基于確定初始簇心的優化K-means 算法
2023-11-29 11:26:14喀什大學計算機科學與技術學院岳珊雍巧玲
數字技術與應用 2023年11期
關鍵詞:模型
喀什大學計算機科學與技術學院 岳珊 雍巧玲
考慮到K-means 聚類算法在聚類過程中同等地看待每個特征維度、簇心的初始選取是隨機的等問題,采用優化K-means 算法SVD-Kmeans。首先對高維樣本數據采用奇異值分解方法,在最大限度保證原始樣本數據特征的前提下進行降維處理,每個樣本降維后得到一個二維指標值,再使用初始簇心求解模型確定初始簇心的選取,最后通過K-means 算法進行聚類求解,形成最終模型。通過在同一數據集上實驗發現,采用SVDKmeans 算法相較傳統K-means 聚類算法準確率提高34.24%左右。
K-means 聚類算法是由J.B.MacQueen 提出,該算法是一種迭代求解的聚類分析算法,該算法具有原理簡單、容易實現、可理解性較強等優勢,但也存在容易出現局部最優、聚類效果依賴于聚類中心的初始化等問題。
基于此,學者們從兩方面進行改進優化,一方面使用該算法與其他算法混合使用[1-3];另一方面從優化算法本身上下功夫,如目前使用較多的K-means++算法[4-8]、二分K-means 算法[9-13]等。然而,這幾種優化方案雖然解決了簇心數量確定、減少算法時間、防止局部最優等問題,但仍然不可避免地存在實驗之初隨機選擇一個樣本點作為第一個初始化的聚類中心的問題。
基于以上考慮,本文首先對高維數據進行降維處理,解決算法同等看待每個特征維度的缺陷,再使用簇心求解模型首先確定兩個簇心的初始位置,最后使用K-means算法對樣本進行聚類操作,通過以上操作,有效地避免了實驗之初簇心隨機選取和K 值不確定的問題。
1 K-means 算法研究
K-means 算法能夠在不知道任何樣本標簽的情況下,通過數據之間的內在關系將樣本分為若干個類別,使得相同類別樣本之間的相似度高,不同類別之間的樣本相似度低。
通過迭代的方式尋找k 個簇的劃分方案,使得聚類結果對應的代價函數最小,如式(1)所示:
其中,xi代表第i個樣本,ci是xi所屬的簇,μci代表簇對應的中心(即均值),N是樣本總數。
2 原始數據處理
選用機器學習MLP 填充方法對數據集中的缺失值進行填充,應用擬合與分類思想,將不含缺失值的行作為訓練樣本的輸入和標簽,缺失值的行(不含缺失值的部分)作為測試樣本的輸出,缺失值即是測試樣本的待預測標簽,填充結果如圖1 所示。
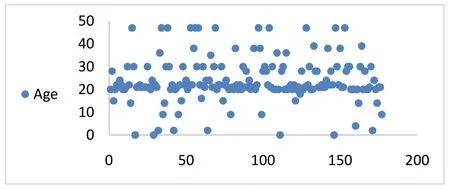
圖1 缺失信息填充Fig.1 Missing information filling
此次試驗共填充177 名乘客的年齡信息,其中縱坐標代表乘客的年齡,通過結果分析發現大部分年齡集中在20 ~30 歲之間。
3 SVD-Kmeans 算法
3.1 降維處理
輸入:N 個樣本。
輸出:一個N×R 矩陣。
(1)對高維矩陣進行奇異值分解得到矩陣V,如式(2)所示:
(2)以矩陣V 的前D列作為降維矩陣,用高維矩陣和V '做矩陣乘法,實現降維,如式(3)所示:
3.2 簇心求解模型
3.2.1 模型假設
(1)簇心作用強度向其四周等強度擴散;
(2)簇心作用強度服從擴散定律,即單位時間影響單位法向量的面積與它的強度梯度成正比。
3.2.2 模型建立
