基于遺傳變鄰域搜索算法的農機跨區調度優化研究
2023-11-23 04:37:28曹光喬任保鑫胡朝中
農業機械學報 2023年10期
曹光喬 馬 斌,2 陳 聰 任保鑫,2 胡朝中
(1.農業農村部南京農業機械化研究所, 南京 210014; 2.中國農業科學院研究生院, 北京 100081)
0 引言
隨著我國新型生產經營主體不斷涌現,規模化經營等現代農業生產模式開始興起,從而帶動對農機社會化服務等需求的增加[1-3]。在我國,大多數地區的耕地呈現碎片化的地理分布,零散農戶仍是農業生產主體。農民的收入很大程度上取決于農產品的產量和市場價格,農機的按需使用能夠幫助農戶提高作物產量和收入[4]。然而,農業機械價格昂貴,小農難以負擔,通常只有擁有較多田地的農戶才會購買農機以滿足作物收獲需求[5]。在農忙時節,采用收獲機跨區作業這種“共享農機”模式是為零散農戶提供按需和低成本服務最有效的方法。
小麥是近一半亞洲地區居民的主要糧食來源,在我國,小麥產量超過全國糧食產量的1/5[6-7]。小麥成熟期因地理位置不同而具有差異,導致小麥收獲機隨作物成熟期自南向北跨區遷徙作業[8],因此農機跨區調度具有很強的時空演化特征和資源約束特征[9-11]。目前農機跨區調度多憑借人為經驗,調度計劃缺乏基于作物成熟期的合理規劃,存在作業區域順序混亂、農機資源配置不合理等問題,造成作業效率低下,貽誤農時,降低了作物的收獲產量和質量[12]。因此,基于“三夏”(夏收、夏種、夏管)時節農機跨區作業需求,研究多約束條件下農機資源配置問題對提高收獲機跨區作業效率、保障作業質量具有重要意義。
近年來,學者從不同角度對農機調度問題進行了大量的研究,他們大都把農機調度問題轉化為帶時間窗的VRP問題或運籌學中的運輸問題[13]。目前研究熱點多集中在單個任務或小區域調度,通常情況下只考慮一個農機供應點或同種類型的農機,在農機調度研究中常用的調度優化目標包括:最大作業收益、最小調度總成本、最小調度路程等[14-16]。農機調度問題屬于NP-hard難題,遇到大型計算實例時,NP-hard問題無法在有效時間內得到解決,常使用啟發式算法進行求解[17-18]。例如文獻[19]將模擬退火算法、遺傳算法和混合Petri網絡模型相結合,提出了一種兩階段的元啟發式算法用于求解甘蔗生產收獲的資源分配調度模型,并獲得了較高的資源利用率。文獻[20]以最小化農機工作時間為目標,提出了一種規劃方法確定生物質收獲和加工操作的順序,解決了多領域生物質順序處理的調度問題。文獻[21]以收獲機服務總面積最大為目標,提出的ALNS元啟發式算法解決了帶時間窗的甘蔗收獲機械的調度問題。文獻[22]分析了農機調度的各種成本,以總調度成本最低建立了重大疫情情況下的農機調度模型,并改進模擬退火算法對模型進行求解。
上述研究都聚焦在區域內的田間路徑優化問題上,在農忙季節,農戶作業需求往往來自不同的省、市、縣,空間跨度從幾十千米到幾百千米不等,多種農機在空間大尺度下的規模化跨區調度更能滿足農業生產需求。在農機跨區調度上,已有一部分研究,例如文獻[23]建立了以調配成本和損失最小為目標的農機跨區作業緊急調配模型,并提出兩種算法求解。文獻[24]通過改進的非支配鄰域搜索算法和禁忌搜索算法解決了農機靜態分區和動態跨區協同調度問題。文獻[25]考慮多庫、多機型和作業時間窗等因素,對農機跨區作業進行研究,提高了服務的準時率和農機的使用率。
