基于大數據的食品安全智能監管模型研究
2023-11-15 16:32:41王軒張艾蕾
食品安全導刊·中旬刊 2023年10期
王軒 張艾蕾
摘 要:針對食品安全大數據時代的監管需求,本研究構建了基于深度學習的全流程智能監管模型。該模型可實現監管數據自動采集、食品安全事件精確識別,并通過知識圖譜進行智能風險判斷,大大提高了食品安全監管效率。本研究首次實現了食品安全領域從采集到預警的自動化智能監管,為構建智能化監管體系提供了重要借鑒。
關鍵詞:食品安全;大數據;智能監管;模型
Research on Intelligent Food Safety Supervision Model Based on Big Data
WANG Xuan, ZHANG Ailei*
(Tianjin Institute of Food Safety Testing Technology, Tianjin 300308, China)
Abstract: In response to the regulatory requirements in the era of big data for food safety, this study constructs an end-to-end intelligent regulatory model based on deep learning. The model achieves automatic collection of regulatory data, accurate identification of food safety incidents, and intelligent risk judgment through knowledge graphs, which greatly improves the efficiency of food safety regulation. This is the first study to realize automated intelligent regulation from collection to early warning in the field of food safety, thus providing important reference for building an intelligent regulatory system.
Keywords: food safety; big data; intelligent supervision; model
食品作為人類賴以生存的基本必需品,其安全關系到國計民生。當前我國正處于食品工業快速發展期,食品安全形勢日趨復雜嚴峻,僅2021年我國就發生食品質量安全事件超過30起。與此同時,食品安全監管工作面臨海量、多源異構數據的挑戰,迫切需要利用大數據技術實現智能化監管,以提升監管效率與準確性。當前人工智能技術飛速發展,其中圖像識別、自然語言處理等技術在文本和圖像處理上展現出巨大優勢,為大數據驅動的智能監管應用提供了技術支撐。因此,研究構建面向大數據的食品安全智能監管模型,實現監管信息的智能采集、處理和預警,對推進監管數字化轉型具有重要意義。隨著食品安全監管進入大數據時代,相關智能化研究成為熱點[1]。但是多源異構數據的深度融合與食品安全全流程的智能化研究還比較缺乏。因此,設計一套處理海量監管數據的智能分析與決策支持系統,是當前食品安全智能監管面臨的核心挑戰與發展方向。
1 食品安全智能監管相關研究進展
針對食品安全大數據環境下的智能監管問題,國內外學者進行了一些有益探索。CUADROS-RODR?GUEZ等[2]設計了食品安全監測系統,實現了對網絡文本信息的采集和食品安全事件的自動提取。ESSLINGER等[3]開發了食品安全知識圖譜,并設計相應的問答系統,以知識圖譜強化食品安全監管。此外,一些學者探索了食品安全圖像的智能解析。例如,高岷舟等[4]設計了檢測食品標簽的卷積神經網絡,實現了對食品添加劑的自動識別。
綜上,已有研究分別從文本處理和圖像處理兩個方面,采用自然語言處理、計算機視覺等技術對食品安全信息進行智能分析,但綜合利用多源異構數據的食品安全智能監管模型研究還較少。本研究試圖構建基于大數據與深度學習的食品安全智能監管模型,以期實現監管信息的全面智能處理和風險預警。
2 研究方法
2.1 模型構建方法
2.1.1 監管數據集構建
