機器學習在發展性閱讀障礙兒童早期篩查中的應用*
2023-11-04 03:27:16卜曉鷗杜亞雯
心理科學進展 2023年11期
卜曉鷗 王 耀 杜亞雯 王 沛
機器學習在發展性閱讀障礙兒童早期篩查中的應用*
卜曉鷗 王 耀 杜亞雯 王 沛
(華東師范大學教育學部特殊教育學系, 上海 200062)
發展性閱讀障礙嚴重影響兒童的學業成就、心理健康和社會適應能力。近年來, 機器學習因其強大的數據處理和挖掘能力逐漸被應用到閱讀障礙兒童的早期篩查中, 在標準化心理教育測試、眼動追蹤、游戲測試、腦成像等多個領域積累了較為豐富的成果, 獲得了更加精準高效、靈活可靠的分類結果。然而, 機器學習在對象選取、數據采集、轉化潛力和安全隱私等方面仍存在局限性。未來研究需要重點關注學齡前閱讀障礙兒童的早期篩查系統的科學性, 同時積極構建多模態數據庫、在多種算法中尋找最佳算法以獲取最優參數, 最終實現臨床實踐中的廣泛使用。
發展性閱讀障礙, 機器學習, 早期篩查, 兒童
1 引言
發展性閱讀障礙(Developmental dyslexia, DD)是一種極其復雜的神經發育性障礙, 其核心特征是盡管個體的智力正常, 視、聽覺功能完好, 但是仍然表現出持續的閱讀、拼寫和寫作困難(Kaisar, 2020)。閱讀障礙在不同的語言和文化中的發生率約為5%~15% (Tamboer et al., 2016), 并且存在代際傳遞現象(Zahia et al., 2020)。目前, 兒童通常于2年級或更高年級在掌握閱讀技能的過程中才有可能被識別出存在閱讀障礙(Sanfilippo et al., 2020)。在經濟發展落后的國家, 貧困兒童發現存在閱讀障礙的年齡更晚(Ballester et al., 2021)。此時往往已經錯過了最佳的干預窗口期, 即幼兒園至1年級大腦可塑性增強的早期階段(Fox et al., 2010)。大量研究已然發現, 患有閱讀障礙的兒童會深陷學習成績低下、自我效能感降低和學習動力不足的惡性循環中(Burns et al., 2022), 甚至出現極高的輟學率和心理健康問題(Livingston et al., 2018)。如果此類兒童未能得到及時的識別和干預, 閱讀障礙的負面影響可能會從童年早期一直持續至成年期(Farah et al., 2021)。因此, 進行高效的早期篩查, 提供有效的早期干預, 對于閱讀障礙兒童的發展具有關鍵性意義。
迄今為止, 閱讀障礙的篩查主要借助于標準化心理教育測試(Lee et al., 2022)、眼動追蹤(Prabha & Bhargavi, 2019)、網絡/手機游戲(Borleffs et al., 2018)以及腦成像技術(Usman et al., 2021)等手段。標準化心理教育測試通常采用智商?成就差異模式(IQ?achievement discrepancy) (Fletcher et al., 2019)、干預?應答模式(response to intervention, RTI) (Miciak et al., 2014)、優勢與弱勢模式(pattern of strengths and weaknesses, PSW) (Hale et al., 2010)來評估和量化個體的智力、語音加工、閱讀技能和詞匯發展等認知能力, 進而達到識別閱讀障礙者的目的(Miciak & Fletcher, 2020)。就眼動追蹤技術的應用而言, 研究者通過記錄閱讀過程中的眼動特征來區分閱讀障礙兒童和非閱讀障礙兒童, 這些特征包括注視/回視時間和次數、眼跳幅度和次數、眨眼頻率和次數以及雙眼協調性等(Hmimdi et al., 2021)。也有研究者以游戲化的形式生成具體的語音測試或認知測試, 開發基于網絡技術的電子學習系統和手機游戲(例如, Deslixate和GraphoGame), 旨在通過教育游戲識別閱讀障礙兒童(Larco et al., 2021; Ojanen et al., 2015)。隨著認知神經技術的發展, 越來越多的研究使用腦成像技術獲取大腦的結構、形態、功能激活和幾何特性, 利用組間均值差異來區分閱讀障礙兒童和典型發展兒童(Livingston et al., 2018; Sihvonen et al., 2021; Yang et al., 2021)。
然而, 閱讀障礙兒童的癥狀具有巨大的個體差異性, 比如不同的病源因素會導致不同的閱讀障礙亞類型(Aaron et al., 1999)。加之傳統的閱讀障礙檢測技術低效耗時, 敏感性和特異性指標不明確, 難以滿足大規模并快速篩查閱讀障礙兒童的需求(Usman et al., 2021)。更重要的是, 閱讀障礙與多種神經、行為和環境因素有關, 這些因素以復雜的方式相互作用導致了閱讀障礙(Catts et al., 2017; McGrath et al., 2020)。因此, 僅憑單一因素或少數因素結合無法完成對閱讀障礙患者的精確診斷(Catts & Petscher, 2022), 即使是傳統的多因素方法也無法涵蓋所有可能的因素和關系(Walda et al., 2022)。研究復雜系統的一種相對新穎有效的方法是機器學習(Kaisar, 2020)。機器學習(Machine Learning, ML)是使用計算機算法讓機器從大量經驗數據中學習規律, 自動識別模式以做出預測或決策(Gilvary et al., 2020)。近年來,因其能夠提供更高的檢測精度和更好的預測結果, 一些研究者們開始嘗試應用機器學習來提高閱讀障礙篩查的精度與敏感性。為此, 本研究通過整合機器學習在閱讀障礙篩查中的最新進展、主要應用范圍、未來可能的發展方向, 旨在廓清閱讀障礙的機器學習研究可能的發展路徑與發展思路。
2 方法
我們對2016年以來用于分類和識別閱讀障礙的機器學習方法的研究進行文獻搜索, 使用的數據庫包括Web of Science、Elsevier Science Direct、EBSCO和PubMed。檢索關鍵詞為“Dyslexia/Reading Disability” AND “Identification/ Screening/Detection/Recognition/Prediction/Diagnosis” AND “Machine Learning/Deep Learning/Artificial Intelligence” AND “Child/Children/ Preschool”。考慮到機器學習技術的飛速發展和迭代, 并且第一篇中文閱讀障礙的機器學習研究發表于2016年, 因此文獻檢索的日期范圍設定為2016年1月1日~ 2022年10月1日。文獻納入標準為: (1)文獻為英文實證期刊論文和會議論文, 全文可得并包含明確的研究問題、方法和結論, 研究結論有翔實的數據支撐; (2)研究對象為18歲以下的兒童, 設置典型發展對照組和閱讀障礙組。閱讀障礙兒童無其他共病(如計算障礙、書寫障礙、自閉癥等)。(3)文獻使用/組合使用機器學習方法篩查閱讀障礙。我們依據上述標準進行獨立篩查, 最后確定納入本次系統綜述的文獻數量為25篇(見表1)。圖1和圖2分別展示了文獻篩選流程和文獻檢索完成后的文獻年度分布情況。
