基于自編碼器的大規(guī)模樣本標(biāo)簽校正方法
2023-10-28 02:37:36孫鄭依馮濤王晶
家電科技 2023年4期
孫鄭依 馮濤 王晶
北京工商大學(xué) 北京 100048
0 引言
壓縮機是空調(diào)系統(tǒng)的核心組件,壓縮機殼體的振動與其運行狀態(tài)密切相關(guān),故可通過壓縮機殼體的振動信號來判別壓縮機的運作狀況。
基于深度學(xué)習(xí)技術(shù)構(gòu)建的異常檢測模型具有強大的自主學(xué)習(xí)能力以及良好的特征提取能力,在學(xué)習(xí)高維數(shù)據(jù)、時間數(shù)據(jù)等復(fù)雜數(shù)據(jù)的表達(dá)、表示方面顯示出了巨大的能力,突破了不同學(xué)習(xí)任務(wù)的界限,可以有效地進(jìn)行異常檢測任務(wù)[1-5]。徐豐甜等[6]針對往復(fù)壓縮機氣閥故障根據(jù)溫度數(shù)據(jù)有不同的表現(xiàn)特點,提出一種基于主成分分析(PCA)法建立基于徑向基函數(shù)的故障異常監(jiān)測模型,實現(xiàn)往復(fù)式壓縮機故障異常自動檢測。王遠(yuǎn)濤等[7]提出一種基于自編碼器模型的制冷壓縮機異常振動檢測方法,探討了自編碼器迭代次數(shù)、隱藏層數(shù)以及訓(xùn)練樣本數(shù)量對判定準(zhǔn)確率的影響,結(jié)果表明,自編碼器模型可以應(yīng)用于制冷壓縮機異常振動檢測任務(wù)并且樣本數(shù)量對準(zhǔn)確率影響顯著。劉恒等[8]針對壓縮機故障樣本稀缺的特點,提出一種基于變分自編碼器模型提取正常樣本共性特征進(jìn)而實現(xiàn)故障檢測的方法。
基于分類的深度學(xué)習(xí)模型可以保證壓縮機正異常判斷的準(zhǔn)確性,但標(biāo)簽準(zhǔn)確的高質(zhì)量數(shù)據(jù)是確保分類模型判別精度的基礎(chǔ)。隨著壓縮機生產(chǎn)技術(shù)的提升,故障壓縮機在生產(chǎn)中出現(xiàn)的幾率越來越低,正常樣本和故障樣本的比例極不均衡;大規(guī)模生產(chǎn)加大了人工現(xiàn)場實時標(biāo)注的難度,很容易出現(xiàn)樣本標(biāo)簽標(biāo)注錯誤的情況。產(chǎn)品生產(chǎn)過程中,各種加工都是根據(jù)設(shè)計參數(shù)進(jìn)行,所以生產(chǎn)出來的正常機都具有趨同的特性,而故障機基本都是偏離正常參數(shù)的結(jié)果,在特征空間中表現(xiàn)出較大的離散度,這些問題對分類模型訓(xùn)練和評估帶來了極大困難。本文針對這一難題,研究了大規(guī)模樣本標(biāo)簽的校正方法,采用基于深度學(xué)習(xí)的自動編碼器神經(jīng)網(wǎng)絡(luò)模型,使用漸進(jìn)調(diào)整方式訓(xùn)練自動編碼器,基于重構(gòu)誤差序列和重構(gòu)損失值分布曲線提煉樣本,糾正錯誤標(biāo)簽,為后續(xù)分類模型提供標(biāo)簽準(zhǔn)確的樣本。
1 自編碼器重構(gòu)樣本誤差序列
自動編碼器是一種無監(jiān)督學(xué)習(xí)模型,它由編碼器(Encoder)和解碼器(Decoder)兩部分構(gòu)成,如圖1所示。編碼器將輸入數(shù)據(jù)映射到低維表示,壓縮為一個特征向量,其中包含了輸入數(shù)據(jù)的重要特征;解碼器將得到的低維表示重新映射回原始數(shù)據(jù)的維度,它的目標(biāo)是盡可能準(zhǔn)確地重構(gòu)原始數(shù)據(jù)。
