig.5 Relative error of spatial grid for irrigation water use in the Yellow River Basin
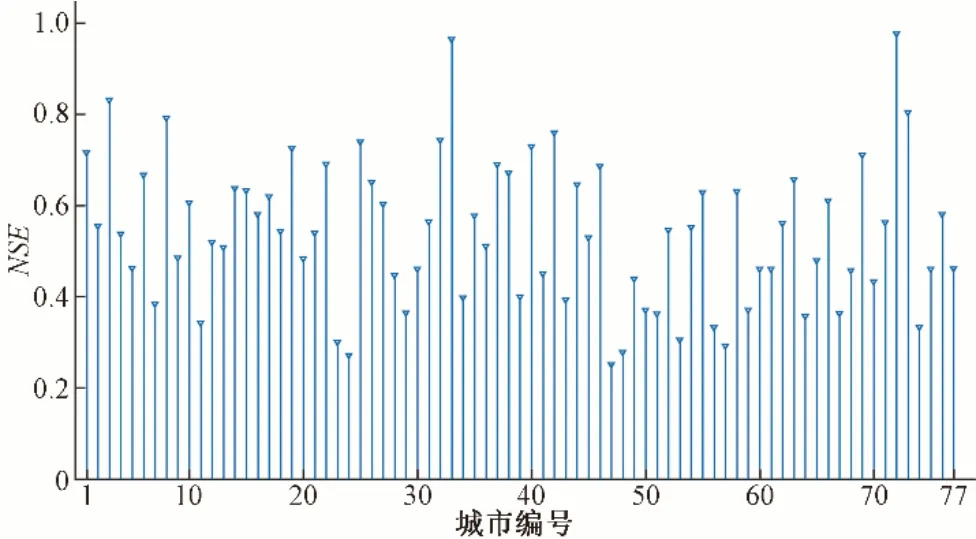
圖6 黃河流域灌溉用水空間柵格NSEFig.6 Irrigation water spatial grid NSE in the Yellow River Basin
由圖4可知,在河套地區以及黃河下游地區,模擬的灌溉用水空間柵格的均方根誤差較大,而在其他地區均有著較高的模擬精度。由此也可看出,河套地區及黃河下游地區灌溉用水量遠高平均值,造成該結果的主要原因為:該區域地勢平坦,作物種植面積大,農田生產潛力、凈初級生產力和歸一化植被指數同其他地區相比較高,而且,由于氣候干燥晝夜溫差大,潛在蒸散發能力強,同時降雨不足[23],土壤含水量低造成該區域灌溉用水遠高平均值。
各城市在不同年份間的模擬精度也有所不同(圖5),如山西晉城市,相對誤差在2000-2013 年間變化幅度較大,在2008 年相對誤差為105%,這是由于晉城市灌溉用水在2000-2013年間變化幅度較大,2000-2008年間維持下降趨勢,而在2008-2013 年間迅速增長,2008 年晉城市灌溉用水量為0.035億m3,而在2013 年灌溉用水量增長至0.144 億m3,增長幅度巨大導致模型模擬精度在2008年尤為差。
模擬的灌溉用水空間柵格的NSE 值整體維持在可接受范圍內,大部分城市NSE值均大于0.4,部分城市NSE值大于0.8(圖6)。由此,模型模擬的灌溉用水空間柵格精度較高,能夠較好地展現灌溉用水的空間分布狀況。
3.3 灌溉用水柵格時空特性分析
模擬的2000-2013 年黃河流域灌溉用水空間柵格如圖7 所示。由圖7可知,灌溉用水的高值主要集中在甘肅地區、寧夏平原、河套平原、渭河、汾河兩岸以及花園口以下地區。出現此類現象的主要原因是:原始的氣候因素如甘肅及寧夏地區氣候干燥,晝夜溫差大,當地作物潛在蒸散發能力強,因而需水量高;灌溉面積因素如河套平原區,地勢平坦,作物種植面積大,導致的需水量高;灌溉條件成熟如渭河、汾河兩岸土壤肥沃,灌溉條件優越,故而所需水量高;作物種植模式如花園口以下地區作物種類多樣,故而需水量高。其綜合因素均體現為潛在蒸散發強,降水少,歸一化植被指數高,土壤含水量低,凈初級生產力高和農田生產潛力高等,該結果同地理變量篩選結果保持一致。

圖7 黃河流域2000-2013年灌溉用水空間柵格Fig.7 Spatial grid of irrigation water use in the Yellow River Basin from 2000 to 2013
