基于改進YOLOv7 的液壓閥塊表面微小缺陷檢測
2023-11-18 03:33:06季娟娟陳亞杰盧道華
計算機工程 2023年11期
季娟娟,王 佳,陳亞杰,盧道華,3
(1.江蘇科技大學 機械工程學院,江蘇 鎮江 212100;2.中國船舶重工集團公司 上海船舶設備研究所,上海 200031;3.江蘇科技大學 海洋裝備研究院,江蘇 鎮江 212003)
0 概述
液壓系統由于具有輸出力大、傳動可靠、可控性高、使用壽命長等優點[1],已被廣泛應用于汽車[2-3]、機器人[4-5]、航空航天[6]、工程機械[7-9]等領域。液壓閥塊是液壓系統中的關鍵零部件,通過控制壓力油在管路中的流動來實現機械動作,在其生產過程中,銑、刨等粗加工操作都會造成液壓閥塊表面出現劃痕、凹坑等缺陷,這些缺陷容易使液壓閥塊出現滲漏的情況,甚至會影響到機械的行駛安全。為了提前篩選出表面有缺陷的液壓閥塊,提高產品的合格率,研究液壓閥塊表面微小缺陷檢測方法具有重要意義。
目前,許多研究人員采用傳統的機器視覺技術進行表面缺陷檢測。文獻[10]設計一種基于形態學的邊緣檢測方法,通過使用Otsu 閾值算法對軸承外圈表面缺陷進行分割,可實現完整的缺陷邊緣提取。文獻[11]使用改進的霍夫變換與新的區域劃分法,針對紋理區域與非紋理區域自動分配不同的缺陷檢測方法,對鋁型材料表面缺陷進行檢測。然而,當工件表面缺陷類別多、背景復雜、各類缺陷表征形式不同、尺寸差異大時,缺陷特征很難量化,無法設定固定的規則來捕捉所有的有效特征,此時傳統的機器視覺技術識別精度會大幅下降。
與人工檢測的主觀性和機器視覺檢測的局限性不同,基于深度學習的缺陷檢測具有精度高、性能好、泛化程度高等優點,其可通過神經網絡自主地發現需要提取哪些特征更能適應復雜的檢測背景。因此,近年來,基于深度學習的表面缺陷檢測方法得到了廣泛研究,并逐步應用在產品缺陷檢測領域。YOLO(You Only Look Once)[12-14]系列算法是典型的單階段目標檢測算法,與Faster R-CNN[15]、SSD[16]等目標檢測算法相比,其檢測速度更快,應用范圍更廣。為了適應不同的應用場景,提高不同對象的檢測精度,研究人員陸續提出了各種基于YOLO 系列算法的改進缺陷檢測方法。文獻[17]提出一種基于特征增強YOLO 的表面缺陷檢測算法,通過改進的特征金字塔網絡來增強多尺度檢測層的空間位置相關性,結合深度可分離卷積和密集連接來降低YOLO模型規模。文獻[18]針對復雜的太陽能電池圖像背景、可變的缺陷形態,提出一種基于改進YOLOv5 的太陽能電池表面缺陷檢測方法,將可變形卷積加入CSP 模塊中,引入ECA-Net[19]注意力機制,再增加一個小缺陷預測頭,從而有效完成太陽能電池表面缺陷檢測任務。
然而,本文所研究的液壓閥塊表面缺陷尺寸非常 小,以往的YOLOv3、YOLOv4、YOLOv5 算法對小目標檢測效果較差,目前只有最新的YOLOv7[20]算法在小目標檢測中有較好的性能表現。除此之外,液壓閥塊表面的劃痕與刀紋形狀非常類似,當劃痕與邊緣的對比度較低時,容易出現誤檢、漏檢的情況。