微博數(shù)據(jù)爬蟲的檢測方法研究
2023-10-30 04:32:52黃志高
現(xiàn)代計算機 2023年16期
黃志高
(泉州師范學院物理與信息工程學院,泉州 362000)
0 引言
網(wǎng)絡爬蟲在各個領域用于收集數(shù)據(jù),即使目標站點禁止機器人爬蟲,某些網(wǎng)絡爬蟲也會收集數(shù)據(jù),某些Web 服務嘗試通過反爬蟲程序方法檢測爬蟲活動并阻止爬蟲程序訪問網(wǎng)頁,但某些惡意Web 爬蟲通過修改其標頭值或分發(fā)源IP 地址來偽裝自己[1],從而繞過檢測方法,就好像它們是普通用戶一樣。
一些公司禁止網(wǎng)絡爬蟲訪問他們的網(wǎng)頁,原因如下:首先,網(wǎng)絡爬蟲可能會降低網(wǎng)絡服務器的可用性;其次,網(wǎng)絡服務器中的內(nèi)容被視為公司的知識產(chǎn)權(quán)。競爭公司可以復制網(wǎng)絡服務器中提供的全部數(shù)據(jù),競爭公司可能會向客戶提供類似的服務。本文研究了傳統(tǒng)的反爬蟲方法和各種回避技術(shù),表明傳統(tǒng)的反爬蟲方法不能阻止分布式爬蟲。然后,提出了一種新的反爬蟲方法,即長尾閾值模型(LTM)方法,該方法逐漸將分布式爬蟲的節(jié)點IP 地址添加到阻止列表中。實驗結(jié)果表明,該方法能夠有效識別誤報率為0.02%的分布式爬蟲。在傳統(tǒng)的基于頻率的方法中[2],當增加閾值以檢測更多的爬蟲節(jié)點時,誤報也會相應增加。
1 傳統(tǒng)反爬蟲方法及其缺陷
1.1 使用HTTP標頭信息進行過濾
基本爬蟲程序發(fā)送請求而不修改其標頭信息,Web 服務器可以通過檢查請求標頭來區(qū)分合法用戶和爬蟲程序,此標頭檢查方法是一種基本的反爬蟲方法。但是,如果爬蟲試圖將自己偽裝成合法用戶,它將使用來自Web 瀏覽器的標頭信息或類似于瀏覽器的HTTP 標頭信息重置[3]。這使得Web 服務器很難通過簡單地檢查請求標頭來確定客戶端是爬蟲程序還是合法用戶。
1.2 基于訪問模式的反爬蟲
基于訪問模式的反爬蟲方法根據(jù)客戶端生成的請求模式將合法用戶與爬蟲程序進行分類。如果客戶端僅連續(xù)請求特定網(wǎng)頁,而不調(diào)用通常應請求的網(wǎng)頁,則該客戶端將被視為爬蟲程序。執(zhí)行主動爬蟲的爬蟲程序預定義了爬蟲程序想要收集的核心網(wǎng)頁,爬蟲程序請求特定的網(wǎng)頁而不請求不必要的網(wǎng)頁。在這種情況下,Web 服務器可以識別客戶端不是合法用戶。通過分析客戶端訪問模式的Web 服務,該服務可以根據(jù)預定義的普通用戶的訪問模式將爬蟲程序與普通用戶區(qū)分開來。雖然這種方法可以根據(jù)訪問模式識別爬蟲,但一些爬蟲甚至通過分析網(wǎng)絡日志來偽裝他們的訪問模式。
