基于改進IGGⅢ-ELM法的混凝土壩變形監測數據粗差識別方法
2023-11-28 02:17:40王巖博顧沖時張建中朱明遠
水利水電科技進展 2023年6期
王巖博,顧沖時,石 立,顧 昊,張建中,陸 希,吳 艷,朱明遠
(1.河海大學水災害防御全國重點實驗室,江蘇 南京 210098; 2.河海大學水利水電學院,江蘇 南京 210098; 3.中國電建集團西北勘測設計研究院有限公司,陜西 西安 710065;4.新疆水利水電科學研究院,新疆 烏魯木齊 830049)
混凝土壩是重要的國民基礎設施,然而大型混凝土壩一旦失事,會給下游人民的生命財產帶來巨大損失,并對周邊城市、村莊和生態環境造成毀滅性的災難[1],因此,確保混凝土壩健康長效服役至關重要。混凝土壩在設計施工中存在的不合理因素和在服役期間受到的動靜循環荷載與惡劣環境侵蝕,會導致混凝土性能和大壩結構整體安全性降低,嚴重影響大壩的安全運行[2],需要大壩安全監控系統實時掌握混凝土壩真實的工作性態,及時發現混凝土壩運行過程中的缺陷和隱患,并對病險壩進行除險加固[3-5]。
在獲取混凝土壩安全監測原始數據時,經常會因為讀數錯誤、計算錯誤、檢測儀器故障等產生一定的粗差。粗差的存在嚴重影響了大壩監測數據序列的準確性,只有采取有效措施予以剔除,才能取得真實可靠的大壩安全預測效果。目前應用廣泛的粗差去除方法有過程線法、統計檢驗法和數學模型法[6-7],這些傳統方法存在粗差識別率低,經常出現誤判、漏判等問題,因此,Zhang等[8]基于集成學習算法提出了用實時數據更新的異常指標矩陣來識別大壩監測數據異常值的方法;Song等[9]基于多變量面板數據和K均值聚類算法建立了大壩異常值監測的理論方法;Shao等[10]利用圖像處理技術和布谷鳥搜索算法處理大壩監測數據中的異常值。