基于CV-XGBoost的水下分流河道砂體厚度預測及應用
2023-11-29 03:28:44白青林劉烜良張軍華王福金劉中偉焦紅巖
吉林大學學報(地球科學版) 2023年5期
白青林,劉烜良,張軍華,王福金,劉中偉,焦紅巖
1.中國石化勝利油田分公司現河采油廠,山東 東營 257068
2.中國石油大學(華東)地球科學與技術學院,山東 青島 266580
0 引言
水下分流河道是一類廣泛分布的沉積儲層。由于河道寬度小,疊置、交叉嚴重,垂向厚度薄、互層多,均方根振幅等常用地震屬性中沒有明顯的河道特征,其精細描述與儲層厚度預測都有很大的困難。
以往有研究人員[1]利用地層厚度與砂地比的乘積來估算砂體厚度,前提是砂體分布與沉積比較穩定。也有研究人員[2]用多井交會分析的方法來預測厚度,但其精度受井震相關性的限制。還有不少學者將機器學習方法用于砂體厚度預測,如隨機森林回歸(random forest regression, RFR)[3]、支持向量回歸(support vector regression, SVR)[4]、混合密度網絡預測[5]等,取得了一定的地質效果,但其應用對象比較簡單。
本文以勝利油田通61井區水下分流河道儲層為例,研究了基于極限梯度提升(extreme gradient boosting, XGBoost)的砂體厚度預測方法。