3 基于機器學習的閱讀障礙早期篩查的主要步驟
3.1 數據采集
基于機器學習的閱讀障礙篩查的第一步是使用相應的技術手段獲取數據。
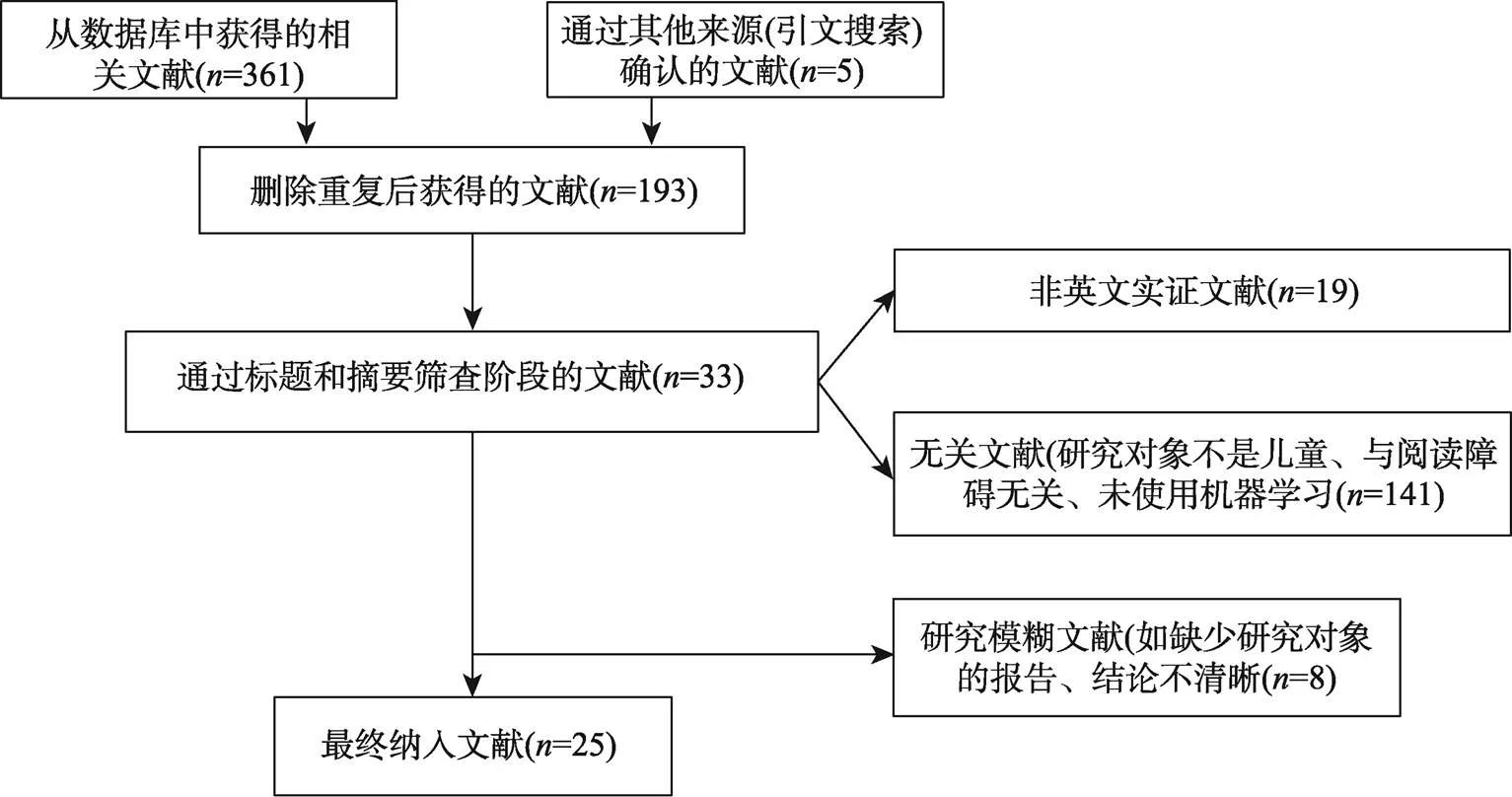
圖1 文獻篩選流程圖
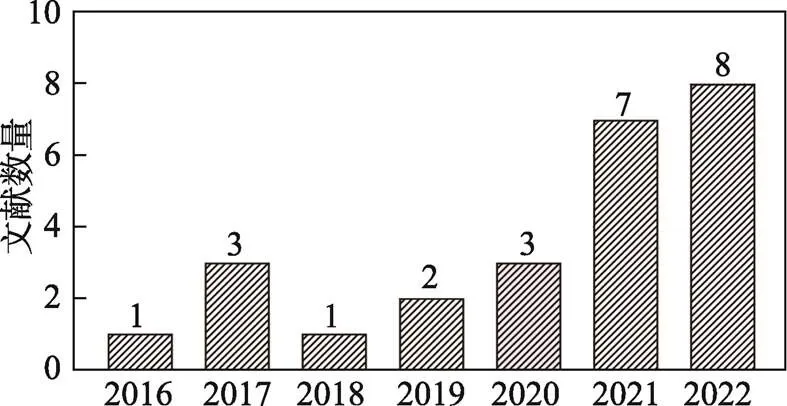
圖2 文獻檢索完成后的文獻年度分布
標準化心理教育測試為機器學習的模型構建提供了最早、最廣泛的證據。其所提供的數據顯示了閱讀障礙患者明顯的行為表現, 主要包括閱讀、語音加工、工作記憶、視聽辨別等。Chen等人(2017)使用荷蘭版的McArthur-Bates溝通發展量表(N-CDI)測量了476名17~35個月的典型發展兒童的早期詞匯發展能力, 使用機器學習算法預測具有閱讀障礙家庭風險的兒童。Shamir等人(2019)采用自行開發的閱讀障礙簡短篩查工具(Zippy 6)測量了125名兒童(6~14歲, 其中閱讀障礙兒童81名)的認知能力和語音能力, 并使用機器學習算法區分閱讀障礙兒童和典型發展兒童。Tolami等人(2021)收集了54名8~11歲兒童(29名閱讀障礙兒童)的語言樣本, 使用計算語言學方法提取拼寫和語法錯誤、詞匯多樣性、語法復雜性指數和可讀性等閱讀障礙的差異特征, 利用機器學習模型診斷閱讀障礙。在中文閱讀障礙研究中, Wang和Bi (2022)收集了399名7~13歲閱讀障礙兒童的認知測試集, 在測量閱讀流暢性、閱讀準確率、語音意識、語素意識、快速命名和正字法意識的基礎上, 使用深度學習模型預測中文閱讀障礙兒童的癥候。Lee等人(2022)采集了1015名7~13歲的兒童(454名閱讀障礙兒童)的漢字字符數據集, 采用多種算法對漢字的反應特征(如筆畫、字素、音調等)、字符結構、回答特征(如正字法、語音詞根等)、個人特征等分類變量進行了機器學習, 最終基于漢字字符的結構、書寫正確率、詞匯地位、筆畫、音調、年級等核心特征構建了中文閱讀障礙篩查模型。
值得注意的是, 眼動特征已經成為基于機器學習進行閱讀障礙分類的常用指標, 它與機器學習的結合提供了認知過程的細粒度信息(Raatikainen et al., 2021), 可作為閱讀障礙的高精度篩查工具。Bhargavi和Prabha (2020)收集了185名9~10歲兒童(97名閱讀障礙兒童)的眼動特征集用以建立閱讀障礙的預測模型, 在此基礎上采用多種機器學習算法提高預測精度, 發現具有較高準確率的最佳特征集是平均注視次數、平均注視時間、平均眼跳時間、總眼跳運動次數和平均注視次數。Ileri等人(2022)記錄了33名9~10歲兒童(20名閱讀障礙兒童)在閱讀文本時的眼電圖(electrooculography, EOG)信號, 通過機器學習分析了不同類型的眼球運動規律, 以此來篩查閱讀障礙者。
隨著智能移動設備的日益普及, 基于網絡/手機游戲的數據收集技術擁有了廣泛的用戶基礎。當前, 研究者已經開發了各種支持、檢測和治療閱讀障礙的應用程序和游戲(Ahmad et al., 2022)。游戲化設計大多以語言能力、知覺加工、工作記憶、執行功能、閱讀技能等為測量內容, 在形式上通過豐富的游戲元素來吸引和激勵用戶。Rello等人(2020)設計了一款用于測查行為和認知缺陷的在線游戲來收集3644名7~17歲用戶(其中包括392名閱讀障礙患者)的數據, 從而建立了一個用于篩查閱讀障礙的機器學習模型。Rauschenberger等人(2022)通過網頁游戲“MusVis”收集了313名兒童(7~12歲, 其中包括116名閱讀障礙兒童)玩游戲的節奏和頻率, 在此基礎上利用機器學習進行模型訓練和預測。
閱讀障礙的本質特征是大腦解剖結構中微妙的空間分布變化(Richlan et al., 2013; Tamboer et al., 2016; Vandermosten et al., 2012)。基于功能性磁共振成像(fMRI)、腦磁圖(MEG)、腦電圖(EEG)、正電子發射掃描(PET)等技術獲取的大腦成像數據為閱讀障礙的機器學習分類提供了客觀證據(Da Silva et al., 2021; Ortiz et al., 2020; Thiede et al., 2020)。fMRI的數據大多關注的是與語言和詞匯決策相關的大腦區域, 探究個體在閱讀任務期間大腦激活的功能差異(Chimeno et al., 2014)。Zahia等人(2020)收集了55名9至12歲西班牙兒童(其中包括18名閱讀障礙)的fMRI結構像, 使用深度學習算法對閱讀障礙兒童進行自動識別。Da Silva等人(2021)從巴西說葡萄牙語的32名8~12歲兒童(16名閱讀障礙兒童)中收集高分辨率的T1-w圖像, 使用深度學習算法對視覺表征的重要區域進行分類。EEG能夠在保持時間和頻域的情況下記錄高時間分辨率的大腦信號, 反映兒童認知處理過程中的大腦功能狀態, 為閱讀障礙的早期診斷提供有效特征。研究者大多關注EEG信號的5個波段, 即delta, theta, alpha, beta和gamma (Ortiz et al., 2020), 通過腦電圖通道之間的相位同步探究大腦的連通性, 然后提取鑒別特征用于閱讀障礙的識別。Zainuddin等人(2019)采集了7~12歲的10名中度閱讀障礙兒童、10名重度閱讀障礙兒童和10名對照組兒童的EEG信號, 通過寫作任務以K最鄰近(KNN)和極限學習機(ELM)來篩查閱讀障礙。Formoso等人(2021)采集了7~8歲的48名兒童(16名閱讀障礙)的EEG信號, 測量通道之間的相位同步, 以揭示聽覺處理過程中激活的腦功能網絡。然后, 使用矢量量化無監督學習和貝葉斯算法相結合的方法提取鑒別特征, 用于閱讀障礙的鑒別。在中文閱讀障礙研究中, Cui等人(2016)采用結構磁共振成像(MRI)和擴散張量成像(DTI)收集了61名10~14歲學齡兒童(其中28名閱讀障礙兒童)的3D T1-w圖像(MPRAGE), 使用機器學習算法將閱讀障礙兒童與典型發展兒童區分開來。
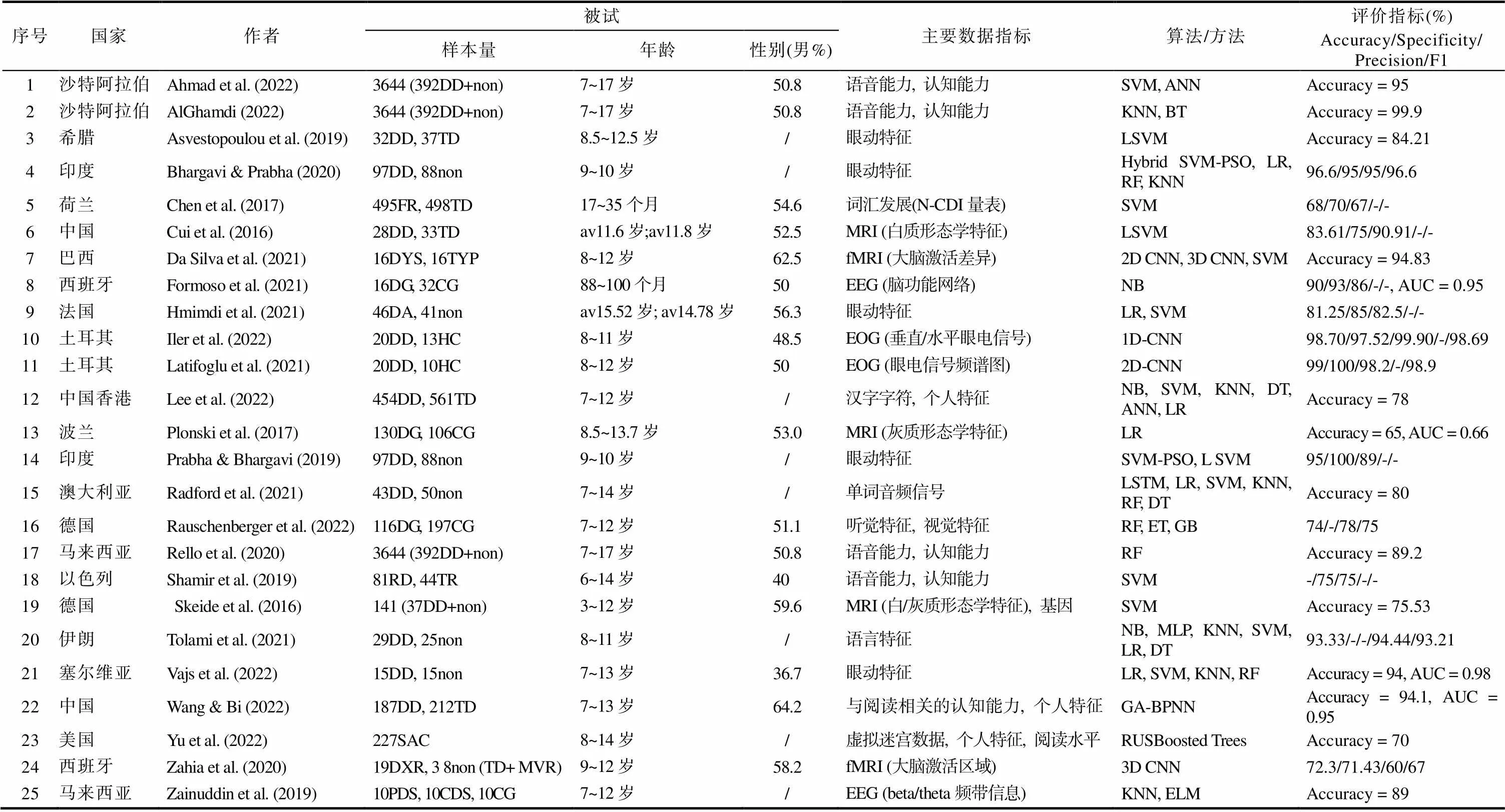
表1 機器學習在發展性閱讀障礙兒童早期篩查中的應用
注: 國家以第一作者所在國家為準, 算法/方法采用重點研究算法, 評價指標采用最佳算法的最優參數。