通過分析文獻發現,現有的研究很少涉及農機車隊作業,無論是小區域調度或大區域調度,很少考慮到作物的收獲周期。事實上,空間大尺度下的農機跨區作業由若干臺農機組成農機車隊,當多臺農機進行跨區作業時,要綜合考慮調度距離、作物收獲時間窗、農機利用率等因素,由于機械折舊費、路橋費等費用的存在,農機跨區作業的調度距離又會存在合理的范圍[26]。近年來,帶時間窗的車輛路徑問題得到了廣泛的拓展,其中解決綠色車輛路徑問題是減少碳排放,實現“雙碳”目標的重要手段,暫時尚未有研究在農機調度中考慮碳排放成本。如何在制定農機跨區調度計劃時尋求社會經濟效益最大化,同時推動綠色發展是一個值得探討的問題。因此探討多庫、多機型、作業時間窗、空間距離等約束條件下的農機跨區作業資源配置問題,建立考慮碳排放的農機跨區調度模型,對保證糧食生產安全和促進碳中和具有重要意義。
本文針對“三夏”時節農機跨區調度的特點建立以最小調度成本為目標的跨區調度模型,同時考慮經濟成本和環境成本,以期為農機跨區調度的管理決策提供依據。并提出一種遺傳變鄰域搜索算法(Genetic algorithm variable neighborhood search,GAVNS)求解模型,在該算法中,采用自適應機制對鄰域權重進行動態調整,以期減少跨區調度成本。
1 問題描述與模型建立
1.1 問題描述
我國幅員遼闊,小麥作物由南向北依次成熟,這種規律為農機提供了一個連續的作業窗口,但我國的農機資源在地理空間上分布不均,在農忙時節,農戶往往通過租賃外地的收獲機服務來完成收獲任務。通常,少量農戶依賴社會信任和關系網絡,往往基于經驗數據,口頭或電話傳遞需求信息給農機駕駛員以完成小麥的跨區機收作業,但這種模式過于依賴個人關系且調度效率低下,易造成資源和信息的不匹配。在大規模的農機調度中,農機合作社參與的調度模式是“三夏”時節完成小麥跨區機收的主要方式。在收獲機跨區作業過程中,農戶的作業需求往往來自不同的省、市、縣,合作社收到包含農田類型、面積和位置等信息的作業訂單后完成收獲機的派遣。收獲機通過卡車搭載成隊列從合作社運輸至待收區,完成收獲作業,農機跨區調度網絡如圖1所示。
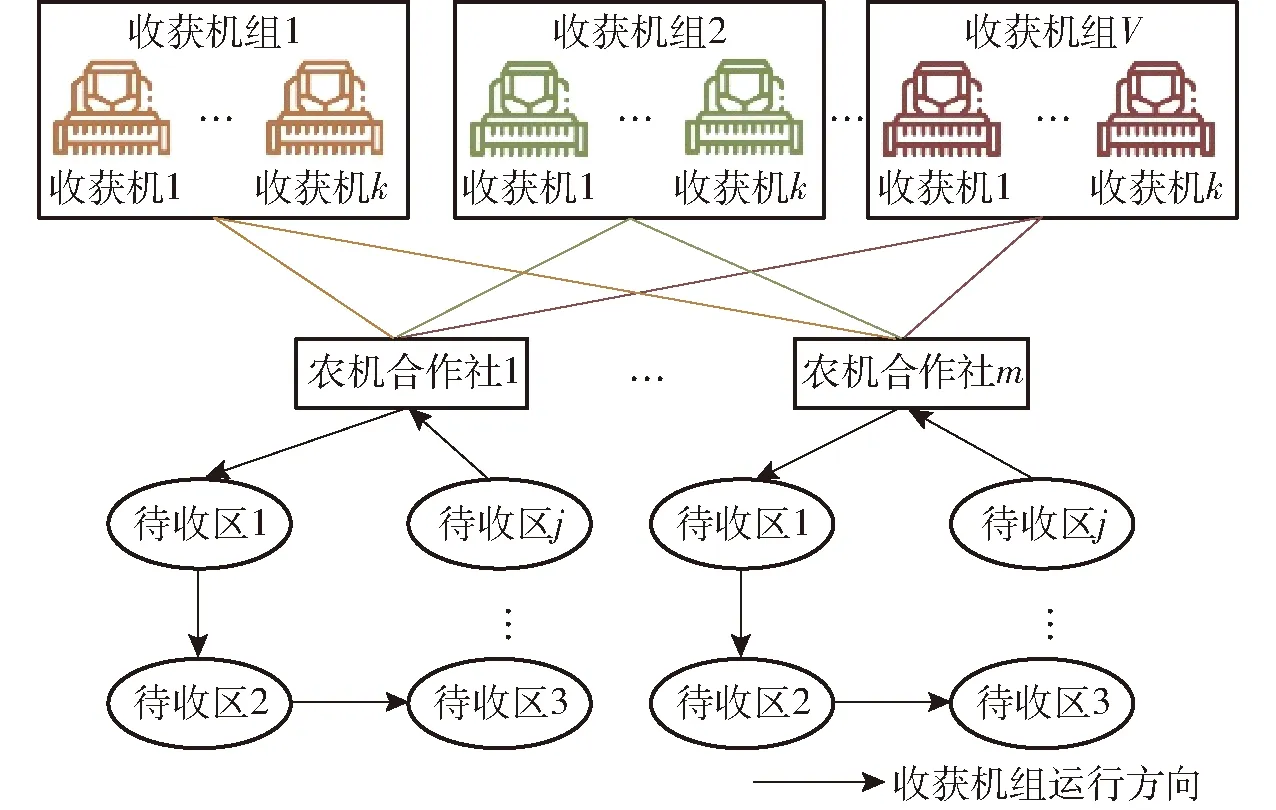
圖1 農機跨區調度網絡圖Fig.1 Network diagram of agricultural machinery cross-region scheduling
該問題考慮多個合作社為多個小麥待收區提供收獲機跨區作業服務,且每個合作社具有多數量、多機型的聯合收獲機。在建立模型之前,作以下假設:一個區縣即為一個待收區;相同型號收獲機的運輸速率和工作效率相同,收獲機從合作社運輸到待收區僅存在公路運輸一種方式,不考慮天氣狀況、道路擁堵情況,無道路容量限制;所有收獲機與其運載卡車之間的比重相同;將收獲機按型號分組,且每組收獲機數量可能不同,分別運往不同區域;每個待收區只能由一個收獲機組服務;農機合作社位置、待收區位置、待收區的待收獲面積已知,一個待收區最多由一個合作社提供服務;收獲機組到達待收區的時間即為開始收獲時間;小麥在收獲時間窗內的品質、產量恒定。
1.2 模型建立
基于以上問題描述,對模型建立中使用的集合、參數和決策變量定義如下:
(1)集合