通過集成學習和添加具有二階偏導的正則項,提高回歸精度和速度,并與LASSO(least absolute shrinkage and selection operator)回歸、梯度下降決策樹(gradient boosting decision tree, GBDT)、支持向量機(support vector machine, SVM)等機器學習方法進行了對比,以驗證本文方法的預測效果;預測過程還對驗證集占比、超參數設置、交叉驗證(cross validation,CV)等應用要素進行了分析討論,以期為推進基于機器學習的儲層預測技術的發展提供參考。
1 XGBoost基本原理
XGBoost算法是GBDT算法的一種改進,由Chen等于2016年最先提出[6-7],改進后的算法學習效果和訓練速度得到了很大的提升。在石油勘探領域,已有多位研究人員在測井資料解釋方面開展了很好的應用[8-12]。
XGBoost由多棵決策樹組成,通過加法模型將一組弱學習器組合成強學習器。設有數據集(xi,yi),xi為包含m個特征的向量,yi為樣本標簽,下標i為樣本序號,共n個樣本,用fk(xi,θk)表示第k棵回歸樹,θk為對應回歸樹的參數集,則模型預測值為
(1)
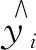
(2)
式中:O為目標函數;L為損失函數,用于評估模型預測值和真實值之間的損失或誤差;Ω為正則化項。
不同于常規GDBT方法,XGBoost加入如下正則化項:
(3)
式中:γ、λ為懲罰因子,防止決策樹過于龐大;T為葉子數目;ωj為葉子節點j的權重。
考察第s輪訓練,式(2)可改寫為
(4)
式中,fs為第s輪的預測值。上述目標函數很難在歐氏空間中優化,為此用泰勒展開,近似到二階導數,得到
