最小二乘直線擬合的含噪聲數(shù)據(jù)檢測(cè)方法仿真
2023-10-29 01:49:14崔建濤
計(jì)算機(jī)仿真 2023年9期
胡 萍,崔建濤
(1. 銅仁學(xué)院大數(shù)據(jù)學(xué)院,貴州 銅仁 554300;2. 鄭州輕工業(yè)大學(xué)軟件學(xué)院,河南 鄭州 450001)
1 引言
信息技術(shù)與傳感技術(shù)的進(jìn)步使各行業(yè)的數(shù)據(jù)高速增長(zhǎng),這些數(shù)據(jù)中包含大量有價(jià)值的信息,通過(guò)數(shù)據(jù)挖掘等手段能夠發(fā)現(xiàn)并利用這些信息。但由于數(shù)據(jù)量龐大,其中會(huì)摻雜一些異常數(shù)據(jù),這些異常數(shù)據(jù)中既有缺失數(shù)據(jù),也包括離群點(diǎn)、噪聲數(shù)據(jù)等。噪聲數(shù)據(jù)對(duì)于有價(jià)值信息而言,不僅會(huì)降低數(shù)據(jù)流的整體質(zhì)量,還會(huì)影響數(shù)據(jù)挖掘效果,導(dǎo)致對(duì)信息出現(xiàn)錯(cuò)誤判斷。
含噪聲數(shù)據(jù)檢測(cè)就是在眾多數(shù)據(jù)中識(shí)別出不同于其它數(shù)據(jù)的過(guò)程。在大數(shù)據(jù)背景下,該技術(shù)在金融、軍事、醫(yī)療等領(lǐng)域都有廣泛應(yīng)用。但隨著數(shù)據(jù)維度和復(fù)雜度的提高,噪聲數(shù)據(jù)檢測(cè)也面臨嚴(yán)峻挑戰(zhàn)。現(xiàn)有的檢測(cè)技術(shù)通常對(duì)數(shù)據(jù)質(zhì)量和噪聲類型有著較高要求,并不是對(duì)所有噪聲數(shù)據(jù)都具有很好的檢測(cè)效果。再加上數(shù)據(jù)的高度復(fù)雜特征,噪聲數(shù)據(jù)檢測(cè)已經(jīng)成為一個(gè)難點(diǎn),相關(guān)技術(shù)人員也對(duì)此展開(kāi)大量研究。
例如,文獻(xiàn)[1]利用改進(jìn)支持向量數(shù)據(jù)描述方法檢測(cè)出噪聲數(shù)據(jù)。通過(guò)馬氏距離修正高斯窗函數(shù),減少檢測(cè)過(guò)程中的干擾因素,采用高斯窗函數(shù)計(jì)算數(shù)據(jù)的分布密度,根據(jù)隸屬度函數(shù)對(duì)改進(jìn)支持向量數(shù)據(jù)描述方法做密度補(bǔ)償,提高檢測(cè)精度。文獻(xiàn)[2]提出基于局部向量點(diǎn)積密度的噪聲檢測(cè)方法。利用向量點(diǎn)積密度策略對(duì)數(shù)據(jù)點(diǎn)做增量計(jì)算,設(shè)置不同優(yōu)化方法和減枝規(guī)則,降低檢測(cè)復(fù)雜度,減少算法開(kāi)銷,計(jì)算各數(shù)據(jù)點(diǎn)之間的距離,通過(guò)距離判斷出噪聲點(diǎn)。
但是上述方法并沒(méi)有分析數(shù)據(jù)是否完整,導(dǎo)致檢測(cè)的誤報(bào)率和漏報(bào)率較高[3]。為此,本文提出基于中值濾波的含噪聲數(shù)據(jù)檢測(cè)方法。針對(duì)初始數(shù)據(jù)進(jìn)行預(yù)處理,擬合失落數(shù)據(jù)點(diǎn),并通過(guò)異常數(shù)據(jù)評(píng)分的方式提取出異常數(shù)據(jù),再利用中值濾波算法從這些數(shù)據(jù)中檢測(cè)出噪聲數(shù)據(jù)。中值濾波就是將數(shù)據(jù)流中某數(shù)據(jù)的值利用其它數(shù)據(jù)點(diǎn)的中值代替,計(jì)算簡(jiǎn)便且抗干擾性較強(qiáng)[4]。實(shí)驗(yàn)結(jié)果表明,該方法提高檢測(cè)精度,降低漏報(bào)率。
2 噪聲數(shù)據(jù)來(lái)源分析
2.1 數(shù)據(jù)流模型構(gòu)建