將簇心起作用的時刻記為t=0,簇心點首先選為坐標原點。時刻t無窮空間中任一點(x,y)的強度記為C(x,y,t)。根據假設2,單位時間通過單位法向面積的強度擴散面積,如式(4)所示:
k為擴散系數,grad表示梯度,負號表示由濃度高向濃度低的地方擴散。考查空間域Ω,Ω 的體積為V,包圍Ω 的曲面為S,S的外法線向量為n,則在[t,t+Δt]內通過Ω 的強度如式(5)所示:
而Ω 內強度的增量如式(6)所示:
質量守恒定律如式(7)所示:
將數據集中所有數據作為簇心,求解每個點的擴散強度和擴散增量,最大的兩個即為本次實驗的初始簇心。
3.3 聚類算法
輸入:N 組樣本數據。
輸出:待分類樣本所對應的分類結果。
(1)使用簇心求解模型求解出的兩個初始簇心,記為μ1,μ2。
(2)計算每個樣本xi到各個簇心的距離,將其分配到與它距離最近的簇。
(3)對于每個簇,利用該簇中的樣本重新計算該簇的中心(即均值向量)。
(4)重復迭代上面2 ~3 步驟T 次,若聚類結果保持不變,則結束。
4 實驗介紹
通過奇異值分解方法盡可能多的保留原始樣本的數據特征得到降維后的矩陣,在本實驗中,N=94,M=49,D=2。本次實驗各奇異值的貢獻率如下所示:
第1 個奇異值的累積貢獻率是:0.20299414497066245
第2 個奇異值的累積貢獻率是:0.4010049338627624
第3 個奇異值的累積貢獻率是:0.5514842977877248
第4 個奇異值的累積貢獻率是:0.6884462710597125
第5 個奇異值的累積貢獻率是:0.8034632384325324
第6 個奇異值的累積貢獻率是:0.9120410189148603
第7 個奇異值的累積貢獻率是:1.0
奇異矩陣為:
降維后的數據結構如圖2 所示。

圖2 降維結果Fig.2 Dimension reduction results
根據數據集特征可知最終確定出2 個簇心,根據簇心公式確定簇心后,使用K-means 方法進行聚類,如圖3 所示。
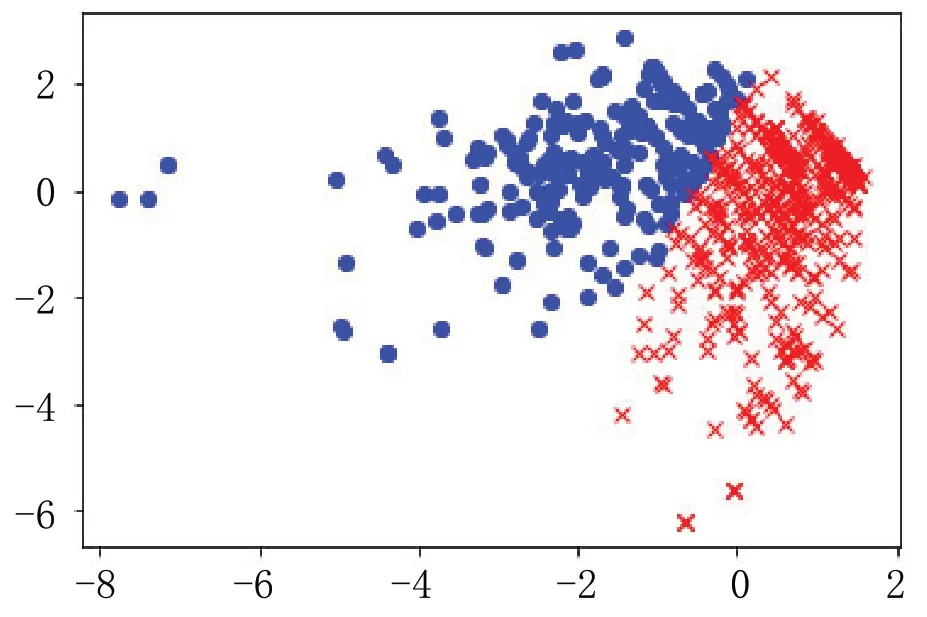
圖3 優化K-means 算法聚類結果Fig.3 Optimize K-means algorithm clustering results
在同一數據集上分別進行K-means 算法和SVDKmeans 算法聚類研究,計算兩種算法聚類準確率如圖4所示。
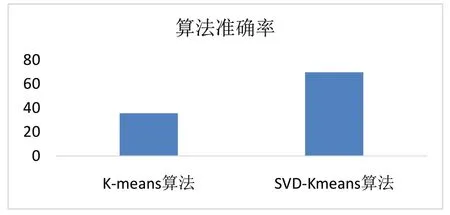
圖4 兩種算法準確率對比Fig.4 Comparison of accuracy between two algorithms
經過對比實驗發現,傳統K-means 算法的準確率為0.3557800224466891,SVD-Kmeans 算法的準確率為0.6980920314253648。
5 結論
通過在數據集進行K-means 聚類算法優化研究,發現當直接使用K-means 算法進行聚類時,準確率只有35.57%,考慮到K-means 算法自身存在的問題,提出優化K-means 算法模型SVD-Kmeans。首先使用奇異值分解方法對數據對象進行降維處理,再使用簇心求解模型確定出兩個初始簇心,然后使用傳統K-means 算法進行聚類研究,通過在同一數據集上再次使用,發現本模型的準確率得到大幅度提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
