基于人工智能的自然語言處理技術的發展與應用
2023-12-05 09:07:46郝立濤于振生
黑龍江科學 2023年22期
郝立濤,于振生
(中國建筑集團有限公司,北京 100029)
自然語言處理(NLP)是人工智能(AI)的一個重要分支,主要用于令計算機理解并生成人類語言。自然語言處理技術使人們能夠與計算機進行更為自然的交互,如搜索引擎查詢、智能語音助手、機器翻譯等。隨著深度學習的發展,特別是在BERT、GPT等模型的推動下,NLP取得了顯著進步。本研究探討了人工智能對自然語言處理技術的影響,綜述了NLP的發展及其在各領域的應用,展望了其未來的發展趨勢。
1 人工智能與自然語言處理技術的發展
早期的NLP系統主要基于手動規則及詞典,受限于語言的復雜性及多樣性,創建與維護規則耗時且困難。隨著統計機器學習方法的出現,人們開始通過大量語料庫學習語言模式,但這種方法忽略了詞的順序及語義信息,對手動設計高度依賴,且無法處理詞匯間的多義性及復雜的語言現象。深度學習的應用改變了NLP領域,主要包括詞嵌入模型(如Word2Vec及GloVe)、序列數據處理的遞歸神經網絡(RNN)及長短期記憶網絡(LSTM)。近幾年,NLP領域出現重大突破,如Transformer模型、大規模預訓練模型BERT及GPT系列,這些模型極大地推動了NLP的應用。各階段發展如圖1。
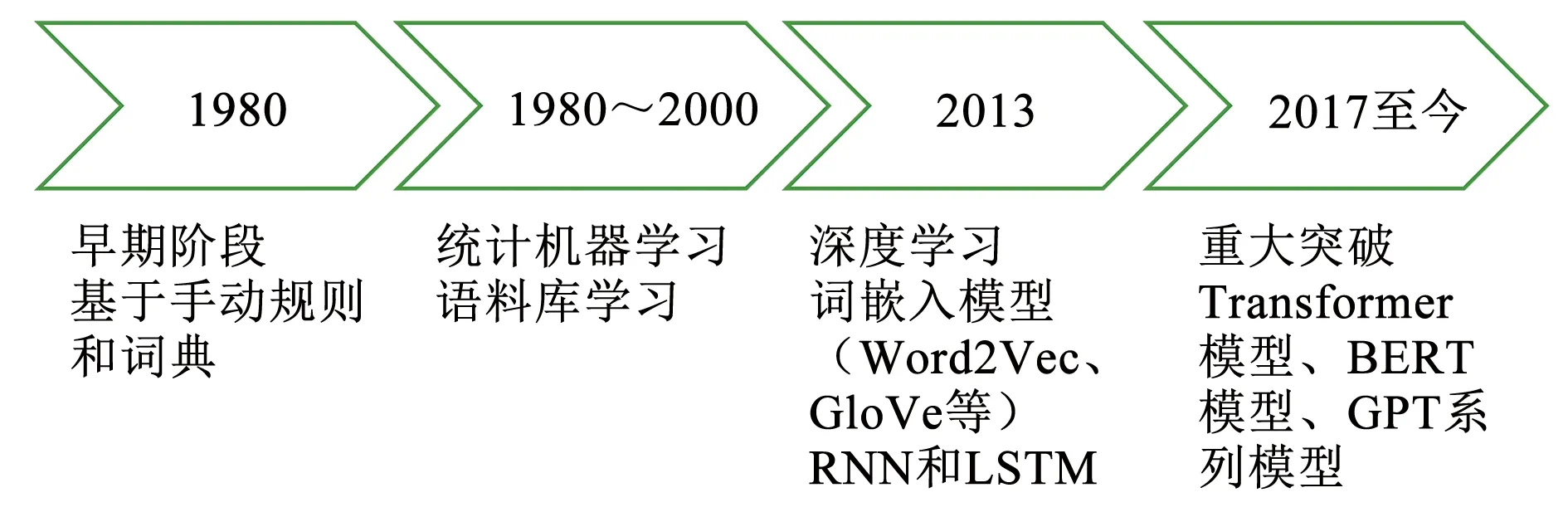
圖1 NLP技術發展歷程Fig.1 History of NLP technology development
1.1 早期的NLP模型及技術
早期的NLP技術主要依賴于手動制定的語法規則及詞典,基于規則的系統通過模擬人類對話來理解簡單的自然語言指令,但無法應對語言的復雜性及多樣性[1]。統計機器學習方法是從大量語料庫中學習語言模式,無需明確編碼語法規則,但需要大量的知識積累,故其性能及泛化能力受到嚴重限制。
1.2 深度學習方法
深度學習方法如神經網絡,能夠自動從原始輸入數據中提取有意義的特征,顯著提升NLP的任務性能。Word2Vec與GloVe等詞嵌入模型的引入為NLP的發展開辟了新道路。這些模型能夠將詞表示為高維向量,捕獲詞的語義及語法信息。例如,詞嵌入模型可捕捉類比關系,如king與queen的關系類似于man與woman。在序列數據處理中,遞歸神經網絡(RNN)是主流。RNN通過維護一個隱藏狀態來捕捉先前輸入的信息,處理序列中的時間依賴性。但隨著時間跨度的增加,RNN在處理長序列時遇到了困難,它們無法有效保留長期依賴信息。為解決這個問題,人們提出了長短期記憶網絡(LSTM),通過引入“門”的機制,選擇性地記住或遺忘信息,從而有效處理長序列[2]。目前已成功將其應用于各種NLP任務,如機器翻譯、語音識別及文本生成。
深度學習是NLP的核心技術,提供了強大的模型及工具,可處理語言的復雜性及豐富性。憑借自動學習特征及處理序列依賴性,深度學習模型大大提升了NLP的任務性能。
1.3 技術發展
近幾年,NLP發展迅速,出現了Transformer模型及大規模預訓練模型,如BERT、GPT系列等,極大推動了NLP的應用。Transformer模型使用自注意力(Self-Attention)機制,摒棄了傳統的序列模型如RNN及LSTM的遞歸結構,使模型能夠并行處理序列中的所有元素,顯著提高計算效率。還能捕獲序列中的長距離依賴關系,這對于許多NLP任務(如機器翻譯、文本摘要等)來說非常重要。故Transformer模型在NLP領域中得到了廣泛應用。BERT(Bidirectional Encoder Representations from Transformers)模型利用大規模的預訓練任務,在海量文本數據基礎上進行自監督學習,學習到了豐富的語義表示。