(5)
其中:
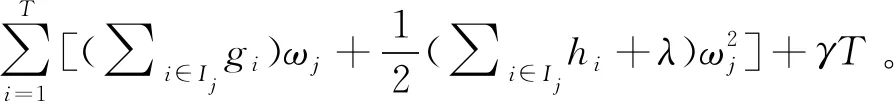
(6)
式中,Ij為葉子節點j的樣本集,即落在葉子節點j上的所有樣本。式(6)為關于ωj的一元二次函數,由式(6)易解得葉子節點j的最優權重和最優目標函數值:
(7)
(8)
為了避免過擬合,模型訓練迭代過程還會加一個縮減系數,以實現小步迭代尋優:
(9)
式中,η為新生成樹模型的縮減系數。
圖1給出了基于樹模型的集成學習原理示意圖,通過多棵樹加法提高集成度,通過模型迭代求得最優解。另外,XGBoost還支持行采樣和列采樣,行采樣是樣本有放回的采樣,列采樣是部分特征參與訓練,目的都是避免過擬合。XGBoost設置了多個模型參數和超參數,通過模型訓練獲取最佳參數集,進行目標預測。
2 儲層厚度預測流程圖構建、屬性提取與模型測試
2.1 儲層厚度預測流程圖構建
基于交叉驗證的極限梯度提升(CV-XGBoost)砂體厚度預測采取以下主要步驟(圖2):一是數據集的準備,主要是地震屬性的提取和優化,屬性提取盡量選物理意義和地質含義明確的地震屬性,屬性優化要去除冗余屬性,選取井震關系好的地震屬性;二是模型訓練,建立訓練集和驗證集,設定超參數,訓練集進行網格搜索與交叉驗證,通過模型誤差評價獲取最佳參數集;三是目標預測,將訓練好的模型用測試集進行預測,得到預測結果。
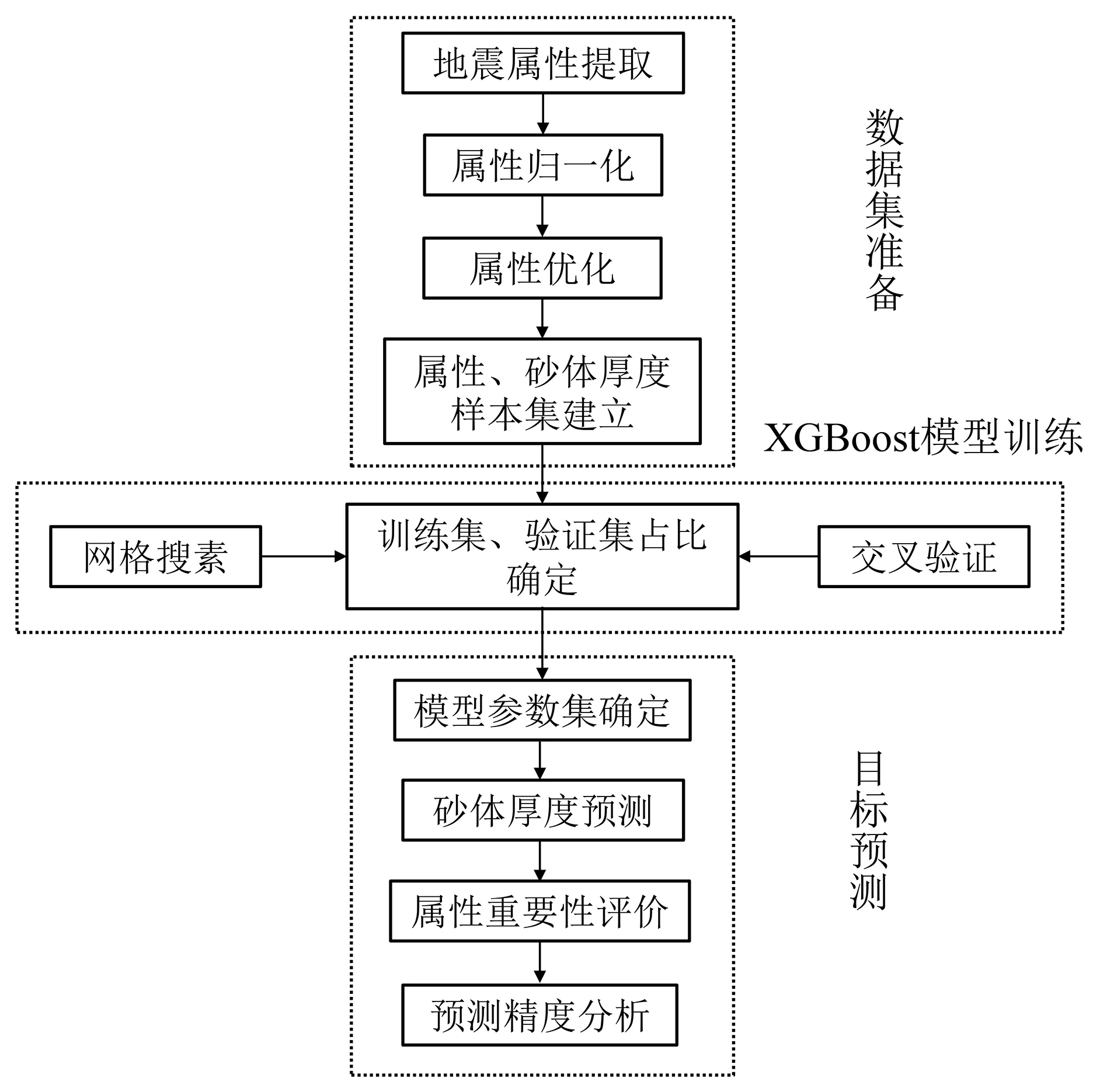
圖2 基于CV-XGBoost的砂體厚度預測流程圖
2.2 屬性提取及共線性評價
