基于Relief-WGS 優化算法的圖像分類方法*
2023-11-29 11:26:02紀峰馬圓月劉瑩
數字技術與應用 2023年11期
紀峰 馬圓月 劉瑩
1.陜西環保產業研究院有限公司;2.西安微電子技術研究所
針對圖像特征選擇問題,特征屬性過多不但會造成維數災難,而且會影響分類的正確率。在采用支持向量機分類時,特征維數較高,會造成分類準確率較低,運算速度較慢等問題。為了解決此問題,提出Relief 算法、鯨魚算法、遺傳算法和支持向量機相結合的Relief-WGS 優化算法,實現圖像特征選擇和分類。首先,使用Relief 算法對特征集進行初步篩選,其次,將篩選的特征子集個數和支持向量機參數編碼到鯨魚-遺傳算法中,最后對特征子集進行優化的同時,對支持向量機參數也進行同步優化。計算結果表明,所提出的算法能在去除掉不重要特征的同時對支持向量機參數進行優化,有效地提高圖像分類準確率。
近年來,隨著圖像技術的發展和相關應用的普及,為了能更好地反映圖像特征,使圖像更有效地應用在多個方面,為此需要在提高圖像識別度的問題上不斷地進行研究。圖像分類準確率的高低取決于所利用的分類特征是否能夠很好地反映所要研究的分類問題。一般而言,特征集中或多或少都包含著一些對分類結果無貢獻的特征,這些特征也稱為冗余特征,過多的冗余特征不僅會使運算變得復雜,處理速度下降,而且可能會導致分類精度降低,因此需要選用對分類識別作用較大的特征[1]。本文對提取的紋理特征進行篩選,根據各個特征和類別的相關性進行特征選擇,降低特征空間維數,加快算法的運算效率。
支持向量機(Support Vector Machine, SVM)作為一種基本的監督學習方法,被廣泛應用于文本識別、圖像識別等[2]。SVM 的原理是通過構建分類超平面作為決策面來最大化不同類型數據之間的差異,有效避免局部最優,在處理有限樣本、高維和非線性數據等復雜問題時具有獨特的優勢。本文結合鯨魚優化算法和遺傳算法來提高算法的精確度和獲得全局最優解。遺傳算法(Genetic Algorithm,GA)是通過模擬自然進化過程搜索最優化的方法[3]。它有著較好的全局搜索能力和保持種群的多樣性,但是計算效率較低。鯨魚優化算法(Whale Optimization Algorithm)具有強大的全局搜索能力,但是在迭代后期容易陷入局部最優解不能得到全局最優解[4]。