TD/CD/TDR/TYP/TR/CG/HC/non: 典型發展兒童; DG/DD/DYS/DA/RD: 閱讀障礙兒童; PDS (poor dyslexic subject): 差閱讀障礙兒童; CDS (capable dyslexic subject): 有能力的閱讀障礙兒童; FR (family risk): 有閱讀障礙家庭風險兒童; SAC (school-aged children): 學齡兒童; MVR: 單目視覺兒童(無閱讀障礙); av (Average): 平均年齡; N-CDI: 荷蘭版的McArthur-Bates溝通發展量表; SVM (Support Vector Machines): 支持向量機; KNN (K-Nearest Neighbors): K最近鄰; LR (Logistic Regression): 邏輯回歸; CNN (Convolutional Neural Network): 卷積神經網絡; RF (Random Forest): 隨機森林; ET (Extra Trees): 極限森林; NB (Na?ve Bayes): 樸素貝葉斯; DT (Decision Tree): 決策樹; ANN (Artificial Neural Network): 人工神經網絡; BT (Boosted Trees): 提升樹; GA-BPNN: 遺傳算法?反向傳播神經網絡; SVM?PSO: 粒子群算法優化支持向量機; GB (Gradient Boosting): 梯度提升; ELM (Extreme Learning Machine): 極限學習機; LSTM (Long-Short Term Memory neural networks): 長短期記憶神經網絡; MLP (Multilayer Perceptron Neural Network Model): 多層感知機。
如今, 越來越多的研究者開始不局限于某種單一模態的數據收集, 他們將量表、行為、影像等數據進行整合, 試圖提高閱讀障礙篩查及其生物標志物檢測的準確性。納入分析的25篇文獻中使用的數據類型占比如下: 標準化心理教育測試和眼動特征數據各為28%, 其次是游戲測試數據為16%, MRI數據為12%, fMRI數據和EEG數據各為8%。
3.2 數據預處理、特征提取和特征選擇
數據預處理的主要目的是使算法能夠從數據集中提取最相關的可解釋特征(Usman et al., 2021)。對于傳統的機器學習方法, 預處理的第一步是將數據轉換為定量(數字)或定性(文本類別)格式。也有一些量表或行為數據采用手動預處理方式, 如請專家將數據標記為無閱讀障礙組和閱讀障礙組(Khan et al., 2018)。在腦成像研究中, 研究者直接收集的數據通常是高維度多變量的數據。以64個通道的EEG數據為例, 即使在一個通道上計算得到一個指標, 則至少得到64個特征值。當特征值數量大于樣本數量, 使用機器學習容易造成過擬合問題以及降低訓練和預測速率。因此, 需要將高維度的特征降低到低維度的特征, 加快后續機器學習的分類和訓練。例如, EEG信號預處理中常采用主成分分析(Principal Components Analysis, PCA)剔除數據次要成分的維度, 做到數據的降維(Ahire et al., 2022)。此外, 腦成像數據還可以使用不同類型的軟件工具包進行預處理。如fMRI圖像可使用matlab的SPM工具箱自動分割出不同的組織類型, 提高數據預處理時像素和體素的可比性(Zahia et al., 2020); 或者使用FreeSurfer圖像分析套件提取可靠的皮層體積和厚度(Plonski et al., 2017)。
預處理完成的下一步是特征選擇和提取, 目的是從原始特征中生成最相關、信息量最大的特征(Abd Rahman et al., 2020), 形成分類所需的數據集。標準化心理教育測試可選擇的特征一般有問卷/認知測試分數、書寫數據、語音數據等。眼動數據通常使用統計度量、基于離散和基于速度的算法選擇特征, 使用主成分分析法(Principal Component Analysis, PCA)提取特征。fMRI數據的特征提取是從腦組織屬性中提取大腦皮層屬性特征, 常見的特征有: 皮層厚度、體積信息、各向異性分數和激活模式等。在EEG數據中, 一般使用傅里葉變換和小波變換提取信號的時間和頻率信息。另外, 最近出現了一些新的特征提取方法, 如深度學習通過構造不同的網絡結構自動從數據中進行特征提取, 具有良好的穩健性和較強的高維數據處理能力。例如, 在Ileri等人(2022)的研究中, 卷積神經網絡(CNN)提供了輸入的分段EOG信號的自動分類, 無需手動提取特征。表2總結了納入分析的25篇文獻中的特征類型。
3.3 模型訓練與分類
在特征提取與選擇完成之后, 研究者便可以利用機器學習進行模型訓練與分類。機器學習大致分為兩種類型: 無監督學習和有監督學習。無監督學習用于在不使用任何輸出數據的情況下查找輸入數據中的模式, 而監督學習主要用于預測未來事件(Russell & Norvig, 2010)。在監督學習中, 訓練模型的目的是從標記的數據學習所有權重和偏差的理想值。近年來的研究一般使用監督學習算法探究閱讀障礙患者和典型發展人群的分類問題。常見的算法有: 支持向量機(Support Vector Machines, SVM)、決策樹(Decision Tree, DT)、隨機森林(Random Forest, RF)、線性回歸(Linear Regression, Linear-R)、邏輯回歸(Logistic Regression, LR)、線性判別分析(Linear Discriminant Analysis, -LDA)、樸素貝葉斯(Na?ve Bayes)、K最近鄰(K-Nearest Neighbors, KNN)、人工神經網絡(Artificial Neural Network, ANN)和卷積神經網絡(Convolutional Neural Network, CNN)等。在訓練模型前, 通常要將整個數據集分為測試集(testing set)和訓練集(training set)。現有關于閱讀障礙的機器學習的研究大多使用K折交叉驗證(K-fold cross-validation), 將數據集分成K等份, 其中K?1份用于訓練集, 1份用于測試集, 以K次測試結果的平均值作為最終的性能評估結果。例如, Plonski等人(2017)采用10倍交叉驗證法, AlGhamdi (2022)采用5倍交叉驗證法和20倍交叉驗證法。當樣本量較小時, 一些研究者也會選用K折交叉驗證的特殊形式——留一法(Leave-one-out cross-validation)構建模型和評估分類結果(Cui et al., 2016; Asvestopoulou et al., 2019).