隨著網(wǎng)絡(luò)與傳感器技術(shù)的快速發(fā)展,產(chǎn)生了大量實(shí)時(shí)變化的數(shù)據(jù)。這些數(shù)據(jù)來(lái)自網(wǎng)絡(luò)管理、證券交易、電力系統(tǒng)、實(shí)時(shí)傳感器等各個(gè)方面[5]。這些數(shù)據(jù)的大量生成和頻繁變化導(dǎo)致數(shù)據(jù)具有一定突發(fā)性。在數(shù)據(jù)庫(kù)中,數(shù)據(jù)的儲(chǔ)存介質(zhì)比較穩(wěn)定,管理系統(tǒng)能夠?qū)崟r(shí)提交用戶的各類操作。數(shù)據(jù)流模型屬于一種實(shí)時(shí)、連續(xù)、無(wú)界的序列。
假設(shè)利用t代表某時(shí)間戳,ai是該時(shí)間段內(nèi)生成的數(shù)據(jù),則數(shù)據(jù)流描述為{…,ai-1,ai,ai+1,…}。和傳統(tǒng)數(shù)據(jù)模型相比,數(shù)據(jù)流模型具有如下特點(diǎn):
1)數(shù)據(jù)生成具有實(shí)時(shí)連續(xù)性;
2)數(shù)據(jù)生成順序不會(huì)受到系統(tǒng)因素制約;
3)數(shù)據(jù)量大,難以預(yù)測(cè)出最大值。
綜上所述,對(duì)于數(shù)據(jù)流而言,無(wú)法儲(chǔ)存整個(gè)數(shù)據(jù)集合,只能通過(guò)維護(hù)來(lái)保證數(shù)據(jù)結(jié)構(gòu)滿足儲(chǔ)存要求。
2.2 噪聲數(shù)據(jù)來(lái)源分析
根據(jù)數(shù)據(jù)流模型特征,總結(jié)噪聲數(shù)據(jù)主要來(lái)自以下方面:
1)傳輸錯(cuò)誤:數(shù)據(jù)傳輸時(shí),特別在無(wú)線傳輸過(guò)程中,容易發(fā)生數(shù)據(jù)缺失、漏傳等現(xiàn)象,導(dǎo)致傳輸錯(cuò)誤;
2)采集錯(cuò)誤:不同數(shù)據(jù)的采集裝置不同,采集系統(tǒng)的集成度較高,數(shù)據(jù)容易出現(xiàn)誤差,此種情況是不能避免的,因?yàn)閿?shù)據(jù)流作為一個(gè)整體,不能將噪聲數(shù)據(jù)分離出來(lái);
3)離散錯(cuò)誤[6]:離散過(guò)程能夠簡(jiǎn)化數(shù)據(jù)結(jié)構(gòu),方便分析。但是該過(guò)程會(huì)將某連續(xù)變量劃分在離散區(qū)間上,需要通過(guò)離散值來(lái)估計(jì)連續(xù)值,這樣就導(dǎo)致了離散方面的誤差;
4)干擾錯(cuò)誤:一些隱私信息通常會(huì)添加人為干擾,確保這些數(shù)據(jù)不被輕易挖掘。所以,在獲取信息時(shí)容易發(fā)生干擾錯(cuò)誤。
雖然噪聲數(shù)據(jù)屬于異常數(shù)據(jù),但并不是所有異常數(shù)據(jù)都是無(wú)用的,有些數(shù)據(jù)只是屬性值或標(biāo)簽發(fā)生錯(cuò)誤,而并非沒(méi)有價(jià)值。因此,必須對(duì)初始數(shù)據(jù)做預(yù)處理,補(bǔ)全缺失值,確定異常數(shù)據(jù),縮小檢測(cè)范圍以此提高檢測(cè)效果。
3 含噪數(shù)據(jù)預(yù)處理
3.1 失落點(diǎn)數(shù)據(jù)擬合
在數(shù)據(jù)流中,會(huì)存在一些缺失的數(shù)據(jù)點(diǎn),會(huì)影響噪聲檢測(cè)的質(zhì)量,容易出現(xiàn)漏檢現(xiàn)象。針對(duì)這一問(wèn)題,本文利用最小二乘擬合算法[7],經(jīng)過(guò)失落點(diǎn)擬合,準(zhǔn)確預(yù)估出該點(diǎn)的信息值。
選取直線擬合方式補(bǔ)全缺失數(shù)據(jù),假設(shè)數(shù)據(jù)x與y之間存在如下關(guān)系:
y=b0+b1x
(1)
式中,b0與b1分別代表截距與斜率。
針對(duì)采集到的N組數(shù)據(jù)(xi,yi)i=1,2,…,N,利用最小二乘算法將該組數(shù)據(jù)擬合成一條直線,補(bǔ)足缺失點(diǎn)。當(dāng)利用該方法完成參數(shù)估計(jì)時(shí),需要保證yi的加權(quán)平方和最小[8]。
針對(duì)b0和b1求導(dǎo),同時(shí)令b0、b1等于0。則能夠獲得b0、b1的最優(yōu)預(yù)測(cè)值0、1:

(2)

(3)
結(jié)合計(jì)算得出的b0與b1值,即可實(shí)現(xiàn)缺失點(diǎn)補(bǔ)足。
3.2 異常數(shù)據(jù)篩選
異常程度初始評(píng)分的目的是用于確定一個(gè)數(shù)據(jù)集合是否為正常的,這說(shuō)明評(píng)分過(guò)程會(huì)更加關(guān)注正常數(shù)據(jù),也就是給正常數(shù)據(jù)賦予更低的異常評(píng)分[9]。

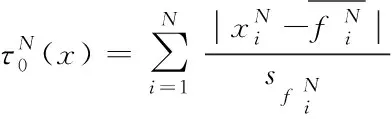
(4)
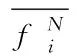
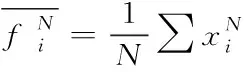
(5)
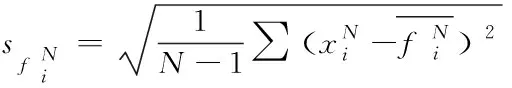
(6)
經(jīng)過(guò)上述預(yù)處理,補(bǔ)全了數(shù)據(jù)流中的缺失值,同時(shí)篩選出異常數(shù)據(jù),減少含噪聲數(shù)據(jù)檢測(cè)的工作量,提高檢測(cè)精度[10]。
4 含噪聲數(shù)據(jù)檢測(cè)
4.1 中值選取
中值濾波能夠避免線性濾波器造成的模糊現(xiàn)象[11],對(duì)濾除噪聲干擾十分有效。中值濾波最方便的處理方法就是通過(guò)某個(gè)條形移動(dòng)窗口在數(shù)據(jù)上進(jìn)行滑動(dòng)[12],進(jìn)而確定出中值。

Yj=Med{xj-v…xj…,xj+v}
(7)
例如,針對(duì)某次測(cè)量工作連續(xù)完成五次采樣,將獲得的數(shù)據(jù)保存在數(shù)列{Sj}(j=5)中,結(jié)合采樣時(shí)間,數(shù)據(jù)的排列順序?yàn)閧S1,S2,S3,S4,S5};再將該序列中的數(shù)值根據(jù)大小重新排序?yàn)?S4>S1>S3>S5>S2。
重新排序后{Sj}(j=5)的中值即為S3,則S3就是濾波輸出。當(dāng)滑動(dòng)窗口H分別為奇數(shù)和偶數(shù)時(shí),計(jì)算公式如下:
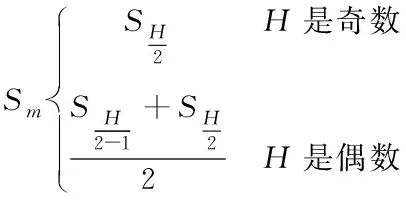
(8)
中值選擇過(guò)程可通過(guò)圖1描述。

