云-霧-邊-端協同的農業裝備數字孿生系統研究
2023-11-23 04:37:30郭大方杜岳峰栗曉宇李國潤宋正河
農業機械學報 2023年10期
郭大方 杜岳峰 栗曉宇 李國潤 陳 度 宋正河
(1.中國農業大學工學院, 北京 100083; 2.中國農業大學現代農業裝備優化設計北京市重點實驗室, 北京 100083)
0 引言
數字孿生是多種信息技術加速碰撞、融合而催生的全新理念,能夠打通物理世界與數字空間形成綜合決策,為現實事物提供全生命周期服務[1-3]。數字孿生正逐步成為新一輪科技革命和產業變革中,各行各業特別是制造業加快數字化轉型的重要力量。在農業裝備領域開展數字孿生研究,有利于提高我國農業裝備水平,有助于加速推進農業機械化和農業裝備產業轉型升級。
近年來,科研人員不斷推進智能化設計[4]、智能測控[5-6]、物聯網、大數據[7]和人工智能等數字孿生使能技術在農業裝備領域的落地實用,并積極促進農業裝備與智慧農業、無人農場[8]的建設快速融合發展,國內農業裝備企業的研發模式、研發手段、數據管控和設計制造管理水平也日益提高,已初步具備開展數字孿生研究的必要條件。然而,農業裝備數字孿生仍面臨著不可忽視的挑戰,農業裝備及其作業過程復雜導致模型開發難度大,國產農業裝備電氣化、信息化、智能化總體水平滯后,農機物聯網、大數據中心等新型基礎設施不完善,傳感采集、信息通信、數據存儲等重要環節尚未形成統一標準等,都為農業裝備數字孿生的研究與應用增加了困難。特別是數字孿生具有多元性的特點,需要多維度、小粒度的實時數據作為支撐,對系統架構的合理性要求更加嚴格。在結合數字孿生與農業裝備特點的同時,如何實現系統各要素的有效部署,是農業裝備數字孿生首先要解決的問題。
目前,農業裝備領域內的主流研究仍集中在建模仿真、智能測控和人工智能等關鍵使能技術,極少直接面向數字孿生本身。在檢索到的文獻中,ZHANG等[9]提出大功率拖拉機數字孿生的構建方法和運行機制,開發了用于改善拖拉機機耕作業質量的數字孿生系統,并通過試驗驗證了方法的有效性。NEMTINOV等[10]提出了一種建立復雜農業裝備數字孿生模型的方法,HOODOROZHKOV等[11]基于Matlab可視化編程為輪式拖拉機開發了高精度數字孿生模型,但未能將模型部署至數字孿生系統中。總之,農業裝備數字孿生研究尚處于萌芽階段,農業裝備數字孿生缺乏實用化的系統級解決方案和典型應用案例。然而,在機床[12]、智能汽車[13]、移動通信[14]等領域中,云計算和移動邊緣計算等技術逐漸興起和應用,云-霧-邊-端高效協同工作可以提供超低時延和高帶寬的服務環境和云計算能力,這為農業裝備數字孿生的實用化提供了參考。
