結合光流算法與注意力機制的U-Net網絡跨模態視聽語音分離
2023-11-18 08:48:26蘭朝鳳蔣朋威郭小霞
電子與信息學報 2023年10期
蘭朝鳳 蔣朋威 陳 歡 韓 闖* 郭小霞
①(哈爾濱理工大學測控技術與通信工程學院 哈爾濱 150080)
②(中國艦船研究設計中心 武漢 430064)
1 引言
在人機交互中,干凈且高質量的聲音輸入,能有效提高語音識別(Automatic Speech Recognition,ASR)和自然語言理解(Natu ral Language P rocessing,NLP)的準確度。然而現實生活中,由于環境的復雜性,存在噪聲和其他說話者的干擾,很難直接得到干凈的語音信號。因此,需要采用語音分離技術對復雜場景下的語音信號進行前端處理,語音分離的最終目的是將目標聲音與背景噪聲(環境噪聲、人聲等)進行分離。
近年來,國內外學者針對語音分離提出了多種模型方法。基于傳統信號處理的角度,人們利用統計學方法解決語音分離。例如W ang等人[1]提出的計算機場景分析(Com putational Auditory Scene Analysis,CASA)、文獻[2,3]提出的非負矩陣分解(Non-negative M atrix Factorization,NM F),但CASA,NM F學習能力不足,限制了整體性能進一步提高。隨著深度學習的快速發展,以深度神經網絡(Deep Neural Network,DNN)為代表的深度模型[4]在語音分離方面取得了顯著的進展,如深度聚類(deep clustering)[5]和置換不變訓練(Perm utation Invariant T raining,PIT)[6]。然而,這些基于音頻流的方法都存在標簽置換問題,很難將分離的音頻與混合信號中相對應的說話者對應。
在擁擠的餐廳和嘈雜的酒吧,人類的感知系統能有效處理復雜環境。例如人類能只關注自己感興趣的聲音,而忽略外部的干擾聲音。這種復雜場景下的語音感知能力不僅依賴人類聽覺系統,還得益于視覺系統,共同促進多感官的感知[7,8]。受此啟發,基于視聽融合的多模態主動說話者檢測[9]、視聽語音分離[10]、視聽同步[11]等研究被相繼提出。