因此,針對液壓閥塊表面缺陷的不同特征,本文提出一種基于改進YOLOv7 的液壓閥塊表面微小缺陷檢測算法,主要改進有以下4 個方面:1)在多尺度特征融合模塊后引入CA[21]注意力機制,在增加較少參數的前提下增強對微小缺陷的特征提取能力;2)將多尺度特征融合模塊中的UpSampling 替換為改進的UpC 多支路上采樣結構,通過UpSampling 與反卷積的并行上采樣,在增大特征尺寸的同時豐富微小缺陷的特征信息;3)采用改進 的ELAN(Efficient Layer Aggregation Network)-RepConv 結構代替多尺度特征融合模塊中的ELAN_2 結構,使算法在訓練時能提取到更多的特征信息且不影響推理速度;4)采用K-means++[22]算法對數據集進行聚類,聚類生成的錨框更符合本文所研究的液壓閥塊表面微小缺陷的尺寸特征,從而加快模型的收斂速度并提高微小缺陷的檢測精度。最后通過多個對比實驗與消融實驗來驗證本文算法的有效性。
1 YOLOv7 算法
YOLOv7 有YOLOv7、YOLOv7-X、YOLOv7-W6、YOLOv7-E6、YOLOv7-D6、YOLOv7-E6E 這6 種 變體。其中,YOLOv7 的參數量最少,檢測速度最快,能夠滿足用戶對高實時性檢測的需求。因此,本文選取YOLOv7 作為基礎算法進行改進。YOLOv7 的網絡結構如圖1 所示。由圖1 可知,YOLOv7 的網絡結構由Input、Backbone、Head 這3 個部分組成。將待檢測對象輸入Backbone 中,Backbone 部分在經過4 個CBS(Conv+BN+SiLU)操作后,使用連續的ELAN 結構與DownC 結構完成特征提取與尺寸縮放;在Backbone 部分的最后一個特征層后使用SPPCSPC 結構,增大感受野并優化特征的提取;將SPPCSPC 結構得到的特征層拼接成一個新的特征層,并和從Backbone 部分提取到的2 個特征層一起傳入多尺度特征融合模塊;在多尺度地融合語義信息和空間信息后,輸出3 個不同尺度的目標特征層;將得到的3 個特征層分別通過RepConv 結構進行輔助訓練;通過YOLO Head 中的卷積調整通道數以得到初步的預測結果;對初步的預測結果進行置信度過濾、NMS(Non-Maximum Suppression)等后處理操作,得到最終的輸出結果。

圖1 YOLOv7 網絡結構Fig.1 YOLOv7 network structure
2 改進的YOLOv7 算法
YOLOv7 相較于YOLOv4、YOLOv3 等其他一階段目標檢測算法,對小目標具有更好的檢測效果,但是,其在目標物都很微小的情況下并不能得到理想的檢測結果。因此,針對液壓閥塊表面缺陷尺寸微小、對比度低等特點,本文對YOLOv7 進行改進,改進的YOLOv7 算法網絡結構如圖2 所示。
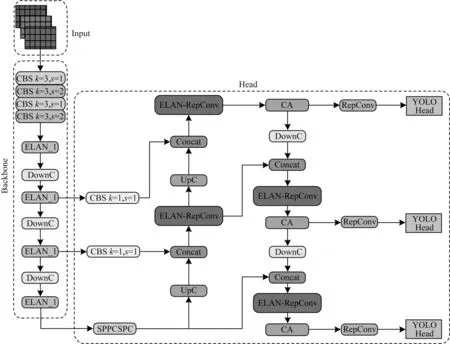
圖2 改進的YOLOv7 網絡結構Fig.2 Improved YOLOv7 network structure
2.1 CA 注意力機制
液壓閥塊的表面缺陷尺寸小,在整個圖像中占有較少的信息量,背景復雜且存在過多干擾信息。為了提高小目標檢測的準確性和減少無關信息的干擾,本文采用注意力機制自適應地聚焦與小目標有關的細節信息,降低對其他信息的關注度。不同于SE(Squeeze-and-Excitation)[23]通道注意力機制只考慮內部通道信息、CBAM(Convolutional Block Attention Module)[24]只考慮局部空間位置范圍內的信息,CA 注意力機制在增加較少計算量的前提下,既考慮到不同通道之間關系的重要性,同時又考慮到空間位置間的長期依賴關系。