同時,也有眾多學者將穩健估計理論引入粗差識別模型中,從而增強模型的魯棒性和泛化能力。趙澤鵬等[11]提出了一種基于最小協方差行列式估計的拉依達準則改進算法來識別大壩監測數據中的殘差異常值;Li等[12]提出了結合穩健統計量和置信區間的早期預警模型來識別監測異常值;李興等[13]提出了基于M估計的改進Pauta準則去除粗差算法,有效地解決了異常值誤判的問題;胡德秀等[14]結合穩健估計抵抗粗差能力強和極限學習機(extreme learning machine,ELM)能夠處理非線性問題的優勢,建立了基于M-ELM的大壩安全監控模型。與傳統方法相比,這些方法能夠較好地解決大壩變形數據中的異常值問題,但當存在連續偏離正常值或低偏差度的監測序列時,仍存在誤判漏判現象,導致可利用信息在穩健估計中不能得到充分利用。這一現象需要進一步研究,以提高對異常數據的識別能力。
目前傳統的大壩安全監控模型有數理統計模型、確定性模型和混合模型。葡萄牙、意大利等國家早在20世紀50年代就開始采用統計回歸法建立大壩變形監控模型[15-16]。我國大壩安全監控模型起步相對較晚,20世紀80年代中期吳中如[17]采用逐步回歸、加權回歸等數理統計方法,建立了實測數據與效應量之間的統計模型,并成功地應用于實際工程中。近年來,隨著計算機、大數據和人工智能的發展,隨機森林算法、神經網絡、粒子群算法等智能算法相繼被引入大壩安全監控領域。Huang等[18]首次將核偏最小二乘法引入超高壩的安全監測中;Xu[19]構建了基于徑向基函數神經網絡的大壩變形監測模型;Gu等[20]基于優化隨機森林方法建立了混凝土壩監測因子挖掘模型;Chen等[21]基于狄利克雷過程-高斯混合模型聚類算法提出了一種考慮時空分異的大壩綜合位移預測模型。這些智能算法能夠更好地解決監控模型中復雜的非線性問題和眾多的不確定因素,提高大壩安全監控模型的魯棒性和泛化能力,進而提高大壩安全監控的預測精度。
