基于頻域Transformer的對抗生成網絡去運動模糊算法
2023-10-30 04:32:42顧軍華牛炳鑫李春杰
現代計算機 2023年16期
關鍵詞:模型
顧軍華,李 巖,陳 晨,牛炳鑫*,李春杰
(1.河北工業大學人工智能與數據科學學院,天津 300401;2.河北省大數據計算重點實驗室(河北工業大學),天津 300401;3.河北高速公路集團有限公司,石家莊 050000)
0 引言
圖像去模糊方法一般是嘗試通過去除模糊偽影來將模糊圖片恢復成清晰圖像。圖像中的模糊現象受到許多因素的影響,如快速運動的物體、失焦、抖動等。由于圖像去模糊是一種不適定問題,從模糊圖像恢復到清晰圖像是一個比較具有挑戰性的任務。基于模糊核估計的模型[1,2]一般是同時估計模糊圖像的模糊核及其清晰圖像。但模糊核估計方法對噪聲比較敏感且目前的模糊核估計方法適應情況少。現實世界中大多數運動模糊情況都屬于不均勻運動模糊,如十字路口一類的動態場景,會有多個物體以不同幅度向不同方向運動。在圖像去模糊任務上,還有一類是端到端的方法,這一類方法無需估計模糊核。目前端到端的方法主要分有對抗和無對抗兩大類,其中大部分模型均使用卷積神經網絡(convolutional neural networks,CNN)進行設計。
目前基于CNN 的去模糊模型研究也都是盡量增大感受野以提高模型的恢復效果。雖然可以通過堆疊卷積層來提升感受野范圍,但是堆疊過多的卷積層會增加參數量和計算量,并且更容易出現噪聲。為了解決以上問題,本文提出了頻域Transformer 圖像去運動模糊模型。Transformer[3]的自注意力機制可以對自身及其他所有位置的像素來建立依賴關系,相當于擁有全局感受野。對于去模糊任務而言,越大的感受野越容易處理劇烈的運動模糊情況。Dosovitskiy等[4]提出的視覺 Transformer(vision transformer,ViT)模型證明了Transformer 在圖像領域的可行性,并且相對于CNN 網絡而言,Transformer 沒有歸納偏差問題。Transformer雖然具有強大的表示能力,但是僅從空域層面處理圖像還是不夠的,因此提出了空頻處理模塊(spatial frequency processing module,SFPM)。通過傅里葉變換將數據從空域轉換到頻域,利用頻率成分和空域圖像間的對應關系,一些在空域難以表述的問題在頻域就能迎刃而解。采用傅里葉變換轉換到頻域后通過其中的平行條紋很容易觀察到運動模糊的方向和大小,因此對頻域圖進行分解操作可以充分利用運動模糊在頻域圖中所體現的方向性特征,從而更有效地恢復運動模糊。由于頻域是有限的頻率表示圖像,僅從頻域處理可能會損失某些信息,因此空域和頻域一同處理可以達到互補的目的。
1 頻域Transformer圖像去運動模糊模型
端到端模型的目的是僅將模糊圖像Ib作為輸入來恢復清晰圖像,不需要模糊核。在訓練階段,有兩個網絡需要訓練,一個是鑒別器,用于區分生成的結果和真實的清晰圖像;另一個是生成器,對其輸入模糊圖片,并輸出一個足以騙過鑒別器的結果。
