面向遙感圖像場景分類的雙知識蒸餾模型
2023-11-18 08:48:26李大湘南藝璇劉
電子與信息學報 2023年10期
李大湘 南藝璇劉 穎
(西安郵電大學通信與信息工程學院 西安 710121)
1 引言
隨著衛星與遙感技術的飛速發展,獲取高分辨率遙感圖像(Remote Sensing Image,RSI)變得越來越容易,且在農業災害檢測[1]與交通出行[2]等方面得到廣泛應用。由于RSI數量的增多,如何利用計算機對RSI進行自動分類,以提高人們基于RSI對地球表面的觀測效率具有重要意義。
根據拍攝場景所包含的主要目標存在的差異性,已有RSI分類方法可分為兩類:(1)基于手工特征的方法。例如:姜亞楠等人[3]提出一種基于多尺度LBP特征融合的RSI分類方法,一定程度上緩解了類似方法因忽略RSI本征屬性及多尺度局部結構而導致獲取的信息量少的問題;Chaib等人[4]則在手工特征的基礎上,對其再實施稀疏自動編碼,這樣做可以有效去除冗余信息,且增加了特征的旋轉不變、尺度不變及稀疏性,從而提高了RSI場景分類精度但由于RSI均由飛行器從高空多角度鳥瞰隨機拍攝,目標對象尺度變化大且無中心分布,這就導致了RSI存在“類內差異大且類間差異小”的問題,則基于手工特征的方法在分類精度方面受限。(2)基于卷積神經網絡(Convolutional Neural Network,CNN)的方法。例如:李彥甫等人[5]將自注意力機制融入殘差卷積網絡,用CNN提取深度語義特征,然后在最后3層嵌入多頭自注意力模塊來提取RSI復雜的全局信息,以此來提高RSI分類性能;Xu等人[6]提出了一個由圖卷積神經網絡驅動的深度特征聚合框架,用于RSI場景分類;Chen等人[7]提出了一種基于多分支局部注意網絡的RSI場景分類方法,有助于在復雜背景下突出主要目標,提高特征表示能力。實驗結果表明,基于大數據驅動的CNN方法一定程度上提高了RSI場景分類精度,但也存在對RSI局部目標感知不足、模型參數量過大的問題。