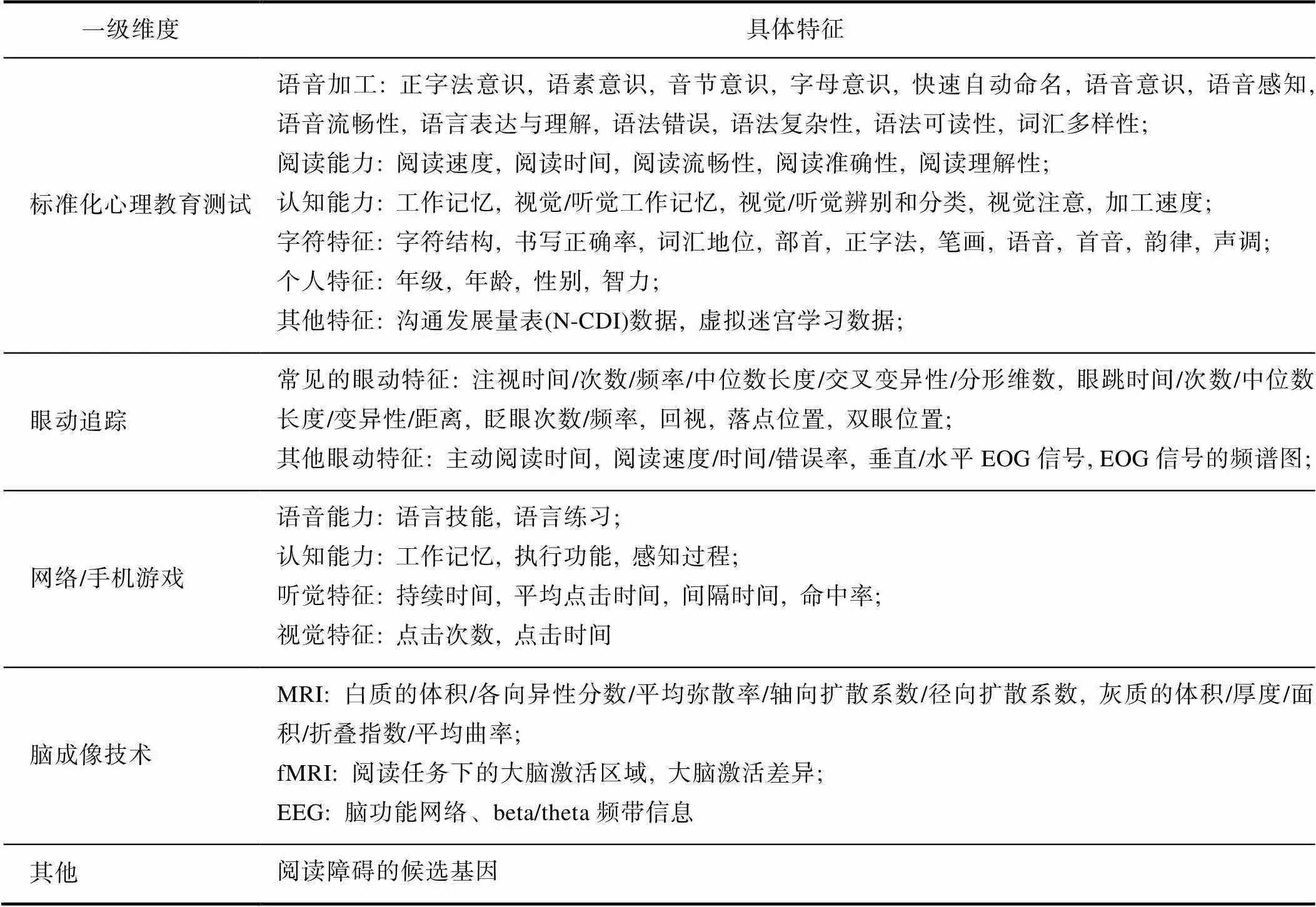
表2 機器學習在發展性閱讀障礙兒童早期篩查中的特征類型
閱讀障礙的識別問題在本質上是二元分類問題, 即區分用戶是否為閱讀障礙者。SVM的原理是從解決線性二分類問題出發, 可以為超高維且特征空間稀疏的數據提供良好的性能。因此, SVM成為閱讀障礙研究中應用得最為廣泛的算法。Shamir等人(2019)采用SVM算法對基于標準化測試和zippy 6篩選測試的閱讀評估數據進行分類, 獲得了75%的特異性和靈敏度。Prabha和Bhargavi (2019)提出一種粒子群算法優化支持向量機(SVM-PSO)模型用于從眼動特征中提取閱讀障礙的生物標記物。與線性支持向量機(Linear SVM )模型相比, 該模型的預測準確率達到了95%。此外, 研究者將SVM混合其他算法來識別閱讀障礙兒童。例如, 使用RF選擇最重要的特征作為SVM的輸入, 模型達到了89.7%的準確率和84.8%的召回率(Raatikainen et al., 2021)。
對于大數據間的復雜規律的挖掘來說, 深度學習的出現解決了這一難題。深度學習算法具有更多的層次結果, 因此對事物的建模或抽象表現能力更強, 也能模擬更復雜的模型。ANN是深度學習的基礎, 它模擬了大腦神經網絡結構和功能, 在不確定的識別(如語音識別、圖像識別)中尤其有效(Lucchiari et al., 2014)。Ahmad等人(2022)使用ANN模型對綜合游戲數據進行分類, 獲得了95%的檢測準確率。隨著神經網絡的發展, 深度學習從淺層的ANN中衍生出來。其中, CNN是用于閱讀障礙分類的最受歡迎的深度學習模型(Usman et al., 2021)。Da Silva等人(2021)選取兩種網絡可視化技術在CNN輸入層中學習高級特征, 僅從腦成像數據(fMRI)就對閱讀障礙兒童的大腦狀態進行了精準分類, 達到94.8%的準確率。不僅如此, 研究者提出一種新的基于EOG信號的CNN方法來識別閱讀障礙。Latifoglu等人(2021)通過閱讀時的跳線和返回眼球運動來篩查和跟蹤閱讀障礙兒童。他們使用二維卷積神經網絡(2D-CNN)模型對這些頻譜圖圖像進行分類, 獲得了99%的準確率、100%的靈敏度、98.18%的特異性和98.94%的F分數。Ileri等人(2022)從水平和垂直通道記錄EOG信號, 應用一維卷積神經網絡(1D-CNN)對這兩個通道的信號進行分類, 準確率分別為98.70%和80.94%。
事實上, 沒有任何一種算法能夠成為適用于所有數據集的最佳算法。算法的選擇受到問題性質、數據集特征和數量、數據格式、訓練和預測時間、存儲需求等多種因素的影響。因此, 研究者越來越傾向于在多種算法中尋找最佳算法以獲取最優參數。研究的整體趨勢為從單一的傳統機器學習算法走向深度學習算法(Deep neural network, DNN)以及比較多種不同類型的算法。Tolami等人(2021)以語言特征為分類指標, 構建了NB, KNN, SVM, LR, DT和MLP模型, 其中屬于深度學習的MLP算法的最高分類準確率達到93.33%。在中文閱讀障礙的研究中, Lee等人(2022)以漢字字符和個人特征為分類指標, 運用NB、KNN、SVM、DT、LR和ANN分別構建模型, 發現這6種算法都可以將閱讀障礙兒童與典型發展兒童區分開來。其中, SVM獲得了80.0%的最高準確率。
基于納入分析的25篇文獻, 算法的使用頻次占比統計如下: SVM占比為27.3%, 其次是KNN和LR各占12.7%, CNN和RF各占9.1%, NB和DT各占5.5%, ANN占比為3.6%, BT、GA-BPNN、GB、ELM、LSTM、MLP、RUSBoosted和ET各占1.8%。
3.4 性能評估
閱讀障礙的結局變量均為二元分類變量, 對于二分類結果的評估首先需要對于不同樣本分類的分類結果進行4類劃分: 真陽性(True Positive, TP)、真陰性(True Negative, TN)、假陽性(False Positive, FP)、假陰性(False Negative, FN)。接著, 根據數據的類別劃分定義評估指標。對于二分類問題, 最常用的評估指標是整體準確率。但是, 準確率只能體現正(陽性)、負(陰性)類樣本合計的正確識別數占總樣本數的比例。在實際應用中, 尤其是臨床篩查中往往會出現數據中的正負樣本量比例過大的問題。針對這些不平衡數據的分類問題, 需要采用多個指標對分類模型進行性能評估。其他常用的評估指標有: 靈敏度(Sensitivity)、特異性(Specificity)、精度(Precision)召回率(Recall)、F1分數(F1 score)、Kappa系數、AUROC曲線與P-R曲線、陽性預測值(Positive Predictive Value, PV+)與陰性預測值(Negative Predictive Value, PV?)等。基于納入分析的25篇文獻, 機器學習模型的評估性能(以準確率為參考)總結如下: 標準化心理教育測試在68%~94.1%之間; 眼動追蹤測試在81.25%~99%之間; 游戲測試在74% ~ 99.9%之間; 基于EEG捕獲的腦成像數據在89% ~ 90%之間; 基于fMRI捕獲的腦成像數據在65% ~ 94.83%之間。
4 基于機器學習的閱讀障礙早期篩查的研究應用
4.1 發現閱讀障礙的預測因素
機器學習最主要的優勢在于模型的靈活度, 即可以擬合相當復雜的多項交互關系或者非線性關系, 由此產生令人矚目的預測準確性。特別是研究涉及到預測性問題, 如預測微博用戶的自殺風險、抑郁癥的易感人群等, 機器學習的統計效果尤其突出。
基于機器學習有助于發現閱讀障礙的預測因素, 我們可以有效檢出具有閱讀障礙風險的兒童對其進行及時干預, 從而降低兒童識字后甚至成年后閱讀失敗的可能性。例如, Tamboer等人(2016)借助MRI技術構建SVM預測模型, 發現最可靠的分類體素位于左側枕葉梭狀回(Left Occipital Fusiform Gyrus, LOFG)、右側枕葉梭狀回(Right Occipital Fusiform Gyrus, ROFG)和左側頂下小葉(Left Inferior Parietal Lobule, LIPL), 敏感性達到82%, 特異性達到78%。因此, 這些腦區是與閱讀、拼寫和語音相關的閱讀障礙類型的潛在生物標志物。Prabha和Bhargavi (2019)基于SVM-PSO構建的預測模型顯示, 平均注視次數、平均注視時間、平均掃視時間、總掃視次數和平均注視次數等眼動特征可以作為兒童閱讀障礙的風險預測指標。該模型預測的準確率高達95%。Formoso等人(2021)收集兒童的EEG信號, 通過腦電通道之間的相位同步來表示腦區之間的連通性。研究結果顯示在16 Hz的刺激下, alpha和beta波段的辨別能力最強, AUC值達到0.95。在中文閱讀障礙的研究中, Wang和Bi (2022)構建了基于遺傳算法?反向傳播神經網絡模型(GA-BPNN)的中文閱讀障礙預測模型, 發現閱讀準確性是預測漢語閱讀困難兒童的最強因素, 語音意識、假字準確率、語素意識、閱讀流暢性、快速數字命名和非字符反應時間對預測也具有重要貢獻。基于納入本次系統綜述的文獻, 最具預測性的特征總結詳見表3。