I:待收區中出發區域集合,I={1,2,…,i}
J:待收區中到達區域集合,J={i+1,i+2,…,i+j}
M:農機合作社集合,M={1,2,…,m},M=I
V:收獲機組集合,V={1,2,…,k}
A:待收區中節點集合,A={(i,j)|i∈I,j∈J}
(2)下標
i:待收區中的出發節點,i∈I
j:待收區中的到達節點,j∈J
k:收獲機組型號,k∈V
(3)參數
qk:k型號收獲機工作效率(hm2/h)
v:每臺收獲機轉運速度(km/h)
ct:每臺收獲機單位距離運輸成本(元/km)
wa:每個操作員時薪(元/h)
eijk:卡車k在路段(i,j)上的碳排放率(kg/km)
twj:完成待收區j收獲所需的工作時間(h)
tij:收獲機從待收區i轉運到待收區j所需時間(h)
tjk:收獲機組k到達待收區j的時間(h)
Sj:待收區j的待收獲面積(hm2)
dij:待收區i和j之間的距離(km)
T:每日可用工作時間(h)
Pc:碳交易價格(元/kg)
N:一個足夠大的正整數
Ej:待收區j小麥開始收獲時間
Lj:待收區j小麥收獲結束時間
α:早到等待成本
β:晚到懲罰成本
(4)決策變量
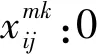
該問題優化目標為調度成本C,包括收獲機運輸成本C1、車輛和人員固定成本C2、時間懲罰成本C3和碳排放成本C4。
收獲機運輸成本與路徑長度呈正相關,運輸成本為
(1)
車輛和人員固定成本主要由駕駛員工資構成,不考慮每臺收獲機在田間轉運的時間損耗,固定成本為
(2)
時間懲罰成本與收獲機到達待收區開始作業時間有關,時間懲罰成本為
(3)
碳排放成本與收獲機轉運途中燃油消耗密切相關,文獻[27]對目前流行的油耗估算模型進行了詳細的對比分析,考慮到收獲機實際轉運過程中的車輛特征、道路特征、車輛運行特征,采用MEET模型估算車輛碳排放量[28]。卡車k在路段(i,j)上的碳排放率(kg/km)為

(4)
其中:ε表示卡車空載且在坡度為0°以速度v行駛時的碳排放率,ω0~ω6為常數,根據卡車類型取值。碳排放率的載重修正因子為
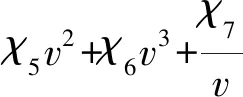
(5)
其中:γ為卡車i在路段(i,j)上的實際載重與其容量的比值,χ0~χ7為常數,根據卡車類型取值。卡車k在路段(i,j)上的碳排放率(kg/km)為
(6)
在轉運過程中收獲機k的碳排放成本C4為
(7)
該問題構建的數學模型,目標函數為
(8)
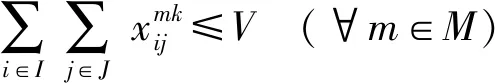
(9)
(10)
(11)
(12)
(13)
(14)
(15)
(16)
(17)
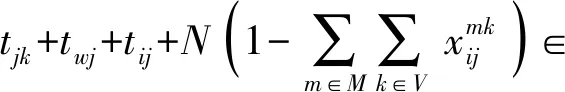
(18)
Ej≤tjk+twj≤Lj(?j∈J)
(19)
(20)