因此,本文在多尺度特征融合模塊后添加3 個CA 注意力機制來提高模型的檢測精度。CA 注意力機制結構如圖3 所示。為了獲取圖像寬度和高度上的注意力并對精確位置信息進行編碼,CA 注意力機制首先將傳進的輸入特征使用全局平均池化沿水平方向與垂直方向進行特征編碼,獲得在寬度和高度2 個方向上的特征圖;接著將寬度方向特征圖的輸出維數調換后與高度方向特征圖進行拼接,拼接后使用1×1 的卷積將得到的中間特征圖通道數壓縮為C/r(r為縮減因子);隨后使用BN(Batch Normalization)批量歸一化與非線性操作對特征圖進行特征映射,映射后使用1×1 卷積沿著空間維度將特征圖分解成2 個獨立的張量,其中,寬度方向特征圖的輸出維數恢復至輸入狀態;然后利用 Sigmoid 激活函數分別得到2 個方向上的注意力權重;最后在原始特征圖上通過乘法加權計算,得到在寬度和高度方向上帶有注意力權重的特征圖。
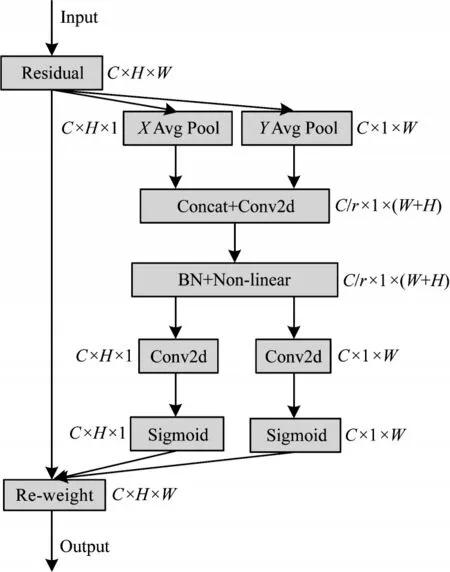
圖3 CA 注意力機制結構Fig.3 CA attention mechanism structure
2.2 改進的UpC 多支路上采樣結構
YOLOv7 使用DownC 結構代替原有的stride 為2 的卷積對特征層進行尺寸減半操作。DownC 結構使 用MaxPooling 和stride 為2 的3×3 卷積對 特征層進行同步下采樣。MaxPooling 考慮到局部區域的最大值信息,卷積操作考慮到局部區域中所有值的信息,因此,結合兩者的特性做同步下采樣并對結果進行特征拼接,可以有效避免特征信息丟失。
參考DownC 結構,本文提出改進的UpC 多支路上采樣結構,如圖4 所示。
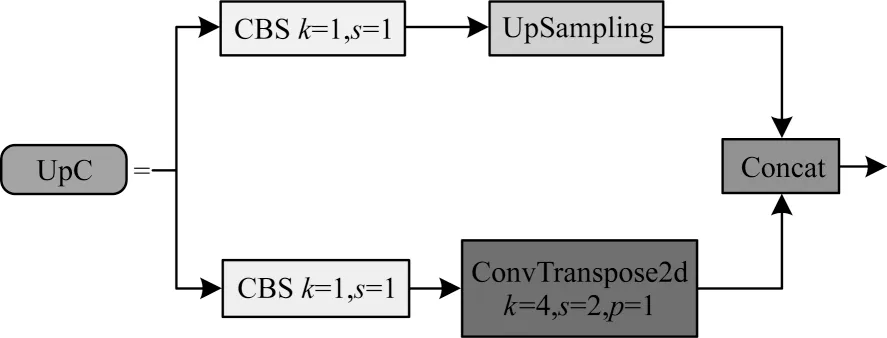
圖4 改進的UpC 多支路上采樣結構Fig.4 Improved UpC multi-branch upsampling structure
2 條支路一開始都使用1×1 卷積進行通道壓縮,減少計算量;然后分別使用UpSampling 與ConvTranspose2d 對特征圖進行上采樣;最后在通道上進行特征圖拼接。其中:UpSampling 通過鄰近點的值進行插值上采樣,沒有參數可以學習;ConvTranspose2d 為卷積的逆過程,在訓練過程中會自動學習最優參數進行上采樣。因此,通過上述2 種方式的結合可以提取到更多的特征信息。反卷積計算公式如下:
其中:sstride為卷積步長;kkernel為卷積核大小;ppadding為邊界填充;sin_size為輸入尺寸;sout_size為輸出尺寸。
反卷積的具體步驟如下:
步驟1在輸入對象的每個元素后根據sstride-1做補0 擴充操作,若sstride為1 就不補0。
步驟2在步驟1 的基礎上按照ppadding再對整體補0。
步驟3將步驟2 所得的結果作為真正的輸入,并使用sstride為1 的卷積對其進行計算,獲得反卷積后的輸出結果。
2.3 改進的ELAN-RepConv 結構
ELAN 結構共有2 條分支,通過2 條分支的多個特征融合,使網絡能夠學習到更多的特征信息。第1 條分支先使用一個1×1 卷積做通道數調整,接著使用多個3×3 卷積做特征提取;第2 條分支使用1×1卷積減少計算量。在2 條分支的特征提取結束后,從第1 條分支引出多個特征圖,與第2 條分支的特征圖拼接在一起得到最后的特征圖。