因此,將兩種算法結合既可以提高算法的精確度又可以達到全局最優解。為了減少前期的運算量,刪除不相關的特征屬性,減少特征維度,利用Relief 算法進行特征選擇。Relief 算法是一種針對二分類問題通過計算特征權重對特征進行選擇的方法。根據各個特征和類別的相關性賦予特征不同的權重,權重小于某個閾值的特征將被移除[5]。采用這種方法可以在分類前期降低樣本維數,減少計算量。
綜上所述,本文提出了一種Relief-WGS 優化算法。該算法首先使用Relief 算法對特征集進行初步篩選,其次,將篩選的特征子集個數和SVM 參數一起編碼到鯨魚-遺傳算法中,再對特征子集進行優化的同時,對SVM 參數進行同步優化,實現圖像分類。
1 原理與方法
首先利用Relief 作為特征預選器濾除相關性小的特征,以WSO-GA 作為搜索算法,SVM 的分類精度作為評估函數,在剩余特征中選擇最優特征子集,最后利用SVM 分類器對所選擇的最優特征進行分類。
1.1 Relief 算法
Relief 算法是一種典型的過濾式算法,在對特征樣本進行選擇與分類的過程中相互獨立,過濾式算法的通用性比較強并且計算的復雜度比較低,適合對大數據的特征樣本進行特征選擇[6]。Relief 算法中特征和類別的相關性是基于特征對近距離樣本的區分能力。核心原理是根據各個特征和類別之間的相關性給每個特征不同的權重,將權重和閾值進行比較,當權重比閾值小時則將該特征刪除。權重值越大則表明該特征代表某圖像的能力越強,反之權重越小則該特征代表某圖像的能力越弱。
1.2 支持向量機
SVM 算法是一個凸優化問題,其原理是用分離超平面作為分離訓練數據的線性函數,解決線性分類問題。假設訓練樣本集合其中,xi∈Rn表示訓練樣本,yi∈ {1 , - 1}表示輸入樣本的類別。訓練的最終目的是找到一個最優分類面,使得兩類樣本之間以最大間隔分開,使泛化誤差達到最小或者有上界。這個最優分類面即超平面,該超平面可描述為如式(1)所示:
式(1)中x為樣本,ω為權向量,b為分類閾值。
1.3 鯨魚-遺傳算法
遺傳算法(Genetic Algorithm, GA)是一種依據生物界優勝劣汰的進化準則衍生出的隨機優化搜索方法。GA 算法的核心思想是先隨機得到一個父代種群,通過計算種群中每一個個體的適應度值,然后對得到的值進行排序,從中找出適應度值最大或最小的n個個體,確定種群的進化方向,然后對個體中的染色體進行遺傳操作,得到新的子代種群,經過有限次迭代之后,得到問題的近似最優解,GA 算法包括三個基本操作:選擇、交叉和變異。