針對上述需求與問題,本研究旨在探索農業裝備與數字孿生結合的方式,面向實際落地應用提出云-霧-邊-端協同的農業裝備數字孿生系統架構,并以籽粒直收型玉米聯合收獲機為對象,以降低脫粒過程中的籽粒破碎率為目標,開發一個原型系統,實現模型預測、模型更新、實時監測和優化決策等功能,并在田間作業環境中驗證系統的有效性,為數字孿生或類似的信息物理系統在農業裝備領域中的應用提供參考。
1 系統架構
1.1 數字孿生框架
農業裝備數字孿生旨在為農業裝備建立實時數據驅動的高保真虛擬模型,并利用信息技術的分析處理能力實現虛實同步演化與交互融合,從而洞察農業裝備的屬性、狀態與行為,建立綜合決策能力,解決農業裝備全生命周期中的復雜性和不確定性問題。
根據GRIEVES[15]提出的三維模型和陶飛等[16]提出的五維模型,農業裝備數字孿生系統中包括物理實體、虛擬模型、連接、孿生數據和服務5個核心要素,如圖1所示。其中,物理實體是具備感知與執行功能的農業裝備。虛擬模型是農業裝備的高保真虛擬模型。連接是實現系統各要素之間信息交互的基礎。孿生數據是系統中所有數據的集合,包括實時感知數據、模型仿真數據、虛實融合數據和孿生服務數據等。孿生服務既包括維持系統運行的功能性服務,也包括解決實際應用需求的業務性服務。
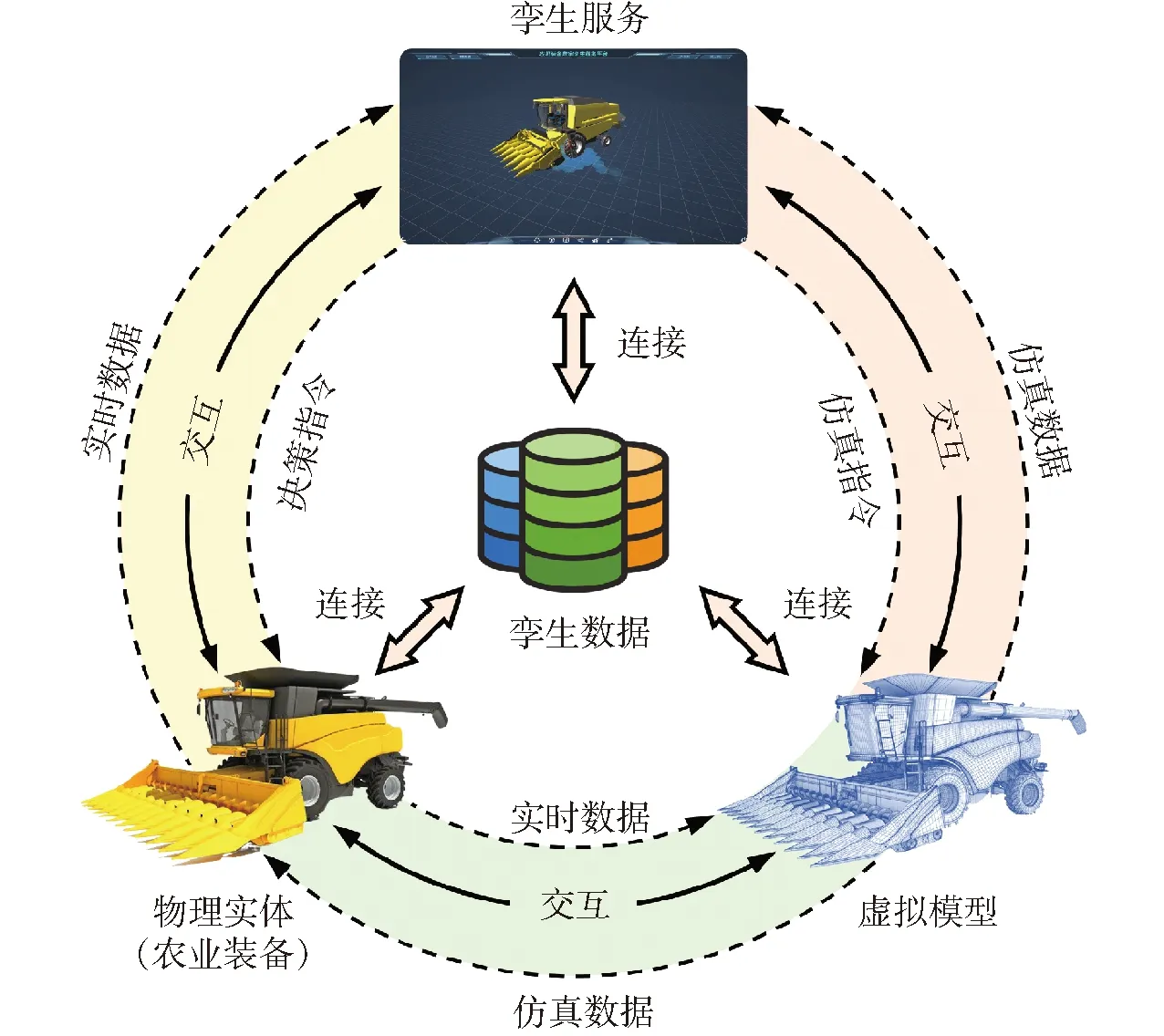
圖1 基于五維模型的農業裝備數字孿生框架Fig.1 Framework of digital twin for agricultural machinery based on 5D model
農業裝備數字孿生系統的運行機制如下:①虛擬模型在數據驅動下精確追蹤和同步農業裝備狀態。②孿生服務評估農業裝備的運行狀態,利用虛擬模型仿真開展優化決策,并交由農業裝備執行。③孿生服務利用數據對自身和虛擬模型進行校驗和更新。④系統運行所積累的模型和數據可以在農業裝備全生命周期中發揮作用。
1.2 云-霧-邊-端架構與機制
研究實踐發現,構建農業裝備數字孿生系統面臨以下問題: ①數字孿生系統需要高效處理海量數據和運行大量復雜的模型和算法。②數字孿生對數據和運算準確性、時效性要求很高。③農業裝備在田間移動作業,必須通過無線通信接入系統。④農業裝備對安全性、穩定性、低時延要求很高。⑤農業生產的季節性強,系統在作業季壓力巨大。