該模型的目標函數(8)表示最小經濟成本與環境成本之和。其中,經濟成本包括運輸成本、固定人力成本和時間懲罰成本,環境成本包括碳排放成本。約束式(9)表示派出的收獲機數小于或等于所有合作社的收獲機總數。約束式(10)表示每個待收區必須且只能被一個收獲機組服務一次,不允許多個收獲機組服務同一個待收區。約束式(11)表示每一個待收區域只能由一個收獲機組服務,不接受多個機組的多次服務。約束式(12)表示從合作社出發的收獲機組在作業完成之后必須返回合作社。約束式(13)表示保證每個收獲機組在完成作業后必須離開該地。約束式(14)表示保證合作社之間不進行收獲機組的轉運。約束式(15)表示禁止收獲機組返回合作社后返回待收區。約束式(16)表示消除區域內環流。約束式(17)表示每日的作業時間和轉運時間之和不超過規定的時間。約束 式(18) 表示收獲機組從待收區i到待收區j的時間窗應滿足的條件。約束式(19)表示收獲機組到達待收區和完成作業需滿足的時間窗。約束式(20)表示決策變量的取值范圍。
2 模型解算
農機跨區調度問題屬于NP-hard難題,采用精確算法求解大規模實例會出現運行時間長,難以求得最優解,現有的研究都傾向于采用智能優化算法求得近似最優解,如遺傳算法、粒子群優化算法、變鄰域搜索算法。遺傳算法能夠在解的空間進行全局搜索,且并行性高,變鄰域搜索算法通過在當前解的鄰域內搜索,可快速找到局部改進解,這種局部搜索能力使算法在每一步的迭代中逐漸改善解的質量,向更優解的方向前進。綜合考慮模型決策變量定義域的規則性,提出遺傳變鄰域搜索算法(GAVNS)對較大規模的農機跨區調度問題進行求解。
2.1 算法流程
GAVNS算法流程如圖2所示。首先生成基于當前參數組合的初始解,再執行選擇、交叉操作,然后用鄰域方法對當前解進行改進,最后,當滿足終止條件時,輸出最優解。GAVNS算法包括染色體編解碼、初始解構造、遺傳操作、隨機擾動、自適應鄰域選擇、種群管理等。
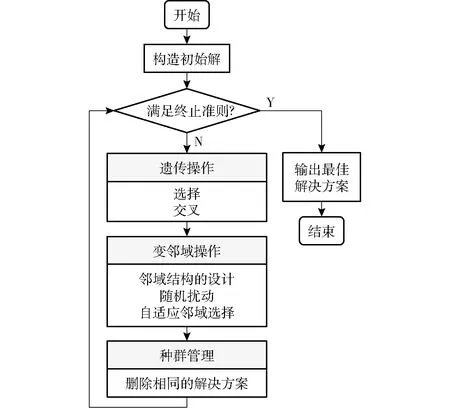
圖2 GAVNS算法流程圖Fig.2 GAVNS algorithm flowchart
2.2 染色體編解碼設計
根據農機合作社提供的跨區服務特點,采用正整數的編碼方式。對染色體的編碼,具體表示為:節點0表示農機合作社,其他節點表示待收區,染色體基因的數量等于待收區數量的3倍。染色體分為3層,在第1層中,所有節點根據待收區編號隨機填充,第2層節點由隨機選擇的k型號收獲機填充,第3層節點對應第2層填充的k型號收獲機的派遣數量。染色體編碼結構如圖3所示。根據第2層的信息,k1型號的收獲機依次為待收區3、2、5、7服務。
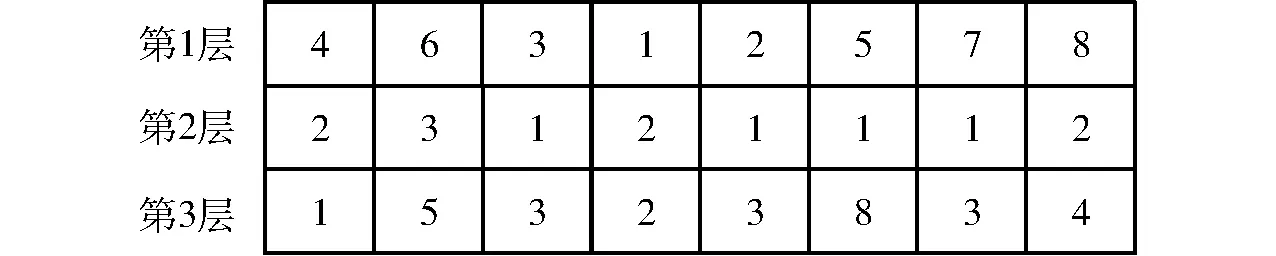
圖3 染色體編碼方式Fig.3 Chromosome encoding method
2.3 初始解構造
為構造初始解,首先將每個待收區j按距離分配到最近的農機合作社m,然后在每個農機合作社覆蓋的待收區內,將所有待收區根據其時間窗的中心值(Ej+Lj)/2進行排序,如果新增加一個待收區后不再滿足模型約束條件,則將該待收區作為調度路徑的首個區域劃入到一條新的調度路徑中,由此得到每個農機合作社的初始調度方案。雖然這種方法得到的目標函數值質量較差,但此種方法存在輕微的約束違規,使算法在較短時間內就能夠完成初始解的構造。
2.4 評價函數
染色體適應度函數可以根據模型中目標函數式進行構造,個體評價函數f(x)為目標函數的倒數,公式為
(21)
式中C(x)——目標函數值
2.5 遺傳操作
2.5.1選擇操作
選擇操作采用精英保留策略與輪盤賭相結合的選擇策略。實現步驟為:先用精英保留策略將每一代種群中一定數量的最優染色體直接保存到下一代,再用輪盤賭的方式對剩下的染色體進行選擇,每條染色體被選中的概率與其適應度成正比。