4.2 輔助篩查閱讀障礙兒童
閱讀障礙兒童的傳統篩查主要通過專業的醫療機構和科研機構進行, 方法以標準化心理教育測試結合兒童外在行為和家長報告為主。雖然近年來眼動追蹤和腦成像技術為閱讀障礙篩查提供了更加客觀的技術支持, 但通過這些復雜的測量工具來對每一個閱讀障礙患者進行大范圍識別幾乎是不可能的。同時, 這些測量工具還存在著價格昂貴、耗時長、普及性差、就診渠道窄等弊端。為此, 機器學習被用來輔助臨床篩查和自動化識別, 不僅可以納入大量客觀分類指標提高準確率, 而且方便快捷, 降低等待成本。
Asvestopoulou等人(2019)開發了一款閱讀障礙的篩查工具DysLexML, 通過眼動追蹤記錄兒童默讀期間的注視點, 應用LSVM構建篩查模型, 準確率達到97%。值得一提的是, DysLexML在存在噪聲的情況下依然具有良好的穩健性和準確率。因此, DysLexML可以覆蓋更多數量和更多樣化的人群, 為在控制較少、規模較大的環境中(如幼兒園)開發廉價的眼動篩查工具奠定了基礎。
以往研究認為, 閱讀障礙與虛擬Hebb- Williams迷宮任務的表現相關, 但是通過實時觀察任務表現來對閱讀障礙兒童進行分類尚不可行(Gabel et al., 2021)。Yu等人(2022)基于機器學習算法開創性地根據迷宮任務的表現預測閱讀能力, 實現以閱讀風險的百分比形式實時反饋閱讀成績。他們以虛擬迷宮數據、閱讀水平和個人特征為指標, 利用RUSBoosted樹算法(RUSBoosted Trees algorithm)構建的模型分類準確率達到70%以上。隨著計算機網絡的發展和電子產品的普及, 以在線評估平臺或應用程序初步篩查閱讀障礙的方式逐漸流行起來。研究者開發了一款分析真實環境下音頻信號的應用程序Dystech, 他們發現與適當的音頻信號處理相關的機器學習算法可以提取出人類專家無法獲取的模式, 篩查準確率達到80%(Radford et al., 2021)。Rauschenberger等人(2022)設計了一款語言獨立游戲MusVis, 使用RF和額外樹(Extra trees, ET)對收集到的游戲數據進行訓練, 德語和西班牙語閱讀障礙的分類準確率分別達到74%和69%。
4.3 預測閱讀障礙高風險兒童
人們普遍認為閱讀障礙具有遺傳基礎(約70%) (蘇萌萌等, 2012; Galaburda et al., 2006)。即使部分有家庭風險的兒童沒有出現閱讀障礙, 但是他們在拼寫、非單詞閱讀和閱讀理解等任務上的表現仍然比典型發展兒童要差(Lyytinen et al., 2005)。在早期發現具有高風險的閱讀障礙的兒童將使早期預防和干預成為可能。這種早期預測功能可通過訓練機器學習預測模型來實現。Skeide等人(2016)認為與識字相關的重要腦區的神經可塑性可能受到遺傳變異的調控, 從而預先限制了兒童的讀寫能力。為此, 他們采集了4~8年級兒童和幼兒園~1年級兒童的灰/白質體積以及與識字相關的基因信息, 利用LSVM構建了閱讀障礙的預測模型, 其準確率分別達到了73%和75%。Chen等人(2017)根據詞匯發展量表分析了17~35個月的兒童的詞匯總量和詞匯類別的群體水平差異, 使用SVM來對家庭風險的閱讀障礙兒童和典型發展兒童進行分類。研究結果顯示風險預測模型的準確率為68%, 敏感性為70%, 特異性為67%, 表明通過機器學習可以在識字前的早期階段區分出有家庭風險的閱讀障礙兒童和典型發展兒童。這個階段有家庭風險的閱讀障礙兒童的顳頂葉和顳枕葉區域已經顯示出功能和結構上的改變, 并且類似于閱讀障礙患者中觀察到的變化(Hosseini et al., 2013; Kraft et al., 2015)。

表3 機器學習在發展性閱讀障礙兒童早期篩查中最具預測性的特征
5 機器學習應用于兒童閱讀障礙早期篩查的優勢與不足
5.1 優勢
近年來, 機器學習在閱讀障礙及其生物標志物檢測中的應用越來越受到研究者的青睞, 其優勢主要體現在以下三個方面。第一, 機器學習可以識別變量之間復雜的非線性關系, 提供對閱讀障礙更加精準的篩查與發展性預測。閱讀障礙是多種因素相互作用的結果(Morris et al., 1998), 傳統的統計學方法(如邏輯回歸)所確定的單個或多個預測因子存在預測能力弱或是無法體現因子間的交互作用的缺點, 不能對數據進行充分挖掘。機器學習則更適合分析閱讀障礙這一類結構復雜問題。以反向傳播神經網絡(BPNN)為例, BPNN作為人類大腦工作機制的模擬, 不僅可以處理模糊映射關系, 還可以識別變量之間復雜的非線性關系(Lyu & Zhang, 2019)。無論是在字母語言還是漢語中, 通過采集與閱讀相關的認知測試或語音測試數據, BPNN模型皆可有效篩查出閱讀障礙兒童(Wang & Bi, 2022)。第二, 與人為識別閱讀障礙的方式相比, 機器學習一方面避免了主觀理解偏差的影響, 另一方面能夠自動化重復的任務, 在更短的時間內分析更多的數據, 實現比人工算法更高的準確性和可重復性。第三, 機器學習具備強大的高維數據處理能力, 可從腦成像數據中提取出額外的、關鍵性的區辨性信息, 檢測到人眼無法觀測到的可能反映重要病理生理機制的微小成像的異常。大腦功能和發育的差異是閱讀障礙風險的早期跡象。隨著年齡增長, 突觸的快速形成使得兒童大腦的激活模式發生變化, 但除非嚴重受傷或病危, 大腦結構從童年到成年保持不變。因此, 高維的腦成像數據可為閱讀障礙的識別提供更準確的結果。例如, Da Silva等人(2021)從大腦成像對發展性閱讀障礙兒童進行了94.8%的準確分類, 同時利用特征可視化技術(CAM)和基于梯度的特征可視化技術(Grad-CAM)在卷積神經網絡層負責學習高級特征, 提供了閱讀障礙兒童和典型發展兒童在閱讀的策略控制和注意過程中相關的大腦區域的可視化圖像。這種在切片水平上對大腦狀態的預測, 以及隨后生成的與分類相關的更細粒度的特征信息可以提高模型的可解釋性。
5.2 不足和啟示