云-端架構物聯網的數據傳輸距離長、系統彈性差,很難滿足上述需求。移動邊緣計算通過在網絡邊緣部署計算和存儲資源,能為移動網絡提供超低時延和高帶寬的服務環境和云計算能力[17-18],為解決上述問題提供了思路。利用云服務器、霧服務器[19]、邊緣設備和農業裝備組成云-霧-邊-端協同的異構計算系統,將瑣碎的低算力數據處理任務和高實時性需求的孿生服務向農業裝備一側傾斜,有利于緩解時延大、穩定性差和安全性低等問題,有助于實現數字孿生系統的快速部署、高效運行、云端協同和有機統一。
圖2展示了云-霧-邊-端協同的農業裝備數字孿生系統的概念原型。其中,“端”指農業裝備;“邊”指安裝在農業裝備上的嵌入式邊緣設備,一方面能夠實現本地數據處理,緩解服務器壓力,另一方面可以部署與測控相關的智能算法,提升農業裝備的能力;“霧”指放置在背靠農場通信基站的機房中的霧服務器,分擔“云”端壓力,實現數據算法、虛擬模型和實時孿生服務的高效運行,同時協同“云”端服務;“云”指部署在遠程機房中的云服務器,具備強大的計算存儲資源和可擴展性,用于部署高算力、準/非實時的孿生服務。具體地,農業裝備與邊緣設備通過現場總線通信,邊緣設備與霧服務器通過4G/5G網絡通信,霧服務器與云服務器通過光纖寬帶網絡通信。
基于云-霧-邊-端架構的農業裝備數字孿生系統的運行機制如圖3所示。首先,農業裝備感知“人-機-物-環境”的運行狀態。邊緣設備處理數據后上傳至霧服務器。霧服務器利用數據和虛擬模型開展實時業務服務,將決策結果下發至邊緣設備與農業裝備。運行過程中,霧服務器在數據的驅動下定時評估虛擬模型并進行小版本的模型參數更新,同時向云服務器反饋運行情況。云服務器依據所有霧服務器的反饋數據對虛擬模型和算法進行大版本的迭代和優化,然后下發并部署至霧服務器。
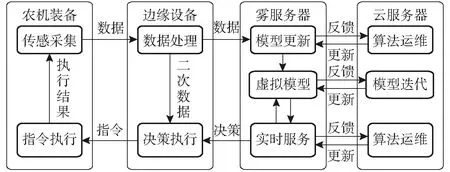
圖3 系統的運行機制Fig.3 Operating mechanism of system
根據上述架構、概念原型和運行機制,圖4給出了一個理想化的農業裝備數字孿生系統在云、霧、邊、端方面的細節,可以作為系統實現的參考。
2 系統實現
大型玉米籽粒直收聯合收獲機融合機、電、液等技術,可以一次完成摘穗、剝皮、脫粒、清選、收集和還田等工序,能夠降低農民勞動強度、提高農業生產率和減少糧食損失,是復雜農業機械的典型代表。因此,以聯合收獲機為對象開發原型系統具有廣泛的參考價值,并且對農業裝備精準化、智能化作業具有重要的意義。