2.5.2交叉操作
在交叉操作中,順序交叉既能保留原有排列基礎,又能融合不同排列,故選用順序交叉算子。如圖4所示,從種群中選取一對父代個體1、2作為交叉對象,在父代個體1、2上隨機選擇兩個基因交叉點形成交叉子路徑。復制父代2中的交叉子路徑置于父代1的最后面,同理,復制父代1中的交叉子路徑置于父代2的最前面。最后刪除路徑中的重復基因,由此形成兩個新的子代1、2。
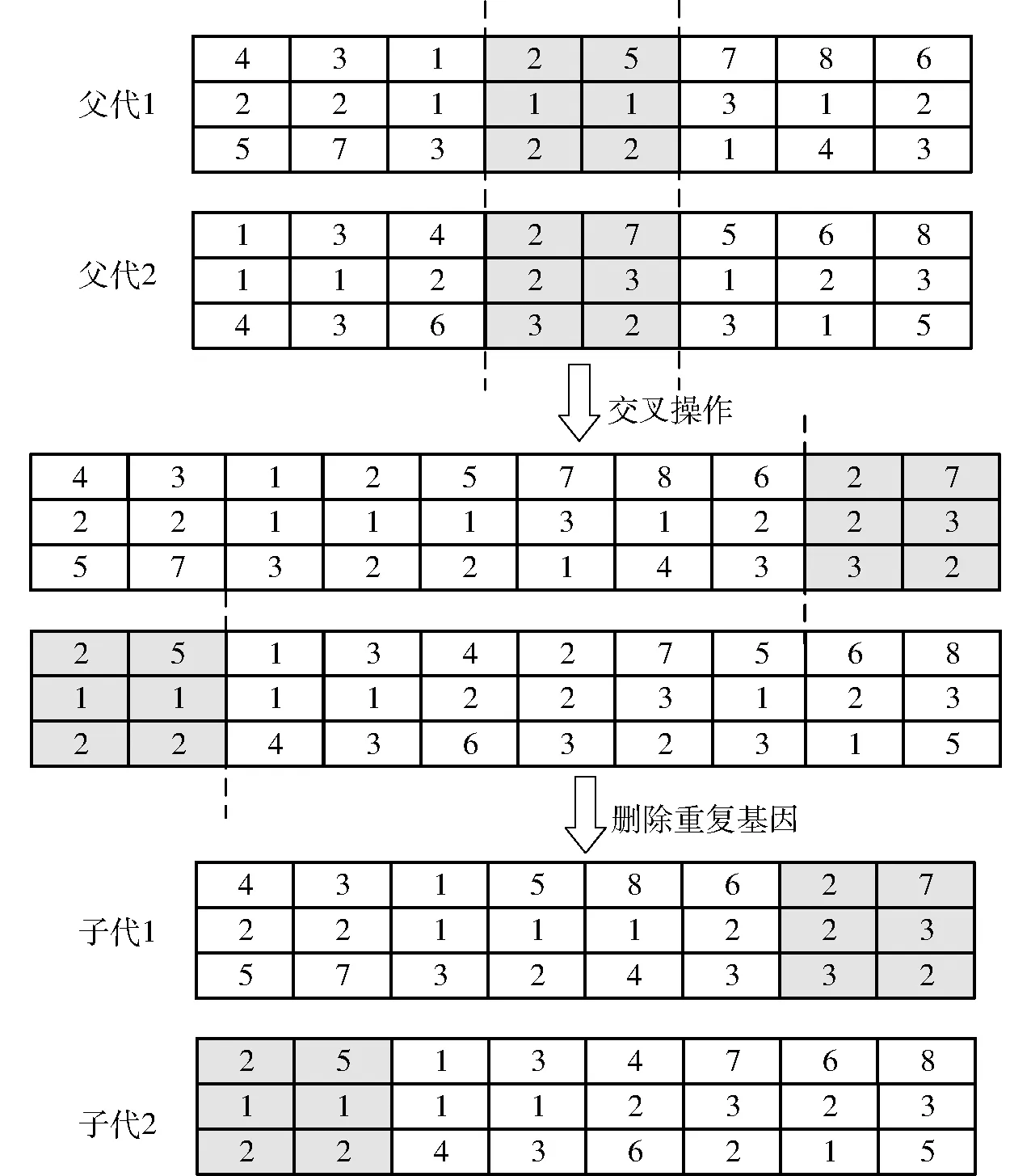
圖4 染色體交叉過程Fig.4 Chromosome crossover process
2.6 變鄰域操作
2.6.1變鄰域結構設計
使用交換、插入、2-Opt、or-Opt鄰域算子進行變鄰域搜索。交換算子是從當前解中隨機選擇兩個不同的節點,交換兩節點的位置。插入算子是從當前解中隨機選擇一個節點,將其插入到新的位置。2-Opt算子是從當前解中隨機選擇兩個不同的節點i、j,并將節點i后的節點順序進行逆轉。or-Opt算子隨機選擇兩個連續的節點,將其逆序插入到隨機選擇的節點j的后面。鄰域結構示意圖如圖5所示。
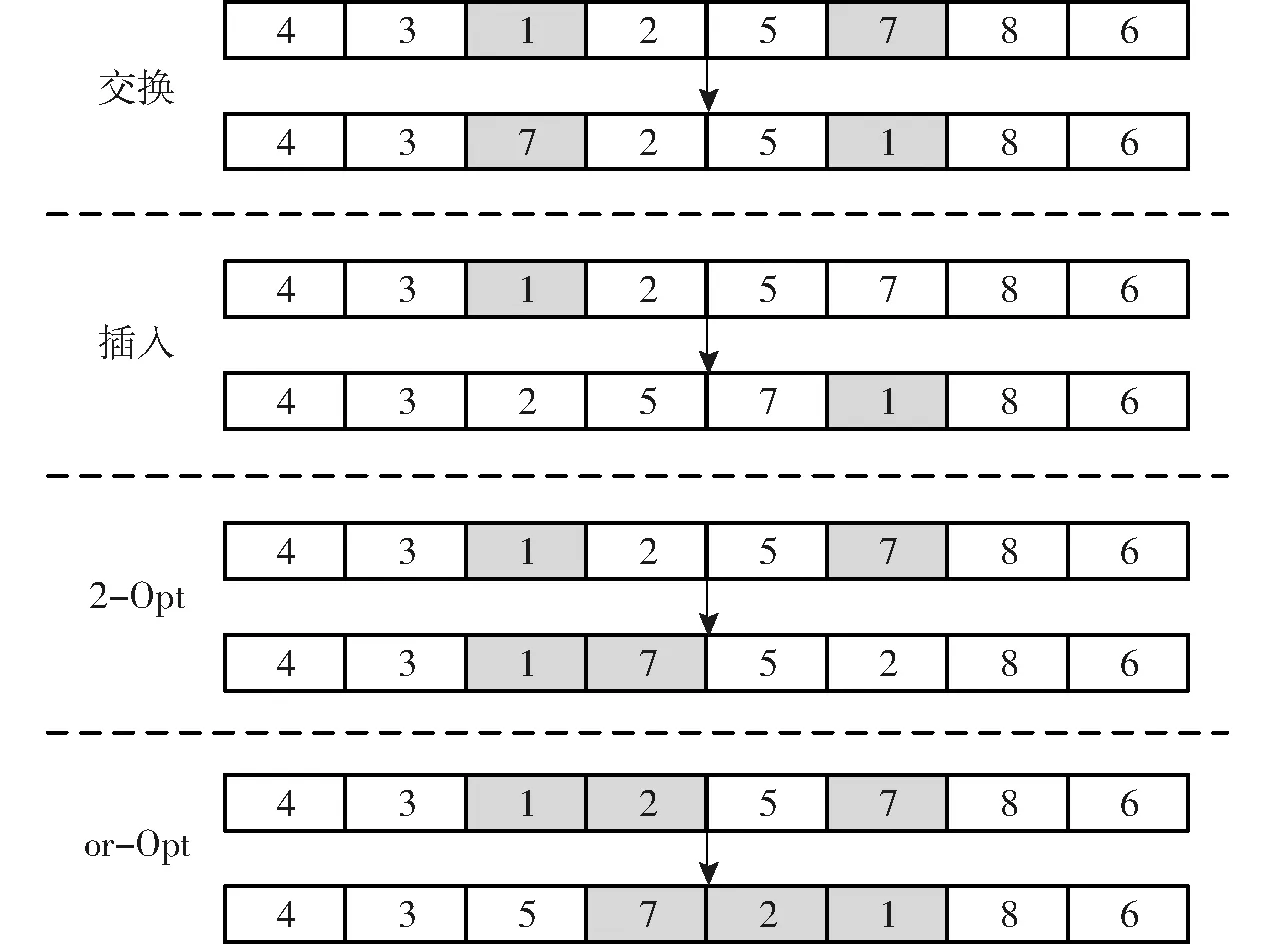
圖5 鄰域結構示意圖Fig.5 Neighborhood structure diagram
2.6.2隨機擾動
首先設定鄰域結構Ni={N1,N2,…,Nn},Nn表示第n個鄰域結構,對種群中的個體c,隨機選擇一個鄰域結構Ni開始擾動,來破壞當前解的局部最優解。在預設的鄰域搜索次數內,嘗試找到改進解c′,則令c=c′;若在該鄰域結構Ni內未找到改進解c′,則隨機選擇下一個鄰域結構Ni進行擾動,直到達到預設的搜索次數。通過增加搜索的多樣性和跳出局部最優解的限制,從而擴展搜索范圍,使目標函數有機會找到更優的解。這種機制能夠有效提升算法的全局搜索能力并改善解的質量。
2.6.3自適應選擇鄰域方法
每次迭代中, 經過計算得到的新解有3種情況, 即新解優化了目標函數并成為新的局部最優解、新解沒有優化但是被接受、新解沒有優化且被舍棄。上述3種情況分別對應不同的分數,每個迭代周期結束后,鄰域方法的權重根據迭代過程中的表現評分變化實現動態變化。首先對每種鄰域方法Ni設置一個初始權重,初始權重均為1。然后,設置權重為1~5之間的整數。在每次搜索中,隨機選擇一種鄰域方法,如果選擇的鄰域方法產生的解比當前最優解更好,則將該鄰域的權重加1,最高可達到5。反之,如果沒有找到更好的解決方案,則將該鄰域方法的權重減1,最低可達到1。這種方法可以動態地調整鄰域結構的權重,使搜索更加靈活和高效。
2.7 種群管理和停止準則
為提高整個種群的質量,每次迭代結束后,用最優個體替換最差個體,以維持種群大小一致性和多樣性,這種機制能避免算法陷入早熟收斂的狀態。在保證種群規模不變的前提下,首先構造新的個體作為初始解,再進行遺傳操作,最后利用自適應變鄰域搜索方法對其進行改進。
當達到最大允許迭代次數時,GAVNS算法停止迭代,求解過程終止。
3 案例分析
3.1 數據來源與收集