以勝利油田通王斷裂帶通61井區為例,提取物理意義明確、以往儲層描述應用效果較好的常用地震屬性[13],包括弧長、平均振幅、平均能量、帶寬、主頻、能量半時、最大振幅、最大幅值、均方根(root mean square, RMS)振幅、總正振幅、過零點數等11個屬性,對89口井的井點屬性做相關性分析,得到圖3所示的Pearson相關系數圖。從圖3可以看到:RMS振幅、總正振幅、最大振幅、最大幅值相互之間有很強的相關性,另外RMS振幅與平均能量、弧長,最大振幅與平均能量、弧長,總正振幅與平均能量等,也都有很強的相關性。這種相關性,不是單一的一種屬性與另一種屬性的線性相關,而是具有多重共線性特征的相關。
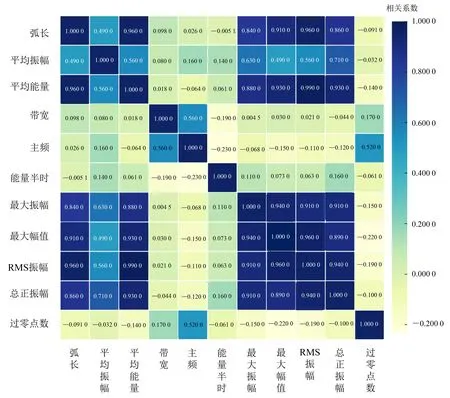
圖3 屬性Pearson相關系數圖
對于多重共線性問題[14],本文還計算了方差膨脹因子(variance inflation factor, VIF),發現RMS振幅多重共線性最嚴重,VIF達150.34。考察屬性的方差比例,在特征值為0.002時,最大振幅與最大幅度的方差比例皆為0.81,大于0.5,由此可知這兩個屬性也存在多重共線性。綜合多屬性相關分析、VIF、方差比例結果,最終去除RMS振幅、最大振幅、最大幅度3種冗余屬性,用其他8種屬性做儲層預測。
2.3 XGBoost模型訓練及參數集確定
2.3.1 驗證集占比的確定