本研究針對玉米聯合收獲機作業過程中籽粒破碎率高這一關系到糧食損失的重要問題,選擇五征4LZ-8型玉米聯合收獲機,參考圖4開發一個簡單的數字孿生原型系統,驗證所提出架構的可行性。
2.1 農業裝備(端)
五征4LZ-8型玉米聯合收獲機的感知與執行功能如圖5所示,檢測了谷物產量Q、發動機負載率η、行駛速度v、脫粒滾筒轉速n、凹板間隙δ和籽粒破碎率Zs總計6個參數[20-21],還開發了v、n和δ的PID閉環控制系統。
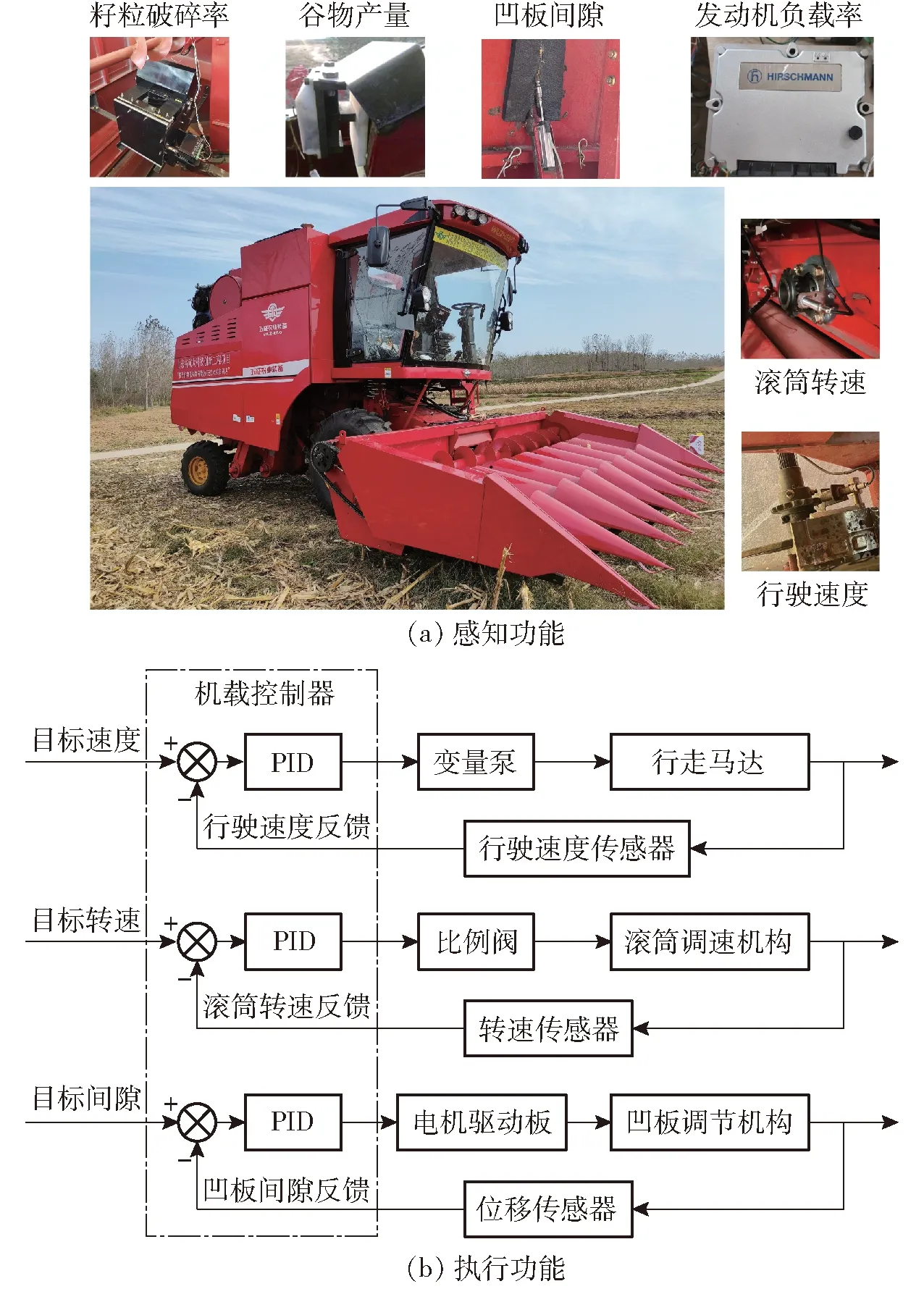
圖5 玉米聯合收獲機的感知與執行功能Fig.5 Sensing and executive function of corn kernel harvester
2.2 邊緣設備(邊)
基于研華UNO-3000G型工控機開發了邊緣設備原型機(圖6)。該邊緣設備安裝在聯合收獲機的駕駛室中。其中,工控機是中央處理單元,通過PCle-CAN卡和4G路由器分別實現總線通信和移動網絡通信。設備能夠實現CAN報文和JSON格式的雙向轉換,并且內置了防脈沖干擾平均值濾波算法

圖6 邊緣設備原型機Fig.6 Prototype of edge device
(1)
式中N——采樣數,N>2,取10
xk——所有采樣數據按照由小到大排列后的第k個值,即x2≤…≤xk≤…≤xN
x′——濾波后數據
2.3 霧服務器(霧)
在配置如表1所示的戴爾T7920型工作站上開發了霧服務器,實際部署有物聯網平臺、虛擬模型、模型更新服務和實時業務服務4部分。

表1 霧服務器配置Tab.1 Configuration of fog server
2.3.1物聯網平臺
物聯網平臺是霧服務器的數據中心和連接中心,集成有通信服務器程序和MySQL&Redis數據庫,實現霧服務器與邊緣設備、云服務器之間的通信,以及數據存儲。為了方便用戶管理接入霧服務器的農業裝備,開發了Web服務器程序和頁面(圖7),包括新增設備、設備管理、數據管理等功能。

圖7 物聯網平臺Web頁面Fig.7 Web page of IoT platform
2.3.2虛擬模型
理論分析、試驗分析和數據分析是構建虛擬模型的3種主要手段。數據模型相較于試驗模型和理論模型[22-23],具有結果準確、時效性高和使用便捷的特點,因此采用基于數據的建模方法。