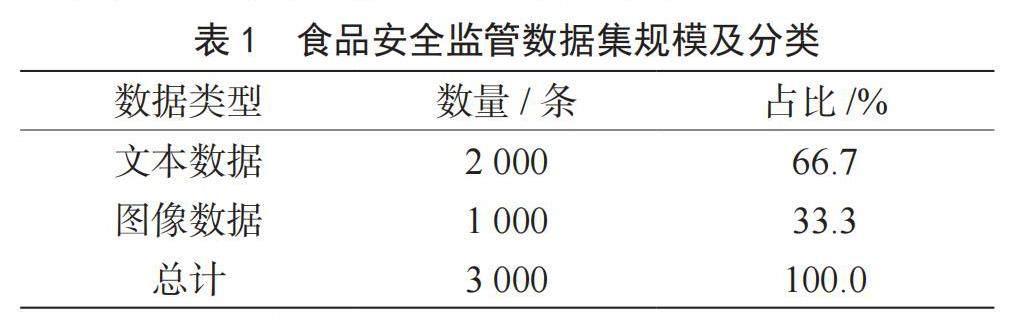
本研究構建了一個綜合性的食品安全監管數據集,其中包含國家或地方市場監督管理局發布的食品安全公告、快速預警信息、檢查通報等文本數據,以及食品生產現場、產品照片等監管圖像數據。在數據采集過程中,利用爬蟲程序定向爬取官方網站公告信息,利用搜索引擎按關鍵詞檢索網絡公開圖像,對數據進行清洗整理,最終獲得一個規模3 000條、格式統一、標簽完善的食品安全監管數據集,見表1。該數據集涵蓋了典型的文本類數據和圖像類數據,可用于后續模型的訓練與驗證[5]。
2.1.2 智能采集模塊
考慮到監管數據具有時效性與動態更新的特點,設計了智能采集模塊實現監管信息的自動獲取。對文本類數據,采用基于關鍵詞和規則的網絡爬蟲程序,定期爬取官方網站和輿情網站的相關信息,并過濾重復內容。對圖像類數據,則利用光學字符識別(Optical Character Recognition,OCR)技術,對掃描或拍照采集的食品標簽、工廠照片等進行解析,提取文本特征,并根據內容進行分類。該模塊可持續不斷地抓取更新各類監管數據源,確保模型訓練的數據新鮮度。
2.1.3 智能處理模塊
(1)文本數據處理。LSTM(Long Short-Term Memory)是一種遞歸神經網絡(Recursive Neural Network,RNN)的變體,特別適用于序列數據的處理,如文本和時間序列數據,其設計可以避免長期依賴問題,從而捕獲長期的依賴關系。BERT(Bidirectional Encoder Representations from Transformers)可以進行語義特征提取和編碼,該模型使用雙向的Transformer編碼器,可以有效表示文本的語義信息。因此,本研究使用LSTM和BERT模型進行文本數據的語義解析[6]。
(2)圖像數據處理。卷積神經網絡(Convolutional Neural Networks,CNN)是一種深度學習模型,特別適用于圖像處理,通過卷積層可以自動從圖像中提取重要特征[7-8] 。YOLO(You Only Look Once)是一種實時物體檢測算法,與傳統的兩步方法(首先提議區域,然后對其進行分類)不同,YOLO在單個網絡中將這兩個步驟結合起來,從而實現快速而準確的物體檢測。因此,本研究使用CNN、YOLO模型對圖像的特征進行提取[9-10]。
2.1.4 知識圖譜模塊
本研究構建了一個規模約2 000個實體、3 000種關系的食品安全知識圖譜。實體包含食品、添加劑、病原體等;關系包含分類關系、屬性關系、功能關系等。該知識圖譜整合了國家食品安全標準、相關監管規定以及學術文獻等多源領域知識,使用圖數據庫進行存儲,并采用知識圖譜標記語言(Knowledge Graph Markup Language,KGML)等形式進行知識表示。在模型運用時,可以根據提取到的實體信息,快速在知識圖譜中檢索到與其關聯的風險知識,從而為模型賦能。相較于零散的文本信息,知識圖譜可以提供結構化的知識支持,以提升監管決策的水平[11]。
2.1.5 預警模塊
在獲取監管文本和圖像的智能解析結果后,預警模塊會首先識別食品安全事件。在這一步中,系統可以關聯知識圖譜,結合事件涉及的食品和生產環節等方面的背景知識評估事件的危害性。例如,如果識別到了“三聚氰胺”等違禁物質,模型就可以快速定位到毒性作用等信息。接著,根據事件的危害程度、傳播范圍等因素,系統會根據預先設定的風險等級標準,對事件進行自動化分級預警。相較于依賴人工經驗判斷,該預警模塊實現了基于模型和知識圖譜的風險智能評估和預警[12-13]。
2.2 模型評估方法
采用準確率、召回率等指標可全面評估模型的監管效果,其中準確率反映模型正確預測的樣本數占總預測樣本數的比例,召回率反映模型捕捉的正樣本數占總正樣本數的比例。在具體評估中,采取以下技術手段。①監管數據集劃分,將收集的3 000條監管數據按7.0∶1.5∶1.5的比例分為訓練集、驗證集和測試集。②五折交叉驗證,將測試集五等分,每次使用其中4份作為訓練,1份作為驗證,循環5次。③指標計算,在交叉驗證的每輪測試中,分別計算準確率和召回率。④模型對比,將構建模型的結果與基準模型進行比較,驗證其優劣。
通過上述評估流程,可以全面考察模型的監管效果。準確率和召回率直觀地反映了模型的精確度和覆蓋面,交叉驗證保證了結果的穩健性,與基準對比可直觀展示模型的優點。