圖1 中值確定過(guò)程圖
4.2 含噪聲數(shù)據(jù)檢測(cè)架構(gòu)
綜合上述滑動(dòng)窗口模型的特征,隨著時(shí)間推移數(shù)據(jù)會(huì)持續(xù)生成,保存的數(shù)據(jù)會(huì)越來(lái)越多,為了快速預(yù)測(cè)數(shù)據(jù)流中的未來(lái)元素,難以將全部元素當(dāng)做歷史數(shù)據(jù)。因此,利用預(yù)測(cè)窗口方法[13],設(shè)定預(yù)測(cè)窗口如下:
Dt={xi-q,xi-q+1,…,xq}
(9)
公式中,q代表預(yù)測(cè)窗口尺寸,通常情況下,該尺寸小于滑動(dòng)窗口,結(jié)合預(yù)測(cè)窗口的數(shù)據(jù),估計(jì)xi+1的平均值與置信區(qū)間。
因數(shù)據(jù)流具有數(shù)量大、實(shí)時(shí)變化的特點(diǎn),為提高檢測(cè)效率,構(gòu)建如下基于中值濾波算法的含噪聲數(shù)據(jù)檢測(cè)框架[14],主要步驟描述為:

步驟二:通過(guò)概率P運(yùn)算數(shù)據(jù)在t+1時(shí)段內(nèi)數(shù)值波動(dòng)區(qū)間,計(jì)算公式如下:

(10)


(11)

(12)
步驟三:當(dāng)數(shù)據(jù)全部生成時(shí),與步驟二設(shè)定的區(qū)間進(jìn)行對(duì)比,若高于預(yù)測(cè)區(qū)間,則說(shuō)明數(shù)據(jù)為噪聲數(shù)據(jù),反之為正常數(shù)據(jù);
步驟四:如果檢測(cè)的數(shù)據(jù)為噪聲數(shù)據(jù),則及時(shí)更新預(yù)測(cè)窗口;
步驟五:反復(fù)操作上述步驟,即可完成含噪聲數(shù)據(jù)檢測(cè)。
5 仿真過(guò)程與結(jié)果分析
本文將在某傳感器數(shù)據(jù)集上完成相關(guān)實(shí)驗(yàn),該數(shù)據(jù)集共分為12組,其中訓(xùn)練集9組,測(cè)試集合3組,每組數(shù)據(jù)都包括正類與負(fù)類樣本。所有數(shù)據(jù)集都會(huì)按照由小到大的比例進(jìn)行標(biāo)簽翻轉(zhuǎn),以此模擬實(shí)際應(yīng)用中的噪聲數(shù)據(jù)。仿真平臺(tái)如圖2所示。
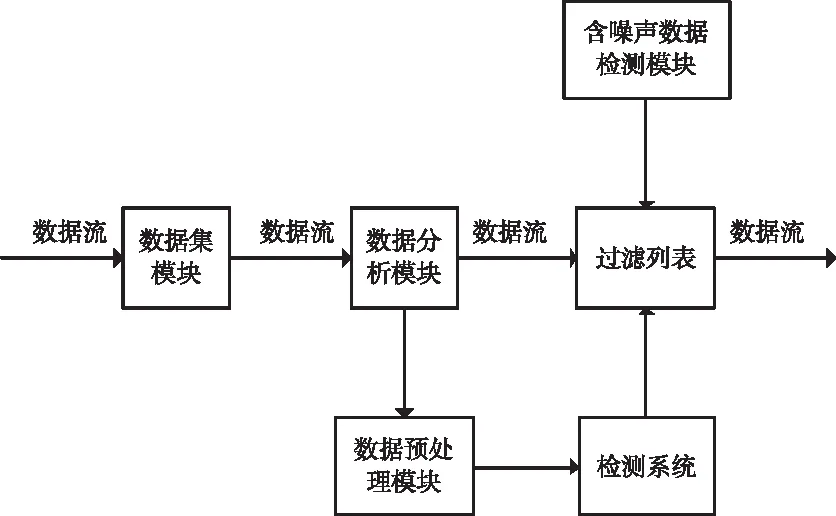
圖2 仿真平臺(tái)結(jié)構(gòu)示意圖
1)數(shù)據(jù)預(yù)處理效果測(cè)試
預(yù)處理效果直接影響后續(xù)的檢測(cè)效果,以傳感器數(shù)據(jù)集合中的位置數(shù)據(jù)為例,利用本文失落數(shù)據(jù)點(diǎn)擬合算法對(duì)缺失數(shù)據(jù)做擬合處理,處理前、后的數(shù)據(jù)如圖3和4所示。
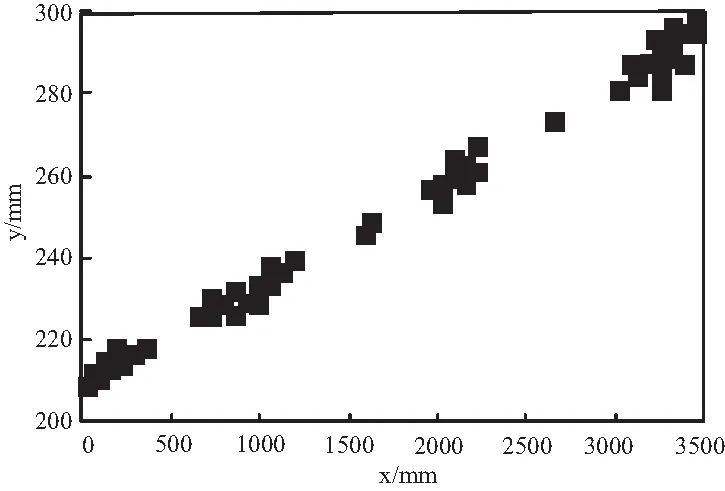
圖3 擬合前數(shù)據(jù)效果圖
圖3中的空白部分為傳感器缺失數(shù)據(jù)值,圖4為利用最小二乘擬合法擬合后的數(shù)據(jù),由此可知經(jīng)過(guò)本文方法處理后補(bǔ)齊了輪廓線,減少失落信息點(diǎn),為含噪數(shù)據(jù)檢測(cè)打下良好基礎(chǔ),能夠有效降低漏檢率。