Gabbay等人[12]提出基于視頻幀的語音分離網絡,利用視頻幀中面部信息輔助進行語音分離,雖然有效地減少了混合噪聲對分離的影響,但是該方法具有局限性,只能在有限的環境下取得較好分離效果,不具有泛化性。A fouras等人[13]在Gabbay等人的基礎上,提出用光譜信號代替圖像信號作為時間信號的分離方案,并用softmask進行預測。谷歌最早提出基于視頻和聲音聯合表征的多流體卷積神經網絡[14],該方法從輸入的視頻流提取人臉圖像,然后從音頻流提取音頻特征,通過在卷積層進行特征拼接,得到融合后視聽特征,將視聽特征輸入雙向長短時記憶網絡(B i-d irectiona l Long Short-Term M em ory,BiLSTM),輸出二值掩蔽(Ideal Binary M ask,IBM),最后將IBM與混合語譜圖相乘得到分離語音。為了提高不同場景下視聽語音分離的魯棒性,Gao等人[15]提出了多任務建模策略。該策略通過學習跨模態的嵌入來建立人臉和聲音的匹配,通過人臉和聲音的相互關聯,有效解決了視聽不一致問題。X iong等人[16]在多任務建模基礎上,提出了基于跨模態注意的聯合特征表示的視聽語音分離,將多任務建模策略應用于視聽融合,提高了視覺信息利用率。
上述利用視覺信息輔助進行語音分離方法,可以從混合聲音中自動分離出對應視覺部分的音頻信號,有效地解決標簽置換問題。但這些方法提取視覺特征僅包括唇部特征,在小規模數據集上,面對更復雜的場景時容易受到干擾。視聽融合采用簡單的特征拼接或疊加方法,融合方法單一,未能充分融合視聽特征。
為提高視覺特征的魯棒性和解決視聽融合單一性,本文在基于跨模態注意聯合特征表示的基礎上,分析面部特征外,通過Farneback算法從光流中獲得唇部運動特征。為了充分考慮光流運動特征、視覺特征、音頻特征之間相互聯系,采用了多頭注意力機制,結合Farneback算法和U-Net網絡,提出了一種新的跨模態融合策略。跨模態融合策略的創新主要在于:利用縮放點積注意力計算音頻特征與視覺特征相關性,同時在縮放點積注意力中加入可學習參數,可以自適應調整注意力權重,加快模型的收斂速度;在縮放點積注意力的基礎上,采用多頭注意力機制,利用不同的子空間計算音頻特征與視覺特征相關性,通過對不同子空間的計算結果進行累加,從而獲得音頻和視覺信息的聯合特征表示,以提高語音分離效果。
2 分離模型