1.3 基于訪問頻率的反爬蟲
基于訪問頻率的反爬蟲方法通過訪問頻率閾值作為特定時間范圍內(nèi)的最大訪問次數(shù)來確定客戶端是爬蟲還是合法用戶。如果來自客戶端的請求數(shù)在預定義的持續(xù)時間內(nèi)超過某個閾值,則Web 服務器會將客戶端分類為爬蟲程序。這種方法有兩個眾所周知的問題。首先,它對分布式爬蟲有漏洞。如果攻擊者使用分布式爬蟲(如Crawlera),則可以管理每個爬蟲節(jié)點的訪問速率保持在閾值以下[4]。其次,普通用戶和爬蟲程序共享單個公共IP 地址,容易被誤識別為爬蟲程序。
2 阻止分布式爬蟲
如上所述,分布式爬蟲程序可以繞過傳統(tǒng)的反爬蟲方法。我們提出了一種新技術(shù)來檢測和阻止傳統(tǒng)反爬蟲技術(shù)無法防御的分布式爬蟲。
2.1 所需的爬蟲節(jié)點數(shù)
為了使分布式爬蟲收集網(wǎng)站的全部數(shù)據(jù),必須滿足以下條件:
其中:Um是一個月內(nèi)更新的項目數(shù),Td是每個IP 地址的最大請求數(shù),Cn是爬蟲程序節(jié)點數(shù)(IP 地址),30 是一個月的天數(shù)。Td乘以 30 得到每月的請求數(shù)。
爬蟲程序節(jié)點需要收集每月所有更新的數(shù)據(jù)。每月更新數(shù)據(jù)數(shù)除以每月最大請求數(shù)。例如,如果一個月內(nèi)有Web 服務更新30000 個項目,并且該服務具有限制規(guī)則,即具有多個(例如100)請求的IP 地址將被阻止,并且嘗試從Web 服務收集每個項目的攻擊者將需要例如10個爬蟲程序節(jié)點來避免限制。因此,隨著Um增加或Td減少,應該增加Cn并以數(shù)字表示網(wǎng)站難以抓取的級別。
2.2 生成長尾區(qū)域
一個月內(nèi)更新的項目數(shù)量不能隨意增加。因此,防止分布式爬蟲的一種簡單方法是Td減少,但這也會顯著增加誤報。在本文中,我們通過反轉(zhuǎn)Web 流量的一般特征并利用分布式爬蟲嘗試復制Web 服務器的整個數(shù)據(jù)的事實來解決這個問題。如果項目按訪問率排序,我們可以在圖表中看到指數(shù)遞減曲線,如圖1 所示。大多數(shù)網(wǎng)絡流量集中在最常請求的項目上,并且有一個長尾區(qū)域具有較低的訪問率。我們計算了此長尾區(qū)域的最大請求計數(shù),并將此值設置為Td3。