在聯合收獲機脫粒“作物-機械”系統中,Q、η、v、n和δ是系統輸入,Zs是系統輸出。選用多層感知機(Multilayer perceptron,MLP)神經網絡構建描述輸入量與輸出量間關系的虛擬模型(圖8)

圖8 基于MLP神經網絡的虛擬模型Fig.8 Virtual model based on MLP neural network
(2)
式中X——MLP神經網絡輸入
H(i)——第i個隱藏層輸出,i∈(0,imax]
W(i)——第i個隱藏層權重,i∈(0,imax]
b(i)——第i個隱藏層偏置,i∈(0,imax]
σi——第i個隱藏層激活函數
Y——MLP神經網絡輸出
W(imax+1)——輸出層權重
b(imax+1)——輸出層偏置
在關于構建聯合收獲機神經網絡模型的現有研究[24-25]中,為了避免過擬合,一般采用隱藏層數量小于等于3個和單層神經元數量小于等于10個的“小”模型。但是,數字孿生要求虛擬模型具有通過更新來適應物理實體最新狀態的潛力,同時模型的更新機制可以改善過擬合問題,所以應設法得到一個較“大”的模型。因此,為了使模型盡可能學習到更深層次的規律,采用了遷移學習中的“預訓練-微調”方法[26]。首先,利用來自不同機型、時間、地域的數據得到粗糙的預訓練模型。然后在預訓練模型的基礎上,利用來自目標聯合收獲機的數據繼續做針對性訓練,最終得到一個精度滿足訓練要求且具有更新潛力的模型。
表2展示了訓練數據的來源,其中數據的采樣頻率為0.5 Hz。在數據預處理中,首先采用雙線性插值法填補缺失數據,再通過

表2 訓練數據來源Tab.2 Source of training data
(3)
式中xj,k——第j個輸入特征xj的第k個值
μj——xj中所有數據均值
σj——xj中所有數據標準差
將每個輸入特征標準化,最后分別對預訓練和微調訓練兩個階段的數據集按照7∶3的比例劃分訓練集和驗證集。
籽粒破碎率Zs通常在5%左右。在模型訓練中,若直接采用均方根誤差(RMSE)作為損失函數訓練模型,會導致訓練損失很快收斂到一個很小的范圍,從而影響訓練效果。為了避免這種情況發生,使模型訓練更多地考慮相對誤差,采用先將真實值和預測值各自取對數后再求RMSE的方式計算模型損失,計算式為
(4)
式中yk——模型第k個輸出量真實值
M——模型輸出量個數,取1
L——模型損失值
采用初始學習率為1×10-3,學習倍率為0.9的Adam梯度下降算法[27]訓練模型。經過反復嘗試,訓練得到隱藏層個數imax為5,隱藏層神經元個數依次為10、15、15、10、4的MLP神經網絡模型。