2.1 光流算法
光流表征的是圖像像素在運動時的瞬時速度矢量,光流法主要是利用圖像序列中像素之間的相關性來找到前后幀跟當前幀之間存在的對應關系、計算出相鄰幀之間像素的運動信息[17]。光流可以被認為是在一幅圖像中亮度模式的表面運動分布,是圖像中所有像素點的2維速度場,其中每個像素的2維運動向量可以理解為一個光流,所有的光流構成光流場,如圖1所示[18]。
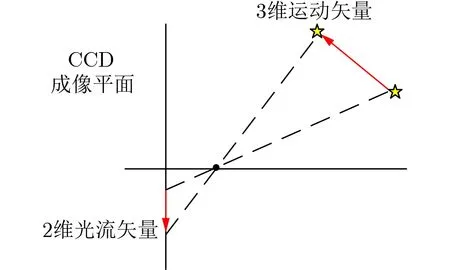
圖1 2 維光流矢量表示觀測場景中3維速度在成像表面投影
通過光流場中2維光流矢量的疏密程度,將光流法分為稀疏光流與稠密光流[19]。稀疏光流是對指定的某一組像素點進行跟蹤,稠密光流是針對圖像或指定的某一片區域進行逐點匹配的圖像配準方法。相比較稀疏光流,稠密光流可以計算圖像所有運動的像素點,進行像素級別的圖像配準。所以,本文利用稠密Farneback光流算法分析唇部的運動信息。
Farneback光流算法假設亮度恒定不變、時間連續運動或是“小運動”、光流的變化幾乎是光滑的。像素在唇部圖像第1幀的光強度為I(x,y,t)(其中x,y代 表像素點當前位置、t代表所在的時間維度),像素點移動了(dx,dy)的距離到下一幀,用了dt時間,根據亮度恒定不變,可得

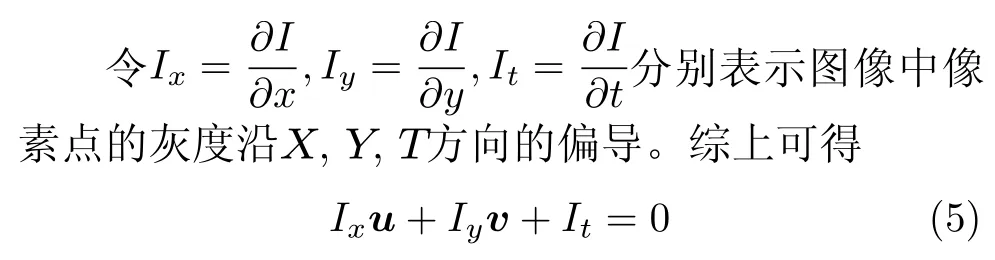
其中,Ix,I y,I t可由唇部圖像數據求得,(u,v)為所求的光流矢量。
2.2 注意力機制
注意力機制可以直接獲取到局部和全局的關系,相比較循環神經網絡(Recurrent Neural Netw ork,RNN)不會受到序列長度限制,同時參數少、模型復雜度低。
注意力機制是在機器學習模型中嵌入的一種特殊結構,用來自動學習和計算輸入數據對輸出數據的貢獻大小。注意力機制的核心公式為
其中,Q,K,V分別表示查詢、鍵、值,dk表 示K的維度大小。Q,K,V計算過程為
其中,X為輸入矩陣,A表示權重矩陣,A Q,A K和AV是3個可訓練的參數矩陣。輸入矩陣X分別與A Q,AK和AV相乘,生成Q,K,V,相當于進行了線性變換。A ttention使用經過矩陣乘法生成的3個可訓練參數矩陣,增強了模型的擬合能力。Q,K,V的計算過程如圖2所示。