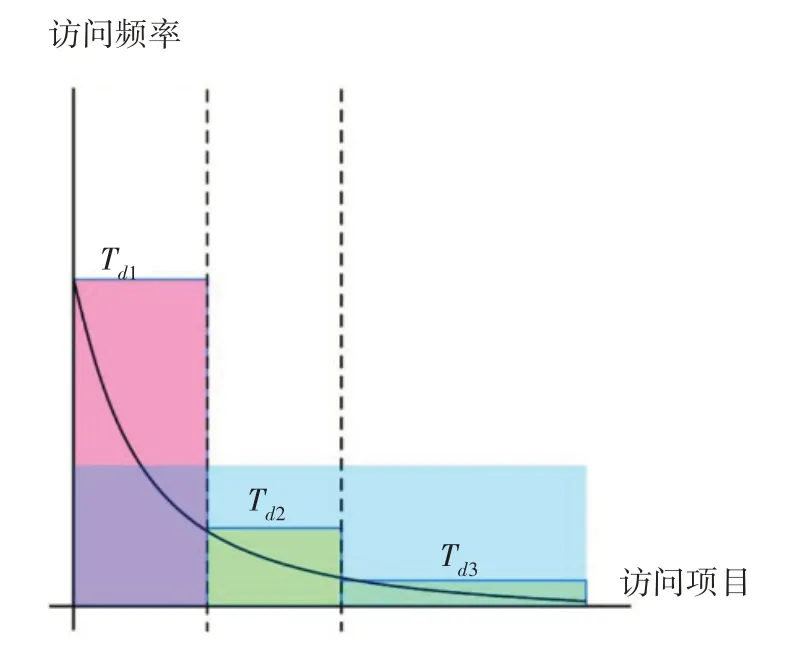
圖1 每個鏈接的訪問頻率
在信息論中,不太可能的事件比可能的事件更具信息量,而長尾地區(qū)的事件比其他事件更不可能。這意味著Web 服務可以從長尾區(qū)域的請求中查找更多信息。因此,當客戶端不斷請求長尾區(qū)域中的項目時,Web 服務可以增加計數(shù),直到達到Td3,而不是達到Td平均值。這意味著Web 服務可以設置更敏感的閾值,而不會增加誤報率。
2.3 長尾區(qū)域節(jié)點縮減
為了使攻擊者從Web 服務收集整個數(shù)據(jù),攻擊者還必須訪問長尾區(qū)域中的項目。但是,攻擊者并不確切知道哪些項目屬于長尾區(qū)域。利用這種信息不對稱性,服務提供商可以輕松識別比其他IP 地址更頻繁地訪問項目的IP 地址。這些已識別的爬蟲程序的IP 地址將包含在阻止列表中,并且阻止列表中的IP 地址數(shù)將為Cm。如果我們開始通過長尾間隔增加該Cm值,攻擊者將使用較少數(shù)量的IP 地址進行爬行,并且會在Td間隔內(nèi)增加Cm[5]。
2.4 虛擬項目
服務提供商可能會添加虛擬項目來檢測爬蟲程序,并且合法用戶無法訪問虛擬項目,因為虛擬項目沒有用戶界面或隱藏。生成虛擬項目的方法很少,它可能以HTML 標簽的形式存在,但屬性設置不會顯示在屏幕上,或者可能包含普通用戶不感興趣的垃圾信息。但是,對服務執(zhí)行順序訪問的爬蟲程序可能會訪問虛擬項目。通過這一特性,虛擬項目可以作為長尾區(qū)域的延伸。在本文中,我們不會在實驗中包含虛擬項目,以便與不包含任何虛擬項目的真實流量日志進行公平比較[6]。
3 實驗測試
實驗旨在評估爬蟲檢測模塊對網(wǎng)絡流量的分類性能。將LTM 方法與基于正常訪問頻率的反爬蟲方法在爬蟲節(jié)點的最大數(shù)量和誤報率上進行了比較[7]。在實驗中使用這個數(shù)據(jù)集有兩個因素,一個是用戶數(shù),另一個是網(wǎng)站中的項目數(shù)。用戶數(shù)量很重要,因為如果用戶數(shù)量較少,某些用戶可能會偏向流量模式。為了實現(xiàn)這一目標,我們開發(fā)了一個基于Python 的數(shù)據(jù)工具和一個模擬器。在數(shù)據(jù)預處理工具中,如圖2所示對原始流量數(shù)據(jù)進行預處理,以計算單個URL 的訪問頻率,并對屬于長尾區(qū)域的集進行分類。每當發(fā)生新的訪問時,模擬器根據(jù)預處理的數(shù)據(jù)確定訪問節(jié)點是否為爬蟲程序。