1.1 模型架構
如圖1 所示,本文提出的網絡基于生成對抗網絡,由生成器和鑒別器兩部分組成,以對抗方式進行訓練。

圖1 模型整體架構
訓練過程中向生成器輸入模糊圖像,而不是像原生的生成對抗網絡(generative adversarial network,GAN)[5]一樣輸入一個隨機噪聲向量。然后通過判別器比較生成器的輸出與清晰圖像之間的差異。其中生成器使用頻域Transformer,判別器使用PatchGAN來進行對抗訓練。
1.2 頻域Transfoorrmmeerr生成器
生成器架構如圖2所示,生成器整體采用U形結構并在編碼器與解碼器間加入了殘差連接。給定一個模糊圖片Ib=RH×W×3,其中H表示圖像的高度,W表示圖像的寬度,3 表示圖像的RGB 通道,模型首先使用卷積層將輸入映射到高維空間來得到特征圖。然后將特征圖傳遞到后面的SFPM 模塊,每個SFPM 模塊包括多個Transformer模塊和一個頻域處理模塊,它們以并行的方式處理輸入圖像。映射后的特征圖通過空頻處理模塊(spatial frequency processing module,SFPM)向下傳遞多層,每個空頻處理模塊包含多個Transformer塊以及一個頻域處理模塊,兩者以并行的方式進行工作。每經過一個空頻處理模塊進行一次下采樣,下采樣通過卷積實現。帶有下采樣部分的左半部分是生成器的編碼器,右半部分則是解碼器。解碼器中首先通過PixelShuffle操作在不丟失信息的前提下進行上采樣,然后輸入到空頻處理模塊進行學習。最后通過一個精煉模塊來對輸出作最后的調整。

圖2 生成器架構
Transformer 的自注意力機制能夠學習全局之間的關系,但是直接用它來處理高分辨率圖像,會使得訓練速度變得很慢,并且對于硬件要求也更高。為了滿足處理大分辨率圖片的需求,引入了局部自注意力機制,通過設置一個窗口大小來控制自注意力的計算范圍,有效減少了計算量。同時結合U 形網絡,在淺層進行局部注意力計算,提取細節特征;在深層進行全局注意力計算,得到全局信息。編碼器部分的每個SFPM 模塊都包含卷積下采樣操作,輸入每通過編碼器其中的一個SFPM,尺寸就會進行縮減,相應地,特征就會增加。當輸入變得足夠小時,就可以將自注意力應用于整個特征圖,從而學習到全局信息。通過這種方法,既可以獲得局部細節,又可以獲得全局信息。在解碼器部分使用的則是亞像素卷積上采樣層,可以表示為如下公式:
1.3 空頻處理模塊
圖像的退化過程可以理解為是將算子H作用在一個輸入圖片f(x,y)上來生成退化圖像g(x,y)。如果算子H已知,那么可以很容易地將退化圖像恢復成原始圖像。但在很多情況下并不能得到這樣一種準確的理想的算子,只能盡量近似它。根據卷積定理,空域中的卷積操作可以轉換為頻域乘法,因此一些直接在空間域表述非常困難,甚至不可能的任務在頻域中變得非常普通。