選權迭代法中的IGGⅢ法是穩健估計中最常用的方法,其初值的選取一般采用最小二乘法。然而,IGGⅢ權函數的一階導數存在不光滑的“尖點”,導致其附近范圍內的信息不能被充分準確地利用,對于小偏差異常值易造成數據誤判漏判的現象。因此,本文結合IGGⅢ與ELM方法進行混凝土壩變形監測數據的粗差識別與回歸分析,采用包含兩個調和系數的四段權函數對IGGⅢ-ELM進行改進(以下簡稱“改進IGGⅢ-ELM法”),并結合工程案例討論該方法在粗差識別和回歸預測中的效果,以期更好地解決監測模型中復雜的非線性問題和眾多的不確定因素,提高大壩安全監測模型的魯棒性和泛化能力,進而提高大壩安全監測的預測精度。
1 改進IGGⅢ-ELM法
1.1 IGGⅢ-ELM法
ELM是一種簡單高效的單隱含層前饋神經網絡算法,相比于傳統的神經網絡算法具有學習速度快、泛化能力強、預測精度高等優點[22-23]。神經網絡隱含層節點輸出權重[14]為
(1)
式中:H為隱含層輸出矩陣;B為隱含層的隨機偏置矩陣,B=(b1,b2,…,bl)T;T為混凝土壩的變形實測值矩陣。

(2)
穩健估計中的選權迭代法是根據殘差大小確定權因子,其中最有效的方案是利用IGGⅢ法逐步降低異常值的權重,達到準確識別粗差的目的。具體公式為
(3)

表1 IGGⅢ法權重處理方法
1.2 IGGⅢ-ELM法的改進
穩健估計是一個保留有效數據信息、削弱可用數據信息、剔除干擾數據信息的反復迭代過程。IGGⅢ權函數的一階導數在k1處存在不光滑的“尖點”,使得k1附近的數據信息不能得到充分利用,易出現誤判漏判的情況。因此,本文采用包含兩個調和系數的四段權函數一階導數來替代式(3):
(4)
改進IGGⅢ的權函數如圖1所示。
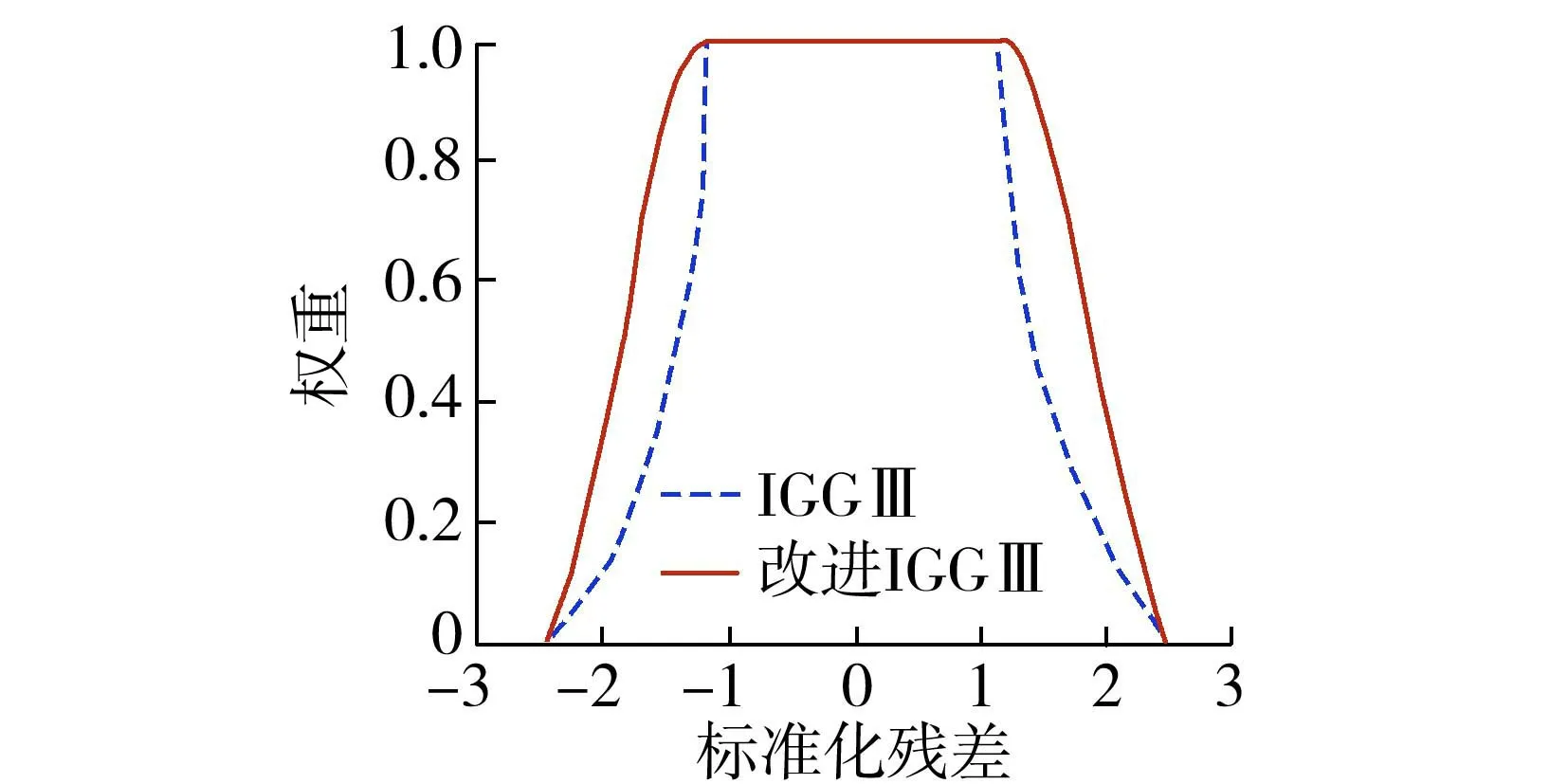