2.3.3模型更新服務
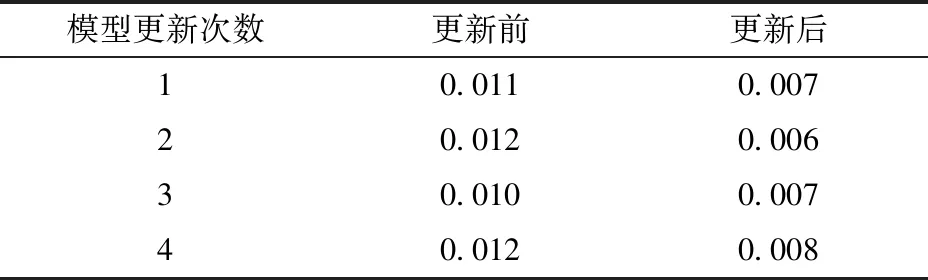
在大部分情況下,一個適應能力強、更新潛力大的虛擬模型無需改動自身結構,僅通過模型更新服務微調即可適應物理實體實際變化。
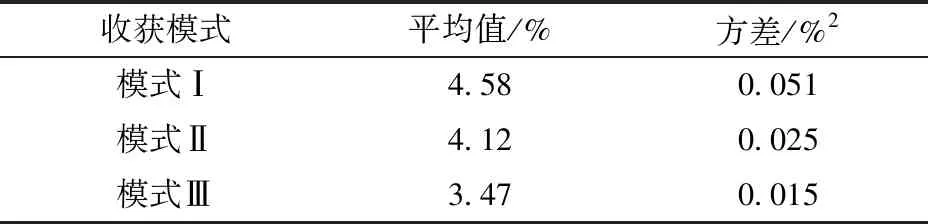
圖9展示了模型更新服務的運行流程。T1為每相鄰兩次模型更新服務的時間間隔。若不考慮外界因素導致突發狀況,“作物-機械”系統的變化是一個持續而緩慢的過程,模型更新服務的工作頻率無需太高,這里取T1為1 200 s。首先,獲取T1內的監測數據,并整理為數據集D。然后,將D作為測試集,評估當前模型在D上的損失L。取閾值Lt為0.01,若L 圖9 模型更新服務的運行流程圖Fig.9 Running flow chart of model update service 2.3.4實時業務服務 為了降低籽粒破碎率,提出基于數字孿生的控制決策優化方法,并開發相應的業務服務。利用實時數據和虛擬模型實現對v、n和δ控制目標值的優化決策。 圖10 優化決策服務流程圖Fig.10 Process of decision-making service 此外,為了直觀地展示機器運行過程,基于Unity3D開發了農業裝備數字孿生服務平臺(圖11)。其中,交互界面分為運行參數監測區域和幾何模型動態展示區域。幾何模型動態展示區域定義了機器尤其是脫粒系統關鍵部件的運動關系,模型的動作和姿態可以在實時數據的驅動下與物理實體保持一致。 圖11 農業裝備數字孿生服務平臺交互界面Fig.11 Interactive interface of digital twin service platform for agricultural machinery 在配置如表3所示的阿里云GPU服務器部署了系統管理平臺和模型迭代服務。 表3 云服務器配置Tab.3 Configuration of cloud server 2.4.1系統管理平臺 系統管理平臺用于實現霧服務器與云服務器間的網絡連接、實時通信、數據存儲和設備管理,為其開發了具有設備管理、設備監測和系統配置等功能的Web頁面,幫助管理人員維持數字孿生系統的正常運轉。 2.4.2模型迭代服務 模型迭代服務是從原理架構的角度上徹底更新虛擬模型,其工作頻率相對模型更新服務更低。