通過預訓練-微調的方式能夠遷移學習各種下游任務,如文本分類、命名實體識別等,在多項NLP基準測試中取得了突破性的成果,成為NLP研究的重點。GPT(Generative Pretrained Transformer)系列模型也是一種預訓練模型。與BERT不同的是,其采用Transformer解碼器進行單向(從左到右)的預訓練。GPT-3是目前最大的GPT模型,含有1750億個參數,能夠生成極其逼真的文本。盡管GPT-3在一些基準測試上的性能略遜于BERT模型,但其在無監督生成任務中表現優異。
2 自然語言處理的主要應用
2.1 搜索引擎的查詢理解與搜索結果排序
搜索引擎幫助人們從海量信息中快速準確地獲取所需的內容。NLP技術的應用可使搜索結果更加智能化、個性化,提升用戶的搜索體驗。在搜索引擎中,查詢理解是第一步。NLP技術能夠幫助搜索引擎理解用戶輸入的自然語言查詢,把用戶的意圖轉化為機器可處理的形式。通過識別關鍵詞、語法結構及語義關聯,NLP可準確地解析查詢,捕捉用戶的搜索意圖并提取關鍵信息[3]。搜索引擎需對候選文檔進行排序,以呈現最相關及有用的搜索結果。傳統的排序算法主要依賴于關鍵詞匹配及網頁排名等,NLP技術可以更深入地理解查詢及文檔內容,基于語義相關性進行排序。例如,使用詞嵌入(word embeddings)技術,NLP可捕捉單詞之間的語義關聯,從而提升排序的準確性及相關性。NLP技術還有諸多應用,如命名實體識別,識別并標記查詢的人名、地名及組織名,提供準確的搜索結果。信息抽取與摘要技術可從文檔中提取關鍵信息并生成簡潔的摘要,幫助用戶快速了解文檔內容。情感分析技術可識別并分析用戶對搜索結果的情感傾向,進一步優化排序及個性化推薦。
2.2 聊天機器人與智能助手
聊天機器人與智能助手通過模擬人與人之間的對話來提供智能化的交互體驗。NLP技術令其能夠理解用戶的自然語言輸入,以自然語言方式與用戶進行交流并提供服務。NLP技術利用語義理解技術,包括命名實體識別、意圖識別及關系抽取等,識別并提取用戶輸入中的關鍵信息,將其轉化為機器可處理的形式,這樣可以更好地理解用戶需求,提供準確及個性化的回應。在對話管理中,NLP技術通過對話狀態追蹤及對話策略管理實現上下文理解及維護,令機器根據對話歷史及上下文作出合理回應,提供符合用戶期望的服務。NLP技術中的語言生成技術可幫助機器生成自然、流暢的回答。例如,使用生成式模型如循環神經網絡(RNN)與轉換器(Transformer),可生成更富表達力及人類化的回復,令對話更加真實可信。
聊天機器人與智能助手應用范圍廣泛,包括客戶服務、智能問答、語音助手等,能夠幫助用戶解答問題、提供信息、執行任務等。NLP技術可實現智能、個性化的對話交互,提供更好的體驗。
2.3 機器翻譯與多語言處理
機器翻譯與多語言處理可解決語言障礙,促進全球交流與理解。NLP技術在其中發揮著關鍵作用,使計算機能夠自動將文本從一種語言轉化為另一種語言,實現跨語言交流及理解。NLP技術的重要作用體現在以下幾方面:①語言模型與翻譯模型。語言模型是機器翻譯的基礎,用于建模不同語言的語法及語義結構。NLP技術可通過建立統計機器翻譯(SMT)模型或基于神經網絡的機器翻譯(NMT)模型對句子進行翻譯和轉換。這些模型使用大規模的雙語語料庫進行訓練,學習源語言與目標語言之間的對應關系,以實現準確的翻譯[4]。②對齊和對比。在機器翻譯中,NLP技術可對齊源語言與目標語言的句子及短語進行對比,找到它們的對應關系。對齊技術可幫助機器翻譯系統理解源語言句子的結構及含義,從而更準確地翻譯。還可用于構建雙語詞典與短語表,以支持更好的翻譯質量及效果。③多語言處理。NLP技術在多語言處理中起到重要的作用,涉及多語言文本的分詞、詞性標注、命名實體識別等任務。多語言處理技術可同時處理多種語言,令NLP系統在多語言環境下具備更廣泛的適應性及應用能力。通過多語言處理,NLP系統能夠跨越語言邊界,實現信息共享與傳遞。