鯨魚優化算法是一種基于復雜優化問題進行尋優的算法,模擬了座頭鯨群體的捕獵行為。該算法可分為包圍收縮、螺旋捕食和搜索獵物三步。
(1)包圍收縮。該階段對鯨群識別獵物并且收縮包圍圈的動作進行模擬。
(2)螺旋捕食。在圍捕獵物時,鯨魚通過螺旋向上游動的方式向獵物移動并吐出氣泡對獵物進行捕食,即在螺旋更新位置的同時對包圍圈進行收縮。
(3)搜索獵物。當≥1時,鯨魚隨機選擇一個領導個體,以此進行全局搜索。
對于參數優化問題,GA 算法有著較好的全局搜索能力和種群的多樣性,但由于要經歷選擇、交叉和變異三步操作才能得到下代種群,因而計算效率較低,收斂速度較慢。由于鯨魚算法在控制參數尋優時會出現實際的優化搜索過程不能完全體現,導致存在求解精度低、收斂速度慢和易陷入局部最優的缺點。因此,將遺傳算法與鯨魚算法進行結合可以提升算法的收斂效果[7]。
2 Relief-WGS 優化算法
基于以上研究,提出Relief-WGS 優化算法,其流程圖如圖1 所示。該算法首先使用Relief 算法對數據特征集進行初步的篩選,然后將SVM 的參數和篩選的特征子集編碼到WOA-GA 算法中,以SVM 的分類精度構建適應度函數,同時優化特征子集和SVM 的參數,具體流程分為如下幾個步驟:

圖1 Relief-WGS 算法流程圖Fig.1 Relief-WGS algorithm flowchart
步驟1:采用Relief 算法對圖像特征進行第一次提取,得到特征矩陣;
步驟2:WOA-GA 算法進行參數初始化,種群大小為30,迭代次數為50,算法的終止條件為達到迭代次數或連續十代的適應度值不變;
步驟3:生成初代種群,由于SVM 的懲罰系數C和核參數σ采用實數編碼,而對特征的二次篩選是通過0、1 進行,0 表示沒有選擇該特征,1 表示選擇該特征,采用二進制編碼;
步驟4:將個體的后N位帶入樣本中進行特征的第二次篩選;
步驟5:將個體的前兩位帶入SVM 模型中,結合二次篩選的訓練樣本,確定SVM 分類模型;
步驟6:將二次篩選測試樣本帶入確定的SVM 中,得到分類結果;
步驟7:計算初代種群的適應度值;