訓練集和驗證集如何設置,它們對機器學習儲層預測有什么樣的影響,是一項很有理論研究價值的工作。一般來說,提高訓練集的占比會提高模型的預測精度,但相應地會減少驗證集占比,而驗證集減少會使利用的井數據減少,失去預測價值。為解決這一問題,本文用XGBoost在[5%,95%]間取驗證集占比,取值間隔為5%,當預測累積的厚度絕對誤差超過100 m時停止模型訓練,并通過交叉驗證輸出最終模型的最佳迭代輪數。經實驗,當驗證集占比為75%時,觸發了停止條件;當驗證集占比為80%時,累積的絕對誤差已達到了142.12 m。圖4給出了不同驗證集占比預測結果井點散點圖,可以看到:1)當驗證集占比較小(25%)時,大多數井預測結果都比較好,只有1口井誤差比較大;2)隨著驗證集占比的提高,驗證井增加、訓練井減少,實際厚度與預測厚度井點分布逐漸分散,到80%已比較分散。
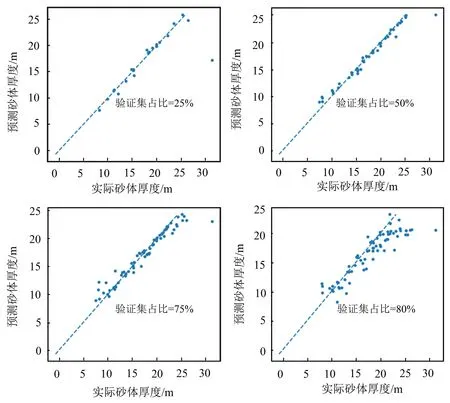
圖4 驗證集占比與預測精度散點分析圖
當驗證集占比為25%時,模型最佳參數如表1所示。

表1 最佳模型組合參數
2.3.2 不同方法效果的對比
用LASSO回歸[15]、GBDT[16]、SVM[17]與本文XGBoost 4種機器學習方法分別進行預測,并將預測結果與真實的儲層厚度進行對比,結果如圖5所示。從圖5可以看到:LASSO回歸方法誤差最大,見T61-140、T61-27井;常規的梯度提升方法(GBDT)在T61-617井點處誤差較大;SVM方法在T61-33、T61-101井處誤差也較大;綜合來看,本文XGBoost方法誤差最小。表2給出了4種模型預測全部厚度的誤差統計,誤差評價分別分為平均絕對誤差(mean absolute error, MAE)、擬合優度可決系數(R2)、平均相對誤差(mean relative error, MRE),整體來看XGBoost誤差最小,為最佳方法。
