基于TB 級數據容量的高并發(fā)高可用緩存設計方案
2023-11-27 09:19:28何川
消費電子 2023年8期
何 川
隨著互聯網越來越普及,我國的網民也不斷增加。2022年6月,我國的互聯網普及率甚至達到了74.4%的高峰,我國的網民數量在10.51億左右。隨著人們的生活質量越來越高,人們的要求也不斷增加,互聯網高并發(fā)場景也越來越多,常見的就有618、雙11等各種網絡購物節(jié),當然還有各種節(jié)假日的火車票網上搶票等,這些都讓互聯網服務器產生了極大的壓力,每逢這些節(jié)點,互聯網峰值流量就會達到甚至超過TB級[1]。如果想要讓用戶擁有更好的使用體驗,就需要讓服務器基于更好的服務,可以從幾個方面一一考量,比如負載均衡、業(yè)務拆分和讓用戶在這些節(jié)點分流等。不過以上這些解決方法并不能解決本質的問題,最重要的是構建一個可以支持大開發(fā)業(yè)務的Web服務器。
一、緩存技術概述
在提升系統相應速度的各項技術中,較為重要與關鍵的一項是緩存,該項技術能將未來可以用到的數據暫時保存下來,從技術架構設計方面來看,緩存這項技術屬于非功能性約束。計算機緩存在運用的時候要求并不高,并非只有系統架構的某個固定位置才能夠使用,而是在多個位置都能被運用。緩存一般分成三大類:一是瀏覽器緩存;二是服務端緩存;三是網絡中的緩存。當緩存技術被運用到系統中的多個部分,系統的整體性能會有極大的提升。當緩存技術被順利運用之后,系統開發(fā)的工作量將會得到降低,也會讓系統的并發(fā)性與吞吐量得到提升。
(一)Nginx緩存
早在0.7.48版本里面,Nginx就已經存在屬于自己的緩存功能,當運用該功能時,其對應的緩存值是Value值。在Nginx里面,其反向代理常會用到proxy_cache相關指令集,此時進行內容緩存時,其設計不但具有可擴展性,更具有穩(wěn)定性。它將過去運用的多線程服務器以及多進程服務器開發(fā)模式徹底拋棄,而是選擇了新的開發(fā)模式,即全異步網絡I/O處理機制和事件驅動架構,這讓整個技術具有了更高的性能[2]。所以,很多知名網站在碰上大流量服務的時候,會更愿意運用Nginx緩存的方式來讓用戶的體驗得以提高。如果出現了低并發(fā)壓力時,運用Nginx緩存能讓使用的所有用戶擁有較快的服務;如果出現了高并發(fā)壓力,要想讓系統的吞吐率得到提升,則可以運用降低部分訪問速度的方式來實現。
(二)Redis緩存
Redis緩存是一種分布式緩存系統,其往往運行的進程是單進程。當運行Redis緩存時,所需要的數據都將會加載于內存里面,所有緩存數據的操作都會在內存里面順利完成。但把數據持久化內存數據導入磁盤這一行為,系統也是支持的。Redis緩存和MySQL等關系型數據庫之間有著特別明顯的區(qū)別,這是因為前者的IO速度會更快,而且其內存使用的效率也更高,除此之外,前者的吞吐量以及響應速度都有較大的提升。在Redis里面,其具有的value擁有結構化的特征,所以其value的數據類型是能夠被自定義的,靈活性較大,所以說其value的特性是極其多樣的。
二、基于TB級數據容量的高并發(fā)高可用緩存設計方案
(一)需求分析