圖4 擬合后數(shù)據(jù)效果圖
2)含噪聲數(shù)據(jù)檢測(cè)效果測(cè)試
以上述實(shí)時(shí)傳感數(shù)據(jù)為例,分別利用本文方法、改進(jìn)支持向量描述算法、局部向量點(diǎn)積密度算法進(jìn)行含噪聲數(shù)據(jù)檢測(cè),檢測(cè)結(jié)果如圖5所示。

圖5 不同方法的含噪聲數(shù)據(jù)檢測(cè)結(jié)果示意圖
分析圖5可知,本文方法能夠?qū)?shí)時(shí)傳感數(shù)據(jù)中的噪聲數(shù)據(jù)全部檢測(cè)出來(lái),而改進(jìn)支持向量描述方法出現(xiàn)了漏檢現(xiàn)象,有個(gè)別噪聲數(shù)據(jù)沒(méi)有被檢測(cè)出來(lái);局部向量點(diǎn)積密度法還出現(xiàn)誤檢情況,有些正常數(shù)據(jù)被檢測(cè)為噪聲數(shù)據(jù)。整體來(lái)看,本文方法對(duì)噪聲數(shù)據(jù)的檢測(cè)最為準(zhǔn)確,這是因?yàn)榻?jīng)過(guò)失落點(diǎn)擬合和初始異常數(shù)據(jù)評(píng)分等過(guò)程有效提高了檢測(cè)精度。
上述測(cè)試只針對(duì)實(shí)時(shí)傳感數(shù)據(jù),在實(shí)際應(yīng)用中還有很多類型的數(shù)據(jù)。為了證明所提方法的實(shí)用性,分別選用網(wǎng)絡(luò)管理數(shù)據(jù)、證券交易數(shù)據(jù)、電力數(shù)據(jù)等進(jìn)行測(cè)試,并將召回率與F1值作為評(píng)價(jià)指標(biāo),計(jì)算公式如下。并繪制三種算法對(duì)于這些數(shù)據(jù)的檢測(cè)箱型圖,如圖6和7所示。