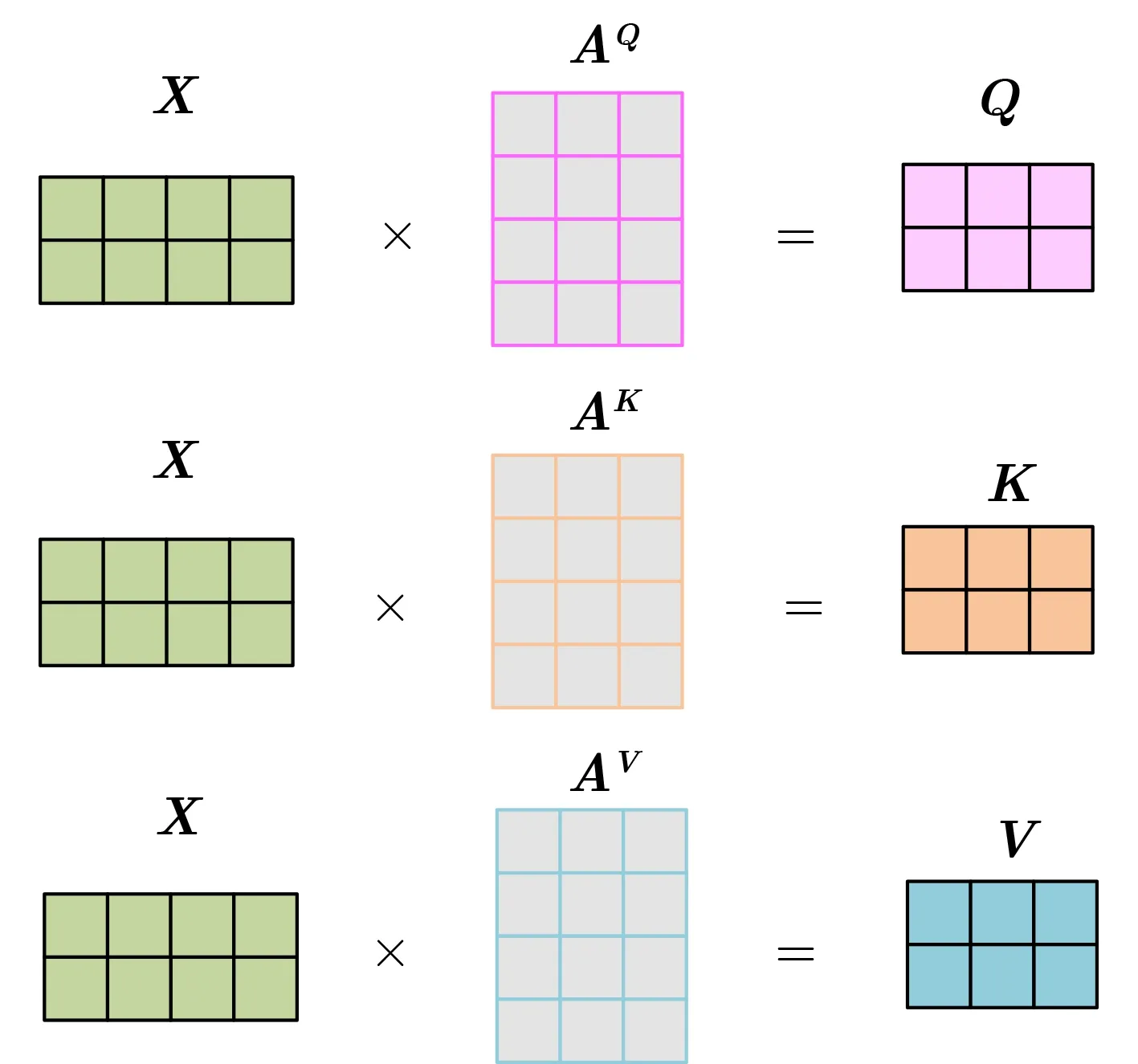
圖2 Q,K,V計算過程
為了進一步增強模型擬合性能,T ransformer對A ttention繼續擴展,提出了多頭注意力。在單頭注意力機制中,Q,K,V是輸入X與A Q,AK和A V分別相乘得到的,A Q,AK和AV是可訓練的參數矩陣。對于同樣的輸入X,本文定義多組不同的A Q,AK和AV,如AQ0,A0K,AV0和AQ1,AK1,A V1,每組分別計算生成不同的Q,K,V,最后學習到不同的參數,如圖3所示。
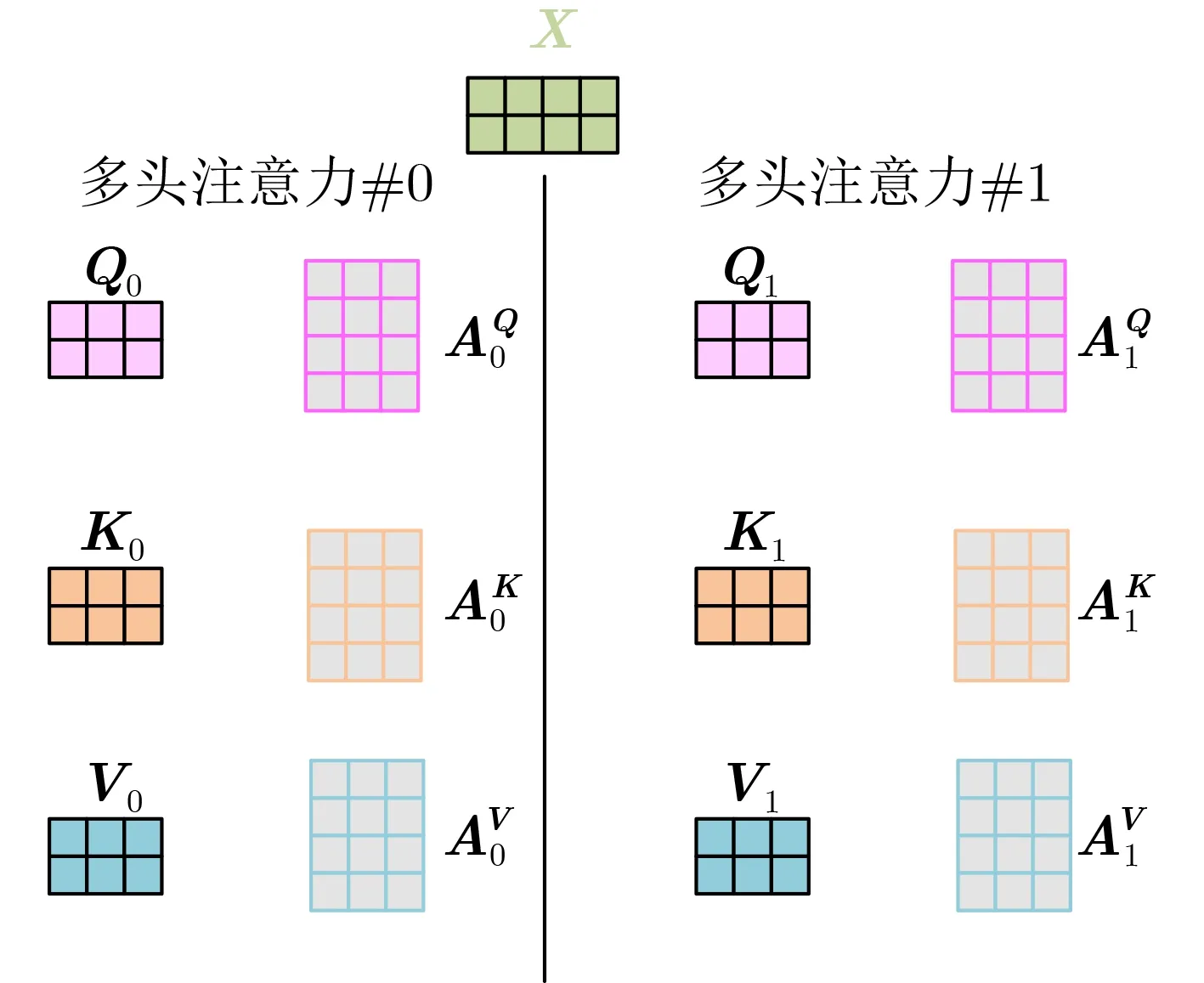
圖3 定義多組A,生成多組Q,K,V
2.3 跨模態融合的光流-視聽分離框架
2.3.1網絡體系結構
基于Farneback光流算法能較好地提取唇部運動特征,以及注意力機制能充分利用視聽特征相關性的優勢,本文提出了跨模態融合的光流-視聽分離(Flow-AudioV isual Speech Separation,Flow-AVSS)網絡。Flow-AVSS采用了常用的混合-分離訓練方法,通過稠密光流(Farneback)算法和輕量級網絡Shu ffleNet v2分別提取運動特征和唇部特征,然后將運動特征與唇部特征進行仿射變換,經過時間卷積模塊得到視覺特征,為充分利用到視覺信息,在進行特征融合時采用多頭注意力機制,將視覺特征與音頻特征進行跨模態融合,得到融合視聽特征,最后融合視聽特征經過U-Net分離網絡得到分離語音。Flow-AVSS網絡如圖4所示。

圖4 跨模態融合的光流-視聽分離框架
圖4主要由4部分組成,分別是唇部網絡、運動網絡、跨模態融合模塊和語音分離網絡。唇部網絡對輸入視頻幀進行特征提取,該網絡由1個3維卷積層和1個ShuffleNet v2網絡[20]組成,唇部網絡采用N個連續堆疊的灰度圖像,生成維度為Kv的唇部特征向量fv,v 表示唇部圖像。
為了能穩定地捕捉視覺特征的空間和時間信息,引入了運動網絡。受動作識別研究的最新進展的啟發,將預訓練的膨脹卷積網絡(In flated 3D convnet,I3D)模型[21]加入到視聽分離框架作為運動網絡。前文光流算法講到,在計算機視覺空間中,光流場是將3維空間的物體運動表現到了2維圖像中,缺少了時間維度。運動網絡通過將2維卷積網絡膨脹到3維,從而獲得缺少的時間維度,將先前灰度圖像估計的光流,生成維度為Km的運動特征向量fm,m表示運動。然后,將運動特征的時間維度與通道維度相乘,獲得與唇部特征相同維度的運動特征。最后,將同維度的運動特征和唇部特征輸入到跨模態融合模塊。