空域中的卷積操作轉化到頻域可以簡化為乘積操作,圖3 中清晰圖像的頻域圖(a)與頻域模糊核(b)進行乘積可得模糊圖像的頻域圖。同樣地,模糊圖像的頻域圖除以頻域模糊核即可得到清晰圖像的頻域圖。因此模型只需要擬合出圖3(b)的倒數再乘上輸入的模糊圖像的頻域圖即可得到清晰圖像。

圖3 頻域乘積示例
在現實世界中模糊圖像與清晰圖像在其頻域圖上仍然有明顯的區別。場景中各種物體的邊緣在頻域圖中相互疊加,頻域中可見的條紋由整幅圖像的抖動而來,圖像的空域信息和頻域信息可以相互補充,充分利用這兩部分信息可以更好地抑制圖像中的模糊偽影。空頻處理模塊設計如圖4(a)所示,左側為Transformer 分支,用于處理空域信息;右側分支為頻域處理分支,用于對頻域圖像進行處理。空域信息和頻域信息并行處理,最后進行融合得到SFPM 模塊的輸出。隨著U 形網絡的加深,SFPM 模塊所處理的特征維度就越高,且越注重全局信息,結合U 形網絡的特點,頻域處理模塊更是可以關注不同層次大小的頻域圖信息。
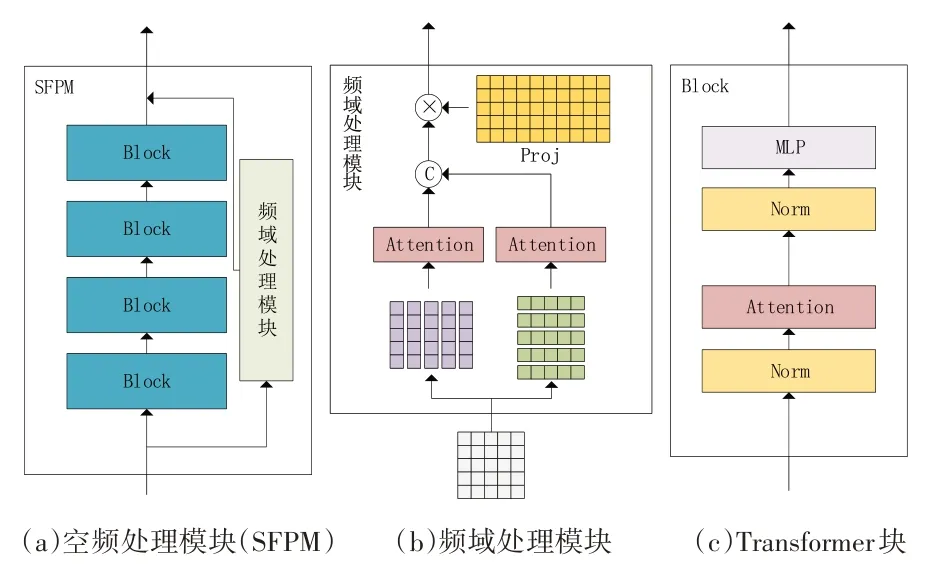
圖4 空頻處理模塊內部結構
為了在頻域對圖像進行處理需要先將圖像轉換到頻域,通過離散傅里葉變換(discrete fourier transform,DFT)轉換而來的頻域圖可以清晰地反映運動模糊的方向與大小。再將頻域圖沿水平垂直方向進行分解,然后計算各自的注意力,可以充分利用運動模糊在頻域中體現的特征,有效地恢復頻域圖。DFT 是采樣后的傅里葉變換,它不包含組成圖像的所有頻率,可能會丟失一些細節信息,因此僅在頻域處理是不夠的,還要結合空域一起處理才能起到互補的作用。
由于模糊圖像的頻域圖包含模糊圖像中的運動方向及幅度,因此頻域處理模塊將頻域圖沿橫縱軸進行分解,將不同方向的模糊頻率分解為水平和垂直方向,然后對分解后的向量分別進行注意力計算。垂直分解的向量表示為i∈{1,…,W},其中W表示圖像寬度;水平分解的向量表示為,j∈ {1,…,H},其中H表示圖像高度。在分解后的向量進行注意力計算之前,首先對其特征維度使用1 × 1 的卷積層擴充至其自身的兩倍,由于頻域圖中包含豐富的不同方向和幅度的頻率,通過擴充分解向量的特征數有助于提高模塊的表達能力,不會丟失關鍵信息。該步驟如下所示:
合并所有垂直分解向量的注意力輸出即可得到垂直注意力輸出Ov。以同樣的方式對水平分解向量進行計算可得Oh。然后將垂直和水平的注意力輸出合并起來并通過矩陣K∈ R2W×W×2C將輸出映射為輸入尺寸,并再次使用1 × 1 的卷積層對特征維度進行聚合,表示如下:
其中:O∈ RH×W×C表示模塊的輸出,iDFT表示離散傅里葉變換的逆運算。傅里葉變換中,低頻主要決定圖像在平滑區域中總體灰度級的顯示,而高頻決定圖像細節部分,如邊緣和噪聲。模糊問題也可以理解為原本高頻銳利的邊緣經過模糊之后變得更平滑,因此去模糊任務就是從比較平滑的低頻區域將原本應是高頻邊緣的部分恢復出來。
1.4 損失函數