針對上述問題,如圖1所示,本文設計了一個基于雙知識蒸餾(Double Know ledge Distillation,DKD)的RSI場景分類新模型。首先,將改進的通道注意力(Channel A ttention,CA)和空間注意力(Spatial A ttention,SA)相結合,構造成一個新的雙注意力(Dual A ttention,DA)模塊,且設計了一個DA蒸餾函數,以將教師網絡中的“注意力知識”遷移到學生網絡之中,增強其對RSI局部目標的感知能力;然后,在學生訓練過程中,將每批圖像的特征建模成一個空間結構關系圖(Spatial Structure Graph,SSG),且設計了一個基于距離、邊與角度等信息的蒸餾函數,構造成一個空間結構(Spatial Structure,SS)蒸餾模塊,以將教師網絡中“SS知識”遷移到學生網絡之中,增強其對RSI的高層語義提取與表達能力。
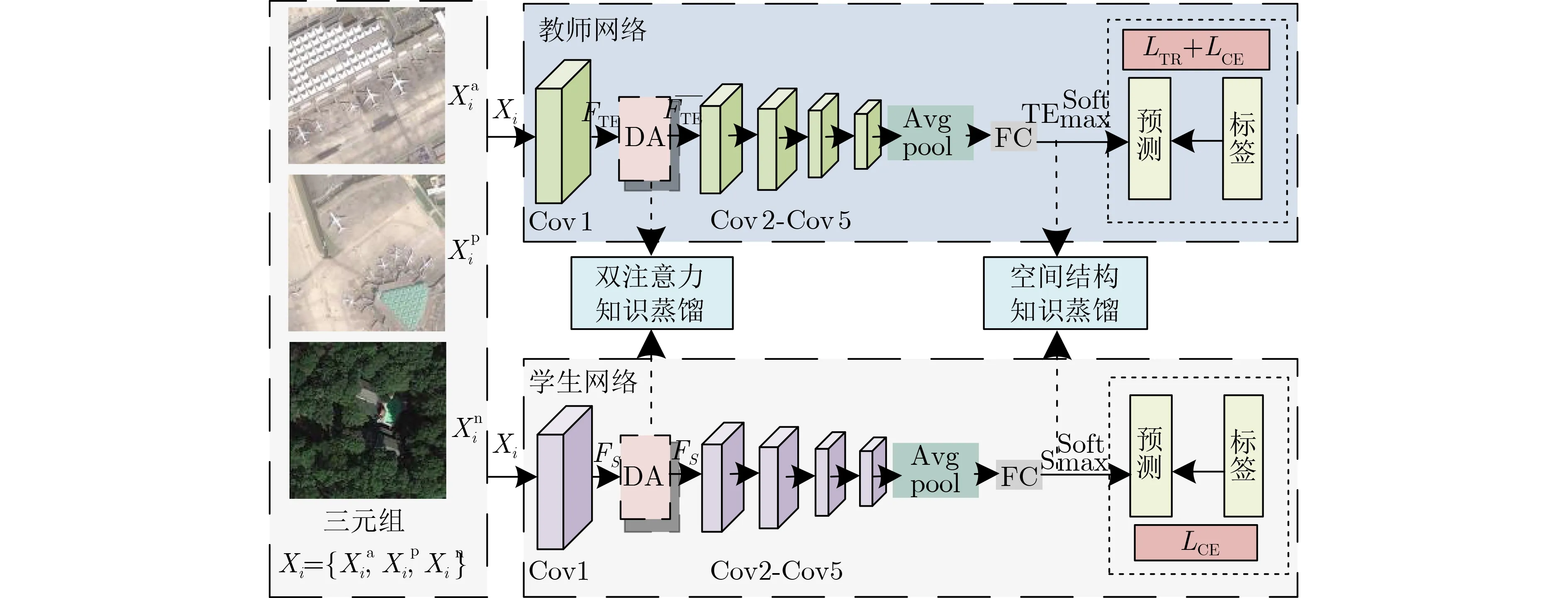
圖1 設計的DKD模型框架結構示意圖
2 所提DKD模型
由圖1可見,設計的DKD模型主要由3大部分組成,即復雜的教師網絡、輕型的學生網絡與蒸餾函數,旨在通過設計的知識蒸餾函數將教師網絡中的DA與SS知識遷移到學生網絡,使其在參數量很小的條件下,性能接近教師網絡[8]。
2.1 教師網絡的設計及訓練
2.1.1教師網絡設計
本節設計了一個新的DA模塊,且將其加入到ResNet101[9]的Conv1殘差模塊之后作為教師網絡。如圖2所示,設計的DA模塊主要由CA及SA兩個分支組成,不防設F∈RH×W×C表示任意輸入的特征圖譜,其中W,H和C分別表示特征圖譜的寬度、高度與通道數,DA過程可總結為
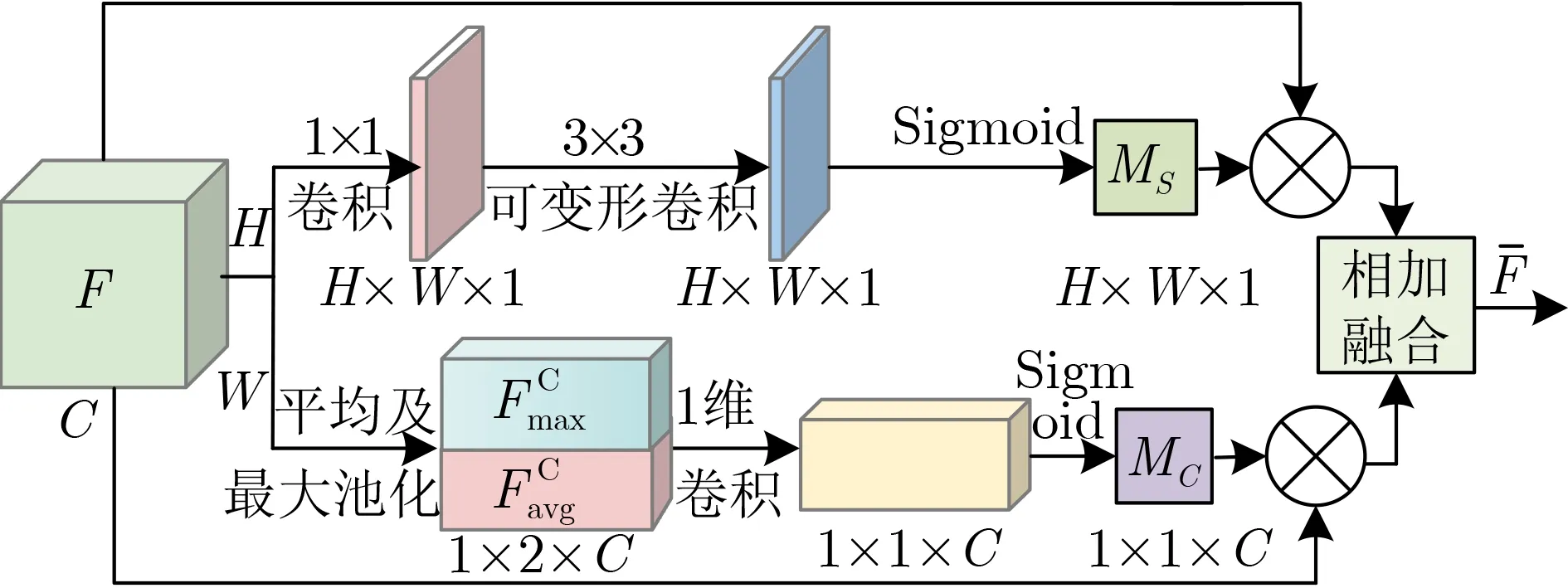
圖2 雙注意力(DA)模塊架構示意圖