黃淮海平原是我國的小麥主要種植區,已有研究表明,每年5月開始,河南南部以及安徽北部等地是小麥聯合收獲機跨區作業的主要輸出地,它們進行跨區作業的范圍從幾十千米到幾百千米不等[8]。數值實驗以河南省駐馬店市為發散中心,選取周邊72個小麥生產區縣,根據實際調查情況和收集的相關實驗數據對模型進行實例分析。各小麥生產區縣的小麥種植面積來源于《中國農村統計年鑒》,假設每個區縣2%的小麥種植面積需要收獲機進行跨區作業服務,各區縣地理位置已知,研究區位和各小麥生產區縣需求信息如圖6和表1所示。
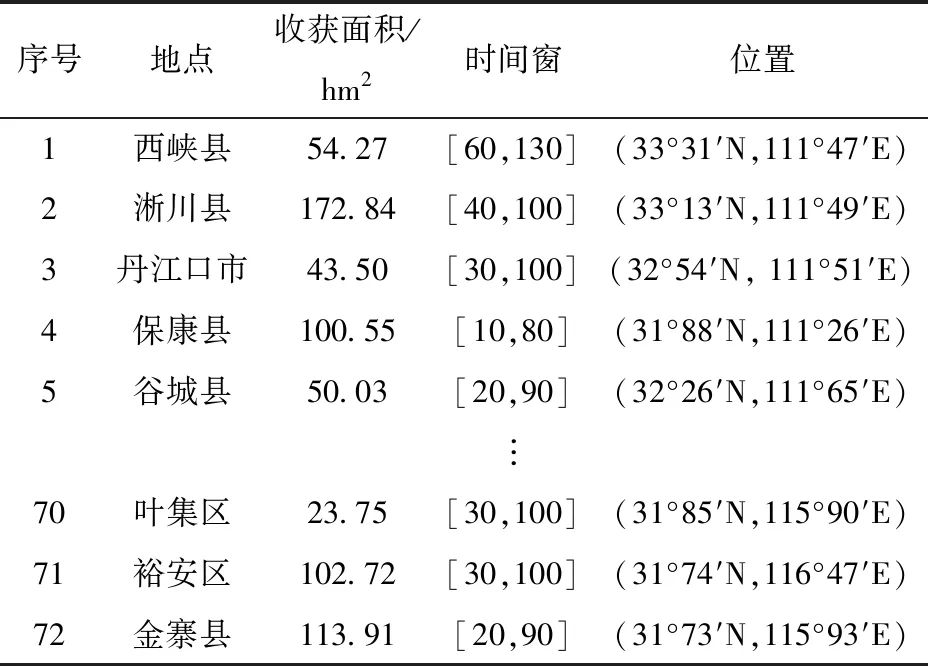
表1 小麥生產區縣需求信息Tab.1 Demand information of wheat production counties
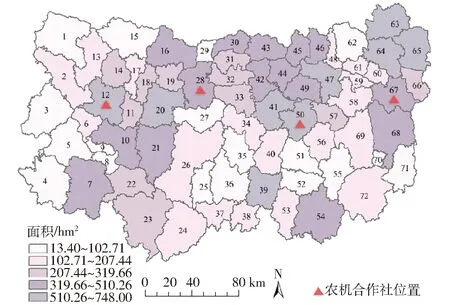
圖6 研究區位Fig.6 Investigation area
假設研究區域共有4個農機合作社,分布在4個不同的區縣,每個區縣有3種型號的收獲機參與跨區作業,整個調度問題將對4個農機合作社周圍的72個區縣提供作業服務,操作員每個工作日的最大工作時間為10 h。農機合作社位置及擁有各型號收獲機數量如表2所示。
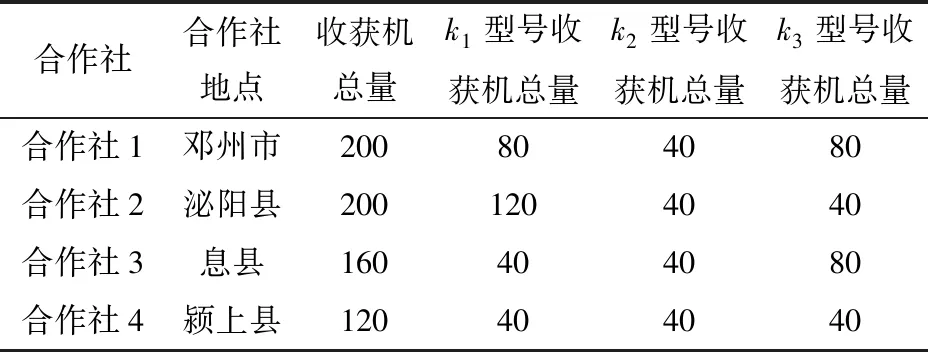
表2 農機合作社位置及擁有各型號收獲機數量Tab.2 Locations of agricultural machinery cooperatives and number of harvesters of each model owned
3.2 模型設置
數值實驗采用Windows 10操作系統,CPU為i7-12700,模擬平臺使用Matlab 2017a。經過反復測試,算法參數設置如下:最大迭代次數(MG)為700、種群數量(NP)為100、交叉概率(Pc)為0.9、最大鄰域搜索次數(MS)為1 000。將相關數據和變量納入構建的模型,對于同一實例,算例運行10次,10個目標值的平均值作為此實例的結果。在“三夏”時節,4個農機合作社分別收集到前期工單,假設每個型號的收獲機都有待派遣的任務。表3給出了農機性能參數及相關運行費用。

表3 農機性能參數及相關運行費用Tab.3 Agricultural machinery performance parameters and associated operating costs
根據我國目前的碳交易價格,假設碳交易價格Pc為0.052 8元/kg,同時,參考文獻[29-30],將計算碳排放成本公式中的參數設置如下:ω0=110、ω1=0、ω2=0、ω3=0.000 375、ω4=8 702、ω5=0、ω6=0,χ0=1.27、χ1=0.061 4、χ2=0、χ3=-0.001 1、χ4=-0.002 35、χ5=0、χ6=0、χ7=-1.33。
3.3 算例計算
3.3.1不同優化算法實驗結果分析
為驗證設計的遺傳變鄰域搜索算法(GAVNS)的有效性,基于相同環境另外編寫求解該模型的遺傳算法(Genetic algorithm, GA)、變鄰域搜索算法(Variable neighborhood search, VNS),將GAVNS算法與GA算法、VNS算法進行對比實驗,得到最終結果如表4所示,其對比迭代曲線如圖7所示。