語音分離網絡的結構類似于U-Net網絡[22],輸出掩碼與輸入掩碼大小相同。該網絡由編碼器和解碼器組成,編碼器的輸入是混合信號的2維音頻特征。輸入經過一系列的卷積層和池化層處理后,對復譜圖進行壓縮降維。將音頻特征fa、唇部特征fv和運動特征fm進行跨模態融合得到視聽特征favm。其中,a表示音頻,avm表示音頻、唇部、運動融合。解碼器的輸入是視聽特征favm,輸出是預測的復合掩碼M,復合掩碼M的維度與輸入頻譜圖維度相同。最后,將復合掩碼M與混合音頻相乘,得到分離后的語譜圖,并進行短時傅里葉逆變換(Inverse Short Time Fourier T ransform,ISTFT)得到最終分離的語音信號。
2.3.2跨模態融合模塊
為了充分考慮各個模態之間相關性,實現不同模態之間的聯合表示,本文提出基于注意力機制的跨模態融合策略,跨模態融合模塊的整體結構如圖5所示。
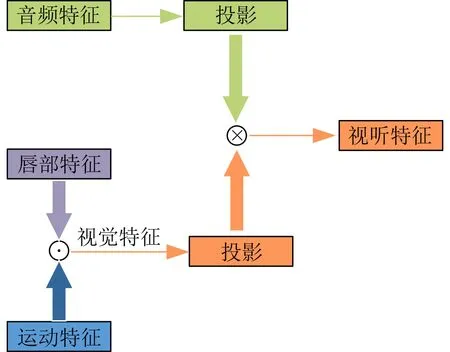
圖5 跨模態融合模塊整體結構
本文利用了運動特征、唇部特征、音頻特征去進行多模態融合。其中,由于運動特征是利用光流算法對圖像進行特征提取,運動特征和唇部特征都屬于視覺特征,是同一種模態,因此在進行特征融合的時候,先利用文獻[23]中提出的特征線性調制(Feature-w ise Linear M odulation,FiLM)對唇部特征和運動特征進行特征仿射變換處理,表示為
其中,γ(·)和β(·)是單層的全連接層,輸出是縮放向量和偏移向量。
運動特征fm經過線性變換與fv相乘進行仿射變換,并送入時間卷積網絡(Tem poral Convolutional Network,TCN)[24]。TCN由1維卷積、批量歸一化(Batch Norm alization,BN)和整流線性單元(Rectified Linear Unit,ReLU)組成,通過TCN模塊可以捕獲唇部特征中的時間關系。最后TCN模塊輸出視覺特征fvm,如圖6所示。