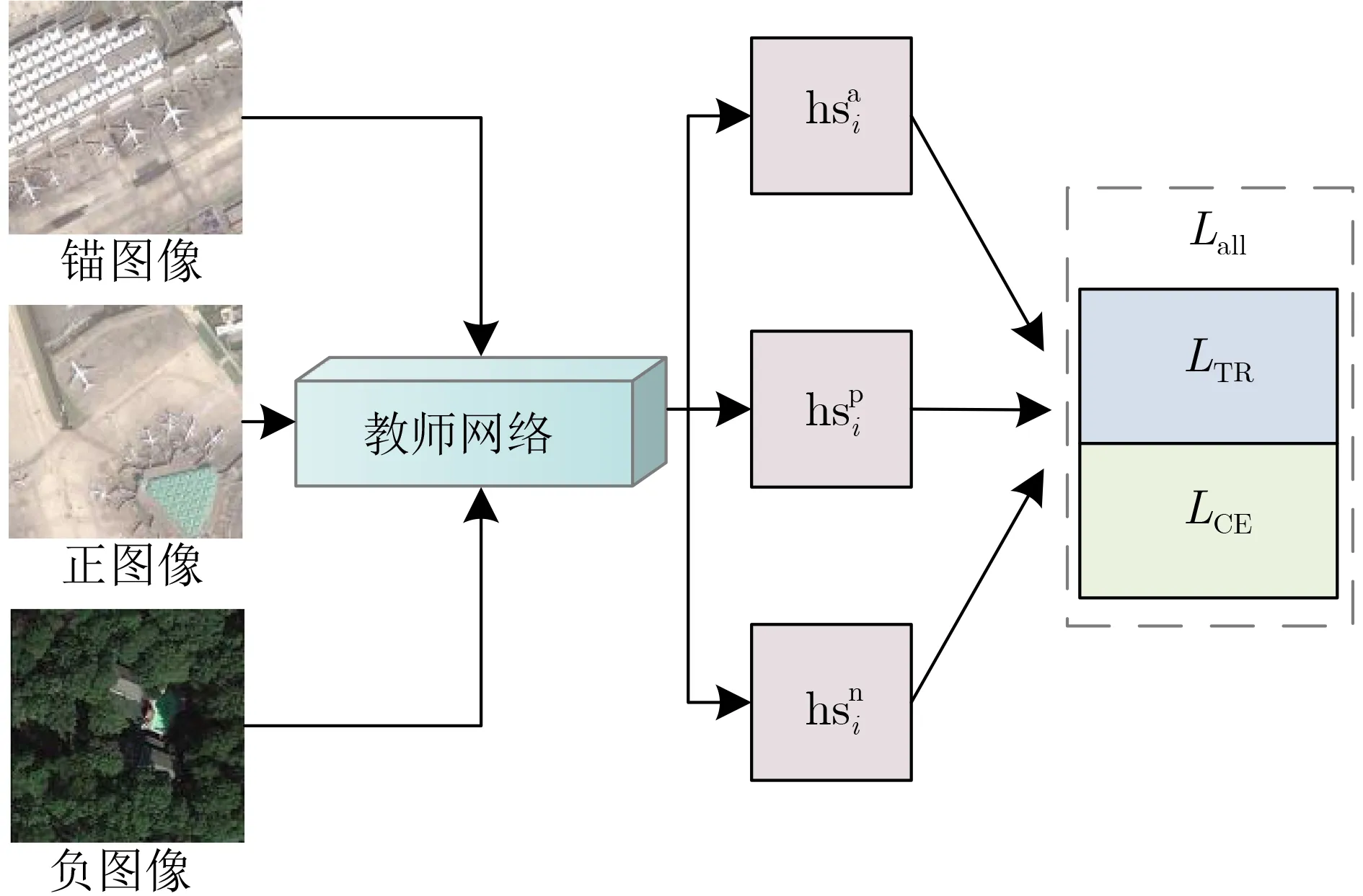
圖3 教師網絡訓練3元孿生框架示意圖
其中,⊙表示廣播元素乘法,Fˉ∈RH×W×C表示經過DA模塊加權之后得到的特征圖,MS ∈RH×W×1表示經SA分支獲得的2維空間注意映射,M C ∈R1×1×C表示經CA分支獲得的1維通道注意映射。
(1)SA分支。為了讓教師網絡在特征提取時更能聚焦于RSI的局部區域,且對不同形態的目標進行自適應性,在CBAM方法[10]啟發下,引入1×1卷積與可變形卷積理論[11],構造一個新的SA分支(如圖2上半部分所示)。設F∈RW×H×C表示輸入的特征圖譜,其中W,H和C分別表示其寬度、高度與通道數。首先,將F送入1×1卷積層進行處理,其結果再送入3×3可變形卷積層,最后經過Sigm oid操作,得到空間注意力映射M s∈RW×H。具體計算過程為


2.2 學生網絡及雙知識蒸餾
2.2.1學生網絡設計
在知識蒸餾模型中,當一個復雜且高精度的教師網絡訓練成功之后,就要設計一個與教師網絡結構相仿的輕型學生網絡,以利于從教師網絡接受底層特征提取與高層語義表示能力。本節設計的輕型學生網絡包含5個卷積模塊、1個平均池化及1個SoftM ax分類層。為了使學生網絡更能關注到RSI的局部目標,且能從教師網絡中接受相應的DA知識,在其第1個卷積后也添加了一個與教師網絡相同的DA模塊,詳細信息如表1所示。
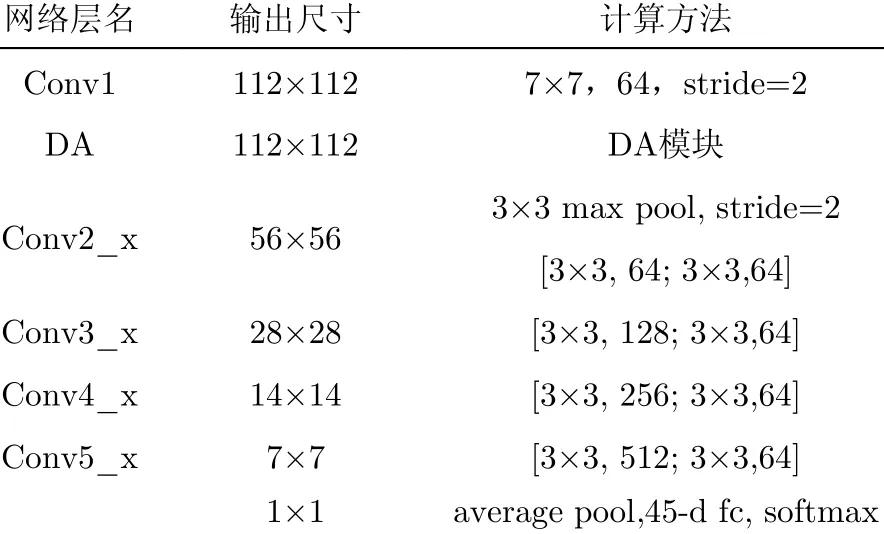
表1 學生網絡具體參數設計
2.2.2雙知識蒸餾設計
(1)DA知識蒸餾
為了將教師網絡中的DA知識遷移到學生網絡,從而提高其前端卷積層對RSI的底層特征捕獲能力。設B={(IMGi,y i)|i=1,2,···,BS}表示任意一批訓練圖像,IMGi與yi分別表示第i幅圖像及其標簽,BS表示批大小。當B中的圖像送入教師網絡與學生網絡之后,基于歸一化均方差函數,定義的DA蒸餾損失為