圖1 IGGⅢ及改進方案的權函數
1.3 增量ELM法確定隱含層節點數
在ELM中,隱含層節點數是影響網絡泛化能力的一個重要參數,本文采取增量ELM法確定隱含層的節點個數。該方法的原理是初始化一個較小的ELM網絡結構,逐漸增加隱含層的節點個數,使其結果達到期望精度為止。具體步驟如下:
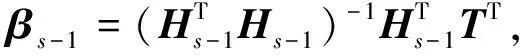
由于(HTsHs)-1是對稱的,因此有
(5)

因此有
(6)
解得:
(7)
因此可得:
(8)
令Ds=(M,N)T,把式(7)代入式(8)可以計算M和N,即可算得βs。
1.4 大壩監測數據中剔除粗差的具體步驟
對于給定的數據擬合段N,初始隱含層節點個數為s,最大隱含層節點數為smax,期望精度為ε。
步驟1在ELM網絡結構中隨機生成輸入大壩環境量因子的權重矩陣ω和偏置矩陣B(i=1,2,…,s)。
步驟2令s=1,計算隱含層輸出矩陣H0和混凝土壩擬合效應量因子權重β0,并計算網絡學習精度es=e0。
步驟3當s


步驟7輸出混凝土壩在連續時間序列上的監測變形權重Pi,Pi為0的樣本序列判定為粗差,予以剔除。
改進IGGⅢ-ELM法粗差識別流程如圖2所示。
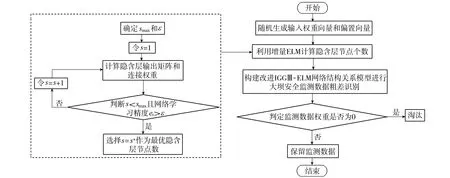
圖2 改進IGGⅢ-ELM法粗差識別流程
2 工程案例
2.1 工程概況
某水電站是雅礱江干流梯級滾動開發的龍頭水庫電站,水庫正常蓄水位1880m,主要任務是發電,兼有防洪、攔沙作用。該水電站的主要建筑物為混凝土雙曲拱壩,壩頂高程1885m,最大壩高305m。本文選取電站運行期2016年9月1日至2018年5月19日的位移監測數據,分析并驗證所用方法的準確性和適用性。圖3為該水電站雙曲拱壩的三維模型。

圖3 雙曲拱壩的三維模型