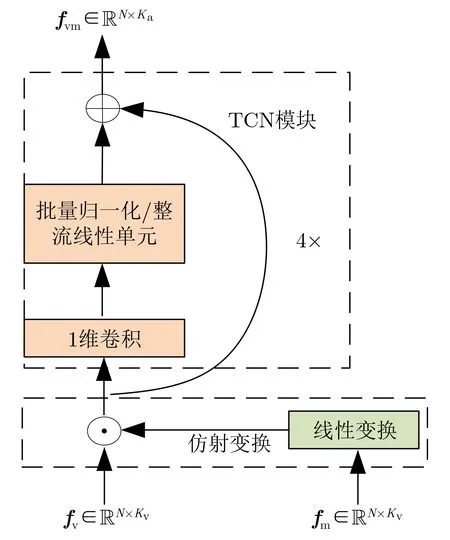
圖6 仿射變換和TCN模塊
受T ransform er多頭注意力[25]啟發,跨模態融合模塊采用了跨模態注意力融合(C ross-M odal A ttention,CMA)策略。在表示注意力機制的式(6)中,加入可學習參數λ,不僅能自適應地調整注意力權重,還能作為殘差連接I(fm),加快模型收斂速度。由式(6)可得縮放點積注意力跨模態融合(Scaled dot-p roduct Cross-M odal A tten tion,SCMA),可表示為
其中,視覺特征fvm經過2維卷積得到Qvm和Kvm,音頻特征fa經過2維卷積得到Va,d是Qvm,Kvm和Va的維度,輸出為視聽融合特征。具體融合過程如圖7(a)所示。
為了進一步增強模型擬合性能,充分利用不同模態的相互關系。在SCMA基礎上,采用多頭注意力跨模態融合(multip le Head Cross-M odal A ttention,HCMA),利用多個子空間讓模型去關注不同方面的信息,如圖7(b)所示。HCMA是將SCMA過程重復進行3次后,再把輸出合并起來,輸出視聽融合特征。由式(7)、式(8)、式(9)、式(11)可得HCMA計算過程
其中,i表 示多頭注意力頭數,Wi Q,Wi K和Wi V表示權重訓練矩陣,Qvmi,Kvmi,Vai分別表示不同子空間下Qvm,Kvm,Va,h eadi表示縮放點積注意力的融合結果。
3 實驗結果與分析
3.1 數據集
AVSpeech數據集中語音長度在3~10 s,在每個片段中,視頻中唯一可見的面孔和原聲帶中唯一可以聽到的聲音屬于一個說話人。該數據集包含了約4 700 h的視頻片段,大約有150 000個不同的說話者,跨越了各種各樣不同性別的人、語音和面部姿態。
干凈的語音剪輯來自AVSpeech數據集,從數據集中不同長度的片段中截取3 s不重疊的語音片段,對于視頻剪輯也是來自AVSpeech數據集,同樣截取與音頻時間相對應的時長為3 s的視頻段,本次實驗隨機選取1 000個干凈語音,然后按照每3個語音混合的方法,生成混合的語音數據庫,再從此混合語音中選取20 000個可懂度相當的混合語音作為本次實驗的數據集,其中90%作為訓練集,剩余的10%作為測試集。本文利用的混合語音按如式(19)的方式生成,公式為