首先, 缺少對最佳干預期的被試群體研究。閱讀障礙具有可遺傳性, 68%的同卵雙胞胎和高達40%~60%的一級親屬之間共同患有閱讀障礙(Vogler et al., 1985)。幾個閱讀障礙的候選基因, 如ROBO1, DCDC2, DYX1C1, KIAA0319, 已經證實在兒童的大腦發育中發揮著重要作用(Galaburda et al., 2006)。兒童大腦可塑性增強的早期階段處于幼兒園至小學1年級期間, 是閱讀障礙早期干預的最佳時期(Fox et al., 2010)。研究發現, 對幼兒園和1年級的高危閱讀障礙兒童進行有效干預的效果(平均效應量為0.31~0.84)遠高于2年級和3年級的高危閱讀障礙兒童(平均效應量為0.23~0.27) (Wanzek & Vaughn, 2007)。為此, 在最佳干預期之前對閱讀障礙兒童, 尤其是對有家庭風險的閱讀障礙兒童進行精準的早期識別至關重要。遺憾的是, 基于上述回顧的所有文獻, 僅有一項機器學習的閱讀障礙研究的被試年齡較小(17~35個月), 其余研究中被試年齡段在6~17歲之間, 兒童識字前(3~7歲)這一階段的研究幾乎是空白2筆者注:Skeide等人(2016)的研究共141名被試, 其中20名被試年齡為5~6歲。這20名被試在5~6之間進行MRI掃描, 約1.7年后的7~9歲左右進行識字能力評估, 因此在此處未納入3~7歲的范疇。。未來研究需要在兒童識字前廣泛收集他們及一級親屬的相關數據, 關注遺傳和環境中可能的風險因素, 建立多模態數據庫, 借助機器學習的強大分類功能篩選閱讀障礙兒童并確立較為穩定的行為/生物標記物, 最終搭建方便、快捷、精準、科學的早期篩查系統。
其次, 機器學習研究中采集的數據質量參差不齊, 采集標準不統一, 數據樣本不足。基于機器學習的閱讀障礙數據庫采集呈現單一數據庫到多方數據庫、單一模態到多模態的趨勢。由于數據庫來自不同的實驗室和不同的人群, 采集標準尚未統一, 數據分布的特征不同, 大量的數據不兼容、結構復雜。因此有必要建立標準化異構數據庫, 提高模型所需的計算力, 避免資源浪費。采集標準不統一的現象尤其充斥于閱讀障礙兒童的腦成像數據庫。一方面, 成像設備型號、參數不統一會對數據質量產生一定影響。由于缺乏權威、固定的標準, 腦成像的可重復性得不到一致認可。另一方面, 分類的準確率在很大程度上取決于樣本量大小。相較于問卷、行為數據, 各課題組公開/非公開的閱讀障礙相關數據庫中腦成像數據量較少。用小樣本訓練的模型很容易陷入對小樣本的過擬合以及對目標任務的欠擬合。針對以上問題, 首先可以通過國際合作建立數據采集以及數據共享的統一標準的平臺, 實現腦成像數據的可重復性應用。其次, 可以通過增多訓練數據、縮小模型需要搜索的空間和優化搜索最優模型的過程等方式進行補救。
再者, 暫時無法在臨床實踐中達到高轉化力并得到更廣泛的使用。雖然大量的研究發現大腦形態、眼球運動和正常聽覺系統中檢測到的變化可以作為閱讀障礙識別的神經生物標記物, 但傳統門診對于閱讀障礙的篩查依舊以標準化心理教育測試(行為標記)為主。這是由于標準化心理教育測試具有測驗內容有代表性、標準化程度高、信效度高和使用方便經濟等優點。機器學習目前尚不具備臨床轉化的必備條件。首先, 訓練數據欠缺代表性。實驗數據通常是在控制實驗無關變量的前提下尋求對典型樣本的估計, 但如果我們的目的是是創建可推廣的預測算法, 樣本需囊括實際生活中大量的個體化病例。其次, 機器學習模型可解釋性和透明度低。存在“算法黑箱”, 輸入的數據和輸出答案之間存在不可觀察的空間, 甚至開發人員都不能完全理解算法運作的具體細節。再者, 機器學習的性能指標不具備臨床適用性, 如F1分數、召回率可能無法適用于臨床環境, 很難被臨床醫生和研究人員理解。最后, 干預方法的驗證研究不足。閱讀障礙的早期篩查的最終目的是為了給兒童提供行之有效的早期干預。但是, 目前僅有兩項研究將機器學習與閱讀障礙干預聯系起來(Atkar & Jayaraju, 2021; Oliaee et al., 2022)。之前對基于機器學習的閱讀障礙的EEG研究主要是通過腦電圖的組間差異(特別是單個頻段的功率)來區分閱讀障礙兒童和典型發展兒童。Oliaee等人(2022)開創性地對特定治療計劃前后的閱讀障礙兒童進行分類, 為評估閱讀障礙治療方案的有效性提供了新的方法。他們利用PCA和序列前向選擇(Sequential Floating Forward Selection, SFFS)算法, 從記錄的腦電圖信號中提取出最優特征子集, 發現閱讀障礙兒童在接受經顱直流電刺激(Transcranial Direct Current Stimulation, tDCS)治療和認知訓練前后的腦電信號在不同區域的頻譜和相位相關特征上發生了顯著變化, 最具識別力的特征子集的分類準確率達到92%。Atkar和Jayaraju (2021)使用一種深度學習?無監督學習的生成對抗網絡模型(Generative Adversarial Networks, GAN)生成兩個或三個字母的印地語單詞的原始音頻數據, 使用生成的數據建立MelGAN系統。該系統通過讓閱讀障礙兒童重復單詞的正確發音來加快恢復過程, 旨在為教師提供一個有效的輔助工具。雖然使用機器學習評估干預效果以及輔助創建干預工具開始走進研究人員的視野, 但它們的實用性和可驗證性仍有待進一步提高。
最后, 被試的數據安全和隱私保護受到威脅。機器學習模型訓練需要大量數據, 但數據庫往往包含大量隱私數據, 如個人身份信息、家庭信息等。如何低成本且高效地防止隱私泄漏變得極為重要。Usman和Muniyandi (2020)構建了一種基于CNN模型和余數模型(RNS)進行閱讀障礙安全分類的方法。他們利用RNS的特殊模塊集開發了一個像素?比特流編碼器, 在使用級聯CNN進行分類之前對訓練集和測試集中MRI數據的每個像素的7位二進制值進行加密, 再使用加密測試數據集預測閱讀障礙兒童。此外, 在數據共享之前制定知情同意、倫理審核同樣有利于防止潛在的數據濫用。
綜上所述, 機器學習已被逐漸應用于閱讀障礙的早期篩查中。數據采集方式從單一模態向多模態的異構數據轉變, 并使用多種模型驗證最佳分類效果, 分類性能在67%~100%之間。當前使用最多的機器學習算法是SVM, 未來深度學習有望為閱讀障礙實現更高的分類性能。在應用中, 閱讀障礙的機器學習研究仍存在樣本量少、臨床實踐率低、多模態數據結合不足、分類性能有待提高等問題。并且, 缺少對最佳干預期的兒童群體研究, 沒有真正實現閱讀障礙兒童的早期篩查。未來的研究首先應重點關注學齡前兒童的風險識別, 著眼于閱讀障礙的早期篩查的標記物研究。其次, 由于閱讀障礙并不特定于某個地區、語言和文化, 因此需要開發獨立于語言的數據收集方法以建立統一標準的閱讀障礙數據庫。最后, 未來的研究需要采集多個來源數據(如量表、行為、腦成像等)、混合多種模型以及考慮多模態的深度學習框架提高機器學習的預測力, 不斷優化構建的閱讀障礙篩查模型, 最終實現臨床實踐中的廣泛使用。
*為納入系統分析的文獻
蘇萌萌, 張玉平, 史冰潔, 舒華. (2012). 發展性閱讀障礙的遺傳關聯分析.,(8), 1259?1267.