2.4 情感分析與社交媒體監測
情感分析與社會媒體監測是NLP技術在文本分析中的重要應用,通過分析文本中的情感及情緒,幫助人們理解用戶的情感傾向,為企業決策、品牌管理及輿情監測提供有力支持。在情感分析方面,NLP技術可自動識別并分析文本中所表達的情感及情緒。通過使用情感詞典、機器學習及深度學習技術,識別文本中的情感極性(如積極、消極或中性)及情感的細粒度分類(如喜悅、憤怒、悲傷等),有助于企業了解用戶對產品、服務及品牌的態度和情感傾向,為市場營銷與客戶關系管理提供指導。在社會媒體監測方面,NLP技術可幫助企業實時跟蹤社交媒體平臺上的輿情及用戶反饋。通過對大量社交媒體數據進行情感分析及文本挖掘,發現用戶對特定話題、事件或品牌的態度及觀點[5],有助于企業及時了解用戶反饋及需求,進行品牌管理、危機管理及市場調研。
NLP還可用于辨別和過濾惡意評論及虛假信息,保護用戶免受惡意行為及不實信息的影響。還可用于社交媒體內容的自動摘要及推薦,幫助用戶快速獲取感興趣的信息及話題。
2.5 語音識別與語音合成
在語音識別方面,NLP技術可將人類語音轉化為文本形式。使用語音信號處理及機器學習技術,分析并解碼音頻信號,將其轉化為文本表示[6],使計算機能夠理解并處理人類的口頭語言,實現語音輸入、命令執行及語音搜索等功能。語音識別在智能助手、語音交互設備及語音轉寫等方面應用廣泛。
在語音合成方面,NLP技術可將文本轉化為自然流暢的語音。使用語音合成技術將文本轉化為口頭語言,以語音形式傳達給用戶,需要考慮音素、聲調、語速等因素,生成自然、真實的語音輸出。語音合成應用廣泛,包括智能助手、語音導航、有聲讀物等,可提供便捷的語音信息傳遞及交互體驗。
3 展望
多語言處理與跨模態交互。NLP技術要能夠處理多種語言文本,滿足不同地區及用戶的需求。隨著視覺與語音等多模態數據的廣泛應用,跨模態交互將成為研究熱點[7]。NLP技術需結合文本、圖像及語音等多種信息源,實現更豐富、更智能的跨模態交互體驗。
個性化與上下文感知。傳統的NLP系統通常基于靜態模型進行文本處理,缺乏對個體差異及對話上下文的準確理解。未來的發展將致力于構建個性化的NLP系統,根據用戶偏好及背景進行定制化交互。此外,對話系統將更加注重上下文的理解及維護,以實現連貫、自然的對話體驗。
隱私與安全保護。隨著NLP技術的廣泛應用,個人隱私與數據安全問題日益凸顯。未來的發展需要重點關注隱私與安全保護技術。應設計隱私保護機制,確保用戶數據安全及保密性。此外,對抗性攻擊及虛假信息的識別也是一個重要的研究方向,令用戶免受虛假信息及惡意操縱的影響。
隨著NLP技術的不斷發展,其在眾多領域得到了廣泛應用,包括搜索引擎、聊天機器人、機器翻譯及社交媒體監測等,為人們提供了智能、高效的服務。未來,多語言處理與跨模態交互將成為研究重點,個性化與上下文感知的NLP系統將提供智能、個性化的交互體驗。應注重保護用戶數據的安全性及隱私性,促進其深入發展。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
文苑(2018年23期)2018-12-14 01:06:06
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
中國生殖健康(2018年5期)2018-11-06 07:15:40