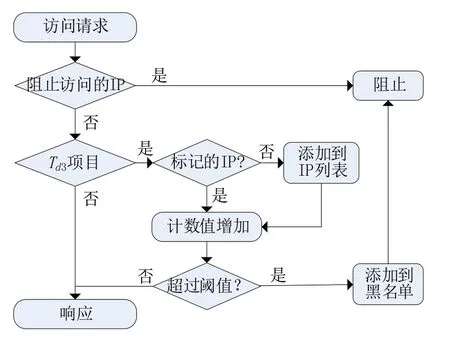
圖2 爬蟲檢測流程
3.1 數(shù)據(jù)源
NASA 在2005 年7月共公布了2493425份訪問日志。我們將這些日志解析為csv 格式,該格式由四列組成,包括IP 地址、日期、訪問目標和訪問結(jié)果。連接的IP 地址總數(shù)為41958,項目數(shù)為21534。
3.2 數(shù)據(jù)預處理和流量分配
我們在實驗的預處理階段執(zhí)行了三個步驟。第一步將日志拆分為兩個數(shù)據(jù)集:訓練集和測試集。在NASA 訪問日志中,前24 天日志設置為訓練集,最后一個日志設置為測試集。第二步篩選出一些訪問日志,以計算更準確的訪問計數(shù)。某些請求合并為單個請求,以防止重復計數(shù)。例如,當用戶訪問html 文件時,他們還可以訪問鏈接的圖像文件。這可能會強制訪問計數(shù)成倍增加。因此,我們刪除了一些對圖像文件的請求。此外,我們還從實驗中排除了訪問結(jié)果不成功的請求日志。
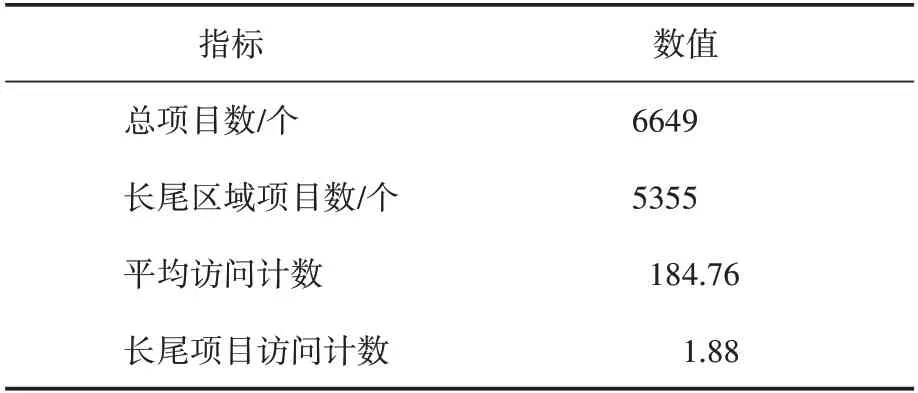
表1 預處理的網(wǎng)絡流量數(shù)據(jù)
實驗中構(gòu)建了一個預處理的流量數(shù)據(jù)集,該數(shù)據(jù)集由來自21649 個原始數(shù)據(jù)的6649 個項目組成,并且它有一個由5355 個項目組成的長尾區(qū)域。總訪問數(shù)平均值為184.76,長尾區(qū)的平均訪問數(shù)為1.88。兩個平均值之間的差異只是表明可以在爬蟲檢測算法中設置一個更靈敏的閾值。
實驗還統(tǒng)計了按訪問頻率排序時最常訪問的鏈接,到最不常訪問的鏈接的特征[8]。比率是指按訪問計數(shù)對所有項目進行排序時每個組所在的間隔。訪問平均值是指屬于每個組的每個項目的平均訪問次數(shù),最大訪問量是指每個組中項目之間的最大訪問計數(shù)。
3.3 虛擬仿真
在仿真實驗中,檢查LTM 是否能夠檢測和禁用分布式爬蟲程序IP 地址組,將實際Web 流量輸入到LTM 時檢查誤報率。整個爬蟲程序檢測流程如圖2所示。
3.4 分布式爬蟲檢測模擬