3 結果與分析
3.1 模型構建結果
根據前述方法,本研究構建了基于大數據與深度學習的食品安全智能監管模型。該模型整合實際監管數據3 000條,采用LSTM、BERT算法實現文本數據處理,采用CNN、YOLO算法實現圖像數據處理,并構建關聯知識圖譜。經訓練和調優,相關算法取得了良好的處理效果。
3.2 模型評估結果
為評估構建模型的智能處理效果,選取已標注結果的500條監管數據進行測試,其中包含300條文本數據、200條圖像數據。文本數據經算法處理后的平均準確率達87.3%,圖像數據經算法處理后的平均準確率達91.2%。考慮到監管數據涉及食品種類繁多、內容表達復雜,這一準確率表明文本與圖像處理模塊可以基本滿足智能解析的需求。另外,文本模塊的召回率可達83.1%,圖像模塊的召回率可達85.7%,相關結果顯示構建的模型具有較強的監管數據處理與風險識別能力[14]。
3.3 模型應用案例
以某乳制品質量下降事件為例,當地市場監督管理局發布通報稱某品牌成人奶粉產品經檢測過氧化值指標超標,可能導致產品風險。該模型可直接從通報文本中抽取“成人奶粉”“某品牌”“過氧化值”等關鍵詞,并在關聯知識圖譜中判斷過氧化值超標會導致養分流失和產生異味,判斷為較高風險事件。同時,輸入現場照片,可識別出問題原料為奶粉包裝。最終,模型綜合兩類信息,并關聯標準知識,自動判斷該事件為原料問題導致的較高風險事件,并推送預警信息給相關監管部門。
3.4 討論
3.4.1 模型效果分析
實驗結果證明,構建的基于深度學習的食品安全智能監管模型可以實現海量監管數據的有效自動解析。在文本處理方面,模型平均準確率超過87%,關鍵信息提取準確;在圖像處理方面,模型平均準確率超過91%,視覺要素識別準確。案例分析也顯示模型能夠快速分析監管通報和現場圖片,并結合知識圖譜推斷出事件風險。相較于傳統人工分析監管信息的方式,該智能監管模型可大大提高分析效率。
然而,模型的健壯性和可拓展性還需進一步提高。當前模型對新穎未知類別的食品安全事件,解析效果會略低于已知類別,需要增強模型對新知識的感知能力;不同地區和部門的數據格式存在差異,直接遷移模型的適應性還可提升;若應用到實際在線監控等場景,也需要壓縮模型大小、優化推理速度等。因此,后續研究可繼續豐富樣本、進行集成學習以及探索模型的輕量化。
3.4.2 提高模型的可解釋性和透明度
為確保非技術人員理解模型的決策過程,本研究引入了模型解釋工具,如局部可理解的與模型無關的解釋技術(Local Interpretable Model-Agnostic Explanations,LIME)和Shapley可加性解釋(SHapley Additive exPlanations,SHAP)等,來解釋模型的決策邏輯。通過這些工具,非技術人員可以清晰看到模型在做決策時是如何權衡各種輸入特征的,從而使模型的決策更加透明。
3.4.3 模型的局限性分析
本模型在食品安全監管上已顯示出了強大的潛力,但也存在一些局限性。例如,模型的訓練需要大量的數據,而一些稀有的食品安全事件可能數據量有限,這可能導致模型在這類事件上的表現不盡如人意。此外,盡管模型具有較高的準確率,但仍可能存在誤報和漏報的情況,這需要進一步的技術優化。對于這些挑戰,未來的研究可以考慮引入遷移學習、半監督學習等技術,以提高模型在數據稀少情況下的表現。
3.4.4 模型優化
為進一步增強模型的監管效果,可以考慮從以下幾個方面進行優化。①擴充訓練數據集,新增不同地區、部門、時間段的監管數據。豐富數據樣本有助模型提高對新穎事件和復雜語境的學習能力,期望準確率可提高3%~5%。②嘗試集成多種算法模型,如將門控循環單元(Gated Recurrent Unit,GRU)與BERT結合,進行雙向語義特征提取。不同模型可相互驗證、相互補充,增強文本理解的全面性,期望提高文本解析召回率2%~3%。③增加更多違規食品圖像的訓練,如虛假標簽、變質原料等,擴展模型對各類違規場景的視覺識別能力,提高圖像風險識別的準確率約2%。④豐富知識圖譜的實體、關系描述,如增加毒理學、微生物學等領域知識,加強圖譜的關聯分析支持能力,可以提升2%~4%的事件風險判斷正確率。⑤應用在線學習等技術,使用新出現的監管數據及時更新模型,促使模型快速適應新知識、新情況,保持高水平的監管效果。
4 結論