Aaron, P. G., Joshi, M., & Williams, K. A. (1999). Not all reading disabilities are alike.,(2), 120?137. https://doi.org/10.1177/002221949903200203
Abd Rahman, R., Omar, K., Noah, S. A. M., Danuri, M. S. N. M., & Al-Garadi, M. A. (2020). Application of machine learning methods in mental health detection: A systematic review.,, 183952?183964. https://doi.org/10.1109/ ACCESS. 2020.3029154
Ahire, N., Awale, R. N., Patnaik, S., & Wagh, A. (2022). A comprehensive review of machine learning approaches for dyslexia diagnosis.,, 13557?13577. https://doi.org/10.1007/s11042-022-13939-0
*Ahmad, N., Rehman, M. B., El Hassan, H. M., Ahmad, I., & Rashid, M. (2022). An efficient machine learning-based feature optimization model for the detection of dyslexia.,, 8491753. https://doi.org/10.1155/2022/8491753
*AlGhamdi, A. S. (2022). Novel ensemble model recommendation approach for the detection of dyslexia.,, 1337. https://doi.org/10.3390/children9091337
*Asvestopoulou, T., Manousaki, V., Psistakis, A., Smyrnakis, I., Andreadakis, V., Aslanides, I. M., & Papadopouli, M. (2019). DysLexML: Screening tool for dyslexia using machine learning.https://doi.org/10.48550/arXiv. 1903.06274
Atkar, G., & Jayaraju, P. (2021). Speech synthesis using generative adversarial network for improving readability of Hindi words to recuperate from dyslexia.,(15), 9353?9362. https://doi.org/ 10.1007/s00521-021-05695-3
Ballester, P. L., da Silva, L. T., Marcon, M., Esper, N. B., Frey, B. N., Buchweitz, A., & Meneguzzi, F. (2021). Predicting brain age at slice level: Convolutional neural networks and consequences for interpretability.,, 598518. https://doi.org/10.3389/ fpsyt.2021.598518
*Bhargavi, R., & Prabha, A. J. (2020). Predictive model for dyslexia from fixations and saccadic eye movement events.,(5), 105538. https://doi.org/10.1016/j.cmpb.2020.105538
Borleffs, E., Glatz, T. K., Daulay, D. A., Richardson, U., Zwarts, F., & Maassen, B. A. M. (2018). GraphoGame SI: The development of a technology-enhanced literacy learning tool for standard Indonesian.,(4), 595?613. https:// doi.org/10.1007/s10212-017-0354-9
Burns, M. K., VanDerHeyden, A. M., Duesenberg-Marshall, M. D., Romero, M. E., Stevens, M. A., Izumi, J. T., & McCollom, E. M. (2022). Decision accuracy of commonly used dyslexia screeners among students who are potentially at-risk for reading difficulties.. Advance online publication. https:// doi.org/10.1177/07319487221096684
Catts, H. W., McIlraith, A., Bridges, M. S., & Nielsen, D. C. (2017). Viewing a phonological deficit within a multifactorial model of dyslexia.,(3), 613?629. https://doi.org/10.1007/s11145-016-9692-2
Catts, H. W., & Petscher, Y. (2022). A cumulative risk and resilience model of dyslexia.,(3), 171?184. https://doi.org/10.1177/ 00222194211037062
*Chen, A., Wijnen, F., Koster, C., & Schnack, H. (2017). Individualized early prediction of familial risk of dyslexia: A study of infant vocabulary development.,, 156. https://doi.org/10.3389/fpsyg.2017. 00156
Chimeno, Y. G., Zapirain, B. G., Prieto, I. S., & Fernandez- Ruanova, B. (2014). Automatic classification of dyslexic children by applying machine learning to fMRI images.,(6), 2995? 3002. https://doi.org/10.3233/BME-141120
*Cui, Z. X., Xia, Z. C., Su, M. M., Shu, H., & Gong, G. L. (2016). Disrupted white matter connectivity underlying developmental dyslexia: A machine learning approach.,(4), 1443?1458. https://doi.org/ 10.1002/hbm.23112
*Da Silva, L. T., Esper, N. B., Ruiz, D. D., Meneguzzi, F., & Buchweitz, A. (2021). Visual explanation for identification of the brain bases for developmental dyslexia on fMRI data.,, 584659. https://doi.org/10.3389/fncom.2021.594659
Farah, R., Ionta, S., & Horowitz-Kraus, T. (2021). Neuro- behavioral correlates of executive dysfunctions in dyslexia over development from childhood to adulthood.,, 708863. https://doi.org/10.3389/fpsyg. 2021.708863
Fletcher, J. M., Lyon, G. R., Fuchs, L. S., & Barnes, M. A. (2019).(2nd ed). The Guilford Press.
*Formoso, M. A., Ortiz, A., Martinez-Murcia, F. J., Gallego, N., & Luque, J. L. (2021). Detecting phase-synchrony connectivity anomalies in EEG signals. Application to dyslexia diagnosis.,(21), 7061. https://doi.org/ 10.3390/s21217061
Fox, S. E., Levitt, P., & Nelson, C. A. (2010). How the timing and quality of early experiences influence the development of brain architecture.,(1), 28?40. https://doi.org/10.1111/j.1467-8624.2009. 01380.x
Gabel, L. A., Voss, K., Johnson, E., Lindstrom, E. R., Truong, D. T., Murray, E. M., … Gruen, J. R. (2021). Identifying dyslexia: Link between maze learning and dyslexia susceptibility gene, DCDC2, in young children.,(2), 116?133. https://doi.org/ 10.1159/000516667
Galaburda, A. M., LoTurco, J., Ramus, F., Fitch, R. H., & Rosen, G. D. (2006). From genes to behavior in developmental dyslexia.,(10), 1213?1217. https://doi.org/10.1038/nn1772
Gilvary, C., Elkhader, J., Madhukar, N., Henchcliffe, C., Goncalves, M. D., & Elemento, O. (2020). A machine learning and network framework to discover new indications for small molecules.,(8), e1008098. https://doi.org/10.1371/journal.pcbi.1008098
Hale, J., Alfonso, V., Berninger, V., Bracken, B., Christo, C., Clark, E., …Yalof, J. (2010). Critical issues in response- to-intervention, comprehensive evaluation, and specific learning disabilities identification and intervention: An expert white paper consensus.,(3), 223?236. https://doi.org/10.1177/ 073194871003300310
*Hmimdi, A., Ward, L. M., Palpanas, T., & Kapoula, Z. (2021). Predicting dyslexia and reading speed in adolescents from eye movements in reading and non-reading tasks: A machine learning approach.,(10), 1337. https://doi.org/10.3390/brainsci11101337
Hosseini, S. M. H., Black, J. M., Soriano, T., Bugescu, N., Martinez, R., Raman, M. M., … Hoeft, F. (2013). Topological properties of large-scale structural brain networks in children with familial risk for reading difficulties.,, 260?274. https://doi.org/ 10.1016/j.neuroimage.2013.01.013
*Ileri, R., Latifoglu, F., & Demirci, E. (2022). A novel approach for detection of dyslexia using convolutional neural network with EOG signals.,(11), 3041?3055. https:// doi.org/10.1007/s11517-022-02656-3
Kaisar, S. (2020). Developmental dyslexia detection using machine learning techniques: A survey.,(3), 181?184. https://doi.org/10.1016/j.icte.2020.05.006
Khan, R. U., Lee, J., & Yin, B. O. (2018). Machine learning and dyslexia: Diagnostic and classification system (DCS) for kids with learning disabilities.,(3), 97?100.
Kraft, I., Cafiero, R., Schaadt, G., Brauer, J., Neef, N. E., Mueller, B., … Skeide, M. A. (2015). Cortical differences in preliterate children at familiar risk of dyslexia are similar to those observed in dyslexic readers.,(9), e378. https://doi.org/10.1093/brain/awv036
Larco, A., Carrillo, J., Chicaiza, N., Yanez, C., & Luján- Mora, S. (2021). Moving beyond limitations: Designing the Helpdys App for children with dyslexia in rural areas.,, 7801. https://doi.org/10.3390/su13137081
*Latifoglu, F., Ileri, R., & Demirci, E. (2021). Assessment of dyslexic children with EOG signals: Determining retrieving words/re-reading and skipping lines using convolutional neural networks.,, 110721. https://doi.org/10.1016/j.chaos.2021.110721
*Lee, S. M. K., Liu, H. W., & Tong, S. X. (2022). Identifying chinese children with dyslexia using machine learning with character dictation.. https://doi.org/10.1080/10888438.2022.2088373.
Livingston, E. M., Siegel, L. S., & Ribary, U. (2018). Developmental dyslexia: Emotional impact and consequences.,(2), 107?135. https://doi.org/10.1080/19404158.2018.1479975
Lucchiari, C., Folgieri, R., & Pravettoni, G. (2014). Fuzzy cognitive maps: A tool to improve diagnostic decisions.,(4), 289?293. https://doi.org/10.1515/ dx-2014-0026
Lyu, J., & Zhang, J. (2019). BP neural network prediction model for suicide attempt among Chinese rural residents.,, 465?473. https:// doi.org/10.1016/j.jad.2018.12.111
Lyytinen, P., Eklund, K., & Lyytinen, H. (2005). Language development and literacy skills in late-talking toddlers with and without familial risk for dyslexia.,(2), 166?192. https://doi.org/10.1007/s11881- 005-0010-y
McGrath, L. M., Peterson, R. L., & Pennington, B. F. (2020). The multiple deficit model: Progress, problems, and prospects.,(1), 7?13. https://doi.org/10.1080/10888438.2019.1706180
Miciak, J., & Fletcher, J. M. (2020). The critical role of instructional response for identifying dyslexia and other learning disabilities.,(5), 343?353. https://doi.org/10.1177/0022219420906801
Miciak, J., Stuebing, K. K., Vaughn, S., Roberts, G., Barth, A. E., & Fletcher, J. M. (2014). Cognitive attributes of adequate and inadequate responders to reading intervention in middle school.,(4), 407?427. https://doi.org/10.17105/SPR-13-0052.1
Morris, R. D., Stuebing, K. K., Fletcher, J. M., Shaywitz, S. E., Lyon, G. R., Shankweiler, D. P., … Shaywitz, B. A. (1998). Subtypes of reading disability: Variability around a phonological core.,(3), 347?373. https://doi.org/10.1037/0022-0663.90.3.347
Ojanen, E., Ronimus, M., Ahonen, T., Chansa-Kabali, T., February, P., Jere-Folotiya, J., … Lyytinen, H. (2015). GraphoGame — A catalyst for multi-level promotion of literacy in diverse contexts.,, 671. https://doi.org/10.3389/fpsyg.2015.00671
Oliaee, A., Mohebbi, M., Shirani, S., & Rostami, R. (2022). Extraction of discriminative features from EEG signals of dyslexic children; before and after the treatment.,(6), 1249?1259. https:// doi.org/10.1007/s11571-022-09794-2.