原生GAN 的損失函數在兩個數據分布完全不重合的時候,JS 散度恒為log 2,所以模型也無法更新。因此損失函數選用WGAN-GP[6]進行訓練,公式如下:
其中:懲罰項對分布Ppenalty進行采樣,分布Ppenalty介于Pdata與PG之間,只需要保證在該分布的采樣的梯度范數小于等于1 即可。此外還增加了一個感知損失函數,感知損失認為生成圖像是從內容圖變換而來,通過計算內容損失不斷迭代生成圖片,使其越來越接近內容圖。在去模糊任務中,生成圖像指的是模糊圖像,而內容圖則是清晰圖像。感知損失函數如下所示:
其中:j表示VGG 網絡的第j層,CjHjWj表示第j層特征圖的尺寸。將對抗損失函數和感知損失函數組合起來就是模型最終的損失函數,其中λ1和λ2是兩個超參數:
2 實驗部分
2.1 數據集
實驗使用GoPro[7]數據集作為訓練集和測試集。它由3214 幅模糊圖像和對應的清晰圖像組成,分辨率為1280 × 720,其中2103 對用于訓練,1111 對用于測試。它使用GoPro 相機以視頻的方式捕捉幀,然后對前后連續短曝光的幀進行平均,生成模糊圖像。
另一個用于測試的RealBlur[8]數據集使用兩個相同型號的相機來捕捉圖像,其中一個是以高快門速度進行拍照,另一個是以低快門速度拍照。由研究人員手持兩臺相機構成的拍攝系統在街道中進行隨機拍攝,該數據集采集到的模糊圖像更為真實。它們都包含4738 對圖像,其中980對用于測試,其余用于訓練。
2.2 實驗設置
實驗使用PyTorch 來實現本文的模型,該模型無需預訓練。訓練是在帶有AMD 5950X CPU以及單塊Nvidia GeForce RTX 3090Ti GPU 的服務器上進行的。實驗將圖像裁剪為幾個大小為256 × 256 的圖像塊,批量訓練大小設置為1。在訓練階段,使用ADAM[9]優化器對模型進行訓練。學習率設置為10-6,使用余弦退火策略逐步降低學習率。實驗使用上述配置在GoPro數據集上訓練了300 輪,然后在模糊圖像數據集GoPro和RealBlur 上對所提出的去模糊模型分別進行了測試。
2.3 實驗結果
實驗在GoPro 和RealBlur 數據集上進行了測試。圖5展示了各模型的效果對比。

圖5 去模糊方法對比
表1 顯示了模型在峰值信噪比(peak signal to noise ratio,PSNR)和結構相似度(structural similarity,SSIM)指標上優于其他方法。

表1 模型測試結果
該模型在GoPro和RealBlur兩個數據集上與幾個經典的去模糊模型進行了比較,其中DeblurGAN和DeblurGANv2 是同一個團隊提出的,使用的是CNN 構成的GAN 網絡。結果表明本文提出的模型在兩個數據集上分別比其他方法至少提高了0.72 dB 和0.83 dB,表現出較強的泛化能力。此外,圖6 展示了一些去模糊的結果圖與頻域圖。
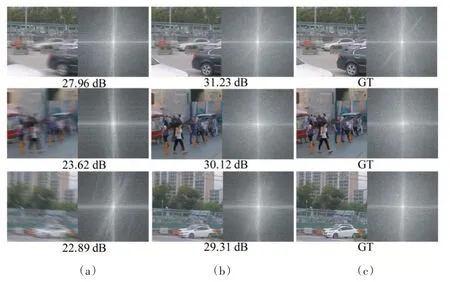
圖6 GoPro數據集的訓練結果