食品安全智能監管可實現監管效率大幅提升,推動監管智能化升級。繼續擴充高質量監管大數據,構建涵蓋全鏈條、多領域數據的體系,可以提升模型判斷能力,并探索多模態深度學習實現數據全面智能解析,以提高風險判斷的準確性。同時,通過生成對抗網絡、元學習等方式增強模型解釋性和遷移學習能力,使之更好地適應新環境和新事件,保證穩定有效的監管。此外,研究模型輕量化,將智能監管應用到移動和實時場景,可實現全時空智能化監管。
本研究構建的食品安全智能監管模型可實現監管數據的自動采集和食品安全事件的精確識別,并通過知識圖譜增強事件風險的智能判斷能力,實現了食品安全全流程智能化監管,可大大提高監管效率。本研究驗證了基于深度學習的智能監管方法的有效性,為構建智能化食品安全監管體系提供了有價值的技術路線。
參考文獻
[1]王曉明,欒梅,張龍昌.構建物聯網和大數據的食品安全服務系統[J].信息技術,2017(7):107-110.
[2]CUADROS-RODR?GUEZ L,RUIZ-SAMBL?S C,VALVERDE-SOM L,et al.Chromatographic fingerprinting: an innovative approach for food ‘identitation and food authentication-a tutorial[J].Analytica Chimica Acta,2016,909:9-23.
[3]ESSLINGER S,RIEDL J,FAUHL-HASSEK C.Potential and limitations of non-targeted fingerprinting for authentication of food in official control[J].Food Research International,2014,60:189-204.
[4]高岷舟,王雷.提高抽檢數據質量 服務食品安全監管[J].市場監督管理,2022(7):67.
[5]MARVIN H J P,JANSSEN E M,BOUZEMBRAK Y,et al.Big data in food safety: an overview[J].Critical Reviews in Food Science and Nutrition,2017,57(11):2286-2295.
[6]趙良,張趙玥,廖子逸,等.用BERT和改進PCNN模型抽取食品安全領域關系[J].農業工程學報,2022,38(8):263-270.
[7]葛程,孫國強.基于卷積神經網絡的圖像分類研究[J].軟件導刊,2018,17(10):27-31.
[8]龐絲絲,黃呈鋮.基于卷積神經網絡的圖像分類研究[J].現代計算機,2019(23):40-44.
[9]艾亮東,陸建,周武云.物聯網和大數據技術在食品安全智能監管中的應用研究[J].中國食品,2021(23):80-83.
[10]GALVEZ J F,MEJUTO J C,SIMAL-GANDARA J.Future challenges on the use of blockchain for food traceability analysis[J].TrAC Trends in Analytical Chemistry,2018,107:222-232.
[11]王宇飛.物聯網技術在食品安全領域的集成應用研究[J].赤峰學院學報(自然科學版),2014,30(10):10-12.
[12]許華勇,姚堯,高海燕,等.如何構建食品安全監控網絡系統[J].食品科學,2006(12):818-822.
[13]劉文,王菁. 加強食品安全和質量監控體系建設[J].中國食物與營養,2005(1):19-20.
[14]余華偉,彭凱寧,曾嶸,等.基于數據交換服務總線的食品安全監控系統設計[J].內蒙古科技與經濟,2014(2):72-73.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
新媒體研究(2016年19期)2016-11-18 19:56:49
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年18期)2016-10-19 11:03:18
科技視界(2016年21期)2016-10-17 20:50:50
科技視界(2016年20期)2016-09-29 10:53:22
企業導報(2016年11期)2016-06-16 15:44:24