表4 閉合路徑下3種算法求解結果對比Tab.4 Comparison of results obtained by three algorithms under closed-path mode
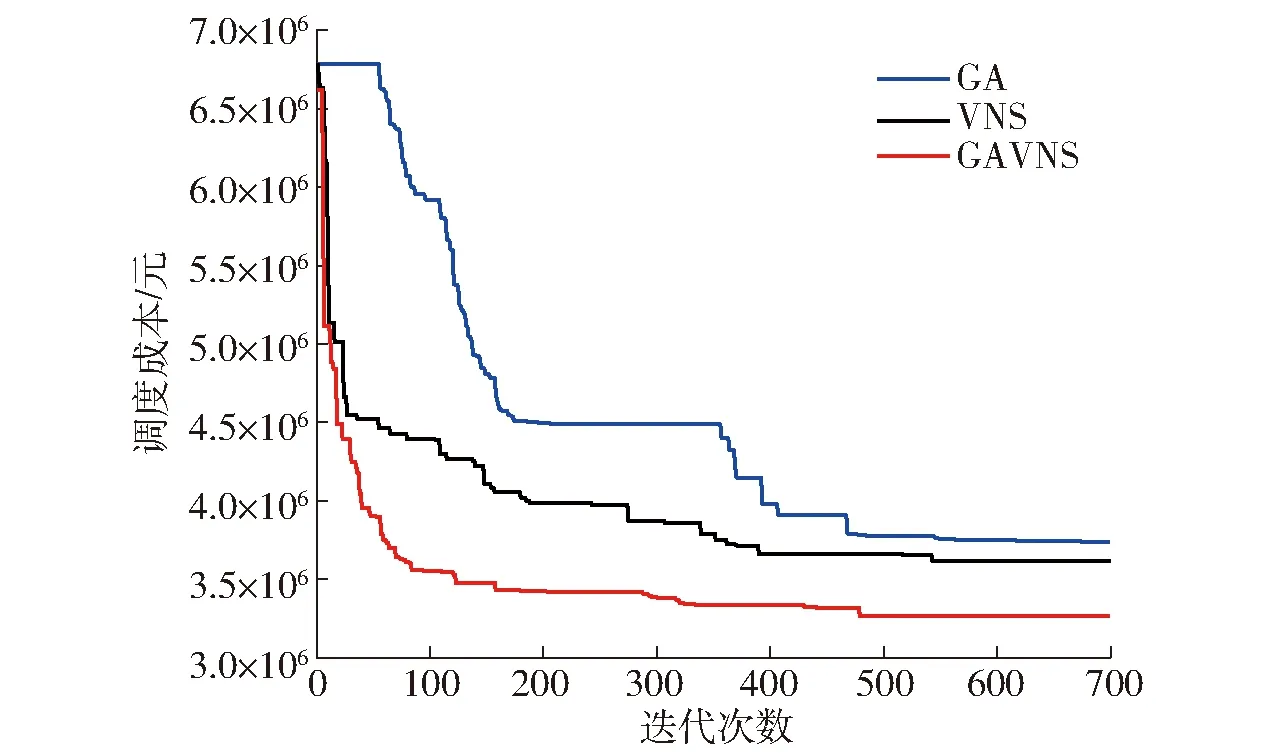
圖7 閉合路徑下3種算法迭代曲線Fig.7 Iteration curves for three algorithms under closed-path mode
從對比結果來看,在調度成本上,GAVNS算法求得的最優值更低,分別比GA算法和VNS算法少16.41%、11.15%,說明GAVNS算法對降低調度成本具有顯著意義。在收獲機使用數和碳排放成本上,GAVNS算法求得的完成作業任務需派出387臺收獲機,收獲機使用數最少,最高減少6.20%;求得的碳排放成本為1.84×105元,優于GA算法和VNS算法,最高節約26.09%,說明GAVNS算法能有效提升每個農機合作社的收獲機使用率,減少車輛碳排放,減少環境污染。從圖7可知,調度成本隨迭代次數的增加而降低,GAVNS算法求解模型的速度快于GA算法和VNS算法,在迭代次數增加至490次左右即可收斂至穩定值,得到最優解的迭代次數更低、收斂速度更快,說明該算法具有較好的收斂性和搜索能力。 GAVNS算法求得的懲罰時間更少,有效降低了麥收懲罰成本,為農忙時節麥收作業預留更多有效作業時間,對保障糧食作物按時收獲具有可行性、合理性和有效性。
3.3.2不同調度模式的實驗結果分析
(1)GAVNS算法在閉合路徑下的調度分析
根據仿真實驗所選區域跨區收獲作業的實際情況,使用建立的調度模型和設計的求解方法進行收獲機跨區調度仿真,在仿真實驗中,所有參與跨區作業的收獲機組的最優調度路徑如圖8所示,最優調度方案如表5所示。

表5 閉合路徑調度模式的最優調度方案Tab.5 Optimal scheduling solution for closed-path scheduling mode

圖8 閉合路徑下的最優調度路徑Fig.8 Optimal scheduling path under closed-path mode
從圖8可知,農機合作社進行跨區作業服務時,優先就近服務,相鄰位置的作業區域由同一個農機合作社提供服務。每個收獲機組的路徑清晰,不同路徑間的迂回和交叉情況較少。
由表5可知,調度成本為3.231 8×106元,收獲機總轉運距離為1.66×105km,4個農機合作社均派出收獲機組進行跨區作業服務,共使用387臺收獲機,每個合作社都有較高的農機利用率。4個農機合作社派出的收獲機組數分別為4、5、6、3,每個機組都進行了多個區縣的跨越,機收的小麥面積分別為3 695.41、4 851.55、6 517.45、3 815.23 hm2,同時每個合作社派出的收獲機組具有一定的相似性,如收獲面積、轉運時間等,說明設計的GAVNS算法能夠根據實際情況為合作社派出的收獲機組規劃合理的作業路線,分配適量的作業任務,保證跨區作業的準時性和均衡性。由式(6)可知,在不考慮收獲機田間作業的油耗下,碳排放成本與轉運距離存在正相關關系,每臺收獲機轉運過程中每行駛1 km平均產生0.28 kg二氧化碳,轉運過程中的燃油消耗會導致一定程度的大氣污染,同時運輸成本和碳排放成本占總調度成本的10.85%,在進行收獲機跨區調度時,對收獲機組的調度不僅要考慮經濟成本,也要兼顧環境成本。