隨著人們的需求越來越高,電商網站秒殺活動也越來越多,僅針對這一場景,該課題選擇從以下幾個方面來分析高并發(fā)Web服務器系統的需求特點。首先分析連接數量方面,當網站服務器屬于高并發(fā)的情況時,其面對的用戶數量是極其龐大的,很多時候用戶數量會達到萬人級別。特別是電商“秒殺”的瞬間,通過數據統計能得出,活動期間的平均并發(fā)訪問量甚至超過了百萬QPS,所以在最初設計系統的時候,就要將高峰期用戶分流、負載均衡以及業(yè)務拆分等措施考慮在內。其次是分析用戶請求的數據類型,從用戶的視角看,其請求的商品頁面的數據其實大部分都是Json數據,這會讓客戶端解析更加便利。由于用戶請求的內容很多都是重復的,且請求的數據類型也并不廣泛,為了讓響應速率得到提升,可以把用戶請求的熱點數據進行緩存。最后分析請求數據量的大小,很多情況下都是請求在客戶端將動態(tài)Json數據進行顯示,此時的數據大多數都是約束到KB級別以下,就算數據達到了MB級別,其通常也是運用數據拆分合并的方式。
(二)架構設計
1.一級緩存架構
要想在分布式系統里面同時將高并發(fā)性能進行滿足,最常運用的方式是將分布式緩存Redis引入進去,在緩存數據庫里存儲熱點數據[3]。具體的過程如下圖1所示,主要分為三個部分:用戶表示、數據源服務以及中間件緩存服務。
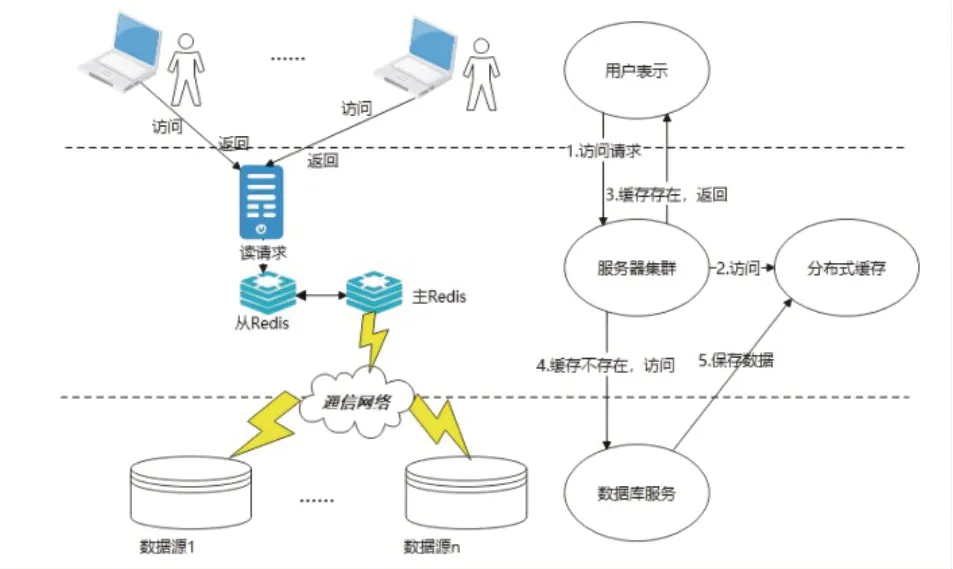
圖1 請求查詢緩存過程

圖2 二級緩存請求過程
當用戶發(fā)送了請求以后,服務器會率先和集中式緩存通信,此時會將用戶請求的相關數據在緩存集群里面進行查找。如果在緩存集群里找到了所需要的數據信息,那么就直接返回,如果沒有在緩存集群里找到所需要的數據信息,則請求源數據庫,且最終獲得的結果要存儲到緩存數據庫里。盡管運用一級緩存的方式能夠讓數據庫的請求壓力得以舒緩,可如果出現了宕機等問題讓Redis集群崩潰,后端數據庫就會因為受到大量請求沖擊而出現崩潰的情況,這時候系統災難的爆發(fā)就在所難免。
2.二級緩存架構
對于上面所提及的一級緩存架構可能會出現的問題,為更有效地解決這些問題,將Ehcache引入Tomcat服務器中,以構建第二級緩存。對于那些熱點商品來說,其被用戶訪問的數量是很大的,假如所有的用戶在獲取相應信息時都要用到Tomcat服務器去連接,大量的訪問量一級并發(fā)量會讓Redis緩存服務器上的負載壓力大幅增加,同時也會出現網絡寬帶受到限制等問題,不僅使得系統的吞吐量下降,也加長了服務端的響應耗時。對于以上所提及的問題,可以通過配置一主多從的服務器集群架構來解決[4],這樣客戶端的請求就能夠均分到不同的服務器節(jié)點上,不會造成同一個服務器節(jié)點出現極大訪問量的情況。除了這種方式外,還有一種更好的方式,即運用服務器本地平臺,把熱點數據存儲成緩存的狀態(tài),這樣就能將遠程緩存的網絡開銷訪問大大減少。
將以上所提及的Redis分布式緩存以及Ehcache二級緩存架構進行結合之后,緩存數據的傳輸開銷以及網絡連接都會得以降低。即使是前者在緩存的過程中有故障發(fā)生,后者也依舊能夠通過本地緩存的方式繼續(xù)提供緩存服務。這不但能將系統發(fā)生緩存穿透以及緩存雪崩情況下的負面影響有所降低,也讓系統的高可用性以及健壯性得到提升。
3.多級緩存架構