其中,A VSi,A VSj和A VSk是來自AVSpeech數據集的不同源視頻的干凈語音;M ix為生成的混合音頻。
3.2 實驗配置及分離性能評價
(1)實驗配置。本文提出的跨模態融合F low-AVSS網絡,是用Pytorch工具包實現。通過Farneback算法計算唇部區域內的光流,唇部數據和音頻數據的處理基于文獻[15],并對訓練數據進行預處理。使用權重衰減為10-2的AdamW作為網絡優化器,初始學習速率為10-4,并且每次迭代以8×104將學習速率減半。實驗設備采用處理器In tel(R)Core(TM)i7-9700 CPU@3.00 GHz,安裝內存32GB,操作系統64位W indows10,GPU型號GEFORCE RTX2080 Ti,實驗在GPU模式下運行,1次訓練所抓取的數據樣本量為8。
(2)分離性能評價。常用于評估語音分離效果的指標有3種:客觀語音質量評估(Percep tua l Evaluation of Speech Quality,PESQ)[26]指標,衡量語音的感知能力;短時客觀可懂度(Short-T im e Objective Intelligibility,STOI)[27]指標,衡量分離語音的可懂度;源失真比(Signal-to-Distortion Ratio,SDR)[28]指標,衡量語音的分離能力。本文利用上述3種評價指標,對提出的跨模態融合光流-視聽語音分離模型進行性能評估。
3.3 結果分析
(1)為了分析跨模態融合的Flow-AVSS網絡性能,利用SDR,PESQ及STOI評價語音分離效果,結果如表1所示。表1中,為了簡化表達,唇部網絡、運動網絡分別縮寫為Lip,Flow。Lip+Flow+特征拼接表示加入運動特征后,采用特征拼接方法的網絡結構,Lip+Flow+SCMA表示加入運動特征后,采用縮放點積注意力跨模態融合的網絡結構,Lip+Flow+HCMA表示加入運動特征后,采用多頭注意力跨模態融合的網絡結構。
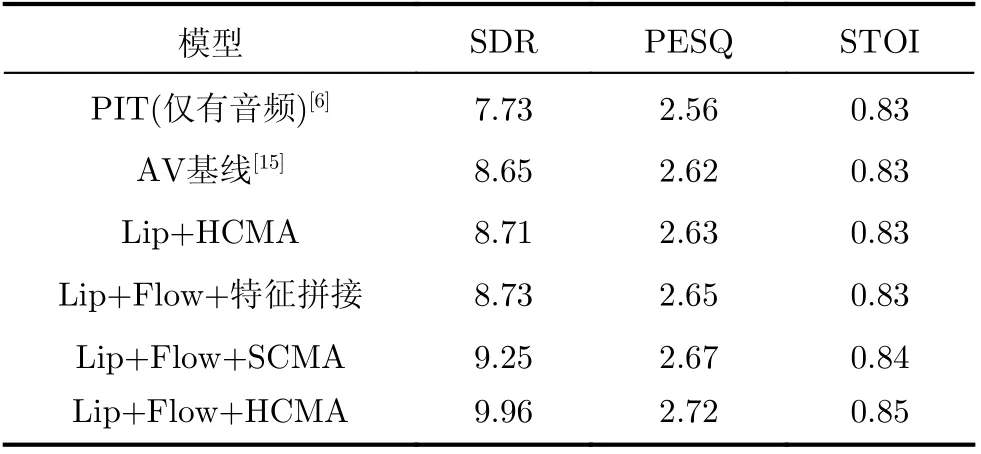
表1 語音分離的性能評估(dB)