2.2 模型影響因子的選取及數據集的劃分
在混凝土壩運行過程中,大壩會受到水壓力、揚壓力、泥沙壓力和溫度等荷載的共同作用,選取水壓分量δH、溫度分量δT、時效分量δθ為自變量,大壩變形的位移δ為因變量,利用ELM建立自變量與因變量間的非線性映射,能夠較好地構建大壩變形位移的預測模型,其表達式為
δ=δH+δT+δθ
(9)

拱冠梁的監測數據是饋控大壩變形安全的關鍵性數據,因此選取13號壩段壩中監測點PL13-3作為研究對象,將其徑向位移監測數據劃分為擬合段(用于模型擬合的數據樣本)和驗證段(用于驗證模型泛化能力的數據樣本),擬合段為2016年9月1日至2018年3月22日(共計522個數據樣本),驗證段為2018年3月23日至2018年5月19日(共計58個數據樣本)。
為了檢驗改進IGGⅢ-ELM法識別粗差的效果,將震蕩、臺坎、突跳、臺階4種類型及偏差量較小的粗差引入到測點PL13-3中(粗差類型分別計為①、②、③、④、⑤),測點的位移過程線見圖4。
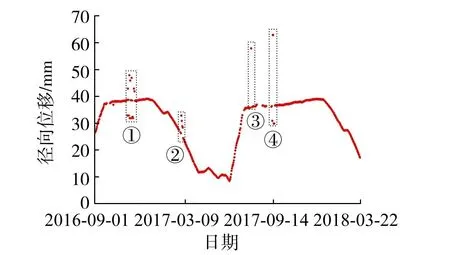
圖4 PL13-3測點加入粗差的位移過程
首先在ELM網絡結構中隨機產生權重ωi和bi,將隱含層節點數初始值取為1,將擬合段數據按式(5)處理后輸入該網絡結構。其次不斷增加隱含層節點數s,當s=42時,滿足所需的學習精度,因此選定隱含層節點數為42個。取δ=0.001,利用改進IGGⅢ-ELM法進行選權迭代,計算每個擬合段數據的權重。圖4中所插入粗差的初次迭代權重如表2所示,最終迭代權重均降為0,根據最終迭代權重可識別出擬合段所有的異常值數據。
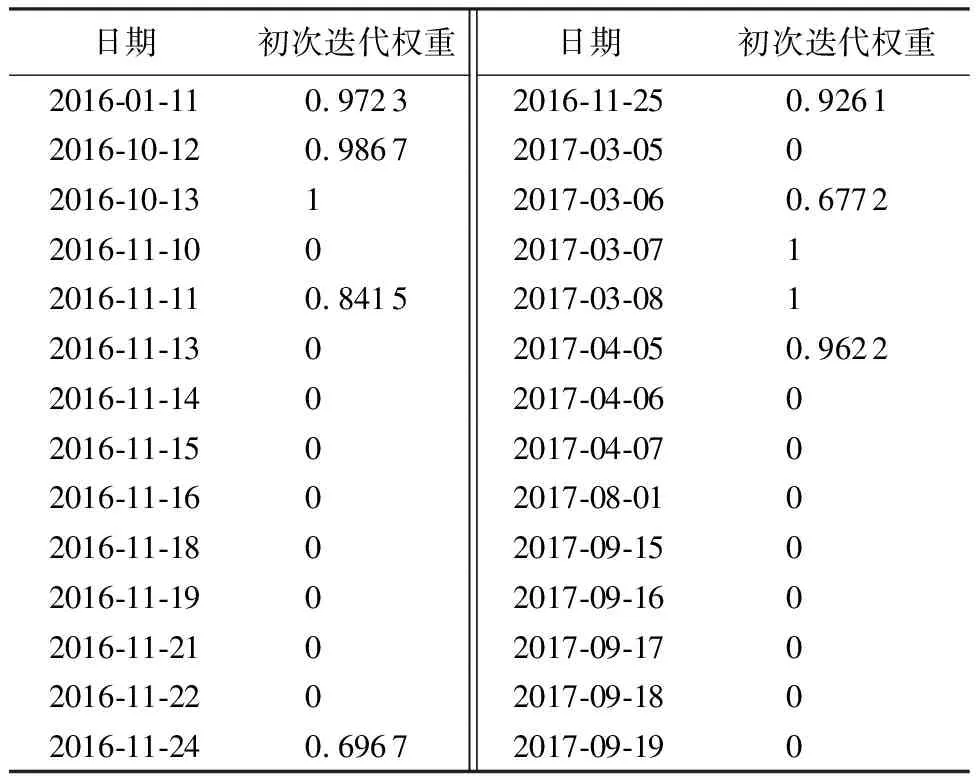
表2 粗差初次迭代權重
2.3 粗差去除效果對比分析