(2)GAVNS算法在開放路徑下的調度分析
在實際的收獲機跨區作業中,在小麥收獲前期,為搶占農時,合作社派出的收獲機往往在完成當前作業后不返回合作社,而是繼續尋找下一個作業點,此時收獲機跨區調度是一個開放的多庫、多機型的車輛路徑問題,在開放路徑中,GAVNS算法的迭代曲線如圖9所示,其最優調度方案如表6所示。
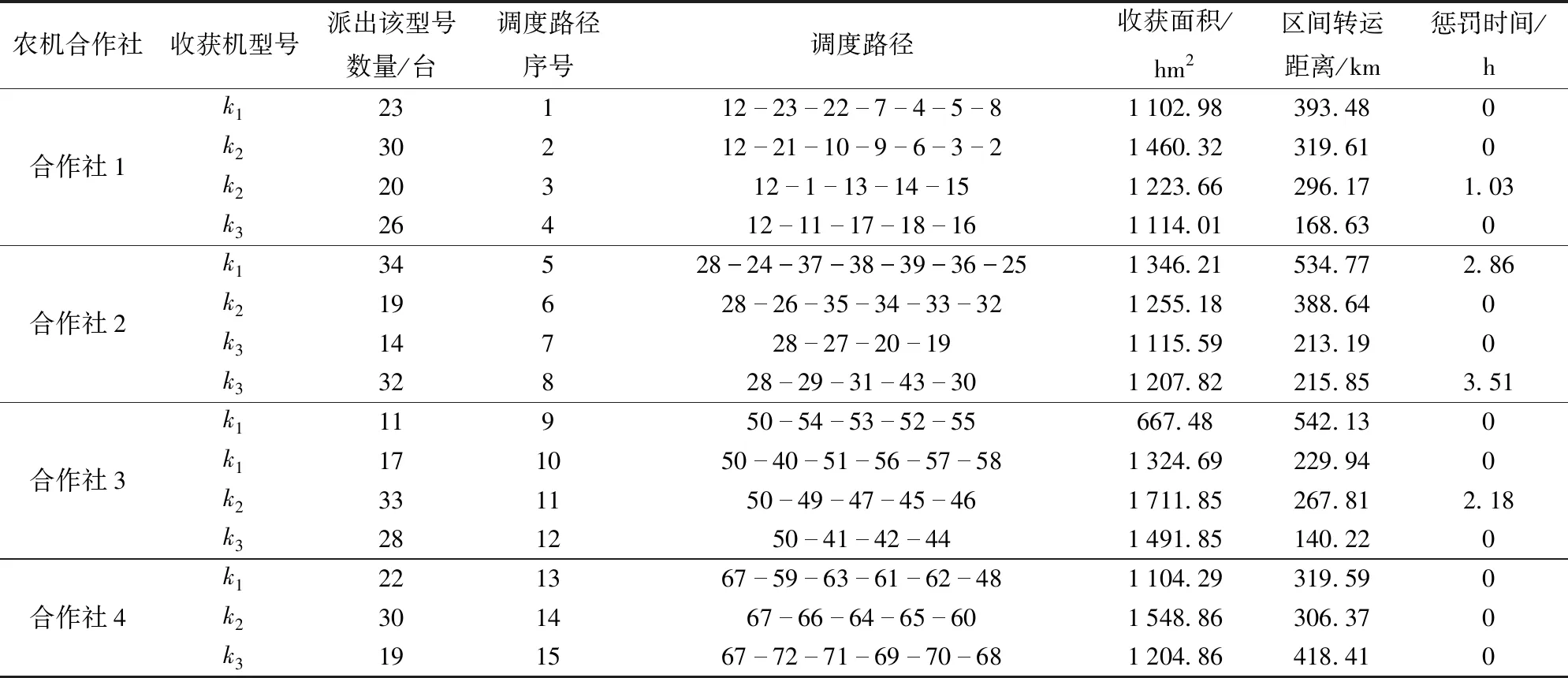
表6 開放路徑調度模式的最優調度方案Tab.6 Optimal scheduling solution for open-path scheduling mode

圖9 開放路徑下GAVNS算法迭代曲線Fig.9 Iteration curves of GAVNS algorithm under open-path mode
由表6可知,在開放路徑下,完成所有收獲任務的調度成本為2.656 3×106元、轉移距離為 1.112×105km, 相比閉合路徑,調度成本、轉移距離分別降低17.76%、33.02%,其主要原因是在開放路徑中,不考慮每個合作社派出的收獲機組的返回路徑,減少了路徑代價,具有較高的經濟性。完成跨區收獲共派出358臺收獲機,派遣的收獲機數比閉合路徑少7.49%,該模式能有效提升收獲機的使用率,同時各收獲機組存在收獲面積和轉運距離的偏差,說明收獲機組的路徑規劃基本遵循了小麥待收區的時間窗、收獲面積的變化規律。在開放路徑下,碳排放成本為1.35×104元,較閉合路徑降低26.63%,兩種調度模式都驗證了碳排放成本與轉運距離存在正相關關系,在轉運距離降低的情況下,碳排放成本也會減少,此種調度模式更有利于降低二氧化碳的排放,減少大氣污染,推動低碳農業的發展。
4 結論
(1)為降低“三夏”時節收獲機跨區調度成本,兼顧環境保護,本文構建合理的多庫、多機型的農機跨區調度模型,設計遺傳變鄰域搜索算法(GAVNS)求解,通過黃淮海平原72個區縣的實例證明模型與算法的有效性。
(2)計算結果表明,GAVNS算法的尋優策略在降低調度成本、轉運距離和懲罰時間方面均具備優勢,GAVNS算法求得的目標函數值較GA算法、VNS算法分別少16.41%、11.15%。對比兩種農機跨區調度模式,開放路徑不考慮收獲機組的返回路徑,農機合作社提供跨區作業服務的效率更高,相比閉合路徑,轉移距離減少33.02%,調度成本減少17.76%,具有更好的經濟性。
猜你喜歡
新作文·小學低年級版(2021年9期)2021-11-27 07:57:46
河南電力(2021年5期)2021-05-29 02:10:00
學生天地(2020年17期)2020-08-25 09:28:54
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
電影(2018年12期)2018-12-23 02:18:48
特別健康(2018年2期)2018-06-29 06:13:42
領導決策信息(2017年10期)2017-05-17 04:49:02
故事大王(2016年7期)2016-09-22 17:30:08
兒童故事畫報(2013年3期)2013-06-24 05:40:30
俄羅斯問題研究(2012年1期)2012-03-25 09:54:48