從表2的實驗數(shù)據(jù),我們可以觀察到爬蟲IP地址集合逐漸減少,直到所有IP 地址都被完全阻止。當?shù)谝粋€爬蟲節(jié)點IP 地址超過Td3閾值IP被封禁,節(jié)點減少計數(shù)呈指數(shù)級增長。這是因為其他爬蟲節(jié)點得到了更多的訪問負荷,并且當爬蟲節(jié)點被訪問時,更多的項目必須訪問被阻止。
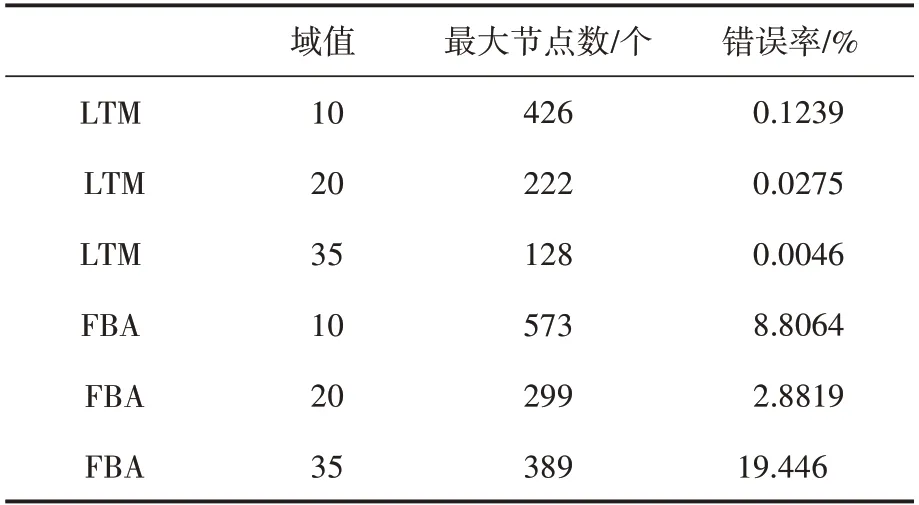
表2 實驗數(shù)據(jù)
實驗閾值設置為20,爬蟲項目包含222 節(jié)點。LTM 檢測到了整個爬蟲項目所有節(jié)點,錯誤率約為0.0275%,遠低于傳統(tǒng)的基于頻率的爬蟲檢測方法。在表2 中,我們將LTM 的結(jié)果與通用的基于頻率的反爬蟲(FBA)方法的結(jié)果進行了比較。LTM 對分布式的爬蟲檢測性能非常依賴于項目的數(shù)量和長尾比率。考慮到這個限制,仿真實驗是使用舊的NASA 交通數(shù)據(jù)進行[9],項目的總數(shù)比通常的現(xiàn)代網(wǎng)絡項目要小得多。如果有10 倍數(shù)據(jù)和類似訪問的頻率分布的項目,我們提出的方法可以從由2000 個節(jié)點組成的網(wǎng)絡項目中檢測出分布式爬蟲。
在實驗中,LTM 達到了最小的錯誤率為0.0046%,而FBA 僅達到0.0367%,這意味著LTM 的檢測可靠性比經(jīng)典FBA 方法提高了500%。當我們將閾值設置為35,這時LTM 達到最小誤報率的值,F(xiàn)BA 方法比LTM 方法多了19.400%的誤報率。
4 結(jié)語
本文介紹了長尾閾值模型(LTM),并展示了LTM 如何有效地檢測分布式爬蟲,相比之下先前的方法是脆弱的。通過模擬真實的網(wǎng)絡流量數(shù)據(jù),LTM 有效地識別了分布式爬蟲,并顯示出極低的誤報率。針對網(wǎng)絡服務的非法網(wǎng)絡爬取成為嚴重的安全威脅[10]。考慮到一些爬蟲開發(fā)者將分布式爬蟲代理服務用于非法目的,LTM 可以提高網(wǎng)絡服務的數(shù)據(jù)安全性。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環(huán)球時報(2017-03-30)2017-03-30 06:44:45
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
中國衛(wèi)生(2015年3期)2015-11-19 02:53:32
Coco薇(2015年1期)2015-08-13 02:47:34