通過集成來自所有霧服務器的反饋數據,擴充數據集或優化模型結構開發和訓練新一代數據模型,經過驗證后將新模型部署至霧服務器運行。 當前系統仍處在原型驗證階段,僅有一臺聯合收獲機和霧服務器接入,所以模型迭代服務中僅提供了一個定向部署虛擬模型的接口。數據分析、模型開發、模型訓練等工作需要人工手動進行。待系統進一步完善后,將有更多的聯合收獲機接入系統,屆時將考慮以自動化方式[29]實現模型迭代。 2022年10月在山東省日照市五蓮縣采用五征4LZ-8型玉米聯合收獲機開展田間試驗。采用五點法測量試驗區域內玉米籽粒含水率為29.36%。試驗參照GB/T 21962—2020《玉米收獲機械》中的方法開展,圖12展示了試驗現場具體情況。 圖12 田間試驗現場Fig.12 Field test situation 為了驗證虛擬模型的預測效果,將聯合收獲機設置為手動控制模式,待駕駛員按照正常收獲操作規程作業1 h后,從模型更新記錄中查詢模型更新的具體時刻,導出更新前后的籽粒破碎率真實值和虛擬模型預測值,如圖13所示(時間取負值表示更新前,時間取正值表示更新后)。 圖13 模型預測效果Fig.13 Prediction effects of model 為了評估虛擬模型的準確性與模型更新方法的有效性,利用式(4)計算模型更新前后各200 s內的損失值,如表4所示。 表4 模型損失值Tab.4 Loss of model 試驗結果顯示,在模型更新前,虛擬模型對籽粒破碎率的預測損失值均大于0.01,達到模型更新閾值。在模型更新后,模型預測值損失降低,預測效果明顯改善。試驗結果表明,虛擬模型的更新潛力和適應能力良好,模型更新服務能夠正常觸發和運行,改善了模型的預測效果。 通過與聯合收獲機的其他脫粒控制方法/模式對比,驗證本研究中基于數字孿生的控制決策優化方法,評價該方法對降低籽粒破碎率的有效性。 試驗采用3種模式交替的方式完成同一地塊的玉米籽粒收獲。其中,模式Ⅰ為手動控制模式,由具有作業經驗的駕駛員通過手動調整作業參數完成收獲作業。模式Ⅱ為反饋控制模式,依據籽粒破碎率的反饋值,按照預設控制策略,逐一調節滾筒轉速、凹板間隙和作業速度,保證籽粒破碎率始終滿足預設條件。模式Ⅲ采用本研究中基于數字孿生的控制決策優化方法。每次試驗中,聯合收獲機分別采用3種模式縱向穿越整個地塊各1次,取每次/每種模式試驗中籽粒破碎率傳感器檢測結果的平均值。為了減小隨機誤差,重復對比試驗10次,試驗結果如圖14所示。 