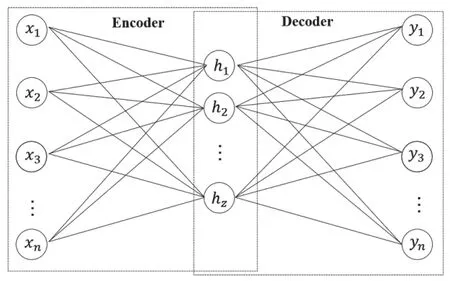
圖1 自編碼器網(wǎng)絡(luò)結(jié)構(gòu)示意圖
對于第k個輸入數(shù)據(jù):
其編碼過程為:
解碼過程為:
式中:Hk為神經(jīng)網(wǎng)絡(luò)的隱含特征;為神經(jīng)網(wǎng)絡(luò)的重構(gòu)向量;W0、W1為權(quán)重;b0、b1為偏置量;σ0、σ1為ReLU激活函數(shù)。
自動編碼器訓(xùn)練過程旨在最小化重構(gòu)誤差即原始輸入數(shù)據(jù)與解碼器輸出數(shù)據(jù)之間的差異。訓(xùn)練過程可以通過最小化重構(gòu)誤差的損失函數(shù)來實現(xiàn)。常見的損失函數(shù)包括均方差損失(Mean Squared Error,MSE)和二進(jìn)制交叉熵?fù)p失(Binary Cross Entropy Loss),本文采取均方差損失。
損失函數(shù)為:
本文研究采用Adam優(yōu)化器,其結(jié)合了動量法和自適應(yīng)學(xué)習(xí)率的特性,能夠在不同參數(shù)和不同數(shù)據(jù)的情況下更好地適應(yīng)和調(diào)整學(xué)習(xí)率,實現(xiàn)對模型參數(shù)的高效優(yōu)化。其更新公式如下:
壓縮機樣本標(biāo)簽主要依靠人工標(biāo)注的方式,當(dāng)面對大規(guī)模樣本時,人工標(biāo)注難免會出現(xiàn)偏差,導(dǎo)致標(biāo)簽與真實情況不符合,直接影響模型分類性能。但人工標(biāo)注出現(xiàn)偏差屬于小概率事件,大部分樣本標(biāo)簽與實際情況是相符的,通過人工標(biāo)注得到的數(shù)據(jù)仍對模型訓(xùn)練具有指導(dǎo)性意義。因此,本文利用自動編碼器模型,基于人工標(biāo)注的方式制作初始數(shù)據(jù)集,逐步校正樣本標(biāo)簽,得到純凈的正常壓縮機數(shù)據(jù)集和故障壓縮機數(shù)據(jù)集,為分類模型奠定數(shù)據(jù)基礎(chǔ)。
訓(xùn)練時單純用正常壓縮機樣本訓(xùn)練自動編碼器,測試時將全部樣本輸入自動編碼器,將每個樣本的重構(gòu)誤差從小到大排序得到重構(gòu)誤差序列。由于生產(chǎn)線在同一生產(chǎn)模式下,因此故障壓縮機與正常壓縮機必然存在一定差異,則其均方差損失較正常壓縮機要大一些,對此,將重構(gòu)誤差序列頭部對應(yīng)的樣本真實標(biāo)簽修改為正常機,尾部修改故障機,進(jìn)行數(shù)據(jù)集的迭代更新。具體實施流程如圖2。
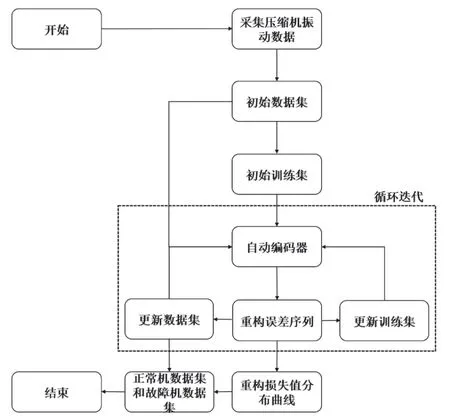
圖2 流程圖
(1)采集樣本制作初始數(shù)據(jù)集,搭建模型架構(gòu),確定損失函數(shù)、優(yōu)化器、學(xué)習(xí)率等參數(shù);
(2)挑選初始數(shù)據(jù)集中標(biāo)簽為正常壓縮機的部分樣本作為初始訓(xùn)練集,訓(xùn)練自動編碼器;
(3)初始數(shù)據(jù)集全部樣本依次輸入訓(xùn)練好的自動編碼器并統(tǒng)計每個樣本損失值,從小到大依次排列得到重構(gòu)誤差序列;