(2)SS知識蒸餾
設B={(IMGi,y i)|i=1,2,···,BS}表示任意一批訓練圖像,當這些圖像經教師網絡與學生網絡處理之后,最后一個FC層的輸出被視作高層語義特征,分別表示為T b={t i|i=1,2,...,BS}與 Sb={s i|i=1,2,...,BS},其中ti與si表示第i幅圖像I MGi分別從教師網絡與學生網絡得到的高層語義特征。為了將教師網絡中的高層語義表示能力遷移到學生網絡之中,如圖4所示,是本節設計的SS知識蒸餾示意圖,旨在利用教師網絡中實例間的相互關系來傳遞結構知識[14]。傳統的知識蒸餾只蒸餾單個圖像語義特征所帶來的知識,而本節設計的SS蒸餾方法,是在傳統方法的基礎上增加了SS關系中的二元距離和3元角度的知識傳遞,其設計動機是:構成知識的東西,通過所學的表征關系比通過所學表征個體更好地表現出來。
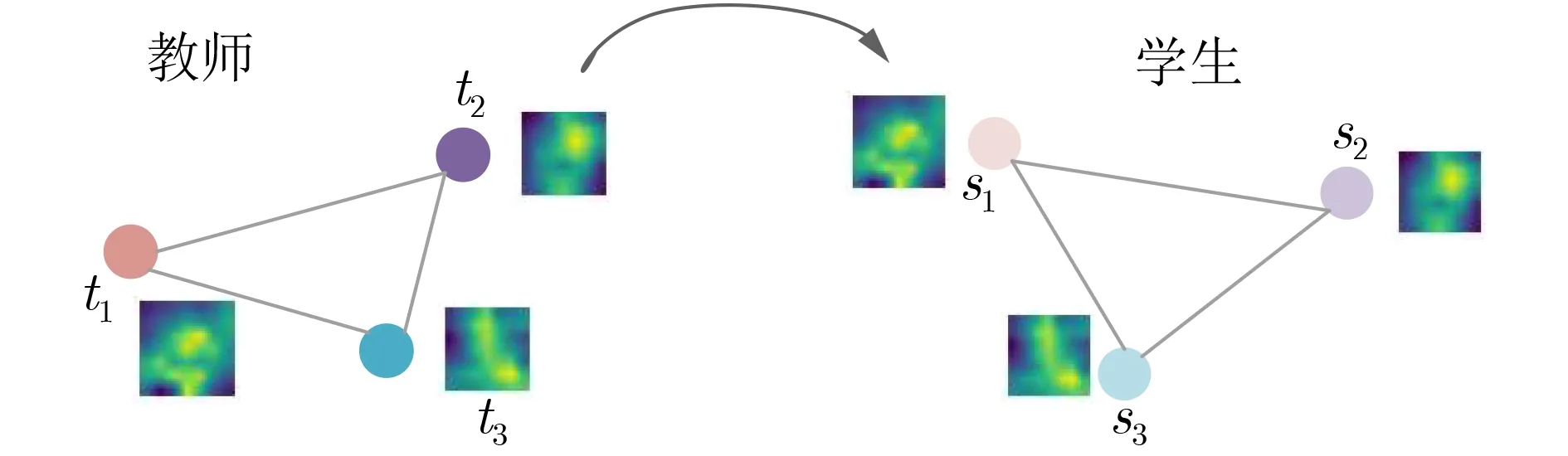
圖4 SS知識蒸餾
首先,以教師網絡獲得的語義特征Tb={t i|i=1,2,...,BS}為例(ti表示教師網絡的特征圖譜),構造

2.3 混合損失及算法步驟
為了將教師網絡中的DA知識與SS知識遷移到學生網絡之中,在DA蒸餾損失LDA(B)與SS蒸餾損失LSS(B)的基礎上,且結合標準的交叉熵分類損失LCE(B),本節定義混合型損失LHTL來訓練學生網絡,其公式為
其中,y i與y?i分別表示第i幅圖像的真實標簽向量與預測標簽向量。在設計的DKD模型中,利用HTL函數來訓練學生網絡,可使其從教師網絡中獲得多種類型的知識,以提高學生網絡的分類準確性。最后,為了更好地理解教師網絡與學生網絡之間的知識蒸餾,學生網絡訓練及測試步驟總結如算法1所示。。
3 實驗結果與分析
3.1 數據集