圖14 籽粒破碎率試驗結果Fig.14 Test results of broken grain rate 通過圖14可以看出,采用模式Ⅰ收獲作業時,籽粒破碎率開始時較高,然后逐漸下降,最后趨于平穩,這是由于駕駛員逐漸熟悉田間情況并作出了適應性調整。采用模式Ⅱ收獲作業時,籽粒破碎率總體低于模式Ⅰ,且更加平穩。采用模式Ⅲ收獲作業時,籽粒破碎率低于模式Ⅱ,遠低于模式Ⅰ,且比模式Ⅰ和模式Ⅱ的波動更小。 根據試驗結果,計算10次試驗中每種模式下籽粒破碎率平均值和方差如表5所示,可以得出:模式Ⅲ下的籽粒破碎率平均值最小,相較于模式Ⅰ降低24.24%,相較于模式Ⅱ降低15.78%;模式Ⅲ下的籽粒破碎率方差也最小,相較于模式Ⅰ降低0.036,相較于模式Ⅱ降低0.01。因此,基于所開發的數字孿生系統,利用實時數據驅動的虛擬模型優化調控機器的運行參數,能夠穩定地降低玉米聯合收獲機脫粒時籽粒破碎率,有效改善糧食的收獲質量。 表5 籽粒破碎率試驗結果分析Tab.5 Analysis of test results of broken grain rate (1)基于數字孿生五維模型,明確了農業裝備數字孿生的核心要素和運行原理。通過分析數字孿生和農業裝備的特點和需求,融合移動邊緣計算技術,提出一種云-霧-邊-端協同的農業裝備數字孿生系統,并闡明了系統架構、概念原型和運行機制。 (2)以籽粒直收型玉米聯合收獲機為對象,以降低玉米脫粒過程中的籽粒破碎率為目標,通過完善聯合收獲機的感知與執行功能,開發邊緣設備、霧服務器和云服務器,實現了模型預測、模型更新、實時監測和優化決策等功能,構建了數字孿生原型系統。 (3)田間試驗結果表明,模型更新能夠提高模型的適應能力,降低預測誤差,改善預測效果;利用數字孿生模型和遺傳算法,優化聯合收獲機行駛速度、滾筒轉速和凹板間隙的控制決策,能夠降低籽粒破碎率。數字孿生原型系統能夠有效運行,既驗證了所提出系統架構的可行性,又證明了數字孿生有助于改善農業裝備作業質量。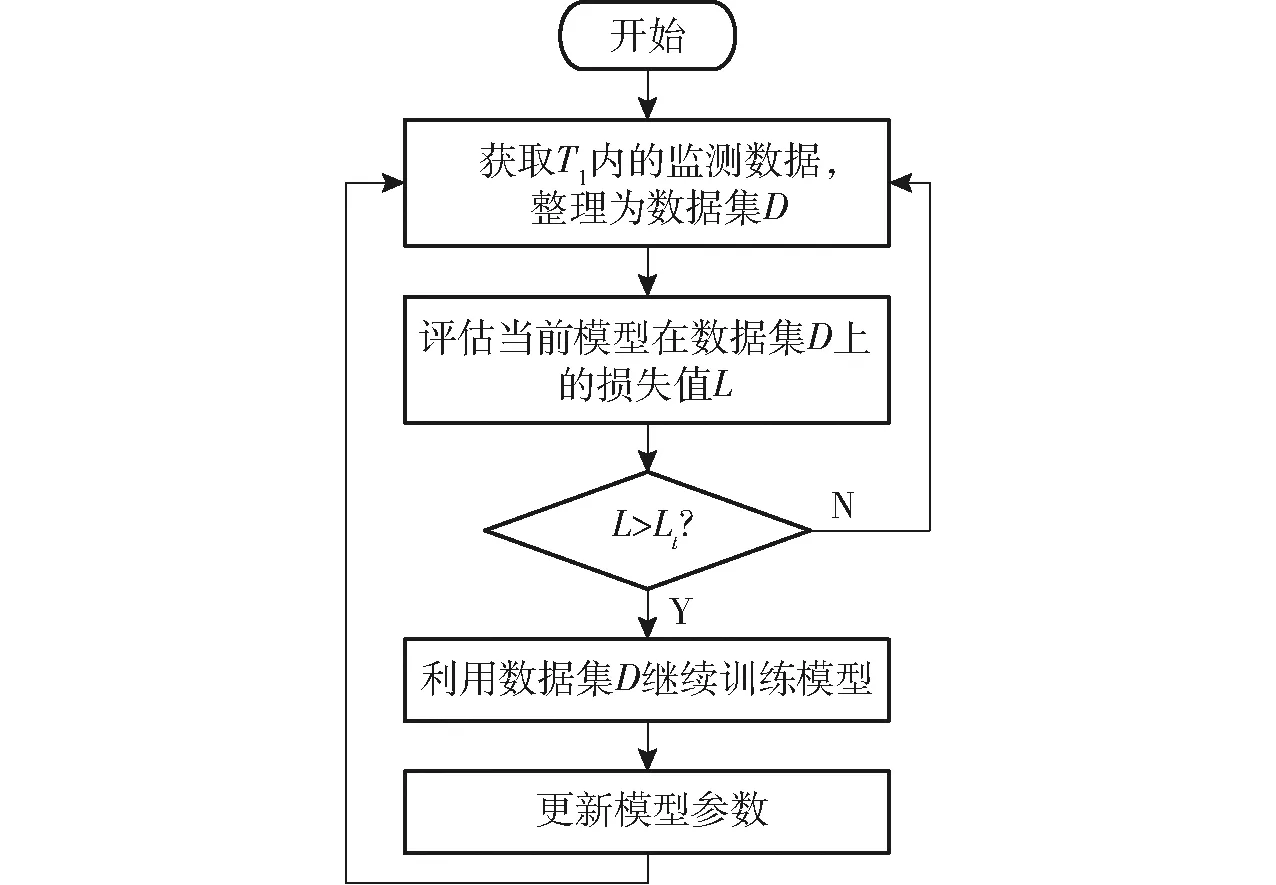
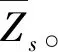


2.4 云服務器(云)

3 試驗驗證

3.1 虛擬模型預測效果驗證

3.2 控制決策優化效果驗證

4 結論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
家庭影院技術(2017年9期)2017-09-26 03:41:45