步驟8:根據初代種群的適應度值進入鯨魚算法中,計算每一頭鯨魚的適應度值,更新個體位置;
步驟9:將位置更新的鯨魚個體代入到遺傳算法中,經過交叉和變異操作,得到新的種群;
步驟10:返回步驟4,計算新種群的適應度值;
步驟11:判斷是否滿足終止條件,若滿足,則輸出最終結果;若不滿足,繼續對種群進行處理,直至滿足終止條件,得到最終結果。
3 實驗結果
本實驗為了驗證Relief-WGS 算法的有效性,將特征子集個數和SVM 參數一起編碼到WOA-GA 算法中,在對SVM 參數進行優化的同時對所有特征進行同步優化。在實驗時需要對數據和參數進行如下幾步處理。
3.1 數據的預處理
為了提高SVM 的分類準確率,將需要用于分類的所選數據樣本進行歸一化處理,并將其分為訓練樣本和測試樣本進行后續分類。
3.2 參數選擇方法
本文使用WOA-GA 算法對SVM 的參數進行優化。設置算法的迭代次數為50,個體長度設定為2,遺傳算法中交叉和變異概率是基于適應度值自適應計算得來的,鯨魚算法位置更新是根據適應度值計算。
適應度函數統一設置為如式(2)-式(4)所示:
式(2)中we1為訓練樣本識別結果的權重,we2為測試樣本識別結果的權重,m1為訓練樣本的總數,m2為測試樣本的總數,nsv1為訓練樣本分類正確的結果,nsv2為測試樣本分類正確的結果,fitness越小,表明綜合的分類準確率越高[8]。
3.3 模型建立
利用從每組訓練樣本中選擇優化后的核參數來對樣本進行新一輪的訓練,獲得SVM 的分類模型,然后通過測試樣本來測試模型的分類精度。實驗選取UCI 數據庫中的5 種數據集進行試驗,所選取數據集的基本信息如表1 所示。
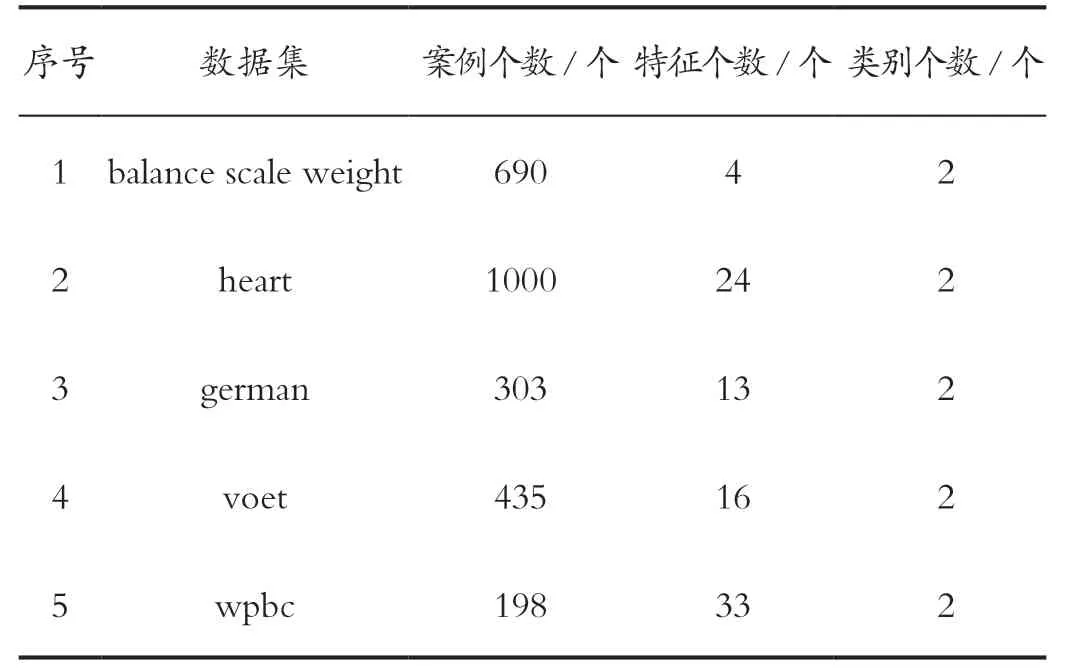
表1 實驗數據集Tab.1 Experimental datasets
利用Relief 算法對提取的特征進行篩選,保留與目標類別相關性較大的特征,然后利用WOA-GA 算法優化參數的SVM 算法對特征子集和核參數進行同步優化,獲得優化后的特征子集。優化特征子集的個數如表2 所示。
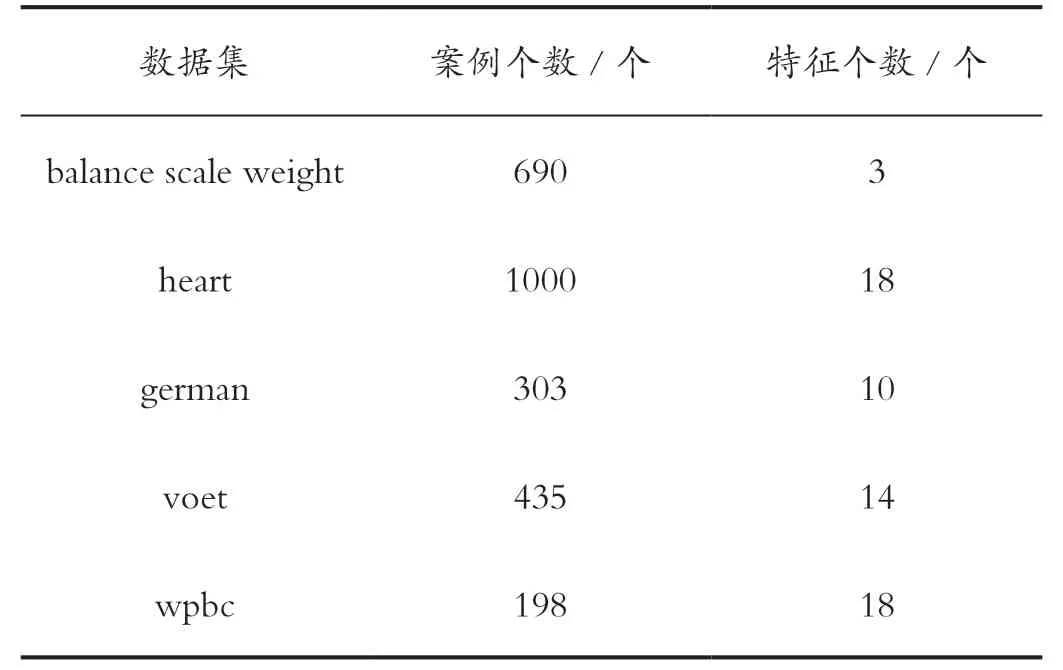
表2 優化特征子集個數Tab.2 Number of optimized feature subsets