實驗數據集采用RSI場景分類領域中的兩個經典大規模數據集AID[15]和NUWPU-45[16],其基本信息是:(1)AID是一個大型航測遙感場景分類數據集,它包含30個場景類別,每類樣本有220至420張,數量不等,共有10 000個樣本。AID中的樣本來自不同的遙感傳感器,具有8~0.5m的不同空間分辨率,每張圖像的大小為600×600;(2)NUW PU-45是西北工業大學創建的航空圖像場景分類公開數據集,該數據集共有場景類45個,每類有700張圖像,每張圖像的大小為256×256,總樣本31500張,且具有30~0.2 m的不同空間分辨率,該數據集的挑戰在于不同的空間分辨率、類內強多樣性及類間相似性。在實驗之前,首先對訓練圖像進行了標準化預處理,即將RSI的像素值歸一化至0-1的范圍,然后采用數據擴充技術來增加數據集的多樣性,以防止訓練過程中的過擬合和偏差[17]。
3.2 實驗方法與評價指標
在實驗過程中,將RSI的大小統一調整為224×224,且采用以下策略對數據集進行劃分:隨機選取A ID的20%和50%圖像用于構造訓練集,其余圖像用于測試。同樣,隨機選取NW PU-45圖像的10%和20%用于構造訓練集,其余用于測試。模型訓練過程中,Epoches與批大小BS分別設置為1 000與32,選擇Adam優化器,并將初始學習率lr設為0.001,且采用余弦衰減策略進行更新。
本文采用RSI分類任務中兩種常用的指標[16]用于定量評價實驗結果,即:(1)總體精度(Overall Accuracy,OA):定義為正確分類的樣本數量與所有樣本數量的比值;(2)混淆矩陣(Con fusion M atrix,CM):是一個2維表,用于分析類間分類誤差和混淆程度,可視化算法的性能。
3.3 消融實驗
為了驗證知識蒸餾在RSI場景分類中的有效性,本節評估了學生網絡從教師網絡中蒸餾不同知識的情況下的分類性能,基于數據集A ID及NWPU-45的消融實驗結果如表2所示,且與其他模型的復雜度對比如表3所示。