(4)根據(jù)重構(gòu)誤差序列,結(jié)合當(dāng)前標(biāo)簽畫出正常樣本與故障樣本重構(gòu)損失值的分布曲線;
(5)修改重構(gòu)誤差序列頭部樣本的標(biāo)簽為正常壓縮機,尾部為故障壓縮機,生成更新數(shù)據(jù)集,頭部樣本作為更新訓(xùn)練集;
(6)根據(jù)更新訓(xùn)練集,繼續(xù)訓(xùn)練上一步得到的自編碼器;
(7)根據(jù)更新數(shù)據(jù)集,重復(fù)第三步,直至正常數(shù)據(jù)與異常數(shù)據(jù)的分布曲線區(qū)分開來;
(8)基于更新數(shù)據(jù)集和重構(gòu)損失值分布曲線,劃分出“干凈”的正常樣本數(shù)據(jù)集和故障樣本數(shù)據(jù)集。
2 數(shù)據(jù)集和模型搭建
2.1 數(shù)據(jù)采集與數(shù)據(jù)集制作
數(shù)據(jù)集來源于大量生產(chǎn)線上空調(diào)壓縮機實測振動數(shù)據(jù),如圖3所示,壓縮機被放置在托盤上,并隨生產(chǎn)線移動。當(dāng)托盤到達(dá)檢測工位時,通過下氣缸將托盤頂起,使其離開生產(chǎn)線,以減小傳送鏈自身的振動對測量結(jié)果的影響。同時,上氣缸下壓,確保加速度計與壓縮機殼體緊密貼合。為了確保加速度計與壓縮機殼體的可靠接觸,在上氣缸和加速度計之間采用彈性阻尼環(huán)進(jìn)行連接。在生產(chǎn)線上使用加速度計來采集壓縮機殼體的振動信號,通過NI9234采集卡進(jìn)行數(shù)字信號采集并做傅里葉變換作為自編碼器的數(shù)據(jù)集。
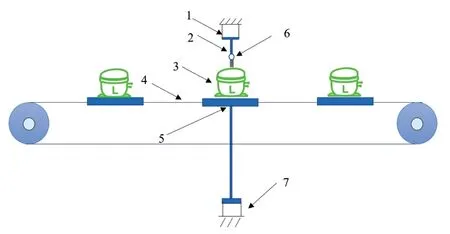
圖3 數(shù)據(jù)采集示意圖
圖4~5分別為正常壓縮機頻譜和故障壓縮機頻譜,為歸納統(tǒng)計壓縮機頻譜數(shù)據(jù)的分布特性,對其做最大最小值歸一化處理。自編碼器的編碼器和解碼器由神經(jīng)元和激活函數(shù)構(gòu)成,歸一化處理能夠加速神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)速率,加快模型收斂速度。
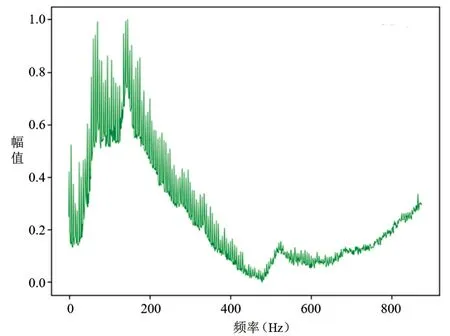
圖4 正常壓縮機頻譜
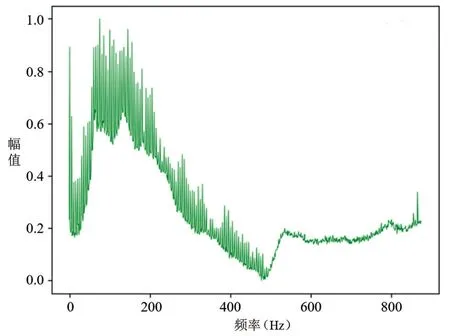
圖5 故障壓縮機頻譜
圖中橫軸為頻率,單位Hz;縱軸為幅值強度,單位dB。本研究中,選取壓縮機數(shù)據(jù)的頻率成分對應(yīng)的幅值強度作為模型的輸入。在生產(chǎn)線上采集的壓縮機振動數(shù)據(jù)共有14784條數(shù)據(jù),將其作為初始數(shù)據(jù)集,標(biāo)簽均由人工方式在采集過程中同步給出。其中,初始正常壓縮機樣本數(shù)為14598,初始故障壓縮機樣本數(shù)為186,隨機挑選初始正常壓縮機樣本中的5000條數(shù)據(jù)作為初始訓(xùn)練集。根據(jù)得到的重構(gòu)誤差序列修改樣本標(biāo)簽,得到更新數(shù)據(jù)集和更新訓(xùn)練集,如表1所示。

表1 數(shù)據(jù)集說明