當運用多級緩存架構時,也就是將所有的數據緩存在不一樣的系統組件里面,利用組件里緩存的協同合作能讓系統擁有更好的高并發(fā)性以及高可用性。當使用多級緩存時,在最初的緩存查找中,需要運用到Nginx和Lua腳本一起結合的方式在代理服務器里面查找。假如能夠直接在緩存中找到數據,那就直接返回,假如沒有辦法找到數據,則只能先去Tomcat服務器尋找,如果還找不到數據,則要在Redis分布式集群里面尋找[5]。假如通過上面這些尋找途徑還是沒有辦法找到數據,最終的辦法就是請求關系型數據庫,當找到所需要的請求數據后,將其緩存在所有的組件里面。具體的請求過程如下圖3所示。
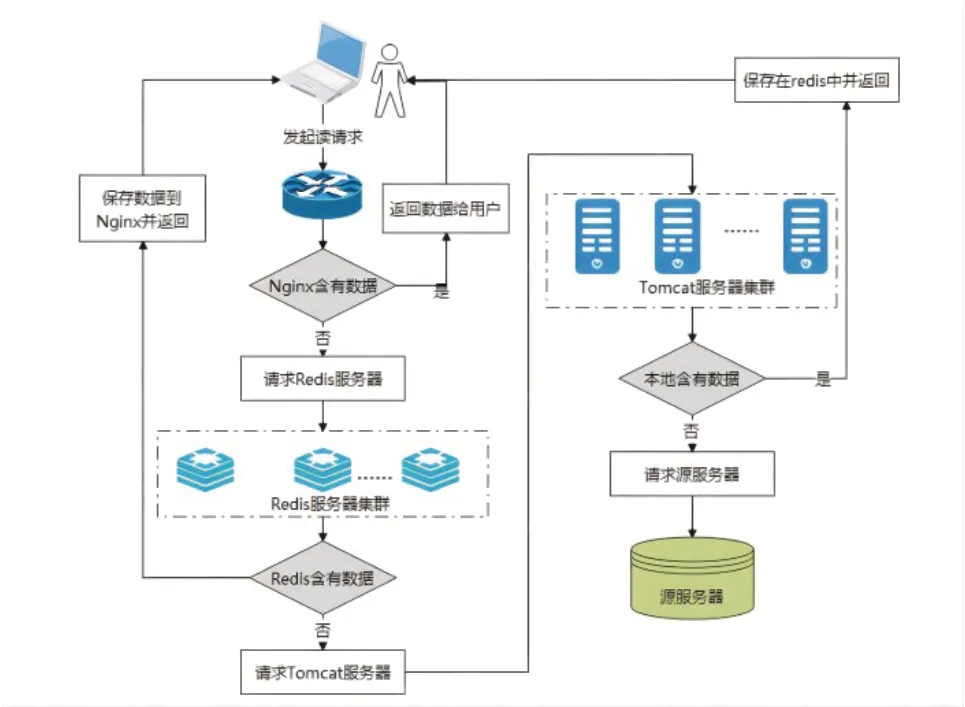
圖3 多級緩存請求過程
4.數據一致性
所謂數據一致性,其實就是在系統運行期間,處于源數據庫里面的數據和緩存里面的數據應當始終保持一致性。因為有緩存這一技術,很多的內容副本在網絡的很多地方都有所分散。假如源服務器里面的內容出現了變化,那些存儲在其他網絡各處的緩存副本將會自動失去效果。確保緩存數據和源數據庫的數據一致,進而確保用戶最終緩存得到的數據是有效的數據。
詳細的流程如下所示:
(1)先將緩存下來的請求數據進行刪除。
(2)等緩存里面的請求數據被徹底刪除后,再將處于源數據庫里面的數據進行自動更新。假如在對源數據庫里面的數據更新失敗了,就需要立即寫請求失敗而返回,這個時候的數據并不會發(fā)生任何變化[6]。這個時候會發(fā)現緩存里面并不存在與之對應的請求數據,那么請求數據會直接從源數據庫里面讀取。同一時間該請求數據也會被放入緩存里面,這時候兩邊的數據是一致的,自然不會有數據一致性的問題發(fā)生。
(3)當源數據庫里面的請求數據得到了更新,就需要對緩存里的數據進行更新。如果對緩存里面的數據進行更新出現了失敗的情況,則立即返回。這時候數據庫里面的數據已經更新過,當讀請求傳送過來之后,在緩存里面并未找到相應的數據時,就要從數據庫里面將對應的數據讀取下來,當然這個請求數據將會直接存入緩存里面。這時候兩邊的數據是一致的,也不會有數據一致性的問題發(fā)生。
(4)等以上的步驟全部成功之后,不管是源數據庫里面的數據還是緩存里面的數據都是一致的,均不會產生數據一致性的問題。
結語
當處于高并發(fā)Web場景時,服務器會有較長的讀請求響應時間,從而導致用戶沒有很好的使用體驗。將分布式緩存引入其中,盡管存在不少優(yōu)勢,可當運用到分布式應用里面時,用戶的所有請求都會讓緩存服務器和應用服務器之間產生網絡連接,因為多種因素的影響,其性能優(yōu)化將會被網絡時間開銷所抵消。不僅如此,還會出現源數據庫和緩存一致性的問題。所以該課題主要是針對單一緩存的局限性來構建多級緩存策略(基于Nginx本地緩存與應用緩存之上的),其目的是讓緩存的性能得到提升,同時減少讀請求響應時間,最終讓用戶得到更好的使用體驗,
猜你喜歡
公民與法治(2022年5期)2022-07-29 00:47:28
教學考試(高考物理)(2021年5期)2021-11-08 10:31:22
中醫(yī)眼耳鼻喉雜志(2021年1期)2021-07-22 07:38:14
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