灌溉用水量在不同年份之間存在著分布差異,但空間用水整體穩定,能夠為黃河流域灌溉用水的合理調配提供科學支撐。
為了探究黃河流域灌溉用水空間柵格的空間自相關性,采用全局莫蘭指數進行空間自相關性的檢驗。黃河流域灌溉用水空間柵格的全局莫蘭指數如表2所示。黃河流域灌溉用水量的全局莫蘭指數均保持在0以上,表明黃河流域的灌溉用水量呈現正向的空間集聚,即整個流域在地理空間具有較好的空間自相關性,其空間屬性間聚合程度較好,并且灌溉用水的空間集聚在2000-2013年間有所下降(全局莫蘭指數減小),即空間差異性隨時間拉大。該結果說明了將黃河流域作為一個分析系統是完全合理的。

表2 黃河流域灌溉用水空間柵格全局莫蘭指數Tab.2 Global Moran's index of spatial grid of irrigation water use in the Yellow River basin
在時間演變規律上,黃河流域灌溉用水年均變化率如圖8所示。由圖8 可知在黃河流域大部分地區,灌溉用水較為穩定,年均變化率不高,可以為黃河流域灌溉用水提供較為精確的灌水預測,為黃河流域實現高質量發展提供決策參考。僅在青海西寧市、甘肅天水市和山西晉城市,年均增長率較高,分別為6.04%、5.12%、12.14%,其中山西晉城市灌溉用水量年均增長率最高;在甘肅甘南藏族自治州,灌溉用水量年均減少率最高,為-5.49%。
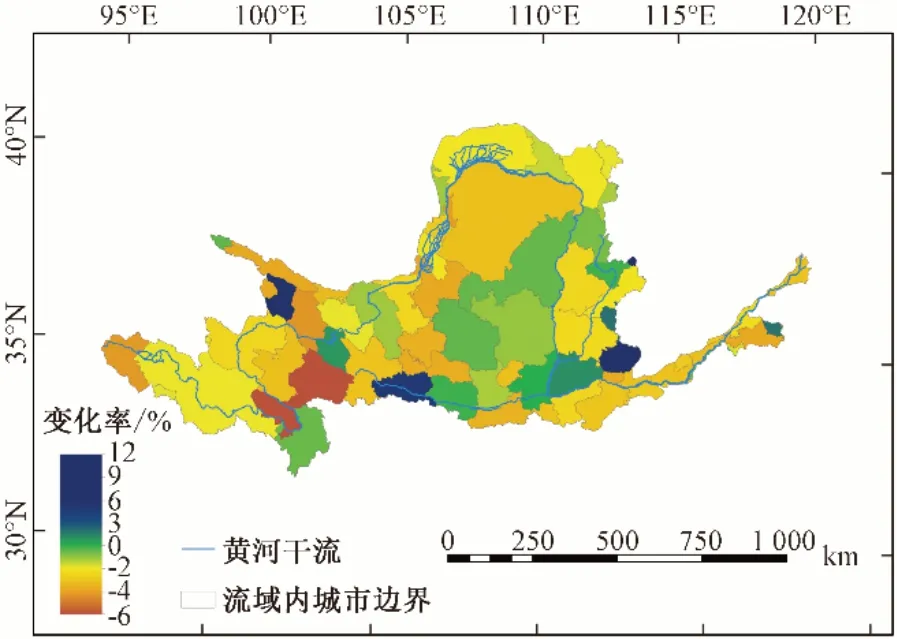
圖8 黃河流域灌溉用水年均變化率Fig.8 Annual average change rate of irrigation water use in the Yellow River Basin
4 結 語
本研究基于地理變量相互關系法,通過篩選與灌溉用水高相關的地理變量,利用卷積神經網絡,實現了黃河流域內灌溉用水的空間柵格化。
利用Spearman 相關分析篩選的與灌溉用水強相關的地理變量分別為:潛在蒸散發、降水、歸一化植被指數、土壤含水量、凈第一生產力和農田生產潛力。利用卷積神經網絡模擬的2000-2013 年黃河流域灌溉用水空間柵格在精度上較高,誤差在可接受范圍內。黃河流域的灌溉用水在空間上呈現正向的集聚性,且集聚性有隨時間逐漸降低趨勢。在時間演變上,黃河流域內不同地區的灌溉用水有著不同的年際變化趨勢,在山西晉城有著最高的年均增長率,而在甘肅甘南藏族自治州則有著最高的年均減少率。
由于黃河流域面積廣闊,上中下游氣候條件、土壤類型和來水條件等差異較大,明晰灌溉用水在黃河流域內的空間分布,可為黃河流域灌溉用水的合理調配提供科學支撐,并且能夠為保障黃河流域高質量發展與農業穩產提供決策參考。