由表1可知,Lip+Flow+特征拼接的SDR值為8.73,相比于AV基線未加光流的SDR提升了0.8 dB,說明加入光流后,提高了視覺特征魯棒性,有效提高視聽語音分離性能。Lip+Flow+SCMA,Lip+Flow+HCMA的SDR值分別為9.25 dB,9.96 dB,相比L ip+F low+特征拼接,SDR分別提高了0.52 dB,1.23 dB,說明采用跨模態注意力,相比特征拼接,能更好地利用不同模態之間相互關系,得到更理想的視聽特征。Lip+Flow+HCMA的SDR值為9.96 dB,相比Lip+Flow+SCMA,SDR提高了0.71 dB,多頭注意力中利用了多個學習Q,K,V的權重矩陣,該權重矩陣是獨立地隨機初始化,然后將輸入的視覺特征映射到不同的子空間,從而獲得更多與音頻特征關聯性強的視覺信息,通過對SCMA單次結果的累加降維,最終獲得視覺信息利用率更高的視聽特征,獲得了更好的分離性能。
(2)由于測試集、服務器配置等不同,評價結果也不同,為了提高對比的準確性。利用本實驗室服務器的配置環境,在本文測試集下對文獻[29]、文獻[14]、文獻[15]和文獻[16]進行復現,并于Lip+F low+SCM A和Lip+F low+HCMA進行對比,結果如表2所示。
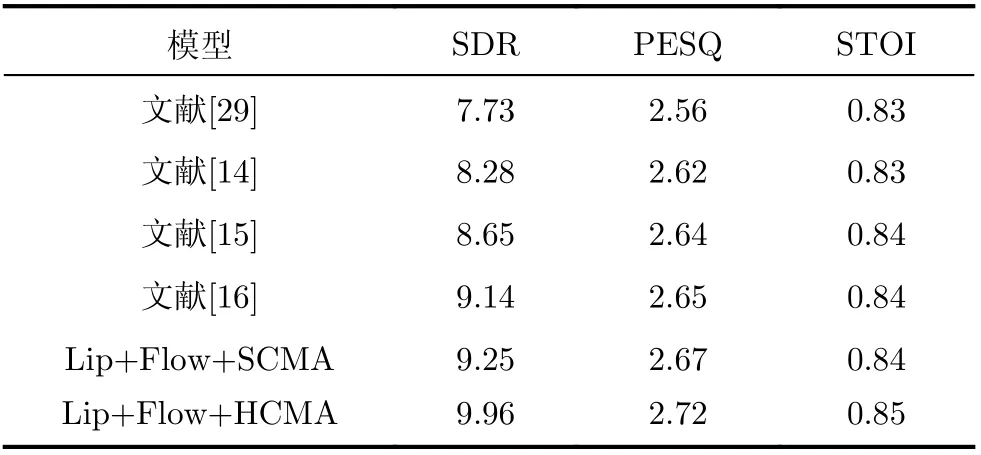
表2 同一數據集、服務器下不同模型分離結果(dB)
由表2可知,采用多頭注意力跨模態融合Flow-AVSS,相比較文獻[29]純語音分離、文獻[14]視聽語音分離、文獻[15]和文獻[16]跨模態融合視聽語音分離,SDR分別提升了2.23 dB,1.68 dB,1.31 dB和0.82 dB。
4 結論
本文針對單通道語音分離,提出一種基于Farneback算法和跨模態注意力融合的視聽語音分離模型。采用Farneback稠密光流算法,提取唇部的運動特征,可以有效提高視覺特征的魯棒性。采用跨模態注意力進行視聽特征融合,可以充分利用音頻流和視頻流之間的相關性。實驗結果表明,本文提出的跨模態注意力融合的光流-視聽語音分離網絡在SDR,PESQ和STOI 3個指標上,都優于純語音分離和采用特征拼接的視聽語音分離網絡。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