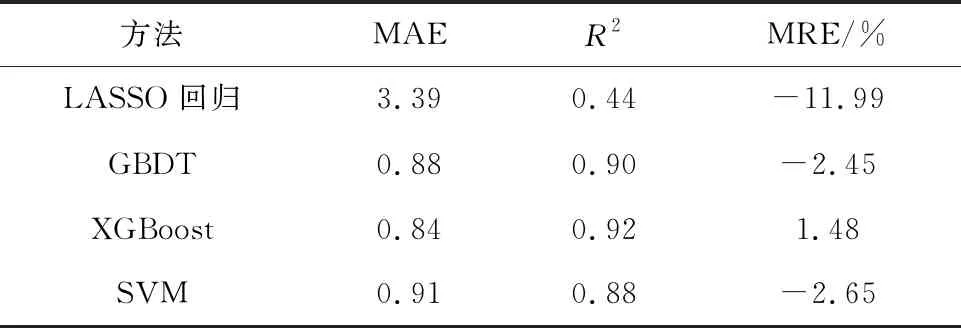
表2 不同機器學習方法預測誤差整體評價
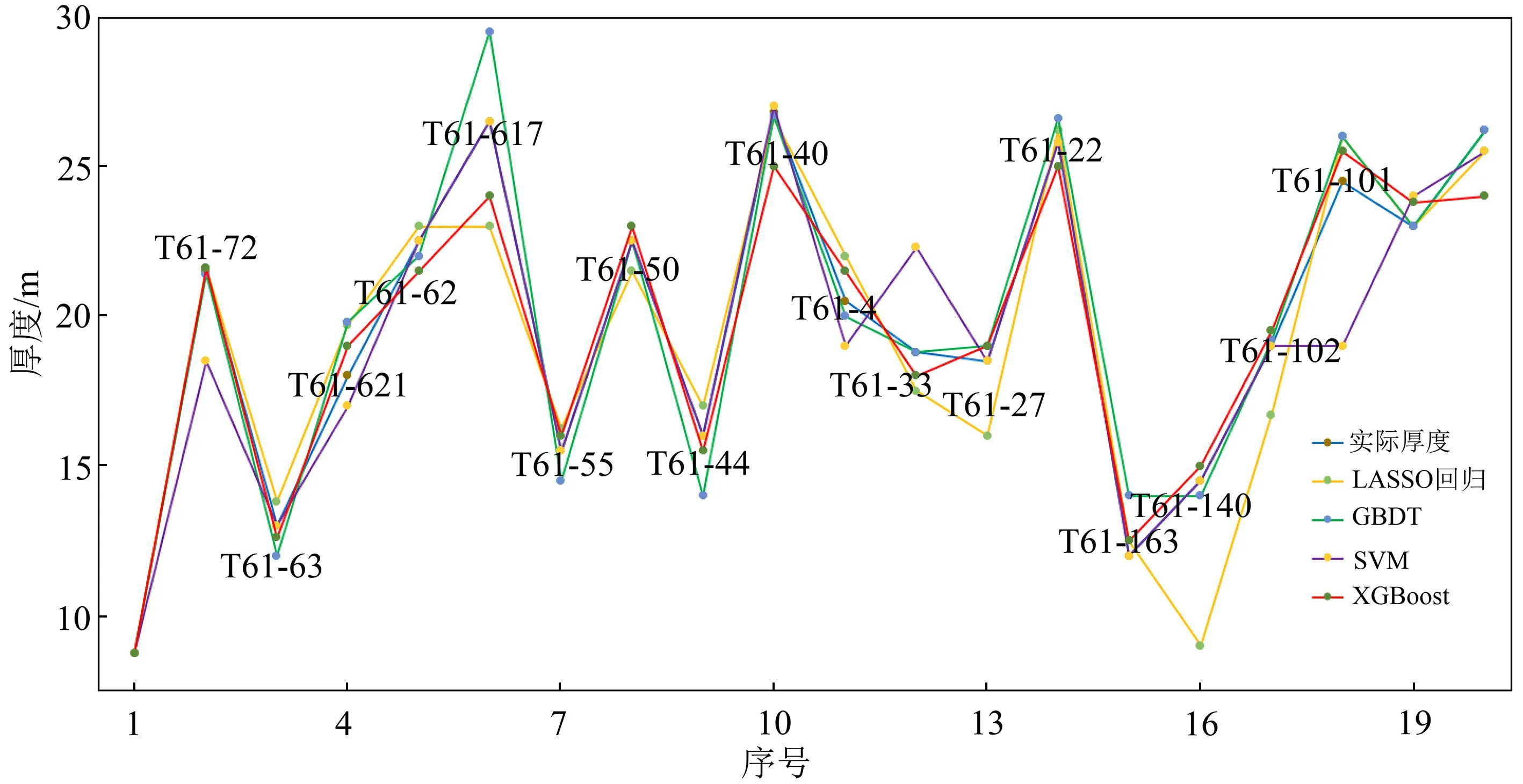
圖5 不同機器學習方法預測結果井點誤差比較
2.3.3 關于交叉驗證模型參數優化的討論
交叉驗證[7],也稱為循環估計,是一種統計學上將數據樣本切割成較小子集的實用方法,該理論是由Seymour Geisser提出的。其基本思想是在某種意義下將原始數據進行分組,一部分作為訓練集,另一部分作為驗證集,先用訓練集對分類器進行訓練,再用驗證集來測試訓練得到的模型,以此來做為評價分類器的性能指標。交叉驗證按類型不同可分為K折交叉驗證和留一交叉驗證。
本次研究選擇K折交叉驗證。取75%的井為訓練集(66口井),剩下25%的井作為驗證集,K取5,做交叉驗證測試。圖6為交叉驗證前后驗證集厚度與真實值的對比,可以看到做了交叉驗證后預測精度得到明顯提高。
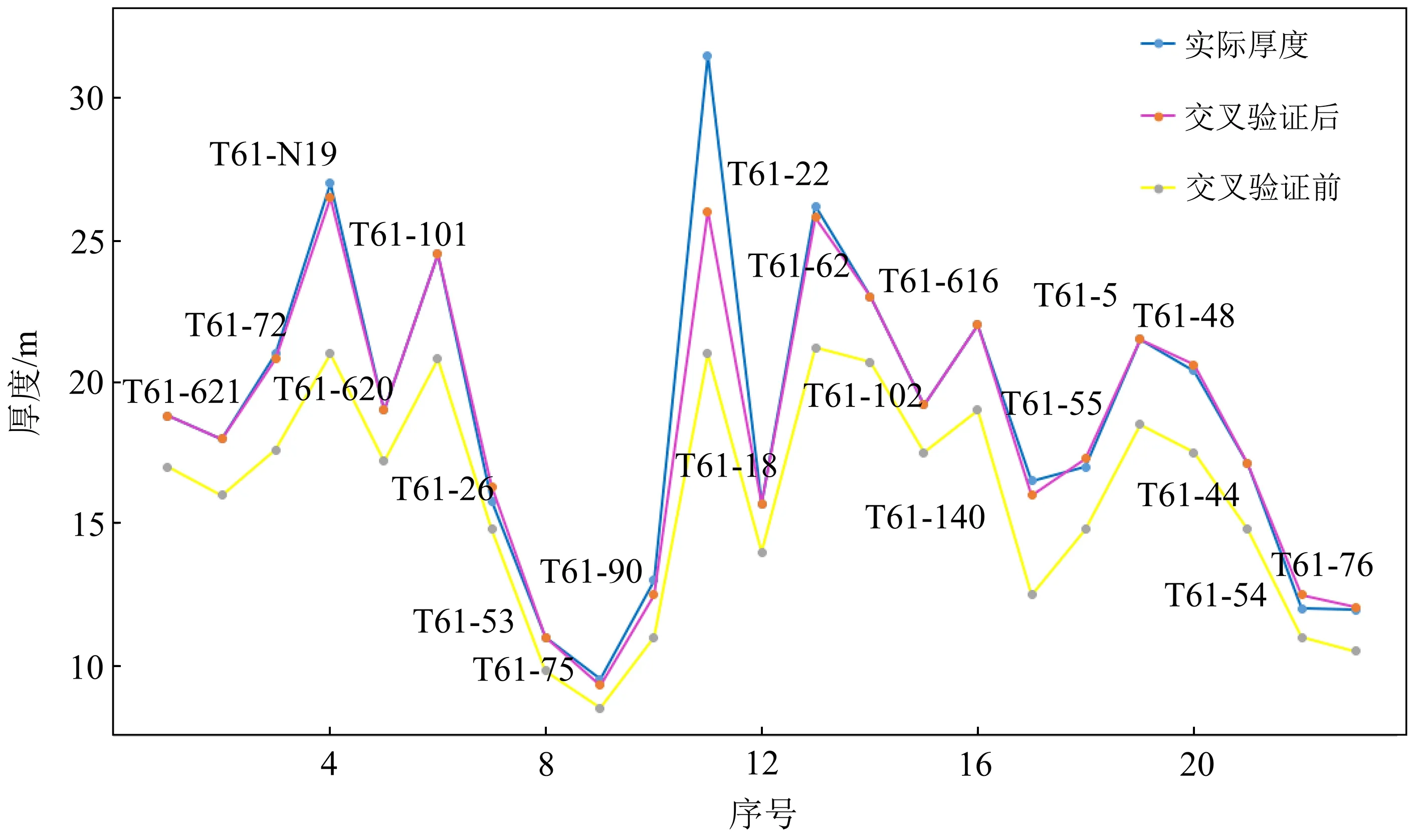
圖6 交叉驗證前后預測精度比較
3 預測結果分析與評價
根據本文XGBoost方法,得到屬性重要性評價結果,如圖7所示。從圖7可以看出,本研究區平均振幅、平均能量、弧長、主頻為厚度預測貢獻度較大的屬性。