“基線”表示學生網絡在訓練時只使用標簽作為監督信息,即LHTL(B)中只保留LCE(B),學生網絡的訓練不使用任何蒸餾知識;“+DA”或“+SS”分別表示只將教師網絡的DA或SS知識作為蒸餾信息來指導學生網絡的訓練;“+DKD”表示同時使用教師網絡中的DA與SS知識蒸餾來指導學生網絡訓練;“教師”表示用“圖3所示3元孿生框架”訓練的教師網絡。
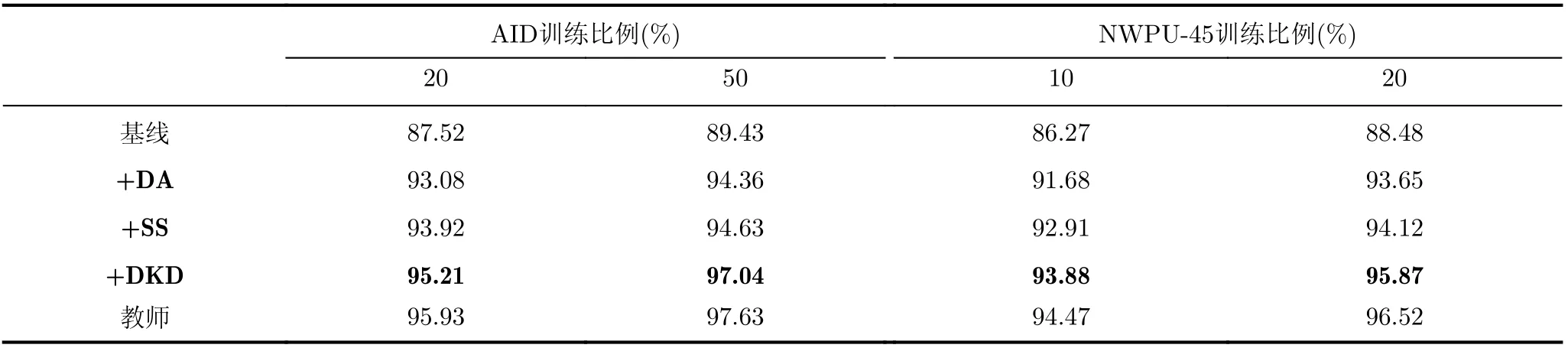
表2 不同訓練比例下消融實驗的OA值(%)

表3 教師與學生網絡性能比較(以A ID數據集(50%)為例)
從表2所示消融實驗結果可以發現,在A ID與NW PU-45兩個RSI數據集上,較之無任何知識蒸餾的原始學生網絡,采用DA蒸餾訓練的學生網絡的OA平均提高了5.56%(20%),4.93%(50%)和5.41%(10%),5.17(20%);采用SS蒸餾訓練的學生網絡的OA平均提高了6.40%(20%),5.20%(50%)和6.64%(10%),5.64(20%);經過DKD訓練的學生網絡OA平均提高了7.69%(20%),7.61%(50%)和7.61%(10%),7.39(20%)。顯然,本文設計的兩個知識蒸餾模塊是有效的,能提高RSI場景分類精度,主要原因是:DA模塊將SA與CA相結合,且設計了一個DA蒸餾函數,能將教師網絡的DA知識有效地傳遞給學生網絡,以提升其提取RSI局部信息的能力;SS蒸餾模塊在學生網絡訓練過程中,將每批訓練圖像的語義特征建模成一個SSG,且設計了融合距離損失、邊損失與角度損失的SS蒸餾函數,以將教師網絡中SS知識遷移到學生網絡之中,增強其對RSI的高層語義提取與表達能力。同時也可看出,兩個知識蒸餾模塊同時使用,比用任意一個蒸餾模塊提升更高,這證實了兩個蒸餾模塊可以相互補充。由表3的數據也可以看出,經DKD的學生網絡分類精度接近教師網絡,但教師網絡的復雜性(參數量、模型大小與訓練耗時)遠高于學生網絡;同時,也可發現學生網絡在精度較高的前提下,其參數量也低于當前其他經典方法。