獲取的優化特征子集通過表2 可知,利用選擇的多個優化特征,以SVM 為分類器進行分類,其中SVM 選用RBF 為核函數。為進一步驗證Relief-WGS 優化算法的有效性,分別和默認核參數的SVM、采用WSO-GA算法優化參數的SVM(WGS)、Relief 算法優化特征的SVM(Relief-SVM)進行分類結果的比較。通過比較分類準確率來評價特征選擇方法的優劣,如表3 所示。
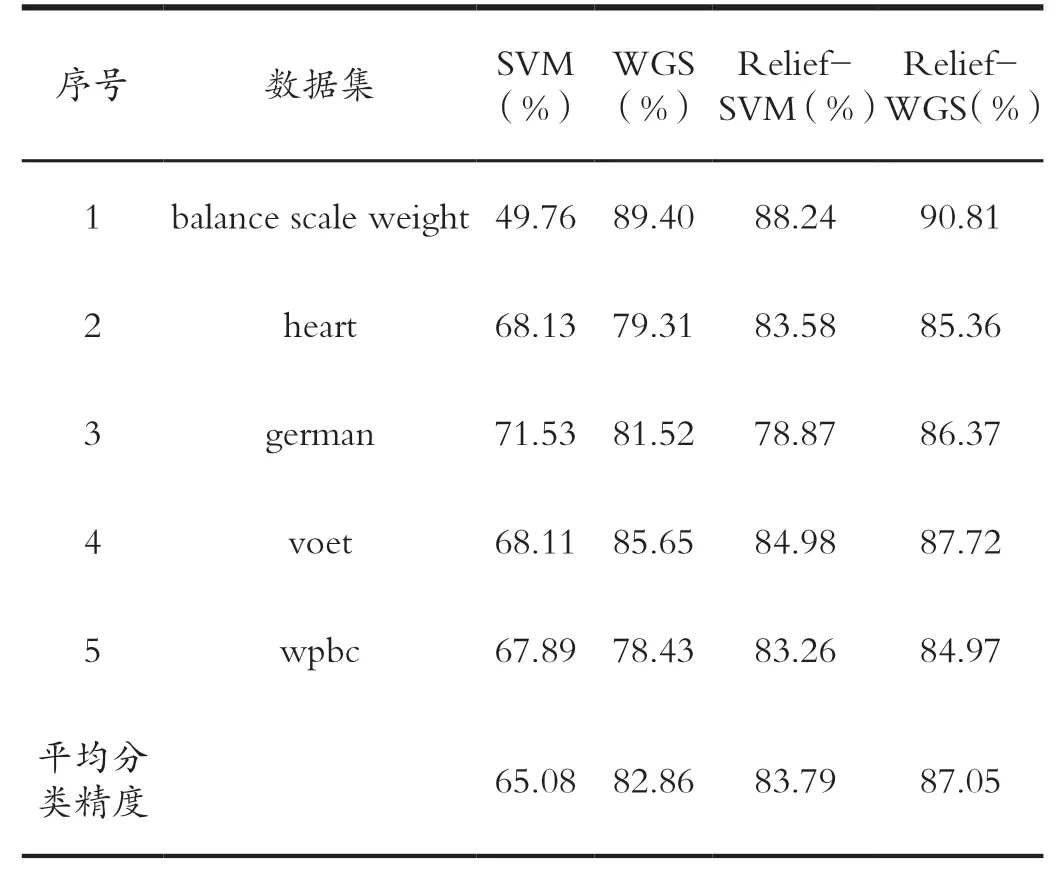
表3 數據集分類結果對比Tab.3 Comparison of dataset classification results
通過表3 可知,本文提出的Relief-WGS 優化算法可以同時優化特征子集和SVM 的參數,實現以優化的特征子集和優化的SVM 參數來提高分類的準確率。為了進一步驗證Relief-WGS 優化算法的有效性,將其與SVM、WGS 和Relief-SVM 進行比較,實驗結果顯示:
(1)對于任意的特征數據而言,使用WGS 優化算法進行參數尋優后的分類準確率比采用默認參數的SVM高,證明了對傳統的SVM 中的參數進行尋優,找到優化的控制參數,可以提高SVM 的分類準確率。
(2)使用Relief-SVM 優化算法對輸入的特征向量篩選后進行分類,分類準確率均有提高,證明了利用Relief-SVM 對輸入的特征數據集進行篩選和優化,得到優化的特征子集,去除掉一些特征不明顯的影響因素,減少不重要因素對分類造成的影響,可以提高分類的準確率。
(3)使用本文提出的Relief-WGS 優化算法得到的分類準確率最高,證明在對特征子集和SVM 的參數同步進行優化時,去除掉不重要的特征并對參數進行優化可以得到更好的分類效果。
4 結論
本文提出一種Relief-WGS 優化算法,同時優化特征子集和SVM 的參數,實現用優化的特征子集和優化的SVM 參數來提高分類的準確率。通過與傳統的SVM、WGS 算法和Relief-SVM 算法相比,本文所提算法將圖像的平均分類準確率分別提高了21.97%、4.19%和3.26%,證明了圖像分類識別的準確性。結果表明,本文提出的特征選擇方法利用最少的特征獲得了最高的分類精度,更有效地用于特征選擇分類。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