采用IGGⅢ-ELM法、DBSCAN聚類算法、羅曼諾夫斯基準則、拉依達準則與改進IGGⅢ-ELM法進行對比,分析不同方法去除粗差的效果。表3為不同方法的粗差識別情況對比。由表3可知,傳統的拉依達準則和羅曼諾夫斯基準則粗差識別能力較差,識別率分別為7.14%和10.71%;DBSCAN聚類算法能識別出16個粗差,識別率為57.14%;IGGⅢ-ELM法能識別出①、②、③、④類型的粗差,但沒有識別出粗差⑤,表明該方法對于小偏差量的異常值沒有抵抗能力;改進IGGⅢ-ELM法能識別出28個粗差,識別率為100%。通過對比可知,改進IGGⅢ-ELM法不僅具有更好的穩健能力,而且能夠充分利用k1附近的數據信息,精準地識別出大壩位移監測數據中偏差量較小的異常值。
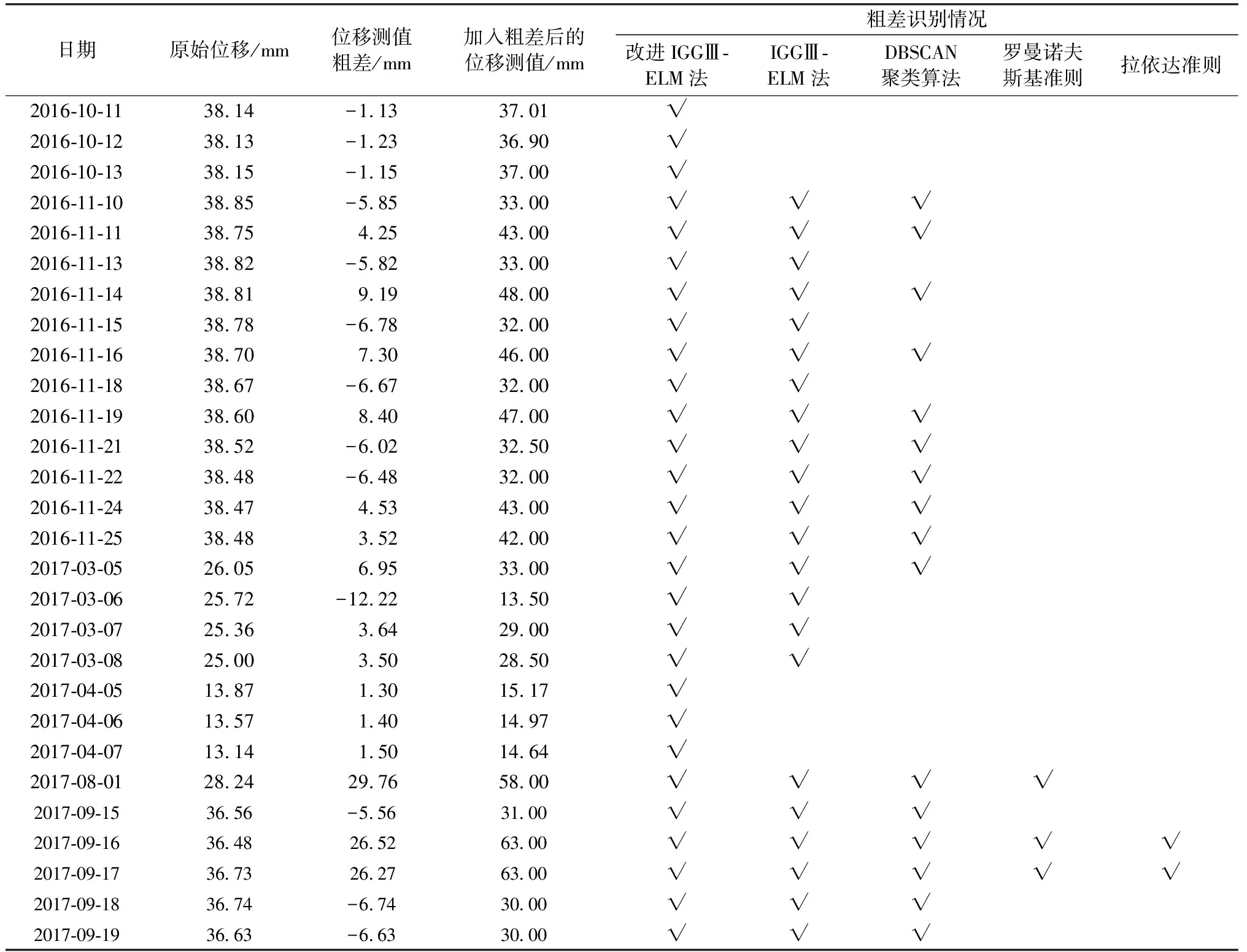
表3 粗差插入位置和不同方法的粗差識別情況
2.4 剔除粗差后的驗證效果
根據表3數據,使用改進IGGⅢ-ELM法對5種方法剔除異常值后的數據集建立大壩安全監測模型,并根據2018年5月21日至2018年12月30日的水壓、溫度、時效分量對大壩徑向位移進行預測,從而評估模型最終的泛化能力,如圖5所示。由圖5可知,利用改進IGGⅢ-ELM法剔除異常值后,模型擬合段的擬合值與實測值基本重合,擬合效果很好;從預測段的散點排列中可以看出,預測段的大壩徑向位移變化趨勢符合擬合段的大壩徑向位移變化規律,表明該方法具有準確的預測精度和良好的泛化能力。
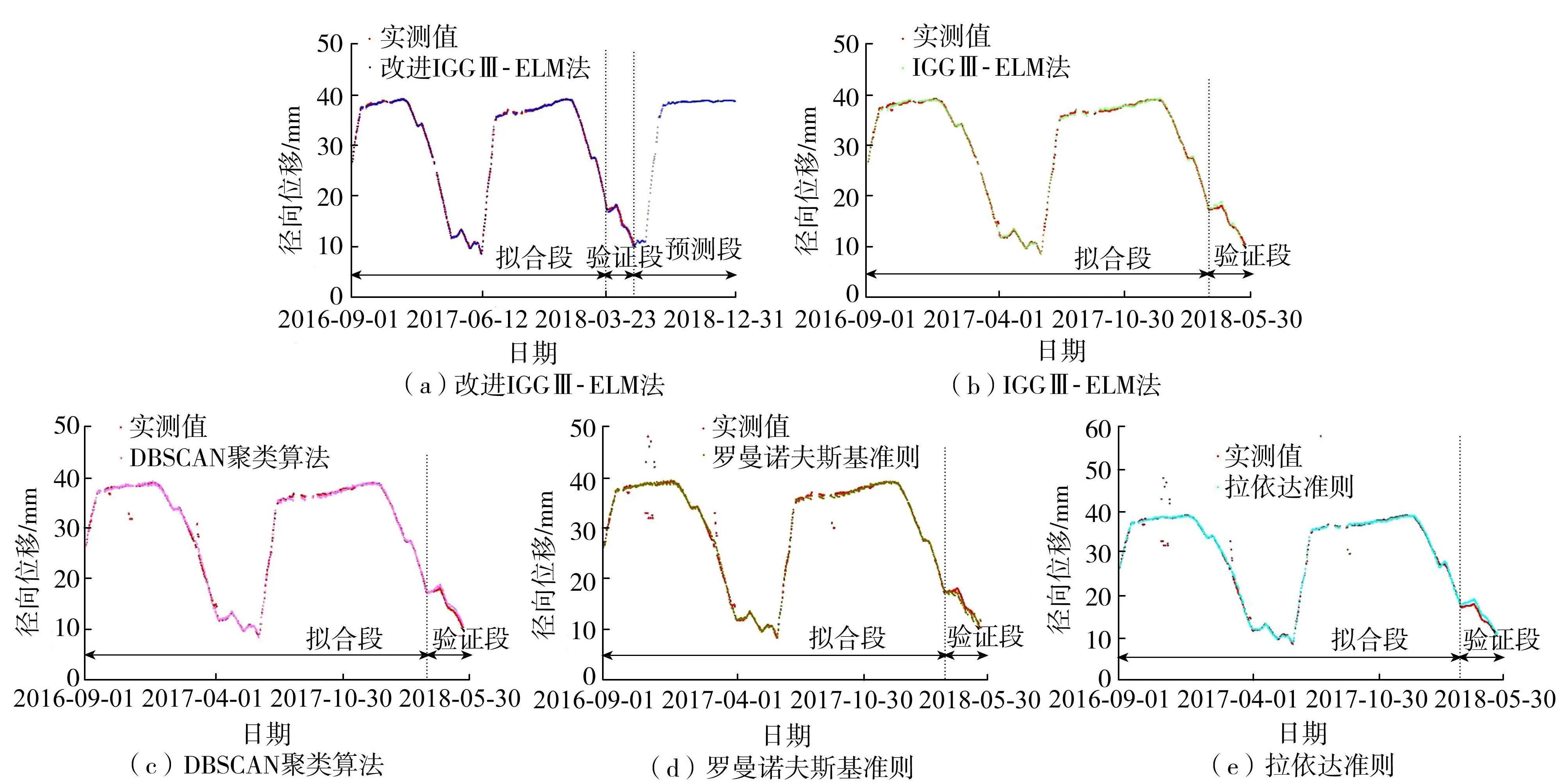
圖5 5種方法剔除粗差后的大壩監測模型泛化能力