3.4 綜合對比實驗
為了進一步驗證所提DKD模型的有效性,基于AID和NWPU-45數據集,與近幾年的ARCNet-VGG[19],MobileNet[20]與V iT-B-16[21]等基準方法進行綜合對比,實驗結果如表4所示。
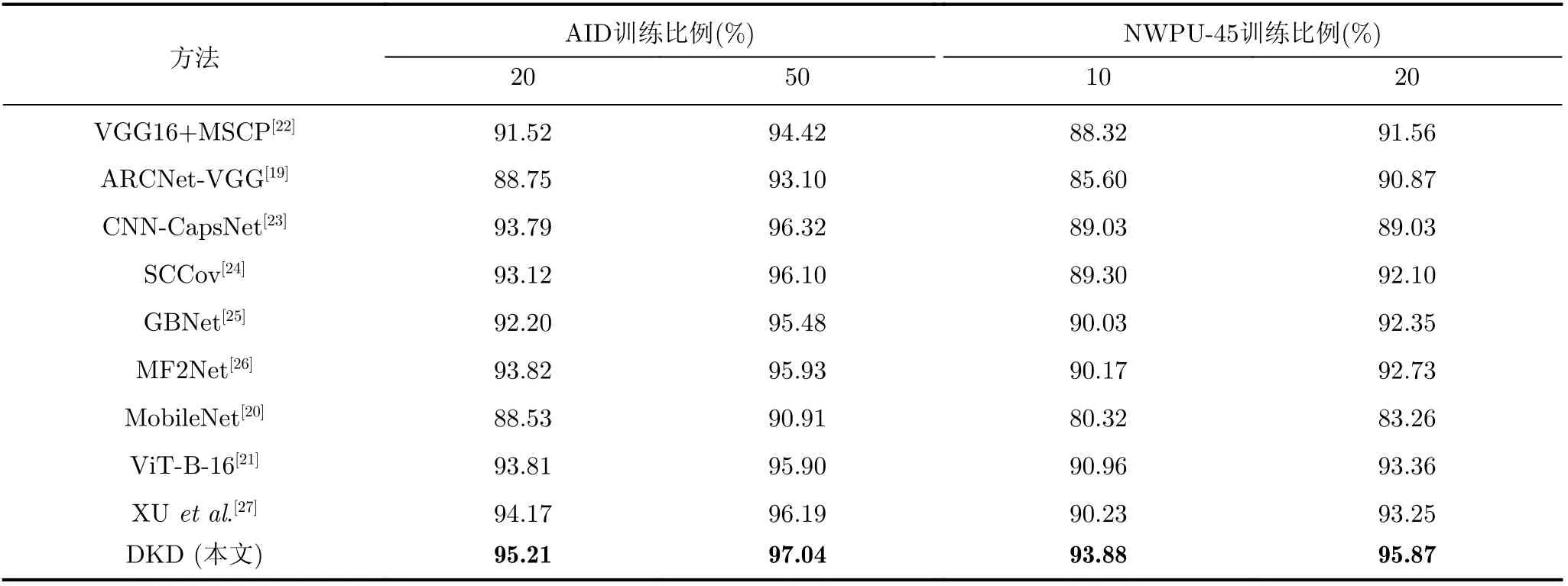
表4 基于AID與NWPU-45數據集的綜合對比實驗結果(%)
從表4所示的數據可知,基于A ID數據集所提DKD模型在20%和50%的訓練比例下,都展現出了最高的OA,分別為95.21%和97.04%;同時,從表4所示數據也可知,基于NWPU-45數據集,所提DKD模型在兩種訓練比例下OA分別達到了93.88%和95.87%,相比其他效果最好的V iT-B-16[21]方法,OA分別提高了2.92%與2.51%,且較之經典的輕量級模型MobileNet[20],OA分別提高了13.56%與12.61%。由此,在以上兩個數據集下的表現可以看出,所提DKD模型在RSI場景分類任務中是有效的。
為了進一步觀察所提DKD模型在RSI場景分類中的具體表現,如圖5與圖6所示,在訓練比例20%的情況下,繪制了A ID和NW PU-45數據集測試時的混淆矩陣。
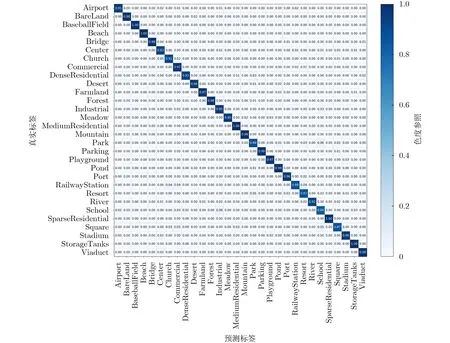
圖5 AID數據集訓練比例為20%時的混淆矩陣
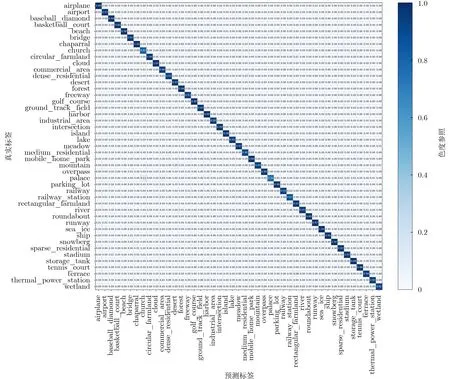
圖6 NWPU-45數據集訓練比例為20%時的混淆矩陣
圖5展示了A ID數據集在20%訓練比例下的混淆矩陣,可以看出,30個場景類別中只有5個的分類精度低于90%。例如:“School”的分類準確率只有84%,是30類中最低的,其中有6%的圖像被錯分為“Industrial”,主要原因是這2個類別均具有相同或相似的紋理特征(例如圓弧),在局部特征上存在較高的相似性。