Ortiz, A., Martinez-Murcia, F. J., Luque, J. L., Gimenez, A., Morales-Ortega, R., & Ortega, J. (2020). Dyslexia diagnosis by EEG temporal and spectral descriptors: An anomaly detection approach.,(7). 2050029. https://doi.org/10.1142/ S012906572050029X
*Plonski, P., Gradkowski, W., Altarelli, I., Monzalvo, K., van Ermingen-Marbach, M., Grande, M., … Jednorog, K. (2017). Multi-parameter machine learning approach to the neuroanatomical basis of developmental dyslexia.,(2), 900?908. https://doi.org/10.1002/ hbm.23426
*Prabha, A. J., & Bhargavi, R. (2019). Prediction of dyslexia from eye movements using machine learning.(2), 814?823. https://doi.org/ 10.1080/03772063.2019.1622461
Raatikainen, P., Hautala, J., Loberg, O., K?rkk?inen, T., Lepp?nen, P., & Nieminen, P. (2021). Detection of developmental dyslexia with machine learning using eye movement data.,, 100087. https://doi.org/10. 1016/j.array.2021.100087
*Radford, J., Richard, G., Richard, H., & Serrurier, M. (2021, February).Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies?HEALTHINF (pp. 58?66), Electr Network. https://doi.org/10.5220/0010196000580066
*Rauschenberger, M., Baeza-Yates, R., & Rello, L. (2022). A universal screening tool for dyslexia by a web-game and machine learning.,628634. https://doi.org/10.3389/fcomp.2021.628634
*Rello, L., Baeza-Yates, R., Ali, A., Bigham, J. P., & Serra, M. (2020). Predicting risk of dyslexia with an online gamified test.,(12), e0241687. https:// doi.org/10.1371/journal.pone.0241687
Richlan, F., Kronbichler, M., & Wimmer, H. (2013). Structural abnormalities in the dyslexic brain: A meta- analysis of voxel-based morphometry studies.,(11), 3055?3065. https://doi.org/ 10.1002/hbm.22127
Russell, S. J., & Norvig, P. (2010).. Hoboken, NJ: Prentice Hall.
Sanfilippo, J., Ness, M., Petscher, Y., Rappaport, L., Zuckerman, B., & Gaab, N. (2020). Reintroducing dyslexia: Early identification and implications for pediatric practice.,(1), e20193046. https:// doi.org/10.1542/peds.2019-3046
*Shamir, N., Zivan, M., & Horowitz‐Kraus, T. (2019). Six‐minute screening test can provide valid information about the skills that underlie childhood reading and cognitive abilities.,(7), 1278?1284. https://doi.org/10.1111/apa.14680
Sihvonen, A. J., Virtala, P., Thiede, A., Laasonen, M., & Kujala, T. (2021). Structural white matter connectometry of reading and dyslexia.,118411. https://doi.org/10.1016/j.neuroimage.2021.118411
*Skeide, M. A., Kraft, I., Mueller, B., Schaadt, G., Neef, N. E., Brauer, J., … Friederici, A. D. (2016). NRSN1 associated grey matter volume of the visual word form area reveals dyslexia before school.,, 2792?2803. https://doi.org/10.1093/brain/aww153
Tamboer, P., Vorst, H. C. M., Ghebreab, S., & Scholte, H. S. (2016). Machine learning and dyslexia: Classification of individual structural neuro-imaging scans of students with and without dyslexia.,, 508?514. https://doi.org/10.1016/j.nicl.2016.03.014
Thiede, A., Glerean, E., Kujala, T., & Parkkonen, L. (2020). Atypical MEG inter-subject correlation during listening to continuous natural speech in dyslexia.,, 116799. https://doi.org/10.1016/j.neuroimage.2020.116799
*Tolami, F. A., Khorasani, M., Kahani, M., Yazdi, S. A. A., & Ghalenoei, M. A. (2021, October).. 11th International Conference on Computer Engineering and Knowledge (ICCKE) (pp. 393?398), Mashad, Iran. https:// doi.org/10.1109/ICCKE54056.2021.9721446
Usman, O. L., & Muniyandi, R. C. (2020). CryptoDL: Predicting dyslexia biomarkers from encrypted neuroimaging dataset using energy-efficient residue number system and deep convolutional neural network.,(5), 836. https://doi.org/10.3390/sym12050836
Usman, O. L., Muniyandi, R. C., Omar, K., & Mohamad, M. (2021). Advance machine learning methods for dyslexia biomarker detection: A review of implementation details and challenges.,, 36879?36897. https:// doi.org/10.1109/ACCESS.2021.3062709
*Vajs, I., Kovic, V., Papic, T., Savic, A. M., & Jankovic, M. M. (2022). Spatiotemporal eye-tracking feature set for improved recognition of dyslexic reading patterns in children.,(13), 4900. https://doi.org/10.3390/ s22134900
Vandermosten, M., Boets, B., Wouters, J., & Ghesquiere, P. (2012). A qualitative and quantitative review of diffusion tensor imaging studies in reading and dyslexia.,(6), 1532?1552. https:// doi.org/10.1016/j.neubiorev.2012.04.002
Vogler, G. P., Defries, J. C., & Decker, S. N. (1985). Family history as an indictor of risk for reading disability.,(10), 616?618. https:// doi.org/10.1177/002221948401701009
Walda, S., Hasselman, F., & Bosman, A. (2022). Identifying determinants of dyslexia: An ultimate attempt using machine learning.,, 869352. https://doi.org/10.3389/fpsyg.2022.869352
*Wang, R., & Bi, H. Y. (2022). A predictive model for chinese children with developmental dyslexia ? Based on a genetic algorithm optimized back-propagation neural network.,, 115949. https://doi.org/10.1016/j.eswa.2021.115949
Wanzek, J., & Vaughn, S. (2007). Research-based implications from extensive early reading interventions.,(4), 541?561. https://doi.org/ 10.1080/02796015.2007.12087917
Yang, X., Zhang, J., Lv, Y., Wang, F., Ding, G., Zhang, M., … Song, Y. (2021). Failure of resting-state frontal- occipital connectivity in linking visual perception with reading fluency in Chinese children with developmental dyslexia.,, 117911. https://doi.org/10. 1016/j.neuroimage.2021.117911
*Yu, Y. C., Shyntassov, K., Zewge, A., & Gabel, L. (2022, March).. 56th Annual Conference on Information Sciences and Systems (pp. 177?181), Electr Network. https://doi.org/ 10.1109/CISS53076.2022.9751182
*Zahia, S., Garcia-Zapirain, B., Saralegui, I., & Fernandez- Ruanova, B. (2020). Dyslexia detection using 3D convolutional neural networks and functional magnetic resonance imaging.,, 105726. https://doi.org/10.1016/j.cmpb.2020.105726
*Zainuddin, A. Z. A., Mansor, W., Lee, K. Y., & Mahmoodin, Z. (2019, July).. Annual International Conference of the IEEE Engineering in Medicine and Biology Society (pp. 4513?4516), Berlin, Germany. https://doi.org/10.1109/EMBC.2019.8857569
Application of machine learning in early screening of children with dyslexia
BU Xiaoou, WANG Yao, DU Yawen, WANG Pei
(Department of Special Education, Faculty of Education, East China Normal University, Shanghai 200062, China)
Developmental dyslexia is the most prevalent form of specific learning disorder with a neurobiological basis that not only restricts an individual's academic achievement and career development, but also negatively affects an individual's psychological and social adjustment substantially. Recently, machine learning has been gradually applied to the early screening of children with dyslexia due to its powerful data processing and mining capabilities, accumulating richer results in various aspects such as standardized psychoeducational testing, eye tracking, game testing and brain imaging. However, machine learning still has limitations in terms of participant selection, data collection, transformation potential, security and privacy. Future researches need to focus on the early identification of pre-school children with dyslexia, construct multimodal data, and find the best classifier among multiple classifiers to obtain optimal parameters, which will eventually achieve widespread use in clinical practice.
dyslexia, machine learning, early screening, children
2022-11-08
* “華東師范大學幸福之花‘音樂畫的腦智機制及促進兒童藝術教育發展的實踐進路’”資助。
王沛, E-mail: wangpei1970@163.com
R395
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
雜文選刊(2016年7期)2016-08-02 08:39:56
小天使·一年級語數英綜合(2016年6期)2016-05-14 12:21:05
河南科技(2014年23期)2014-02-27 14:19:15