選取平均絕對誤差(MAE)、均方根誤差(RMSE)、決定系數(R2)作為評判指標進行對比,結果如表4所示。從表4可知,在剔除異常值后的大壩徑向位移驗證中,5種方法的R2均在0.85以上,驗證段的MAE、RMSE均在1以內,表明利用改進IGGⅢ-ELM法進行大壩安全監測建模是合理和準確的。其中利用改進IGGⅢ-ELM法剔除粗差后擬合段和驗證數據是5種方法中誤差最小、相關性最強的一組數據。綜上可知,利用改進IGGⅢ-ELM法去除粗差的比例最高,對后續大壩徑向位移的監測效果最好。

表4 評判指標對比
3 結 語
針對復雜因素影響下大壩安全監測數據中的粗差問題,結合增量ELM法尋找最優網絡結構速度快、改進IGGⅢ選權迭代法對異常值的抗差能力強、ELM對數據序列的預測效率高和處理非線性問題能力強等方面的優勢,提出了基于改進IGGⅢ-ELM法的混凝土壩變形監測數據粗差識別方法。改進IGGⅢ-ELM法能夠很好地解決連續時間序列數據中的粗差識別問題。工程案例表明,在人為添加28個粗差的大壩監測數據序列中,粗差識別率為100%。相比于其他4種粗差識別方法,該模型剔除粗差效果更好、識別精度更高、泛化能力更強,驗證了模型的準確性與可靠性。通過5種方法剔除粗差后,利用改進IGGⅢ-ELM法對大壩安全進行監測,結果表明所用方法在剔除粗差后具有更好的擬合效果和更高的預測精度。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
現代裝飾(2022年5期)2022-10-13 08:48:04
建材發展導向(2022年10期)2022-07-28 03:04:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
水利規劃與設計(2020年1期)2020-05-25 08:01:30
小哥白尼(趣味科學)(2019年3期)2019-06-17 11:57:44
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