圖6展示了在NWPU-45數據集的混淆矩陣,當訓練比例為20%時,在45個類別中只有3類的分類準確率小于90%,其中“Palace”的精確度最低,只達到76%,這是由于該類圖像的主要目標是宮殿建筑物,而其他很多類別的圖像中也包含有房屋建筑,特別是“Church”類別,它們具有極相似的建筑風格與布局,使得其分類變得困難,導致分類準確率最低。
3.5 模型可視化
對于使用了注意力機制的RSI場景分類算法,為了分析CNN網絡在RSI中關注的是什么局部區域,熱圖是一種非常有效的方法。如圖7所示(圖像是來自NW PU-45驗證集),本節使用G rad-CAM[28]將經過訓練的4種不同網絡進行了可視化,即利用梯度來計算最后一個卷積層中每個神經元的重要性,以獲得感興趣的決策,可視化結果顯示圖像中的哪個區域是模型做出分類決策的重要特征,熱圖中顯示越紅的區域表示這些地方更具辨別力,是模型在對該圖像進行分類時最感興趣的區域。從圖7所示熱圖可見,經DKD之后學生網絡在具有復雜背景的RSI中,較之其他3種方法,其注意力聚焦的感興趣區域更精準且更完整。

圖7 使用Grad-CAM進行可視化對比
4 結論
面向RSI場景分類問題,本文設計了一種新的DKD模型。首先,將改進的CA與SA相結合構造成DA模塊,且設計了一個DA蒸餾函數,以將教師網絡的DA知識傳遞到學生網絡,提高后者對RSI目標局部信息的提取能力;其次,將每批訓練圖像的特征建模成一個SSG,且構造了一個SS蒸餾模塊,以將教師網絡中的SS知識傳遞給學生網絡,從而增強后者對RSI的高層語義提取與表達能力。此外,在兩個大型公開RSI數據集上的對比實驗結果表明,學生模型在參數數量明顯減少的情況下,其精度可接近復雜的教師網絡,也優于其他方法,更利于部署在遙感應用平臺上。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