本文提出的改進ELAN-RepConv 結構是將多尺度特征融合模塊中的ELAN_2 結構中的部分3×3 卷積替換成RepConv 結構。RepConv 結構可以在訓練時通過多分支的特征提取學習到更多特征;在推理時可通過結構重參化將其轉換成卷積核為3×3 的Conv+BN+SiLU+BN 單路結構,此時,ELAN-RepConv結構與原來的ELAN_2 結構基本一致。因此,改進的ELAN-RepConv 結構能夠在不增加過多計算量的前提下進一步提升模型的特征學習能力。改進的ELAN-RepConv 結構如 圖5 所 示。

圖5 改進的ELAN-RepConv 結構Fig.5 Improved ELAN-RepConv structure
2.4 K-means++錨框聚類
YOLOv7 使用的 先驗框 尺寸是通過K-means[25]算法在MS COCO 數據集上聚類而得到的。MS COCO數據集大約包含41%的小目標(area<32×32),其余都是中等目標與大目標。而液壓閥塊的表面缺陷基本都為微小缺陷,面積約占整個圖像的0.05%,沒有大目標的存在,原先設定的先驗框不符合本文研究對象的尺寸特性。因此,需要采用聚類算法針對本文所研究的數據集重新生成更利于模型收斂的先驗框尺寸。聚類算法中最常用的是K-means 算法和K-means++算法,聚類中心初始值設定的好壞對聚類結果有著一定的影響。K-means 算法隨機選取數據集中的K個點作為初始聚類中心,其聚類中心的隨機初始化可能使聚類結果陷入局部最優狀態[26],從而產生錯誤的收斂結果。而K-means++算法的聚類中心是在選擇過程中自動調優的,在K-means 算法的基礎上解決了聚類中心的初始化問題,可以有效地避免局部最優問題。因此,本文采用K-means++算法對數據集進行聚類,聚類結果如圖6 所示(彩色效果見《計算機工程》官網HTML 版)。
3 實驗結果與分析
3.1 實驗數據
本文所研究的液壓閥塊圖像是從工廠實際生產線上所采集到的,共有325 張,圖像大小為2 464×2 056,含有凹坑(pit)缺陷的圖片有226 張,含有劃痕(scratch)缺陷的圖片有99 張。為了避免過擬合并提高網絡的魯棒性,降低各方面外界因素對檢測結果的影響,本文結合離線數據增強與Mosaic 數據增強操作對數據集進行擴充。
考慮到工場實際生產環境中可能會出現光照不均、對比度變化等情況,為了貼合真實場景可能出現的問題,隨機融合上下翻轉、亮度調節、高斯平滑、對比度調整、添加高斯噪聲這5 種數據增強操作將原有的數據集擴充到1 950 張。其中,含有凹坑缺陷的圖片有1 356 張,含有劃痕缺陷的圖片有594 張。擴充完畢后使用LabelImg 圖像標注工具對數據集進行標注,手動框選出圖像中缺陷的具體位置并標注出對應的類別,標注結束后,缺陷的位置與類別信息會自動地保存在相應的PASCAL VOC 格式的xml 文件中。根據缺陷類別將數據集按照8∶2 的比例隨機分為1 560 張圖像(訓練集)和390 張圖像(測試集)。
3.2 評價指標
本次實驗主要研究的是工業生產環境下的表面缺陷,既要滿足實時性又要獲得較好的檢測性能,因此,采用檢測速度FPS(Frames Per Second)與平均精度均值(mean Average Precision,mAP)作為評價指標來比較各算法。FPS 是每秒可檢測完的圖片數量,mAP 是各類缺陷檢測精度的平均值。mAP 的計算公式如式(2)所示:
其中:n為缺陷類別數;AAP為每類缺陷的平均精度值,可由P-R 曲線下的陰影面積獲得。
3.3 實驗結果
本次實驗是在ubuntu20.04 操作系統下基于PyTorch 深度學習框架實現的,GPU 選用顯存大小為24 GB 的NVIDIA GeForce RTX 3090,CPU 配置是8 核 的AMD EPYC 7601,CUDNN 版本為11.1,PyTorch 版本是1.8.0,Python 語言環境是3.8.10。
實驗的超參數配置如下:在模型訓練階段,參數調整使用SGD 優化器,初始學習率設為0.01,動量為0.937,使用warm up 學習率衰減,權重衰減系數設置為0.000 5。此外,批量大小設置為1,總共訓練150 個輪數。本文算法檢測得到的P-R 曲線如圖7 所示。
P-R 曲線的橫軸為召回率,縱軸為精確率。由圖7 可知,各類P-R 曲線下的面積都很大,AP 值較高,即模型的檢測性能較好。其中,pit 缺陷的平均精度值達到0.986,scratch 缺陷的平均精度值達到0.966。
3.4 對比分析與消融實驗
3.4.1 聚類算法對比
本節通過聚類算法的對比實驗,驗證使用K-means++聚類算法生成的先驗框對液壓閥塊表面微小缺陷檢測的有效性。
在相同訓練參數的前提下,將K-means、K-means++算法在實驗數據集上聚類生成的先驗框分別應用在原YOLOv7 算法上,對比結果如表1 所示。

表1 2 種先驗框的平均精度值Table 1 Average precision values of two kinds of prior boxes %
從表1 可知,使用K-means++聚類算法聚類生成的先驗框應用在原YOLOv7 上時平均精度值比K-means 聚類算法高3.5 個百分點,K-means++聚類可提高邊框回歸位置預測的精確度。
3.4.2 注意力機制對比
在多尺度特征融合模塊后引入CBAM、SE 以及CA 這3 種不同的注意力機制,在K-means++算法的基礎上對網絡進行訓練,記錄得到的平均精度值,對比結果如表2 所示。

表2 引入不同注意力機制的平均精度值Table 2 Average precision values of introducing different attention mechanisms %
從表2 可以看出,引入SE 以及CA 注意力機制都可以提高平均精度值,但引入CBAM 注意力機制后平均精度值反而降低。引入CA 注意力機制后平均精度值相較于CBAM 與SE 分別提高2.6 與0.8 個百分點。綜上所述,引入CA 注意力機制對提高小目標檢測精度具有有效性。
3.4.3 YOLOv7 算法與本文算法的對比
從數據集中分別抽出4 張圖片進行對比,標注出真實框的4 張原圖如圖8 所示。使用YOLOv7 與本文算法對這4 張圖片進行檢測,將檢測到的缺陷部分截取出來進行對比,結果如圖9 所示。由圖9 可知,YOLOv7 算法相對于本文算法更容易出現漏檢的情況,且部分缺陷無法被識別或者識別出的置信度值較低,而本文算法能夠盡可能準確地檢測出圖上存在的微小缺陷。
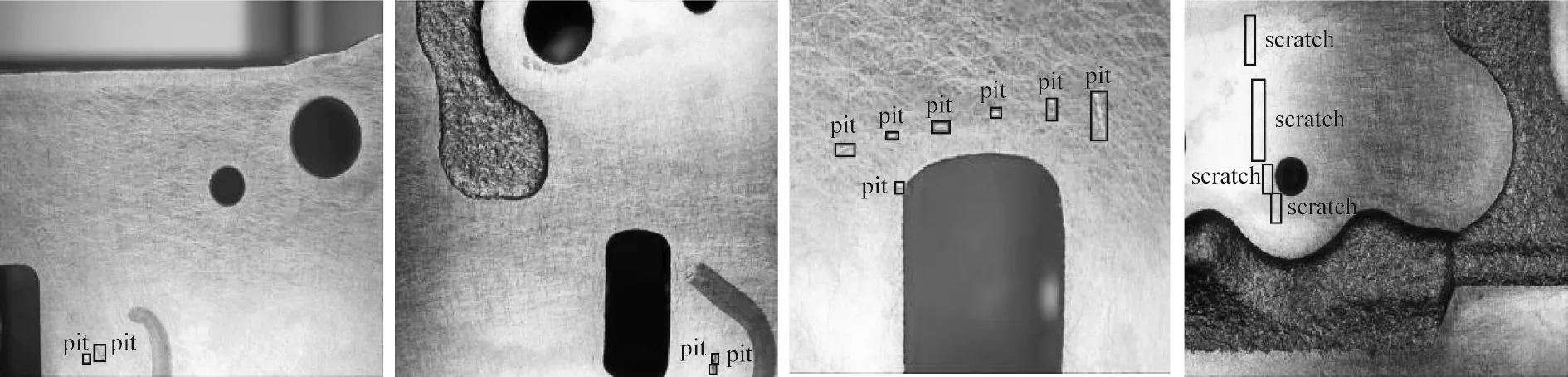
圖8 標注出真實框的原圖Fig.8 Original drawing marked with real frame