本研究的核心目標(biāo)是讓參與訓(xùn)練自編碼器的正常機數(shù)據(jù)越純越好,使得自動編碼器的編碼器部分學(xué)得樣本的特征向量能更準(zhǔn)確、充分地表達(dá)正常壓縮機數(shù)據(jù)特征,解碼器重構(gòu)時能夠?qū)φ嚎s機數(shù)據(jù)進(jìn)行一個很好的還原;當(dāng)給自編碼器輸入故障機數(shù)據(jù)時,由于兩類數(shù)據(jù)存在一定差異,使得故障壓縮機樣本的損失值會稍大一些,這樣可選取分布靠前的樣本標(biāo)注為正常壓縮機;分布靠后的樣本標(biāo)注為故障壓縮機,最終得到兩類樣本的“干凈”數(shù)據(jù)集,為分類模型提供準(zhǔn)確的訓(xùn)練樣本。
2.2 自動編碼器模型搭建
本研究基于PyTorch深度學(xué)習(xí)框架搭建自編碼器網(wǎng)絡(luò)模型,模型架構(gòu)如圖6所示。
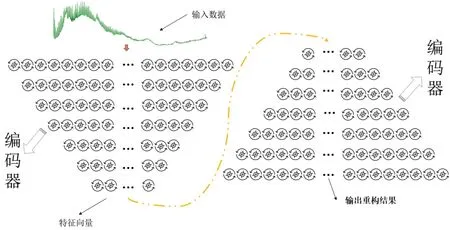
圖6 編碼器網(wǎng)絡(luò)結(jié)構(gòu)圖
該模型架構(gòu)屬于堆疊式自動編碼器的形式,編碼器和解碼器由多個線形層和激活函數(shù)組成,輸入層為了匹配輸入的頻譜數(shù)據(jù)共設(shè)置876個神經(jīng)元,編碼器將876維的頻譜數(shù)據(jù)逐漸壓縮至20維作為輸入數(shù)據(jù)特征向量的表示。激活函數(shù)選用了ReLU激活函數(shù)和Sigmoid激活函數(shù),前者具備良好的非線性建模能力,后者可以將輸出限制在0~1之間來匹配輸入數(shù)據(jù)。本研究采用均方差損失函數(shù)(MSELoss)作為重構(gòu)誤差的度量,并使用Adam優(yōu)化器來更新模型參數(shù)。
3 結(jié)果與討論
研究對象為某廠商生產(chǎn)的汽車空調(diào)壓縮機,數(shù)據(jù)均由生產(chǎn)線上實測而得。基于圖2,本研究共進(jìn)行80000次迭代訓(xùn)練、修改標(biāo)簽47次,經(jīng)過修改后,數(shù)據(jù)集中正常壓縮機樣本數(shù)變?yōu)?4519,故障壓縮機樣本數(shù)為265。為了評估模型的性能,本研究跟蹤了損失函數(shù)隨訓(xùn)練迭代次數(shù)的變化,截取部分損失函數(shù)曲線如圖7所示。
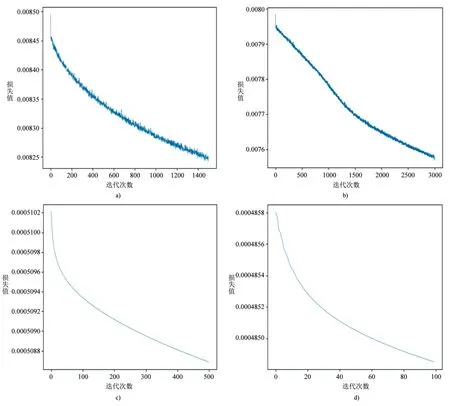
圖7 損失函數(shù)曲線
損失函數(shù)值在訓(xùn)練開始時較高,但隨著訓(xùn)練的進(jìn)行,損失曲線呈梯度下降趨勢,說明自動編碼器正在學(xué)習(xí)輸入數(shù)據(jù)的特征。如圖7 a)、b),在訓(xùn)練前期,損失下降的較快,訓(xùn)練振動的幅度較大,在相同的迭代次數(shù)情況下,損失函數(shù)值下降范圍大概在0.0013左右;但隨著訓(xùn)練的進(jìn)行,下降趨勢逐步減小,如圖7 c)、d),相同的迭代次數(shù)損失函數(shù)值下降范圍很小,此時加大了重構(gòu)誤差序列頭部所占比例,增加訓(xùn)練樣本并增大batchsize參數(shù),使模型加快收斂速度、梯度下降方向準(zhǔn)確度增加、訓(xùn)練振動幅度減小。本文得到的自動編碼器模型對數(shù)據(jù)的重構(gòu)結(jié)果如圖8,重構(gòu)損失值分布曲線如圖9所示。
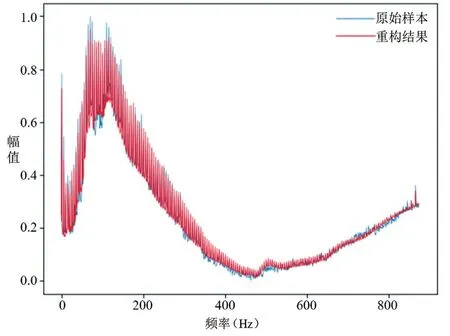
圖8 重構(gòu)結(jié)果