由圖中頻域圖像也可看出,模型對圖像的恢復體現在頻域中的效果很明顯,成功濾除了造成模糊的頻率條紋。
2.4 消融實驗
本節詳細分析了模型中組件的作用,并在GoPro 和RealBlur 兩個數據集上進行對比實驗,實驗結果見表2。U 形網絡結構的性能優于簡單的對生成器的輸入和輸出應用殘差連接,如表2中的(A)和(B)所示。它將每個下采樣階段的特征圖與對應的上采樣階段使用殘差連接結合起來。在U形網絡結構中,網絡越深感受野越大,網絡將更加關注更抽象的全局相關性。相比之下,當網絡深度較淺時,它會更加關注紋理細節。
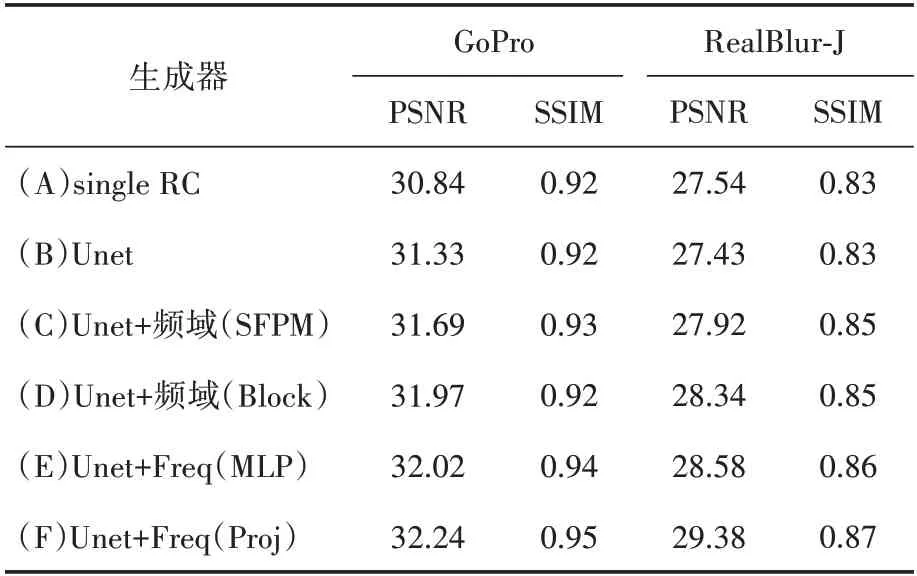
表2 消融實驗結果
本節嘗試將頻域處理模塊置于不同位置,結果顯示頻域處理模塊的位置對于去模糊效果是有影響的。(C)嘗試將頻域處理模塊置于與U形網絡并行的位置,使其與Transformer 的U 形網絡共享輸入再合并輸出。與之相比,(D)中將頻域處理模塊放入Transformer塊或(E)中將頻域處理模塊放入MLP 中的性能要更好。當頻域處理模塊與U 形網絡并行時,直接對圖像進行處理,將輸入轉換到頻域后對輸入進行卷積運算。它只能用有限的頻率在頻域表示圖像,這意味著它會丟失一些信息。但將其放入與Transformer塊并行的位置,它就可以處理多個不同大小的特征映射,并可以獲得全局和局部的相關性。關于表2 中的(E),是將頻域處理模塊部署在MLP 模塊旁邊。雖然最后的分數有一定的提升,但計算量比(D)提高了3 倍左右。在(F)中,再把它放回Transformer 塊的旁邊,同時改變其內部結構。在(C)和(D)中,只在頻域對圖像進行橫縱向分解后的注意力計算,而(F)中,增加了一個投影矩陣,橫縱向分解向量進行注意力計算后通過該投影矩陣可以自動學習關鍵信息,結果也表明該方法對于去模糊的效果有一定的改善。
3 結語
本文提出一種端到端的基于GAN 的頻域Transformer 的去模糊模型,無須估計模糊核,主要面向不均勻運動模糊問題。文中對Transformer的內部結構進行了重新設計,加入了頻域處理模塊,使得模型能夠同時在空域和頻域上對圖像進行恢復,充分利用了運動模糊在頻域圖中的特征,與Transformer 處理空域互補,取得了更好的恢復效果。同時生成器U 形網絡的架構,使得模型能夠處理高分辨率圖片,并且可以學習到模糊圖片的局部細節以及全局信息。得益于Transformer 的特性,模型對于數據增廣的收益要大于基于CNN 的模型,數據量越大對模型效果越有利。模型受益于Transformer 的自注意力機制,但同樣受制于自注意力機制,因為對于高分辨率圖片構成的輸入序列已經屬于超長序列,自注意力計算的代價很大,造成了模型參數量大、計算速度慢的問題,后續工作需在此基礎上壓縮模型參數量,提高模型運行效率,便于部署在計算資源有限的嵌入式終端,如交通監控攝像頭等設備。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