圖9 2 種算法的檢測結果對比Fig.9 Comparison of detection results of two algorithms
3.4.4 不同算法的對比
選擇本文改進的YOLOv7 算法與Faster R-CNN、YOLOv4、MobileNetv3-YOLOv4、YOLOv5-X、YOLOv7、YOLOv7-W6、YOLOv7-E6E 這7 種檢測算法進行對比實驗,將測試時的參數量、精確率、召回率、pit 精度值、scratch 精度值、平均精度值以及檢測速度作為評估指標,對比結果如表3 所示。由表3 可知,改進后的YOLOv7 算法在所有算法中檢測精 度最高,比 Faster R-CNN、YOLOv4、YOLOv5-X 以 及MobileNetv3-YOLOv4 這4 種算法的平均精度值至少高出45 個百分點,可見這4 種算法對本文數據集中的微小缺陷檢測能力非常差,漏檢率高。雖然YOLOv7-W6 與YOLOv7-E6E的檢測精度相較于原YOLOv7 算法高,但是參數量非常大,導致檢測速度很低,不符合實際工業應用場景的要求。本文算法檢測速度高于YOLOv7-W6 與YOLOv7-E6E,平均精度值比兩者分別高出4.9 和1.8 個百分點。綜上所述,本文算法能夠在保證高實時性的前提下準確檢測液壓閥塊表面的微小缺陷。

表3 不同算法的結果對比Table 3 Comparison of results of different algorithms
3.4.5 消融實驗
在使用相同訓練參數的前提下,對改進模塊進行消融實驗。逐步加入K-means++錨框聚類算法、CA 注意力機制、改進的UpC 多支路上采樣結構與改進的ELAN-RepConv 結構,通過多個評價指標驗證每一步改進方法對檢測精度提升的有效性。消融實驗結果如表4 所示。由表4 可知,通過添加K-means++聚類算法,平均精度值提高3.5 個百分點,引入CA 注意力機制后又提高1.4 個百分點,添加UpC 多分支上采樣結構,平均精度值進一步提高,最后使用ELAN-RepConv 結構將平均精度值提高到97.6%。可知,與原始YOLOv7 算法相比,改進算法使液壓閥塊表面缺陷檢測的平均精度值提高了8.4 個百分點。

表4 消融實驗結果Table 4 Results of ablation experiment
4 結束語
本文針對液壓閥塊表面缺陷尺寸微小、背景復雜、對比度低的特點,提出一種基于改進YOLOv7 的液壓閥塊表面微小缺陷檢測算法。通過引入CA 注意力機制,同時使用改進的UpC 多支路上采樣結構與改進的ELAN-RepConv 結構,提高對微小缺陷的特征提取能力并減少特征信息丟失。同時,為了增強本文算法的魯棒性,采用離線數據增強融合Mosaic 數據增強以及K-means++錨框聚類算法來提高算法的性能。多個對比實驗和消融實驗結果表明,改進的YOLOv7 目標檢測算法平均精度值達到97.6%,比原YOLOv7 算法提高8.4 個百分點,檢測速度達到55.2 frame/s,符合實際生產需求。下一步將在模型的主干特征提取部分采用Transformer 網絡對算法結構進行改進,在提高檢測速度的前提下進一步提升液壓閥塊表面微小缺陷檢測精度。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產業(2016年3期)2016-05-17 04:32:12