圖6 不同方法F1值測(cè)試結(jié)果對(duì)比圖
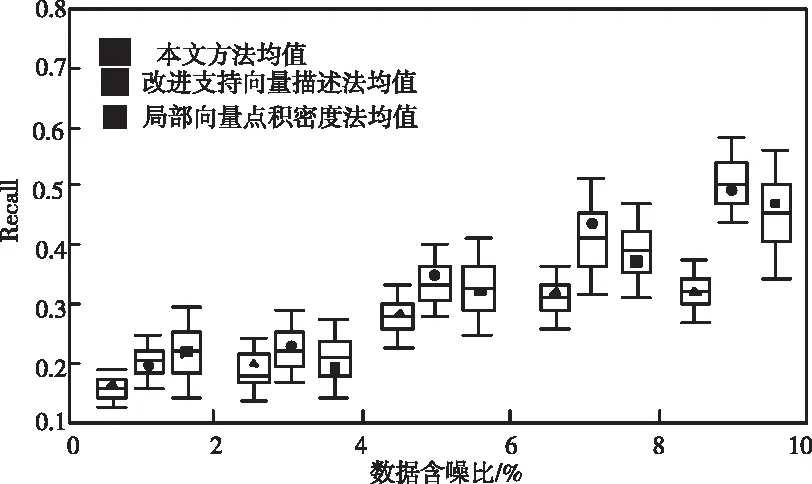
圖7 不同算法Recall值測(cè)試結(jié)果對(duì)比圖
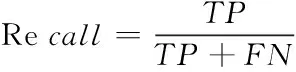
(13)

(14)
式中,TP代表正常數(shù)據(jù)被認(rèn)為是正常的分類,FN代表正常數(shù)據(jù)被認(rèn)為是噪聲數(shù)據(jù)的錯(cuò)誤分類。Precision代表準(zhǔn)確率。計(jì)算公式分別如下:

(15)
式中,FP代表噪聲數(shù)據(jù)被認(rèn)為是正常數(shù)據(jù)的錯(cuò)誤分類,TN代表噪聲數(shù)據(jù)被認(rèn)為是噪聲數(shù)據(jù)的正確分類。
如圖6和7所示的箱型圖不僅能夠反映不同方法對(duì)于不同數(shù)據(jù)集的整體檢測(cè)精度,還能體現(xiàn)出算法的穩(wěn)定性。箱體內(nèi)的線段代表含噪聲檢測(cè)方法在不同數(shù)據(jù)集中的F1值和召回率的中位數(shù),箱體描述所有實(shí)驗(yàn)結(jié)果的數(shù)值分布區(qū)間,箱體越短說(shuō)明測(cè)試結(jié)果越集中。
由此可以看出,本文方法的F1值明顯高于其它方法,同時(shí)沒(méi)有受到噪聲數(shù)據(jù)多少的影響,始終保持在較高水平,說(shuō)明所提方法的誤報(bào)率低且準(zhǔn)確率高,而其它方法的F1值均隨噪聲含量的增多出現(xiàn)明顯下降趨勢(shì)。此外,中值濾波算法的召回率比其它方法低,意味著該方法更加可靠,能夠?qū)W習(xí)到噪聲數(shù)據(jù)的更多特征;且所提方法的整體箱型較短,說(shuō)明測(cè)試數(shù)值較為集中,方法檢測(cè)性能更加穩(wěn)定。
6 結(jié)論
在各領(lǐng)域數(shù)據(jù)量急劇增長(zhǎng)背景下,數(shù)據(jù)結(jié)構(gòu)變得更加復(fù)雜,且其中會(huì)摻雜很多噪聲數(shù)據(jù)。因此,本文利用中值濾波算法對(duì)噪聲數(shù)據(jù)檢測(cè)展開(kāi)深入研究。通過(guò)失落點(diǎn)擬合和初始數(shù)據(jù)異常評(píng)分等過(guò)程對(duì)數(shù)據(jù)做預(yù)處理,確定出異常數(shù)據(jù),針對(duì)這些異常數(shù)據(jù),利用中值濾波算法構(gòu)建含噪聲數(shù)據(jù)檢測(cè)架構(gòu),進(jìn)一步檢測(cè)出噪聲數(shù)據(jù)。實(shí)驗(yàn)結(jié)果表明,所提方法有效解決了噪聲干擾問(wèn)題,為數(shù)據(jù)分析提供更高質(zhì)量的數(shù)據(jù)。現(xiàn)階段,大部分?jǐn)?shù)據(jù)都是實(shí)時(shí)的,所以實(shí)時(shí)檢測(cè)技術(shù)更加符合數(shù)據(jù)處理需求,在今后研究中應(yīng)完成從靜態(tài)數(shù)據(jù)到動(dòng)態(tài)數(shù)據(jù)的完全跨越,不斷提高含噪聲數(shù)據(jù)檢測(cè)的實(shí)用性。
猜你喜歡
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
兒童故事畫(huà)報(bào)(2019年5期)2019-05-26 14:26:14
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