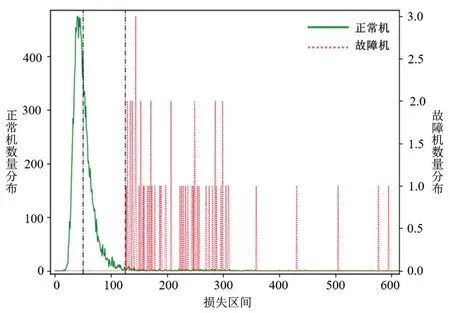
圖9 重構(gòu)損失值分布曲線
如圖9所示,將全部樣本損失值從小到大排序并等間隔劃分區(qū)間,正常壓縮機樣本分布曲線能夠區(qū)別于故障壓縮機樣本分布曲線,即正常壓縮機整體損失值偏小,故障壓縮機整體損失值偏大一些。針對這一分布特性,可選定某一區(qū)間界限,挑選出樣本標(biāo)簽與真實情況準(zhǔn)確無誤的樣本劃為分類模型的數(shù)據(jù)集。在本研究中,圖中第50個區(qū)間內(nèi)的某一損失值0.00054,設(shè)為正常壓縮機樣本標(biāo)簽的分界線;第125個區(qū)間內(nèi)的某一損失值0.0014,設(shè)為故障壓縮機樣本標(biāo)簽的分界線。在現(xiàn)有樣本中,若樣本輸入自編碼器模型得到的損失值小于0.00054可認(rèn)為其真實標(biāo)簽為正常壓縮機;大于0.0014則認(rèn)為其真實標(biāo)簽為故障壓縮機。
訓(xùn)練好的自動編碼器模型也可作為人工實時標(biāo)注現(xiàn)場的輔助工具,若人工標(biāo)注為正常壓縮機,且其損失值小于0.00054;或人工標(biāo)注為故障壓縮機,其損失值大于0.0014,則可直接劃分到分類模型數(shù)據(jù)集當(dāng)中。
在原始數(shù)據(jù)集中,共包含14598個正常壓縮機和186個故障壓縮機,經(jīng)過本研究校正后,正常壓縮機個數(shù)變?yōu)?4519,故障壓縮機個數(shù)變?yōu)?65。如表2所示,在正常壓縮機當(dāng)中,標(biāo)簽未被修改即人工標(biāo)注正確的個數(shù)為14400,被修改即人工標(biāo)注錯誤的個數(shù)為198;故障壓縮機中,“標(biāo)簽未被修改”即人工標(biāo)注正確的個數(shù)為67,“標(biāo)簽被修改”即人工標(biāo)注錯誤的個數(shù)為119,所修改的樣本標(biāo)簽經(jīng)過人工復(fù)聽認(rèn)可。

表2 標(biāo)簽校正結(jié)果
選擇表2中“標(biāo)簽未被修改”列中的樣本作為后續(xù)分類模型的訓(xùn)練測試樣本,因為這類樣本的標(biāo)簽得到了人工和自編碼器模型的雙重認(rèn)定,確保了樣本標(biāo)簽的準(zhǔn)確性。
4 結(jié)論
本文提出一種針對大規(guī)模樣本標(biāo)簽的校正方法,通過樣本漸進(jìn)調(diào)整,完成了自動編碼器模型的訓(xùn)練,實現(xiàn)了樣本標(biāo)簽的校正。在樣本漸進(jìn)調(diào)整的訓(xùn)練過程中,自編碼器損失值梯度逐步下降,最終收斂,表明自編碼器可用于樣本漸進(jìn)調(diào)整。本研究可對工業(yè)現(xiàn)場采集的大規(guī)模樣本進(jìn)行標(biāo)簽校正,可為后續(xù)分類模型的訓(xùn)練、驗證和測試提供了標(biāo)簽更為準(zhǔn)確的數(shù)據(jù)樣本。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
汽車維修與保養(yǎng)(2015年12期)2015-04-18 07:51:49
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維修與保養(yǎng)(2015年2期)2015-04-17 01:30:34