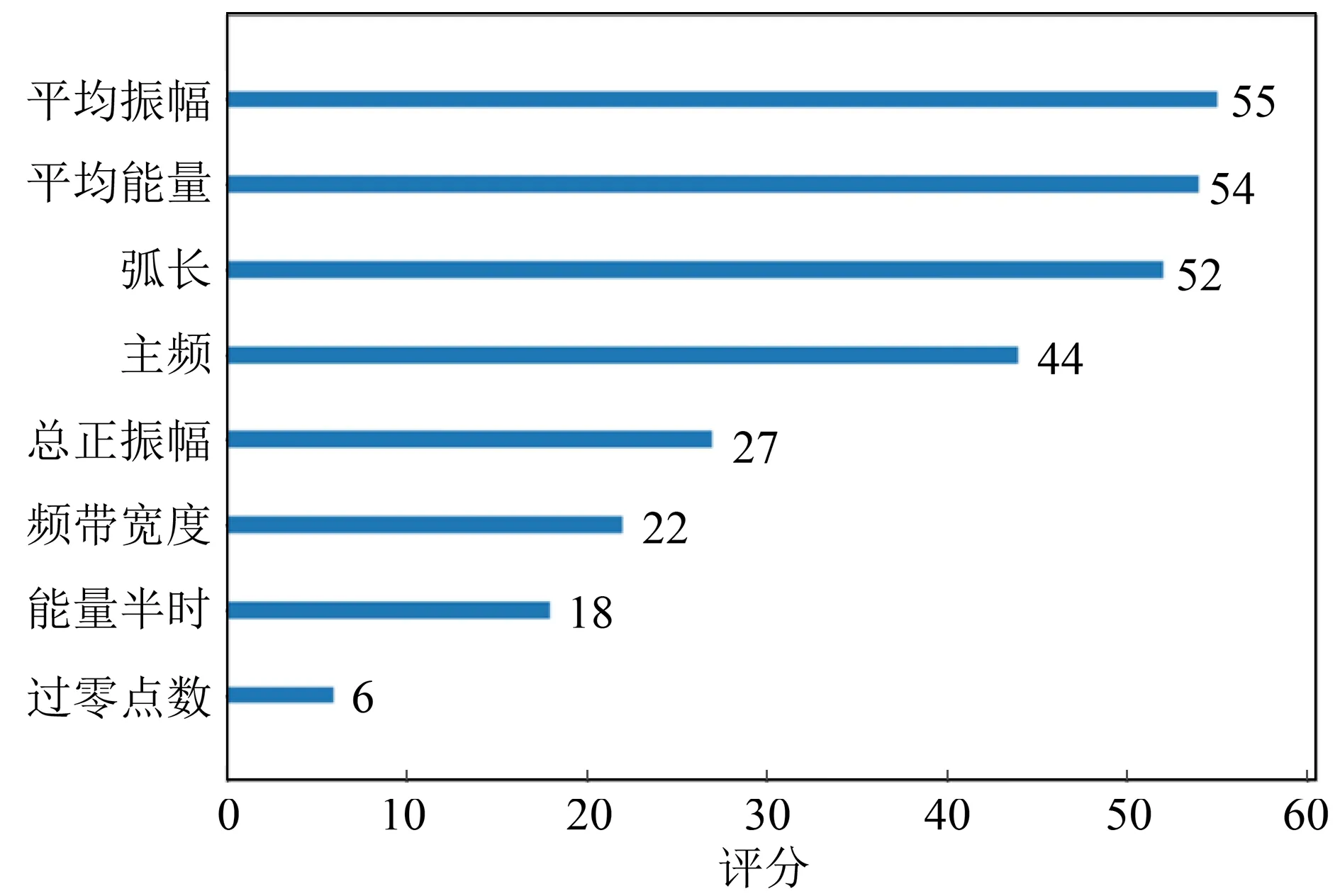
圖7 地震屬性重要性評分
圖8a為根據插值得到的井點厚度圖,它沒有地震屬性的關聯信息;圖8b、c為本文在不同驗證集占比下由XGBoost預測得到的砂體厚度圖;圖8d為根據前述重要性分析得到的最佳屬性。由圖8a—c整體來看,砂體有2個厚度中心,這在25%驗證集占比情況下特別清晰(圖8b),所以要了解研究區砂體的宏觀分布,可用較多的訓練集、較少的驗證集,此認識與圖4分析結果一致。仔細觀察圖8a,右側存在數據孤立點,這不符合地質認識;從圖8b結合圖8d地震屬性來看,圖8b左邊的砂體厚度中心范圍較大,與屬性關聯度不高。對比來看,用75%驗證集占比預測,雖然如圖4分析預測精度會略低于25%驗證集,但它參與驗證的井多,所蘊含的厚度信息豐富,綜合認為是比較合適的預測結果。
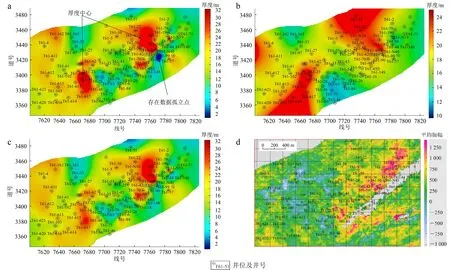
a. 根據插值得到的井點厚度圖;b. 本文方法25%驗證集占比預測結果;c. 本文方法75%驗證集占比預測結果;d. 平均振幅最佳屬性。
4 結論
通過CV-XGBoost砂體厚度預測方法研究與實際應用,可以得到以下結論:
1)多重共線性分析技術對去除相關度高的冗余屬性、優化模型的數據集十分適用。
2)本文方法具有比LASSO回歸、GBDT、SVM方法更高的預測精度,對復雜砂體儲層預測具有很好的應用效果,值得在儲層預測中推廣。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
